 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Surrogate Docking: Accelerating Automated Drug Discovery with Graph Neural Networks
Nov 04, 2022
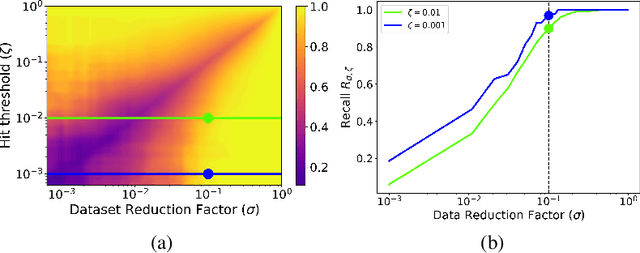
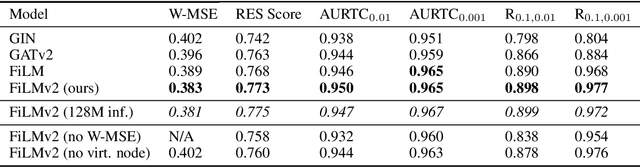
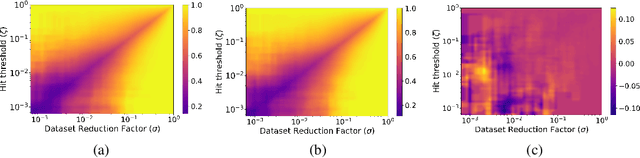

The process of screening molecules for desirable properties is a key step in several applications, ranging from drug discovery to material design. During the process of drug discovery specifically, protein-ligand docking, or chemical docking, is a standard in-silico scoring technique that estimates the binding affinity of molecules with a specific protein target. Recently, however, as the number of virtual molecules available to test has rapidly grown, these classical docking algorithms have created a significant computational bottleneck. We address this problem by introducing Deep Surrogate Docking (DSD), a framework that applies deep learning-based surrogate modeling to accelerate the docking process substantially. DSD can be interpreted as a formalism of several earlier surrogate prefiltering techniques, adding novel metrics and practical training practices. Specifically, we show that graph neural networks (GNNs) can serve as fast and accurate estimators of classical docking algorithms. Additionally, we introduce FiLMv2, a novel GNN architecture which we show outperforms existing state-of-the-art GNN architectures, attaining more accurate and stable performance by allowing the model to filter out irrelevant information from data more efficiently. Through extensive experimentation and analysis, we show that the DSD workflow combined with the FiLMv2 architecture provides a 9.496x speedup in molecule screening with a <3% recall error rate on an example docking task. Our open-source code is available at https://github.com/ryienh/graph-dock.
Towards Real World HDRTV Reconstruction: A Data Synthesis-based Approach
Nov 06, 2022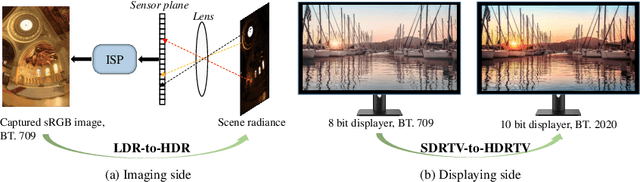
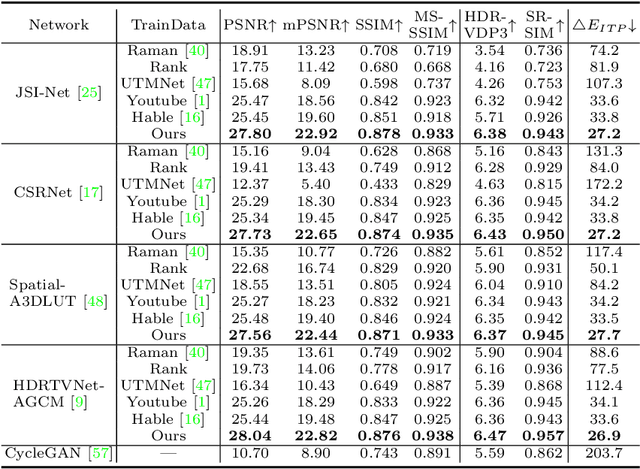


Existing deep learning based HDRTV reconstruction methods assume one kind of tone mapping operators (TMOs) as the degradation procedure to synthesize SDRTV-HDRTV pairs for supervised training. In this paper, we argue that, although traditional TMOs exploit efficient dynamic range compression priors, they have several drawbacks on modeling the realistic degradation: information over-preservation, color bias and possible artifacts, making the trained reconstruction networks hard to generalize well to real-world cases. To solve this problem, we propose a learning-based data synthesis approach to learn the properties of real-world SDRTVs by integrating several tone mapping priors into both network structures and loss functions. In specific, we design a conditioned two-stream network with prior tone mapping results as a guidance to synthesize SDRTVs by both global and local transformations. To train the data synthesis network, we form a novel self-supervised content loss to constraint different aspects of the synthesized SDRTVs at regions with different brightness distributions and an adversarial loss to emphasize the details to be more realistic. To validate the effectiveness of our approach, we synthesize SDRTV-HDRTV pairs with our method and use them to train several HDRTV reconstruction networks. Then we collect two inference datasets containing both labeled and unlabeled real-world SDRTVs, respectively. Experimental results demonstrate that, the networks trained with our synthesized data generalize significantly better to these two real-world datasets than existing solutions.
