 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-Shot Learning for Biometric Verification
Nov 12, 2022

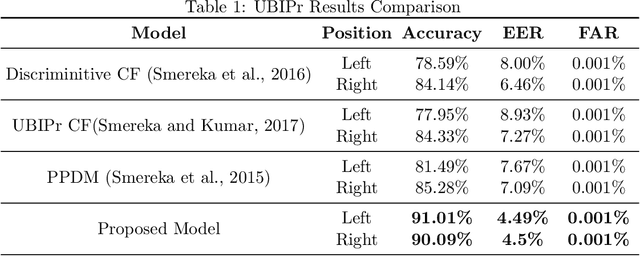
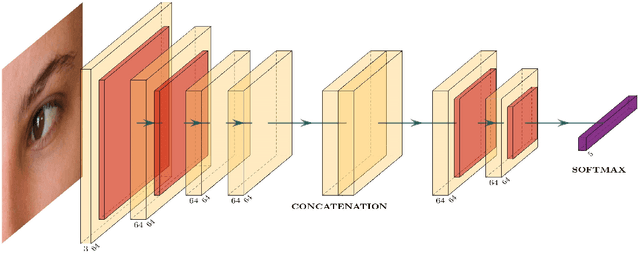
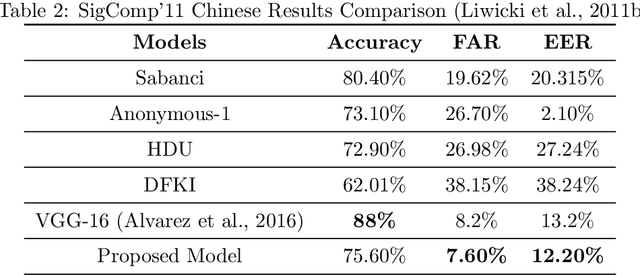
In machine learning applications, it is common practice to feed as much information as possible. In most cases, the model can handle large data sets that allow to predict more accurately. In the presence of data scarcity, a Few-Shot learning (FSL) approach aims to build more accurate algorithms with limited training data. We propose a novel end-to-end lightweight architecture that verifies biometric data by producing competitive results as compared to state-of-the-art accuracies through Few-Shot learning methods. The dense layers add to the complexity of state-of-the-art deep learning models which inhibits them to be used in low-power applications. In presented approach, a shallow network is coupled with a conventional machine learning technique that exploits hand-crafted features to verify biometric images from multi-modal sources such as signatures, periocular region, iris, face, fingerprints etc. We introduce a self-estimated threshold that strictly monitors False Acceptance Rate (FAR) while generalizing its results hence eliminating user-defined thresholds from ROC curves that are likely to be biased on local data distribution. This hybrid model benefits from few-shot learning to make up for scarcity of data in biometric use-cases. We have conducted extensive experimentation with commonly used biometric datasets. The obtained results provided an effective solution for biometric verification systems.
Small Language Models for Tabular Data
Nov 05, 2022

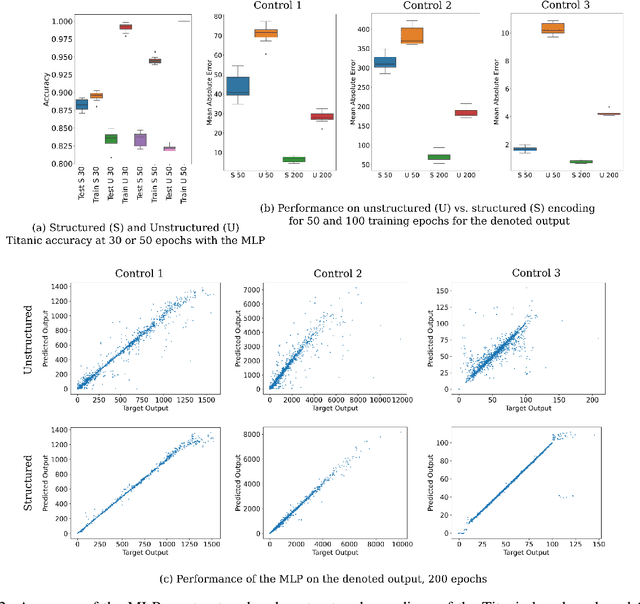
Supervised deep learning is most commonly applied to difficult problems defined on large and often extensively curated datasets. Here we demonstrate the ability of deep representation learning to address problems of classification and regression from small and poorly formed tabular datasets by encoding input information as abstracted sequences composed of a fixed number of characters per input field. We find that small models have sufficient capacity for approximation of various functions and achieve record classification benchmark accuracy. Such models are shown to form useful embeddings of various input features in their hidden layers, even if the learned task does not explicitly require knowledge of those features. These models are also amenable to input attribution, allowing for an estimation of the importance of each input element to the model output as well as of which inputs features are effectively embedded in the model. We present a proof-of-concept for the application of small language models to mixed tabular data without explicit feature engineering, cleaning, or preprocessing, relying on the model to perform these tasks as part of the representation learning process.
