 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Few-Shot Relation Extraction Pipeline Based on Adaptive Prototype Fusion
Oct 15, 2022
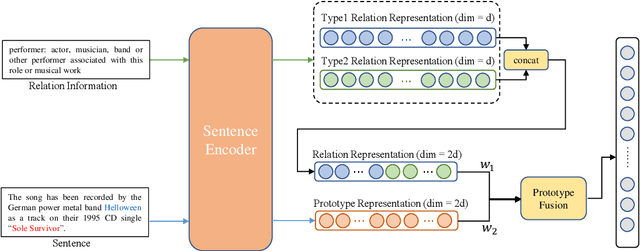
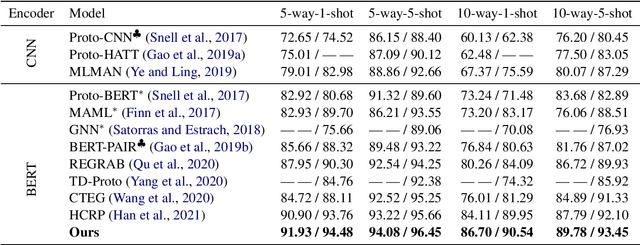
Few-shot relation extraction (FSRE) aims at recognizing unseen relations by learning with merely a handful of annotated instances. To more effectively generalize to new relations, this paper proposes a novel pipeline for the FSRE task based on adaptive prototype fusion. Specifically, for each relation class, the pipeline fully explores the relation information by concatenating two types of embedding, and then elaborately combine the relation representation with the adaptive prototype fusion mechanism. The whole framework can be effectively and efficiently optimized in an end-to-end fashion. Experiments on the benchmark dataset FewRel 1.0 show a significant improvement of our method against state-of-the-art methods.
Fairness Reprogramming
Sep 21, 2022
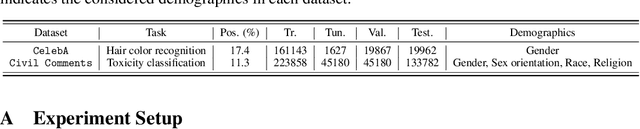
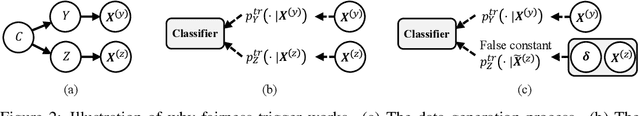
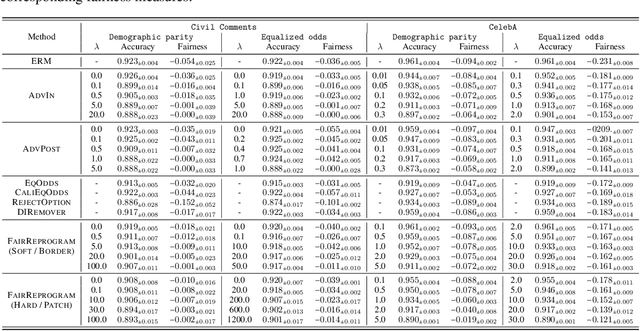
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.
