 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Wireless Information and Power Transfer: A Bottom-Up Cross-Layer Design Framework
Jan 28, 2022
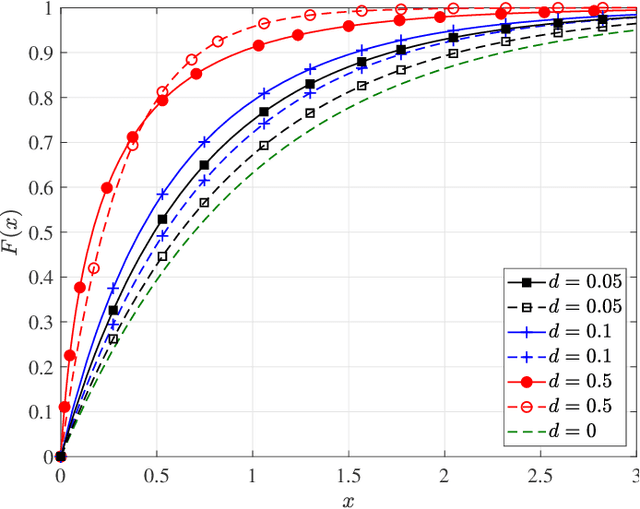
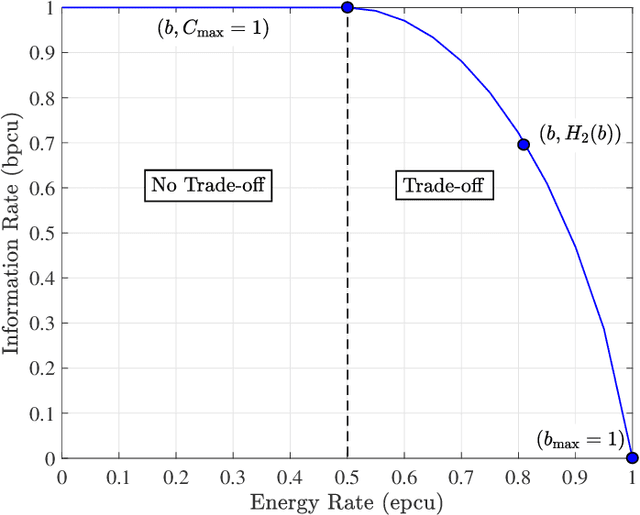
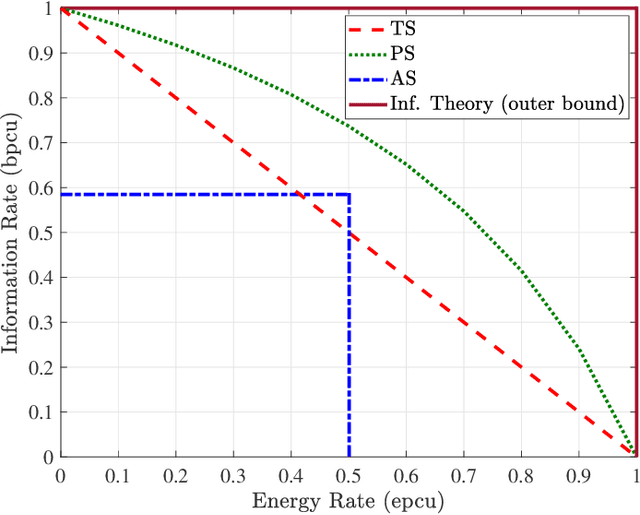
The efficiency of wireless information and power transfer (WIPT) systems requires an essential reevaluation and rethinking of the entire transceiver chain, which is characterized by a bottom-up cross-layer design approach. In this paper, we introduce and describe the key design layers: i) "Mathematical modeling", associated with the investigation of mathematical models for the wireless power transfer process, ii) "Information-theoretic limits", which refers to the fundamental limits of the WIPT channel, iii) "Link design", corresponding to signal processing techniques that make WIPT feasible, iv) "System-level perspective", which studies the developed WIPT techniques from a macroscopic system-level point-of-view, and v) "Experimental studies", that refers to real-world implementation of WIPT systems. These layers are well-connected and their interplay is imperative for the effective design of WIPT systems. Specific case studies are discussed, which demonstrates the interdisciplinary nature of the aforementioned cross-layer design framework.
