 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
Nov 05, 2022
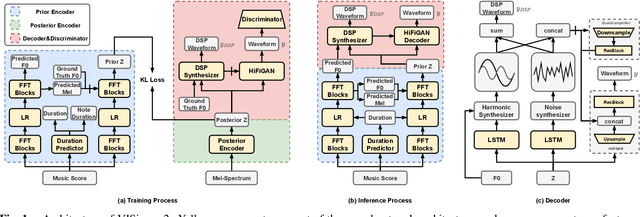
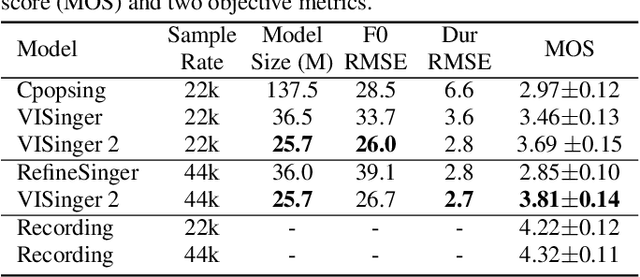
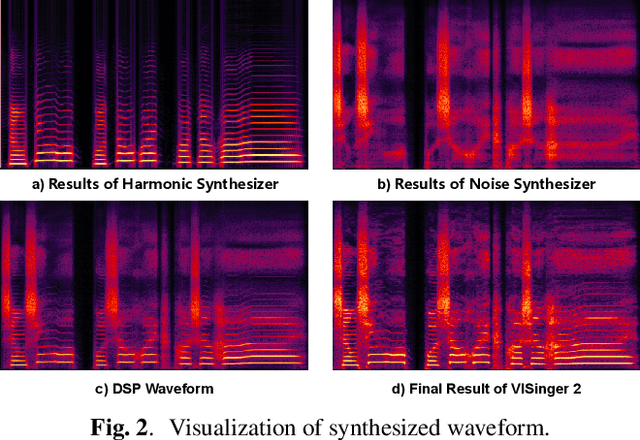
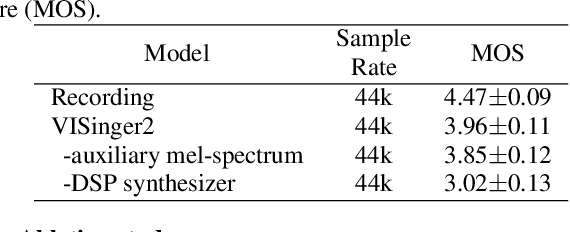
End-to-end singing voice synthesis (SVS) model VISinger can achieve better performance than the typical two-stage model with fewer parameters. However, VISinger has several problems: text-to-phase problem, the end-to-end model learns the meaningless mapping of text-to-phase; glitches problem, the harmonic components corresponding to the periodic signal of the voiced segment occurs a sudden change with audible artefacts; low sampling rate, the sampling rate of 24KHz does not meet the application needs of high-fidelity generation with the full-band rate (44.1KHz or higher). In this paper, we propose VISinger 2 to address these issues by integrating the digital signal processing (DSP) methods with VISinger. Specifically, inspired by recent advances in differentiable digital signal processing (DDSP), we incorporate a DSP synthesizer into the decoder to solve the above issues. The DSP synthesizer consists of a harmonic synthesizer and a noise synthesizer to generate periodic and aperiodic signals, respectively, from the latent representation z in VISinger. It supervises the posterior encoder to extract the latent representation without phase information and avoid the prior encoder modelling text-to-phase mapping. To avoid glitch artefacts, the HiFi-GAN is modified to accept the waveforms generated by the DSP synthesizer as a condition to produce the singing voice. Moreover, with the improved waveform decoder, VISinger 2 manages to generate 44.1kHz singing audio with richer expression and better quality. Experiments on OpenCpop corpus show that VISinger 2 outperforms VISinger, CpopSing and RefineSinger in both subjective and objective metrics.
Useful Confidence Measures: Beyond the Max Score
Oct 25, 2022


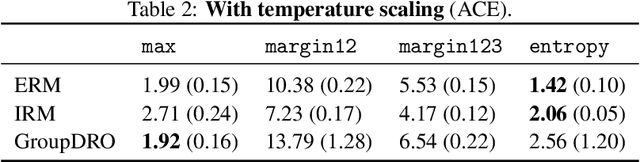
An important component in deploying machine learning (ML) in safety-critic applications is having a reliable measure of confidence in the ML model's predictions. For a classifier $f$ producing a probability vector $f(x)$ over the candidate classes, the confidence is typically taken to be $\max_i f(x)_i$. This approach is potentially limited, as it disregards the rest of the probability vector. In this work, we derive several confidence measures that depend on information beyond the maximum score, such as margin-based and entropy-based measures, and empirically evaluate their usefulness, focusing on NLP tasks with distribution shifts and Transformer-based models. We show that when models are evaluated on the out-of-distribution data ``out of the box'', using only the maximum score to inform the confidence measure is highly suboptimal. In the post-processing regime (where the scores of $f$ can be improved using additional in-distribution held-out data), this remains true, albeit less significant. Overall, our results suggest that entropy-based confidence is a surprisingly useful measure.
