 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sensing-Assisted Eavesdropper Estimation: An ISAC Breakthrough in Physical Layer Security
Oct 15, 2022
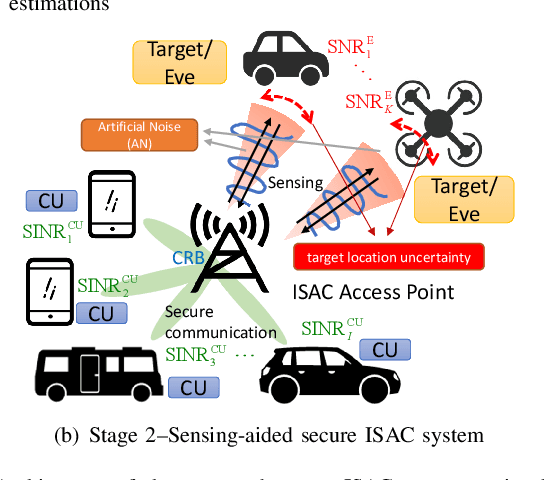
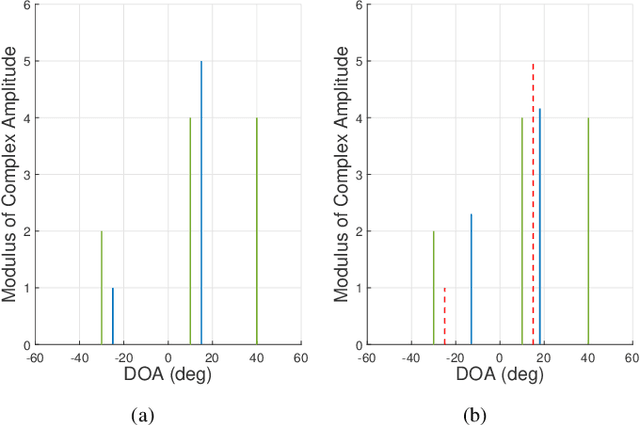
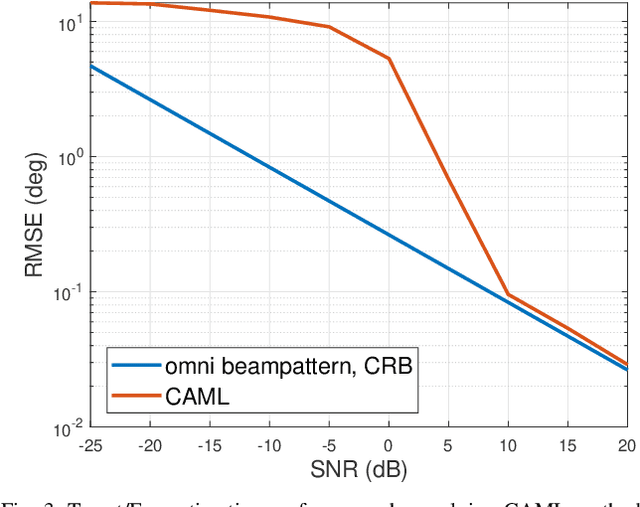
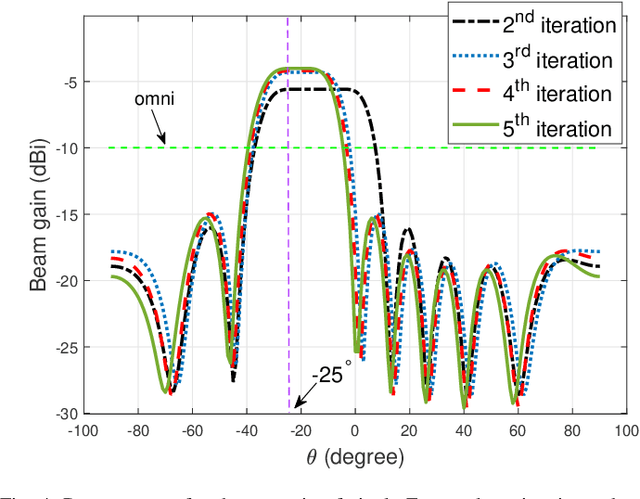
In this paper, we investigate the sensing-aided physical layer security (PLS) towards Integrated Sensing and Communication (ISAC) systems. A well-known limitation of PLS is the need to have information about potential eavesdroppers (Eves). The sensing functionality of ISAC offers an enabling role here, by estimating the directions of potential Eves to inform PLS. In our approach, the ISAC base station (BS) firstly emits an omni-directional waveform to search for potential Eves' directions by employing the combined Capon and approximate maximum likelihood (CAML) technique. Using the resulting information about potential Eves, we formulate secrecy rate expressions, that are a function of the Eves' estimation accuracy. We then formulate a weighted optimization problem to simultaneously maximize the secrecy rate and minimize the CRB with the aid of the artificial noise (AN), and minimize the CRB of targets'/Eves' estimation. By taking the possible estimation errors into account, we enforce a beampattern constraint with a wide main beam covering all possible directions of Eves. This implicates that security needs to be enforced in all these directions. By improving estimation accuracy, the sensing and security functionalities provide mutual benefits, resulting in improvement of the mutual performances with every iteration of the optimization, until convergence. Our results avail of these mutual benefits and reveal the usefulness of sensing as an enabler for practical PLS.
