 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NEURAL MARIONETTE: A Transformer-based Multi-action Human Motion Synthesis System
Sep 27, 2022
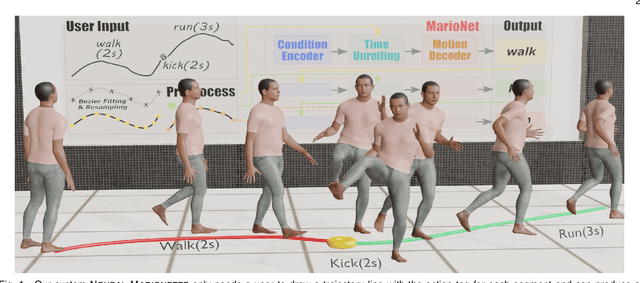
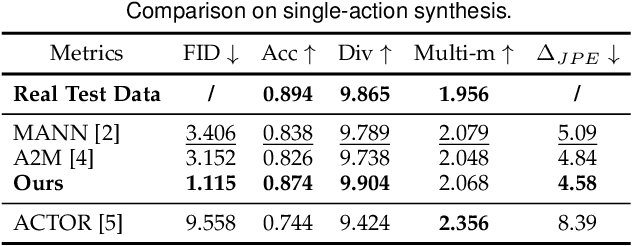

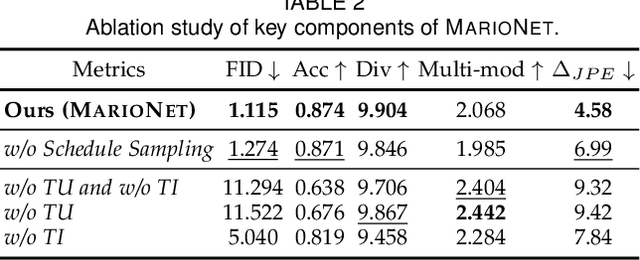
We present a neural network-based system for long-term, multi-action human motion synthesis. The system, dubbed as NEURAL MARIONETTE, can produce high-quality and meaningful motions with smooth transitions from simple user input, including a sequence of action tags with expected action duration, and optionally a hand-drawn moving trajectory if the user specifies. The core of our system is a novel Transformer-based motion generation model, namely MARIONET, which can generate diverse motions given action tags. Different from existing motion generation models, MARIONET utilizes contextual information from the past motion clip and future action tag, dedicated to generating actions that can smoothly blend historical and future actions. Specifically, MARIONET first encodes target action tag and contextual information into an action-level latent code. The code is unfolded into frame-level control signals via a time unrolling module, which could be then combined with other frame-level control signals like the target trajectory. Motion frames are then generated in an auto-regressive way. By sequentially applying MARIONET, the system NEURAL MARIONETTE can robustly generate long-term, multi-action motions with the help of two simple schemes, namely "Shadow Start" and "Action Revision". Along with the novel system, we also present a new dataset dedicated to the multi-action motion synthesis task, which contains both action tags and their contextual information. Extensive experiments are conducted to study the action accuracy, naturalism, and transition smoothness of the motions generated by our system.
PL-EVIO: Robust Monocular Event-based Visual Inertial Odometry with Point and Line Features
