 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-agent Communication with Graph Information Bottleneck under Limited Bandwidth
Dec 29, 2021
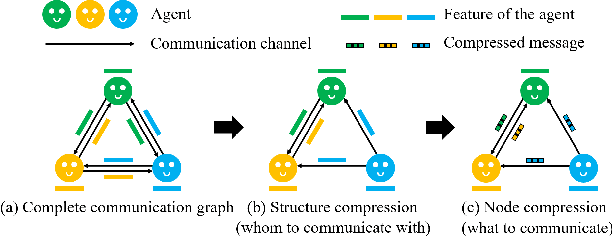
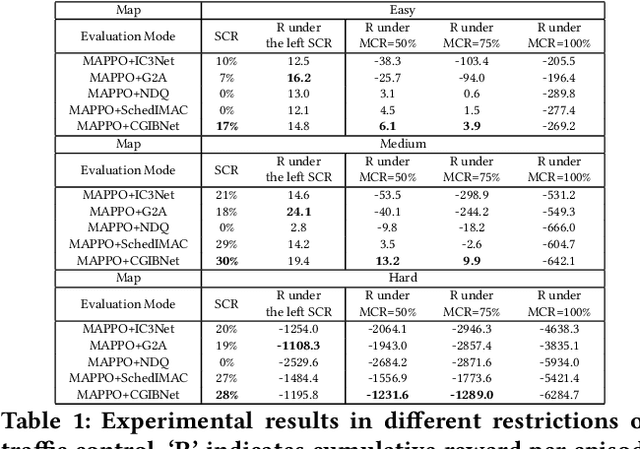
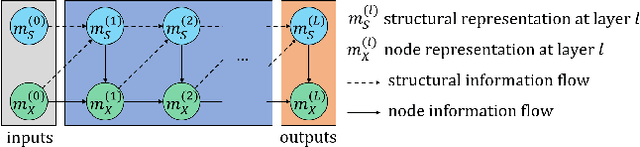
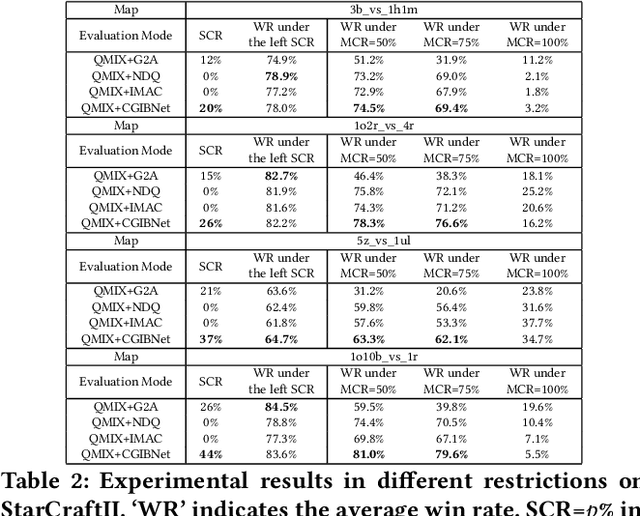
Recent studies have shown that introducing communication between agents can significantly improve overall performance in cooperative Multi-agent reinforcement learning (MARL). In many real-world scenarios, communication can be expensive and the bandwidth of the multi-agent system is subject to certain constraints. Redundant messages who occupy the communication resources can block the transmission of informative messages and thus jeopardize the performance. In this paper, we aim to learn the minimal sufficient communication messages. First, we initiate the communication between agents by a complete graph. Then we introduce the graph information bottleneck (GIB) principle into this complete graph and derive the optimization over graph structures. Based on the optimization, a novel multi-agent communication module, called CommGIB, is proposed, which effectively compresses the structure information and node information in the communication graph to deal with bandwidth-constrained settings. Extensive experiments in Traffic Control and StanCraft II are conducted. The results indicate that the proposed methods can achieve better performance in bandwidth-restricted settings compared with state-of-the-art algorithms, with especially large margins in large-scale multi-agent tasks.