Augmentation-Free Graph Contrastive Learning of Invariant-Discriminative Representations
Oct 15, 2022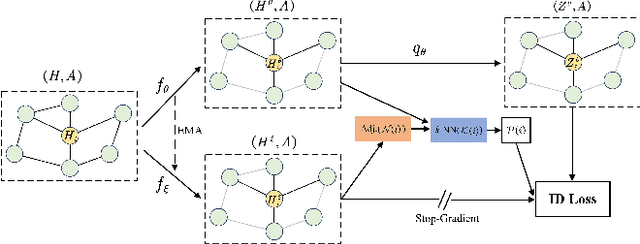
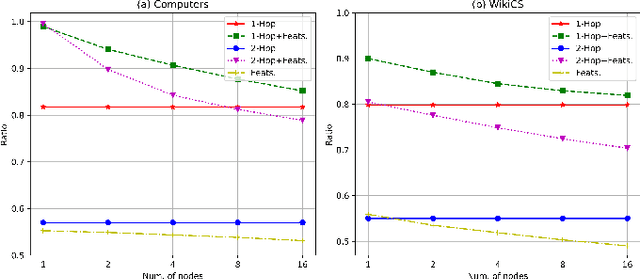
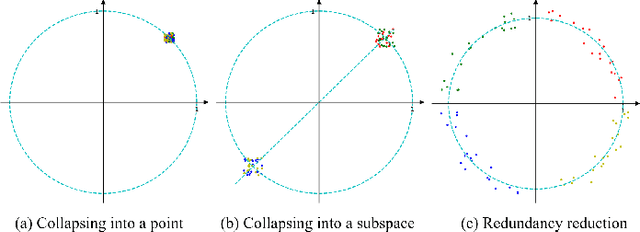

The pretasks are mainly built on mutual information estimation, which requires data augmentation to construct positive samples with similar semantics to learn invariant signals and negative samples with dissimilar semantics in order to empower representation discriminability. However, an appropriate data augmentation configuration depends heavily on lots of empirical trials such as choosing the compositions of data augmentation techniques and the corresponding hyperparameter settings. We propose an augmentation-free graph contrastive learning method, invariant-discriminative graph contrastive learning (iGCL), that does not intrinsically require negative samples. iGCL designs the invariant-discriminative loss (ID loss) to learn invariant and discriminative representations. On the one hand, ID loss learns invariant signals by directly minimizing the mean square error between the target samples and positive samples in the representation space. On the other hand, ID loss ensures that the representations are discriminative by an orthonormal constraint forcing the different dimensions of representations to be independent of each other. This prevents representations from collapsing to a point or subspace. Our theoretical analysis explains the effectiveness of ID loss from the perspectives of the redundancy reduction criterion, canonical correlation analysis, and information bottleneck principle. The experimental results demonstrate that iGCL outperforms all baselines on 5 node classification benchmark datasets. iGCL also shows superior performance for different label ratios and is capable of resisting graph attacks, which indicates that iGCL has excellent generalization and robustness.
Deconfounding Legal Judgment Prediction for European Court of Human Rights Cases Towards Better Alignment with Experts
Oct 25, 2022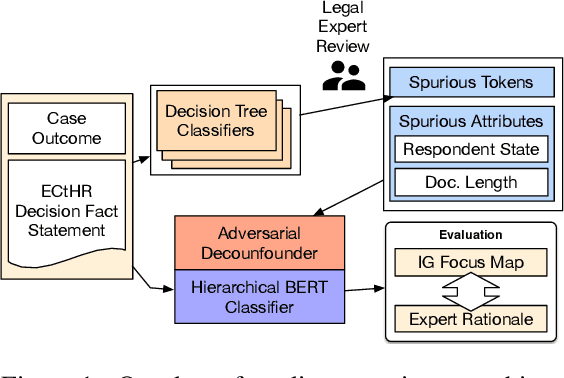
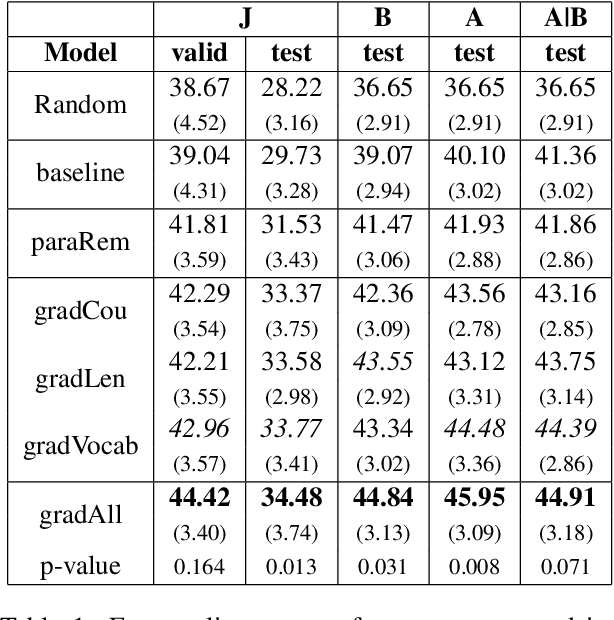