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Oct 04, 2022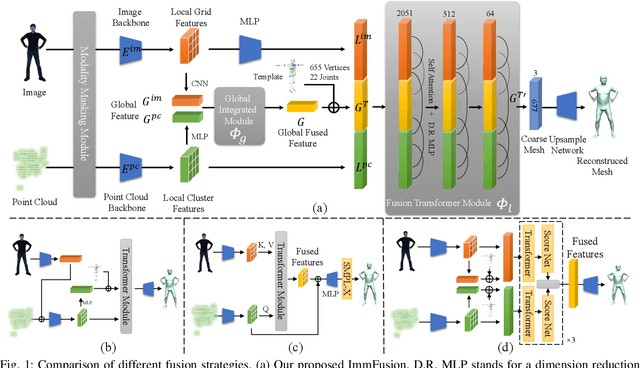
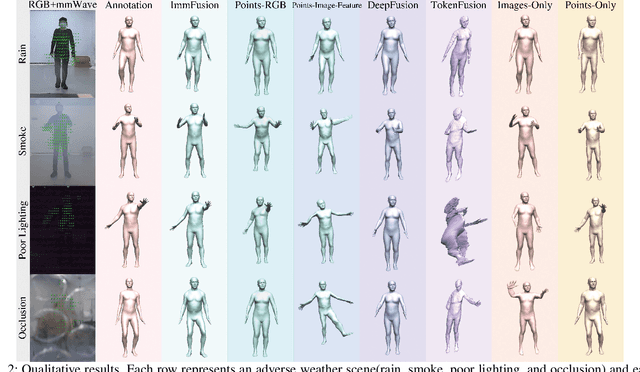


3D human reconstruction from RGB images achieves decent results in good weather conditions but degrades dramatically in rough weather. Complementary, mmWave radars have been employed to reconstruct 3D human joints and meshes in rough weather. However, combining RGB and mmWave signals for robust all-weather 3D human reconstruction is still an open challenge, given the sparse nature of mmWave and the vulnerability of RGB images. In this paper, we present ImmFusion, the first mmWave-RGB fusion solution to reconstruct 3D human bodies in all weather conditions robustly. Specifically, our ImmFusion consists of image and point backbones for token feature extraction and a Transformer module for token fusion. The image and point backbones refine global and local features from original data, and the Fusion Transformer Module aims for effective information fusion of two modalities by dynamically selecting informative tokens. Extensive experiments on a large-scale dataset, mmBody, captured in various environments demonstrate that ImmFusion can efficiently utilize the information of two modalities to achieve a robust 3D human body reconstruction in all weather conditions. In addition, our method's accuracy is significantly superior to that of state-of-the-art Transformer-based LiDAR-camera fusion methods.