Topical Segmentation of Spoken Narratives: A Test Case on Holocaust Survivor Testimonies
Oct 25, 2022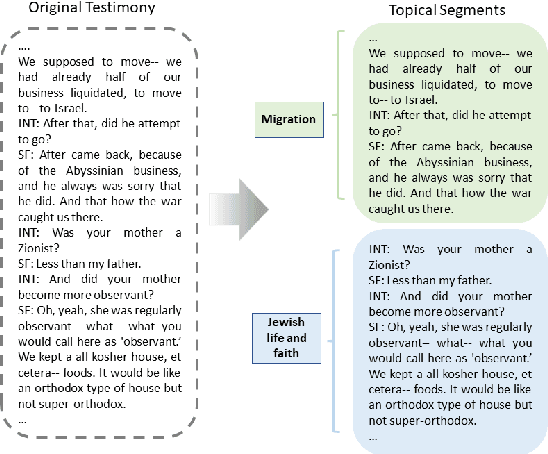
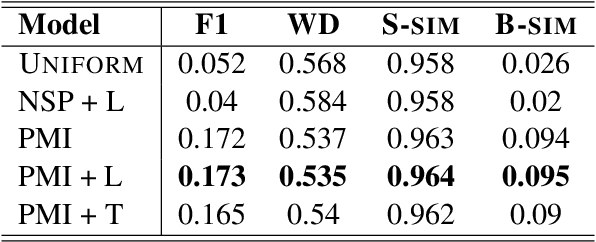
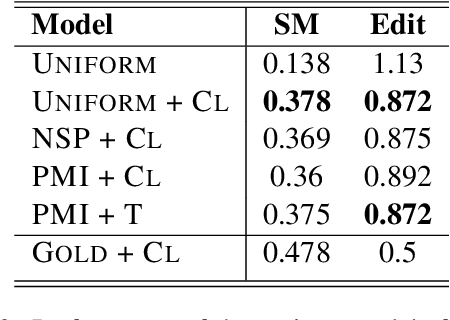
The task of topical segmentation is well studied, but previous work has mostly addressed it in the context of structured, well-defined segments, such as segmentation into paragraphs, chapters, or segmenting text that originated from multiple sources. We tackle the task of segmenting running (spoken) narratives, which poses hitherto unaddressed challenges. As a test case, we address Holocaust survivor testimonies, given in English. Other than the importance of studying these testimonies for Holocaust research, we argue that they provide an interesting test case for topical segmentation, due to their unstructured surface level, relative abundance (tens of thousands of such testimonies were collected), and the relatively confined domain that they cover. We hypothesize that boundary points between segments correspond to low mutual information between the sentences proceeding and following the boundary. Based on this hypothesis, we explore a range of algorithmic approaches to the task, building on previous work on segmentation that uses generative Bayesian modeling and state-of-the-art neural machinery. Compared to manually annotated references, we find that the developed approaches show considerable improvements over previous work.
Visually Similar Products Retrieval for Shopsy
Oct 10, 2022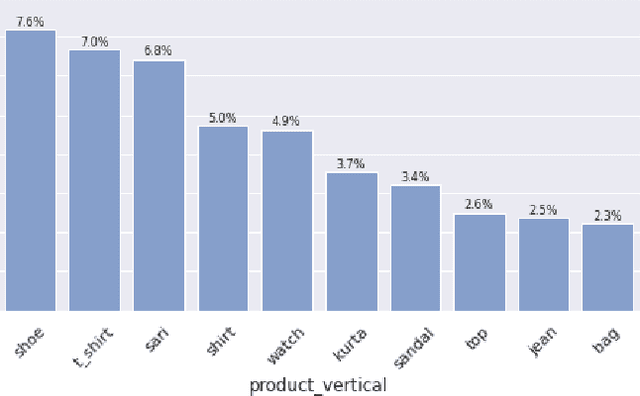
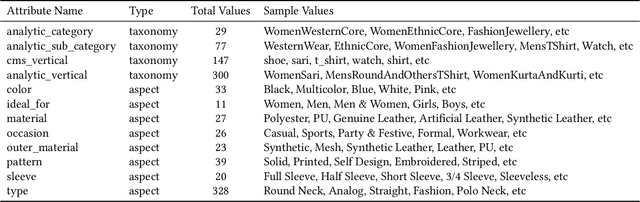
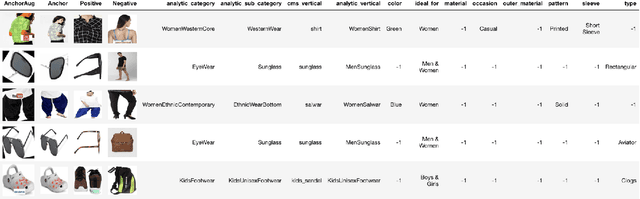
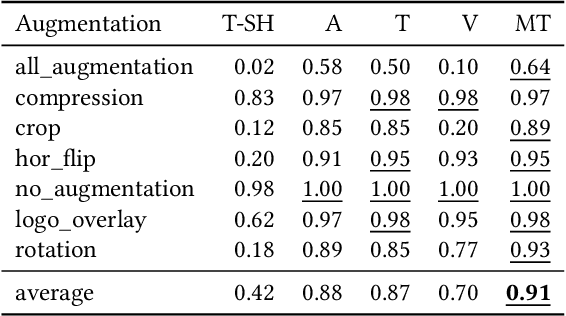
Visual search is of great assistance in reseller commerce, especially for non-tech savvy users with affinity towards regional languages. It allows resellers to accurately locate the products that they seek, unlike textual search which recommends products from head brands. Product attributes available in e-commerce have a great potential for building better visual search systems as they capture fine grained relations between data points. In this work, we design a visual search system for reseller commerce using a multi-task learning approach. We also highlight and address the challenges like image compression, cropping, scribbling on the image, etc, faced in reseller commerce. Our model consists of three different tasks: attribute classification, triplet ranking and variational autoencoder (VAE). Masking technique is used for designing the attribute classification. Next, we introduce an offline triplet mining technique which utilizes information