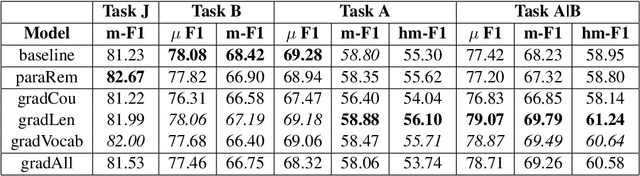
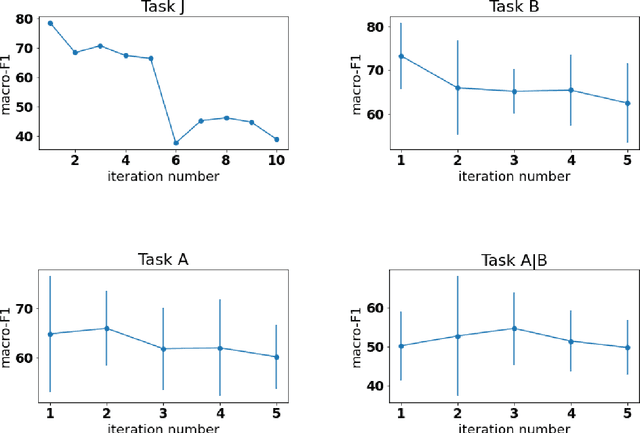
This work demonstrates that Legal Judgement Prediction systems without expert-informed adjustments can be vulnerable to shallow, distracting surface signals that arise from corpus construction, case distribution, and confounding factors. To mitigate this, we use domain expertise to strategically identify statistically predictive but legally irrelevant information. We adopt adversarial training to prevent the system from relying on it. We evaluate our deconfounded models by employing interpretability techniques and comparing to expert annotations. Quantitative experiments and qualitative analysis show that our deconfounded model consistently aligns better with expert rationales than baselines trained for prediction only. We further contribute a set of reference expert annotations to the validation and testing partitions of an existing benchmark dataset of European Court of Human Rights cases.
A Novel Block-Wise Index Modulation Scheme for High-Mobility OTFS Communications
Oct 25, 2022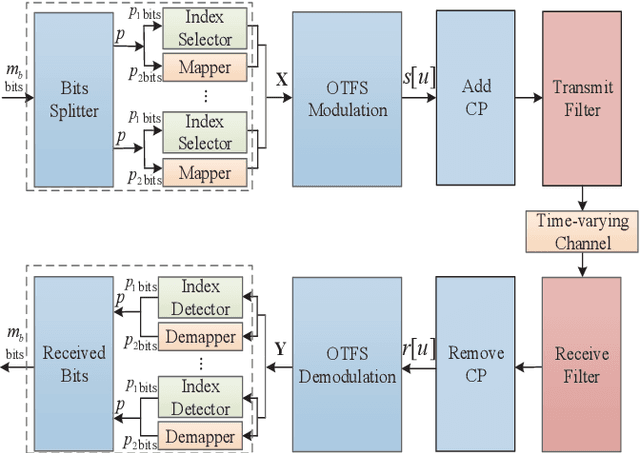
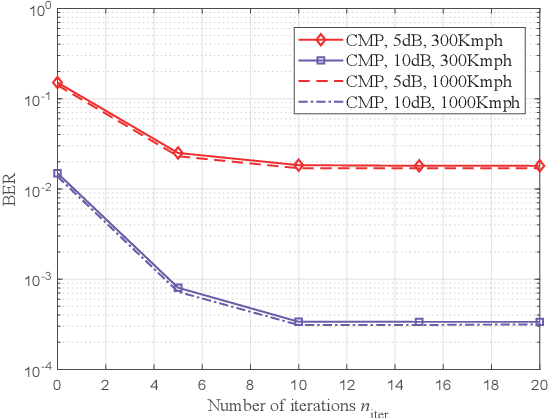
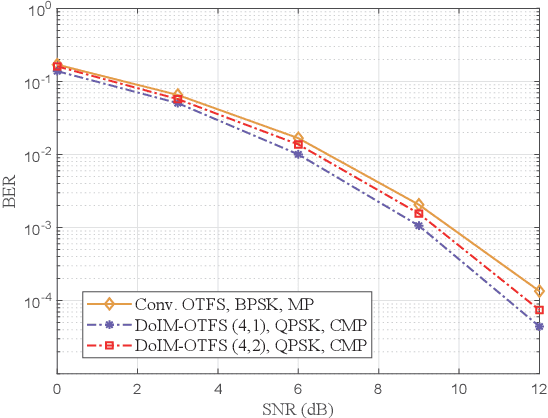
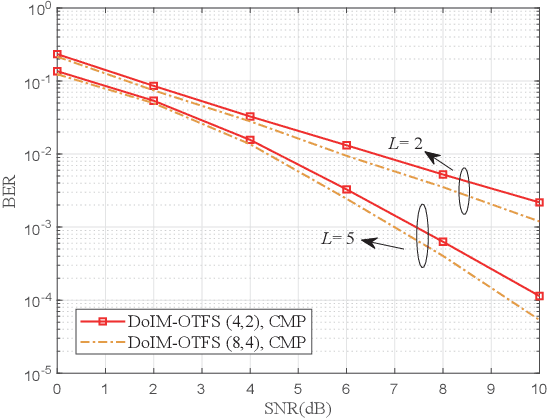
As a promising technique for high-mobility wireless communications, orthogonal time frequency space (OTFS) has been proved to enjoy excellent advantages with respect to traditional orthogonal frequency division multiplexing (OFDM). However, a challenging problem is to design efficient systems to further improve the performance. In this paper, we propose a novel block-wise index modulation (IM) scheme for OTFS systems, named Doppler-IM with OTFS (DoIM-OTFS), where a block of Doppler resource bins are activated simultaneously. For practical implementation, we develop a low complexity customized message passing (CMP) algorithm for our proposed DoIM-OTFS scheme. Simulation results demonstrate our proposed DoIM-OTFS system outperforms traditional OTFS system without IM. The proposed CMP algorithm can achieve desired performance and robustness to the imperfect channel state information (CSI).