Sep 25, 2022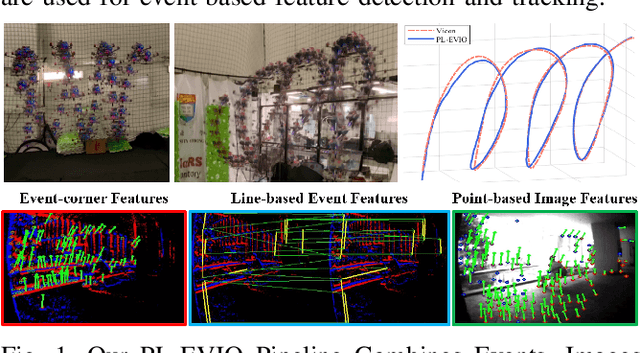
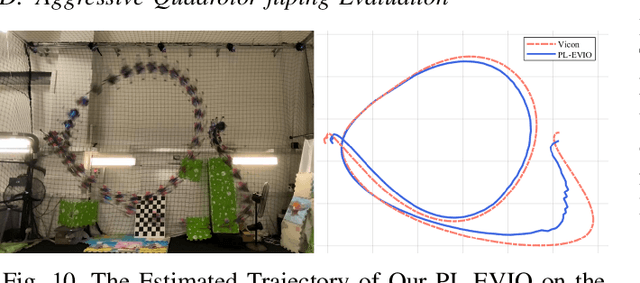
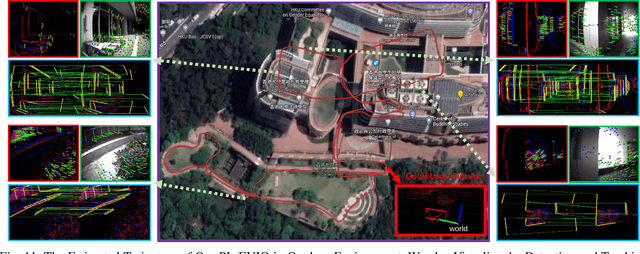
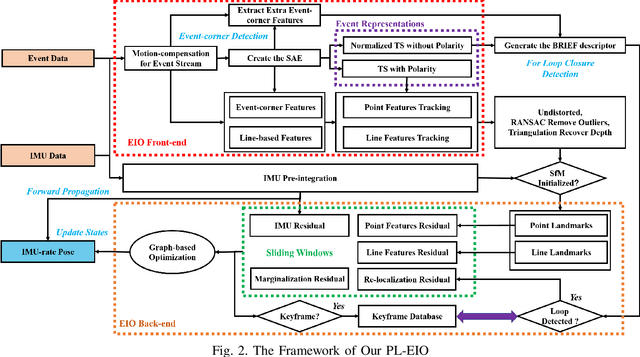
Event cameras are motion-activated sensors that capture pixel-level illumination changes instead of the intensity image with a fixed frame rate. Compared with the standard cameras, it can provide reliable visual perception during high-speed motions and in high dynamic range scenarios. However, event cameras output only a little information or even noise when the relative motion between the camera and the scene is limited, such as in a still state. While standard cameras can provide rich perception information in most scenarios, especially in good lighting conditions. These two cameras are exactly complementary. In this paper, we proposed a robust, high-accurate, and real-time optimization-based monocular event-based visual-inertial odometry (VIO) method with event-corner features, line-based event features, and point-based image features. The proposed method offers to leverage the point-based features in the nature scene and line-based features in the human-made scene to provide more additional structure or constraints information through well-design feature management. Experiments in the public benchmark datasets show that our method can achieve superior performance compared with the state-of-the-art image-based or event-based VIO. Finally, we used our method to demonstrate an onboard closed-loop autonomous quadrotor flight and large-scale outdoor experiments. Videos of the evaluations are presented on our project website: https://b23.tv/OE3QM6j
Multi-stage image denoising with the wavelet transform
Oct 03, 2022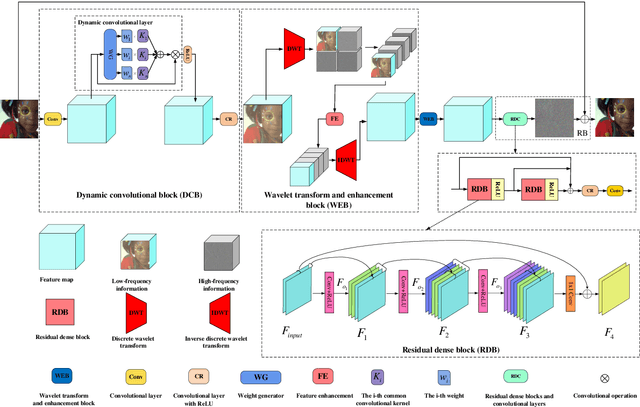
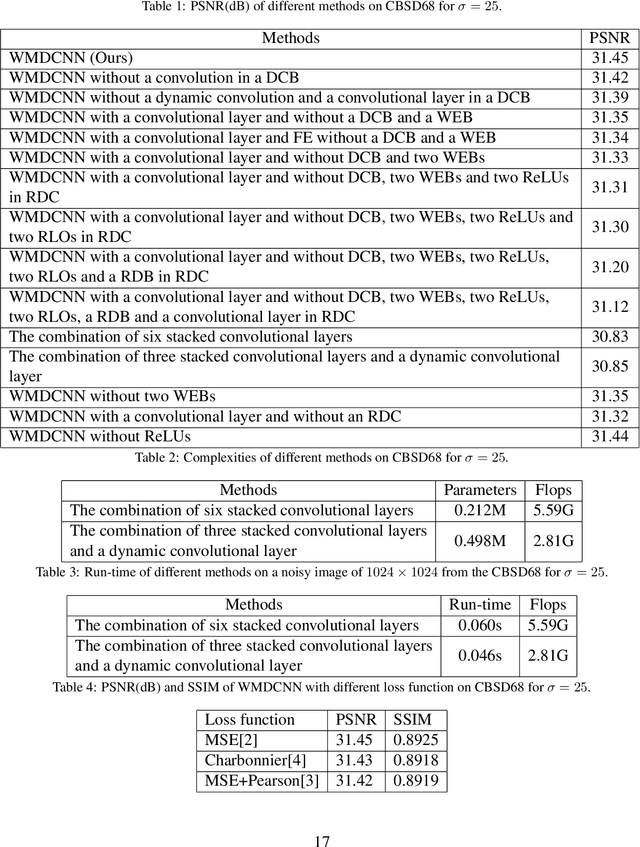
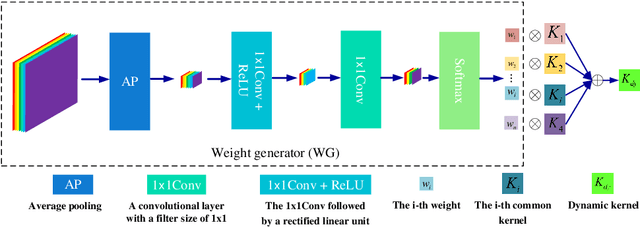
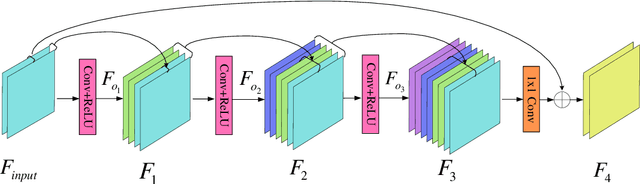
