 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
Mar 04, 2024
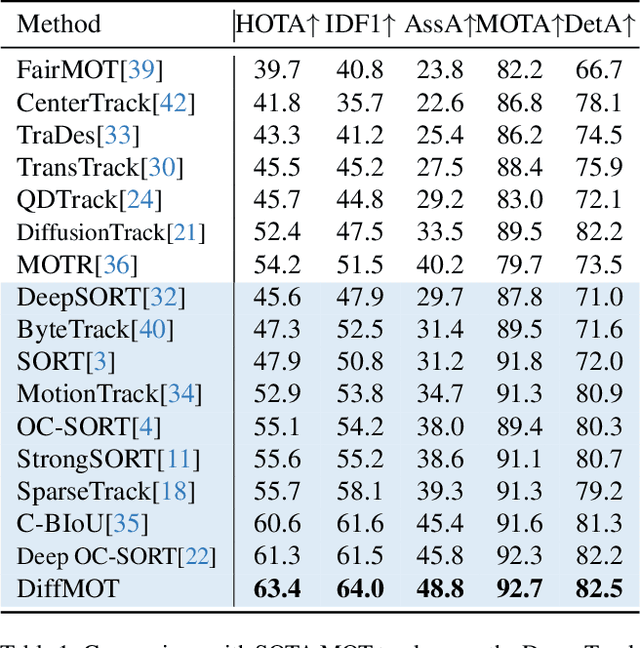
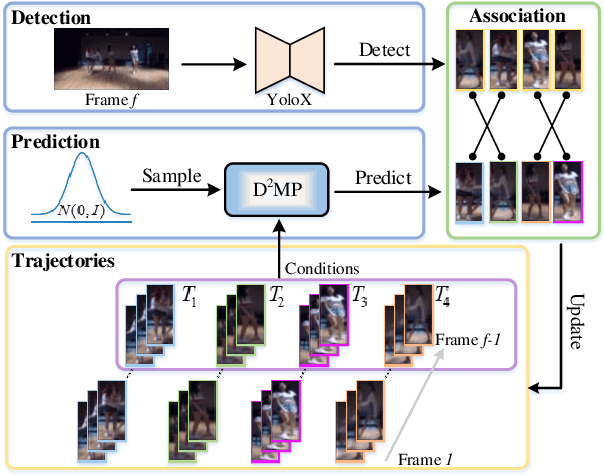
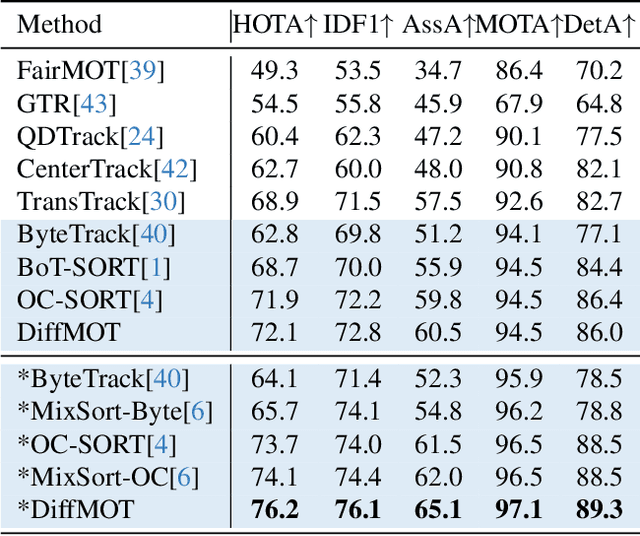
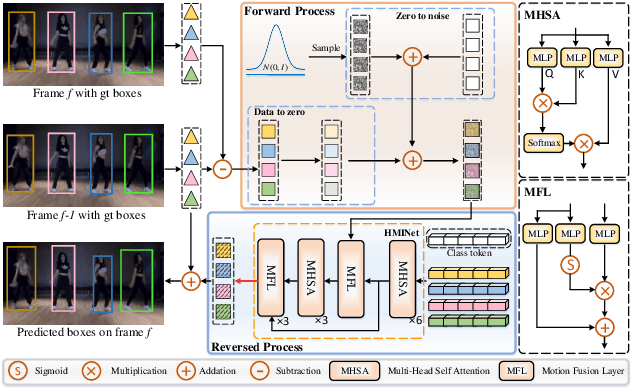
In Multiple Object Tracking, objects often exhibit non-linear motion of acceleration and deceleration, with irregular direction changes. Tacking-by-detection (TBD) with Kalman Filter motion prediction works well in pedestrian-dominant scenarios but falls short in complex situations when multiple objects perform non-linear and diverse motion simultaneously. To tackle the complex non-linear motion, we propose a real-time diffusion-based MOT approach named DiffMOT. Specifically, for the motion predictor component, we propose a novel Decoupled Diffusion-based Motion Predictor (D MP). It models the entire distribution of various motion presented by the data as a whole. It also predicts an individual object's motion conditioning on an individual's historical motion information. Furthermore, it optimizes the diffusion process with much less sampling steps. As a MOT tracker, the DiffMOT is real-time at 22.7FPS, and also outperforms the state-of-the-art on DanceTrack and SportsMOT datasets with 63.4 and 76.2 in HOTA metrics, respectively. To the best of our knowledge, DiffMOT is the first to introduce a diffusion probabilistic model into the MOT to tackle non-linear motion prediction.
