 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
Dec 14, 2021
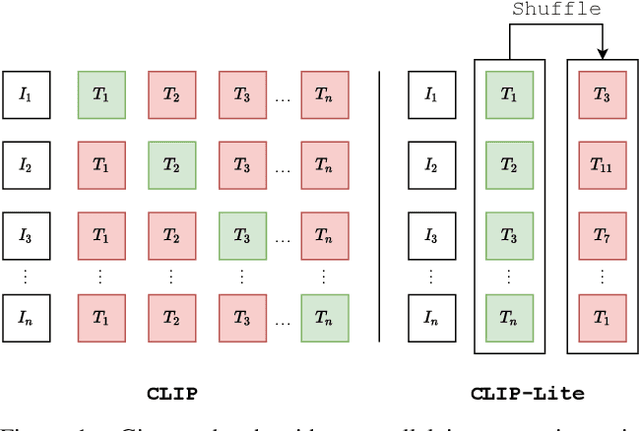
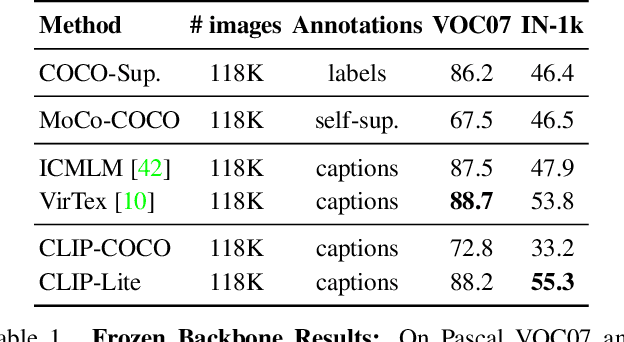
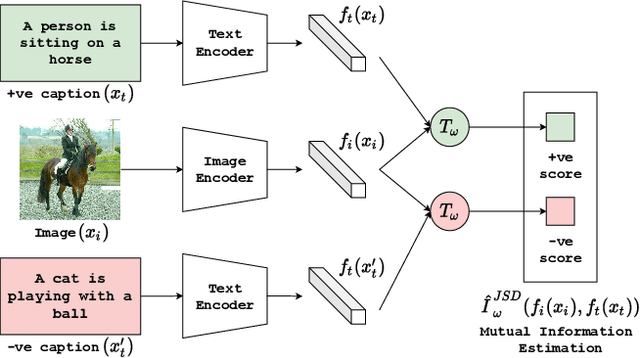
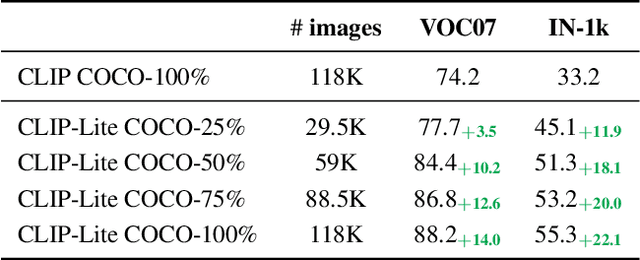
We propose CLIP-Lite, an information efficient method for visual representation learning by feature alignment with textual annotations. Compared to the previously proposed CLIP model, CLIP-Lite requires only one negative image-text sample pair for every positive image-text sample during the optimization of its contrastive learning objective. We accomplish this by taking advantage of an information efficient lower-bound to maximize the mutual information between the two input modalities. This allows CLIP-Lite to be trained with significantly reduced amounts of data and batch sizes while obtaining better performance than CLIP. We evaluate CLIP-Lite by pretraining on the COCO-Captions dataset and testing transfer learning to other datasets. CLIP-Lite obtains a +15.4% mAP absolute gain in performance on Pascal VOC classification, and a +22.1% top-1 accuracy gain on ImageNet, while being comparable or superior to other, more complex, text-supervised models. CLIP-Lite is also superior to CLIP on image and text retrieval, zero-shot classification, and visual grounding. Finally, by performing explicit image-text alignment during representation learning, we show that CLIP-Lite can leverage language semantics to encourage bias-free visual representations that can be used in downstream tasks.
