 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigation of chemical structure recognition by encoder-decoder models in learning progress
Nov 02, 2022
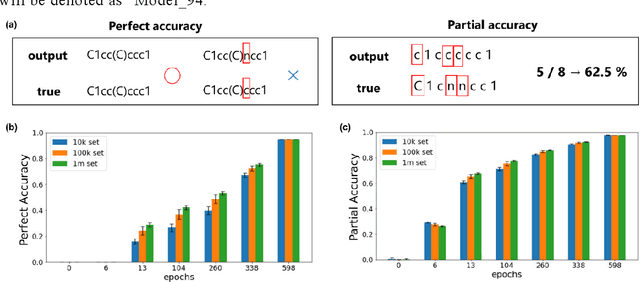
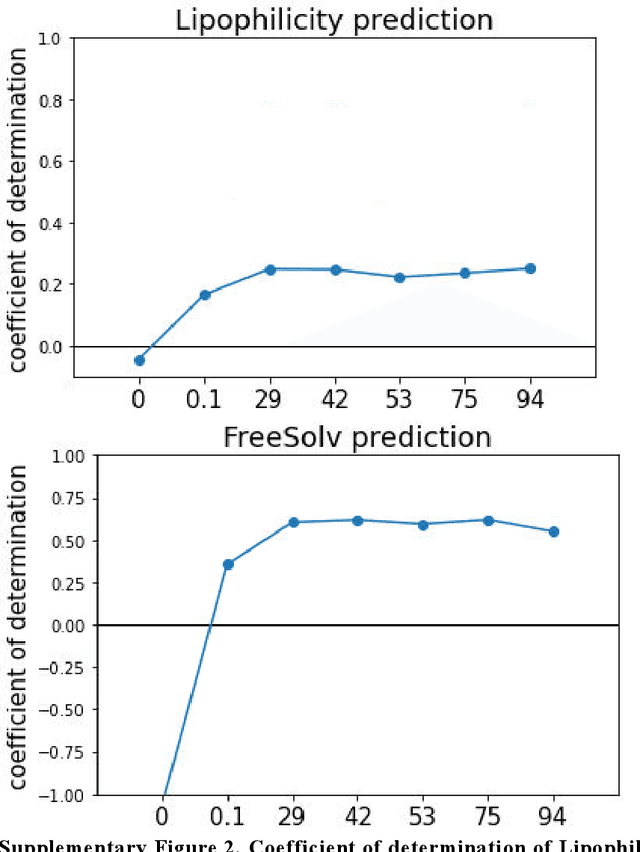
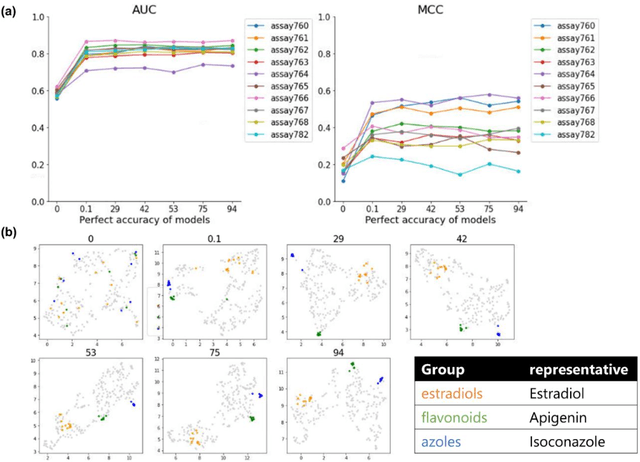
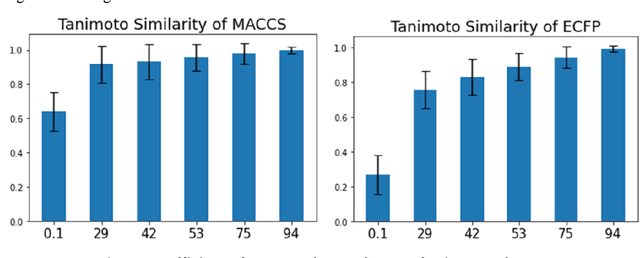
Descriptor generation methods using latent representations of encoder$-$decoder (ED) models with SMILES as input are useful because of the continuity of descriptor and restorability to the structure. However, it is not clear how the structure is recognized in the learning progress of ED models. In this work, we created ED models of various learning progress and investigated the relationship between structural information and learning progress. We showed that compound substructures were learned early in ED models by monitoring the accuracy of downstream tasks and input$-$output substructure similarity using substructure$-$based descriptors, which suggests that existing evaluation methods based on the accuracy of downstream tasks may not be sensitive enough to evaluate the performance of ED models with SMILES as descriptor generation methods. On the other hand, we showed that structure restoration was time$-$consuming, and in particular, insufficient learning led to the estimation of a larger structure than the actual one. It can be inferred that determining the endpoint of the structure is a difficult task for the model. To our knowledge, this is the first study to link the learning progress of SMILES by ED model to chemical structures for a wide range of chemicals.