Quantization Adaptor for Bit-Level Deep Learning-Based Massive MIMO CSI Feedback
Nov 05, 2022
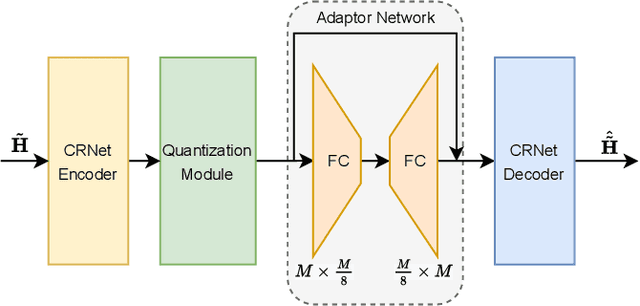
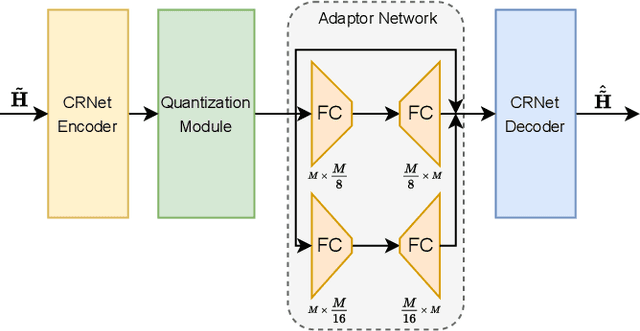
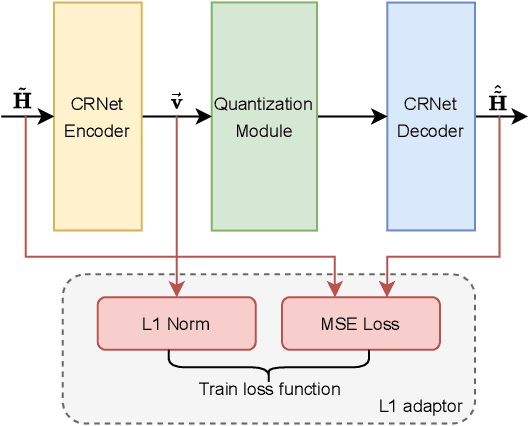
In massive multiple-input multiple-output (MIMO) systems, the user equipment (UE) needs to feed the channel state information (CSI) back to the base station (BS) for the following beamforming. But the large scale of antennas in massive MIMO systems causes huge feedback overhead. Deep learning (DL) based methods can compress the CSI at the UE and recover it at the BS, which reduces the feedback cost significantly. But the compressed CSI must be quantized into bit streams for transmission. In this paper, we propose an adaptor-assisted quantization strategy for bit-level DL-based CSI feedback. First, we design a network-aided adaptor and an advanced training scheme to adaptively improve the quantization and reconstruction accuracy. Moreover, for easy practical employment, we introduce the expert knowledge of data distribution and propose a pluggable and cost-free adaptor scheme. Experiments show that compared with the state-of-the-art feedback quantization method, this adaptor-aided quantization strategy can achieve better quantization accuracy and reconstruction performance with less or no additional cost. The open-source codes are available at https://github.com/zhangxd18/QCRNet.