PhysioGait: Context-Aware Physiological Context Modeling for Person Re-identification Attack on Wearable Sensing
Oct 30, 2022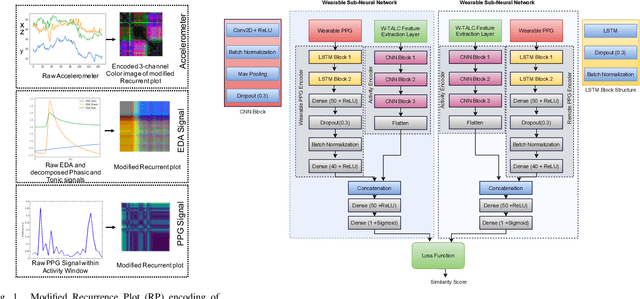
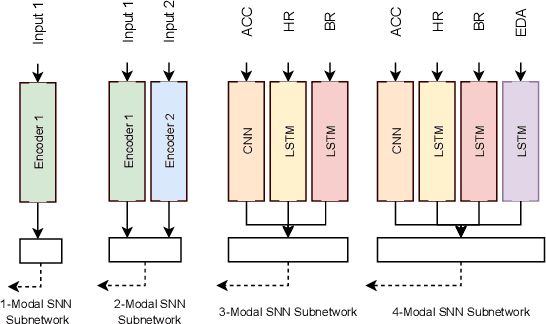
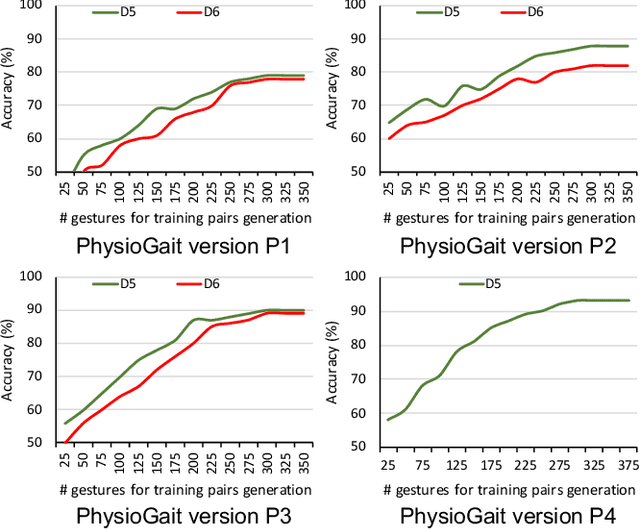
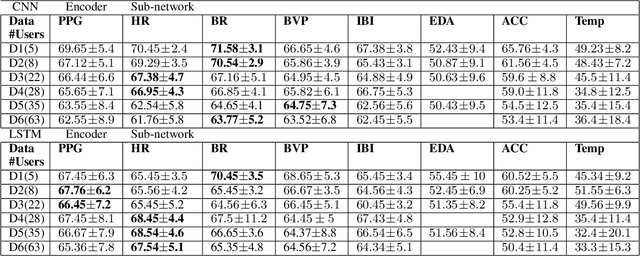
Person re-identification is a critical privacy breach in publicly shared healthcare data. We investigate the possibility of a new type of privacy threat on publicly shared privacy insensitive large scale wearable sensing data. In this paper, we investigate user specific biometric signatures in terms of two contextual biometric traits, physiological (photoplethysmography and electrodermal activity) and physical (accelerometer) contexts. In this regard, we propose PhysioGait, a context-aware physiological signal model that consists of a Multi-Modal Siamese Convolutional Neural Network (mmSNN) which learns the spatial and temporal information individually and performs sensor fusion in a Siamese cost with the objective of predicting a person's identity. We evaluated PhysioGait attack model using 4 real-time collected datasets (3-data under IRB #HP-00064387 and one publicly available data) and two combined datasets achieving 89% - 93% accuracy of re-identifying persons.