Behavioral graph fraud detection in E-commerce
Oct 13, 2022

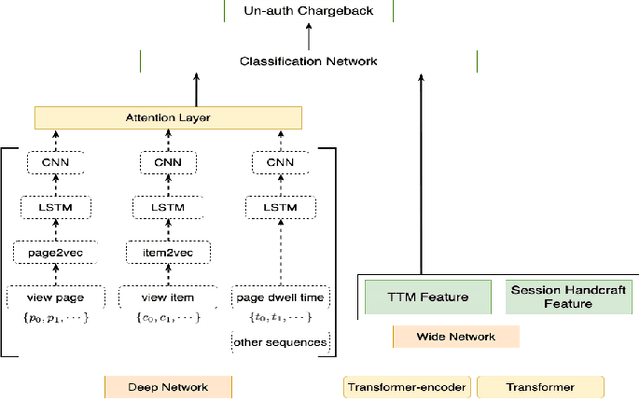
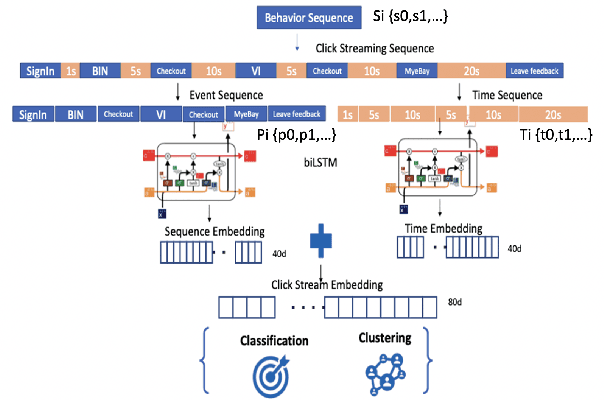
In e-commerce industry, graph neural network methods are the new trends for transaction risk modeling.The power of graph algorithms lie in the capability to catch transaction linking network information, which is very hard to be captured by other algorithms.However, in most existing approaches, transaction or user connections are defined by hard link strategies on shared properties, such as same credit card, same device, same ip address, same shipping address, etc. Those types of strategies will result in sparse linkages by entities with strong identification characteristics (ie. device) and over-linkages by entities that could be widely shared (ie. ip address), making it more difficult to learn useful information from graph. To address aforementioned problems, we present a novel behavioral biometric based method to establish transaction linkings based on user behavioral similarities, then train an unsupervised GNN to extract embedding features for downstream fraud prediction tasks. To our knowledge, this is the first time similarity based soft link has been used in graph embedding applications. To speed up similarity calculation, we apply an in-house GPU based HDBSCAN clustering method to remove highly concentrated and isolated nodes before graph construction. Our experiments show that embedding features learned from similarity based behavioral graph have achieved significant performance increase to the baseline fraud detection model in various business scenarios. In new guest buyer transaction scenario, this segment is a challenge for traditional method, we can make precision increase from 0.82 to 0.86 at the same recall of 0.27, which means we can decrease false positive rate using this method.
Fairness Reprogramming
Sep 21, 2022
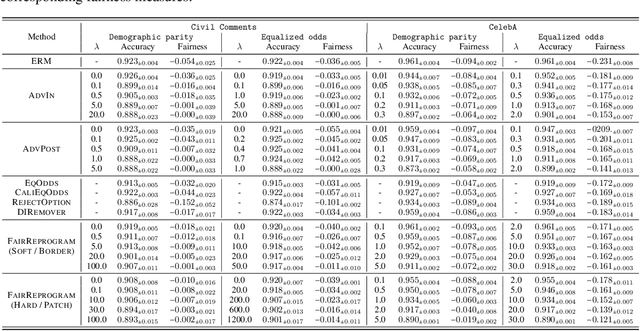
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.