Augmentation for Learning From Demonstration with Environmental Constraints
Oct 13, 2022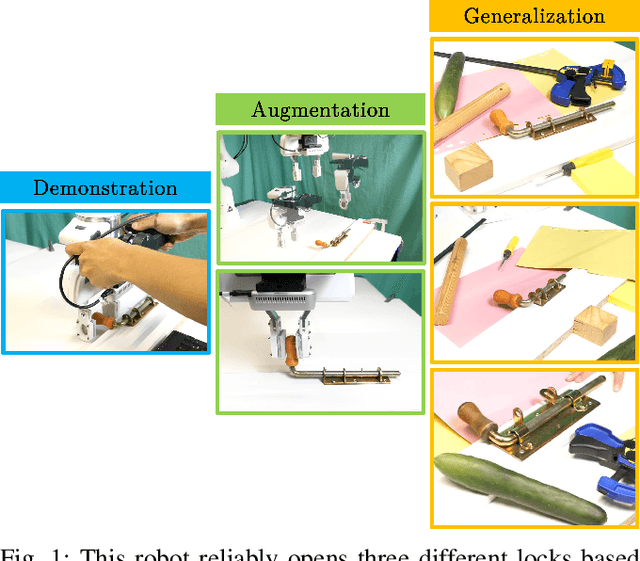
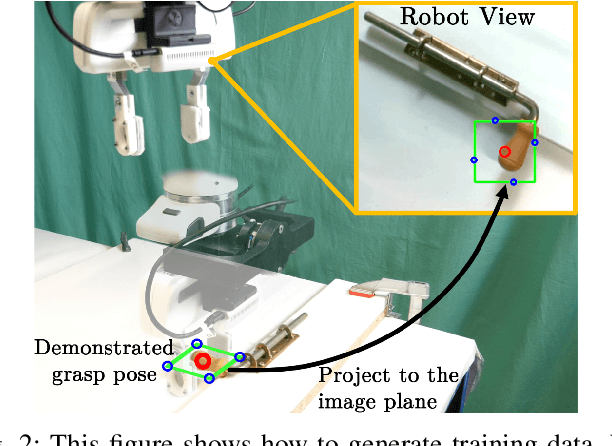
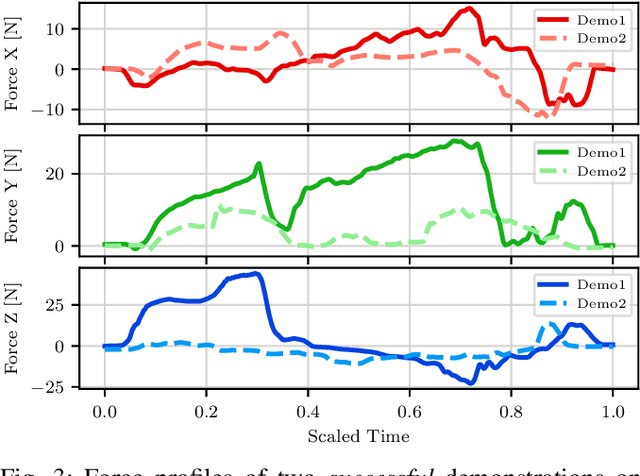

We introduce a Learning from Demonstration (LfD) approach for contact-rich manipulation tasks with articulated mechanisms. The extracted policy from a single human demonstration generalizes to different mechanisms of the same type and is robust against environmental variations. The key to achieving such generalization and robustness from a single human demonstration is to autonomously augment the initial demonstration to gather additional information through purposefully interacting with the environment. Our real-world experiments on complex mechanisms with multi-DOF demonstrate that our approach can reliably accomplish the task in a changing environment. Videos are available at the: https://sites.google.com/view/rbosalfdec/home
An Adaptive Threshold for the Canny Edge Detection with Actor-Critic Algorithm
Sep 19, 2022


Visual surveillance aims to perform robust foreground object detection regardless of the time and place. Object detection shows good results using only spatial information, but foreground object detection in visual surveillance requires proper temporal and spatial information processing. In deep learning-based foreground object detection algorithms, the detection ability is superior to classical background subtraction (BGS) algorithms in an environment similar to training. However, the performance is lower than that of the classical BGS algorithm in the environment different from training. This paper proposes a spatio-temporal fusion network (STFN) that could extract temporal and spatial information using a temporal network and a spatial network. We suggest a method using a semi-foreground map for stable training of the proposed STFN. The proposed algorithm shows excellent performance in an environment different from training, and we show it through experiments with various public datasets. Also, STFN can generate a compliant background image in a semi-supervised method, and it can operate in real-time on a desktop with GPU. The proposed method shows 11.28% and 18.33% higher FM than the latest deep learning method in the LASIESTA and SBI dataset, respectively.