from multiple attributes to capture relative order within the data. This technique displays a better performance compared to the traditional triplet mining baseline, which uses single label/attribute information. We also compare and report incremental gain achieved by our unified multi-task model over each individual task separately. The effectiveness of our method is demonstrated using the in-house dataset of product images from the Lifestyle business-unit of Flipkart, India's largest e-commerce company. To efficiently retrieve the images in production, we use the Approximate Nearest Neighbor (ANN) index. Finally, we highlight our production environment constraints and present the design choices and experiments conducted to select a suitable ANN index.
On Designing Day Ahead and Same Day Ridership Level Prediction Models for City-Scale Transit Networks Using Noisy APC Data
Oct 10, 2022
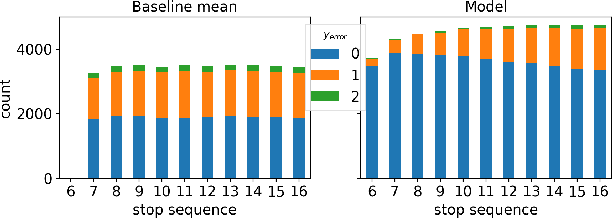
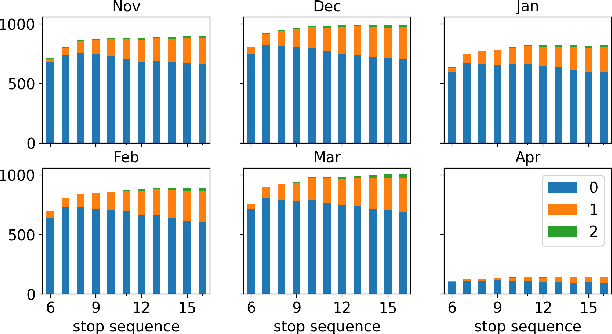
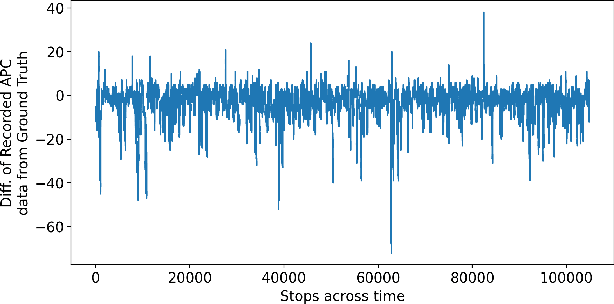
The ability to accurately predict public transit ridership demand benefits passengers and transit agencies. Agencies will be able to reallocate buses to handle under or over-utilized bus routes, improving resource utilization, and passengers will be able to adjust and plan their schedules to avoid overcrowded buses and maintain a certain level of comfort. However, accurately predicting occupancy is a non-trivial task. Various reasons such as heterogeneity, evolving ridership patterns, exogenous events like weather, and other stochastic variables, make the task much more challenging. With the progress of big data, transit authorities now have access to real-time passenger occupancy information for their vehicles. The amount of data generated is staggering. While there is no shortage in data, it must still be cleaned, processed, augmented, and merged before any useful information can be generated. In this paper, we propose the use and fusion of data from multiple sources, cleaned, processed, and merged together, for use in training machine learning models to predict transit ridership. We use data that spans a 2-year period (2020-2022) incorporating transit, weather, traffic, and calendar data. The resulting data, which equates to 17 million observations, is used to train separate models for the trip and stop level prediction. We evaluate our approach on real-world transit data provided by the public transit agency of Nashville, TN. We demonstrate that the trip level model based on Xgboost and the stop level model based on LSTM outperform the baseline statistical model across the entire transit service day.