Cyber-resilience for marine navigation by information fusion and change detection
Feb 01, 2022


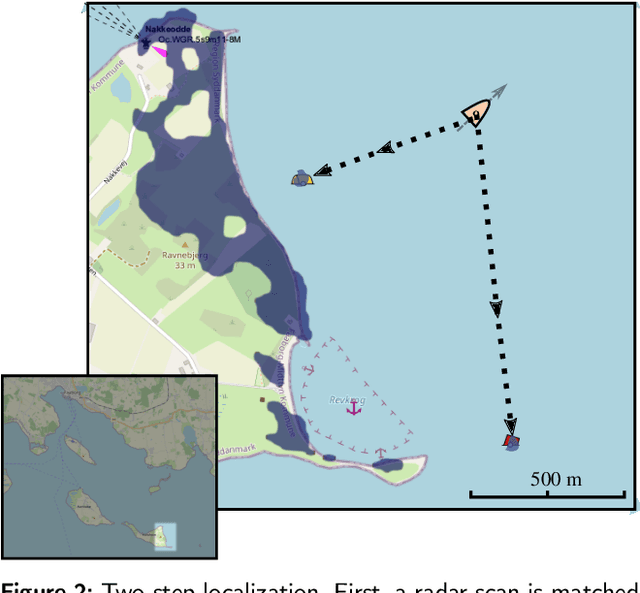
Cyber-resilience is an increasing concern in developing autonomous navigation solutions for marine vessels. This paper scrutinizes cyber-resilience properties of marine navigation through a prism with three edges: multiple sensor information fusion, diagnosis of not-normal behaviours, and change detection. It proposes a two-stage estimator for diagnosis and mitigation of sensor signals used for coastal navigation. Developing a Likelihood Field approach, a first stage extracts shoreline features from radar and matches them to the electronic navigation chart. A second stage associates buoy and beacon features from the radar with chart information. Using real data logged at sea tests combined with simulated spoofing, the paper verifies the ability to timely diagnose and isolate an attempt to compromise position measurements. A new approach is suggested for high level processing of received data to evaluate their consistency, that is agnostic to the underlying technology of the individual sensory input. A combined parametric Gaussian modelling and Kernel Density Estimation is suggested and compared with a generalized likelihood ratio change detector that uses sliding windows. The paper shows how deviations from nominal behaviour and isolation of the components is possible when under attack or when defects in sensors occur.
An Adaptive Threshold for the Canny Edge Detection with Actor-Critic Algorithm
Sep 19, 2022


Visual surveillance aims to perform robust foreground object detection regardless of the time and place. Object detection shows good results using only spatial information, but foreground object detection in visual surveillance requires proper temporal and spatial information processing. In deep learning-based foreground object detection algorithms, the detection ability is superior to classical background subtraction (BGS) algorithms in an environment similar to training. However, the performance is lower than that of the classical BGS algorithm in the environment different from training. This paper proposes a spatio-temporal fusion network (STFN) that could extract temporal and spatial information using a temporal network and a spatial network. We suggest a method using a semi-foreground map for stable training of the proposed STFN. The proposed algorithm shows excellent performance in an environment different from training, and we show it through experiments with various public datasets. Also, STFN can generate a compliant background image in a semi-supervised method, and it can operate in real-time on a desktop with GPU. The proposed method shows 11.28% and 18.33% higher FM than the latest deep learning method in the LASIESTA and SBI dataset, respectively.
LAB: Learnable Activation Binarizer for Binary Neural Networks
Oct 25, 2022

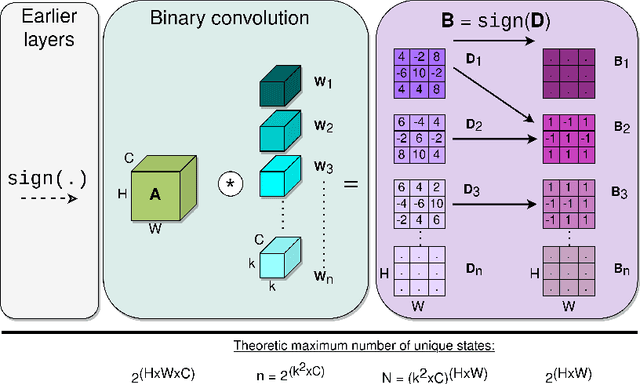
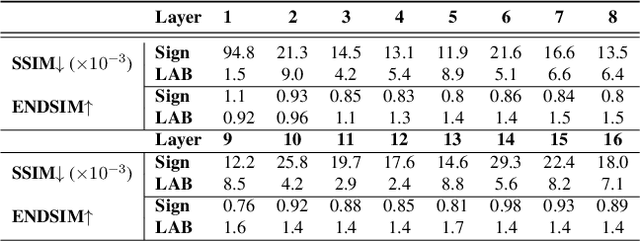
Binary Neural Networks (BNNs) are receiving an upsurge of attention for bringing power-hungry deep learning towards edge devices. The traditional wisdom in this space is to employ sign() for binarizing featuremaps. We argue and illustrate that sign() is a uniqueness bottleneck, limiting information propagation throughout the network. To alleviate this, we propose to dispense sign(), replacing it with a learnable activation binarizer (LAB), allowing the network to learn a fine-grained binarization kernel per layer - as opposed to global thresholding. LAB is a novel universal module that can seamlessly be integrated into existing architectures. To confirm this, we plug it into four seminal BNNs and show a considerable performance boost at the cost of tolerable increase in delay and complexity. Finally, we build an end-to-end BNN (coined as LAB-BNN) around LAB, and demonstrate that it achieves competitive performance on par with the state-of-the-art on ImageNet.