Wireless Transmission of Images With The Assistance of Multi-level Semantic Information
Feb 08, 2022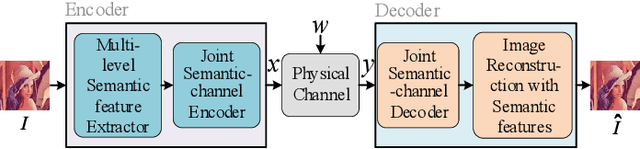
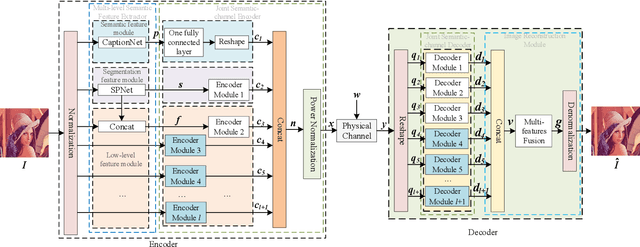
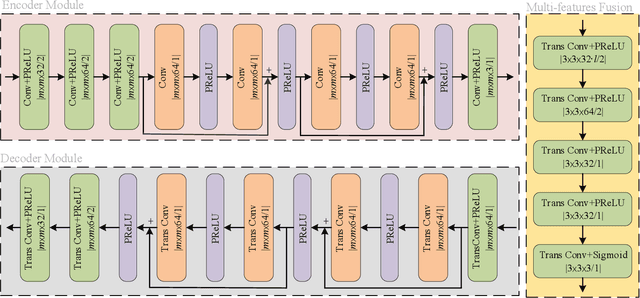
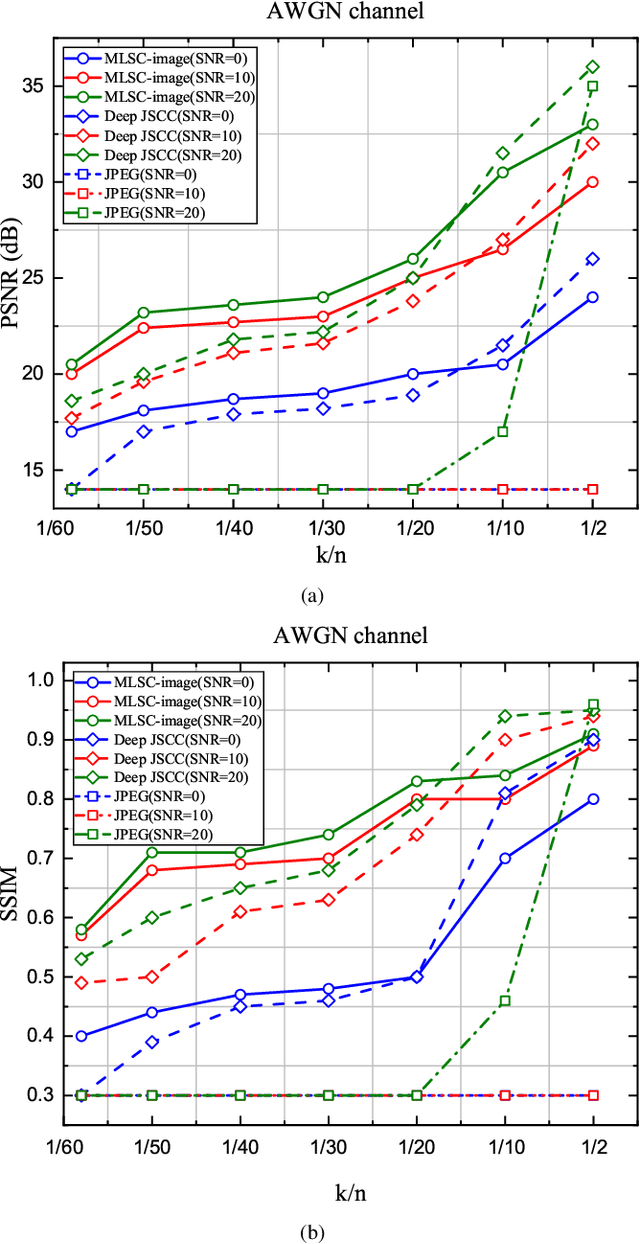
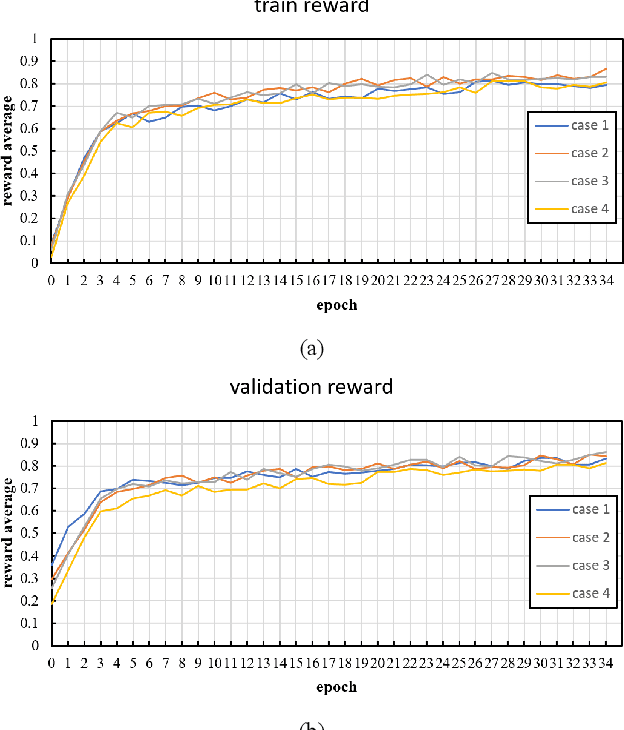
Semantic-oriented communication has been considered as a promising to boost the bandwidth efficiency by only transmitting the semantics of the data. In this paper, we propose a multi-level semantic aware communication system for wireless image transmission, named MLSC-image, which is based on the deep learning techniques and trained in an end to end manner. In particular, the proposed model includes a multilevel semantic feature extractor, that extracts both the highlevel semantic information, such as the text semantics and the segmentation semantics, and the low-level semantic information, such as local spatial details of the images. We employ a pretrained image caption to capture the text semantics and a pretrained image segmentation model to obtain the segmentation semantics. These high-level and low-level semantic features are then combined and encoded by a joint semantic and channel encoder into symbols to transmit over the physical channel. The numerical results validate the effectiveness and efficiency of the proposed semantic communication system, especially under the limited bandwidth condition, which indicates the advantages of the high-level semantics in the compression of images.
Mapping the Ictal-Interictal-Injury Continuum Using Interpretable Machine Learning
Nov 09, 2022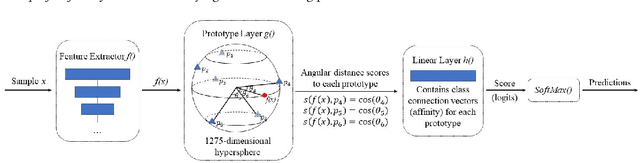

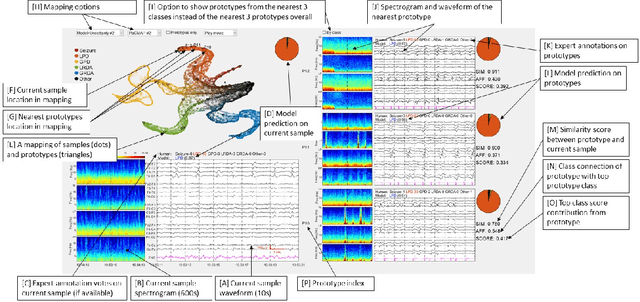

