 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tighter PAC-Bayes Generalisation Bounds by Leveraging Example Difficulty
Oct 20, 2022
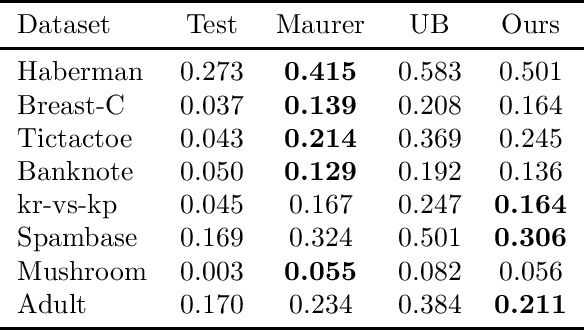
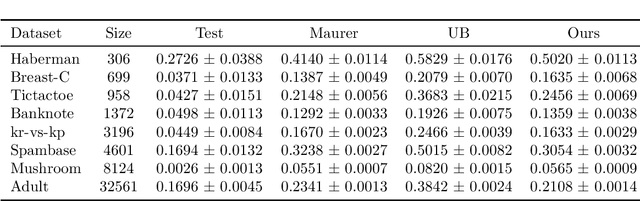
We introduce a modified version of the excess risk, which can be used to obtain tighter, fast-rate PAC-Bayesian generalisation bounds. This modified excess risk leverages information about the relative hardness of data examples to reduce the variance of its empirical counterpart, tightening the bound. We combine this with a new bound for $[-1, 1]$-valued (and potentially non-independent) signed losses, which is more favourable when they empirically have low variance around $0$. The primary new technical tool is a novel result for sequences of interdependent random vectors which may be of independent interest. We empirically evaluate these new bounds on a number of real-world datasets.
Optimizing Information Freshness in RIS-assisted NOMA-based IoT Networks
Feb 28, 2022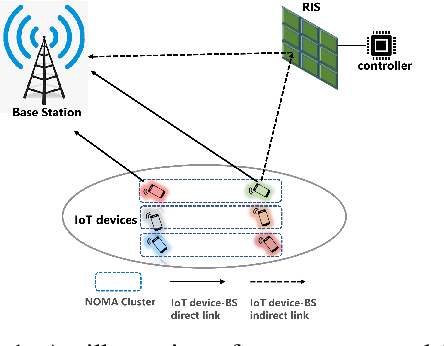
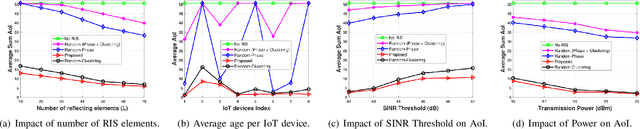
This paper investigates the benefits of integrating reconfigurable intelligent surface (RIS) on minimizing the average sum age of information (AoI) in uplink non-orthogonal multiple access-based Internet-of-Things (IoT) networks. In this setup, an optimization problem is formulated to optimize the RIS configuration, the transmit power per IoT device and the clustering policy of IoT devices. The formulated problem is a mixed-integer non-convex one, and in order to solve it we obtain first the RIS configuration by adopting a semi-definite relaxation (SDR) approach. Afterwards, the joint power allocation and user-clustering problem is solved using the concept of bi-level optimization and is decomposed into an outer user clustering problem and an inner power allocation problem. Optimal closed-form expressions are derived for the inner problem and the Hungarian method is employed to solve the outer one. Numerical results demonstrate the performance superiority of our approach.
Information Extraction through AI techniques: The KIDs use case at CONSOB
Jan 29, 2022
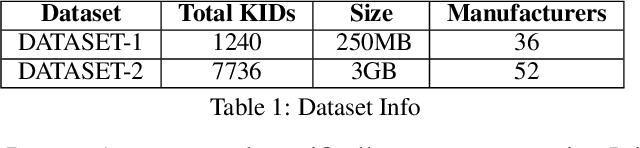
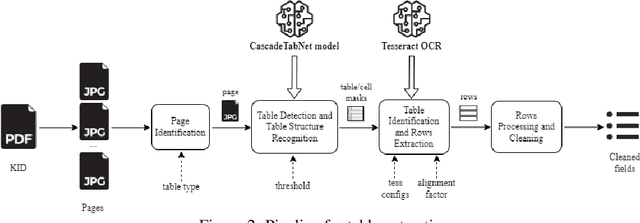
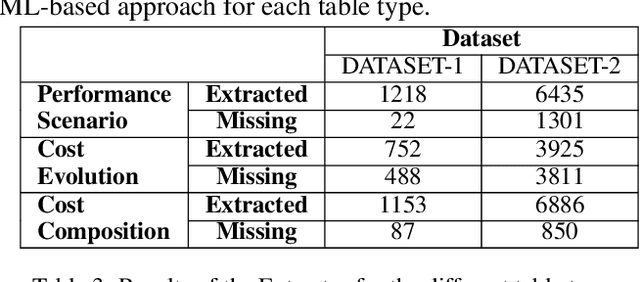
In this paper we report on the initial activities carried out within a collaboration between Consob and Sapienza University. We focus on Information Extraction from documents describing financial instruments. We discuss how we automate this task, via both rule-based and machine learning-based methods and provide our first results.
