 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Priors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning
Jan 20, 2022
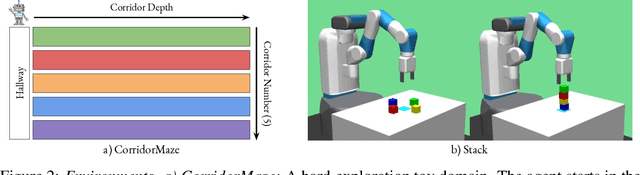
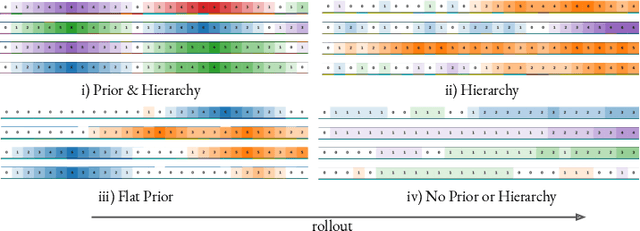
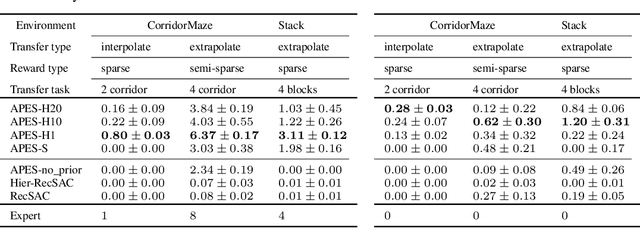
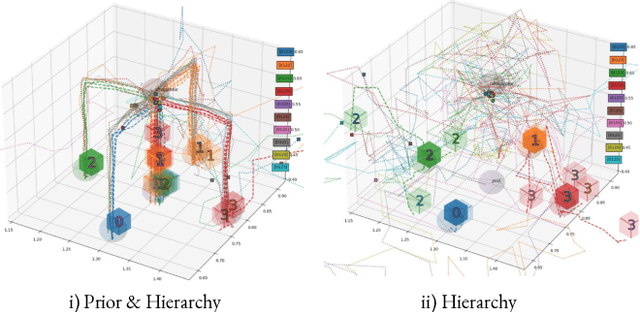
The ability to discover behaviours from past experience and transfer them to new tasks is a hallmark of intelligent agents acting sample-efficiently in the real world. Equipping embodied reinforcement learners with the same ability may be crucial for their successful deployment in robotics. While hierarchical and KL-regularized RL individually hold promise here, arguably a hybrid approach could combine their respective benefits. Key to these fields is the use of information asymmetry to bias which skills are learnt. While asymmetric choice has a large influence on transferability, prior works have explored a narrow range of asymmetries, primarily motivated by intuition. In this paper, we theoretically and empirically show the crucial trade-off, controlled by information asymmetry, between the expressivity and transferability of skills across sequential tasks. Given this insight, we provide a principled approach towards choosing asymmetry and apply our approach to a complex, robotic block stacking domain, unsolvable by baselines, demonstrating the effectiveness of hierarchical KL-regularized RL, coupled with correct asymmetric choice, for sample-efficient transfer learning.
