 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Framework to Evaluate Independent Component Analysis applied to EEG signal: testing on the Picard algorithm
Oct 16, 2022
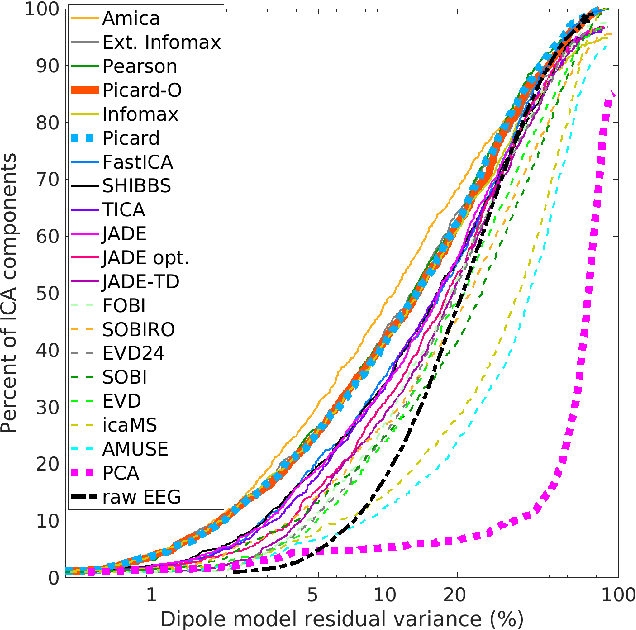
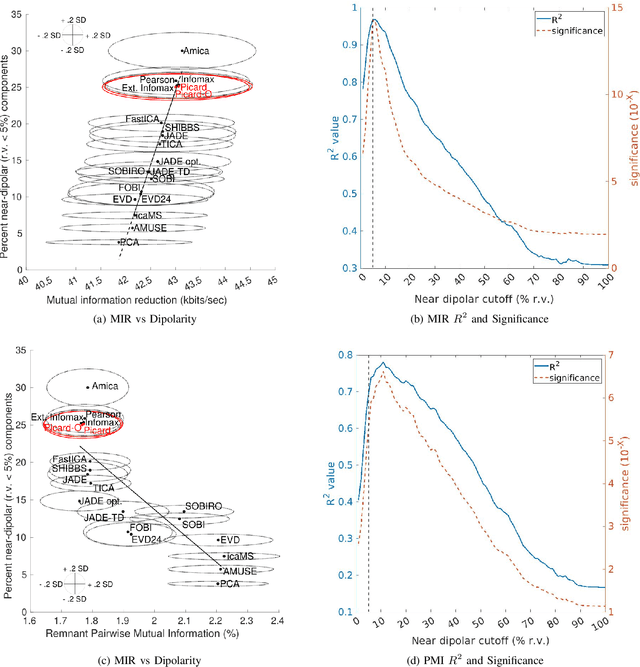
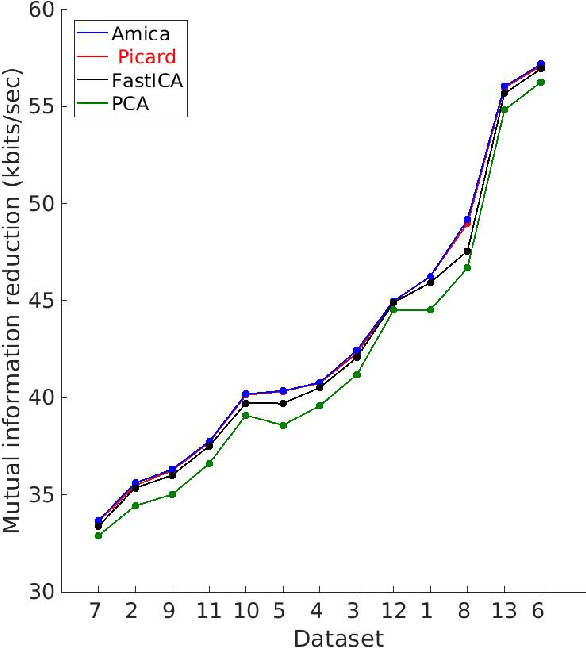
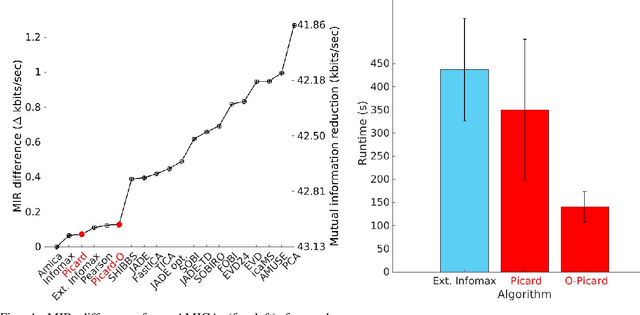
Independent component analysis (ICA), is a blind source separation method that is becoming increasingly used to separate brain and non-brain related activities in electroencephalographic (EEG) and other electrophysiological recordings. It can be used to extract effective brain source activities and estimate their cortical source areas, and is commonly used in machine learning applications to classify EEG artifacts. Previously, we compared results of decomposing 13 71-channel scalp EEG datasets using 22 ICA and other blind source separation (BSS) algorithms. We are now making this framework available to the scientific community and, in the process of its release are testing a recent ICA algorithm (Picard) not included in the previous assay. Our test framework uses three main metrics to assess BSS performance: Pairwise Mutual Information (PMI) between scalp channel pairs; PMI remaining between component pairs after decomposition; and, the complete (not pairwise) Mutual Information Reduction (MIR) produced by each algorithm. We also measure