 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Unified Framework of Medical Information Annotation and Extraction for Chinese Clinical Text
Mar 08, 2022
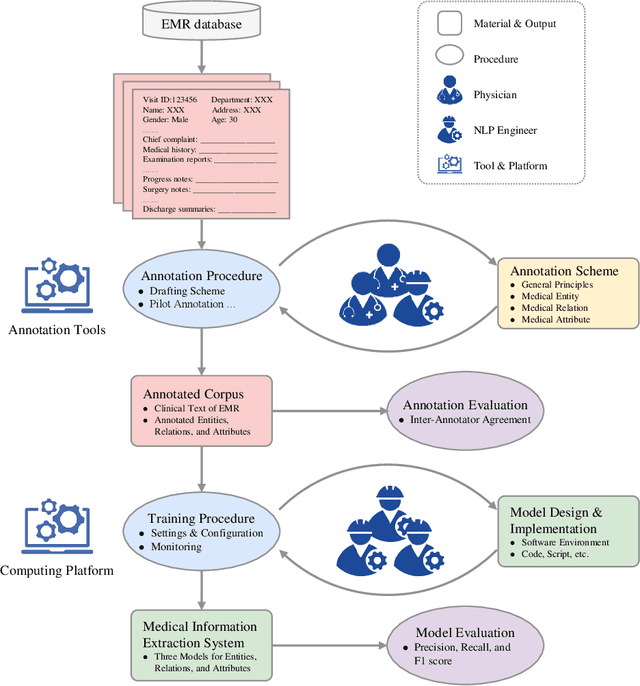
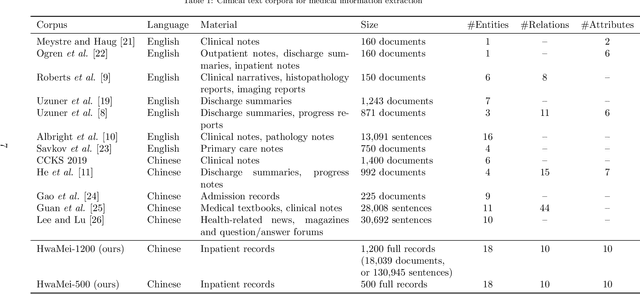
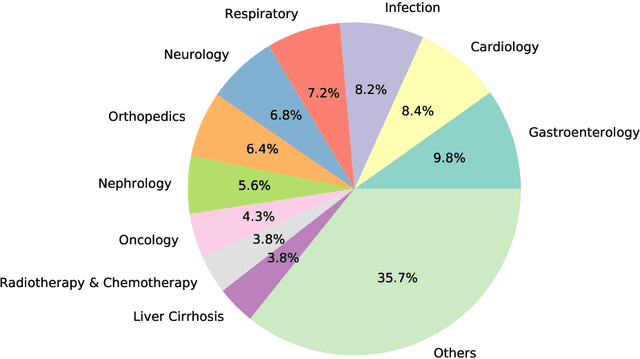
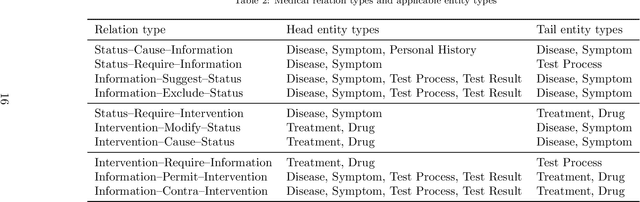
Medical information extraction consists of a group of natural language processing (NLP) tasks, which collaboratively convert clinical text to pre-defined structured formats. Current state-of-the-art (SOTA) NLP models are highly integrated with deep learning techniques and thus require massive annotated linguistic data. This study presents an engineering framework of medical entity recognition, relation extraction and attribute extraction, which are unified in annotation, modeling and evaluation. Specifically, the annotation scheme is comprehensive, and compatible between tasks, especially for the medical relations. The resulted annotated corpus includes 1,200 full medical records (or 18,039 broken-down documents), and achieves inter-annotator agreements (IAAs) of 94.53%, 73.73% and 91.98% F 1 scores for the three tasks. Three task-specific neural network models are developed within a shared structure, and enhanced by SOTA NLP techniques, i.e., pre-trained language models. Experimental results show that the system can retrieve medical entities, relations and attributes with F 1 scores of 93.47%, 67.14% and 90.89%, respectively. This study, in addition to our publicly released annotation scheme and code, provides solid and practical engineering experience of developing an integrated medical information extraction system.