Retweet-BERT: Political Leaning Detection Using Language Features and Information Diffusion on Social Networks
Jul 18, 2022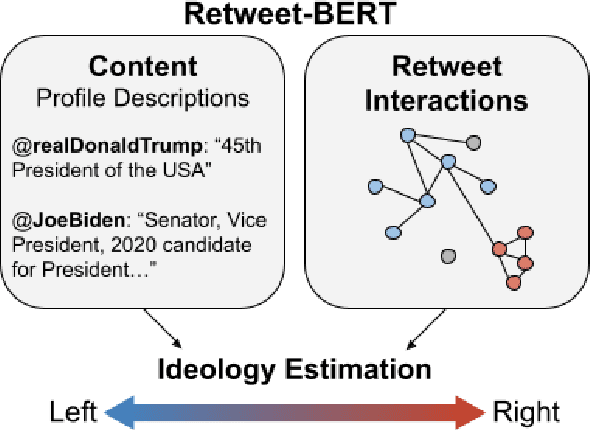
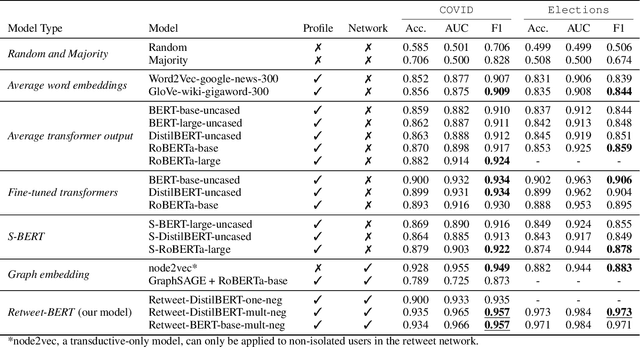
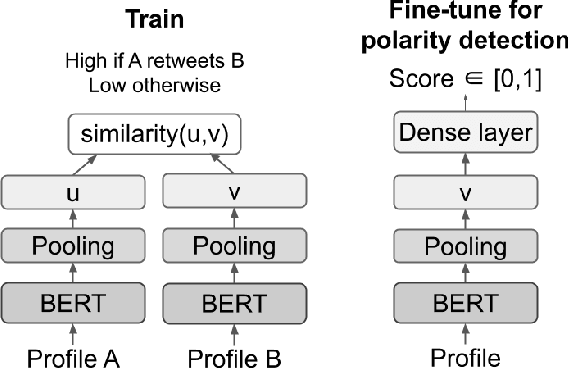

Estimating the political leanings of social media users is a challenging and ever more pressing problem given the increase in social media consumption. We introduce Retweet-BERT, a simple and scalable model to estimate the political leanings of Twitter users. Retweet-BERT leverages the retweet network structure and the language used in users' profile descriptions. Our assumptions stem from patterns of networks and linguistics homophily among people who share similar ideologies. Retweet-BERT demonstrates competitive performance against other state-of-the-art baselines, achieving 96%-97% macro-F1 on two recent Twitter datasets (a COVID-19 dataset and a 2020 United States presidential elections dataset). We also perform manual validation to validate the performance of Retweet-BERT on users not in the training data. Finally, in a case study of COVID-19, we illustrate the presence of political echo chambers on Twitter and show that it exists primarily among right-leaning users. Our code is open-sourced and our data is publicly available.
* 11 pages, 3 figures, 4 tables. arXiv admin note: text overlap with arXiv:2103.10979
Speeding Up Action Recognition Using Dynamic Accumulation of Residuals in Compressed Domain
Sep 29, 2022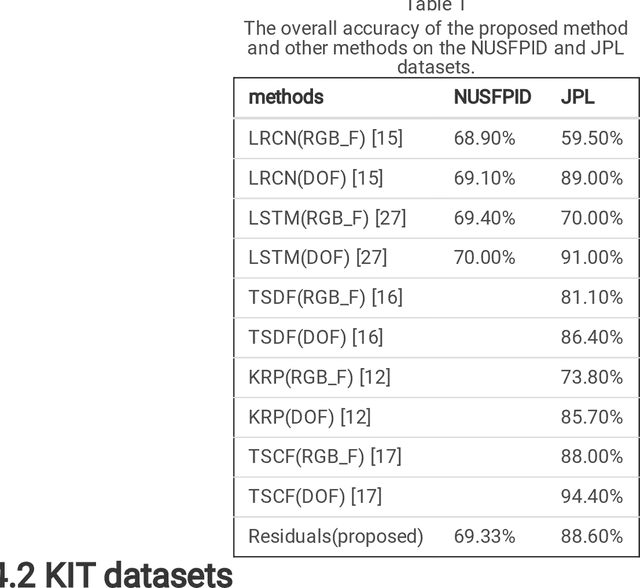