Wireless Information and Power Transfer: A Bottom-Up Cross-Layer Design Framework
Jan 28, 2022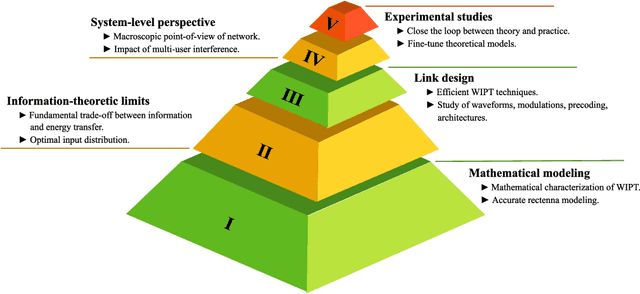
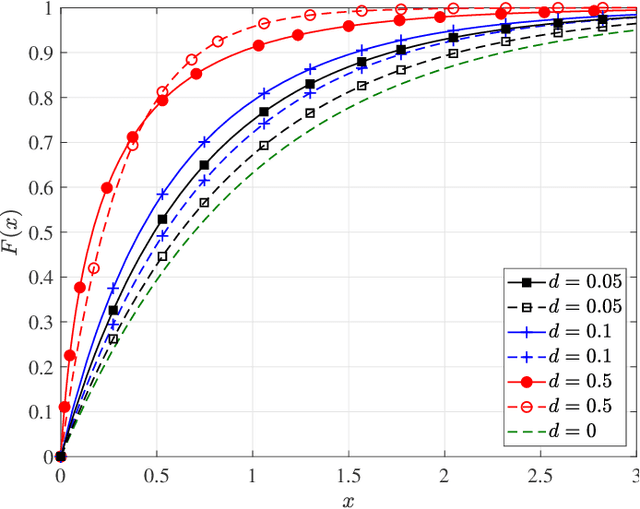
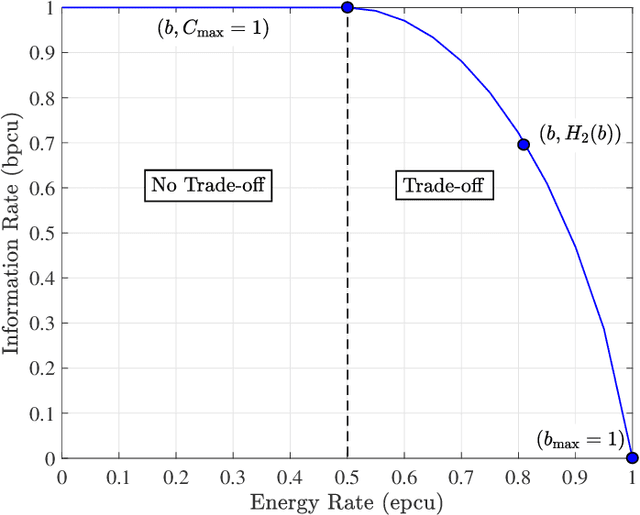
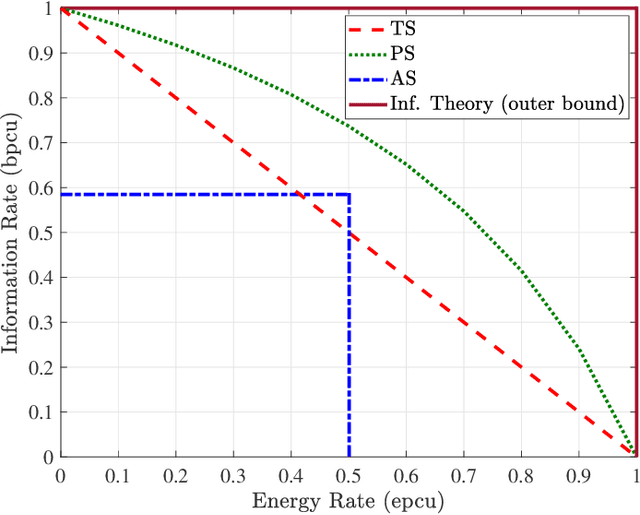
The efficiency of wireless information and power transfer (WIPT) systems requires an essential reevaluation and rethinking of the entire transceiver chain, which is characterized by a bottom-up cross-layer design approach. In this paper, we introduce and describe the key design layers: i) "Mathematical modeling", associated with the investigation of mathematical models for the wireless power transfer process, ii) "Information-theoretic limits", which refers to the fundamental limits of the WIPT channel, iii) "Link design", corresponding to signal processing techniques that make WIPT feasible, iv) "System-level perspective", which studies the developed WIPT techniques from a macroscopic system-level point-of-view, and v) "Experimental studies", that refers to real-world implementation of WIPT systems. These layers are well-connected and their interplay is imperative for the effective design of WIPT systems. Specific case studies are discussed, which demonstrates the interdisciplinary nature of the aforementioned cross-layer design framework.