Graph Summarization via Node Grouping: A Spectral Algorithm
Nov 08, 2022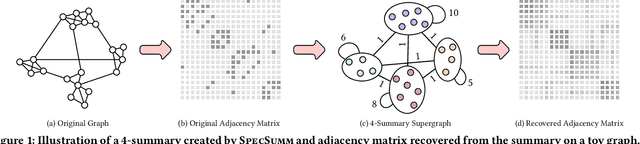
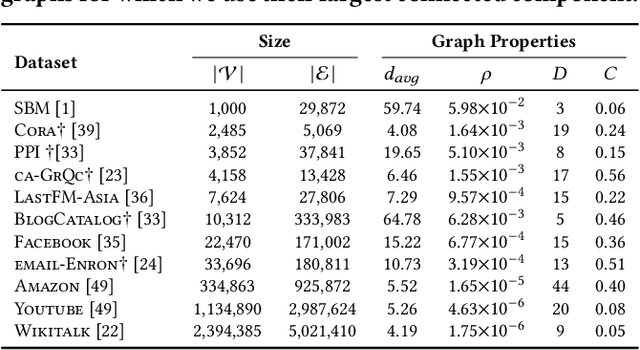
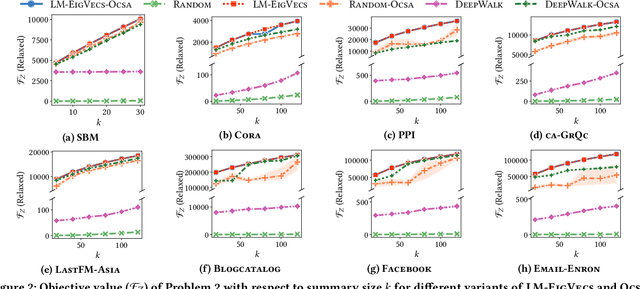
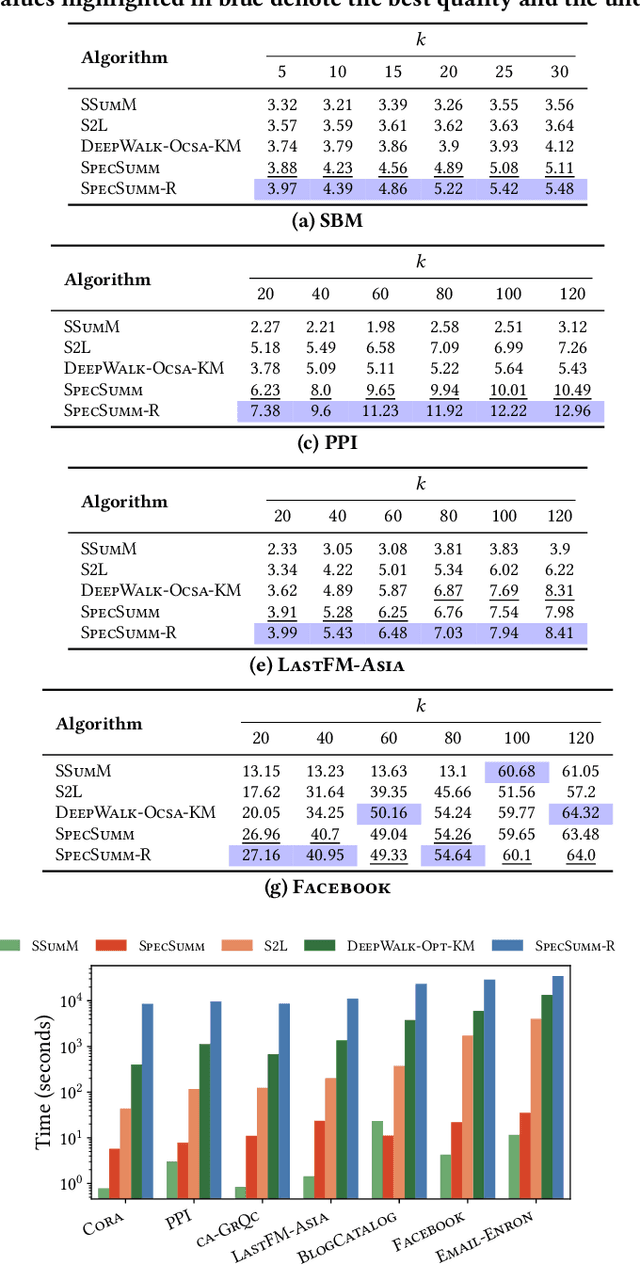
Graph summarization via node grouping is a popular method to build concise graph representations by grouping nodes from the original graph into supernodes and encoding edges into superedges such that the loss of adjacency information is minimized. Such summaries have immense applications in large-scale graph analytics due to their small size and high query processing efficiency. In this paper, we reformulate the loss minimization problem for summarization into an equivalent integer maximization problem. By initially allowing relaxed (fractional) solutions for integer maximization, we analytically expose the underlying connections to the spectral properties of the adjacency matrix. Consequently, we design an algorithm called SpecSumm that consists of two phases. In the first phase, motivated by spectral graph theory, we apply k-means clustering on the k largest (in magnitude) eigenvectors of the adjacency matrix to assign nodes to supernodes. In the second phase, we propose a greedy heuristic that updates the initial assignment to further improve summary quality. Finally, via extensive experiments on 11 datasets, we show that SpecSumm efficiently produces high-quality summaries compared to state-of-the-art summarization algorithms and scales to graphs with millions of nodes.