Enabling Digital Twin in Vehicular Edge Computing: A Multi-Agent Multi-Objective Deep Reinforcement Learning Solution
Oct 31, 2022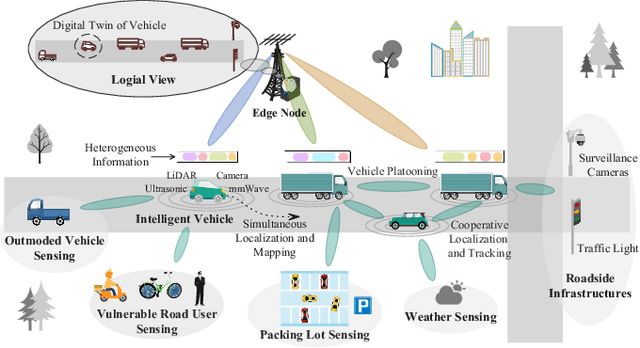
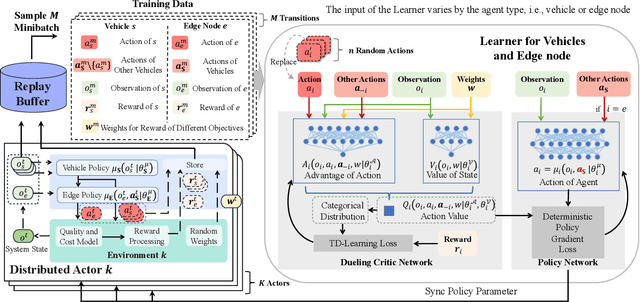
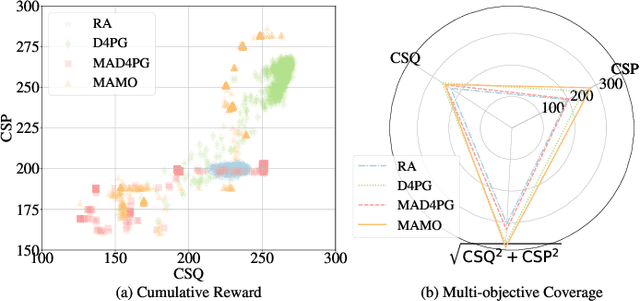
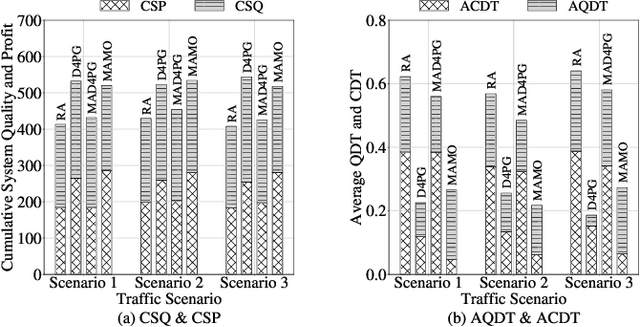
With recent advances in sensing technologies, wireless communications, and computing paradigms, traditional vehicles are evolving to electronic consumer products, driving the research on digital twins in vehicular edge computing (DT-VEC). This paper makes the first attempt to achieve the quality-cost tradeoff in DT-VEC. First, a DT-VEC architecture is presented, where the heterogeneous information can be sensed by vehicles and uploaded to the edge node via vehicle-to-infrastructure (V2I) communications. The DT-VEC are modeled at the edge node, forming a logical view to reflect the physical vehicular environment. Second, we model the DT-VEC by deriving an ISAC (integrated sensing and communication)-assisted sensing model and a reliability-guaranteed uploading model. Third, we define the quality of DT-VEC by considering the timeliness and consistency, and define the cost of DT-VEC by considering the redundancy, sensing cost, and transmission cost. Then, a bi-objective problem is formulated to maximize the quality and minimize the cost. Fourth, we propose a multi-agent multi-objective (MAMO) deep reinforcement learning solution implemented distributedly in the vehicles and the edge nodes. Specifically, a dueling critic network is proposed to evaluate the advantage of action over the average of random actions. Finally, we give a comprehensive performance evaluation, demonstrating the superiority of the proposed MAMO.