the "dipolarity" of the scalp projection maps for the decomposed component, defined by the number of components whose scalp projection maps nearly match the projection of a single equivalent dipole. Within this framework, Picard performed similarly to Infomax ICA. This is not surprising since Picard is a type of Infomax algorithm that uses the L-BFGS method for faster convergence, in contrast to Infomax and Extended Infomax (runica) which use gradient descent. Our results show that Picard performs similarly to Infomax and, likewise, better than other BSS algorithms, excepting the more computationally complex AMICA. We have released the source code of our framework and the test data through GitHub.
Retrieval Augmentation for T5 Re-ranker using External Sources
Oct 11, 2022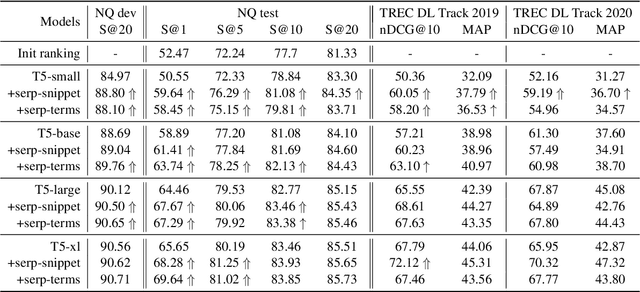
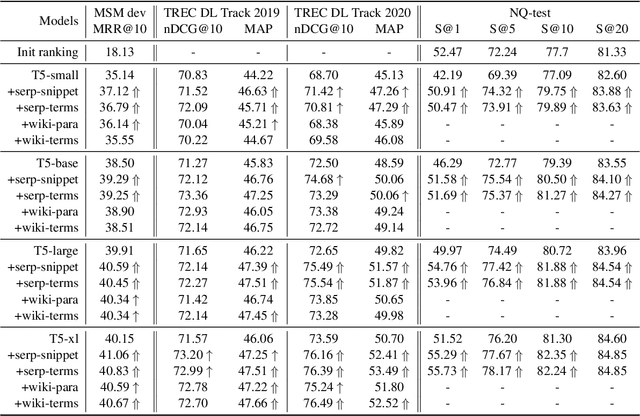
Retrieval augmentation has shown promising improvements in different tasks. However, whether such augmentation can assist a large language model based re-ranker remains unclear. We investigate how to augment T5-based re-rankers using high-quality information retrieved from two external corpora -- a commercial web search engine and Wikipedia. We empirically demonstrate how retrieval augmentation can substantially improve the effectiveness of T5-based re-rankers for both in-domain and zero-shot out-of-domain re-ranking tasks.