Modern GPR Target Recognition Methods
Nov 02, 2022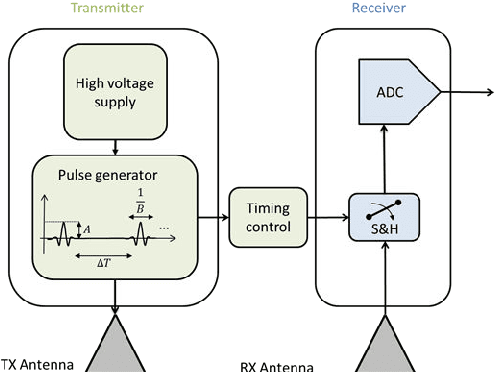
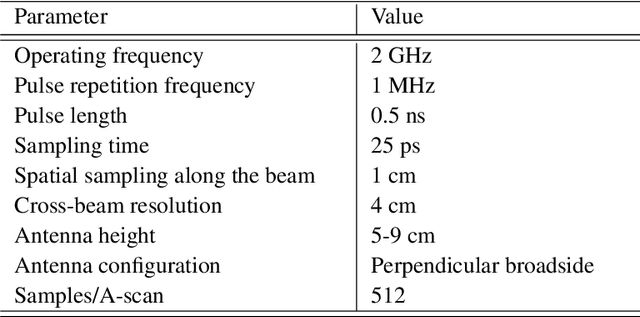
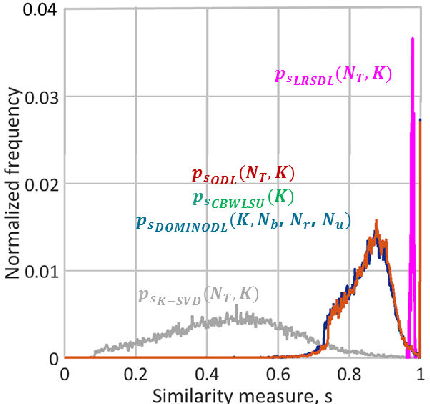
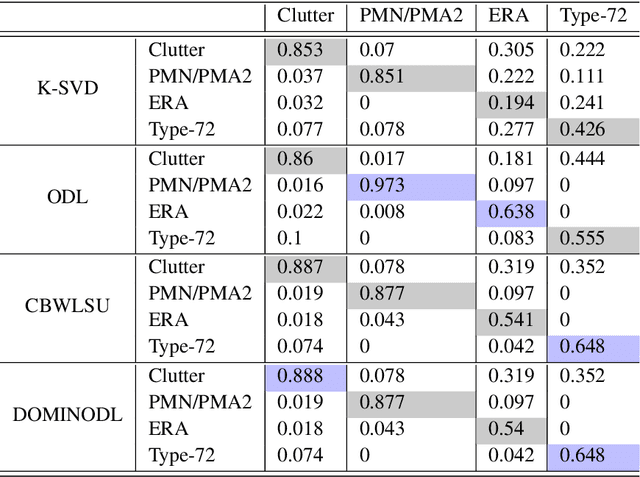
Traditional GPR target recognition methods include pre-processing the data by removal of noisy signatures, dewowing (high-pass filtering to remove low-frequency noise), filtering, deconvolution, migration (correction of the effect of survey geometry), and can rely on the simulation of GPR responses. The techniques usually suffer from the loss of information, inability to adapt from prior results, and inefficient performance in the presence of strong clutter and noise. To address these challenges, several advanced processing methods have been developed over the past decade to enhance GPR target recognition. In this chapter, we provide an overview of these modern GPR processing techniques. In particular, we focus on the following methods: adaptive receive processing of range profiles depending on the target environment; adoption of learning-based methods so that the radar utilizes the results from prior measurements; application of methods that exploit the fact that the target scene is sparse in some domain or dictionary; application of advanced classification techniques; and convolutional coding which provides succinct and representatives features of the targets. We describe each of these techniques or their combinations through a representative application of landmine detection.