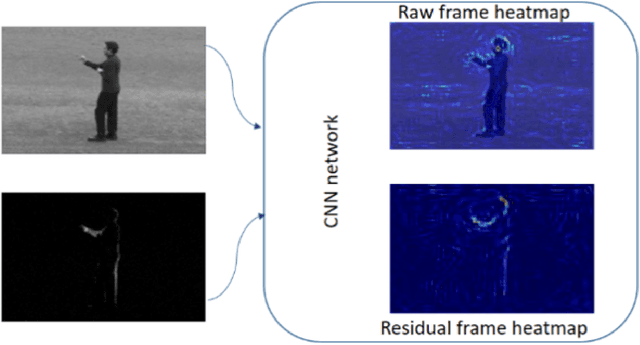
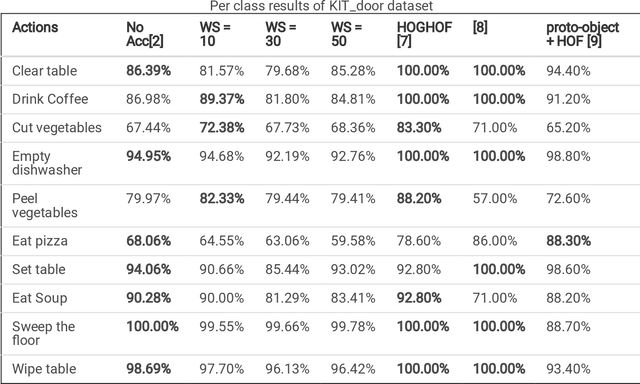

With the widespread use of installed cameras, video-based monitoring approaches have seized considerable attention for different purposes like assisted living. Temporal redundancy and the sheer size of raw videos are the two most common problematic issues related to video processing algorithms. Most of the existing methods mainly focused on increasing accuracy by exploring consecutive frames, which is laborious and cannot be considered for real-time applications. Since videos are mostly stored and transmitted in compressed format, these kinds of videos are available on many devices. Compressed videos contain a multitude of beneficial information, such as motion vectors and quantized coefficients. Proper use of this available information can greatly improve the video understanding methods' performance. This paper presents an approach for using residual data, available in compressed videos directly, which can be obtained by a light partially decoding procedure. In addition, a method for accumulating similar residuals is proposed, which dramatically reduces the number of processed frames for action recognition. Applying neural networks exclusively for accumulated residuals in the compressed domain accelerates performance, while the classification results are highly competitive with raw video approaches.
Optimizing Crop Management with Reinforcement Learning and Imitation Learning
Sep 20, 2022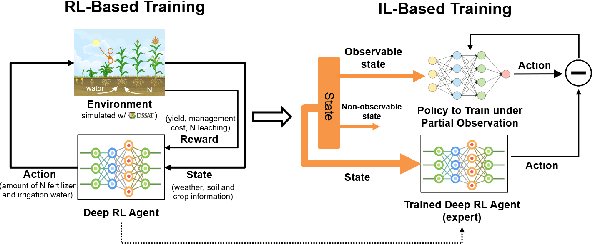