Better Few-Shot Relation Extraction with Label Prompt Dropout
Oct 25, 2022
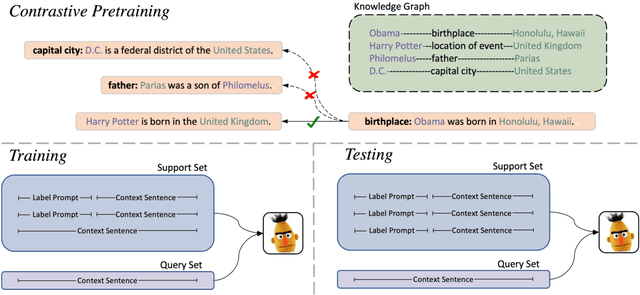
Few-shot relation extraction aims to learn to identify the relation between two entities based on very limited training examples. Recent efforts found that textual labels (i.e., relation names and relation descriptions) could be extremely useful for learning class representations, which will benefit the few-shot learning task. However, what is the best way to leverage such label information in the learning process is an important research question. Existing works largely assume such textual labels are always present during both learning and prediction. In this work, we argue that such approaches may not always lead to optimal results. Instead, we present a novel approach called label prompt dropout, which randomly removes label descriptions in the learning process. Our experiments show that our approach is able to lead to improved class representations, yielding significantly better results on the few-shot relation extraction task.
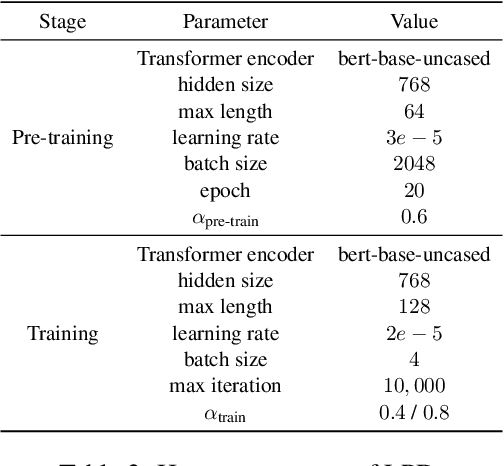
DialogConv: A Lightweight Fully Convolutional Network for Multi-view Response Selection
Oct 25, 2022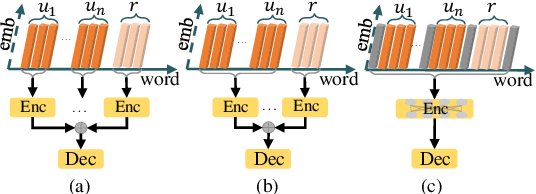
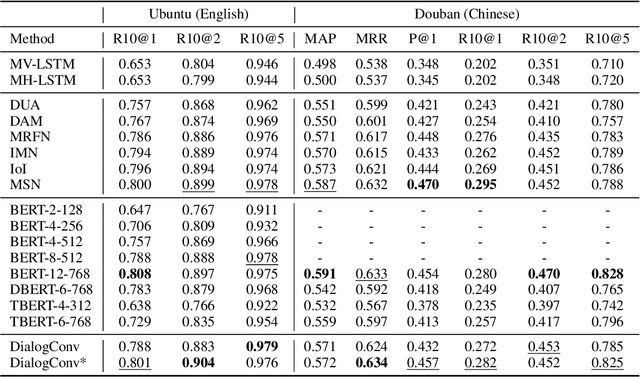
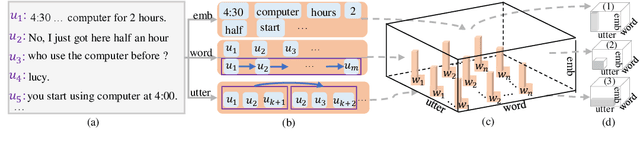
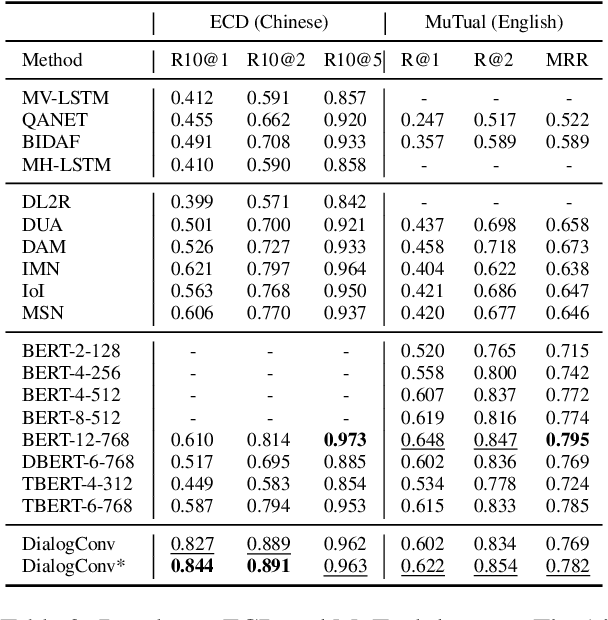
Current end-to-end retrieval-based dialogue systems are mainly based on Recurrent Neural Networks or Transformers with attention mechanisms. Although promising results have been achieved, these models often suffer from slow inference or huge number of parameters. In this paper, we propose a novel lightweight fully convolutional architecture, called DialogConv, for response selection. DialogConv is exclusively built on top of convolution to extract matching features of context and response. Dialogues are modeled in 3D views, where DialogConv performs convolution operations on embedding view, word view