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and a residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
ViTALiTy: Unifying Low-rank and Sparse Approximation for Vision Transformer Acceleration with a Linear Taylor Attention
Nov 09, 2022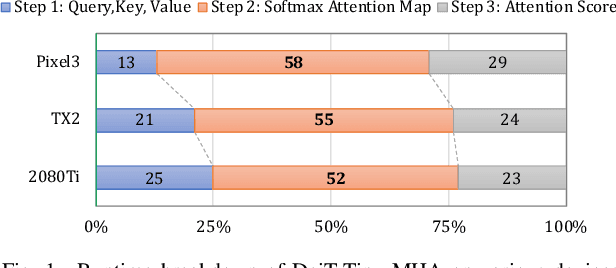
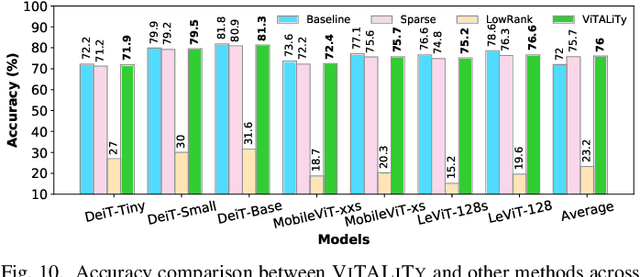
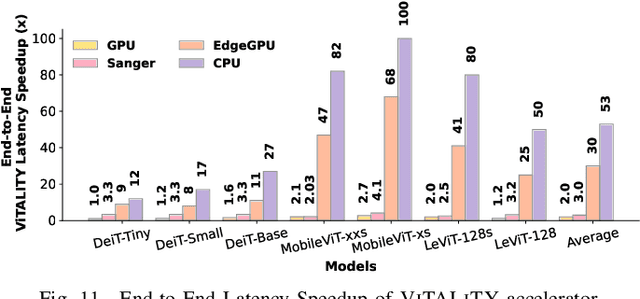
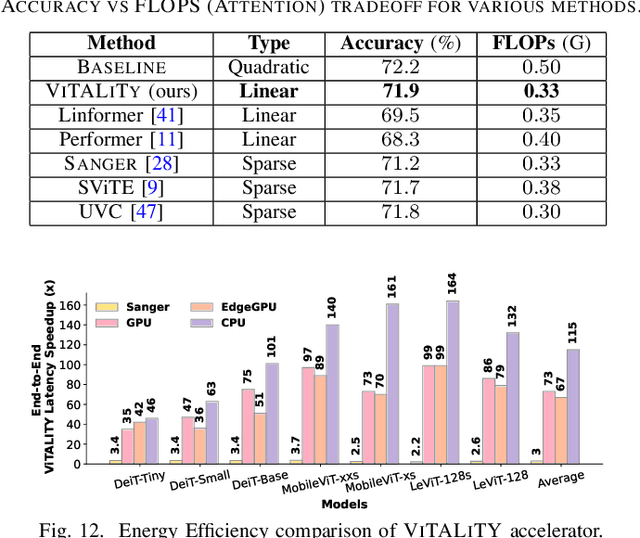
Vision Transformer (ViT) has emerged as a competitive alternative to convolutional neural networks for various computer vision applications. Specifically, ViT multi-head attention layers make it possible to embed information globally across the overall image. Nevertheless, computing and storing such attention matrices incurs a quadratic cost dependency on the number of patches, limiting its achievable efficiency and scalability and prohibiting more extensive real-world ViT applications on resource-constrained devices. Sparse attention has been shown to be a promising direction for improving hardware acceleration efficiency for NLP models. However, a systematic counterpart approach is still missing for accelerating ViT models. To close the above gap, we propose a first-of-its-kind algorithm-hardware codesigned framework, dubbed ViTALiTy, for boosting the inference efficiency of ViTs. Unlike sparsity-based Transformer accelerators for NLP, ViTALiTy unifies both low-rank and sparse components of the attention in ViTs. At the algorithm level, we approximate the dot-product softmax operation via first-order Taylor attention with row-mean centering as the low-rank component to linearize the cost of attention blocks and further boost the accuracy by incorporating a sparsity-based regularization. At the hardware level, we develop a dedicated accelerator to better leverage the resulting workload and pipeline from ViTALiTy's linear Taylor attention which requires the execution of only the low-rank component, to further boost the hardware efficiency. Extensive experiments and ablation studies validate that ViTALiTy offers boosted end-to-end efficiency (e.g., $3\times$ faster and $3\times$ energy-efficient) under comparable accuracy, with respect to the state-of-the-art solution.