Unmasking the Lottery Ticket Hypothesis: What's Encoded in a Winning Ticket's Mask?
Oct 06, 2022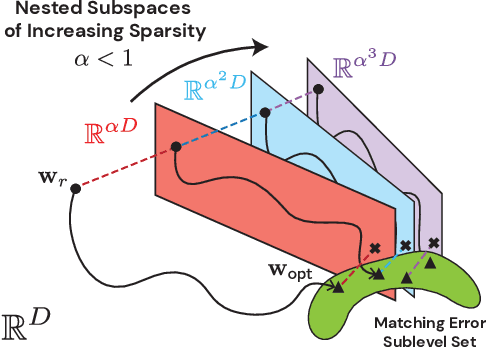
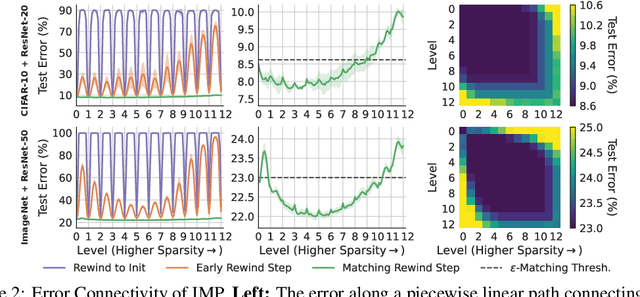
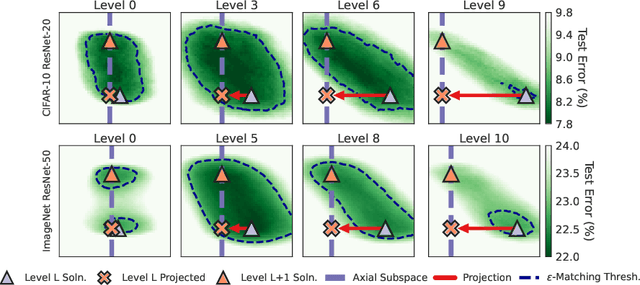
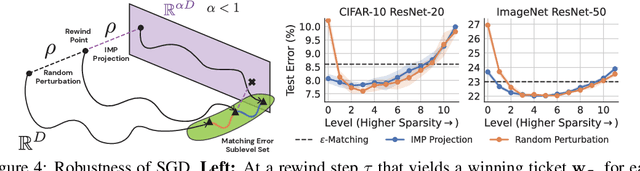
Modern deep learning involves training costly, highly overparameterized networks, thus motivating the search for sparser networks that can still be trained to the same accuracy as the full network (i.e. matching). Iterative magnitude pruning (IMP) is a state of the art algorithm that can find such highly sparse matching subnetworks, known as winning tickets. IMP operates by iterative cycles of training, masking smallest magnitude weights, rewinding back to an early training point, and repeating. Despite its simplicity, the underlying principles for when and how IMP finds winning tickets remain elusive. In particular, what useful information does an IMP mask found at the end of training convey to a rewound network near the beginning of training? How does SGD allow the network to extract this information? And why is iterative pruning needed? We develop answers in terms of the geometry of the error landscape. First, we find that$\unicode{x2014}$at higher sparsities$\unicode{x2014}$pairs of pruned networks at successive pruning iterations are connected by a linear path with zero error barrier if and only if they are matching. This indicates that masks found at the end of training convey the identity of an axial subspace that intersects a desired linearly connected mode of a matching sublevel set. Second, we show SGD can exploit this information due to a strong form of robustness: it can return to this mode despite strong perturbations early in training. Third, we show how the flatness of the error landscape at the end of training determines a limit on the fraction of weights that can be pruned at each iteration of IMP. Finally, we show that the role of retraining in IMP is to find a network with new small weights to prune. Overall, these results make progress toward demystifying the existence of winning tickets by revealing the fundamental role of error landscape geometry.