and utterance view to capture richer semantic information from multiple contextual views. On the four benchmark datasets, compared with state-of-the-art baselines, DialogConv is on average about 8.5x smaller in size, and 79.39x and 10.64x faster on CPU and GPU devices, respectively. At the same time, DialogConv achieves the competitive effectiveness of response selection.
Augmentations in Hypergraph Contrastive Learning: Fabricated and Generative
Oct 07, 2022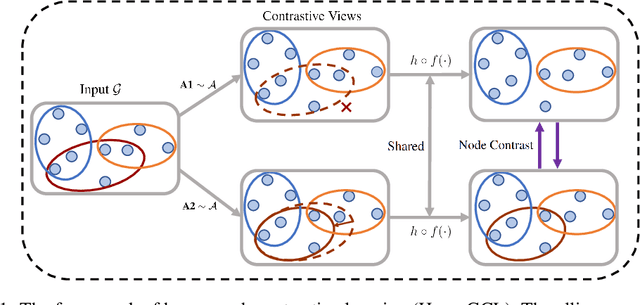

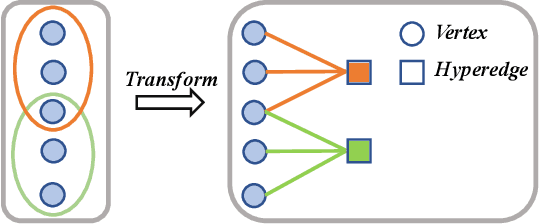

This paper targets at improving the generalizability of hypergraph neural networks in the low-label regime, through applying the contrastive learning approach from images/graphs (we refer to it as HyperGCL). We focus on the following question: How to construct contrastive views for hypergraphs via augmentations? We provide the solutions in two folds. First, guided by domain knowledge, we fabricate two schemes to augment hyperedges with higher-order relations encoded, and adopt three vertex augmentation strategies from graph-structured data. Second, in search of more effective views in a data-driven manner, we for the first time propose a hypergraph generative model to generate augmented views, and then an end-to-end differentiable pipeline to jointly learn hypergraph augmentations and model parameters. Our technical innovations are reflected in designing both fabricated and generative augmentations of hypergraphs. The experimental findings include: (i) Among fabricated augmentations in HyperGCL, augmenting hyperedges provides the most numerical gains, implying that higher-order information in structures is usually more downstream-relevant; (ii) Generative augmentations do better in preserving higher-order information to further benefit generalizability; (iii) HyperGCL also boosts robustness and fairness in hypergraph representation learning. Codes are released at https://github.com/weitianxin/HyperGCL.