IMPORTANCE: An interpretable machine learning model can provide faithful explanations of each prediction and yet maintain higher performance than its black box counterpart. OBJECTIVE: To design an interpretable machine learning model which accurately predicts EEG protopatterns while providing an explanation of its predictions with assistance of a specialized GUI. To map the cEEG latent features to a 2D space in order to visualize the ictal-interictal-injury continuum and gain insight into its high-dimensional structure. DESIGN, SETTING, AND PARTICIPANTS: 50,697 50-second cEEG samples from 2,711 ICU patients collected between July 2006 and March 2020 at Massachusetts General Hospital. Samples were labeled as one of 6 EEG activities by domain experts, with 124 different experts providing annotations. MAIN OUTCOMES AND MEASURES: Our neural network is interpretable because it uses case-based reasoning: it compares a new EEG reading to a set of learned prototypical EEG samples from the training dataset. Interpretability was measured with task-specific neighborhood agreement statistics. Discriminatory performance was evaluated with AUROC and AUPRC. RESULTS: The model achieves AUROCs of 0.87, 0.93, 0.96, 0.92, 0.93, 0.80 for classes Seizure, LPD, GPD, LRDA, GRDA, Other respectively. This performance is statistically significantly higher than that of the corresponding uninterpretable (black box) model with p<0.0001. Videos of the ictal-interictal-injury continuum are provided. CONCLUSION AND RELEVANCE: Our interpretable model and GUI can act as a reference for practitioners who work with cEEG patterns. We can now better understand the relationships between different types of cEEG patterns. In the future, this system may allow for targeted intervention and training in clinical settings. It could also be used for re-confirming or providing additional information for diagnostics.