Dynamic Survival Transformers for Causal Inference with Electronic Health Records
Oct 25, 2022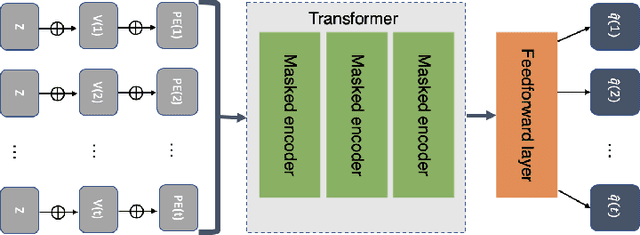
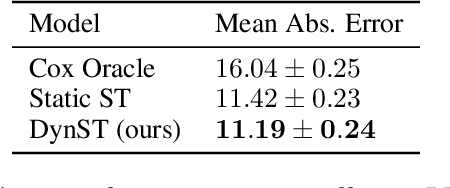


In medicine, researchers often seek to infer the effects of a given treatment on patients' outcomes. However, the standard methods for causal survival analysis make simplistic assumptions about the data-generating process and cannot capture complex interactions among patient covariates. We introduce the Dynamic Survival Transformer (DynST), a deep survival model that trains on electronic health records (EHRs). Unlike previous transformers used in survival analysis, DynST can make use of time-varying information to predict evolving survival probabilities. We derive a semi-synthetic EHR dataset from MIMIC-III to show that DynST can accurately estimate the causal effect of a treatment intervention on restricted mean survival time (RMST). We demonstrate that DynST achieves better predictive and causal estimation than two alternative models.
Multilingual Auxiliary Tasks Training: Bridging the Gap between Languages for Zero-Shot Transfer of Hate Speech Detection Models
Oct 25, 2022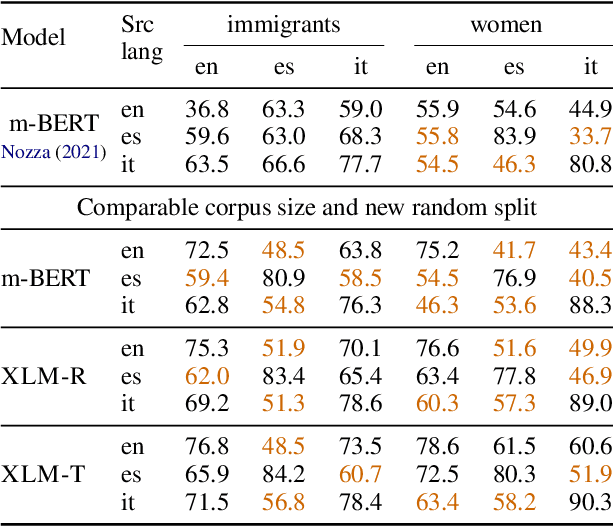
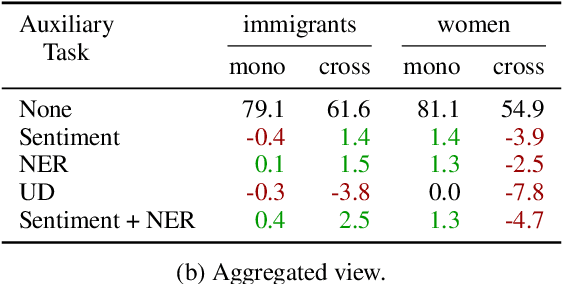
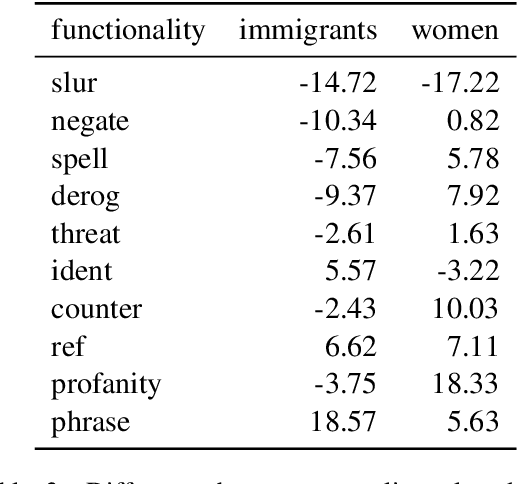
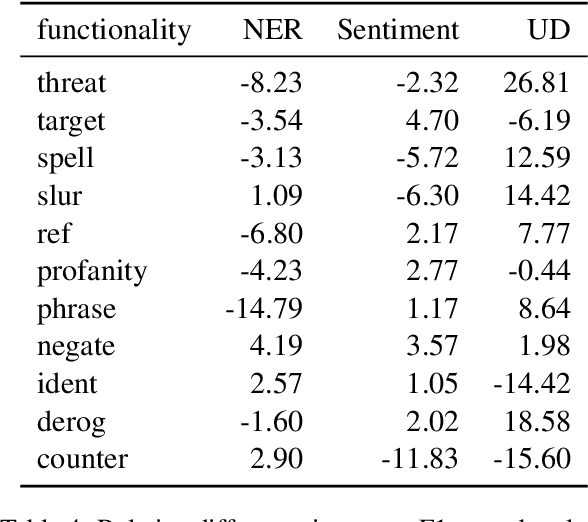
Zero-shot cross-lingual transfer learning has been shown to be highly challenging for tasks involving a lot of linguistic specificities or when a cultural gap is present between languages, such as in hate speech detection. In this paper, we highlight this limitation for hate speech detection in several domains and languages using strict