Grounding Scene Graphs on Natural Images via Visio-Lingual Message Passing
Nov 03, 2022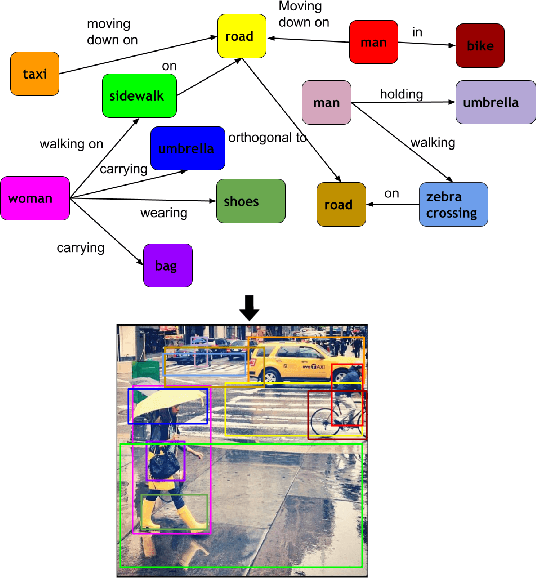
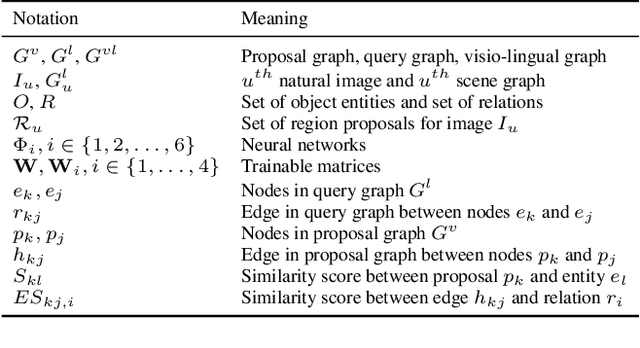
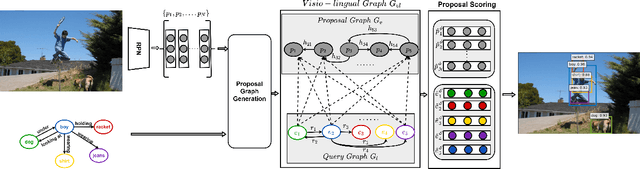
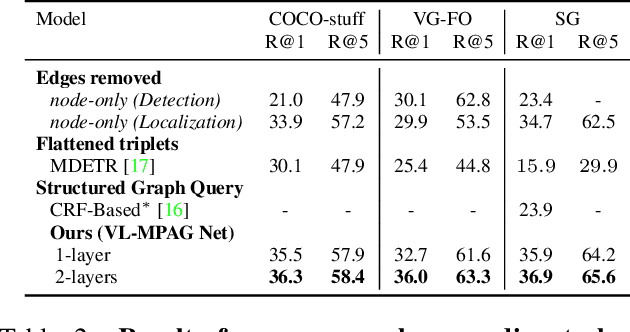
This paper presents a framework for jointly grounding objects that follow certain semantic relationship constraints given in a scene graph. A typical natural scene contains several objects, often exhibiting visual relationships of varied complexities between them. These inter-object relationships provide strong contextual cues toward improving grounding performance compared to a traditional object query-only-based localization task. A scene graph is an efficient and structured way to represent all the objects and their semantic relationships in the image. In an attempt towards bridging these two modalities representing scenes and utilizing contextual information for improving object localization, we rigorously study the problem of grounding scene graphs on natural images. To this end, we propose a novel graph neural network-based approach referred to as Visio-Lingual Message PAssing Graph Neural Network (VL-MPAG Net). In VL-MPAG Net, we first construct a directed graph with object proposals as nodes and an edge between a pair of nodes representing a plausible relation between them. Then a three-step inter-graph and intra-graph message passing is performed to learn the context-dependent representation of the proposals and query objects. These object representations are used to score the proposals to generate object localization. The proposed method significantly outperforms the baselines on four public datasets.