An Improved Time Feedforward Connections Recurrent Neural Networks
Nov 03, 2022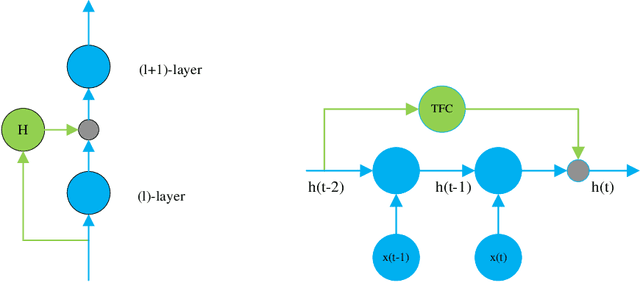
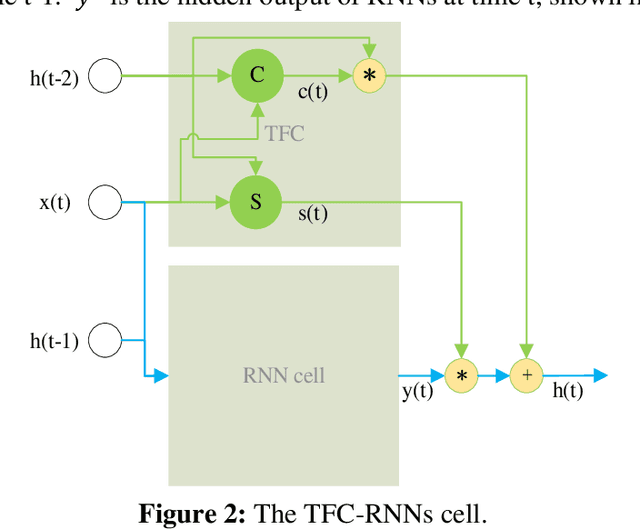
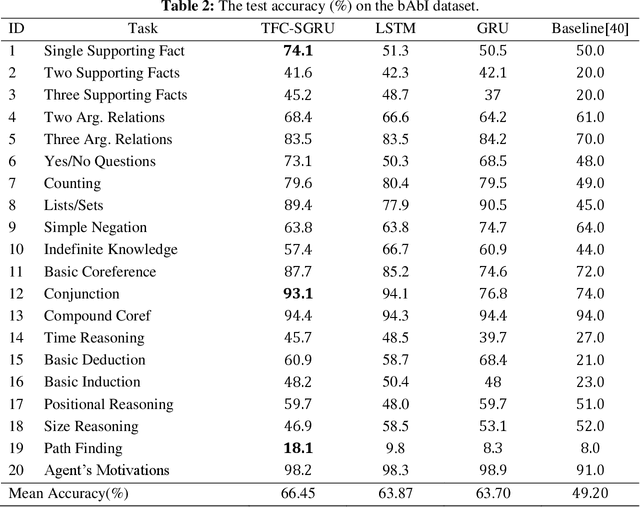
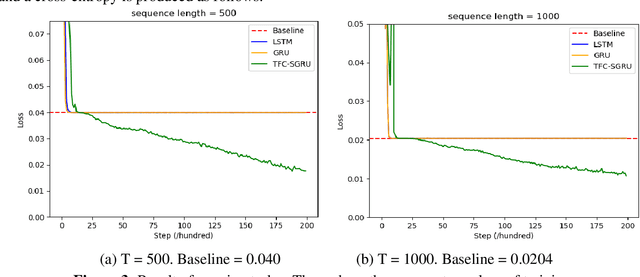
Recurrent Neural Networks (RNNs) have been widely applied to deal with temporal problems, such as flood forecasting and financial data processing. On the one hand, traditional RNNs models amplify the gradient issue due to the strict time serial dependency, making it difficult to realize a long-term memory function. On the other hand, RNNs cells are highly complex, which will significantly increase computational complexity and cause waste of computational resources during model training. In this paper, an improved Time Feedforward Connections Recurrent Neural Networks (TFC-RNNs) model was first proposed to address the gradient issue. A parallel branch was introduced for the hidden state at time t-2 to be directly transferred to time t without the nonlinear transformation at time t-1. This is effective in improving the long-term dependence of RNNs. Then, a novel cell structure named Single Gate Recurrent Unit (SGRU) was presented. This cell structure can reduce the number of parameters for RNNs cell, consequently reducing the computational complexity. Next, applying SGRU to TFC-RNNs as a new TFC-SGRU model solves the above two difficulties. Finally, the performance of our proposed TFC-SGRU was verified through several experiments in terms of long-term memory and anti-interference capabilities. Experimental results demonstrated that our proposed TFC-SGRU model can capture helpful information with time step 1500 and effectively filter out the noise. The TFC-SGRU model accuracy is better than the LSTM and GRU models regarding language processing ability.