experimental settings. Then, we propose to train on multilingual auxiliary tasks -- sentiment analysis, named entity recognition, and tasks relying on syntactic information -- to improve zero-shot transfer of hate speech detection models across languages. We show how hate speech detection models benefit from a cross-lingual knowledge proxy brought by auxiliary tasks fine-tuning and highlight these tasks' positive impact on bridging the hate speech linguistic and cultural gap between languages.
Computed tomography coronary angiogram images, annotations and associated data of normal and diseased arteries
Nov 03, 2022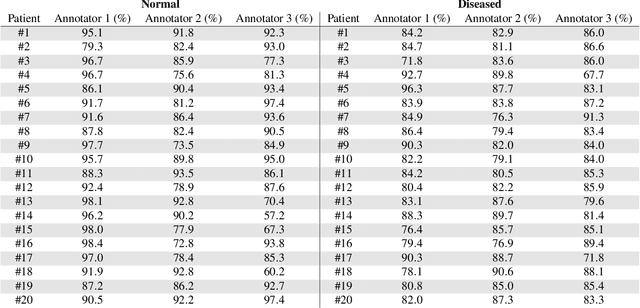
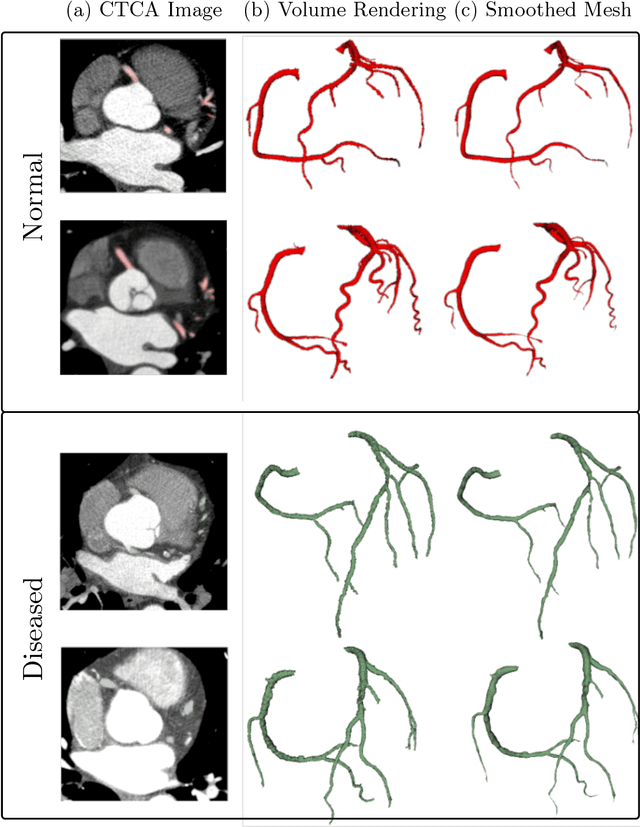
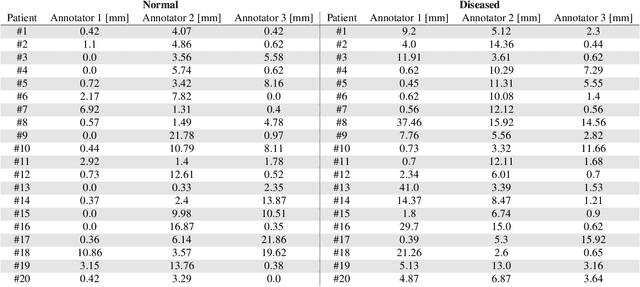
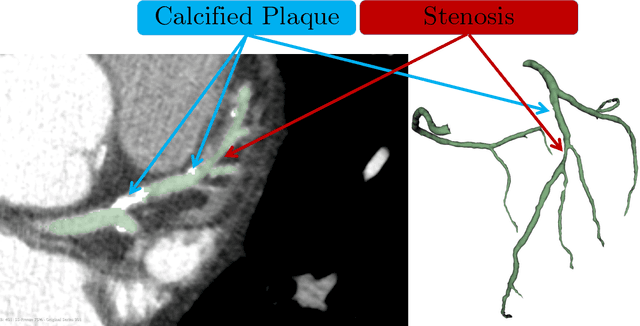
Computed Tomography Coronary Angiography (CTCA) is a non-invasive method to evaluate coronary artery anatomy and disease. CTCA is ideal for geometry reconstruction to create virtual models of coronary arteries. To our knowledge there is no public dataset that includes centrelines and segmentation of the full coronary tree. We provide anonymized CTCA images, voxel-wise annotations and associated data in the form of centrelines, calcification scores and meshes of the coronary lumen in 20 normal and 20 diseased cases. Images were obtained along with patient information with informed, written consent as part of Coronary Atlas (https://www.coronaryatlas.org/). Cases were classified as normal (zero calcium score with no signs of stenosis) or diseased (confirmed coronary artery disease). Manual voxel-wise segmentations by three experts were combined using majority voting to