M$^3$Video: Masked Motion Modeling for Self-Supervised Video Representation Learning
Oct 12, 2022
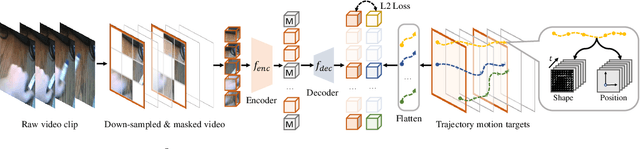

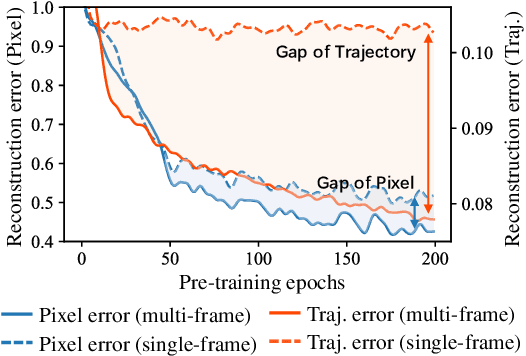
We study self-supervised video representation learning that seeks to learn video features from unlabeled videos, which is widely used for video analysis as labeling videos is labor-intensive. Current methods often mask some video regions and then train a model to reconstruct spatial information in these regions (e.g., original pixels). However, the model is easy to reconstruct this information by considering content in a single frame. As a result, it may neglect to learn the interactions between frames, which are critical for video analysis. In this paper, we present a new self-supervised learning task, called Masked Motion Modeling (M$^3$Video), for learning representation by enforcing the model to predict the motion of moving objects in the masked regions. To generate motion targets for this task, we track the objects using optical flow. The motion targets consist of position transitions and shape changes of the tracked objects, thus the model has to consider multiple frames comprehensively. Besides, to help the model capture fine-grained motion details, we enforce the model to predict trajectory motion targets in high temporal resolution based on a video in low temporal resolution. After pre-training using our M$^3$Video task, the model is able to anticipate fine-grained motion details even taking a sparsely sampled video as input. We conduct extensive experiments on four benchmark datasets. Remarkably, when doing pre-training with 400 epochs, we improve the accuracy from 67.6\% to 69.2\% and from 78.8\% to 79.7\% on Something-Something V2 and Kinetics-400 datasets, respectively.
Graph Perceiver IO: A General Architecture for Graph Structured Data
Sep 14, 2022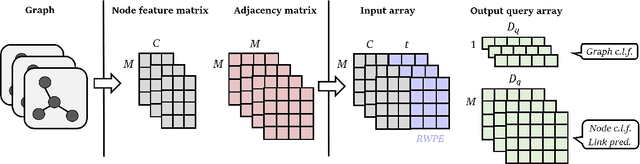
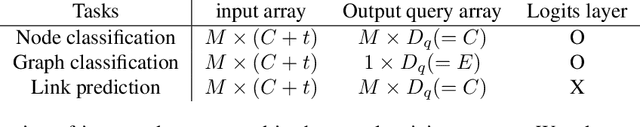
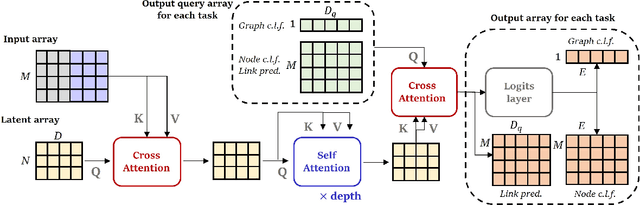
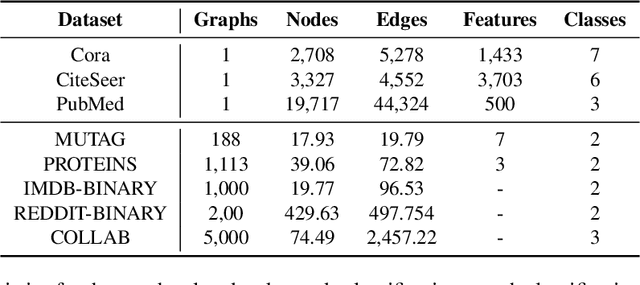
Multimodal machine learning has been widely studied for the development of general intelligence. Recently, the remarkable multimodal algorithms, the Perceiver and Perceiver IO, show competitive results for diverse dataset domains and tasks. However, recent works, Perceiver and Perceiver IO, have focused on heterogeneous modalities, including image, text, and speech, and there are few research works for graph structured datasets. A graph is one of the most generalized dataset structures, and we can represent the other dataset, including images, text, and speech, as graph structured data. A graph has an adjacency matrix different from other dataset domains such as text and image, and it is not trivial to handle the topological information, relational information, and canonical positional information. In this study, we provide a Graph Perceiver IO, the Perceiver IO for the graph structured dataset. We keep the main structure of the Graph Perceiver IO as the Perceiver IO because the Perceiver IO already handles the diverse dataset well, except for the graph structured dataset. The Graph Perceiver IO is a general method, and it can handle diverse datasets such as graph structured data as well as text and images. Comparing the graph neural networks, the Graph Perceiver IO requires a lower complexity, and it can incorporate the local and global information efficiently. We show that Graph Perceiver IO shows competitive results for diverse graph-related tasks, including node classification, graph classification, and link prediction.