MALUNet: A Multi-Attention and Light-weight UNet for Skin Lesion Segmentation
Nov 03, 2022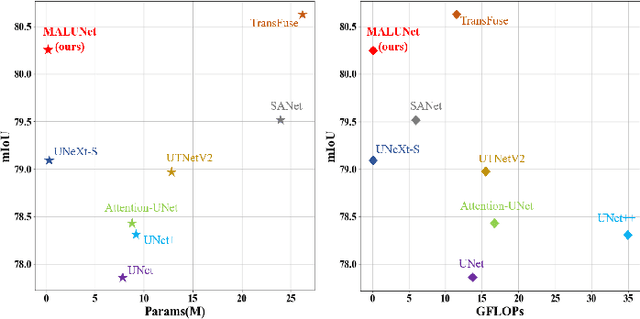
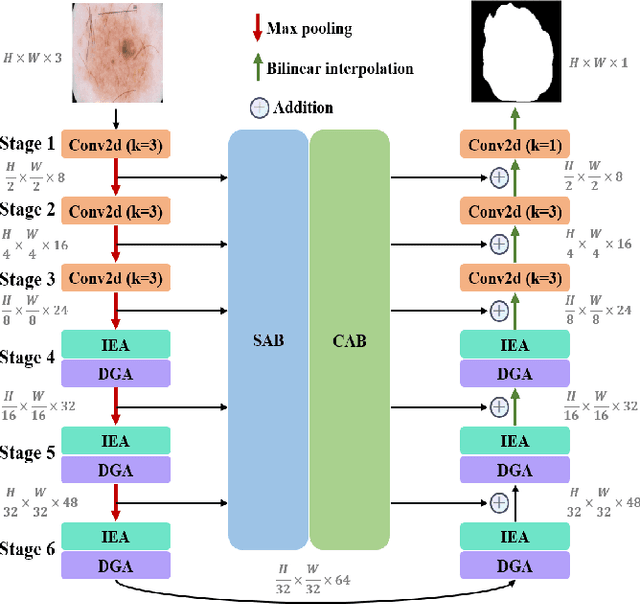
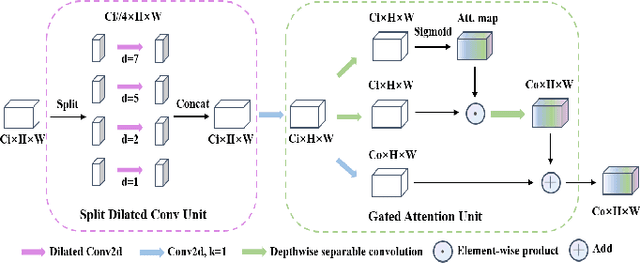
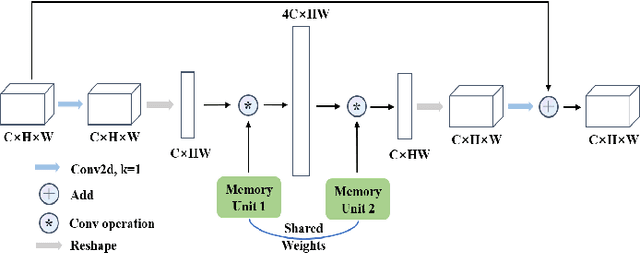
Recently, some pioneering works have preferred applying more complex modules to improve segmentation performances. However, it is not friendly for actual clinical environments due to limited computing resources. To address this challenge, we propose a light-weight model to achieve competitive performances for skin lesion segmentation at the lowest cost of parameters and computational complexity so far. Briefly, we propose four modules: (1) DGA consists of dilated convolution and gated attention mechanisms to extract global and local feature information; (2) IEA, which is based on external attention to characterize the overall datasets and enhance the connection between samples; (3) CAB is composed of 1D convolution and fully connected layers to perform a global and local fusion of multi-stage features to generate attention maps at channel axis; (4) SAB, which operates on multi-stage features by a shared 2D convolution to generate attention maps at spatial axis. We combine four modules with our U-shape architecture and obtain a light-weight medical image segmentation model dubbed as MALUNet. Compared with UNet, our model improves the mIoU and DSC metrics by 2.39% and 1.49%, respectively, with a 44x and 166x reduction in the number of parameters and computational complexity. In addition, we conduct comparison experiments on two skin lesion segmentation datasets (ISIC2017 and ISIC2018). Experimental results show that our model achieves state-of-the-art in balancing the number of parameters, computational complexity and segmentation performances. Code is available at https://github.com/JCruan519/MALUNet.