generate the final annotations. Provided data can be used for a variety of research purposes, such as 3D printing patient-specific models, development and validation of segmentation algorithms, education and training of medical personnel and in-silico analyses such as testing of medical devices.
Relating graph auto-encoders to linear models
Nov 03, 2022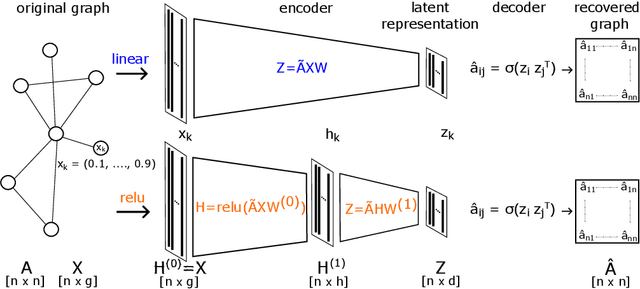
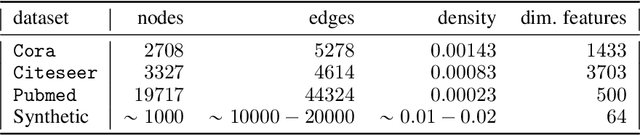
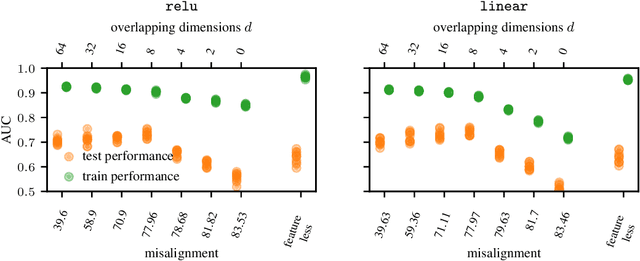
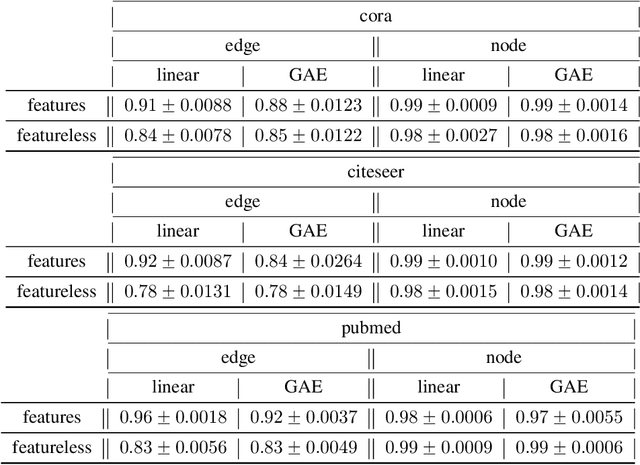
Graph auto-encoders are widely used to construct graph representations in Euclidean vector spaces. However, it has already been pointed out empirically that linear models on many tasks can outperform graph auto-encoders. In our work, we prove that the solution space induced by graph auto-encoders is a subset of the solution space of a linear map. This demonstrates that linear embedding models have at least the representational power of graph auto-encoders based on graph convolutional networks. So why are we still using nonlinear graph auto-encoders? One reason could be that actively restricting the linear solution space might introduce an inductive bias that helps improve learning and generalization. While many researchers believe that the nonlinearity of the encoder is the critical ingredient towards this end, we instead identify the node features of the graph as a more powerful inductive bias. We give theoretical insights by introducing a corresponding bias in a linear model and analyzing the change in the solution space. Our experiments show that the linear encoder can outperform the nonlinear encoder when using feature information.