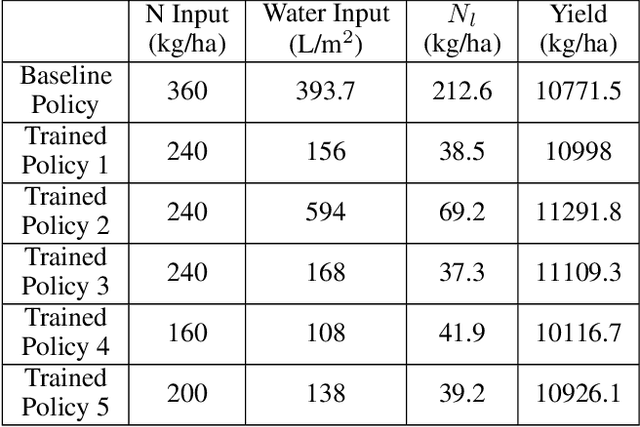
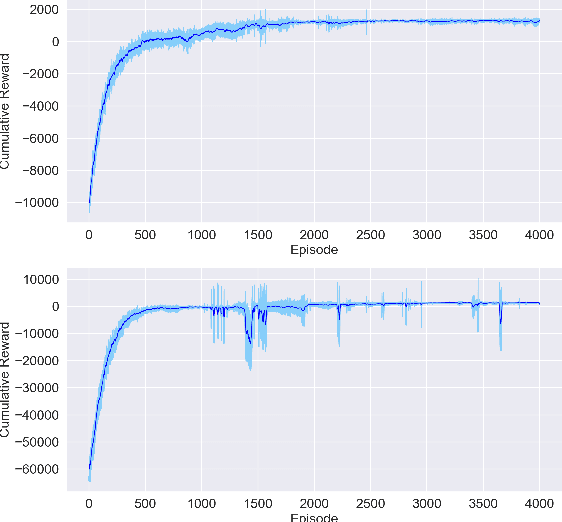
Crop management, including nitrogen (N) fertilization and irrigation management, has a significant impact on the crop yield, economic profit, and the environment. Although management guidelines exist, it is challenging to find the optimal management practices given a specific planting environment and a crop. Previous work used reinforcement learning (RL) and crop simulators to solve the problem, but the trained policies either have limited performance or are not deployable in the real world. In this paper, we present an intelligent crop management system which optimizes the N fertilization and irrigation simultaneously via RL, imitation learning (IL), and crop simulations using the Decision Support System for Agrotechnology Transfer (DSSAT). We first use deep RL, in particular, deep Q-network, to train management policies that require all state information from the simulator as observations (denoted as full observation). We then invoke IL to train management policies that only need a limited amount of state information that can be readily obtained in the real world (denoted as partial observation) by mimicking the actions of the previously RL-trained policies under full observation. We conduct experiments on a case study using maize in Florida and compare trained policies with a maize management guideline in simulations. Our trained policies under both full and partial observations achieve better outcomes, resulting in a higher profit or a similar profit with a smaller environmental impact. Moreover, the partial-observation management policies are directly deployable in the real world as they use readily available information.