Multi-stream Fusion for Class Incremental Learning in Pill Image Classification
Oct 05, 2022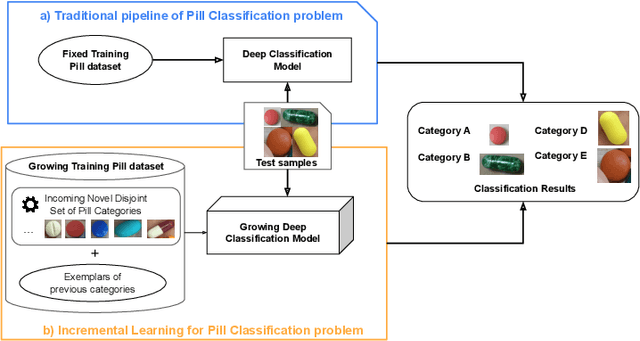
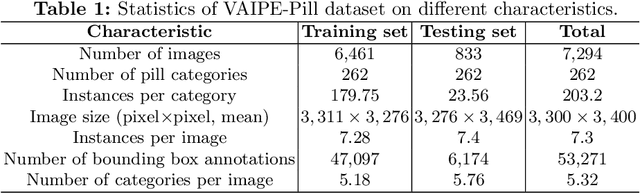

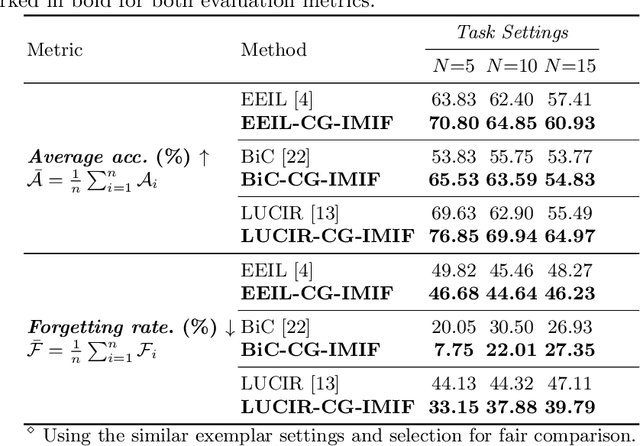
Classifying pill categories from real-world images is crucial for various smart healthcare applications. Although existing approaches in image classification might achieve a good performance on fixed pill categories, they fail to handle novel instances of pill categories that are frequently presented to the learning algorithm. To this end, a trivial solution is to train the model with novel classes. However, this may result in a phenomenon known as catastrophic forgetting, in which the system forgets what it learned in previous classes. In this paper, we address this challenge by introducing the class incremental learning (CIL) ability to traditional pill image classification systems. Specifically, we propose a novel incremental multi-stream intermediate fusion framework enabling incorporation of an additional guidance information stream that best matches the domain of the problem into various state-of-the-art CIL methods. From this framework, we consider color-specific information of pill images as a guidance stream and devise an approach, namely "Color Guidance with Multi-stream intermediate fusion"(CG-IMIF) for solving CIL pill image classification task. We conduct comprehensive experiments on real-world incremental pill image classification dataset, namely VAIPE-PCIL, and find that the CG-IMIF consistently outperforms several state-of-the-art methods by a large margin in different task settings. Our code, data, and trained model are available at https://github.com/vinuni-vishc/CG-IMIF.
A Max-relevance-min-divergence Criterion for Data Discretization with Applications on Naive Bayes