Emotional Brain State Classification on fMRI Data Using Deep Residual and Convolutional Networks
Oct 31, 2022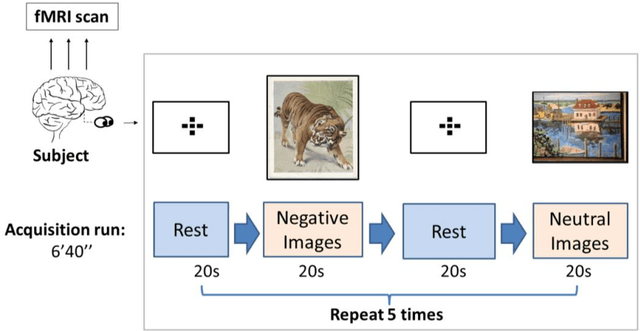
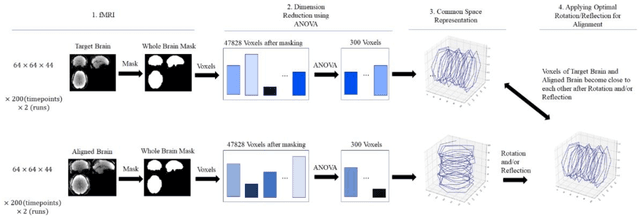
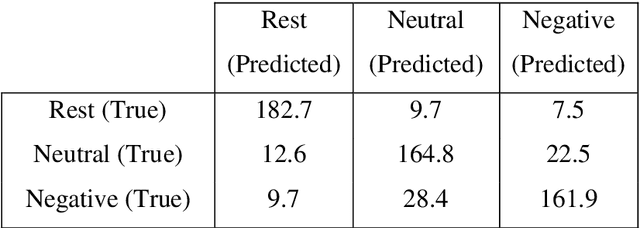
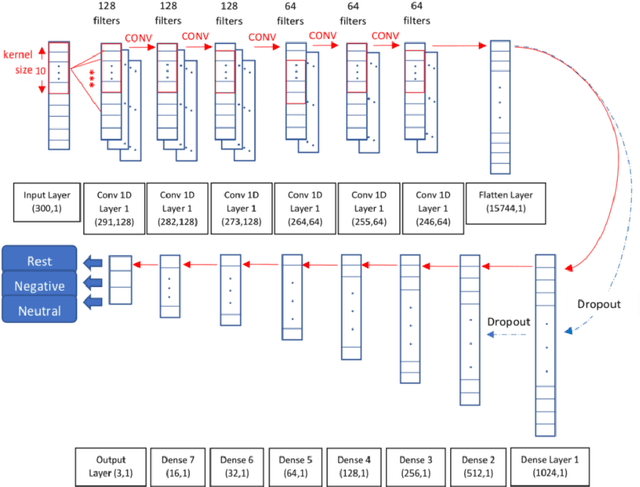
The goal of emotional brain state classification on functional MRI (fMRI) data is to recognize brain activity patterns related to specific emotion tasks performed by subjects during an experiment. Distinguishing emotional brain states from other brain states using fMRI data has proven to be challenging due to two factors: a difficulty to generate fast yet accurate predictions in short time frames, and a difficulty to extract emotion features which generalize to unseen subjects. To address these challenges, we conducted an experiment in which 22 subjects viewed pictures designed to stimulate either negative, neutral or rest emotional responses while their brain activity was measured using fMRI. We then developed two distinct Convolution-based approaches to decode emotional brain states using only spatial information from single, minimally pre-processed (slice timing and realignment) fMRI volumes. In our first approach, we trained a 1D Convolutional Network (84.9% accuracy; chance level 33%) to classify 3 emotion conditions using One-way Analysis of Variance (ANOVA) voxel selection combined with hyperalignment. In our second approach, we trained a 3D ResNet-50 model (78.0% accuracy; chance level 50%) to classify 2 emotion conditions from single 3D fMRI volumes directly. Our Convolutional and Residual classifiers successfully learned group-level emotion features and could decode emotion conditions from fMRI volumes in milliseconds. These approaches could potentially be used in brain computer interfaces and real-time fMRI neurofeedback research.