Could Giant Pretrained Image Models Extract Universal Representations?
Nov 03, 2022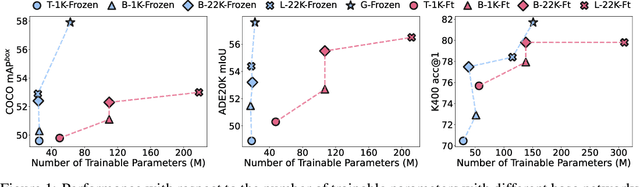
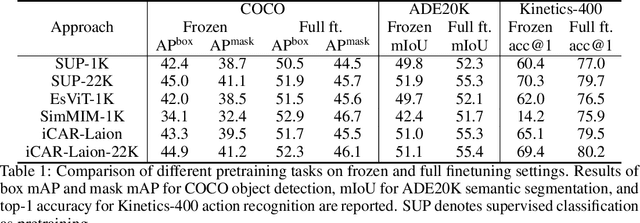
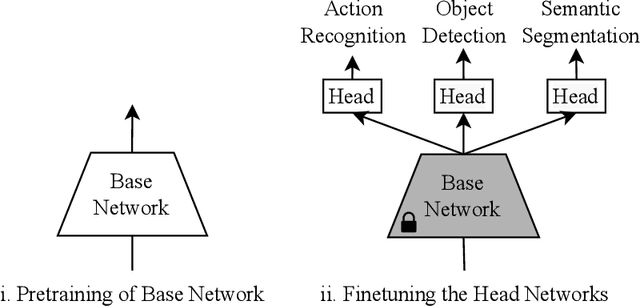
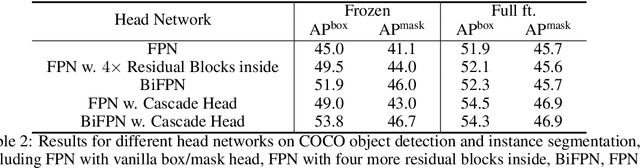
Frozen pretrained models have become a viable alternative to the pretraining-then-finetuning paradigm for transfer learning. However, with frozen models there are relatively few parameters available for adapting to downstream tasks, which is problematic in computer vision where tasks vary significantly in input/output format and the type of information that is of value. In this paper, we present a study of frozen pretrained models when applied to diverse and representative computer vision tasks, including object detection, semantic segmentation and video action recognition. From this empirical analysis, our work answers the questions of what pretraining task fits best with this frozen setting, how to make the frozen setting more flexible to various downstream tasks, and the effect of larger model sizes. We additionally examine the upper bound of performance using a giant frozen pretrained model with 3 billion parameters (SwinV2-G) and find that it reaches competitive performance on a varied set of major benchmarks with only one shared frozen base network: 60.0 box mAP and 52.2 mask mAP on COCO object detection test-dev, 57.6 val mIoU on ADE20K semantic segmentation, and 81.7 top-1 accuracy on Kinetics-400 action recognition. With this work, we hope to bring greater attention to this promising path of freezing pretrained image models.