Autoregressive Entity Generation for End-to-End Task-Oriented Dialog
Sep 19, 2022
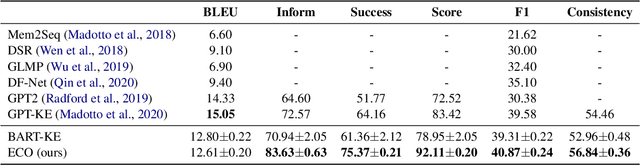
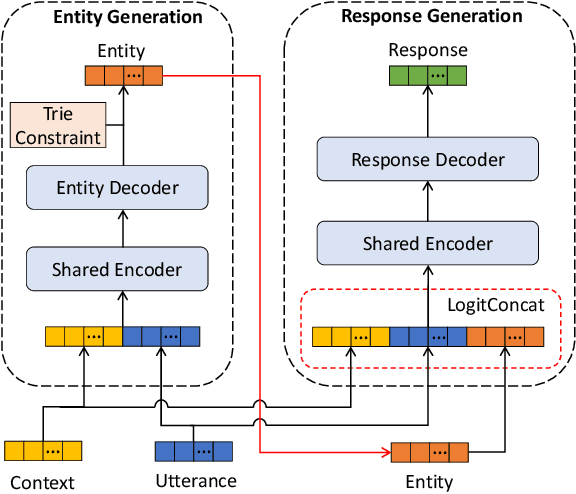
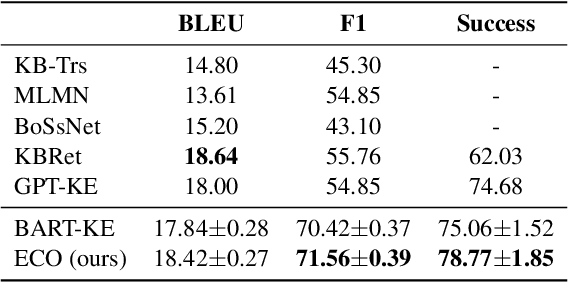
Task-oriented dialog (TOD) systems often require interaction with an external knowledge base to retrieve necessary entity (e.g., restaurant) information to support the response generation. Most current end-to-end TOD systems either retrieve the KB information explicitly or embed it into model parameters for implicit access.~While the former approach demands scanning the KB at each turn of response generation, which is inefficient when the KB scales up, the latter approach shows higher flexibility and efficiency. In either approach, the systems may generate a response with conflicting entity information. To address this issue, we propose to generate the entity autoregressively first and leverage it to guide the response generation in an end-to-end system. To ensure entity consistency, we impose a trie constraint on entity generation. We also introduce a logit concatenation strategy to facilitate gradient backpropagation for end-to-end training. Experiments on MultiWOZ 2.1 single and CAMREST show that our system can generate more high-quality and entity-consistent responses.
MGTR: End-to-End Mutual Gaze Detection with Transformer
Oct 06, 2022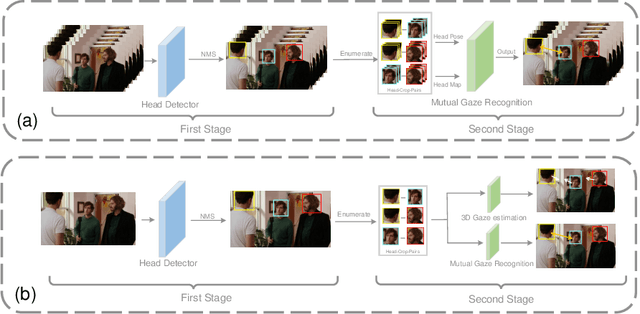
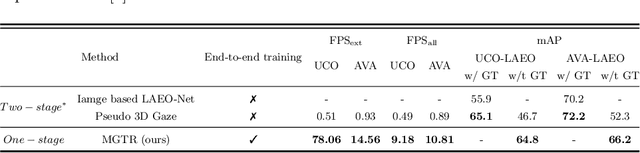
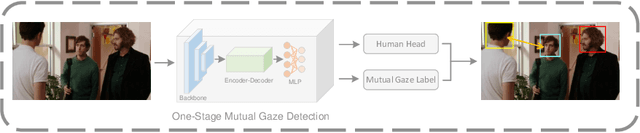
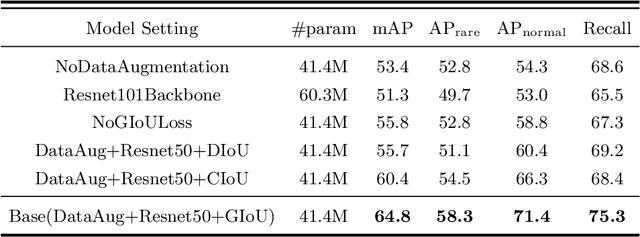
People's looking at each other or mutual gaze is ubiquitous in our daily interactions, and detecting mutual gaze is of great significance for understanding human social scenes. Current mutual gaze detection methods focus on two-stage methods, whose inference speed is limited by the two-stage pipeline and the performance in the second stage is affected by the first one. In this paper, we propose a novel one-stage mutual gaze detection framework called Mutual Gaze TRansformer or MGTR to perform mutual gaze detection in an end-to-end