* Book chapter, 56 pages, 17 figures, 12 tables. arXiv admin note: substantial text overlap with arXiv:1806.04599
A Joint Framework Towards Class-aware and Class-agnostic Alignment for Few-shot Segmentation
Nov 02, 2022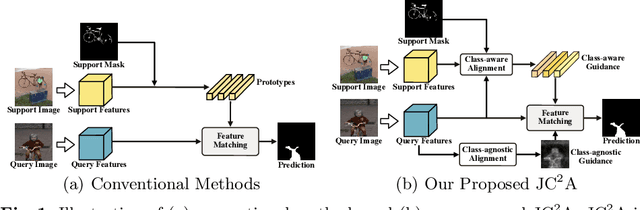
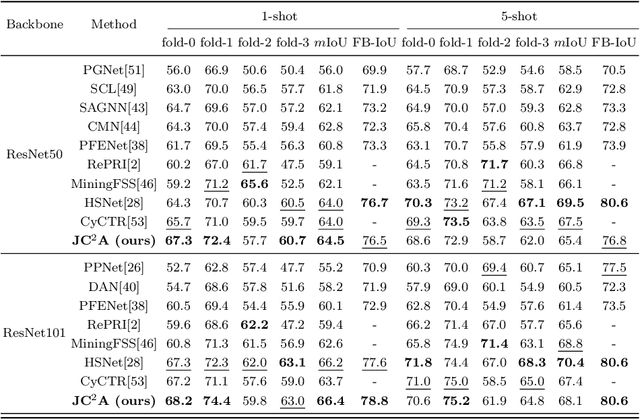
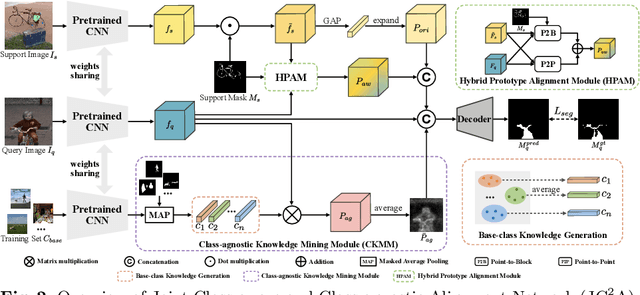
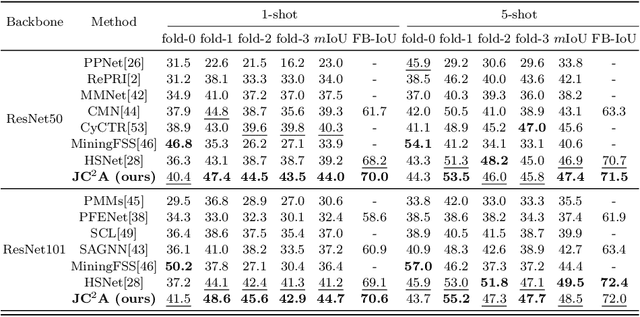
Few-shot segmentation (FSS) aims to segment objects of unseen classes given only a few annotated support images. Most existing methods simply stitch query features with independent support prototypes and segment the query image by feeding the mixed features to a decoder. Although significant improvements have been achieved, existing methods are still face class biases due to class variants and background confusion. In this paper, we propose a joint framework that combines more valuable class-aware and class-agnostic alignment guidance to facilitate the segmentation. Specifically, we design a hybrid alignment module which establishes multi-scale query-support correspondences to mine the most relevant class-aware information for each query image from the corresponding support features. In addition, we explore utilizing base-classes knowledge to generate class-agnostic prior mask which makes a distinction between real background and foreground by highlighting all object regions, especially those of unseen classes. By jointly aggregating class-aware and class-agnostic alignment guidance, better segmentation performances are obtained on query images. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed joint framework performs better, especially on the 1-shot setting.
