 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Anatomy-aware Framework for Automatic Segmentation of Parotid Tumor from Multimodal MRI
Oct 04, 2022
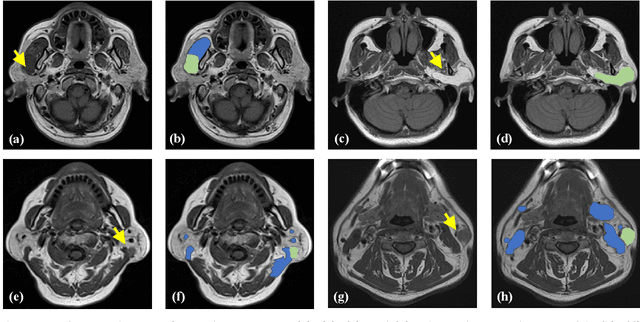

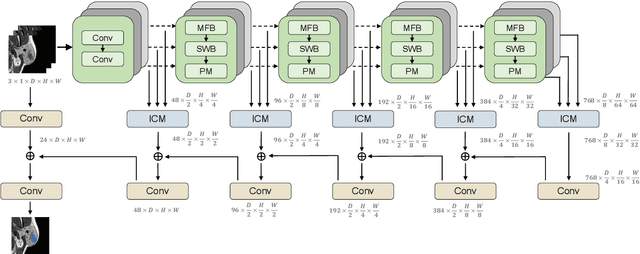

Magnetic Resonance Imaging (MRI) plays an important role in diagnosing the parotid tumor, where accurate segmentation of tumors is highly desired for determining appropriate treatment plans and avoiding unnecessary surgery. However, the task remains nontrivial and challenging due to ambiguous boundaries and various sizes of the tumor, as well as the presence of a large number of anatomical structures around the parotid gland that are similar to the tumor. To overcome these problems, we propose a novel anatomy-aware framework for automatic segmentation of parotid tumors from multimodal MRI. First, a Transformer-based multimodal fusion network PT-Net is proposed in this paper. The encoder of PT-Net extracts and fuses contextual information from three modalities of MRI from coarse to fine, to obtain cross-modality and multi-scale tumor information. The decoder stacks the feature maps of different modalities and calibrates the multimodal information using the channel attention mechanism. Second, considering that the segmentation model is prone to be disturbed by similar anatomical structures and make wrong predictions, we design anatomy-aware loss. By calculating the distance between the activation regions of the prediction segmentation and the ground truth, our loss function forces the model to distinguish similar anatomical structures with the tumor and make correct predictions. Extensive experiments with MRI scans of the parotid tumor showed that our PT-Net achieved higher segmentation accuracy than existing networks. The anatomy-aware loss outperformed state-of-the-art loss functions for parotid tumor segmentation. Our framework can potentially improve the quality of preoperative diagnosis and surgery planning of parotid tumors.
A Uniform Representation Learning Method for OCT-based Fingerprint Presentation Attack Detection and Reconstruction
Sep 25, 2022
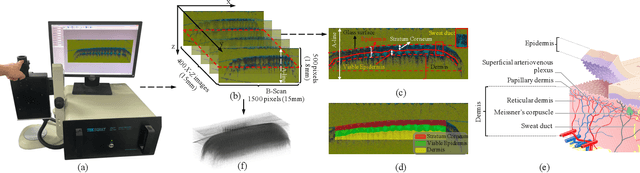

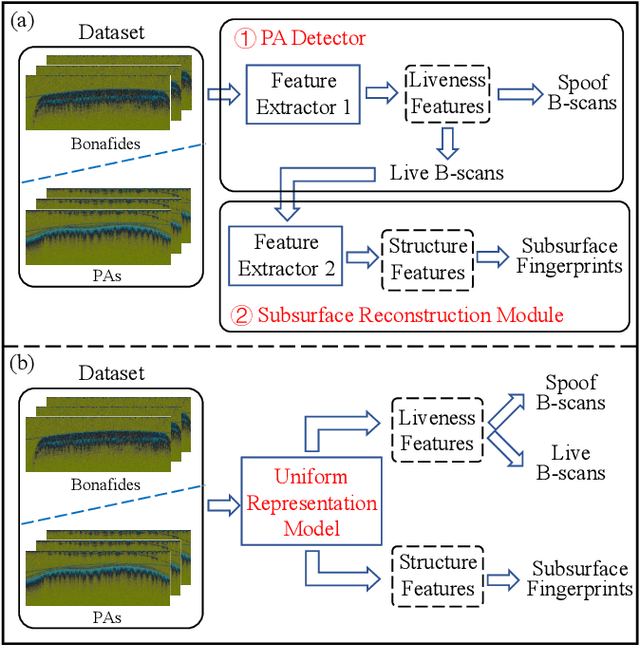