* Accepted in IEEE MSN 2022. arXiv admin note: substantial text overlap with arXiv:2106.11900
Zero-Shot On-the-Fly Event Schema Induction
Oct 12, 2022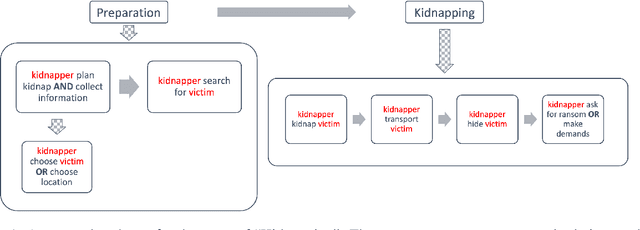
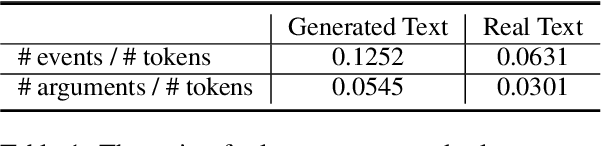

What are the events involved in a pandemic outbreak? What steps should be taken when planning a wedding? The answers to these questions can be found by collecting many documents on the complex event of interest, extracting relevant information, and analyzing it. We present a new approach in which large language models are utilized to generate source documents that allow predicting, given a high-level event definition, the specific events, arguments, and relations between them to construct a schema that describes the complex event in its entirety. Using our model, complete schemas on any topic can be generated on-the-fly without any manual data collection, i.e., in a zero-shot manner. Moreover, we develop efficient methods to extract pertinent information from texts and demonstrate in a series of experiments that these schemas are considered to be more complete than human-curated ones in the majority of examined scenarios. Finally, we show that this framework is comparable in performance with previous supervised schema induction methods that rely on collecting real texts while being more general and flexible without the need for a predefined ontology.
Global Spectral Filter Memory Network for Video Object Segmentation
Oct 12, 2022
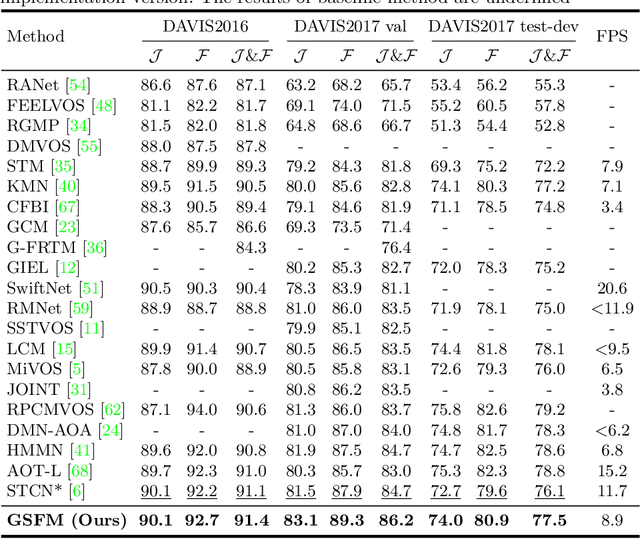

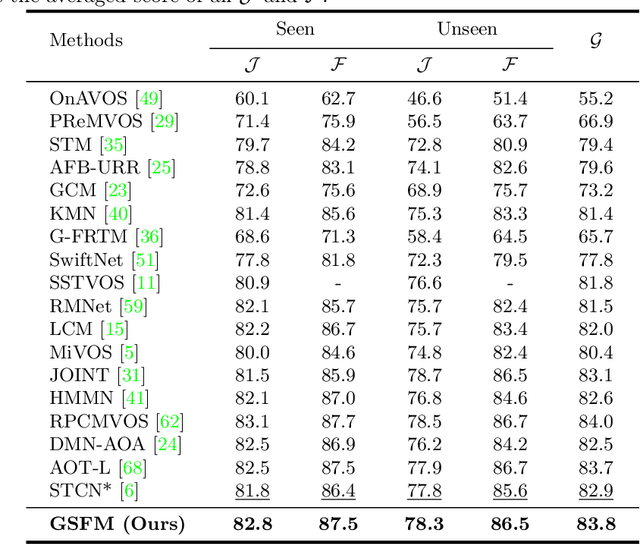
This paper studies semi-supervised video object segmentation through boosting intra-frame interaction. Recent memory network-based methods focus on exploiting inter-frame temporal reference while paying little attention to intra-frame spatial dependency. Specifically, these segmentation model tends to be susceptible to interference from unrelated nontarget objects in a certain frame. To this end, we propose Global Spectral Filter Memory network (GSFM), which improves intra-frame interaction through learning long-term spatial dependencies in the spectral domain. The key components of GSFM is 2D (inverse) discrete Fourier transform for spatial information mixing. Besides, we empirically find low frequency feature should be enhanced in encoder (backbone) while high frequency for decoder (segmentation head). We attribute this to semantic information extracting role for encoder and fine-grained details highlighting role for decoder. Thus, Low (High) Frequency Module is proposed to fit this circumstance. Extensive experiments on the popular DAVIS and YouTube-VOS benchmarks demonstrate that GSFM noticeably outperforms the baseline method and achieves state-of-the-art performance. Besides, extensive analysis shows that the proposed modules are reasonable and of great generalization ability. Our source code is available at https://github.com/workforai/GSFM.