Mass-Editing Memory in a Transformer
Oct 13, 2022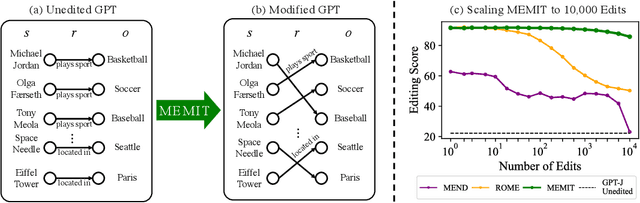
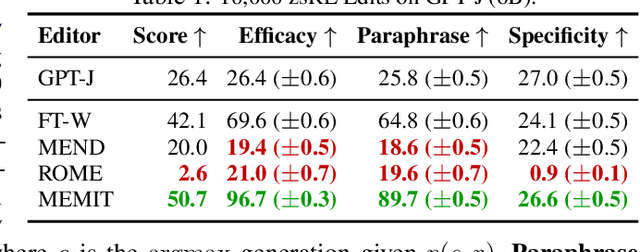
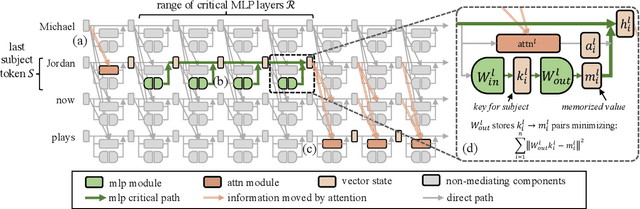
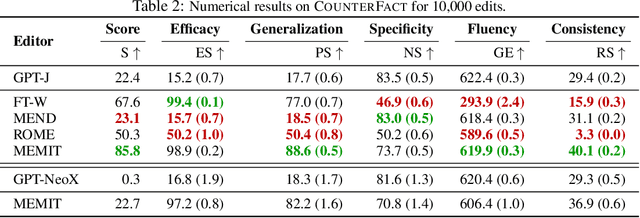
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop MEMIT, a method for directly updating a language model with many memories, demonstrating experimentally that it can scale up to thousands of associations for GPT-J (6B) and GPT-NeoX (20B), exceeding prior work by orders of magnitude. Our code and data are at https://memit.baulab.info.
Linear Guardedness and its Implications
Oct 18, 2022
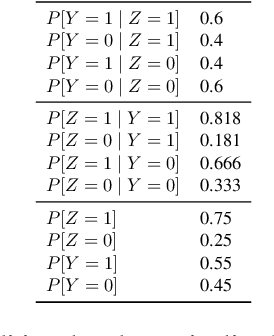
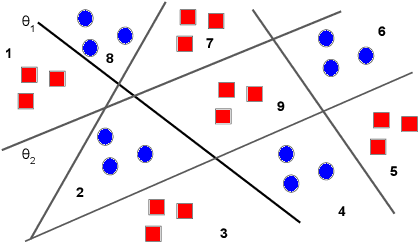
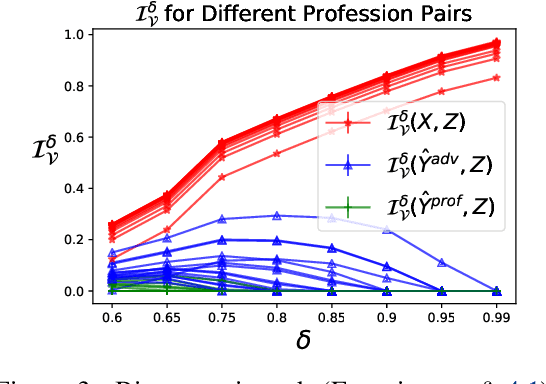
Previous work on concept identification in neural representations has focused on linear concept subspaces and their neutralization. In this work, we formulate the notion of linear guardedness -- the inability to directly predict a given concept from the representation -- and study its implications. We show that, in the binary case, the neutralized concept cannot be recovered by an additional linear layer. However, we point out that -- contrary to what was implicitly argued in previous works -- multiclass softmax classifiers can be constructed that indirectly recover the concept. Thus, linear guardedness does not guarantee that linear classifiers do not utilize the neutralized concepts, shedding light on theoretical limitations of linear information removal methods.