SAP-DETR: Bridging the Gap Between Salient Points and Queries-Based Transformer Detector for Fast Model Convergency
Nov 03, 2022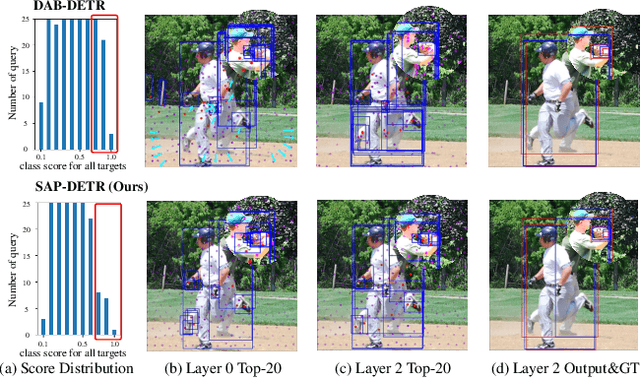
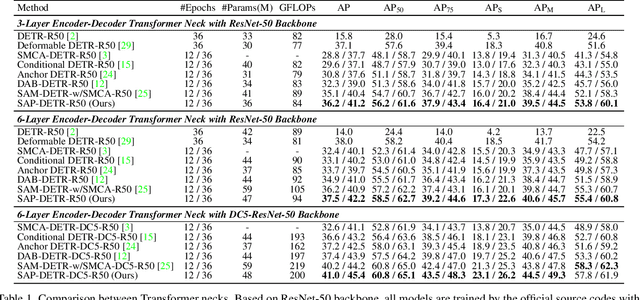
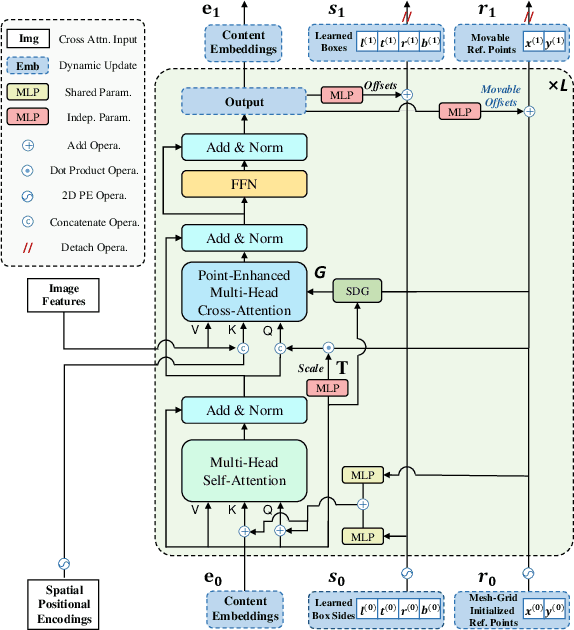

Recently, the dominant DETR-based approaches apply central-concept spatial prior to accelerate Transformer detector convergency. These methods gradually refine the reference points to the center of target objects and imbue object queries with the updated central reference information for spatially conditional attention. However, centralizing reference points may severely deteriorate queries' saliency and confuse detectors due to the indiscriminative spatial prior. To bridge the gap between the reference points of salient queries and Transformer detectors, we propose SAlient Point-based DETR (SAP-DETR) by treating object detection as a transformation from salient points to instance objects. In SAP-DETR, we explicitly initialize a query-specific reference point for each object query, gradually aggregate them into an instance object, and then predict the distance from each side of the bounding box to these points. By rapidly attending to query-specific reference region and other conditional extreme regions from the image features, SAP-DETR can effectively bridge the gap between the salient point and the query-based Transformer detector with a significant convergency speed. Our extensive experiments have demonstrated that SAP-DETR achieves 1.4 times convergency speed with competitive performance. Under the standard training scheme, SAP-DETR stably promotes the SOTA approaches by 1.0 AP. Based on ResNet-DC-101, SAP-DETR achieves 46.9 AP.