Efficient Compressed Ratio Estimation using Online Sequential Learning for Edge Computing
Nov 08, 2022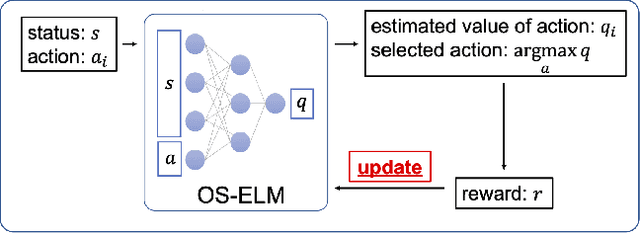
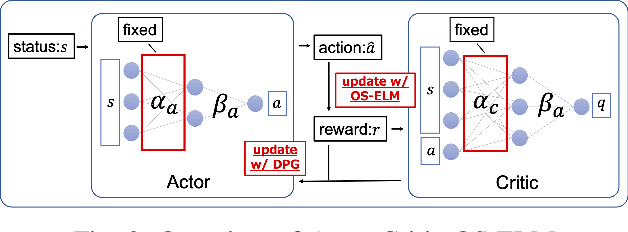
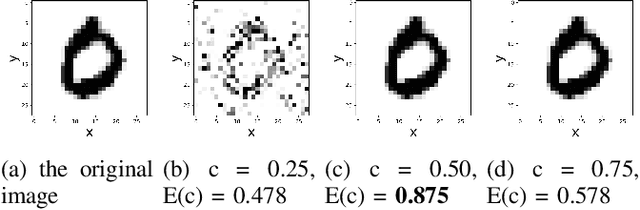
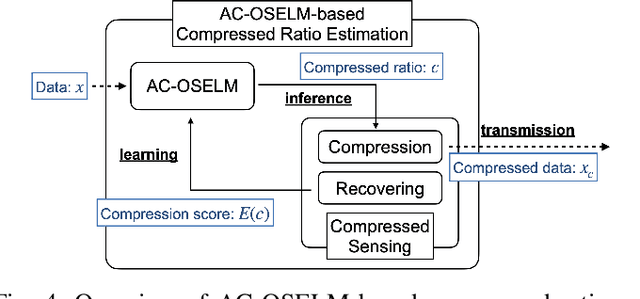
Owing to the widespread adoption of the Internet of Things, a vast amount of sensor information is being acquired in real time. Accordingly, the communication cost of data from edge devices is increasing. Compressed sensing (CS), a data compression method that can be used on edge devices, has been attracting attention as a method to reduce communication costs. In CS, estimating the appropriate compression ratio is important. There is a method to adaptively estimate the compression ratio for the acquired data using reinforcement learning. However, the computational costs associated with existing reinforcement learning methods that can be utilized on edges are expensive. In this study, we developed an efficient reinforcement learning method for edge devices, referred to as the actor--critic online sequential extreme learning machine (AC-OSELM), and a system to compress data by estimating an appropriate compression ratio on the edge using AC-OSELM. The performance of the proposed method in estimating the compression ratio is evaluated by comparing it with other reinforcement learning methods for edge devices. The experimental results show that AC-OSELM achieved the same or better compression performance and faster compression ratio estimation than the existing methods.