The technology of optical coherence tomography (OCT) to fingerprint imaging opens up a new research potential for fingerprint recognition owing to its ability to capture depth information of the skin layers. Developing robust and high security Automated Fingerprint Recognition Systems (AFRSs) are possible if the depth information can be fully utilized. However, in existing studies, Presentation Attack Detection (PAD) and subsurface fingerprint reconstruction based on depth information are treated as two independent branches, resulting in high computation and complexity of AFRS building.Thus, this paper proposes a uniform representation model for OCT-based fingerprint PAD and subsurface fingerprint reconstruction. Firstly, we design a novel semantic segmentation network which only trained by real finger slices of OCT-based fingerprints to extract multiple subsurface structures from those slices (also known as B-scans). The latent codes derived from the network are directly used to effectively detect the PA since they contain abundant subsurface biological information, which is independent with PA materials and has strong robustness for unknown PAs. Meanwhile, the segmented subsurface structures are adopted to reconstruct multiple subsurface 2D fingerprints. Recognition can be easily achieved by using existing mature technologies based on traditional 2D fingerprints. Extensive experiments are carried on our own established database, which is the largest public OCT-based fingerprint database with 2449 volumes. In PAD task, our method can improve 0.33% Acc from the state-of-the-art method. For reconstruction performance, our method achieves the best performance with 0.834 mIOU and 0.937 PA. By comparing with the recognition performance on surface 2D fingerprints, the effectiveness of our proposed method on high quality subsurface fingerprint reconstruction is further proved.
Motif-guided Time Series Counterfactual Explanations
Nov 08, 2022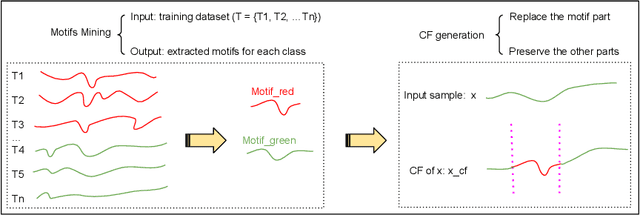
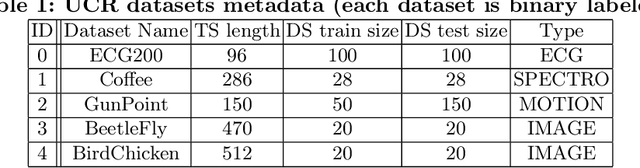
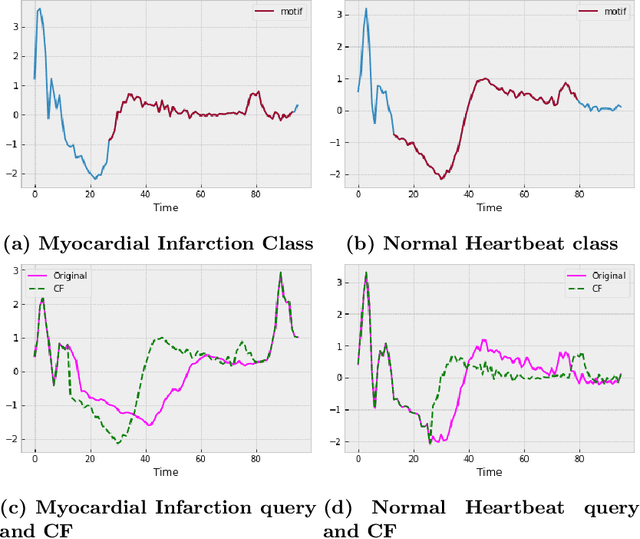
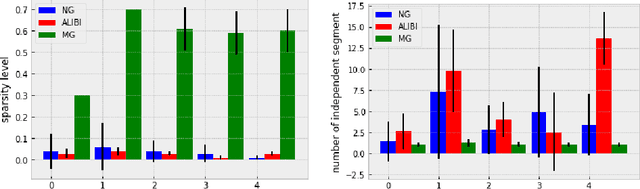
With the rising need of interpretable machine learning methods, there is a necessity for a rise in human effort to provide diverse explanations of the influencing factors of the model decisions. To improve the trust and transparency of AI-based systems, the EXplainable Artificial Intelligence (XAI) field has emerged. The XAI paradigm is bifurcated into two main categories: feature attribution and counterfactual explanation methods. While feature attribution methods are based on explaining the reason behind a model decision, counterfactual explanation methods discover the smallest input changes that will result in a different decision. In this