FENICE: Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction
Mar 04, 2024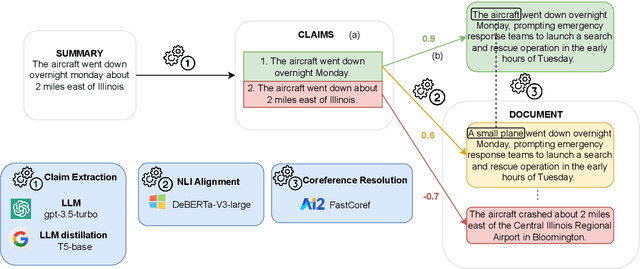
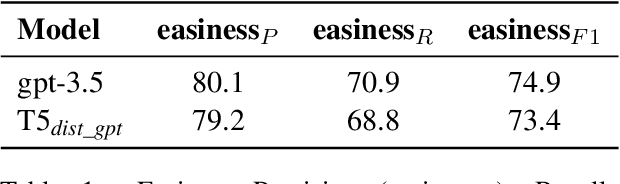
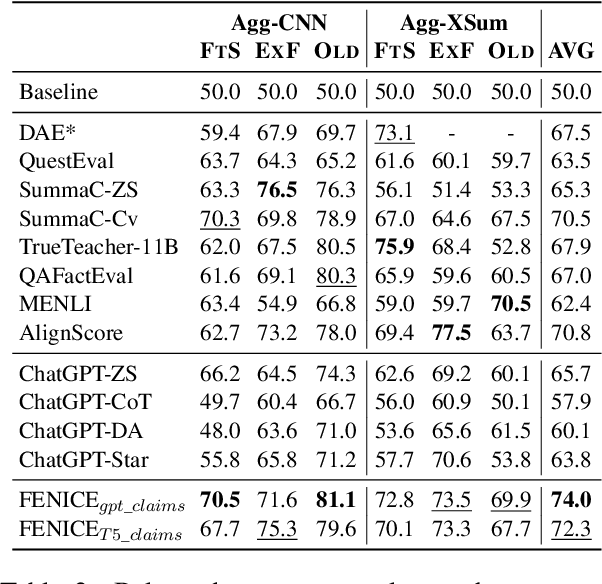

Recent advancements in text summarization, particularly with the advent of Large Language Models (LLMs), have shown remarkable performance. However, a notable challenge persists as a substantial number of automatically-generated summaries exhibit factual inconsistencies, such as hallucinations. In response to this issue, various approaches for the evaluation of consistency for summarization have emerged. Yet, these newly-introduced metrics face several limitations, including lack of interpretability, focus on short document summaries (e.g., news articles), and computational impracticality, especially for LLM-based metrics. To address these shortcomings, we propose Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction (FENICE), a more interpretable and efficient factuality-oriented metric. FENICE leverages an NLI-based alignment between information in the source document and a set of atomic facts, referred to as claims, extracted from the summary. Our metric sets a new state of the art on AGGREFACT, the de-facto benchmark for factuality evaluation. Moreover, we extend our evaluation to a more challenging setting by conducting a human annotation process of long-form summarization.