Finite Sample Identification of Wide Shallow Neural Networks with Biases
Nov 08, 2022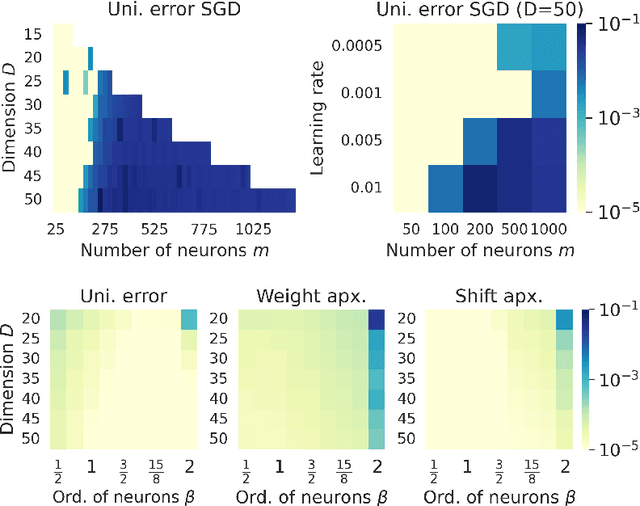
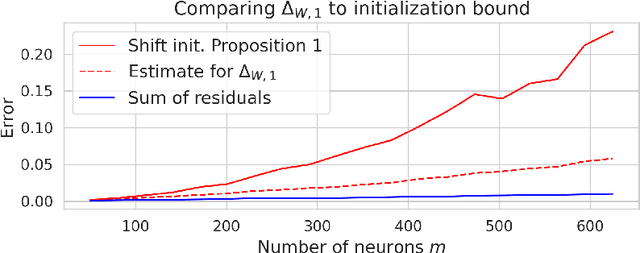
Artificial neural networks are functions depending on a finite number of parameters typically encoded as weights and biases. The identification of the parameters of the network from finite samples of input-output pairs is often referred to as the \emph{teacher-student model}, and this model has represented a popular framework for understanding training and generalization. Even if the problem is NP-complete in the worst case, a rapidly growing literature -- after adding suitable distributional assumptions -- has established finite sample identification of two-layer networks with a number of neurons $m=\mathcal O(D)$, $D$ being the input dimension. For the range $D<m<D^2$ the problem becomes harder, and truly little is known for networks parametrized by biases as well. This paper fills the gap by providing constructive methods and theoretical guarantees of finite sample identification for such wider shallow networks with biases. Our approach is based on a two-step pipeline: first, we recover the direction of the weights, by exploiting second order information; next, we identify the signs by suitable algebraic evaluations, and we recover the biases by empirical risk minimization via gradient descent. Numerical results demonstrate the effectiveness of our approach.
High-resolution embedding extractor for speaker diarisation