DC-cycleGAN: Bidirectional CT-to-MR Synthesis from Unpaired Data
Nov 02, 2022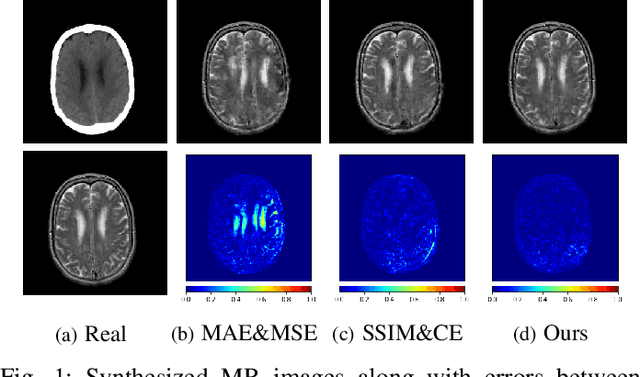
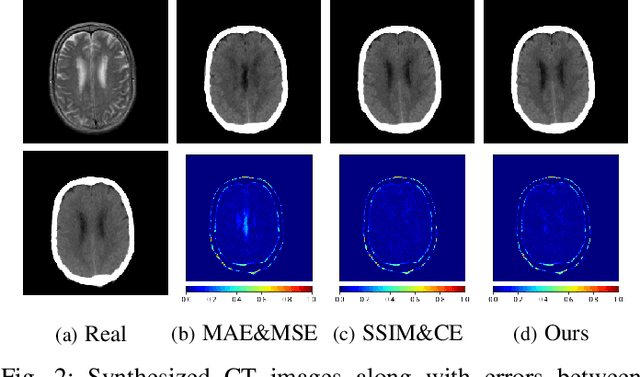
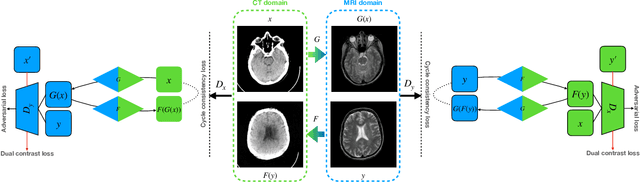
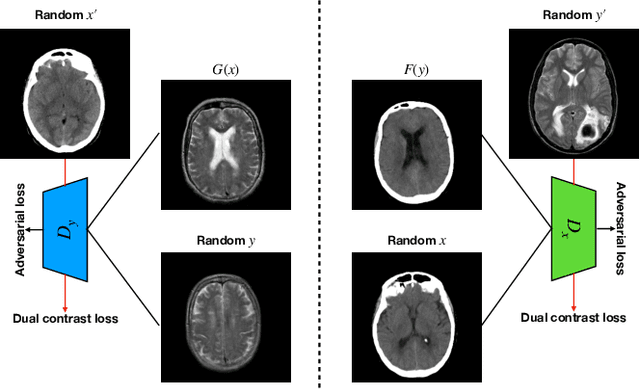
Magnetic resonance (MR) and computer tomography (CT) images are two typical types of medical images that provide mutually-complementary information for accurate clinical diagnosis and treatment. However, obtaining both images may be limited due to some considerations such as cost, radiation dose and modality missing. Recently, medical image synthesis has aroused gaining research interest to cope with this limitation. In this paper, we propose a bidirectional learning model, denoted as dual contrast cycleGAN (DC-cycleGAN), to synthesis medical images from unpaired data. Specifically, a dual contrast loss is introduced into the discriminators to indirectly build constraints between MR and CT images by taking the advantage of samples from the source domain as negative sample and enforce the synthetic images fall far away from the source domain. In addition, cross entropy and structural similarity index (SSIM) are integrated into the cycleGAN in order to consider both luminance and structure of samples when synthesizing images. The experimental results indicates that DC-cycleGAN is able to produce promising results as compared with other cycleGAN-based medical image synthesis methods such as cycleGAN, RegGAN, DualGAN and NiceGAN. The code will be available at https://github.com/JiayuanWang-JW/DC-cycleGAN.