Machine and deep learning methods for predicting 3D genome organization
Mar 04, 2024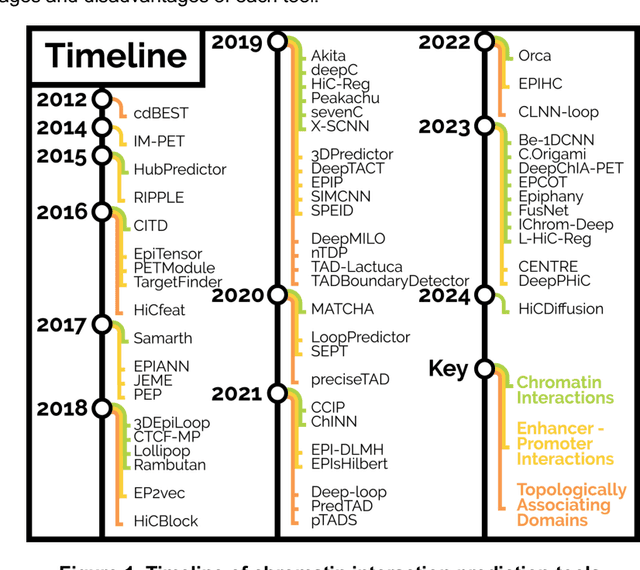
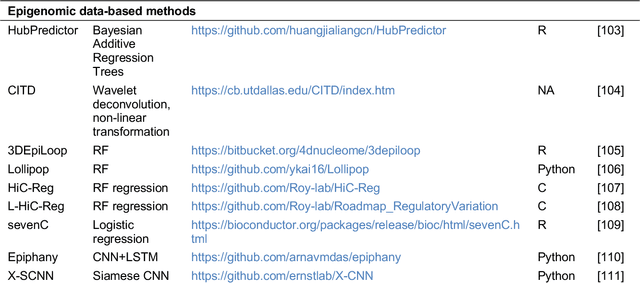

Three-Dimensional (3D) chromatin interactions, such as enhancer-promoter interactions (EPIs), loops, Topologically Associating Domains (TADs), and A/B compartments play critical roles in a wide range of cellular processes by regulating gene expression. Recent development of chromatin conformation capture technologies has enabled genome-wide profiling of various 3D structures, even with single cells. However, current catalogs of 3D structures remain incomplete and unreliable due to differences in technology, tools, and low data resolution. Machine learning methods have emerged as an alternative to obtain missing 3D interactions and/or improve resolution. Such methods frequently use genome annotation data (ChIP-seq, DNAse-seq, etc.), DNA sequencing information (k-mers, Transcription Factor Binding Site (TFBS) motifs), and other genomic properties to learn the associations between genomic features and chromatin interactions. In this review, we discuss computational tools for predicting three types of 3D interactions (EPIs, chromatin interactions, TAD boundaries) and analyze their pros and cons. We also point out obstacles of computational prediction of 3D interactions and suggest future research directions.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024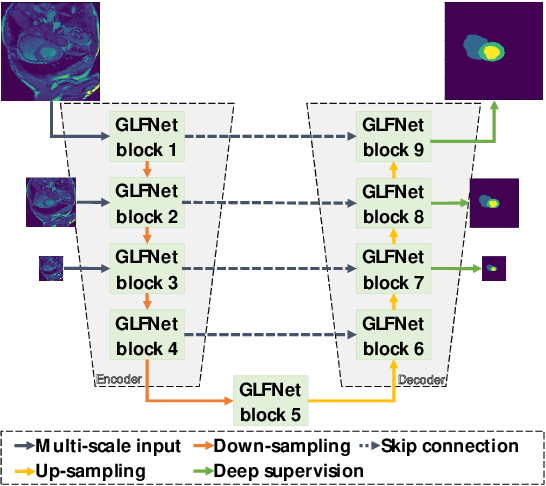
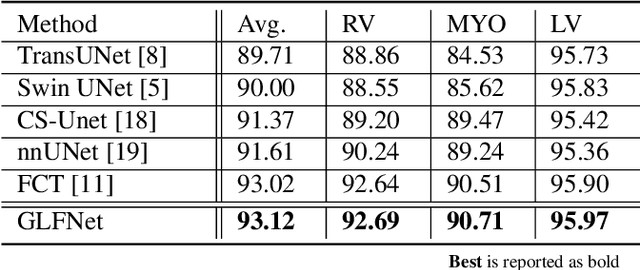
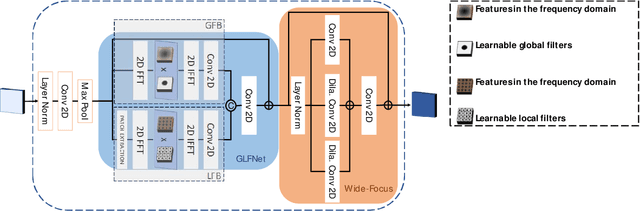
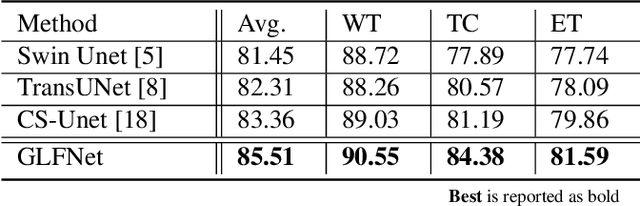
We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.