Nov 08, 2022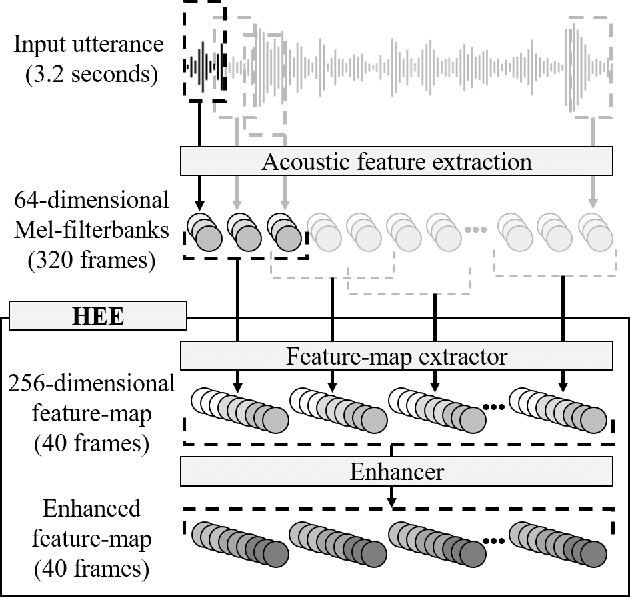
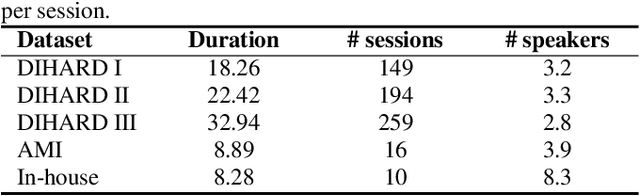
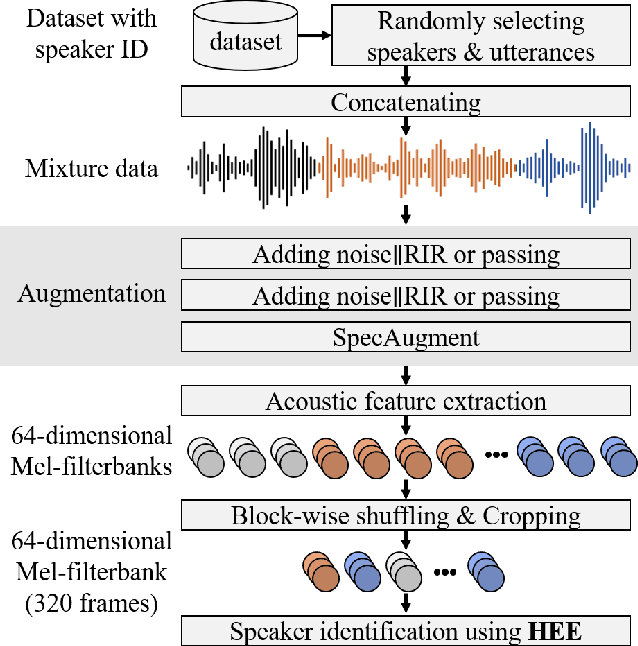
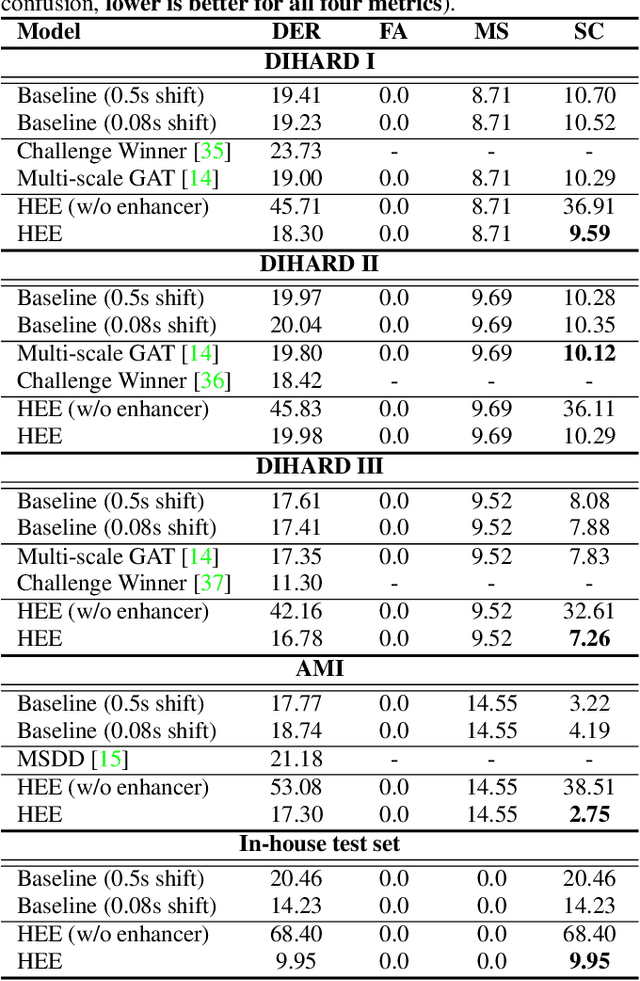
Speaker embedding extractors significantly influence the performance of clustering-based speaker diarisation systems. Conventionally, only one embedding is extracted from each speech segment. However, because of the sliding window approach, a segment easily includes two or more speakers owing to speaker change points. This study proposes a novel embedding extractor architecture, referred to as a high-resolution embedding extractor (HEE), which extracts multiple high-resolution embeddings from each speech segment. Hee consists of a feature-map extractor and an enhancer, where the enhancer with the self-attention mechanism is the key to success. The enhancer of HEE replaces the aggregation process; instead of a global pooling layer, the enhancer combines relative information to each frame via attention leveraging the global context. Extracted dense frame-level embeddings can each represent a speaker. Thus, multiple speakers can be represented by different frame-level features in each segment. We also propose an artificially generating mixture data training framework to train the proposed HEE. Through experiments on five evaluation sets, including four public datasets, the proposed HEE demonstrates at least 10% improvement on each evaluation set, except for one dataset, which we analyse that rapid speaker changes less exist.