Sep 20, 2022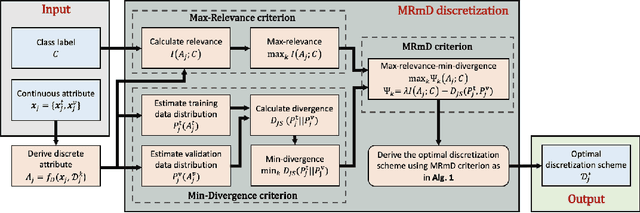
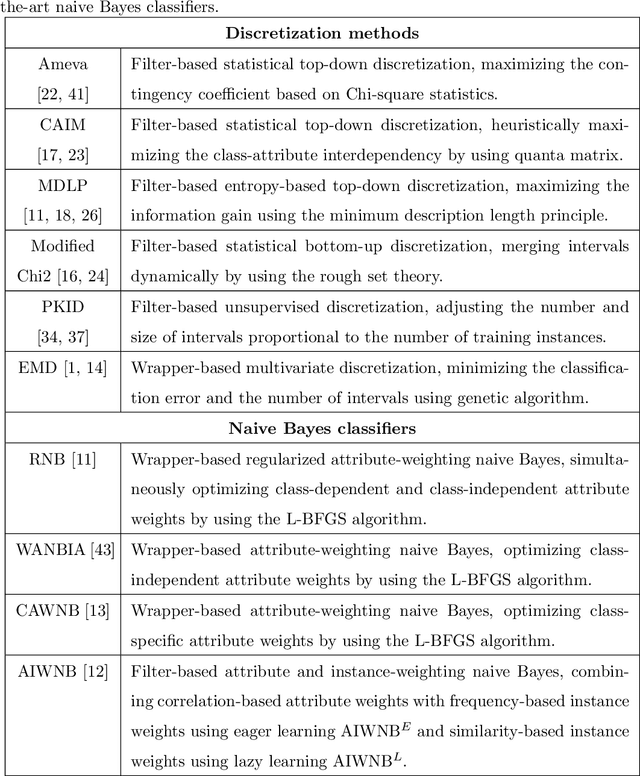
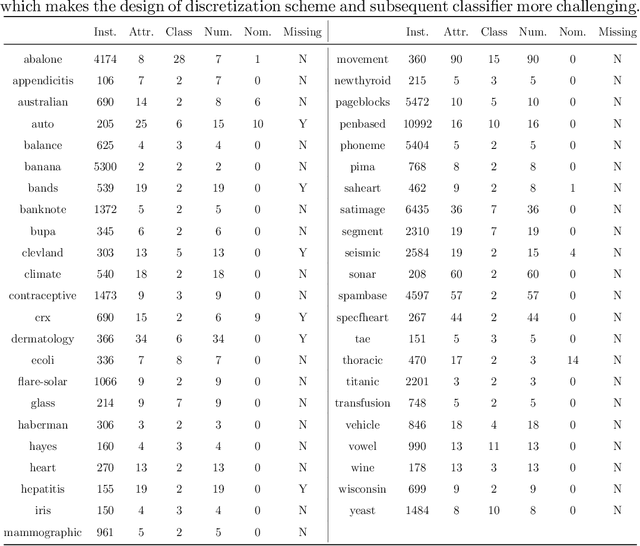
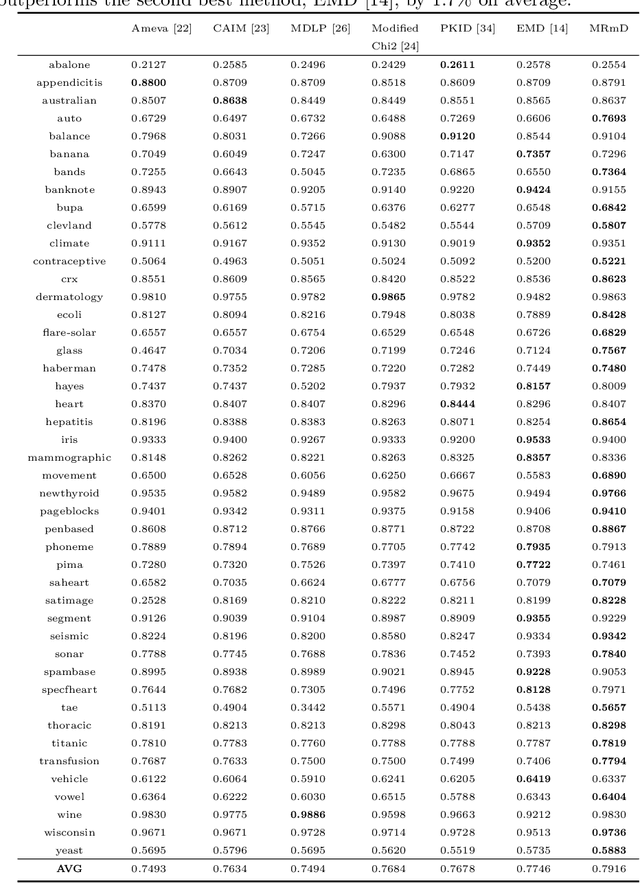
In many classification models, data is discretized to better estimate its distribution. Existing discretization methods often target at maximizing the discriminant power of discretized data, while overlooking the fact that the primary target of data discretization in classification is to improve the generalization performance. As a result, the data tend to be over-split into many small bins since the data without discretization retain the maximal discriminant information. Thus, we propose a Max-Dependency-Min-Divergence (MDmD) criterion that maximizes both the discriminant information and generalization ability of the discretized data. More specifically, the Max-Dependency criterion maximizes the statistical dependency between the discretized data and the classification variable while the Min-Divergence criterion explicitly minimizes the JS-divergence between the training data and the validation data for a given discretization scheme. The proposed MDmD criterion is technically appealing, but it is difficult to reliably estimate the high-order joint distributions of attributes and the classification variable. We hence further propose a more practical solution, Max-Relevance-Min-Divergence (MRmD) discretization scheme, where each attribute is discretized separately, by simultaneously maximizing the discriminant information and the generalization ability of the discretized data. The proposed MRmD is compared with the state-of-the-art discretization algorithms under the naive Bayes classification framework on 45 machine-learning benchmark datasets. It significantly outperforms all the compared methods on most of the datasets.