Enhancing Patent Retrieval using Text and Knowledge Graph Embeddings: A Technical Note
Nov 03, 2022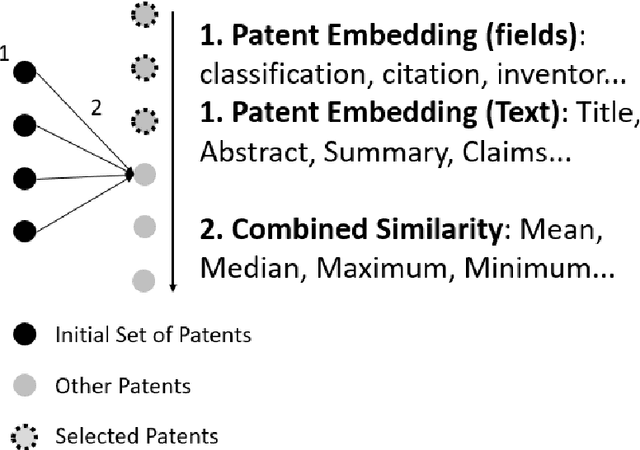
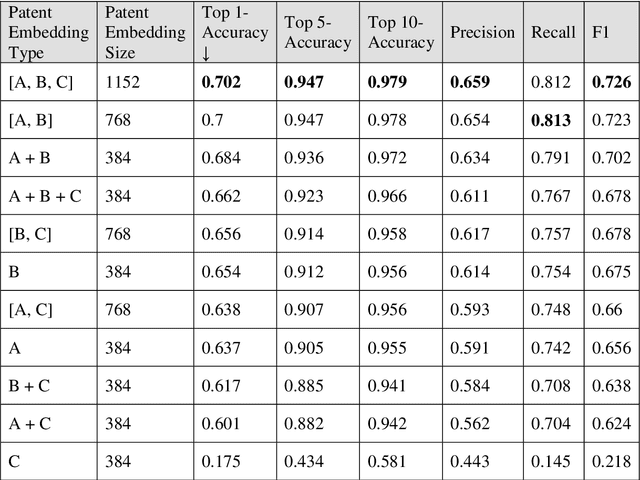
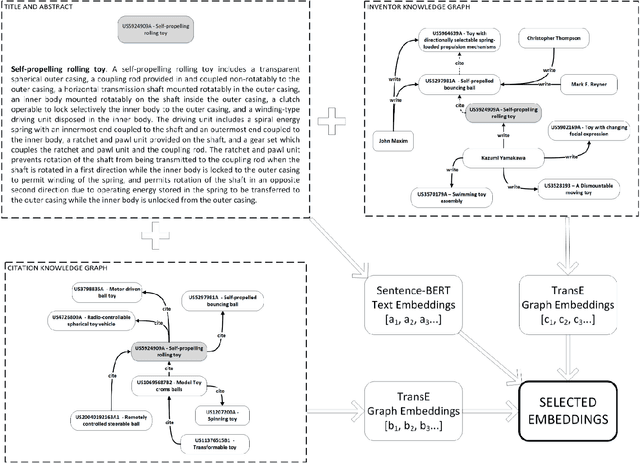
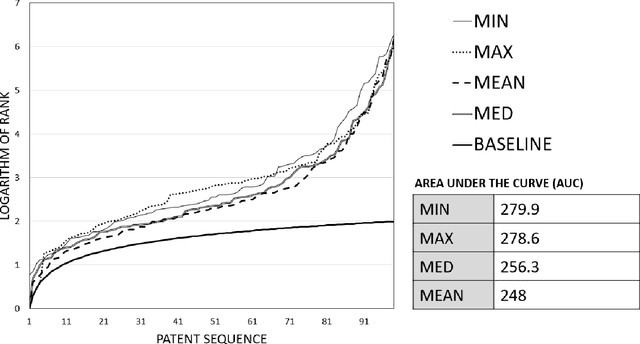
Patent retrieval influences several applications within engineering design research, education, and practice as well as applications that concern innovation, intellectual property, and knowledge management etc. In this article, we propose a method to retrieve patents relevant to an initial set of patents, by synthesizing state-of-the-art techniques among natural language processing and knowledge graph embedding. Our method involves a patent embedding that captures text, citation, and inventor information, which individually represent different facets of knowledge communicated through a patent document. We obtain text embeddings using Sentence-BERT applied to titles and abstracts. We obtain citation and inventor embeddings through TransE that is trained using the corresponding knowledge graphs. We identify using a classification task that the concatenation of text, citation, and inventor embeddings offers a plausible representation of a patent. While the proposed patent embedding could be used to associate a pair of patents, we observe using a recall task that multiple initial patents could be associated with a target patent using mean cosine similarity, which could then be utilized to rank all target patents and retrieve the most relevant ones. We apply the proposed patent retrieval method to a set of patents corresponding to a product family and an inventor's portfolio.