Semantic Visual Simultaneous Localization and Mapping: A Survey
Sep 14, 2022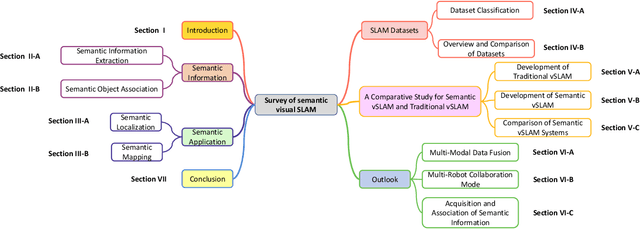
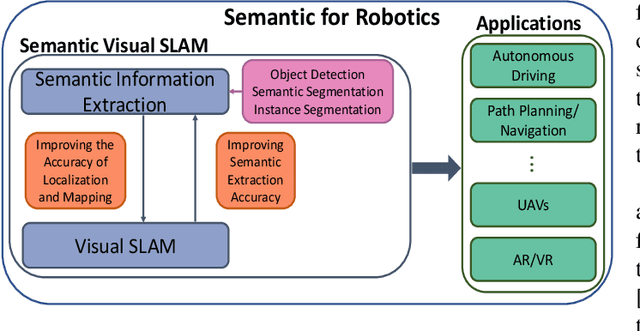

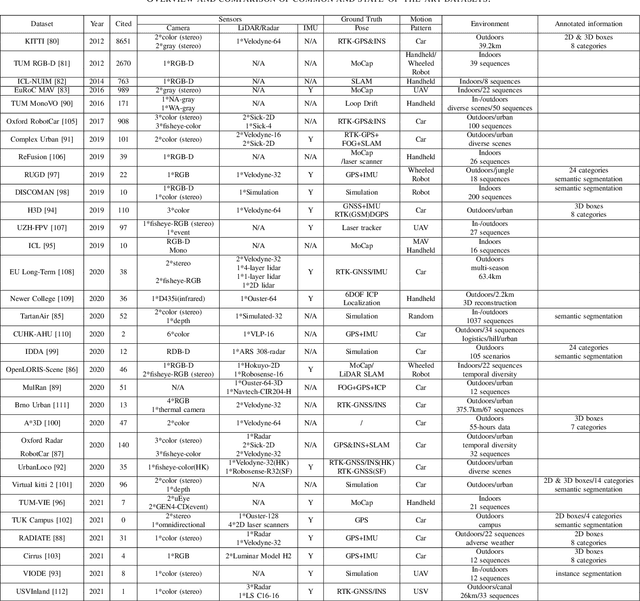
Visual Simultaneous Localization and Mapping (vSLAM) has achieved great progress in the computer vision and robotics communities, and has been successfully used in many fields such as autonomous robot navigation and AR/VR. However, vSLAM cannot achieve good localization in dynamic and complex environments. Numerous publications have reported that, by combining with the semantic information with vSLAM, the semantic vSLAM systems have the capability of solving the above problems in recent years. Nevertheless, there is no comprehensive survey about semantic vSLAM. To fill the gap, this paper first reviews the development of semantic vSLAM, explicitly focusing on its strengths and differences. Secondly, we explore three main issues of semantic vSLAM: the extraction and association of semantic information, the application of semantic information, and the advantages of semantic vSLAM. Then, we collect and analyze the current state-of-the-art SLAM datasets which have been widely used in semantic vSLAM systems. Finally, we discuss future directions that will provide a blueprint for the future development of semantic vSLAM.