paper, we aim at building trust and transparency in time series models by using motifs to generate counterfactual explanations. We propose Motif-Guided Counterfactual Explanation (MG-CF), a novel model that generates intuitive post-hoc counterfactual explanations that make full use of important motifs to provide interpretive information in decision-making processes. To the best of our knowledge, this is the first effort that leverages motifs to guide the counterfactual explanation generation. We validated our model using five real-world time-series datasets from the UCR repository. Our experimental results show the superiority of MG-CF in balancing all the desirable counterfactual explanations properties in comparison with other competing state-of-the-art baselines.
Deep Appearance Prefiltering
Nov 08, 2022


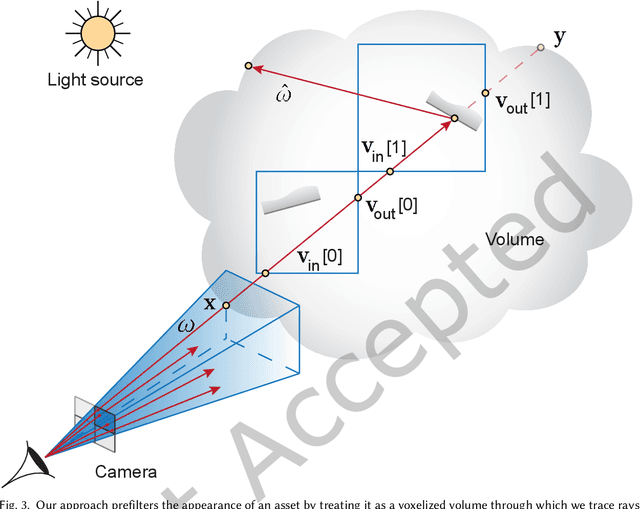
Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
Doubly Inhomogeneous Reinforcement Learning
Nov 08, 2022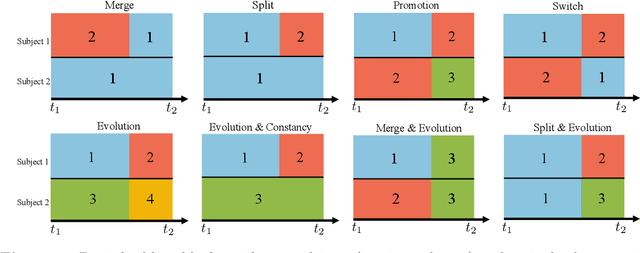
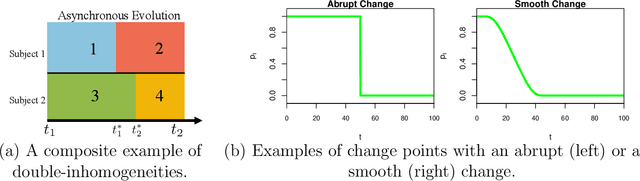

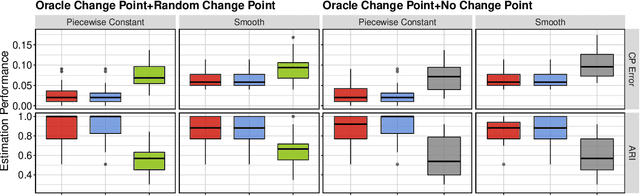
This paper studies reinforcement learning (RL) in doubly inhomogeneous environments under temporal non-stationarity and subject heterogeneity. In a number of applications, it is commonplace to encounter datasets generated by system dynamics that may change over time and population, challenging high-quality sequential decision making. Nonetheless, most existing RL solutions require either temporal stationarity or subject homogeneity, which would result in sub-optimal policies if both assumptions were violated. To address both challenges simultaneously, we propose an original algorithm to determine the ``best data chunks" that display similar dynamics over time and across individuals for policy learning, which alternates between most recent change point detection and cluster identification. Our method is general, and works with a wide range of clustering and change point detection algorithms. It is multiply robust in the sense that it takes multiple initial estimators as input and only requires one of them to be consistent. Moreover, by borrowing information over time and population, it allows us to detect weaker signals and has better convergence properties when compared to applying the clustering algorithm per time or the change point detection algorithm per subject. Empirically, we demonstrate the usefulness of our method through extensive simulations and a real data application.