Blessing from Experts: Super Reinforcement Learning in Confounded Environments
Sep 29, 2022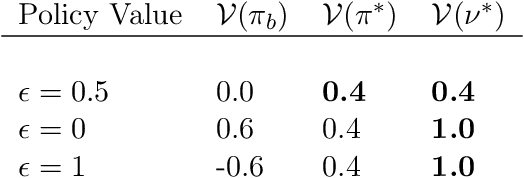
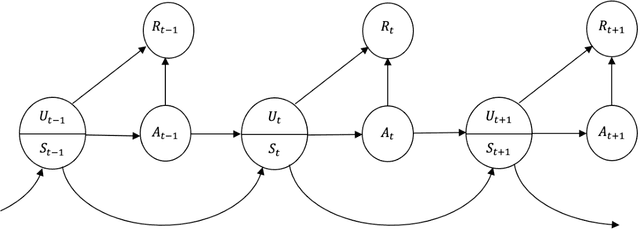
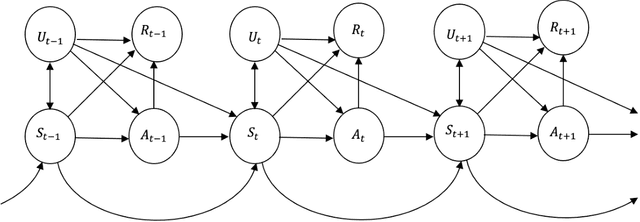
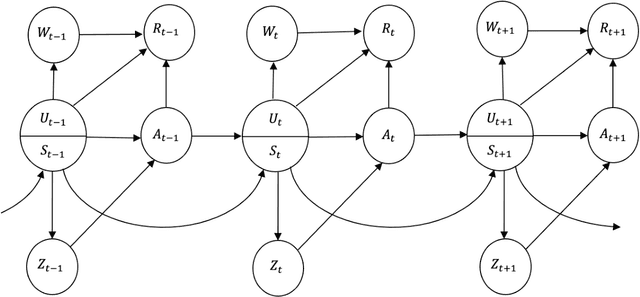
We introduce super reinforcement learning in the batch setting, which takes the observed action as input for enhanced policy learning. In the presence of unmeasured confounders, the recommendations from human experts recorded in the observed data allow us to recover certain unobserved information. Including this information in the policy search, the proposed super reinforcement learning will yield a super-policy that is guaranteed to outperform both the standard optimal policy and the behavior one (e.g., the expert's recommendation). Furthermore, to address the issue of unmeasured confounding in finding super-policies, a number of non-parametric identification results are established. Finally, we develop two super-policy learning algorithms and derive their corresponding finite-sample regret guarantees.