ChartReformer: Natural Language-Driven Chart Image Editing
Mar 01, 2024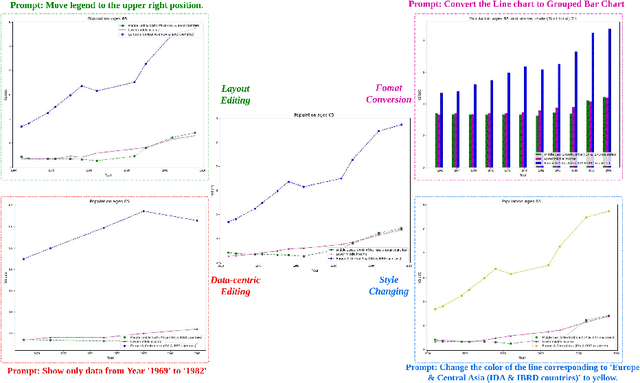
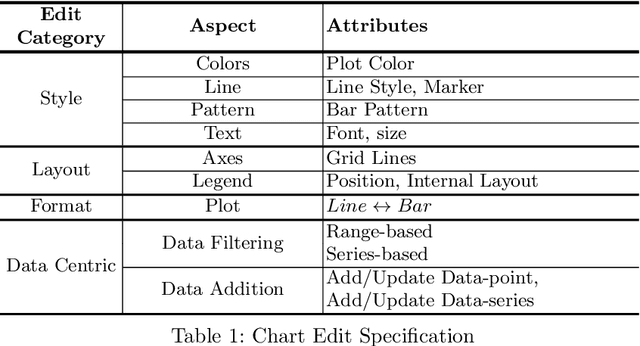
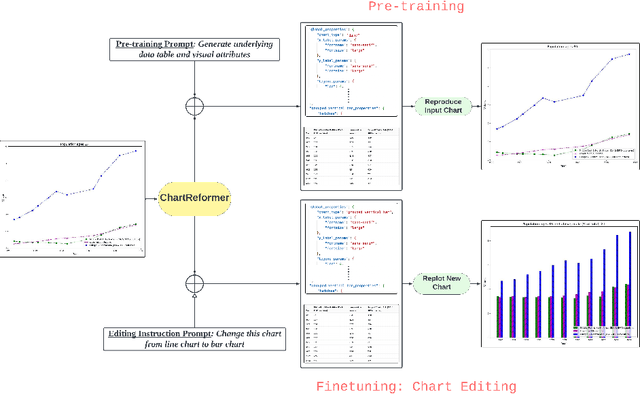
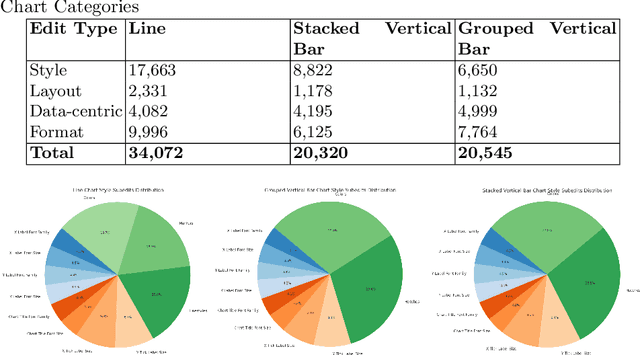
Chart visualizations are essential for data interpretation and communication; however, most charts are only accessible in image format and lack the corresponding data tables and supplementary information, making it difficult to alter their appearance for different application scenarios. To eliminate the need for original underlying data and information to perform chart editing, we propose ChartReformer, a natural language-driven chart image editing solution that directly edits the charts from the input images with the given instruction prompts. The key in this method is that we allow the model to comprehend the chart and reason over the prompt to generate the corresponding underlying data table and visual attributes for new charts, enabling precise edits. Additionally, to generalize ChartReformer, we define and standardize various types of chart editing, covering style, layout, format, and data-centric edits. The experiments show promising results for the natural language-driven chart image editing.