manner. By designing mutual gaze instance triples, MGTR can detect each human head bounding box and simultaneously infer mutual gaze relationship based on global image information, which streamlines the whole process with simplicity. Experimental results on two mutual gaze datasets show that our method is able to accelerate mutual gaze detection process without losing performance. Ablation study shows that different components of MGTR can capture different levels of semantic information in images. Code is available at https://github.com/Gmbition/MGTR
Generalized Bandit Regret Minimizer Framework in Imperfect Information Extensive-Form Game
Mar 28, 2022
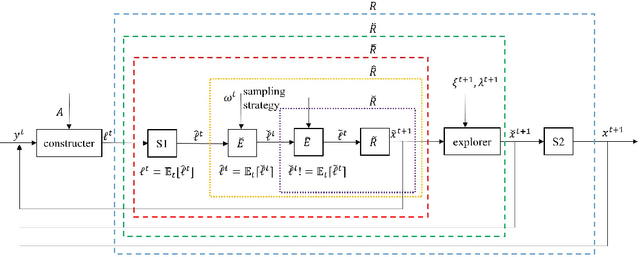
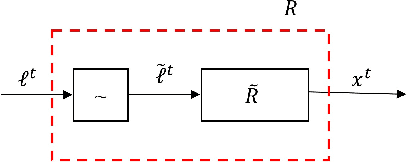
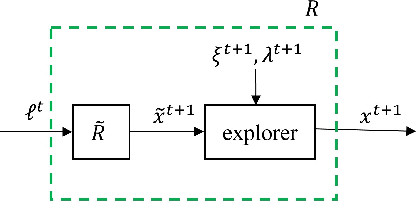
Regret minimization methods are a powerful tool for learning approximate Nash equilibrium (NE) in two-player zero-sum imperfect information extensive-form games (IIEGs). We consider the problem in the interactive bandit-feedback setting where we don't know the dynamics of the IIEG. In general, only the interactive trajectory and the reached terminal node value $v(z^t)$ are revealed. To learn NE, the regret minimizer is required to estimate the full-feedback loss gradient $\ell^t$ by $v(z^t)$ and minimize the regret. In this paper, we propose a generalized framework for this learning setting. It presents a theoretical framework for the design and the modular analysis of the bandit regret minimization methods. We demonstrate that the most recent bandit regret minimization methods can be analyzed as a particular case of our framework. Following this framework, we describe a novel method SIX-OMD to learn approximate NE. It is model-free and extremely improves the best existing convergence rate from the order of $O(\sqrt{X B/T}+\sqrt{Y C/T})$ to $O(\sqrt{ M_{\mathcal{X}}/T} +\sqrt{ M_{\mathcal{Y}}/T})$. Moreover, SIX-OMD is computationally efficient as it needs to perform the current strategy and average strategy updates only along the sampled trajectory.