Video Event Extraction via Tracking Visual States of Arguments
Nov 05, 2022
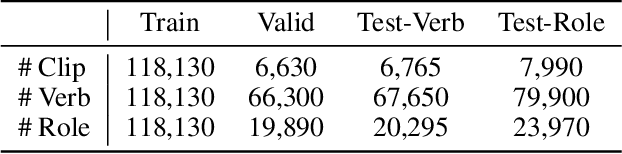

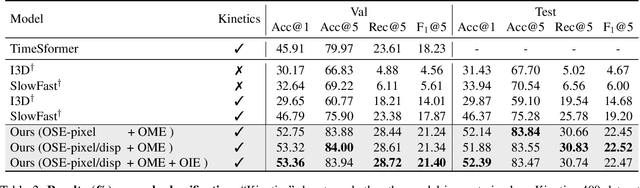
Video event extraction aims to detect salient events from a video and identify the arguments for each event as well as their semantic roles. Existing methods focus on capturing the overall visual scene of each frame, ignoring fine-grained argument-level information. Inspired by the definition of events as changes of states, we propose a novel framework to detect video events by tracking the changes in the visual states of all involved arguments, which are expected to provide the most informative evidence for the extraction of video events. In order to capture the visual state changes of arguments, we decompose them into changes in pixels within objects, displacements of objects, and interactions among multiple arguments. We further propose Object State Embedding, Object Motion-aware Embedding and Argument Interaction Embedding to encode and track these changes respectively. Experiments on various video event extraction tasks demonstrate significant improvements compared to state-of-the-art models. In particular, on verb classification, we achieve 3.49% absolute gains (19.53% relative gains) in F1@5 on Video Situation Recognition.
Efficient few-shot learning for pixel-precise handwritten document layout analysis
Oct 27, 2022



Layout analysis is a task of uttermost importance in ancient handwritten document analysis and represents a fundamental step toward the simplification of subsequent tasks such as optical character recognition and automatic transcription. However, many of the approaches adopted to solve this problem rely on a fully supervised learning paradigm. While these systems achieve very good performance on this task, the drawback is that pixel-precise text labeling of the entire training set is a very time-consuming process, which makes this type of information rarely available in a real-world scenario. In the present paper, we address this problem by proposing an efficient few-shot learning framework that achieves performances comparable to current state-of-the-art fully supervised methods on the publicly available DIVA-HisDB dataset.