Multiple Signal Classification Based Joint Communication and Sensing System
Nov 08, 2022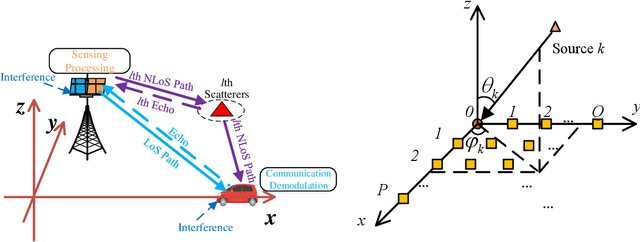
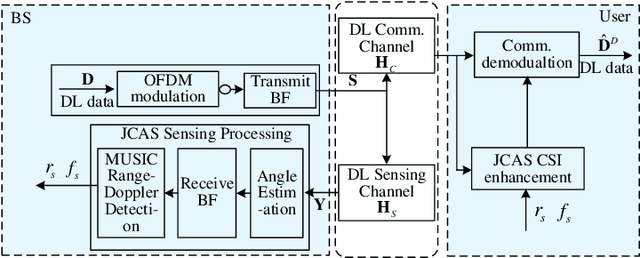
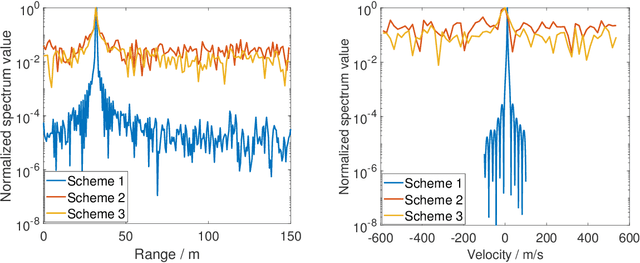
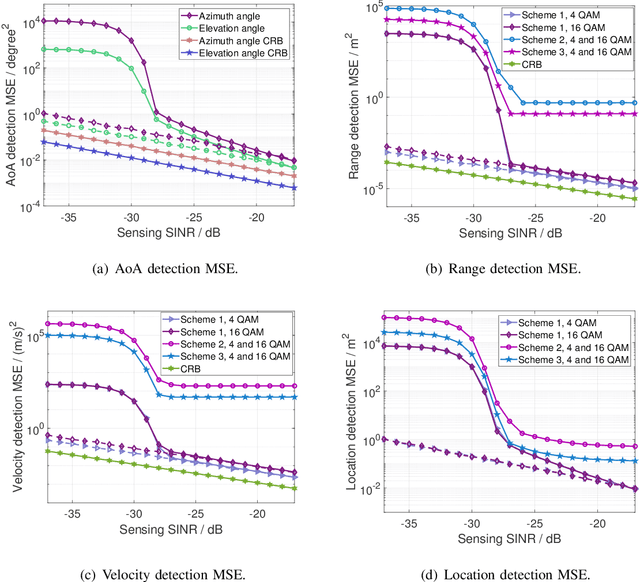
Joint communication and sensing (JCS) has become a promising technology for mobile networks because of its higher spectrum and energy efficiency. Up to now, the prevalent fast Fourier transform (FFT)-based sensing method for mobile JCS networks is on-grid based, and the grid interval determines the resolution. Because the mobile network usually has limited consecutive OFDM symbols in a downlink (DL) time slot, the sensing accuracy is restricted by the limited resolution, especially for velocity estimation. In this paper, we propose a multiple signal classification (MUSIC)-based JCS system that can achieve higher sensing accuracy for the angle of arrival, range, and velocity estimation, compared with the traditional FFT-based JCS method. We further propose a JCS channel state information (CSI) enhancement method by leveraging the JCS sensing results. Finally, we derive a theoretical lower bound for sensing mean square error (MSE) by using perturbation analysis. Simulation results show that in terms of the sensing MSE performance, the proposed MUSIC-based JCS outperforms the FFT-based one by more than 20 dB. Moreover, the bit error rate (BER) of communication demodulation using the proposed JCS CSI enhancement method is significantly reduced compared with communication using the originally estimated CSI.