Chance-Constrained Motion Planning with Event-Triggered Estimation
Oct 13, 2022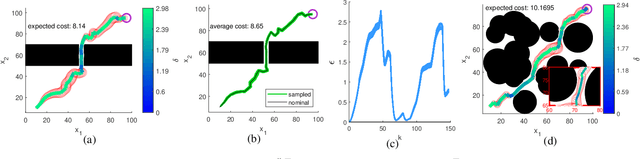
We consider the problem of autonomous navigation using limited information from a remote sensor network. Because the remote sensors are power and bandwidth limited, we use event-triggered (ET) estimation to manage communication costs. We introduce a fast and efficient sampling-based planner which computes motion plans coupled with ET communication strategies that minimize communication costs, while satisfying constraints on the probability of reaching the goal region and the point-wise probability of collision. We derive a novel method for offline propagation of the expected state distribution, and corresponding bounds on this distribution. These bounds are used to evaluate the chance constraints in the algorithm. Case studies establish the validity of our approach, demonstrating fast computation of optimal plans.
Knowledge-grounded Dialog State Tracking
Oct 13, 2022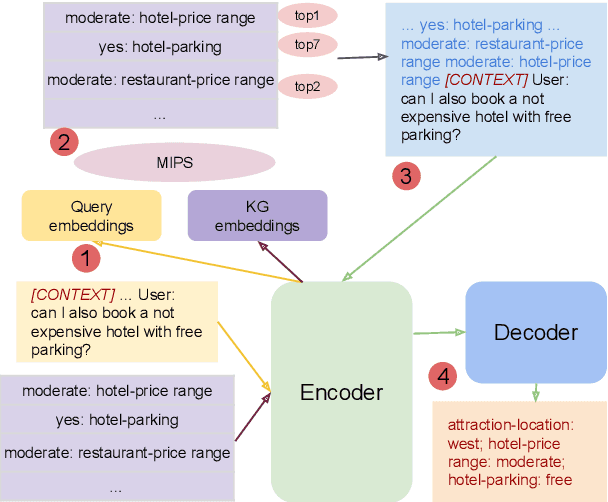
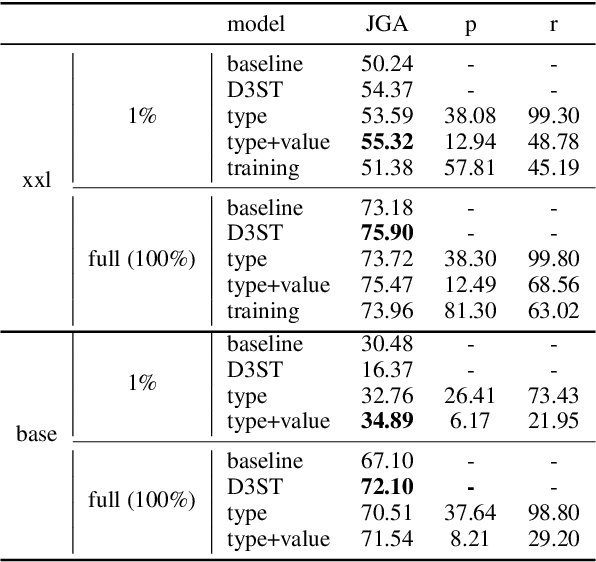
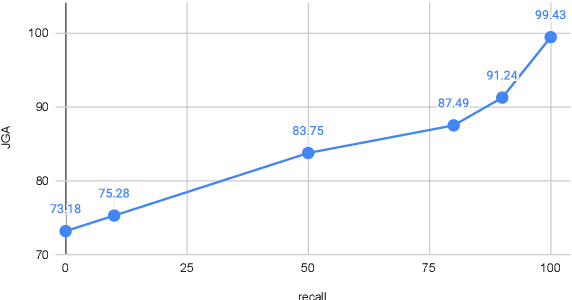
Knowledge (including structured knowledge such as schema and ontology, and unstructured knowledge such as web corpus) is a critical part of dialog understanding, especially for unseen tasks and domains. Traditionally, such domain-specific knowledge is encoded implicitly into model parameters for the execution of downstream tasks, which makes training inefficient. In addition, such models are not easily transferable to new tasks with different schemas. In this work, we propose to perform dialog state tracking grounded on knowledge encoded externally. We query relevant knowledge of various forms based on the dialog context where such information can ground the prediction of dialog states. We demonstrate superior performance of our proposed method over strong baselines, especially in the few-shot learning setting.