Adversarial Cross-View Disentangled Graph Contrastive Learning
Sep 16, 2022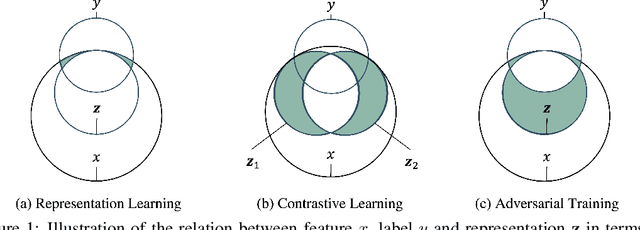
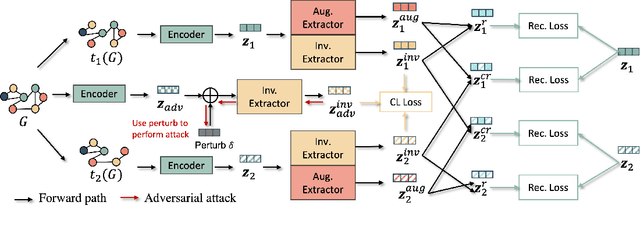

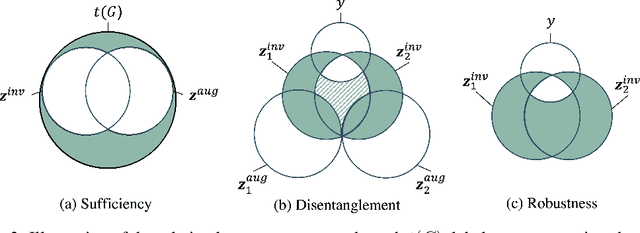
Graph contrastive learning (GCL) is prevalent to tackle the supervision shortage issue in graph learning tasks. Many recent GCL methods have been proposed with various manually designed augmentation techniques, aiming to implement challenging augmentations on the original graph to yield robust representation. Although many of them achieve remarkable performances, existing GCL methods still struggle to improve model robustness without risking losing task-relevant information because they ignore the fact the augmentation-induced latent factors could be highly entangled with the original graph, thus it is more difficult to discriminate the task-relevant information from irrelevant information. Consequently, the learned representation is either brittle or unilluminating. In light of this, we introduce the Adversarial Cross-View Disentangled Graph Contrastive Learning (ACDGCL), which follows the information bottleneck principle to learn minimal yet sufficient representations from graph data. To be specific, our proposed model elicits the augmentation-invariant and augmentation-dependent factors separately. Except for the conventional contrastive loss which guarantees the consistency and sufficiency of the representations across different contrastive views, we introduce a cross-view reconstruction mechanism to pursue the representation disentanglement. Besides, an adversarial view is added as the third view of contrastive loss to enhance model robustness. We empirically demonstrate that our proposed model outperforms the state-of-the-arts on graph classification task over multiple benchmark datasets.
Image Compressed Sensing with Multi-scale Dilated Convolutional Neural Network
Sep 28, 2022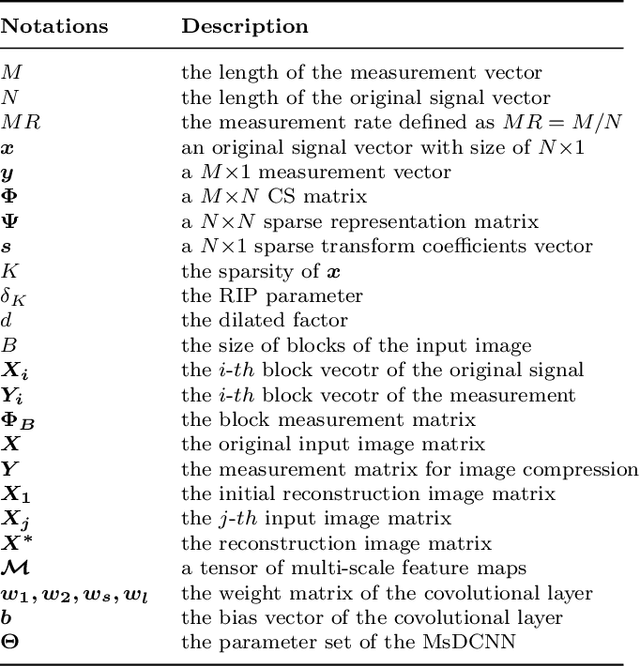
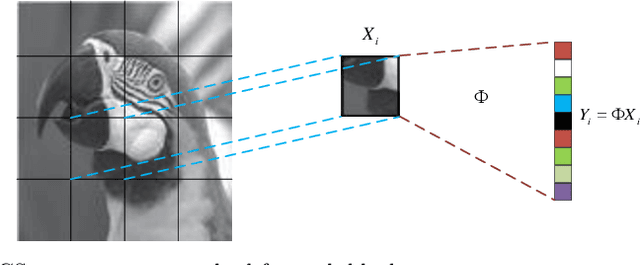
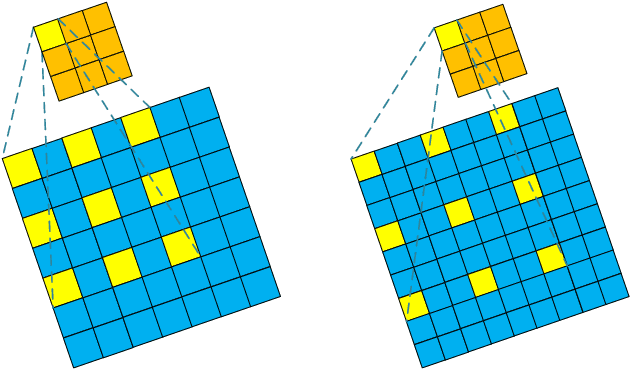
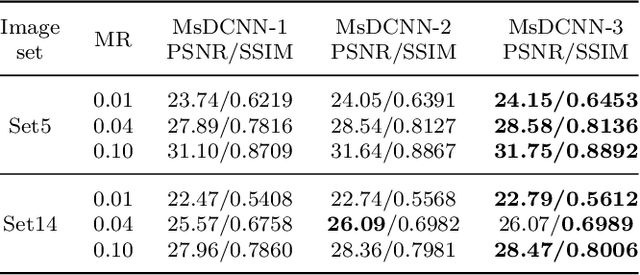
Deep Learning (DL) based Compressed Sensing (CS) has been applied for better performance of image reconstruction than traditional CS methods. However, most existing DL methods utilize the block-by-block measurement and each measurement block is restored separately, which introduces harmful blocking effects for reconstruction. Furthermore, the neuronal receptive fields of those methods are designed to be the same size in each layer, which can only collect single-scale spatial information and has a negative impact on the reconstruction process. This paper