Speech-text based multi-modal training with bidirectional attention for improved speech recognition
Nov 01, 2022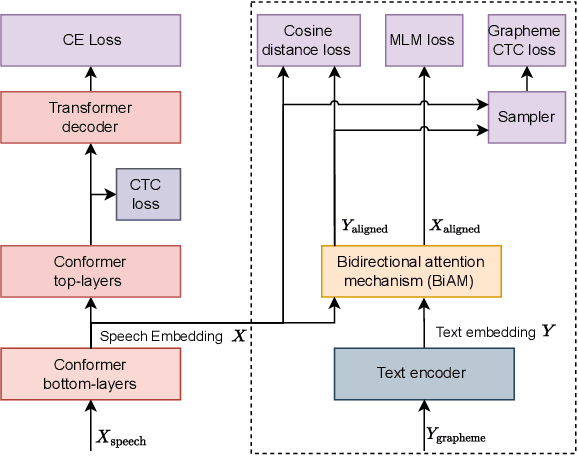
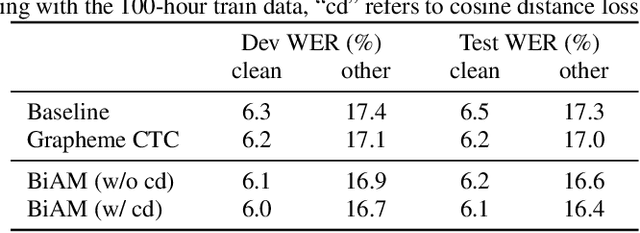
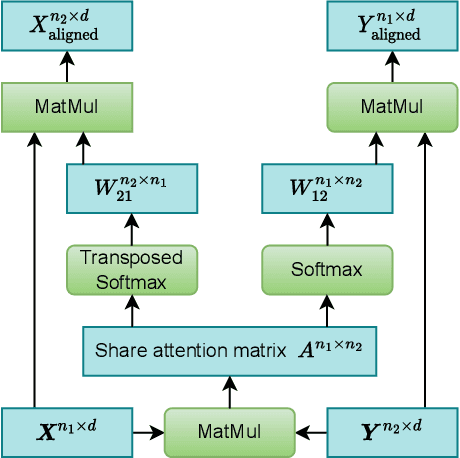
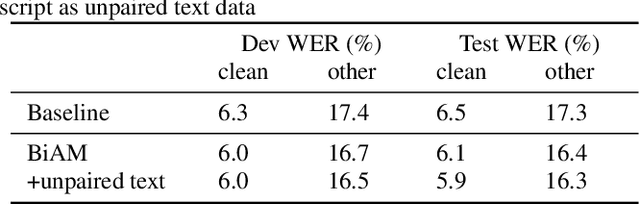
To let the state-of-the-art end-to-end ASR model enjoy data efficiency, as well as much more unpaired text data by multi-modal training, one needs to address two problems: 1) the synchronicity of feature sampling rates between speech and language (aka text data); 2) the homogeneity of the learned representations from two encoders. In this paper we propose to employ a novel bidirectional attention mechanism (BiAM) to jointly learn both ASR encoder (bottom layers) and text encoder with a multi-modal learning method. The BiAM is to facilitate feature sampling rate exchange, realizing the quality of the transformed features for the one kind to be measured in another space, with diversified objective functions. As a result, the speech representations are enriched with more linguistic information, while the representations generated by the text encoder are more similar to corresponding speech ones, and therefore the shared ASR models are more amenable for unpaired text data pretraining. To validate the efficacy of the proposed method, we perform two categories of experiments with or without extra unpaired text data. Experimental results on Librispeech corpus show it can achieve up to 6.15% word error rate reduction (WERR) with only paired data learning, while 9.23% WERR when more unpaired text data is employed.