Multi-stage image denoising with the wavelet transform
Sep 27, 2022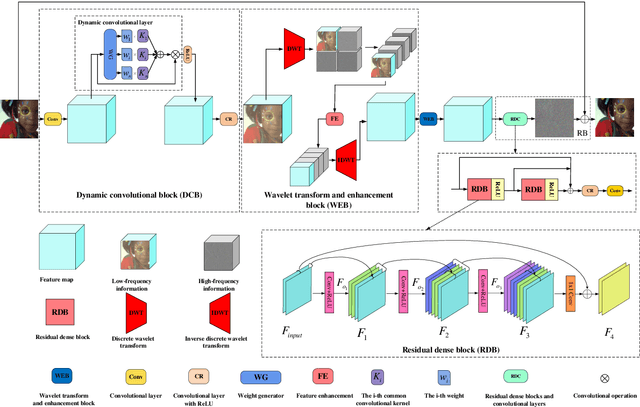
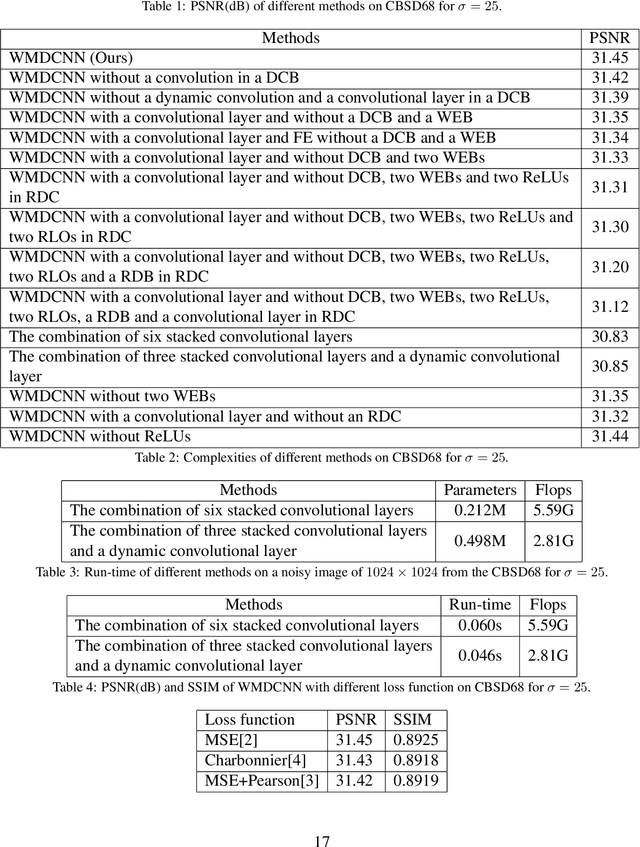
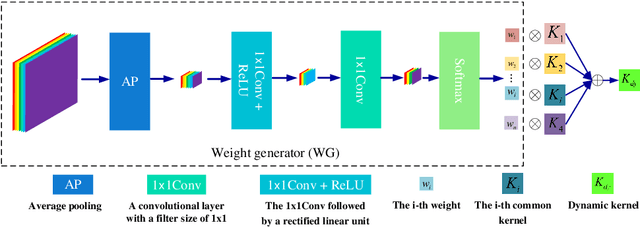
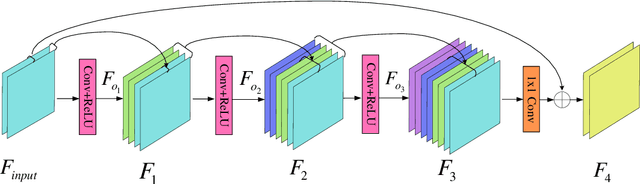
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
Covered Information Disentanglement: Model Transparency via Unbiased Permutation Importance
Nov 18, 2021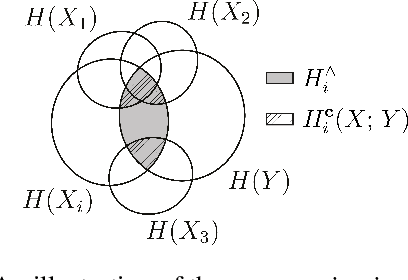
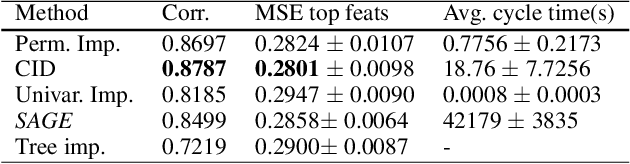
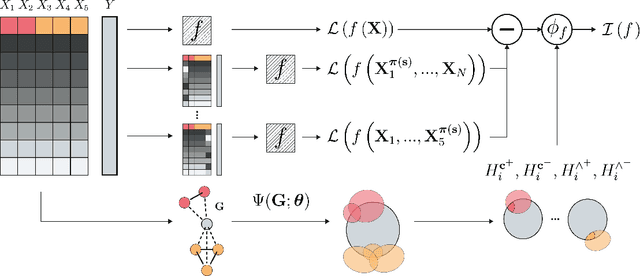
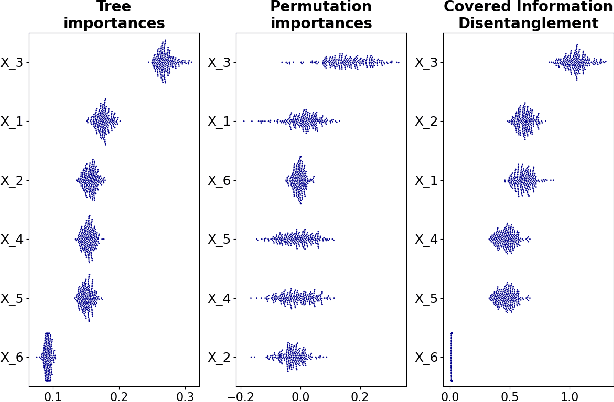
Model transparency is a prerequisite in many domains and an increasingly popular area in machine learning research. In the medical domain, for instance, unveiling the mechanisms behind a disease often has higher priority than the diagnostic itself since it might dictate or guide potential treatments and research directions. One of the most popular approaches to explain model global predictions is the permutation importance where the performance on permuted data is benchmarked against the baseline. However, this method and other related approaches will undervalue the importance of a feature in the presence of covariates since these cover part of its provided information. To address this issue, we propose Covered Information Disentanglement (CID), a method that considers all feature information overlap to correct the values provided by permutation importance. We further show how to compute CID efficiently when coupled with Markov random fields. We demonstrate its efficacy in adjusting permutation importance first on a controlled toy dataset and discuss its effect on real-world medical data.