SimOn: A Simple Framework for Online Temporal Action Localization
Nov 08, 2022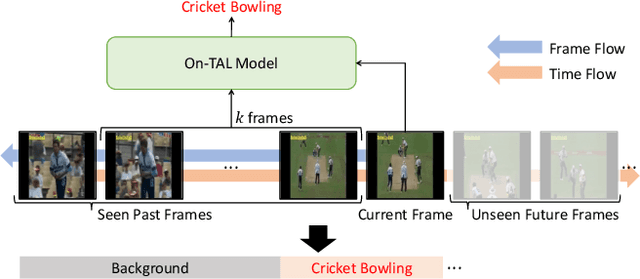
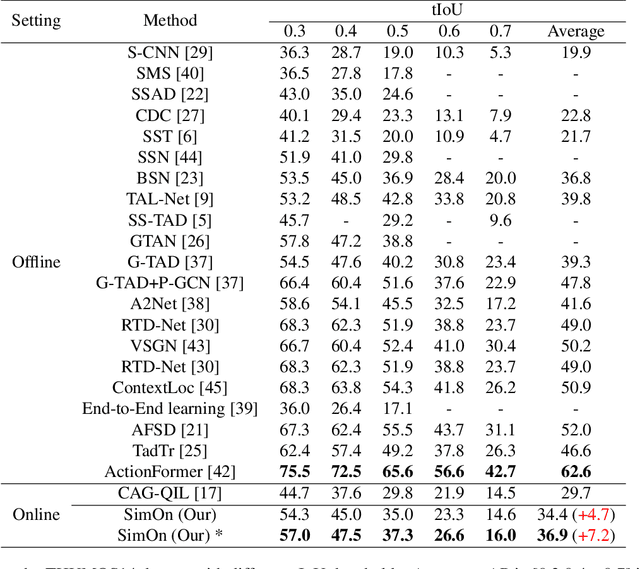
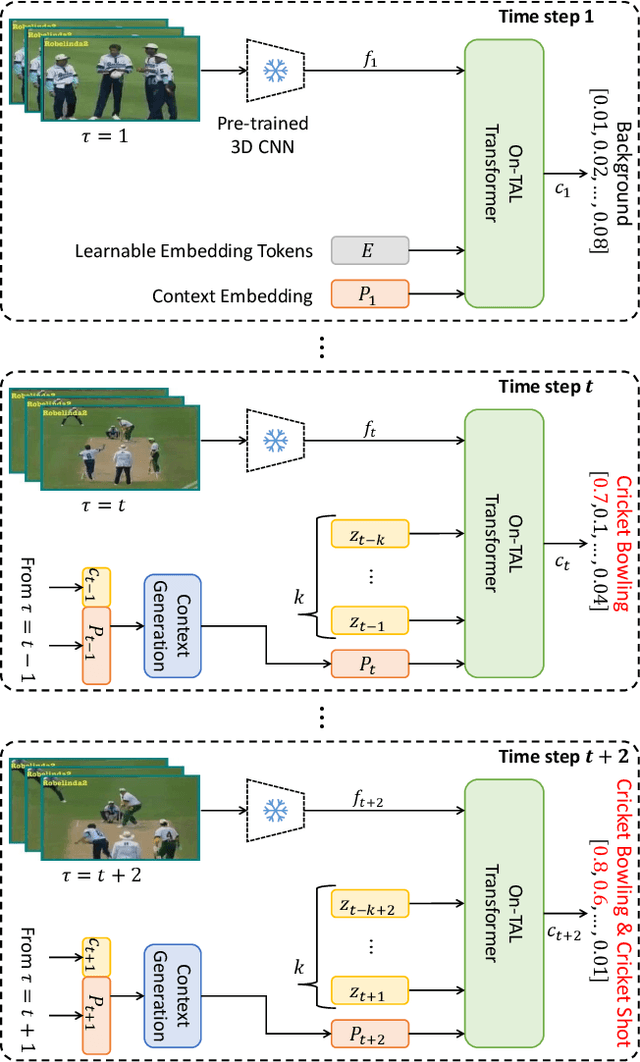
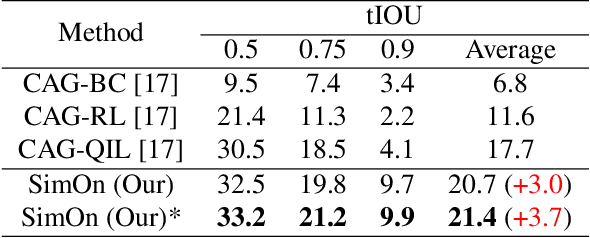
Online Temporal Action Localization (On-TAL) aims to immediately provide action instances from untrimmed streaming videos. The model is not allowed to utilize future frames and any processing techniques to modify past predictions, making On-TAL much more challenging. In this paper, we propose a simple yet effective framework, termed SimOn, that learns to predict action instances using the popular Transformer architecture in an end-to-end manner. Specifically, the model takes the current frame feature as a query and a set of past context information as keys and values of the Transformer. Different from the prior work that uses a set of outputs of the model as past contexts, we leverage the past visual context and the learnable context embedding for the current query. Experimental results on the THUMOS14 and ActivityNet1.3 datasets show that our model remarkably outperforms the previous methods, achieving a new state-of-the-art On-TAL performance. In addition, the evaluation for Online Detection of Action Start (ODAS) demonstrates the effectiveness and robustness of our method in the online setting. The code is available at https://github.com/TuanTNG/SimOn
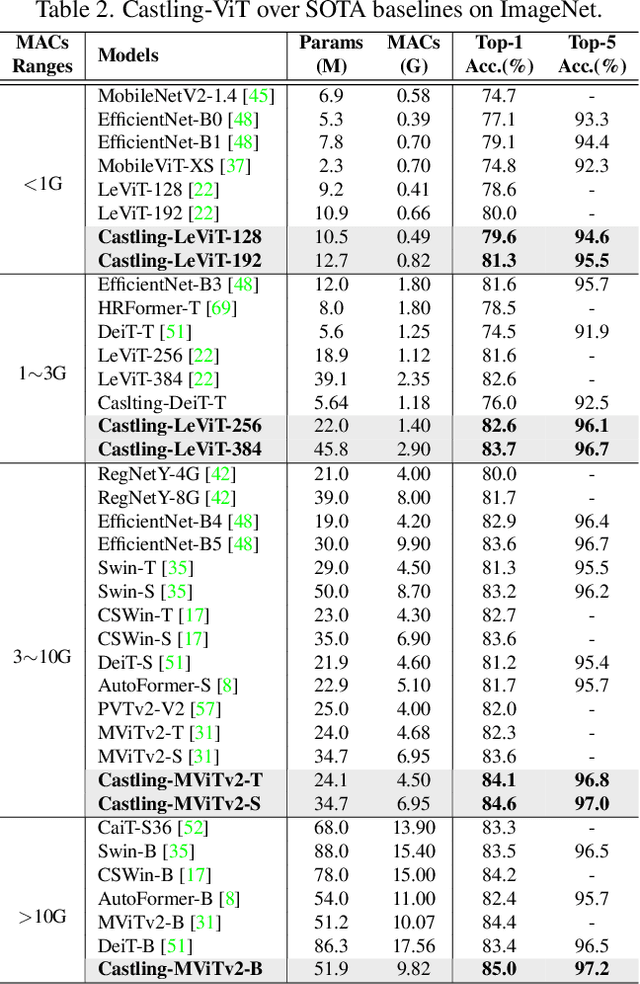