Orchestrating Collaborative Cybersecurity: A Secure Framework for Distributed Privacy-Preserving Threat Intelligence Sharing
Sep 06, 2022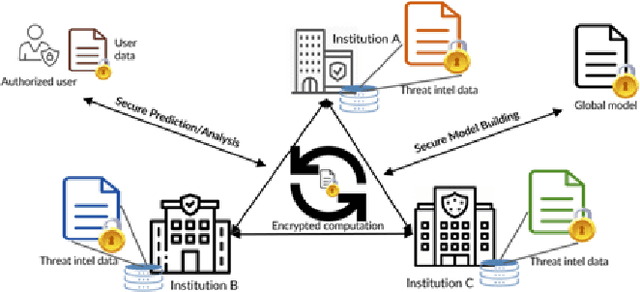
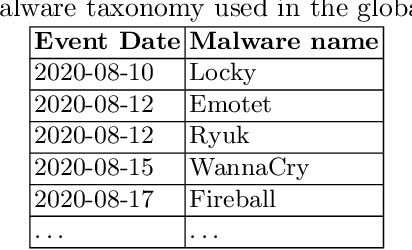
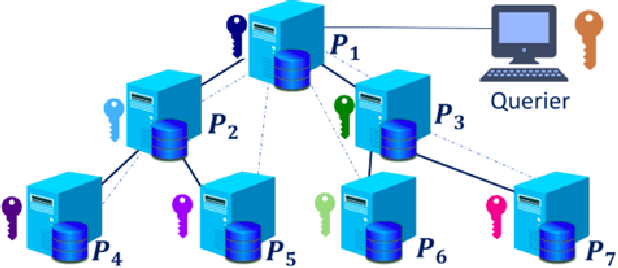
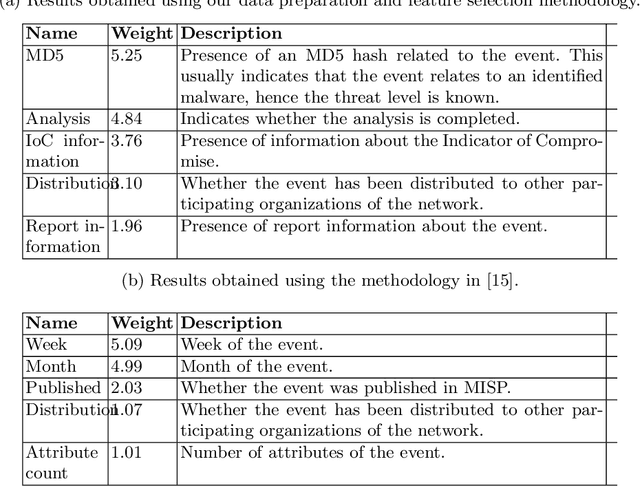
Cyber Threat Intelligence (CTI) sharing is an important activity to reduce information asymmetries between attackers and defenders. However, this activity presents challenges due to the tension between data sharing and confidentiality, that result in information retention often leading to a free-rider problem. Therefore, the information that is shared represents only the tip of the iceberg. Current literature assumes access to centralized databases containing all the information, but this is not always feasible, due to the aforementioned tension. This results in unbalanced or incomplete datasets, requiring the use of techniques to expand them; we show how these techniques lead to biased results and misleading performance expectations. We propose a novel framework for extracting CTI from distributed data on incidents, vulnerabilities and indicators of compromise, and demonstrate its use in several practical scenarios, in conjunction with the Malware Information Sharing Platforms (MISP). Policy implications for CTI sharing are presented and discussed. The proposed system relies on an efficient combination of privacy enhancing technologies and federated processing. This lets organizations stay in control of their CTI and minimize the risks of exposure or leakage, while enabling the benefits of sharing, more accurate and representative results, and more effective predictive and preventive defenses.
Sequential Information Design: Markov Persuasion Process and Its Efficient Reinforcement Learning
Feb 22, 2022In today's economy, it becomes important for Internet platforms to consider the sequential information design problem to align its long term interest with incentives of the gig service providers. This paper proposes a novel model of sequential information design, namely the Markov persuasion processes (MPPs), where a sender, with informational advantage, seeks to persuade a stream of myopic receivers to take actions that maximizes the sender's cumulative utilities in a finite horizon Markovian environment with varying prior and utility functions. Planning in MPPs thus faces the unique challenge in finding a signaling policy that is simultaneously persuasive to the myopic receivers and inducing the optimal long-term cumulative utilities of the sender. Nevertheless, in the population level where the model is known, it turns out that we can efficiently determine the optimal (resp. $\epsilon$-optimal) policy with finite (resp. infinite) states and outcomes, through a modified formulation of the Bellman equation. Our main technical contribution is to study the MPP under the online reinforcement learning (RL) setting, where the goal is to learn the optimal signaling policy by interacting with with the underlying MPP, without the knowledge of the sender's utility functions, prior distributions, and the Markov transition kernels. We design a provably efficient no-regret learning algorithm, the Optimism-Pessimism Principle for Persuasion Process (OP4), which features a novel combination of both optimism and pessimism principles. Our algorithm enjoys sample efficiency by achieving a sublinear $\sqrt{T}$-regret upper bound. Furthermore, both our algorithm and theory can be applied to MPPs with large space of outcomes and states via function approximation, and we showcase such a success under the linear setting.