ResAttUNet: Detecting Marine Debris using an Attention activated Residual UNet
Oct 16, 2022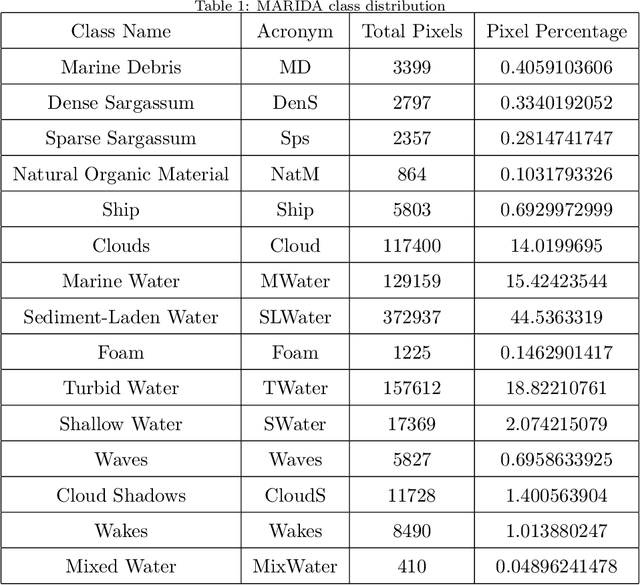
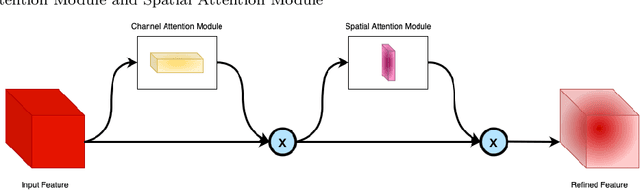
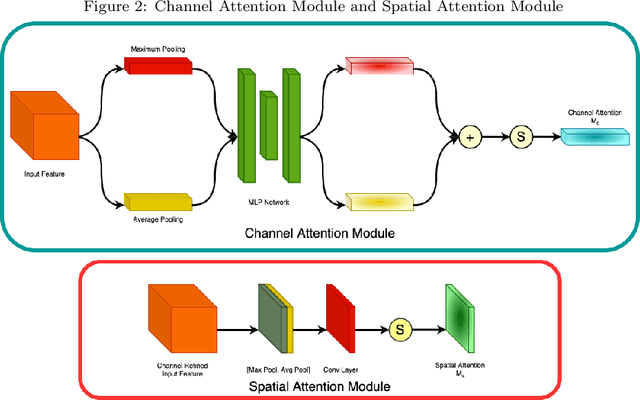
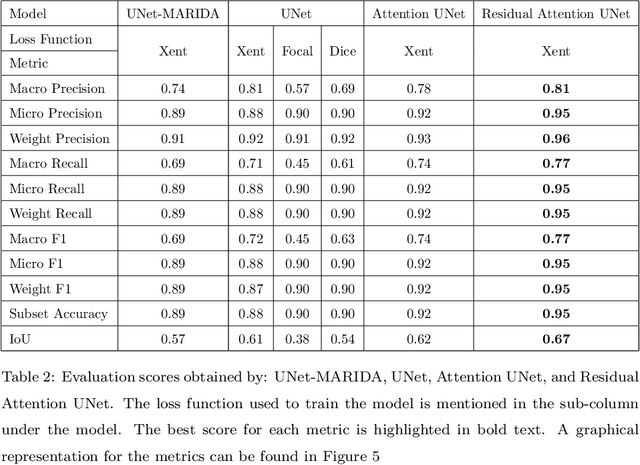
Currently, a significant amount of research has been done in field of Remote Sensing with the use of deep learning techniques. The introduction of Marine Debris Archive (MARIDA), an open-source dataset with benchmark results, for marine debris detection opened new pathways to use deep learning techniques for the task of debris detection and segmentation. This paper introduces a novel attention based segmentation technique that outperforms the existing state-of-the-art results introduced with MARIDA. The paper presents a novel spatial aware encoder and decoder architecture to maintain the contextual information and structure of sparse ground truth patches present in the images. The attained results are expected to pave the path for further research involving deep learning using remote sensing images. The code is available at https://github.com/sheikhazhanmohammed/SADMA.git
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
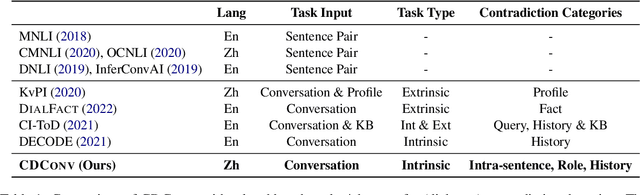

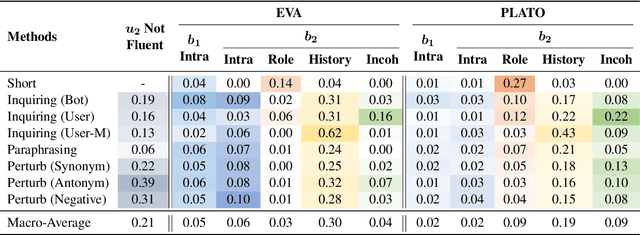
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.