A Joint Framework Towards Class-aware and Class-agnostic Alignment for Few-shot Segmentation
Nov 02, 2022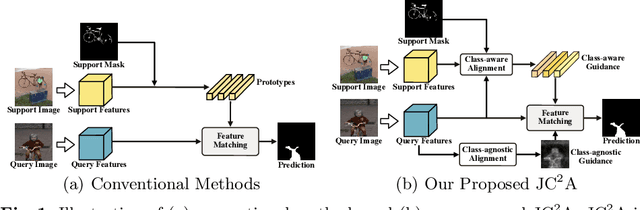
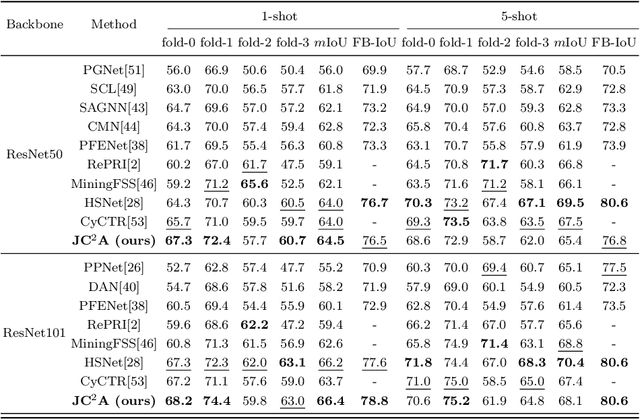
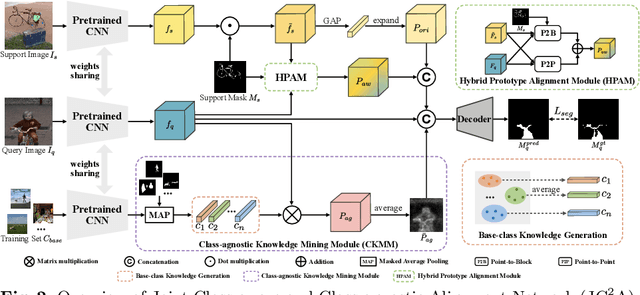
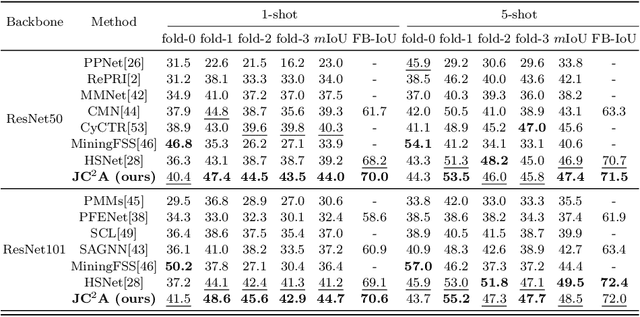
Few-shot segmentation (FSS) aims to segment objects of unseen classes given only a few annotated support images. Most existing methods simply stitch query features with independent support prototypes and segment the query image by feeding the mixed features to a decoder. Although significant improvements have been achieved, existing methods are still face class biases due to class variants and background confusion. In this paper, we propose a joint framework that combines more valuable class-aware and class-agnostic alignment guidance to facilitate the segmentation. Specifically, we design a hybrid alignment module which establishes multi-scale query-support correspondences to mine the most relevant class-aware information for each query image from the corresponding support features. In addition, we explore utilizing base-classes knowledge to generate class-agnostic prior mask which makes a distinction between real background and foreground by highlighting all object regions, especially those of unseen classes. By jointly aggregating class-aware and class-agnostic alignment guidance, better segmentation performances are obtained on query images. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed joint framework performs better, especially on the 1-shot setting.