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Nov 18, 2022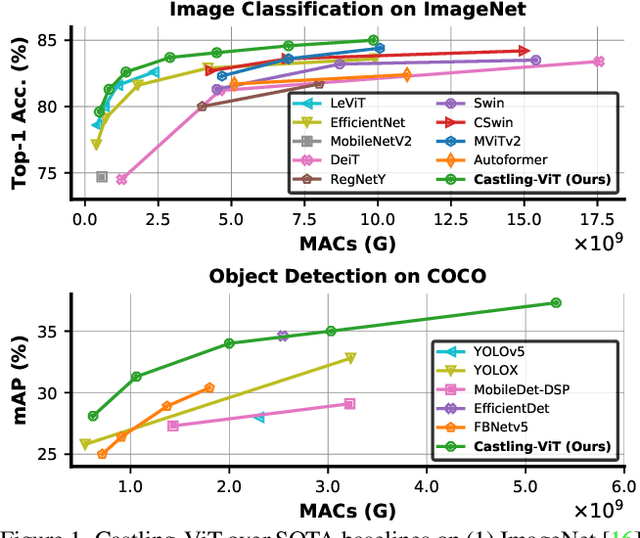
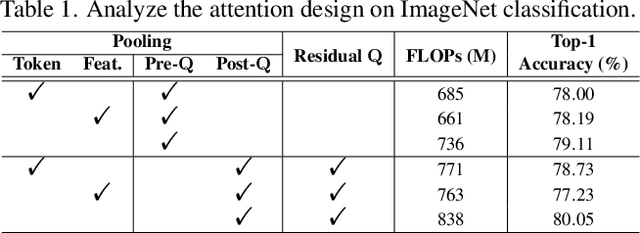
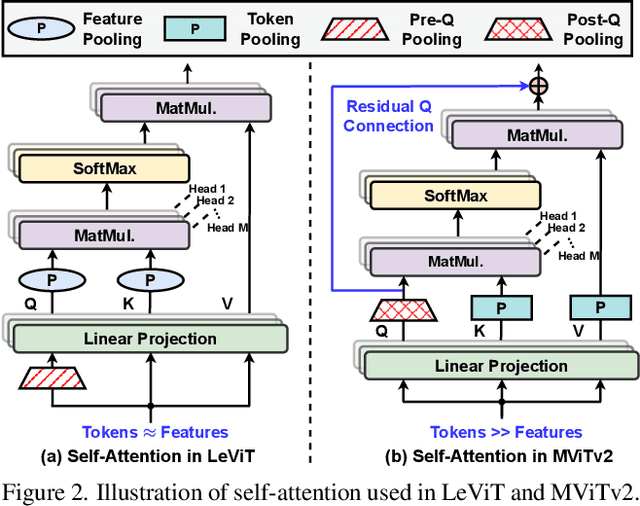
Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022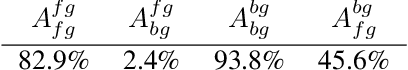



Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
Sentiment Analysis of ESG disclosures on Stock Market
Oct 03, 2022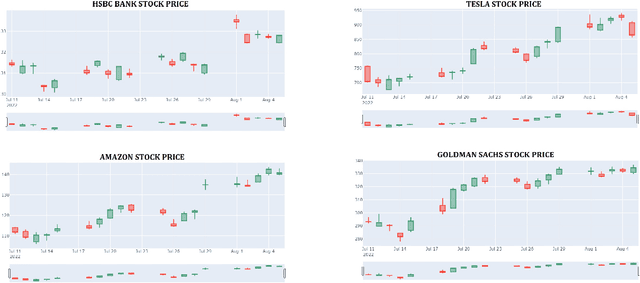
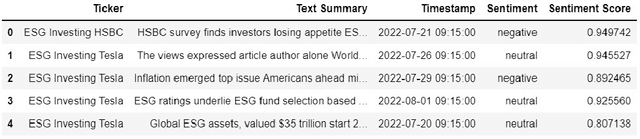

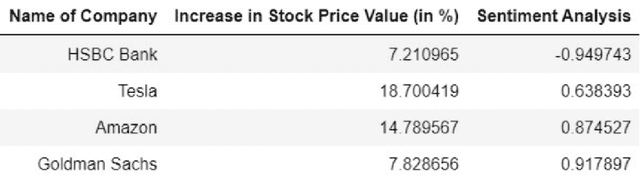
In this paper, we look at the impact of Environment, Social and Governance related news articles and social media data on the stock market performance. We pick four stocks of companies which are widely known in their domain to understand the complete effect of ESG as the newly opted investment style remains restricted to only the stocks with widespread information. We summarise live data of both twitter tweets and newspaper articles and create a sentiment index using a dictionary technique based on online information for the month of July, 2022. We look at the stock price data for all the four companies and calculate the percentage change in each of them. We also compare the overall sentiment of the company to its percentage change over a specific historical period.
DVCFlow: Modeling Information Flow Towards Human-like Video Captioning
Nov 19, 2021
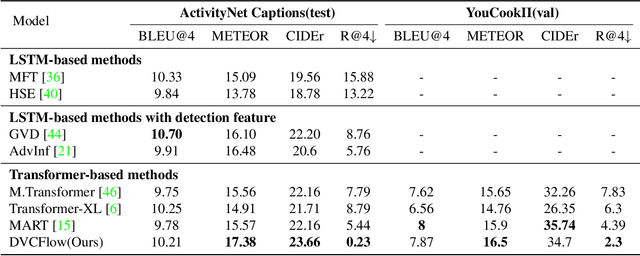