Structure-Preserving Spectral Reflectance Estimation using Guided Filtering
Sep 16, 2022

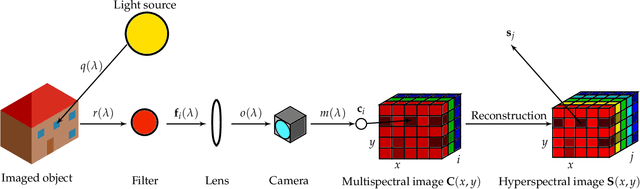
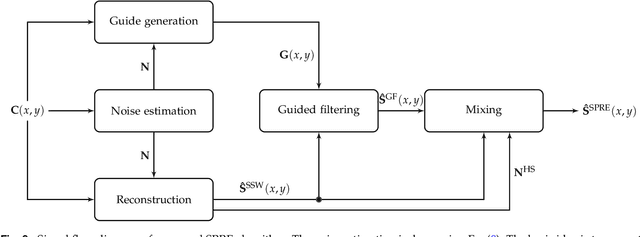
Light spectra are a very important source of information for diverse classification problems, e.g., for discrimination of materials. To lower the cost for acquiring this information, multispectral cameras are used. Several techniques exist for estimating light spectra out of multispectral images by exploiting properties about the spectrum. Unfortunately, especially when capturing multispectral videos, the images are heavily affected by noise due to the nature of limited exposure times in videos. Therefore, models that explicitly try to lower the influence of noise on the reconstructed spectrum are highly desirable. Hence, a novel reconstruction algorithm is presented. This novel estimation method is based on the guided filtering technique which preserves basic structures, while using spatial information to reduce the influence of noise. The evaluation based on spectra of natural images reveals that this new technique yields better quantitative and subjective results in noisy scenarios than other state-of-the-art spatial reconstruction methods. Specifically, the proposed algorithm lowers the mean squared error and the spectral angle up to 46% and 35% in noisy scenarios, respectively. Furthermore, it is shown that the proposed reconstruction technique works out-of-the-box and does not need any calibration or training by reconstructing spectra from a real-world multispectral camera with nine channels.
HSVI can solve zero-sum Partially Observable Stochastic Games
Oct 26, 2022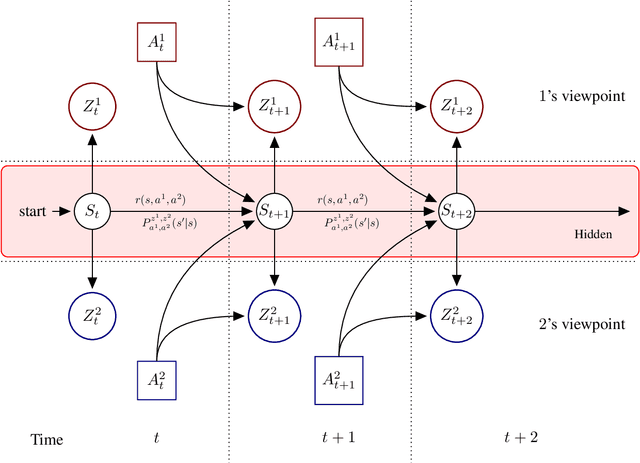
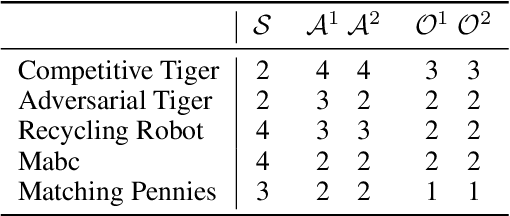
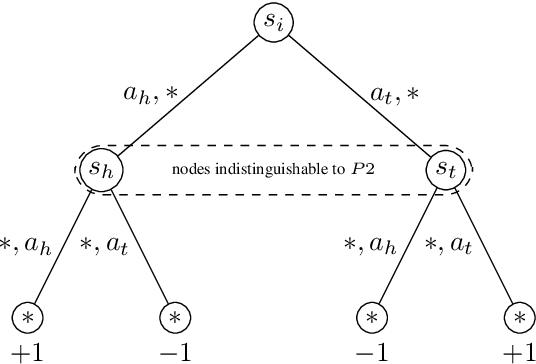
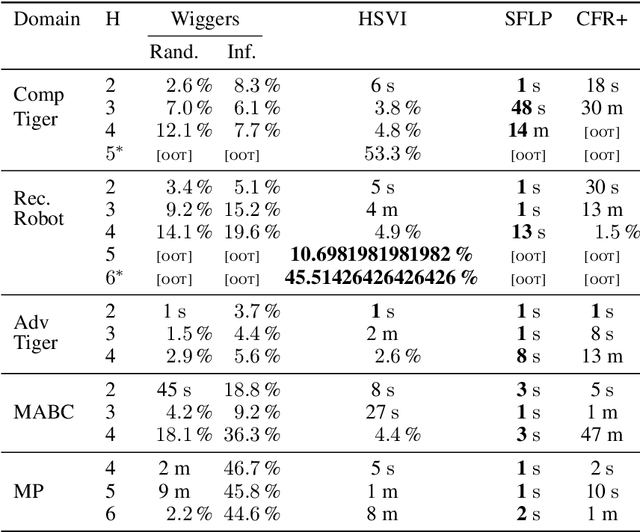
State-of-the-art methods for solving 2-player zero-sum imperfect information games rely on linear programming or regret minimization, though not on dynamic programming (DP) or heuristic search (HS), while the latter are often at the core of state-of-the-art solvers for other sequential decision-making problems. In partially observable or collaborative settings (e.g., POMDPs and Dec- POMDPs), DP and HS require