Symmetry and Variance: Generative Parametric Modelling of Historical Brick Wall Patterns
Oct 23, 2022
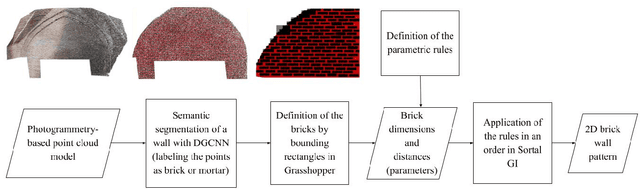

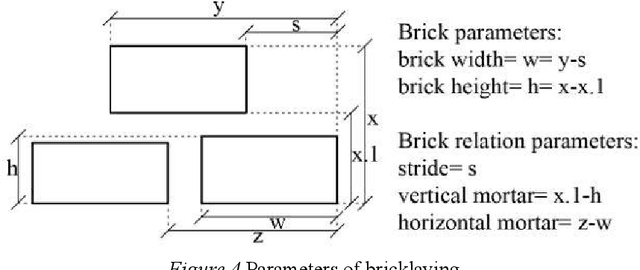
This study integrates artificial intelligence and computational design tools to extract information from architectural heritage. Photogrammetry-based point cloud models of brick walls from the Anatolian Seljuk period are analysed in terms of the interrelated units of construction, simultaneously considering both the inherent symmetries and irregularities. The real-world data is used as input for acquiring the stochastic parameters of spatial relations and a set of parametric shape rules to recreate designs of existing and hypothetical brick walls within the style. The motivation is to be able to generate large data sets for machine learning of the style and to devise procedures for robotic production of such designs with repetitive units.
* 10 pages, 7 Figures. This paper is published at "Symmetry: Art and Science | 12th SIS-Symmetry Congress"
Compressed Gastric Image Generation Based on Soft-Label Dataset Distillation for Medical Data Sharing
Sep 29, 2022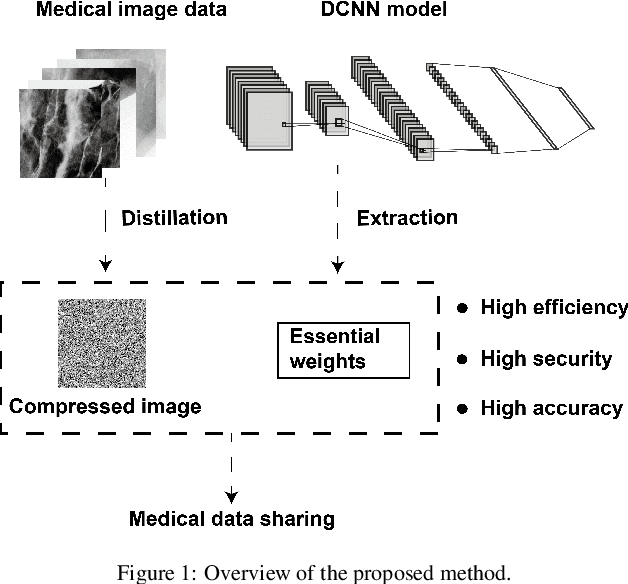
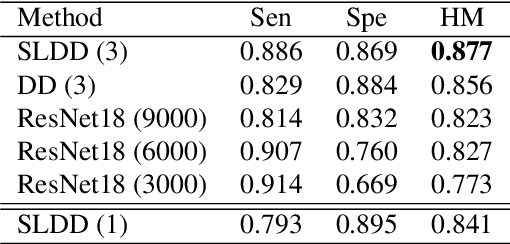
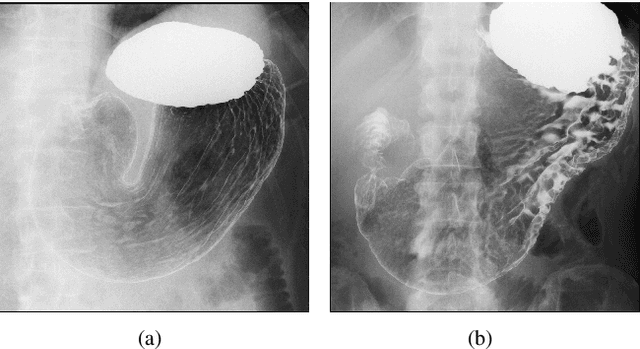
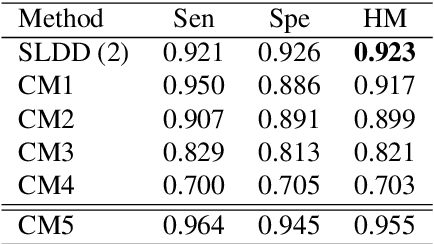
Background and objective: Sharing of medical data is required to enable the cross-agency flow of healthcare information and construct high-accuracy computer-aided diagnosis systems. However, the large sizes of medical datasets, the massive amount of memory of saved deep convolutional neural network (DCNN) models, and patients' privacy protection are problems that can lead to inefficient medical data sharing. Therefore, this study proposes a novel soft-label dataset distillation method for medical data sharing. Methods: The proposed method distills valid information of medical image data and generates several compressed images with different data distributions for anonymous medical data sharing. Furthermore, our method can extract essential weights of DCNN models to reduce the memory required to save trained models for efficient medical data sharing. Results: The proposed method can compress tens of thousands of images into several soft-label images and reduce the size of a trained model to a few hundredths of its original size. The compressed images obtained after distillation have been visually anonymized; therefore, they do not contain the private information of the patients. Furthermore, we can realize high-detection performance with a small number of compressed images. Conclusions: The experimental results show that the proposed method can improve the efficiency and security of medical data sharing.