AffRankNet+: Ranking Affect Using Privileged Information
Aug 12, 2021

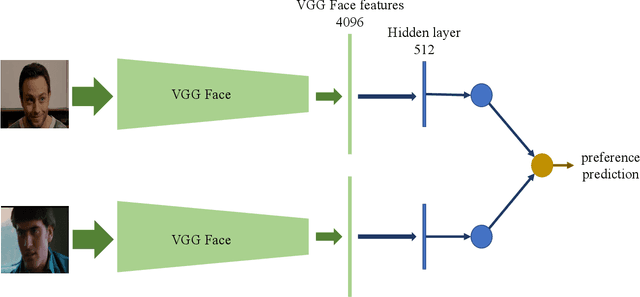
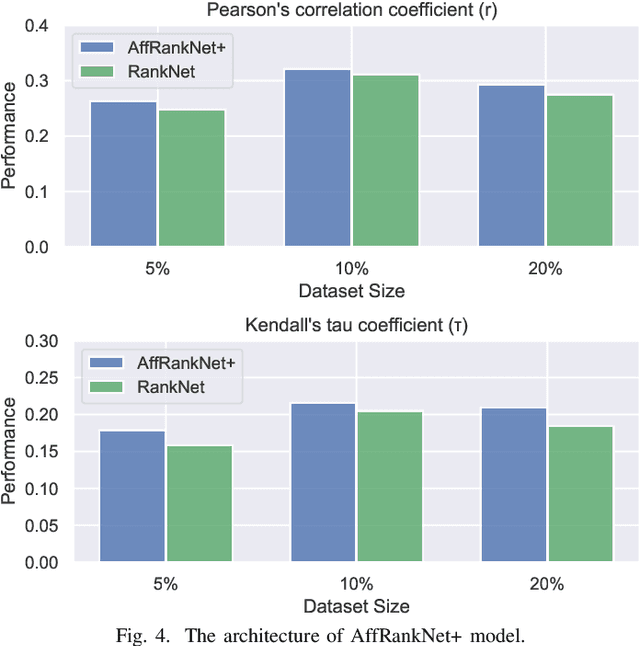
Many of the affect modelling tasks present an asymmetric distribution of information between training and test time; additional information is given about the training data, which is not available at test time. Learning under this setting is called Learning Under Privileged Information (LUPI). At the same time, due to the ordinal nature of affect annotations, formulating affect modelling tasks as supervised learning ranking problems is gaining ground within the Affective Computing research community. Motivated by the two facts above, in this study, we introduce a ranking model that treats additional information about the training data as privileged information to accurately rank affect states. Our ranking model extends the well-known RankNet model to the LUPI paradigm, hence its name AffRankNet+. To the best of our knowledge, it is the first time that a ranking model based on neural networks exploits privileged information. We evaluate the performance of the proposed model on the public available Afew-VA dataset and compare it against the RankNet model, which does not use privileged information. Experimental evaluation indicates that the AffRankNet+ model can yield significantly better performance.