introducing an appropriate statistic that induces a fully observable problem as well as bounding (convex) approximators of the optimal value function. This approach has succeeded in some subclasses of 2-player zero-sum partially observable stochastic games (zs- POSGs) as well, but how to apply it in the general case still remains an open question. We answer it by (i) rigorously defining an equivalent game to work with, (ii) proving mathematical properties of the optimal value function that allow deriving bounds that come with solution strategies, (iii) proposing for the first time an HSVI-like solver that provably converges to an $\epsilon$-optimal solution in finite time, and (iv) empirically analyzing it. This opens the door to a novel family of promising approaches complementing those relying on linear programming or iterative methods.
Deep Learning is Provably Robust to Symmetric Label Noise
Oct 26, 2022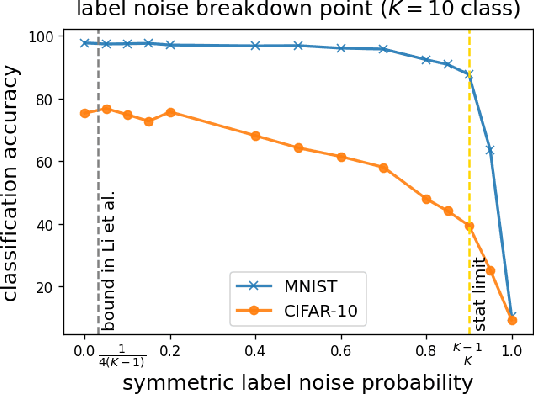
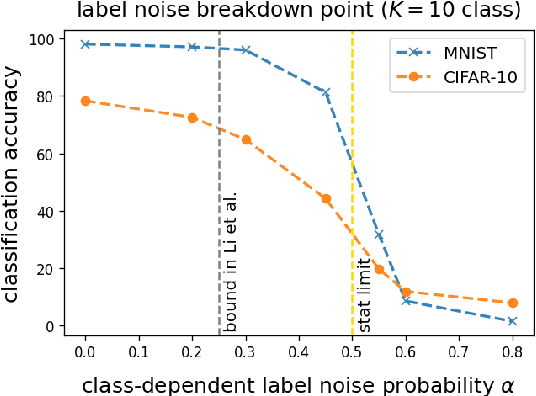
Deep neural networks (DNNs) are capable of perfectly fitting the training data, including memorizing noisy data. It is commonly believed that memorization hurts generalization. Therefore, many recent works propose mitigation strategies to avoid noisy data or correct memorization. In this work, we step back and ask the question: Can deep learning be robust against massive label noise without any mitigation? We provide an affirmative answer for the case of symmetric label noise: We find that certain DNNs, including under-parameterized and over-parameterized models, can tolerate massive symmetric label noise up to the information-theoretic threshold. By appealing to classical statistical theory and universal consistency of DNNs, we prove that for multiclass classification, $L_1$-consistent DNN classifiers trained under symmetric label noise can achieve Bayes optimality asymptotically if the label noise probability is less than $\frac{K-1}{K}$, where $K \ge 2$ is the number of classes. Our results show that for symmetric label noise, no mitigation is necessary for $L_1$-consistent estimators. We conjecture that for general label noise, mitigation strategies that make use of the noisy data will outperform those that ignore the noisy data.