LightVessel: Exploring Lightweight Coronary Artery Vessel Segmentation via Similarity Knowledge Distillation
Nov 02, 2022
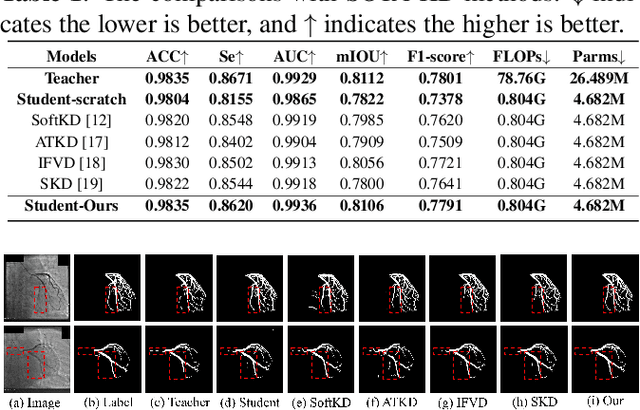
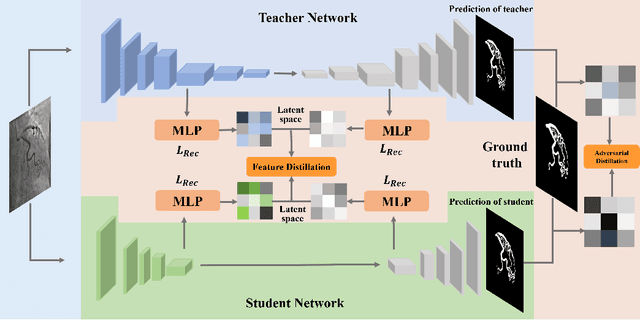
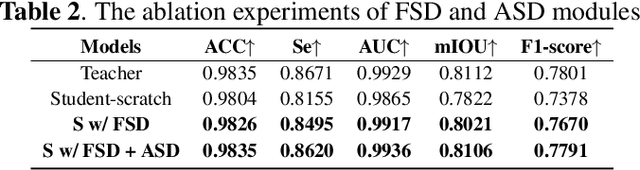
In recent years, deep convolution neural networks (DCNNs) have achieved great prospects in coronary artery vessel segmentation. However, it is difficult to deploy complicated models in clinical scenarios since high-performance approaches have excessive parameters and high computation costs. To tackle this problem, we propose \textbf{LightVessel}, a Similarity Knowledge Distillation Framework, for lightweight coronary artery vessel segmentation. Primarily, we propose a Feature-wise Similarity Distillation (FSD) module for semantic-shift modeling. Specifically, we calculate the feature similarity between the symmetric layers from the encoder and decoder. Then the similarity is transferred as knowledge from a cumbersome teacher network to a non-trained lightweight student network. Meanwhile, for encouraging the student model to learn more pixel-wise semantic information, we introduce the Adversarial Similarity Distillation (ASD) module. Concretely, the ASD module aims to construct the spatial adversarial correlation between the annotation and prediction from the teacher and student models, respectively. Through the ASD module, the student model obtains fined-grained subtle edge segmented results of the coronary artery vessel. Extensive experiments conducted on Clinical Coronary Artery Vessel Dataset demonstrate that LightVessel outperforms various knowledge distillation counterparts.