Multi-dimensional Edge-based Audio Event Relational Graph Representation Learning for Acoustic Scene Classification
Nov 01, 2022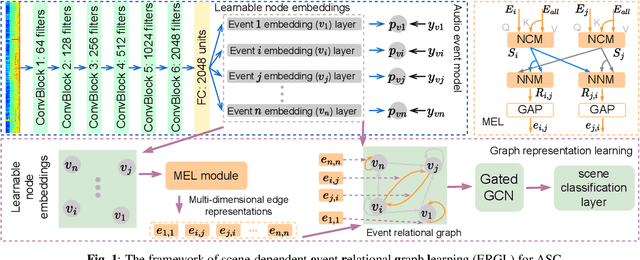
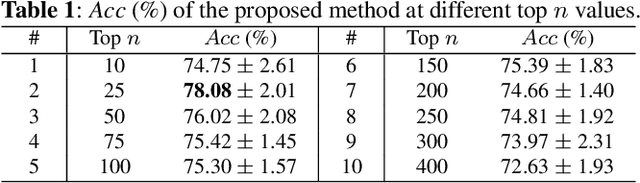

Most existing deep learning-based acoustic scene classification (ASC) approaches directly utilize representations extracted from spectrograms to identify target scenes. However, these approaches pay little attention to the audio events occurring in the scene despite they provide crucial semantic information. This paper conducts the first study that investigates whether real-life acoustic scenes can be reliably recognized based only on the features that describe a limited number of audio events. To model the task-specific relationships between coarse-grained acoustic scenes and fine-grained audio events, we propose an event relational graph representation learning (ERGL) framework for ASC. Specifically, ERGL learns a graph representation of an acoustic scene from the input audio, where the embedding of each event is treated as a node, while the relationship cues derived from each pair of event embeddings are described by a learned multidimensional edge feature. Experiments on a polyphonic acoustic scene dataset show that the proposed ERGL achieves competitive performance on ASC by using only a limited number of embeddings of audio events without any data augmentations. The validity of the proposed ERGL framework proves the feasibility of recognizing diverse acoustic scenes based on the event relational graph. Our code is available on our homepage (https://github.com/Yuanbo2020/ERGL).
Seg&Struct: The Interplay Between Part Segmentation and Structure Inference for 3D Shape Parsing
Nov 01, 2022
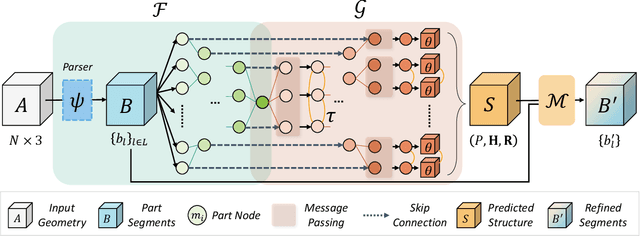
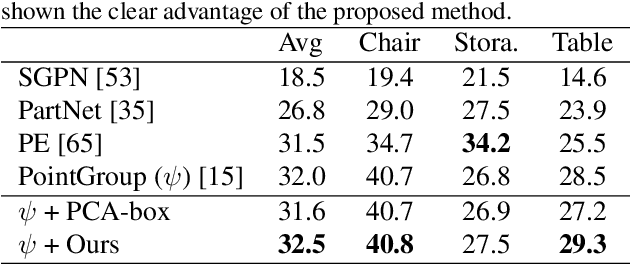
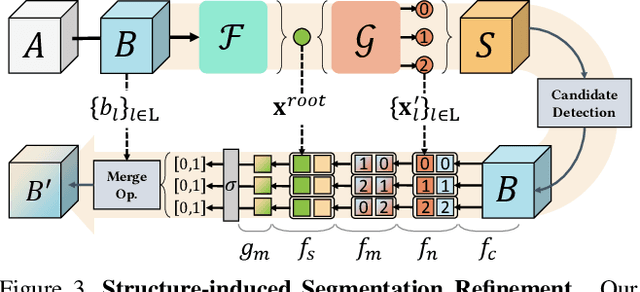
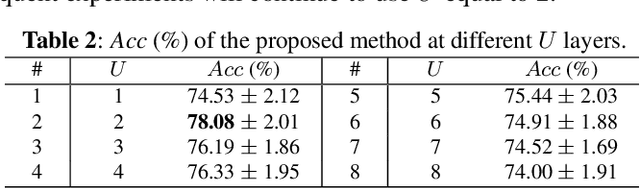
We propose Seg&Struct, a supervised learning framework leveraging the interplay between part segmentation and structure inference and demonstrating their synergy in an integrated framework. Both part segmentation and structure inference have been extensively studied in the recent deep learning literature, while the supervisions used for each task have not been fully exploited to assist the other task. Namely, structure inference has been typically conducted with an autoencoder that does not leverage the point-to-part associations. Also, segmentation has been mostly performed without structural priors that tell the plausibility of the output segments. We present how these two tasks can be best combined while fully utilizing supervision to improve performance. Our framework first decomposes a raw input shape into part segments using an off-the-shelf algorithm, whose outputs are then mapped to nodes in a part hierarchy, establishing point-to-part associations. Following this, ours predicts the structural information, e.g., part bounding boxes and part relationships. Lastly, the segmentation is rectified by examining the confusion of part boundaries using the structure-based part features. Our experimental results based on the StructureNet and PartNet demonstrate that the interplay between the two tasks results in remarkable improvements in both tasks: 27.91% in structure inference and 0.5% in segmentation.