Model Order Selection with Variational Autoencoding
Oct 27, 2022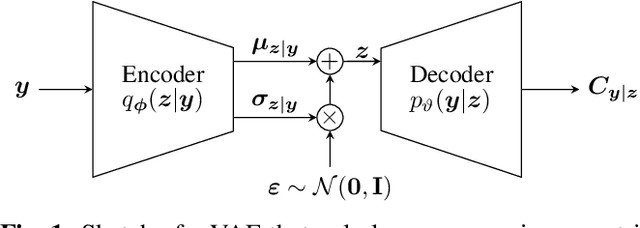
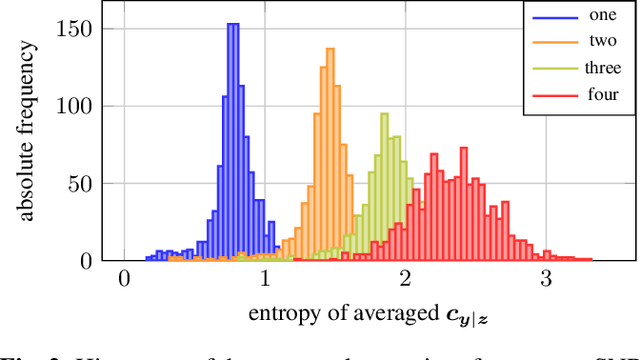
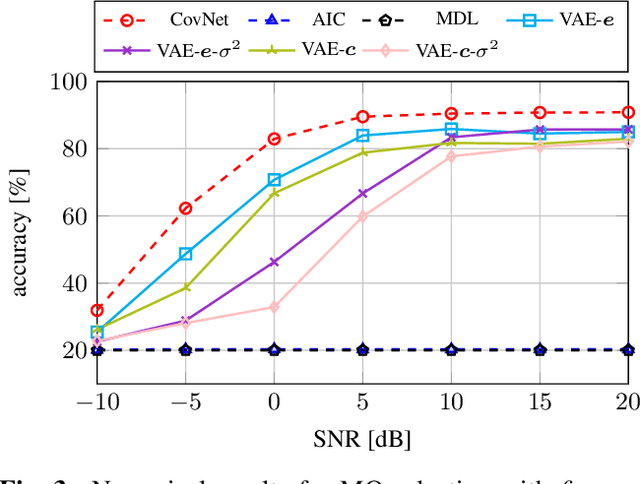
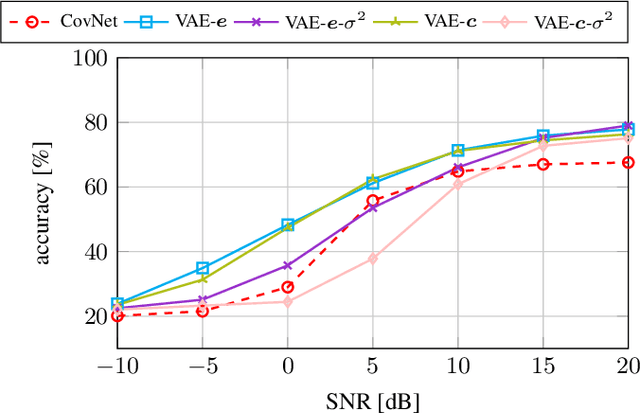
Classical methods for model order selection often fail in scenarios with low SNR or few snapshots. Deep learning based methods are promising alternatives for such challenging situations as they compensate lack of information in observations with repeated training on large datasets. This manuscript proposes an approach that uses a variational autoencoder (VAE) for model order selection. The idea is to learn a parameterized conditional covariance matrix at the VAE decoder that approximates the true signal covariance matrix. The method itself is unsupervised and only requires a small representative dataset for calibration purposes after training of the VAE. Numerical simulations show that the proposed method clearly outperforms classical methods and even reaches or beats a supervised approach depending on the considered snapshots.
Disentangled and Robust Representation Learning for Bragging Classification in Social Media
Oct 27, 2022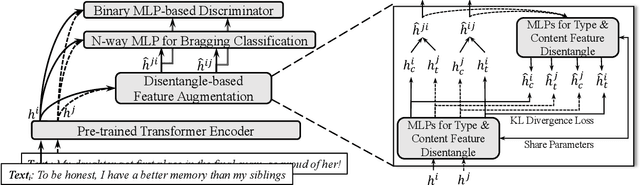
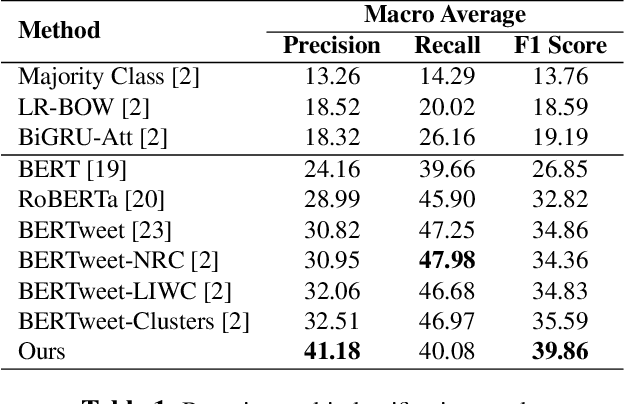
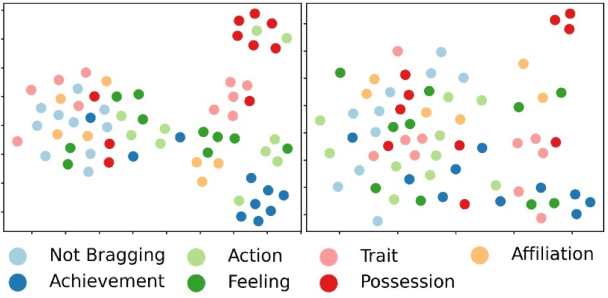
Researching bragging behavior on social media arouses interest of computational (socio) linguists. However, existing bragging classification datasets suffer from a serious data imbalance issue. Because labeling a data-balance dataset is expensive, most methods introduce external knowledge to improve model learning. Nevertheless, such methods inevitably introduce noise and non-relevance information from external knowledge. To overcome the drawback, we propose a novel bragging classification method with disentangle-based representation augmentation and domain-aware adversarial strategy. Specifically, model learns to disentangle and reconstruct representation and generate augmented features via disentangle-based representation augmentation. Moreover, domain-aware adversarial strategy aims to constrain domain of augmented features to improve their robustness. Experimental results demonstrate that our method achieves state-of-the-art performance compared to other methods.