Crafting Knowledge: Exploring the Creative Mechanisms of Chat-Based Search Engines
Feb 29, 2024In the domain of digital information dissemination, search engines act as pivotal conduits linking information seekers with providers. The advent of chat-based search engines utilizing Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), exemplified by Bing Chat, marks an evolutionary leap in the search ecosystem. They demonstrate metacognitive abilities in interpreting web information and crafting responses with human-like understanding and creativity. Nonetheless, the intricate nature of LLMs renders their "cognitive" processes opaque, challenging even their designers' understanding. This research aims to dissect the mechanisms through which an LLM-powered chat-based search engine, specifically Bing Chat, selects information sources for its responses. To this end, an extensive dataset has been compiled through engagements with New Bing, documenting the websites it cites alongside those listed by the conventional search engine. Employing natural language processing (NLP) techniques, the research reveals that Bing Chat exhibits a preference for content that is not only readable and formally structured, but also demonstrates lower perplexity levels, indicating a unique inclination towards text that is predictable by the underlying LLM. Further enriching our analysis, we procure an additional dataset through interactions with the GPT-4 based knowledge retrieval API, unveiling a congruent text preference between the RAG API and Bing Chat. This consensus suggests that these text preferences intrinsically emerge from the underlying language models, rather than being explicitly crafted by Bing Chat's developers. Moreover, our investigation documents a greater similarity among websites cited by RAG technologies compared to those ranked highest by conventional search engines.
Leveraging Diverse Modeling Contexts with Collaborating Learning for Neural Machine Translation
Feb 28, 2024Autoregressive (AR) and Non-autoregressive (NAR) models are two types of generative models for Neural Machine Translation (NMT). AR models predict tokens in a word-by-word manner and can effectively capture the distribution of real translations. NAR models predict tokens by extracting bidirectional contextual information which can improve the inference speed but they suffer from performance degradation. Previous works utilized AR models to enhance NAR models by reducing the training data's complexity or incorporating the global information into AR models by virtue of NAR models. However, those investigated methods only take advantage of the contextual information of a single type of model while neglecting the diversity in the contextual information that can be provided by different types of models. In this paper, we propose a novel generic collaborative learning method, DCMCL, where AR and NAR models are treated as collaborators instead of teachers and students. To hierarchically leverage the bilateral contextual information, token-level mutual learning and sequence-level contrastive learning are adopted between AR and NAR models. Extensive experiments on four widely used benchmarks show that the proposed DCMCL method can simultaneously improve both AR and NAR models with up to 1.38 and 2.98 BLEU scores respectively, and can also outperform the current best-unified model with up to 0.97 BLEU scores for both AR and NAR decoding.