Personalized Federated Learning with Server-Side Information
May 23, 2022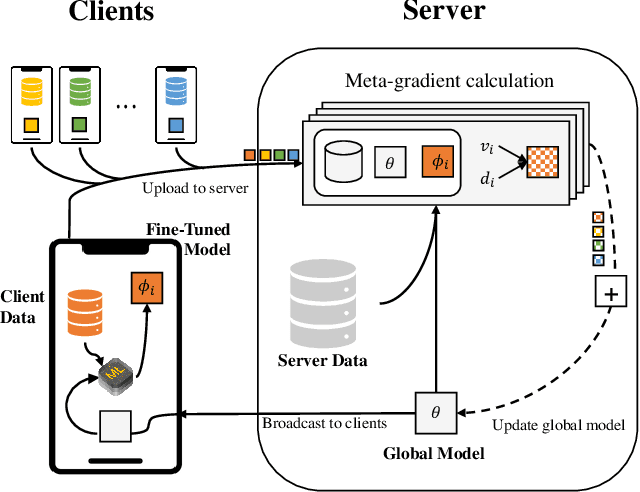
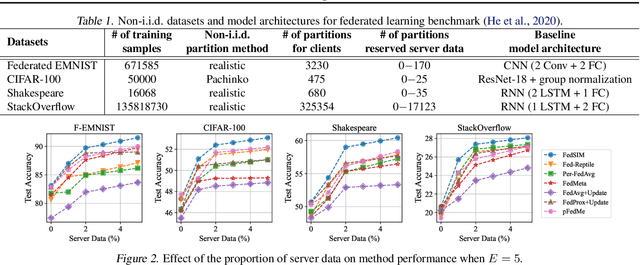
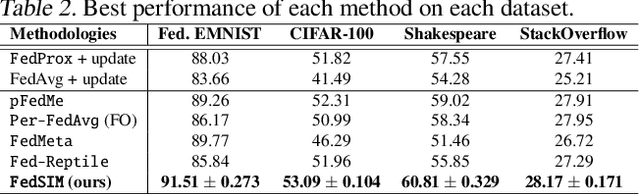
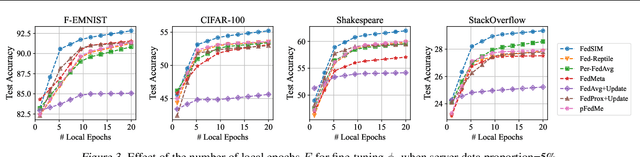
Personalized Federated Learning (FL) is an emerging research field in FL that learns an easily adaptable global model in the presence of data heterogeneity among clients. However, one of the main challenges for personalized FL is the heavy reliance on clients' computing resources to calculate higher-order gradients since client data is segregated from the server to ensure privacy. To resolve this, we focus on a problem setting where the server may possess its own data independent of clients' data -- a prevalent problem setting in various applications, yet relatively unexplored in existing literature. Specifically, we propose FedSIM, a new method for personalized FL that actively utilizes such server data to improve meta-gradient calculation in the server for increased personalization performance. Experimentally, we demonstrate through various benchmarks and ablations that FedSIM is superior to existing methods in terms of accuracy, more computationally efficient by calculating the full meta-gradients in the server, and converges up to 34.2% faster.