Pixel-Aligned Non-parametric Hand Mesh Reconstruction
Oct 17, 2022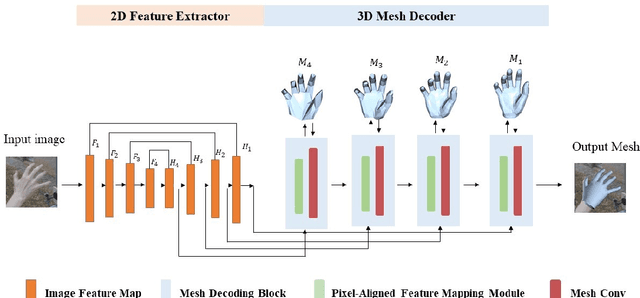
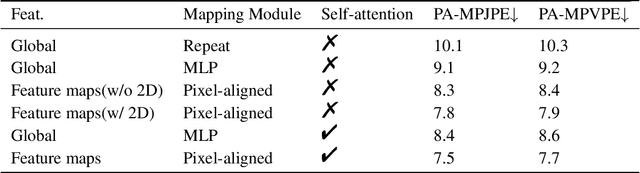
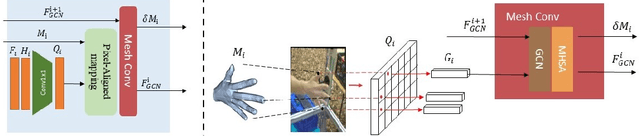

Non-parametric mesh reconstruction has recently shown significant progress in 3D hand and body applications. In these methods, mesh vertices and edges are visible to neural networks, enabling the possibility to establish a direct mapping between 2D image pixels and 3D mesh vertices. In this paper, we seek to establish and exploit this mapping with a simple and compact architecture. The network is designed with these considerations: 1) aggregating both local 2D image features from the encoder and 3D geometric features captured in the mesh decoder; 2) decoding coarse-to-fine meshes along the decoding layers to make the best use of the hierarchical multi-scale information. Specifically, we propose an end-to-end pipeline for hand mesh recovery tasks which consists of three phases: a 2D feature extractor constructing multi-scale feature maps, a feature mapping module transforming local 2D image features to 3D vertex features via 3D-to-2D projection, and a mesh decoder combining the graph convolution and self-attention to reconstruct mesh. The decoder aggregate both local image features in pixels and geometric features in vertices. It also regresses the mesh vertices in a coarse-to-fine manner, which can leverage multi-scale information. By exploiting the local connection and designing the mesh decoder, Our approach achieves state-of-the-art for hand mesh reconstruction on the public FreiHAND dataset.
Construction and Evaluation of a Self-Attention Model for Semantic Understanding of Sentence-Final Particles
Oct 01, 2022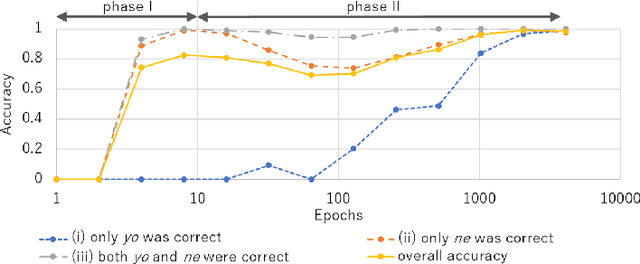
Sentence-final particles serve an essential role in spoken Japanese because they express the speaker's mental attitudes toward a proposition and/or an interlocutor. They are acquired at early ages and occur very frequently in everyday conversation. However, there has been little proposal for a computational model of acquiring sentence-final particles. This paper proposes Subjective BERT, a self-attention model that takes various subjective senses in addition to language and images as input and learns the relationship between words and subjective senses. An evaluation experiment revealed that the model understands the usage of "yo", which expresses the speaker's intention to communicate new information, and that of "ne", which denotes the speaker's desire to confirm that some information is shared.