A Survey on Fundamental Concepts and Practical Challenges of Hyperspectral images
Oct 25, 2022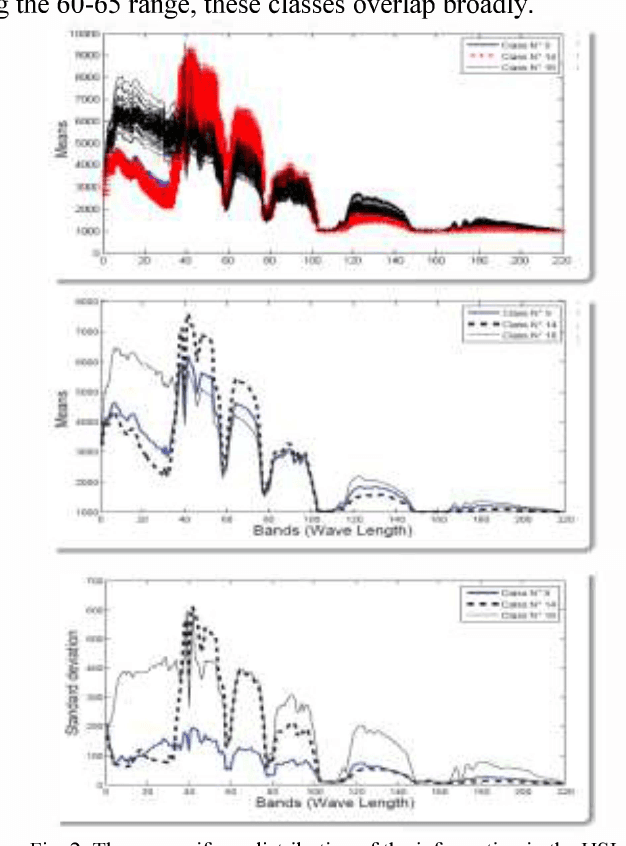
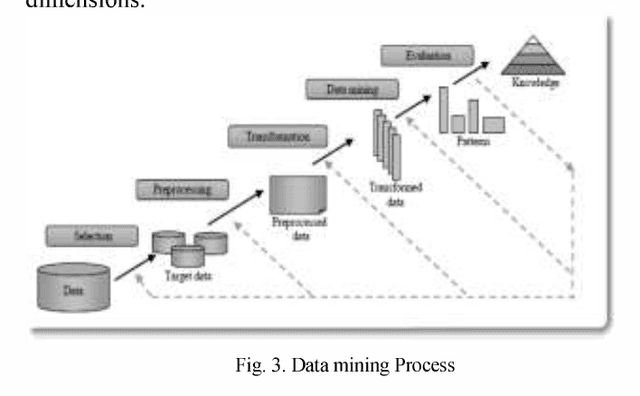

The Remote sensing provides a synoptic view of land by detecting the energy reflected from Earth's surface. The Hyperspectral images (HSI) use perfect sensors that extract more than a hundred of images, with more detailed information than using traditional Multispectral data. In this paper, we aim to study this aspect of communication in the case of passive reception. First, a brief overview of acquisition process and treatment of Hyperspectral images is provided. Then, we explain representation spaces and the various analysis methods of these images. Furthermore, the factors influencing this analysis are investigated and some applications, in this area, are presented. Finally, we explain the relationship between Hyperspectral images and Datamining and we outline the open issues related to this area. So we consider the case study: HSI AVIRIS 92AV3C. This study serves as map of route for integrating classification methods in the higher dimensionality data. Keywords-component: Hyperspectral images, Passive Sensing,Classification, Data mining.