Using Language to Extend to Unseen Domains
Oct 20, 2022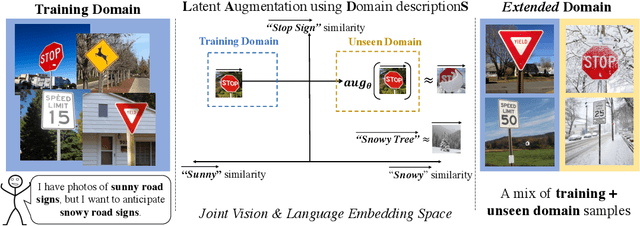
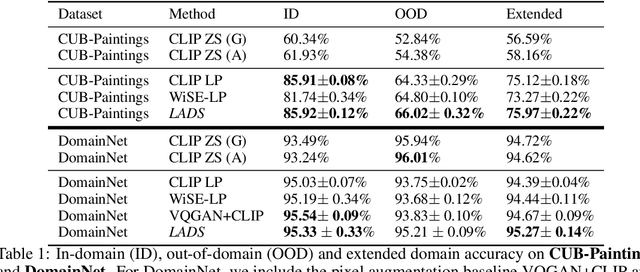
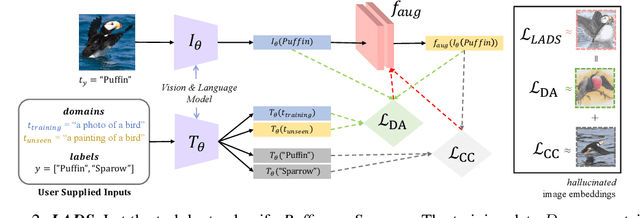

It is expensive to collect training data for every possible domain that a vision model may encounter when deployed. We instead consider how simply verbalizing the training domain (e.g. "photos of birds") as well as domains we want to extend to but do not have data for (e.g. "paintings of birds") can improve robustness. Using a multimodal model with a joint image and language embedding space, our method LADS learns a transformation of the image embeddings from the training domain to each unseen test domain, while preserving task relevant information. Without using any images from the unseen test domain, we show that over the extended domain containing both training and unseen test domains, LADS outperforms standard fine-tuning and ensemble approaches over a suite of four benchmarks targeting domain adaptation and dataset bias
UCEpic: Unifying Aspect Planning and Lexical Constraints for Explainable Recommendation
Sep 28, 2022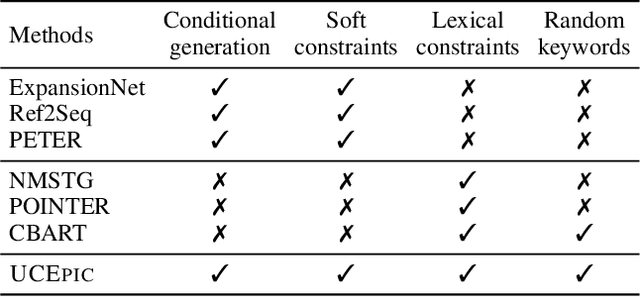
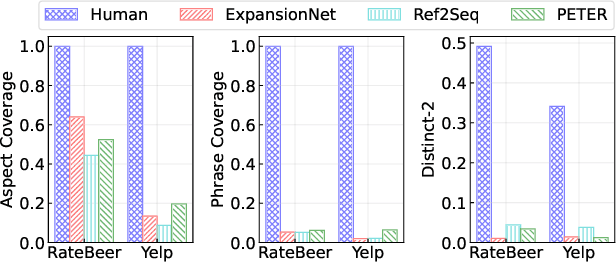
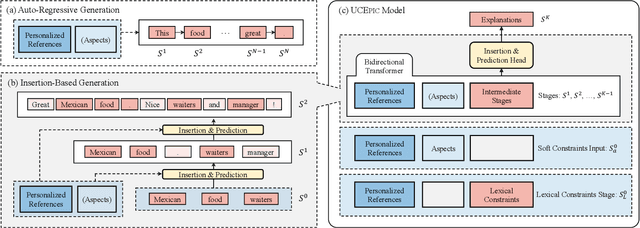

Personalized natural language generation for explainable recommendations plays a key role in justifying why a recommendation might match a user's interests. Existing models usually control the generation process by soft constraints (e.g.,~aspect planning). While promising, these methods struggle to generate specific information correctly, which prevents generated explanations from being informative and diverse. In this paper, we propose UCEpic, an explanation generation model that unifies aspect planning and lexical constraints for controllable personalized generation. Specifically, we first pre-train a non-personalized text generator by our proposed robust insertion process so that the model is able to generate sentences containing lexical constraints. Then, we demonstrate the method of incorporating aspect planning and personalized references into the insertion process to obtain personalized explanations. Compared to previous work controlled by soft constraints, UCEpic incorporates specific information from keyphrases and then largely improves the diversity and informativeness of generated explanations. Extensive experiments on RateBeer and Yelp show that UCEpic can generate high-quality and diverse explanations for recommendations.