Adversarial Auto-Augment with Label Preservation: A Representation Learning Principle Guided Approach
Nov 02, 2022

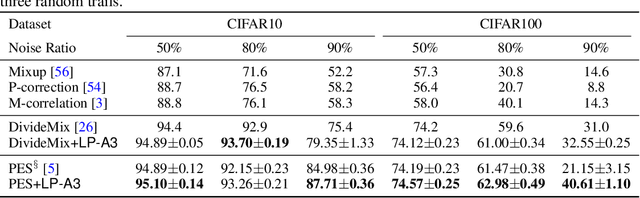

Data augmentation is a critical contributing factor to the success of deep learning but heavily relies on prior domain knowledge which is not always available. Recent works on automatic data augmentation learn a policy to form a sequence of augmentation operations, which are still pre-defined and restricted to limited options. In this paper, we show that a prior-free autonomous data augmentation's objective can be derived from a representation learning principle that aims to preserve the minimum sufficient information of the labels. Given an example, the objective aims at creating a distant "hard positive example" as the augmentation, while still preserving the original label. We then propose a practical surrogate to the objective that can be optimized efficiently and integrated seamlessly into existing methods for a broad class of machine learning tasks, e.g., supervised, semi-supervised, and noisy-label learning. Unlike previous works, our method does not require training an extra generative model but instead leverages the intermediate layer representations of the end-task model for generating data augmentations. In experiments, we show that our method consistently brings non-trivial improvements to the three aforementioned learning tasks from both efficiency and final performance, either or not combined with strong pre-defined augmentations, e.g., on medical images when domain knowledge is unavailable and the existing augmentation techniques perform poorly. Code is available at: https://github.com/kai-wen-yang/LPA3}{https://github.com/kai-wen-yang/LPA3.