Deep Explainable Learning with Graph Based Data Assessing and Rule Reasoning
Nov 10, 2022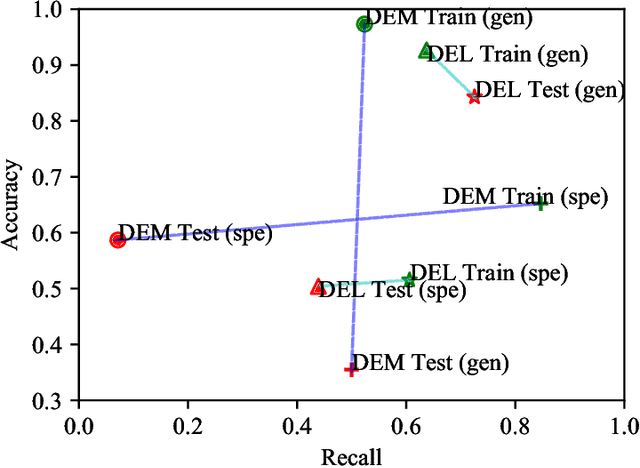
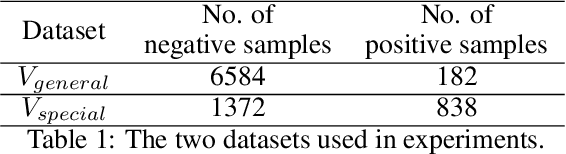
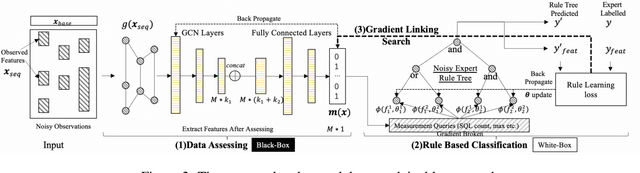
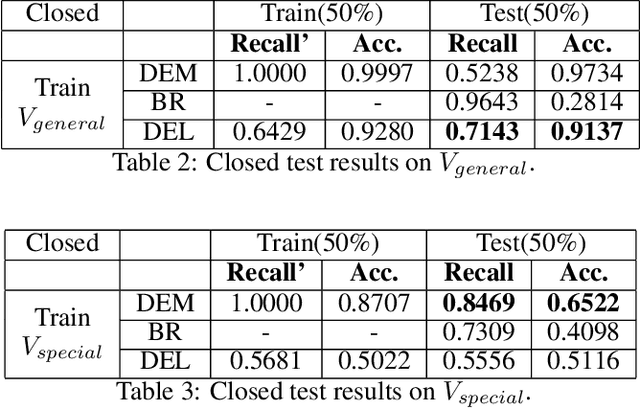
Learning an explainable classifier often results in low accuracy model or ends up with a huge rule set, while learning a deep model is usually more capable of handling noisy data at scale, but with the cost of hard to explain the result and weak at generalization. To mitigate this gap, we propose an end-to-end deep explainable learning approach that combines the advantage of deep model in noise handling and expert rule-based interpretability. Specifically, we propose to learn a deep data assessing model which models the data as a graph to represent the correlations among different observations, whose output will be used to extract key data features. The key features are then fed into a rule network constructed following predefined noisy expert rules with trainable parameters. As these models are correlated, we propose an end-to-end training framework, utilizing the rule classification loss to optimize the rule learning model and data assessing model at the same time. As the rule-based computation is none-differentiable, we propose a gradient linking search module to carry the gradient information from the rule learning model to the data assessing model. The proposed method is tested in an industry production system, showing comparable prediction accuracy, much higher generalization stability and better interpretability when compared with a decent deep ensemble baseline, and shows much better fitting power than pure rule-based approach.