Downlink and Uplink Cooperative Joint Communication and Sensing
Nov 08, 2022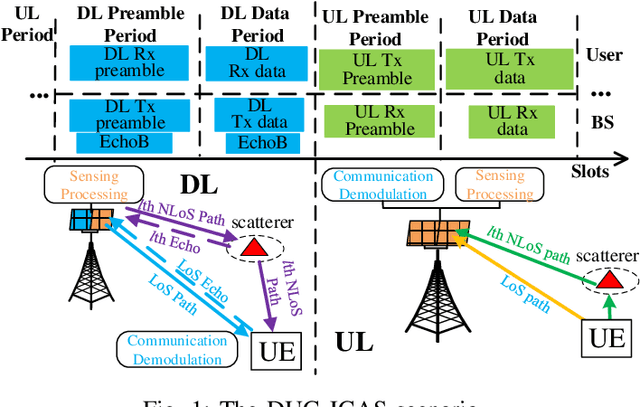
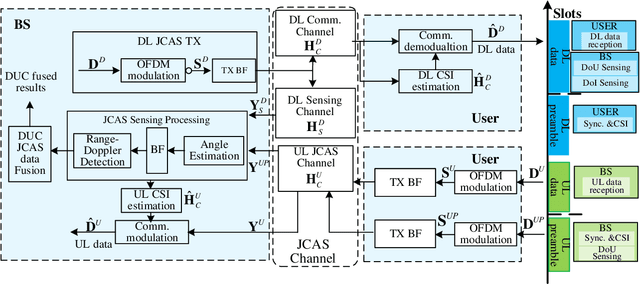
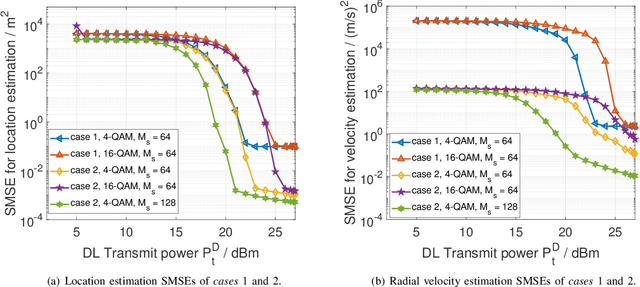
Downlink (DL) and uplink (UL) joint communication and sensing (JCAS) technologies have been individually studied for realizing sensing using DL and UL communication signals, respectively. Since the spatial environment and JCAS channels in the consecutive DL and UL JCAS time slots are generally unchanged, DL and UL JCAS may be jointly designed to achieve better sensing performance. In this paper, we propose a novel DL and UL cooperative (DUC) JCAS scheme, including a unified multiple signal classification (MUSIC)-based JCAS sensing scheme for both DL and UL JCAS and a DUC JCAS fusion method. The unified MUSIC JCAS sensing scheme can accurately estimate AoA, range, and Doppler based on a unified MUSIC-based sensing module. The DUC JCAS fusion method can distinguish between the sensing results of the communication user and other dumb targets. Moreover, by exploiting the channel reciprocity, it can also improve the sensing and channel state information (CSI) estimation accuracy. Extensive simulation results validate the proposed DUC JCAS scheme. It is shown that the minimum location and velocity estimation mean square errors of the proposed DUC JCAS scheme are about 20 dB lower than those of the state-of-the-art separated DL and UL JCAS schemes.