Robust Hyperspectral Image Fusion with Simultaneous Guide Image Denoising via Constrained Convex Optimization
Sep 24, 2022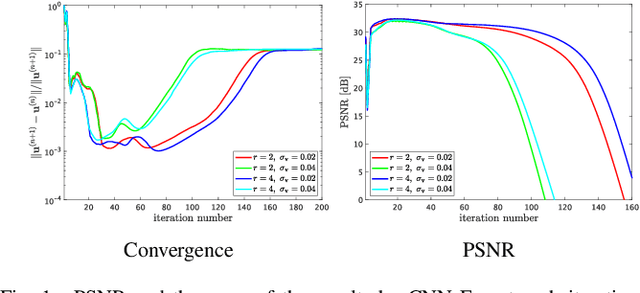
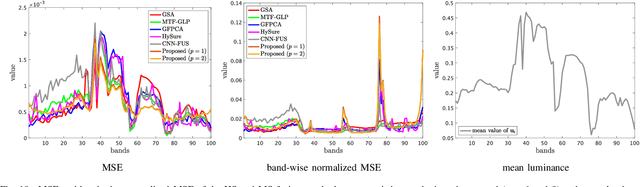

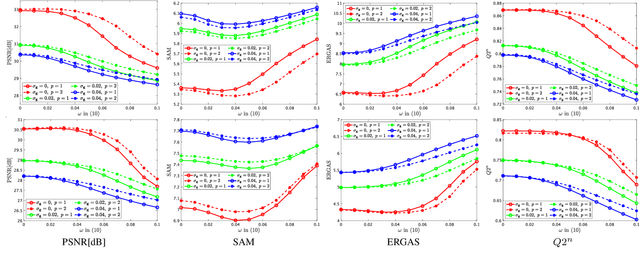
The paper proposes a new high spatial resolution hyperspectral (HR-HS) image estimation method based on convex optimization. The method assumes a low spatial resolution HS (LR-HS) image and a guide image as observations, where both observations are contaminated by noise. Our method simultaneously estimates an HR-HS image and a noiseless guide image, so the method can utilize spatial information in a guide image even if it is contaminated by heavy noise. The proposed estimation problem adopts hybrid spatio-spectral total variation as regularization and evaluates the edge similarity between HR-HS and guide images to effectively use apriori knowledge on an HR-HS image and spatial detail information in a guide image. To efficiently solve the problem, we apply a primal-dual splitting method. Experiments demonstrate the performance of our method and the advantage over several existing methods.