Deep Unsupervised Key Frame Extraction for Efficient Video Classification
Nov 12, 2022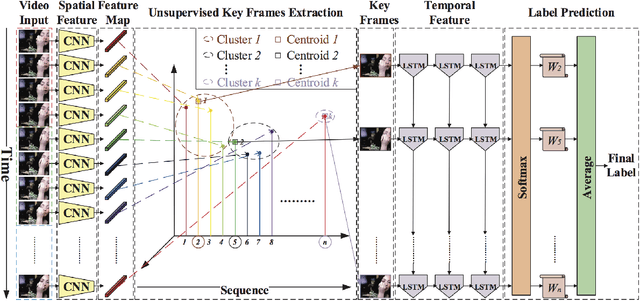
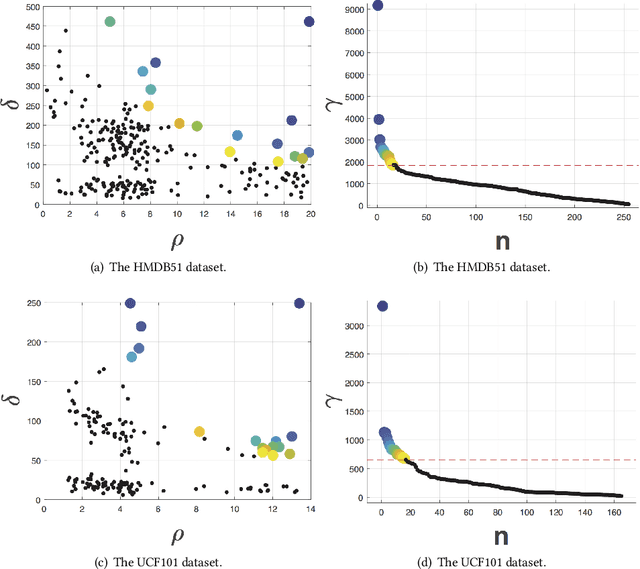
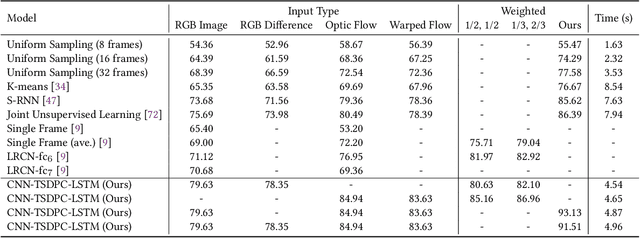
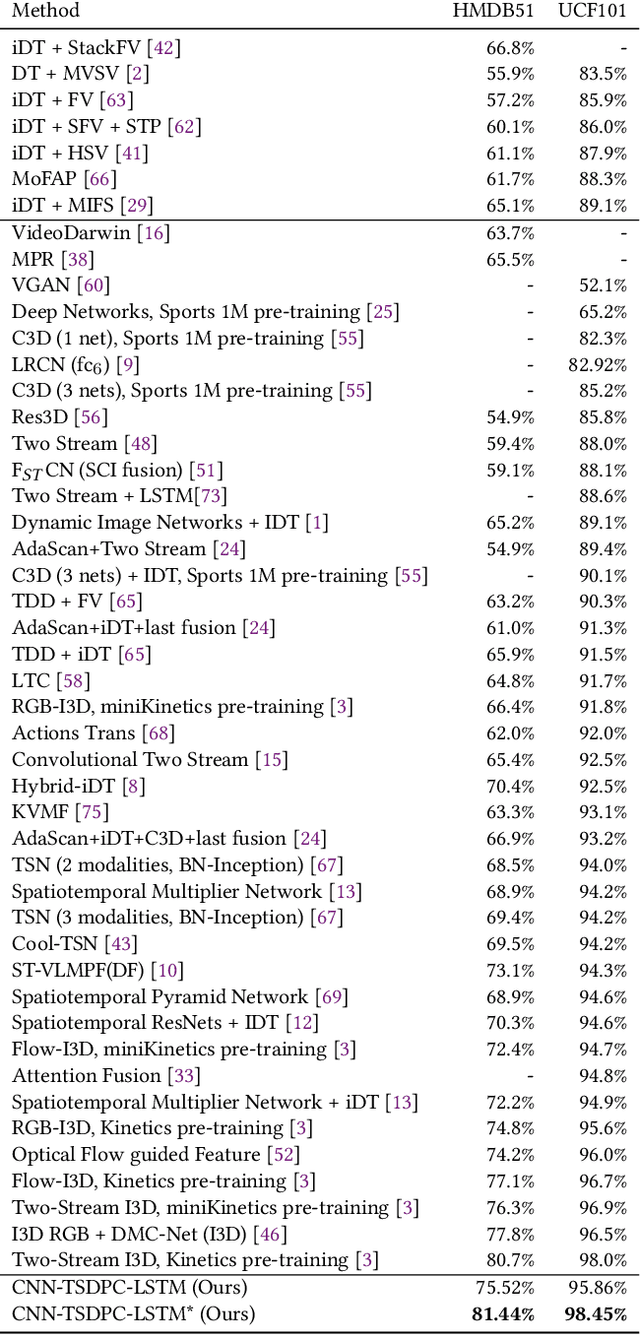
Video processing and analysis have become an urgent task since a huge amount of videos (e.g., Youtube, Hulu) are uploaded online every day. The extraction of representative key frames from videos is very important in video processing and analysis since it greatly reduces computing resources and time. Although great progress has been made recently, large-scale video classification remains an open problem, as the existing methods have not well balanced the performance and efficiency simultaneously. To tackle this problem, this work presents an unsupervised method to retrieve the key frames, which combines Convolutional Neural Network (CNN) and Temporal Segment Density Peaks Clustering (TSDPC). The proposed TSDPC is a generic and powerful framework and it has two advantages compared with previous works, one is that it can calculate the number of key frames automatically. The other is that it can preserve the temporal information of the video. Thus it improves the efficiency of video classification. Furthermore, a Long Short-Term Memory network (LSTM) is added on the top of the CNN to further elevate the performance of classification. Moreover, a weight fusion strategy of different input networks is presented to boost the performance. By optimizing both video classification and key frame extraction simultaneously, we achieve better classification performance and higher efficiency. We evaluate our method on two popular datasets (i.e., HMDB51 and UCF101) and the experimental results consistently demonstrate that our strategy achieves competitive performance and efficiency compared with the state-of-the-art approaches.