Toward Reliable Neural Specifications
Nov 14, 2022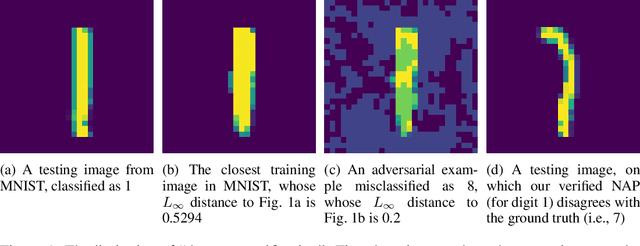


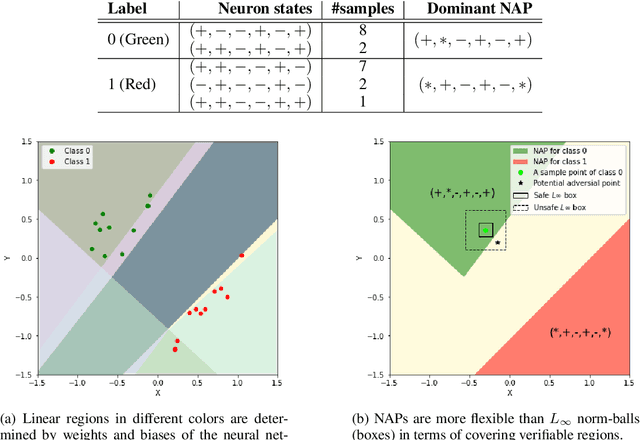
Having reliable specifications is an unavoidable challenge in achieving verifiable correctness, robustness, and interpretability of AI systems. Existing specifications for neural networks are in the paradigm of data as specification. That is, the local neighborhood centering around a reference input is considered to be correct (or robust). However, our empirical study shows that such a specification is extremely overfitted since usually no data points from the testing set lie in the certified region of the reference input, making them impractical for real-world applications. We propose a new family of specifications called neural representation as specification, which uses the intrinsic information of neural networks - neural activation patterns (NAP), rather than input data to specify the correctness and/or robustness of neural network predictions. We present a simple statistical approach to mining dominant neural activation patterns. We analyze NAPs from a statistical point of view and find that a single NAP can cover a large number of training and testing data points whereas ad hoc data-as-specification only covers the given reference data point. To show the effectiveness of discovered NAPs, we formally verify several important properties, such as various types of misclassifications will never happen for a given NAP, and there is no-ambiguity between different NAPs. We show that by using NAP, we can verify the prediction of the entire input space, while still recalling 84% of the data. Thus, we argue that using NAPs is a more reliable and extensible specification for neural network verification.