Consistent Training via Energy-Based GFlowNets for Modeling Discrete Joint Distributions
Nov 02, 2022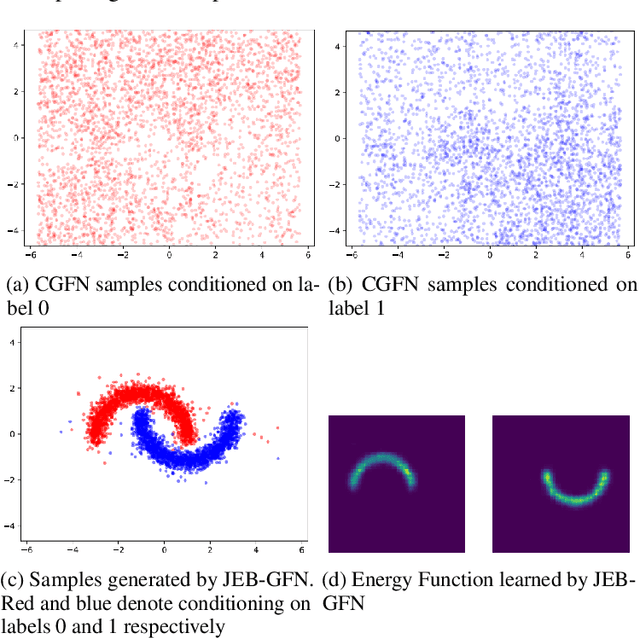
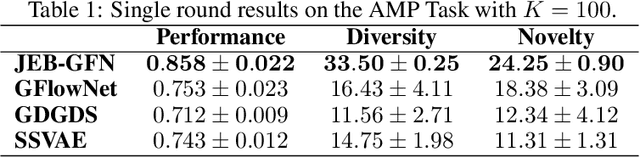
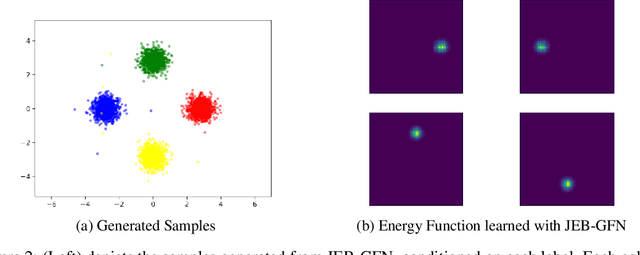
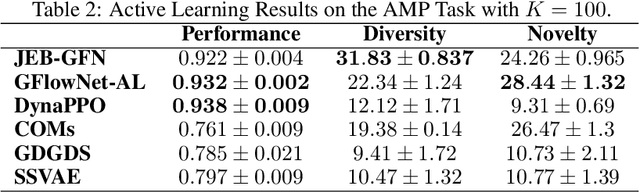
Generative Flow Networks (GFlowNets) have demonstrated significant performance improvements for generating diverse discrete objects $x$ given a reward function $R(x)$, indicating the utility of the object and trained independently from the GFlowNet by supervised learning to predict a desirable property $y$ given $x$. We hypothesize that this can lead to incompatibility between the inductive optimization biases in training $R$ and in training the GFlowNet, potentially leading to worse samples and slow adaptation to changes in the distribution. In this work, we build upon recent work on jointly learning energy-based models with GFlowNets and extend it to learn the joint over multiple variables, which we call Joint Energy-Based GFlowNets (JEBGFNs), such as peptide sequences and their antimicrobial activity. Joint learning of the energy-based model, used as a reward for the GFlowNet, can resolve the issues of incompatibility since both the reward function $R$ and the GFlowNet sampler are trained jointly. We find that this joint training or joint energy-based formulation leads to significant improvements in generating anti-microbial peptides. As the training sequences arose out of evolutionary or artificial selection for high antibiotic activity, there is presumably some structure in the distribution of sequences that reveals information about the antibiotic activity. This results in an advantage to modeling their joint generatively vs. pure discriminative modeling. We also evaluate JEBGFN in an active learning setting for discovering anti-microbial peptides.