A practical method for occupational skills detection in Vietnamese job listings
Oct 26, 2022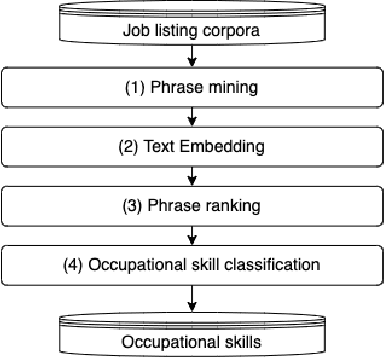
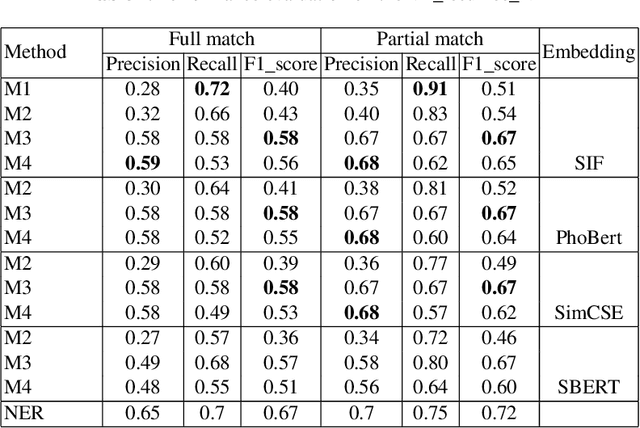
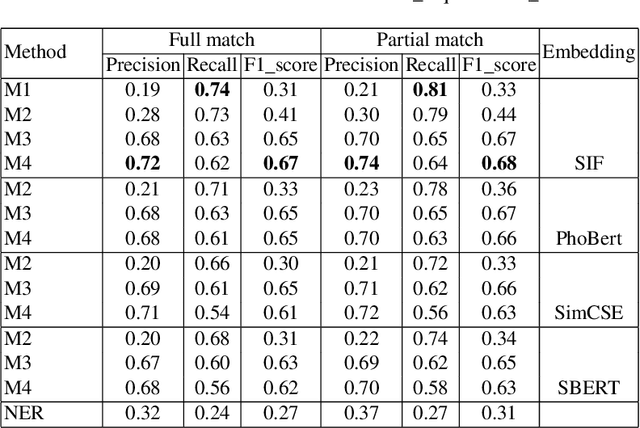
Vietnamese labor market has been under an imbalanced development. The number of university graduates is growing, but so is the unemployment rate. This situation is often caused by the lack of accurate and timely labor market information, which leads to skill miss-matches between worker supply and the actual market demands. To build a data monitoring and analytic platform for the labor market, one of the main challenges is to be able to automatically detect occupational skills from labor-related data, such as resumes and job listings. Traditional approaches rely on existing taxonomy and/or large annotated data to build Named Entity Recognition (NER) models. They are expensive and require huge manual efforts. In this paper, we propose a practical methodology for skill detection in Vietnamese job listings. Rather than viewing the task as a NER task, we consider the task as a ranking problem. We propose a pipeline in which phrases are first extracted and ranked in semantic similarity with the phrases' contexts. Then we employ a final classification to detect skill phrases. We collected three datasets and conducted extensive experiments. The results demonstrated that our methodology achieved better performance than a NER model in scarce datasets.