GFlowOut: Dropout with Generative Flow Networks
Nov 07, 2022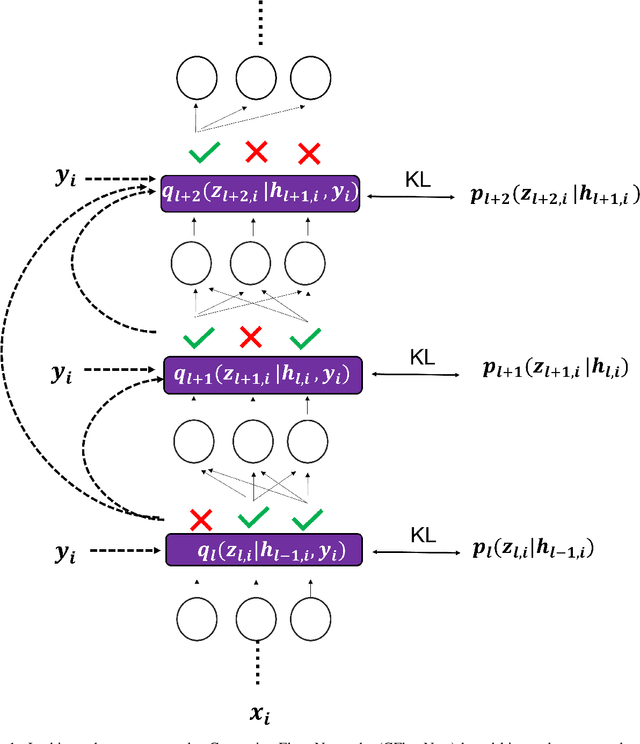
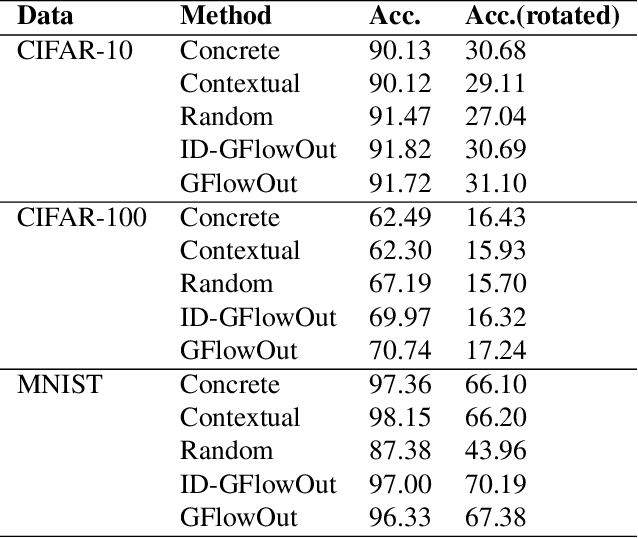
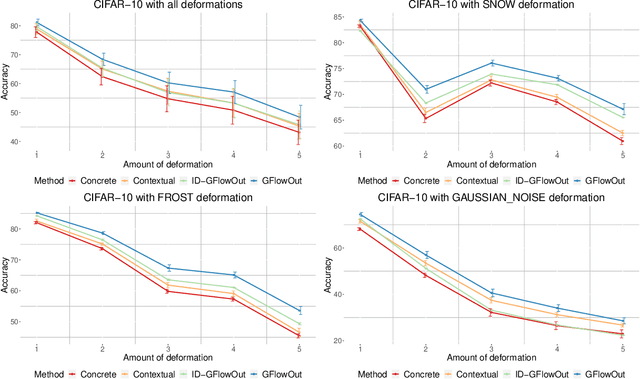
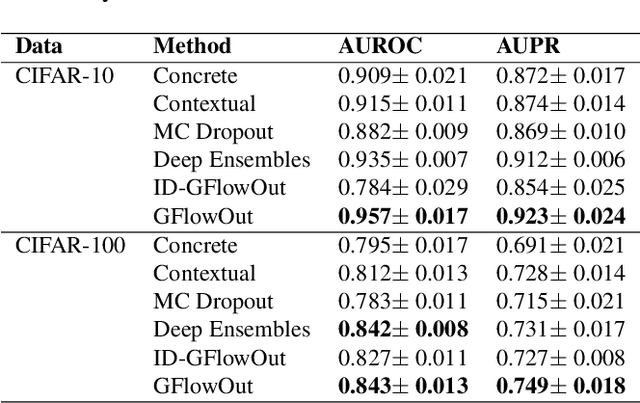
Bayesian Inference offers principled tools to tackle many critical problems with modern neural networks such as poor calibration and generalization, and data inefficiency. However, scaling Bayesian inference to large architectures is challenging and requires restrictive approximations. Monte Carlo Dropout has been widely used as a relatively cheap way for approximate Inference and to estimate uncertainty with deep neural networks. Traditionally, the dropout mask is sampled independently from a fixed distribution. Recent works show that the dropout mask can be viewed as a latent variable, which can be inferred with variational inference. These methods face two important challenges: (a) the posterior distribution over masks can be highly multi-modal which can be difficult to approximate with standard variational inference and (b) it is not trivial to fully utilize sample-dependent information and correlation among dropout masks to improve posterior estimation. In this work, we propose GFlowOut to address these issues. GFlowOut leverages the recently proposed probabilistic framework of Generative Flow Networks (GFlowNets) to learn the posterior distribution over dropout masks. We empirically demonstrate that GFlowOut results in predictive distributions that generalize better to out-of-distribution data, and provide uncertainty estimates which lead to better performance in downstream tasks.