Analysis and prediction of heart stroke from ejection fraction and serum creatinine using LSTM deep learning approach
Sep 28, 2022
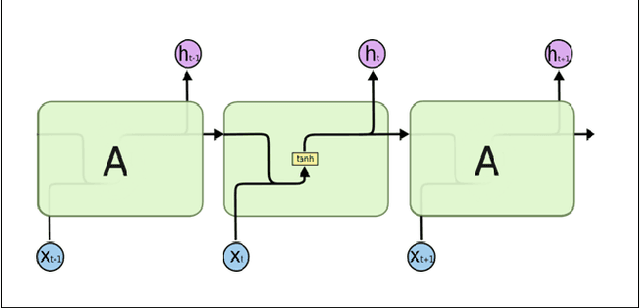
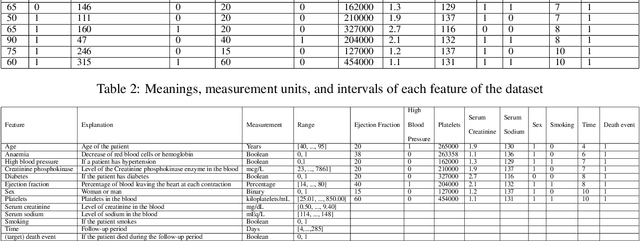
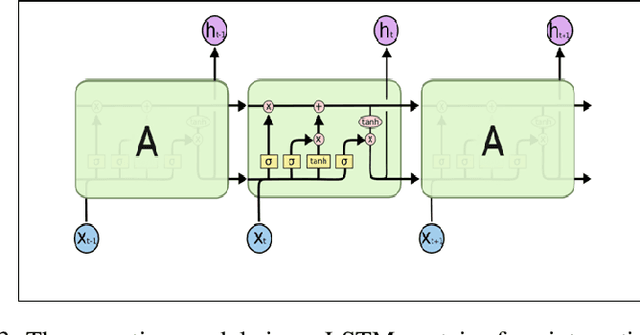
The combination of big data and deep learning is a world-shattering technology that can greatly impact any objective if used properly. With the availability of a large volume of health care datasets and progressions in deep learning techniques, systems are now well equipped to predict the future trend of any health problems. From the literature survey, we found the SVM was used to predict the heart failure rate without relating objective factors. Utilizing the intensity of important historical information in electronic health records (EHR), we have built a smart and predictive model utilizing long short-term memory (LSTM) and predict the future trend of heart failure based on that health record. Hence the fundamental commitment of this work is to predict the failure of the heart using an LSTM based on the patient's electronic medicinal information. We have analyzed a dataset containing the medical records of 299 heart failure patients collected at the Faisalabad Institute of Cardiology and the Allied Hospital in Faisalabad (Punjab, Pakistan). The patients consisted of 105 women and 194 men and their ages ranged from 40 and 95 years old. The dataset contains 13 features, which report clinical, body, and lifestyle information responsible for heart failure. We have found an increasing trend in our analysis which will contribute to advancing the knowledge in the field of heart stroke prediction.
WaveNets: Wavelet Channel Attention Networks
Nov 04, 2022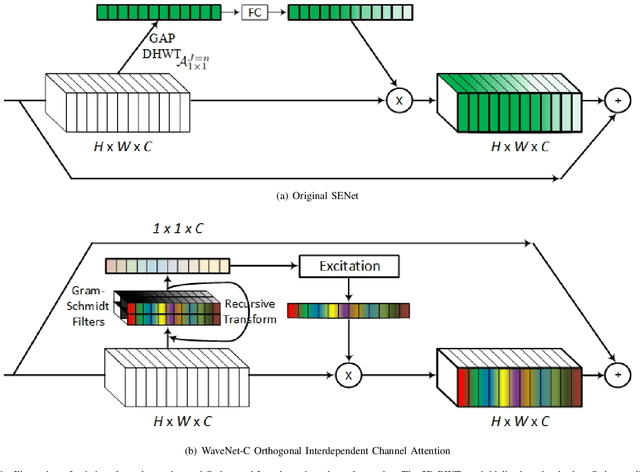
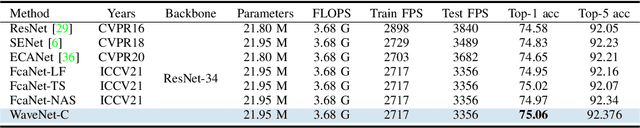
Channel Attention reigns supreme as an effective technique in the field of computer vision. However, the proposed channel attention by SENet suffers from information loss in feature learning caused by the use of Global Average Pooling (GAP) to represent channels as scalars. Thus, designing effective channel attention mechanisms requires finding a solution to enhance features preservation in modeling channel inter-dependencies. In this work, we utilize Wavelet transform compression as a solution to the channel representation problem. We first test wavelet transform as an Auto-Encoder model equipped with conventional channel attention module. Next, we test wavelet transform as a standalone channel compression method. We prove that global average pooling is equivalent to the recursive approximate Haar wavelet transform. With this proof, we generalize channel attention using Wavelet compression and name it WaveNet. Implementation of our method can be embedded within existing channel attention methods with a couple of lines of code. We test our proposed method using ImageNet dataset for image classification task. Our method outperforms the baseline SENet, and achieves the state-of-the-art results. Our code implementation is publicly available at https://github.com/hady1011/WaveNet-C.