Feature Correlation-guided Knowledge Transfer for Federated Self-supervised Learning
Nov 14, 2022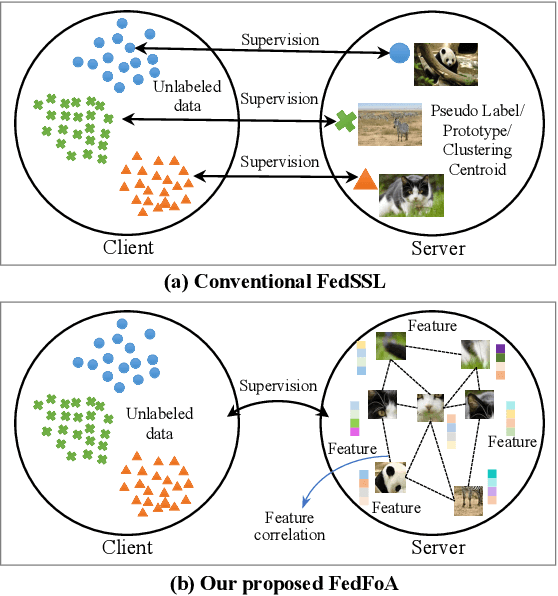
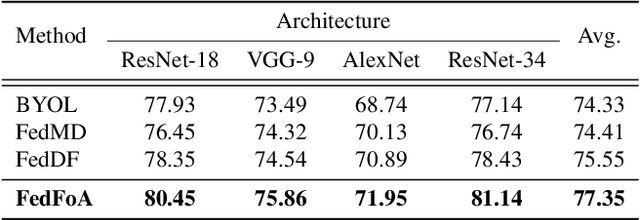
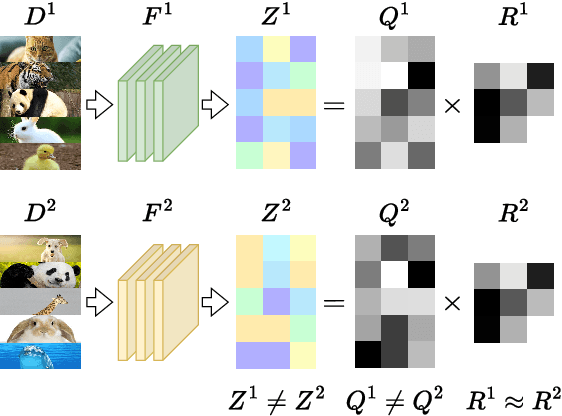
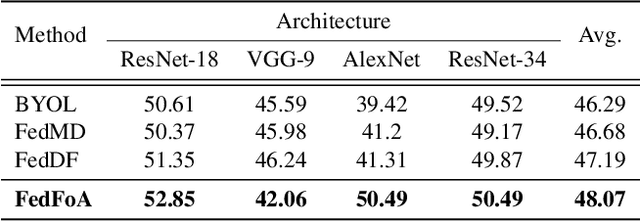
To eliminate the requirement of fully-labeled data for supervised model training in traditional Federated Learning (FL), extensive attention has been paid to the application of Self-supervised Learning (SSL) approaches on FL to tackle the label scarcity problem. Previous works on Federated SSL generally fall into two categories: parameter-based model aggregation (i.e., FedAvg, applicable to homogeneous cases) or data-based feature sharing (i.e., knowledge distillation, applicable to heterogeneous cases) to achieve knowledge transfer among multiple unlabeled clients. Despite the progress, all of them inevitably rely on some assumptions, such as homogeneous models or the existence of an additional public dataset, which hinder the universality of the training frameworks for more general scenarios. Therefore, in this paper, we propose a novel and general method named Federated Self-supervised Learning with Feature-correlation based Aggregation (FedFoA) to tackle the above limitations in a communication-efficient and privacy-preserving manner. Our insight is to utilize feature correlation to align the feature mappings and calibrate the local model updates across clients during their local training process. More specifically, we design a factorization-based method to extract the cross-feature relation matrix from the local representations. Then, the relation matrix can be regarded as a carrier of semantic information to perform the aggregation phase. We prove that FedFoA is a model-agnostic training framework and can be easily compatible with state-of-the-art unsupervised FL methods. Extensive empirical experiments demonstrate that our proposed approach outperforms the state-of-the-art methods by a significant margin.