Zero-Shot Classification by Logical Reasoning on Natural Language Explanations
Nov 07, 2022
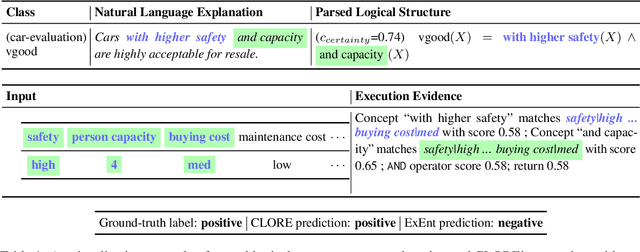
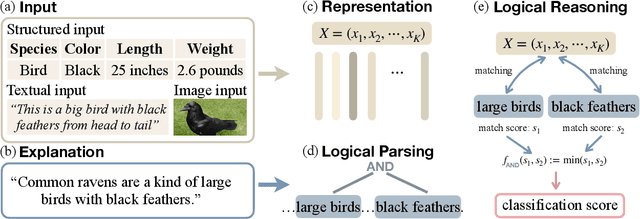
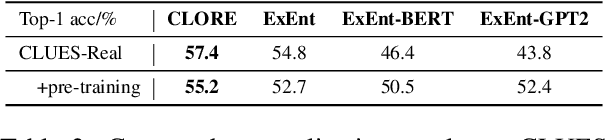
Humans can classify an unseen category by reasoning on its language explanations. This ability is owing to the compositional nature of language: we can combine previously seen concepts to describe the new category. For example, we might describe mavens as "a kind of large birds with black feathers", so that others can use their knowledge of concepts "large birds" and "black feathers" to recognize a maven. Inspired by this observation, in this work we tackle zero-shot classification task by logically parsing and reasoning on natural language explanations. To this end, we propose the framework CLORE (Classification by LOgical Reasoning on Explanations). While previous methods usually regard textual information as implicit features, CLORE parses the explanations into logical structure the and then reasons along this structure on the input to produce a classification score. Experimental results on explanation-based zero-shot classification benchmarks demonstrate that CLORE is superior to baselines, mainly because it performs better on tasks requiring more logical reasoning. Alongside classification decisions, CLORE can provide the logical parsing and reasoning process as a form of rationale. Through empirical analysis we demonstrate that CLORE is also less affected by linguistic biases than baselines.