COOL: A Conjoint Perspective on Spatio-Temporal Graph Neural Network for Traffic Forecasting
Mar 02, 2024

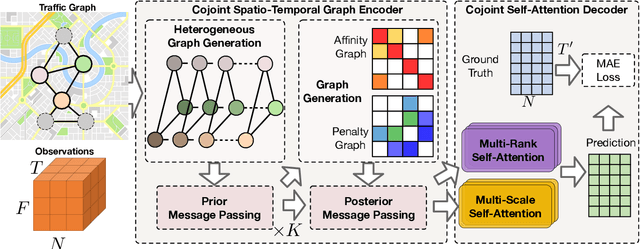
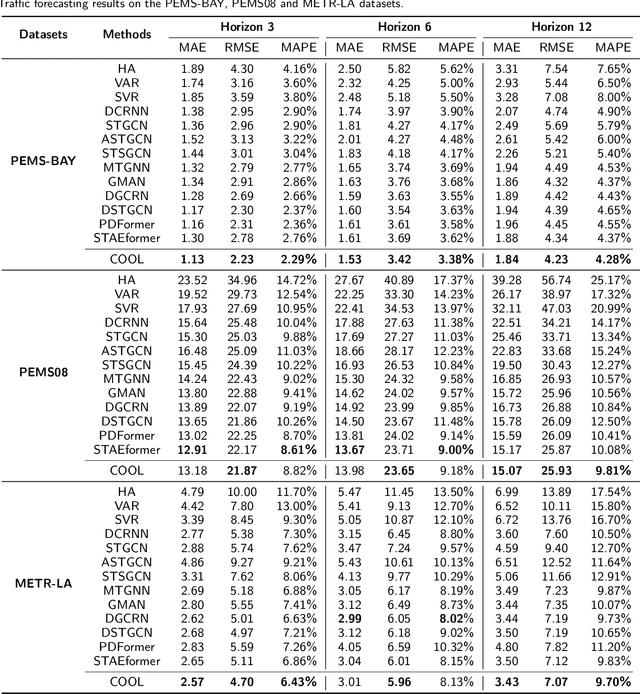
This paper investigates traffic forecasting, which attempts to forecast the future state of traffic based on historical situations. This problem has received ever-increasing attention in various scenarios and facilitated the development of numerous downstream applications such as urban planning and transportation management. However, the efficacy of existing methods remains sub-optimal due to their tendency to model temporal and spatial relationships independently, thereby inadequately accounting for complex high-order interactions of both worlds. Moreover, the diversity of transitional patterns in traffic forecasting makes them challenging to capture for existing approaches, warranting a deeper exploration of their diversity. Toward this end, this paper proposes Conjoint Spatio-Temporal graph neural network (abbreviated as COOL), which models heterogeneous graphs from prior and posterior information to conjointly capture high-order spatio-temporal relationships. On the one hand, heterogeneous graphs connecting sequential observation are constructed to extract composite spatio-temporal relationships via prior message passing. On the other hand, we model dynamic relationships using constructed affinity and penalty graphs, which guide posterior message passing to incorporate complementary semantic information into node representations. Moreover, to capture diverse transitional properties to enhance traffic forecasting, we propose a conjoint self-attention decoder that models diverse temporal patterns from both multi-rank and multi-scale views. Experimental results on four popular benchmark datasets demonstrate that our proposed COOL provides state-of-the-art performance compared with the competitive baselines.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024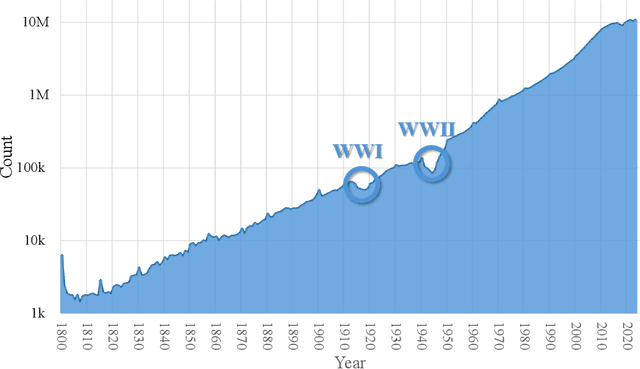