Multi-Fidelity Cost-Aware Bayesian Optimization
Nov 04, 2022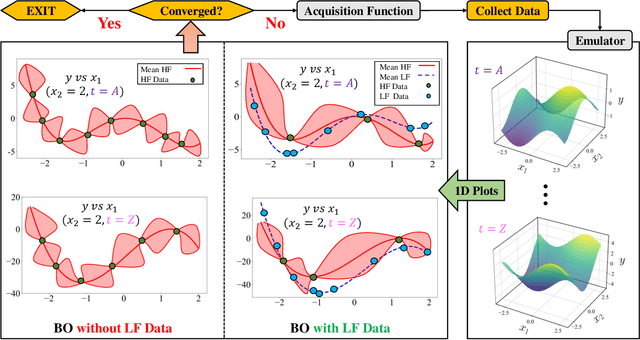
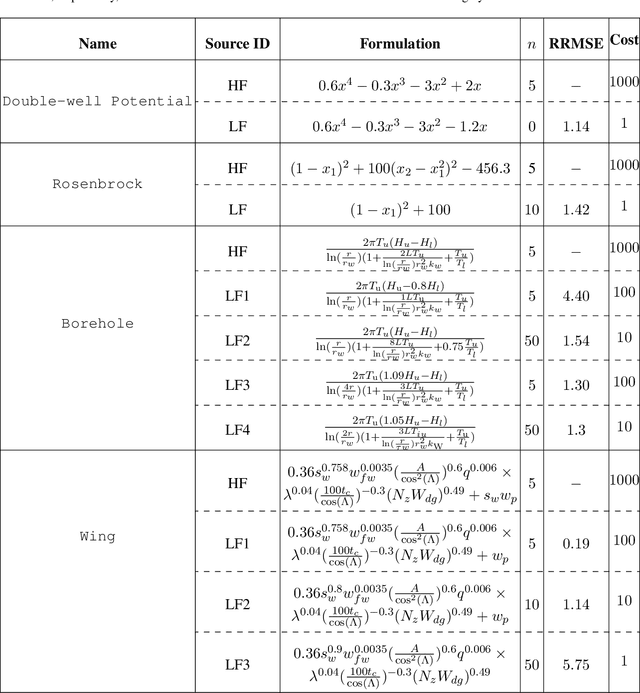
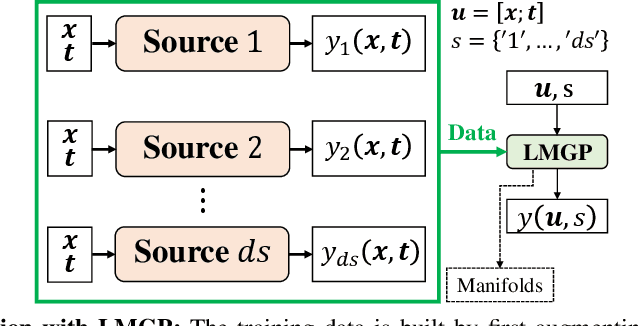
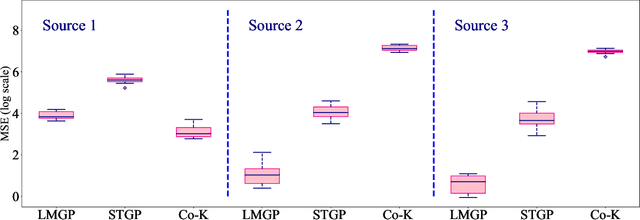
Bayesian optimization (BO) is increasingly employed in critical applications such as materials design and drug discovery. An increasingly popular strategy in BO is to forgo the sole reliance on high-fidelity data and instead use an ensemble of information sources which provide inexpensive low-fidelity data. The overall premise of this strategy is to reduce the overall sampling costs by querying inexpensive low-fidelity sources whose data are correlated with high-fidelity samples. Here, we propose a multi-fidelity cost-aware BO framework that dramatically outperforms the state-of-the-art technologies in terms of efficiency, consistency, and robustness. We demonstrate the advantages of our framework on analytic and engineering problems and argue that these benefits stem from our two main contributions: (1) we develop a novel acquisition function for multi-fidelity cost-aware BO that safeguards the convergence against the biases of low-fidelity data, and (2) we tailor a newly developed emulator for multi-fidelity BO which enables us to not only simultaneously learn from an ensemble of multi-fidelity datasets, but also identify the severely biased low-fidelity sources that should be excluded from BO.