proposes a novel framework named Multi-scale Dilated Convolution Neural Network (MsDCNN) for CS measurement and reconstruction. During the measurement period, we directly obtain all measurements from a trained measurement network, which employs fully convolutional structures and is jointly trained with the reconstruction network from the input image. It needn't be cut into blocks, which effectively avoids the block effect. During the reconstruction period, we propose the Multi-scale Feature Extraction (MFE) architecture to imitate the human visual system to capture multi-scale features from the same feature map, which enhances the image feature extraction ability of the framework and improves the performance of image reconstruction. In the MFE, there are multiple parallel convolution channels to obtain multi-scale feature information. Then the multi-scale features information is fused and the original image is reconstructed with high quality. Our experimental results show that the proposed method performs favorably against the state-of-the-art methods in terms of PSNR and SSIM.
Can Information Flows Suggest Targets for Interventions in Neural Circuits?
Nov 09, 2021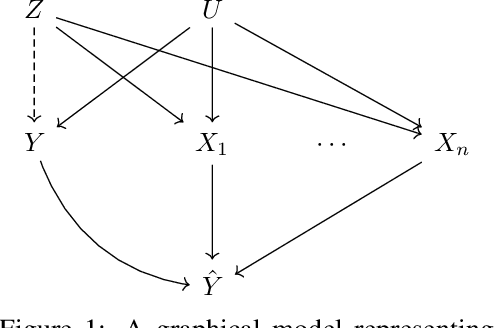
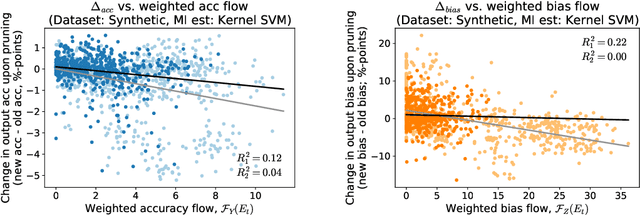
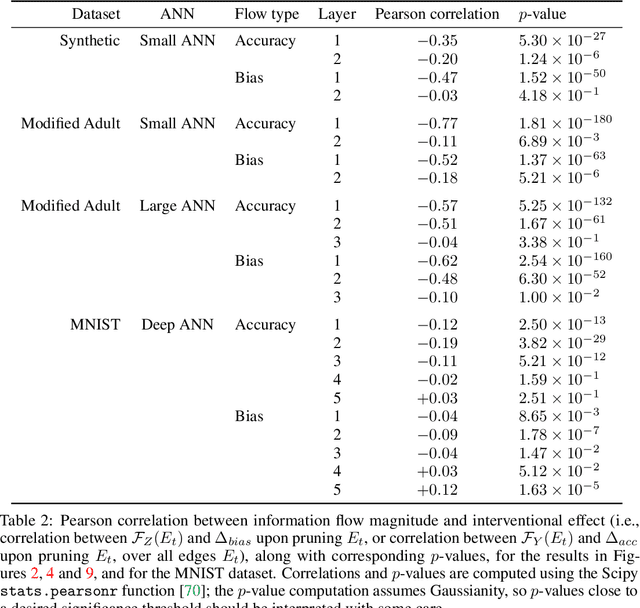
Motivated by neuroscientific and clinical applications, we empirically examine whether observational measures of information flow can suggest interventions. We do so by performing experiments on artificial neural networks in the context of fairness in machine learning, where the goal is to induce fairness in the system through interventions. Using our recently developed $M$-information flow framework, we measure the flow of information about the true label (responsible for accuracy, and hence desirable), and separately, the flow of information about a protected attribute (responsible for bias, and hence undesirable) on the edges of a trained neural network. We then compare the flow magnitudes against the effect of intervening on those edges by pruning. We show that pruning edges that carry larger information flows about the protected attribute reduces bias at the output to a greater extent. This demonstrates that $M$-information flow can meaningfully suggest targets for interventions, answering the title's question in the affirmative. We also evaluate bias-accuracy tradeoffs for different intervention strategies, to analyze how one might use estimates of desirable and undesirable information flows (here, accuracy and bias flows) to inform interventions that preserve the former while reducing the latter.