Towards Cross-Cultural Analysis using Music Information Dynamics
Nov 24, 2021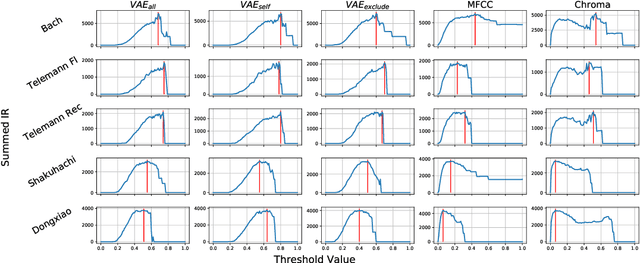
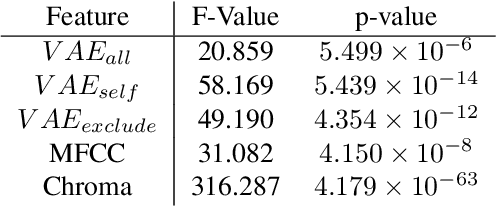
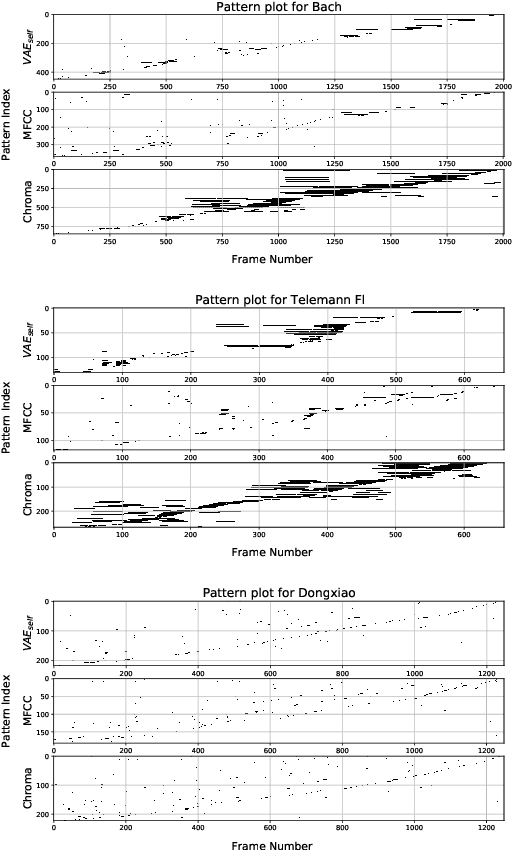
A music piece is both comprehended hierarchically, from sonic events to melodies, and sequentially, in the form of repetition and variation. Music from different cultures establish different aesthetics by having different style conventions on these two aspects. We propose a framework that could be used to quantitatively compare music from different cultures by looking at these two aspects. The framework is based on an Music Information Dynamics model, a Variable Markov Oracle (VMO), and is extended with a variational representation learning of audio. A variational autoencoder (VAE) is trained to map audio fragments into a latent representation. The latent representation is fed into a VMO. The VMO then learns a clustering of the latent representation via a threshold that maximizes the information rate of the quantized latent representation sequence. This threshold effectively controls the sensibility of the predictive step to acoustic changes, which determines the framework's ability to track repetitions on longer time scales. This approach allows characterization of the overall information contents of a musical signal at each level of acoustic sensibility. Our findings under this framework show that sensibility to subtle acoustic changes is higher for East-Asian musical traditions, while the Western works exhibit longer motivic structures at higher thresholds of differences in the latent space. This suggests that a profile of information contents, analyzed as a function of the level of acoustic detail can serve as a possible cultural characteristic.