An IoT Cloud and Big Data Architecture for the Maintenance of Home Appliances
Oct 25, 2022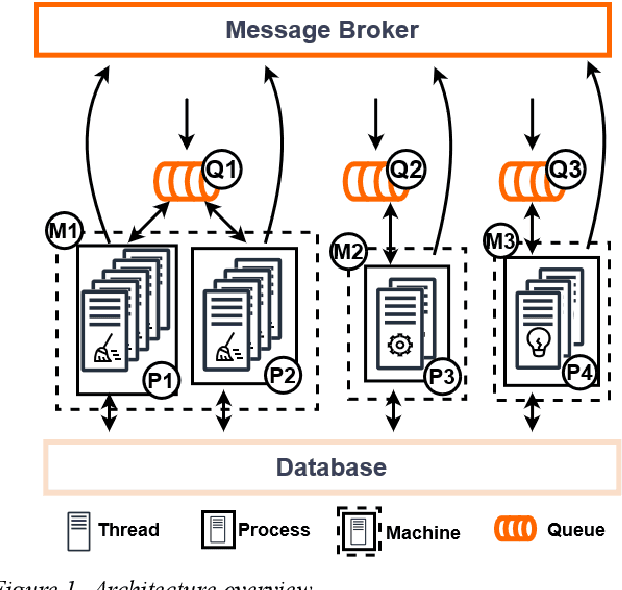
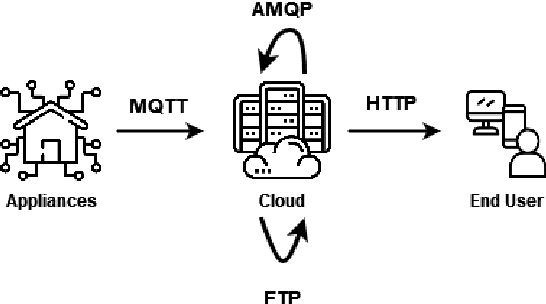
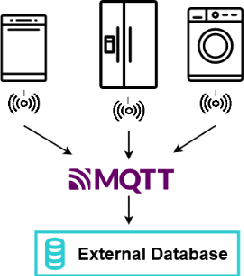
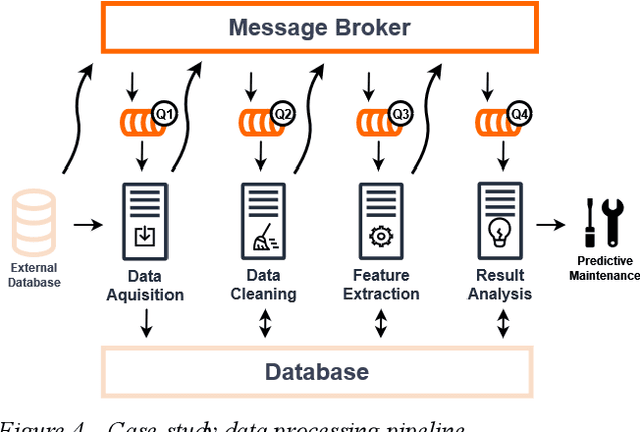
Billions of interconnected Internet of Things (IoT) sensors and devices collect tremendous amounts of data from real-world scenarios. Big data is generating increasing interest in a wide range of industries. Once data is analyzed through compute-intensive Machine Learning (ML) methods, it can derive critical business value for organizations. Powerfulplatforms are essential to handle and process such massive collections of information cost-effectively and conveniently. This work introduces a distributed and scalable platform architecture that can be deployed for efficient real-world big data collection and analytics. The proposed system was tested with a case study for Predictive Maintenance of Home Appliances, where current and vibration sensors with high acquisition frequency were connected to washing machines and refrigerators. The introduced platform was used to collect, store, and analyze the data. The experimental results demonstrated that the presented system could be advantageous for tackling real-world IoT scenarios in a cost-effective and local approach.