Bayesian Reconstruction and Differential Testing of Excised mRNA
Nov 14, 2022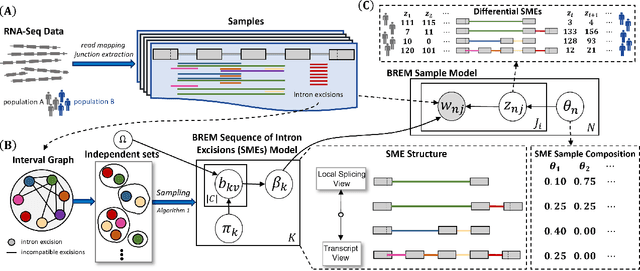
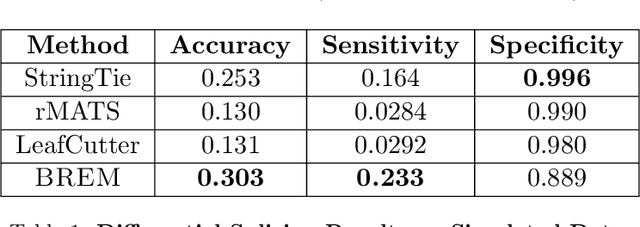

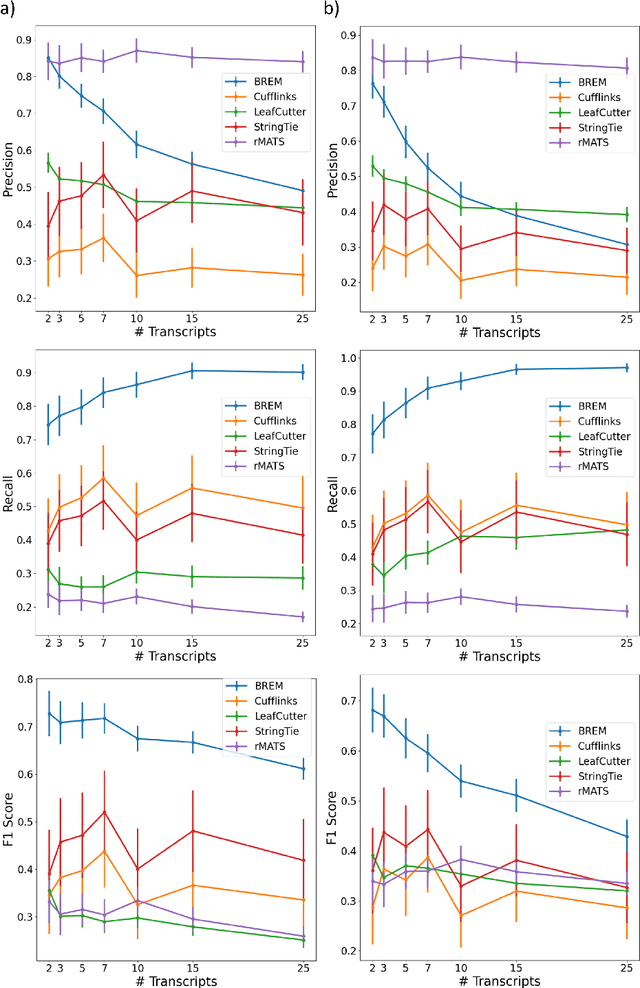
Characterizing the differential excision of mRNA is critical for understanding the functional complexity of a cell or tissue, from normal developmental processes to disease pathogenesis. Most transcript reconstruction methods infer full-length transcripts from high-throughput sequencing data. However, this is a challenging task due to incomplete annotations and the differential expression of transcripts across cell-types, tissues, and experimental conditions. Several recent methods circumvent these difficulties by considering local splicing events, but these methods lose transcript-level splicing information and may conflate transcripts. We develop the first probabilistic model that reconciles the transcript and local splicing perspectives. First, we formalize the sequence of mRNA excisions (SME) reconstruction problem, which aims to assemble variable-length sequences of mRNA excisions from RNA-sequencing data. We then present a novel hierarchical Bayesian admixture model for the Reconstruction of Excised mRNA (BREM). BREM interpolates between local splicing events and full-length transcripts and thus focuses only on SMEs that have high posterior probability. We develop posterior inference algorithms based on Gibbs sampling and local search of independent sets and characterize differential SME usage using generalized linear models based on converged BREM model parameters. We show that BREM achieves higher F1 score for reconstruction tasks and improved accuracy and sensitivity in differential splicing when compared with four state-of-the-art transcript and local splicing methods on simulated data. Lastly, we evaluate BREM on both bulk and scRNA sequencing data based on transcript reconstruction, novelty of transcripts produced, model sensitivity to hyperparameters, and a functional analysis of differentially expressed SMEs, demonstrating that BREM captures relevant biological signal.