Robot to Human Object Handover using Vision and Joint Torque Sensor Modalities
Oct 27, 2022
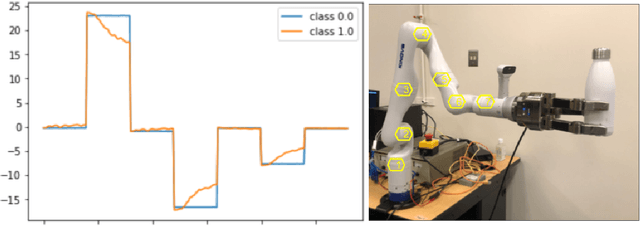
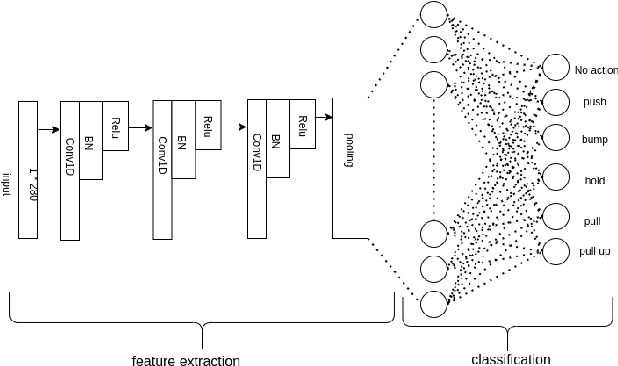
We present a robot-to-human object handover algorithm and implement it on a 7-DOF arm equipped with a 3-finger mechanical hand. The system performs a fully autonomous and robust object handover to a human receiver in real-time. Our algorithm relies on two complementary sensor modalities: joint torque sensors on the arm and an eye-in-hand RGB-D camera for sensor feedback. Our approach is entirely implicit, i.e., there is no explicit communication between the robot and the human receiver. Information obtained via the aforementioned sensor modalities is used as inputs to their related deep neural networks. While the torque sensor network detects the human receiver's "intention" such as: pull, hold, or bump, the vision sensor network detects if the receiver's fingers have wrapped around the object. Networks' outputs are then fused, based on which a decision is made to either release the object or not. Despite substantive challenges in sensor feedback synchronization, object, and human hand detection, our system achieves robust robot-to-human handover with 98\% accuracy in our preliminary real experiments using human receivers.
Decentralized Federated Learning via Non-Coherent Over-the-Air Consensus
Oct 27, 2022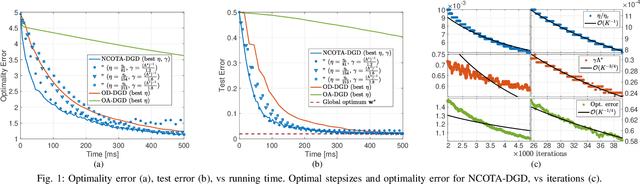
This paper presents NCOTA-DGD, a Decentralized Gradient Descent (DGD) algorithm that combines local gradient descent with Non-Coherent Over-The-Air (NCOTA) consensus at the receivers to solve distributed machine-learning problems over wirelessly-connected systems. NCOTA-DGD leverages the waveform superposition properties of the wireless channels: it enables simultaneous transmissions under half-duplex constraints, by mapping local signals to a mixture of preamble sequences, and consensus via non-coherent combining at the receivers. NCOTA-DGD operates without channel state information and leverages the average channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization algorithms). It is shown both theoretically and numerically that, for smooth and strongly-convex problems with fixed consensus and learning stepsizes, the updates of NCOTA-DGD converge (in Euclidean distance) to the global optimum with rate $\mathcal O(K^{-1/4})$ for a target number of iterations $K$. NCOTA-DGD is evaluated numerically over a logistic regression problem, showing faster convergence vis-\`a-vis running time than implementations of the classical DGD algorithm over digital and analog orthogonal channels.
Make More of Your Data: Minimal Effort Data Augmentation for Automatic Speech Recognition and Translation
Oct 27, 2022

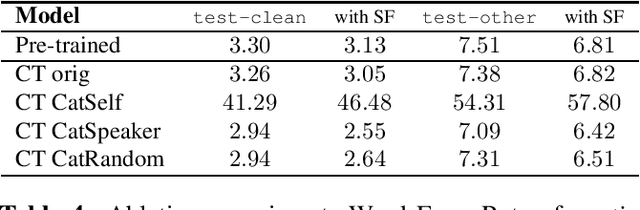
Data augmentation is a technique to generate new training data based on existing data. We evaluate the simple and cost-effective method of concatenating the original data examples to build new training instances. Continued training with such augmented data is able to improve off-the-shelf Transformer and Conformer models that were optimized on the original data only. We demonstrate considerable improvements on the LibriSpeech-960h test sets (WER 2.83 and 6.87 for test-clean and test-other), which carry over to models combined with shallow fusion (WER 2.55 and 6.27). Our method of continued training also leads to improvements of up to 0.9 WER on the ASR part of CoVoST-2 for four non English languages, and we observe that the gains are highly dependent on the size of the original training data. We compare different concatenation strategies and found that our method does not need speaker information to achieve its improvements. Finally, we demonstrate on two datasets that our methods also works for speech translation tasks.