RIS Design to Optimize the CRB for Source Localization
Oct 01, 2022
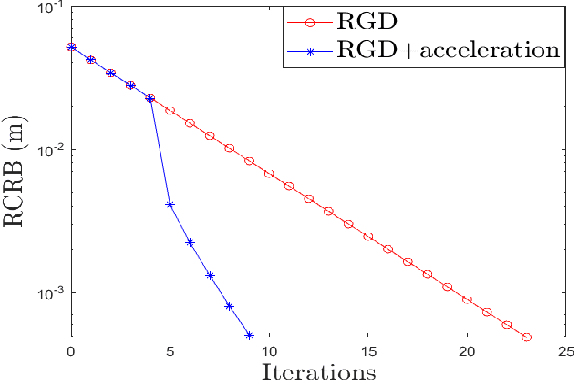
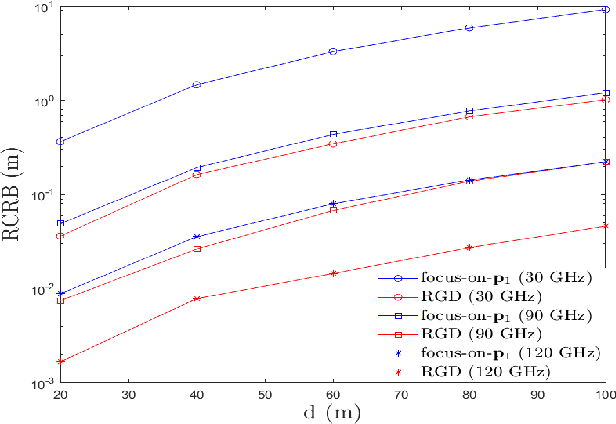
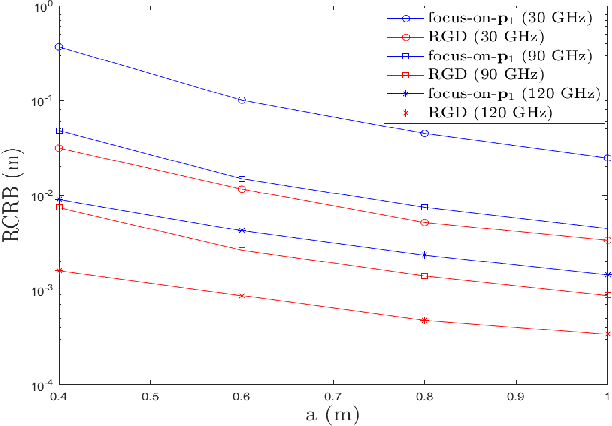
Reconfigurable Intelligent Surface (RIS) plays a pivotal role in enhancing source localization accuracy. Based on the information inequality of Fisher information analyses, the Cram\'{e}r-Rao Bound (CRB) of the localization error can be used to evaluate the localization accuracy for a given set of RIS coefficients. However, there is a lack of research in optimizing these RIS coefficients to decrease the CRB under the constraint imposed by the RIS hardware. In this paper, we adopt the manifold optimization method to derive the locally optimal CRB of the localization error, where the RIS coefficients are restricted to lie on the complex circle manifold. Specifically, the Wirtinger derivatives are calculated in the gradient descent part, and the Riemannian nonlinear acceleration technique is employed to speed up the convergence rate. Simulation results show that the proposed method can yield the locally optimal RIS coefficients and can significantly decrease the CRB of localization error. Moreover, the iteration number can be reduced by the acceleration technique.