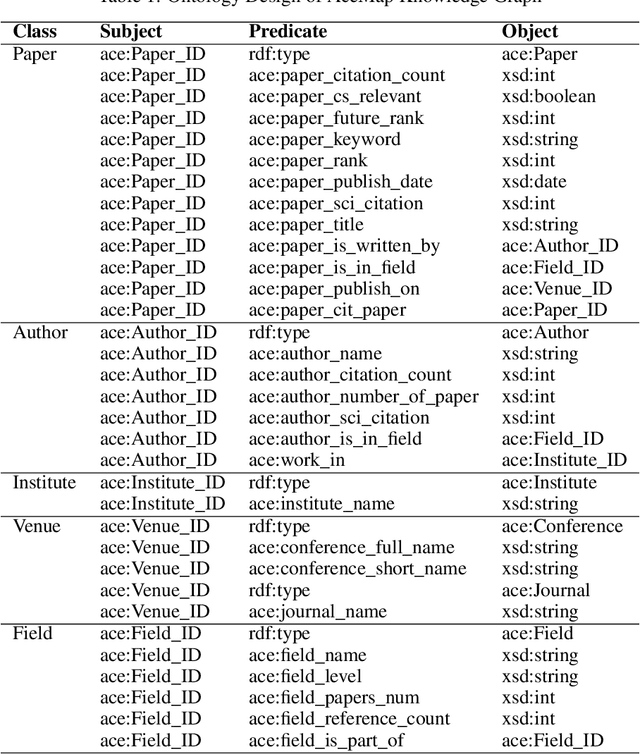
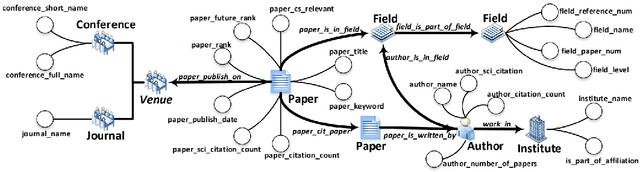
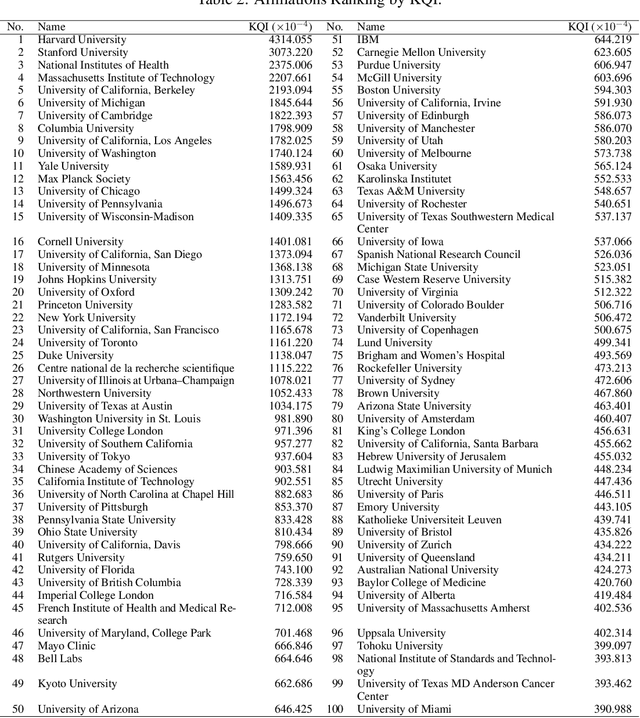
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
BiVRec: Bidirectional View-based Multimodal Sequential Recommendation
Feb 27, 2024The integration of multimodal information into sequential recommender systems has attracted significant attention in recent research. In the initial stages of multimodal sequential recommendation models, the mainstream paradigm was ID-dominant recommendations, wherein multimodal information was fused as side information. However, due to their limitations in terms of transferability and information intrusion, another paradigm emerged, wherein multimodal features were employed directly for recommendation, enabling recommendation across datasets. Nonetheless, it overlooked user ID information, resulting in low information utilization and high training costs. To this end, we propose an innovative framework, BivRec, that jointly trains the recommendation tasks in both ID and multimodal views, leveraging their synergistic relationship to enhance recommendation performance bidirectionally. To tackle the information heterogeneity issue, we first construct structured user interest representations and then learn the synergistic relationship between them. Specifically, BivRec comprises three modules: Multi-scale Interest Embedding, comprehensively modeling user interests by expanding user interaction sequences with multi-scale patching; Intra-View Interest Decomposition, constructing highly structured interest representations using carefully designed Gaussian attention and Cluster attention; and Cross-View Interest Learning, learning the synergistic relationship between the two recommendation views through coarse-grained overall semantic similarity and fine-grained interest allocation similarity BiVRec achieves state-of-the-art performance on five datasets and showcases various practical advantages.