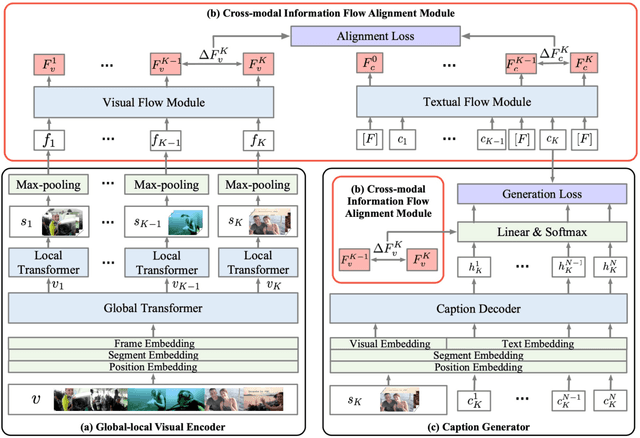
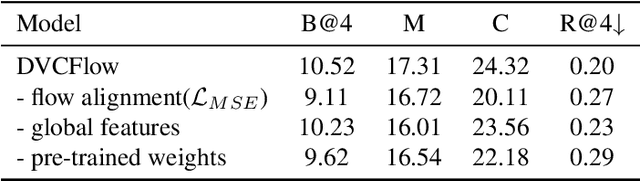
Dense video captioning (DVC) aims to generate multi-sentence descriptions to elucidate the multiple events in the video, which is challenging and demands visual consistency, discoursal coherence, and linguistic diversity. Existing methods mainly generate captions from individual video segments, lacking adaptation to the global visual context and progressive alignment between the fast-evolved visual content and textual descriptions, which results in redundant and spliced descriptions. In this paper, we introduce the concept of information flow to model the progressive information changing across video sequence and captions. By designing a Cross-modal Information Flow Alignment mechanism, the visual and textual information flows are captured and aligned, which endows the captioning process with richer context and dynamics on event/topic evolution. Based on the Cross-modal Information Flow Alignment module, we further put forward DVCFlow framework, which consists of a Global-local Visual Encoder to capture both global features and local features for each video segment, and a pre-trained Caption Generator to produce captions. Extensive experiments on the popular ActivityNet Captions and YouCookII datasets demonstrate that our method significantly outperforms competitive baselines, and generates more human-like text according to subject and objective tests.