Weighted MMSE Precoding for Constructive Interference Region
Oct 01, 2022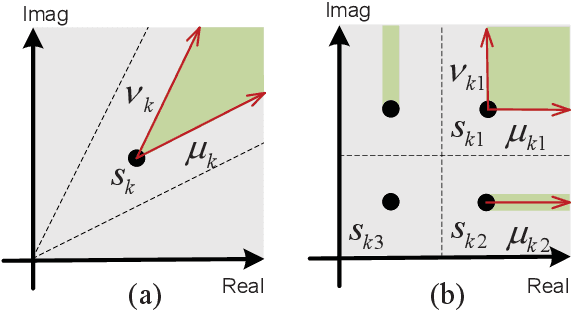
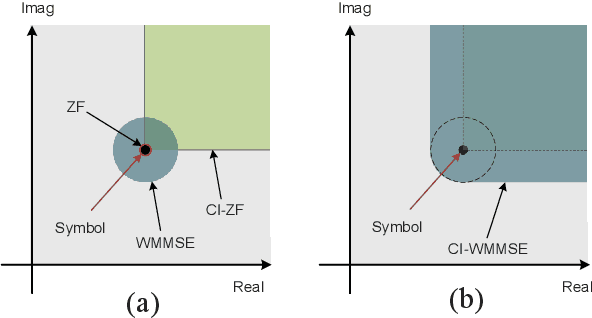
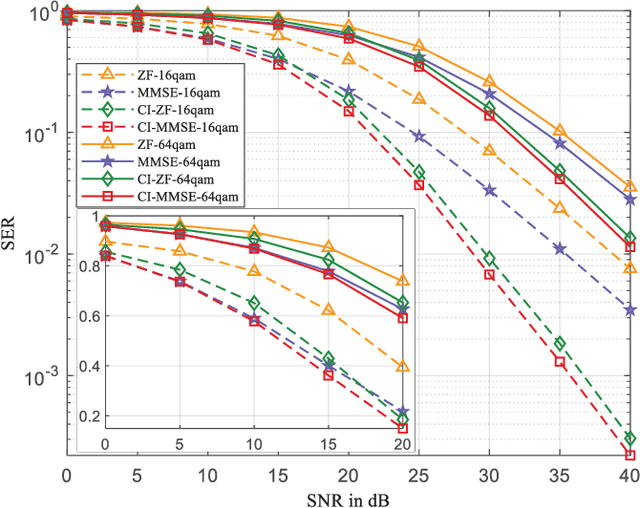
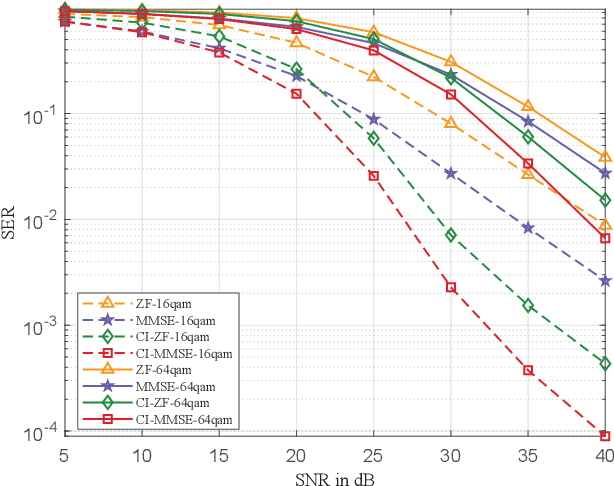
In this paper, we propose a symbol-level precoding (SLP) design that aims to minimize the weighted mean square error between the received signal and the constellation point located in the constructive interference region (CIR). Unlike most existing SLP schemes that rely on channel state information (CSI) only, the proposed scheme exploits both CSI and the distribution information of the noise to achieve improved performance. We firstly propose a simple generic description of CIR that facilitates the subsequent SLP design. Such an objective can further be formulated as a nonnegative least squares (NNLS) problem, which can be solved efficiently by the active-set algorithm. Furthermore, the weighted minimum mean square error (WMMSE) precoding and the existing SLP can be easily verified as special cases of the proposed scheme. Finally, simulation results show that the proposed precoding outperforms the state-of-the-art SLP schemes in full signal-to-noise ratio ranges in both uncoded and coded systems without additional complexity over conventional SLP.