The Lottery Ticket Hypothesis for Vision Transformers
Nov 02, 2022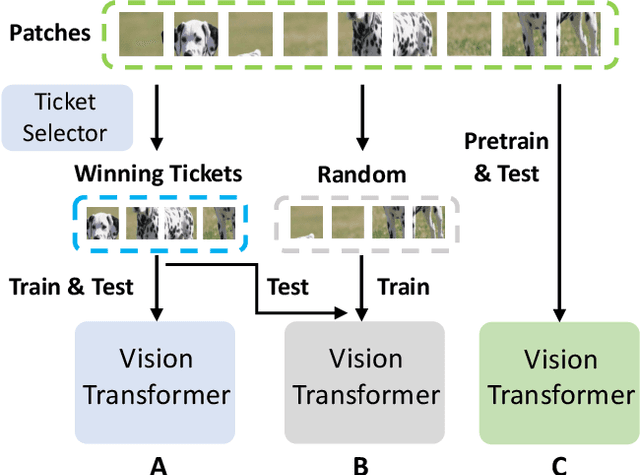
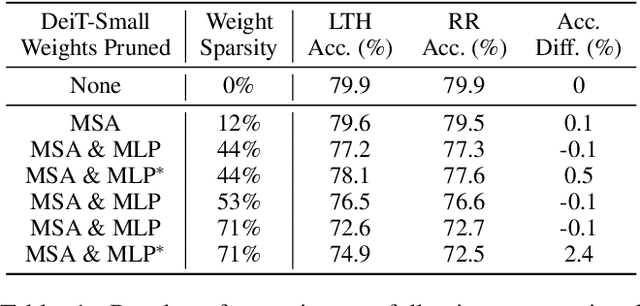
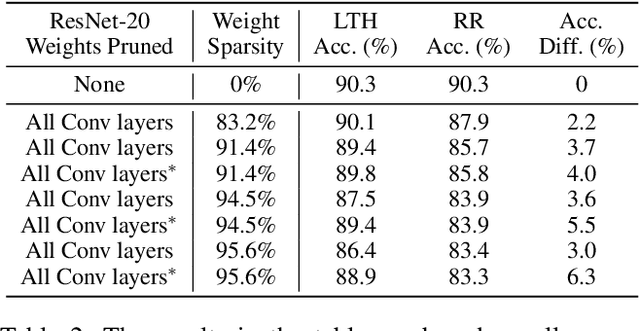
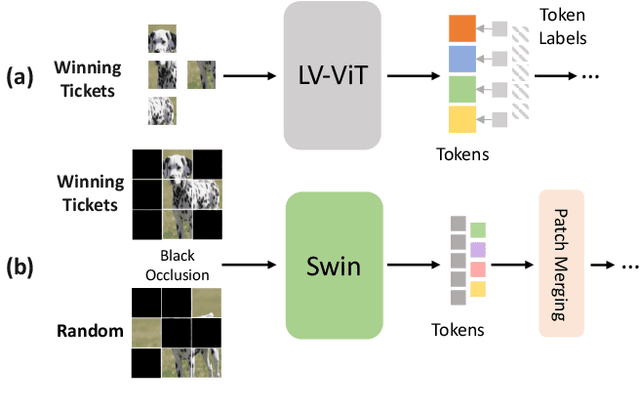
The conventional lottery ticket hypothesis (LTH) claims that there exists a sparse subnetwork within a dense neural network and a proper random initialization method, called the winning ticket, such that it can be trained from scratch to almost as good as the dense counterpart. Meanwhile, the research of LTH in vision transformers (ViTs) is scarcely evaluated. In this paper, we first show that the conventional winning ticket is hard to find at weight level of ViTs by existing methods. Then, we generalize the LTH for ViTs to input images consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. We call this subset of input patches the winning tickets, which represent a significant amount of information in the input. Furthermore, we present a simple yet effective method to find the winning tickets in input patches for various types of ViT, including DeiT, LV-ViT, and Swin Transformers. More specifically, we use a ticket selector to generate the winning tickets based on the informativeness of patches. Meanwhile, we build another randomly selected subset of patches for comparison, and the experiments show that there is clear difference between the performance of models trained with winning tickets and randomly selected subsets.