Privacy-preserving Automatic Speaker Diarization
Oct 26, 2022
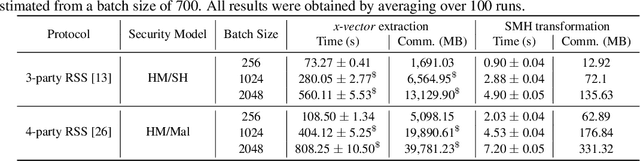
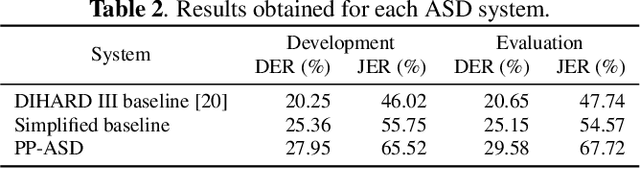
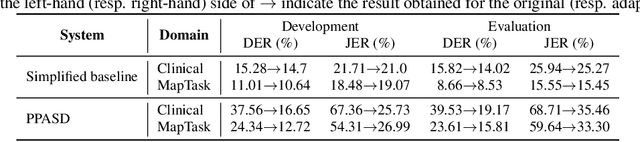
Automatic Speaker Diarization (ASD) is an enabling technology with numerous applications, which deals with recordings of multiple speakers, raising special concerns in terms of privacy. In fact, in remote settings, where recordings are shared with a server, clients relinquish not only the privacy of their conversation, but also of all the information that can be inferred from their voices. However, to the best of our knowledge, the development of privacy-preserving ASD systems has been overlooked thus far. In this work, we tackle this problem using a combination of two cryptographic techniques, Secure Multiparty Computation (SMC) and Secure Modular Hashing, and apply them to the two main steps of a cascaded ASD system: speaker embedding extraction and agglomerative hierarchical clustering. Our system is able to achieve a reasonable trade-off between performance and efficiency, presenting real-time factors of 1.1 and 1.6, for two different SMC security settings.
From Obstacle Avoidance To Motion Learning Using Local Rotation of Dynamical Systems
Oct 26, 2022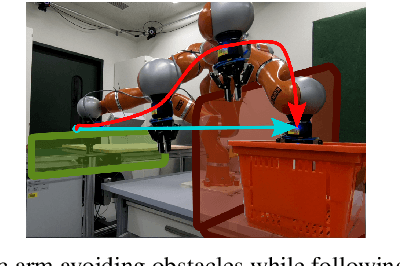
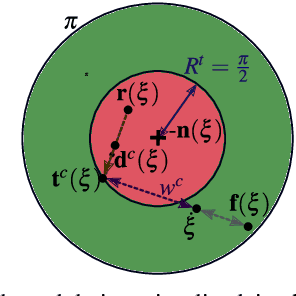
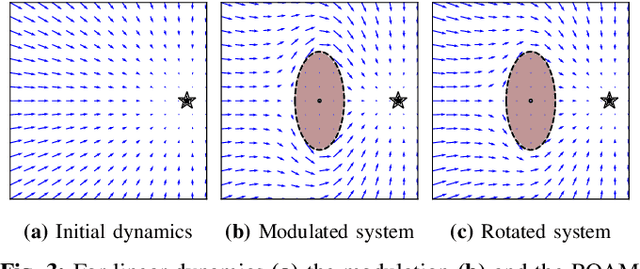
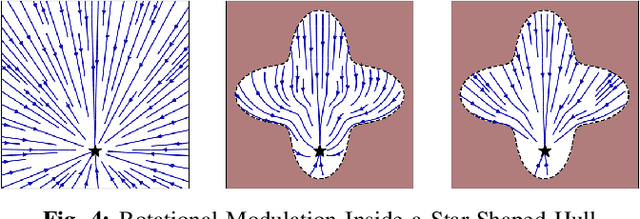
In robotics motion is often described from an external perspective, i.e., we give information on the obstacle motion in a mathematical manner with respect to a specific (often inertial) reference frame. In the current work, we propose to describe the robotic motion with respect to the robot itself. Similar to how we give instructions to each other (go straight, and then after multiple meters move left, and then a sharp turn right.), we give the instructions to a robot as a relative rotation. We first introduce an obstacle avoidance framework that allows avoiding star-shaped obstacles while trying to stay close to an initial (linear or nonlinear) dynamical system. The framework of the local rotation is extended to motion learning. Automated clustering defines regions of local stability, for which the precise dynamics are individually learned. The framework has been applied to the LASA-handwriting dataset and shows promising results.