 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Rethinking Dimensionality Reduction in Grid-based 3D Object Detection
Sep 24, 2022
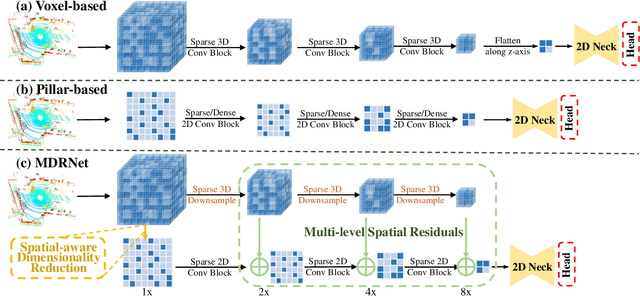
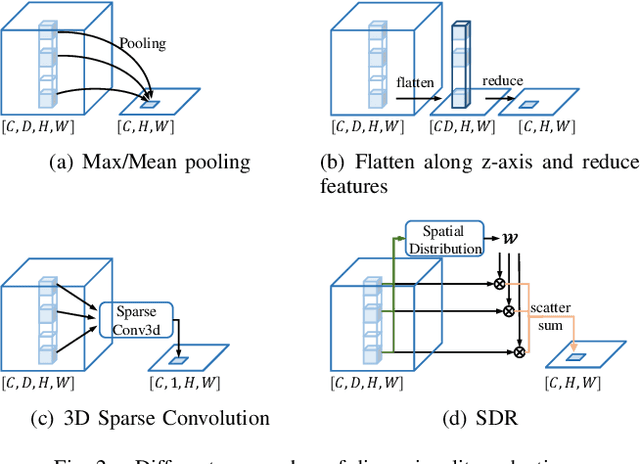

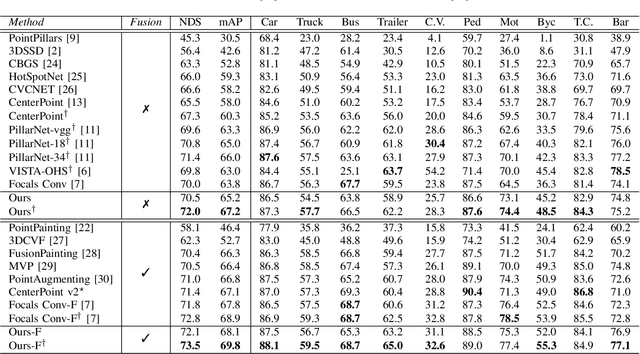
Bird's eye view (BEV) is widely adopted by most of the current point cloud detectors due to the applicability of well-explored 2D detection techniques. However, existing methods obtain BEV features by simply collapsing voxel or point features along the height dimension, which causes the heavy loss of 3D spatial information. To alleviate the information loss, we propose a novel point cloud detection network based on a Multi-level feature dimensionality reduction strategy, called MDRNet. In MDRNet, the Spatial-aware Dimensionality Reduction (SDR) is designed to dynamically focus on the valuable parts of the object during voxel-to-BEV feature transformation. Furthermore, the Multi-level Spatial Residuals (MSR) is proposed to fuse the multi-level spatial information in the BEV feature maps. Extensive experiments on nuScenes show that the proposed method outperforms the state-of-the-art methods. The code will be available upon publication.
Inharmonious Region Localization with Auxiliary Style Feature
Oct 05, 2022

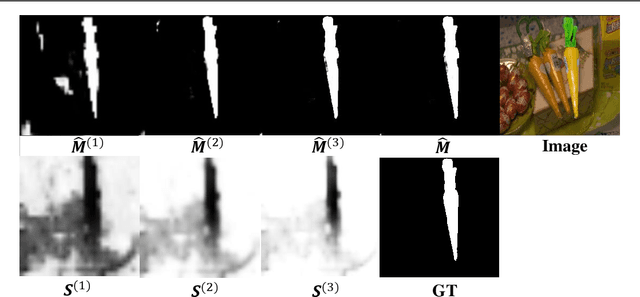
With the prevalence of image editing techniques, users can create fantastic synthetic images, but the image quality may be compromised by the color/illumination discrepancy between the manipulated region and background. Inharmonious region localization aims to localize the inharmonious region in a synthetic image. In this work, we attempt to leverage auxiliary style feature to facilitate this task. Specifically, we propose a novel color mapping module and a style feature loss to extract discriminative style features containing task-relevant color/illumination information. Based on the extracted style features, we also propose a novel style voting module to guide the localization of inharmonious region. Moreover, we introduce semantic information into the style voting module to achieve further improvement. Our method surpasses the existing methods by a large margin on the benchmark dataset.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.
Exact and Approximate Conformal Inference in Multiple Dimensions
Oct 31, 2022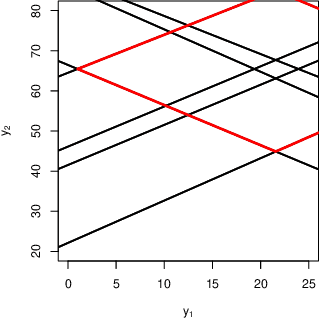
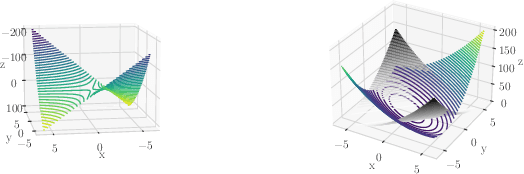

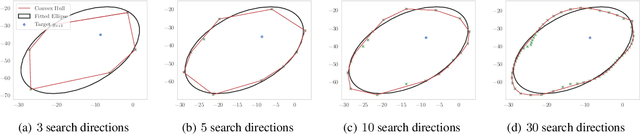
It is common in machine learning to estimate a response y given covariate information x. However, these predictions alone do not quantify any uncertainty associated with said predictions. One way to overcome this deficiency is with conformal inference methods, which construct a set containing the unobserved response y with a prescribed probability. Unfortunately, even with one-dimensional responses, conformal inference is computationally expensive despite recent encouraging advances. In this paper, we explore the multidimensional response case within a regression setting, delivering exact derivations of conformal inference p-values when the predictive model can be described as a linear function of y. Additionally, we propose different efficient ways of approximating the conformal prediction region for non-linear predictors while preserving computational advantages. We also provide empirical justification for these approaches using a real-world data example.
The Road to Industry 4.0 and Beyond: A Communications-, Information-, and Operation Technology Collaboration Perspective
May 10, 2022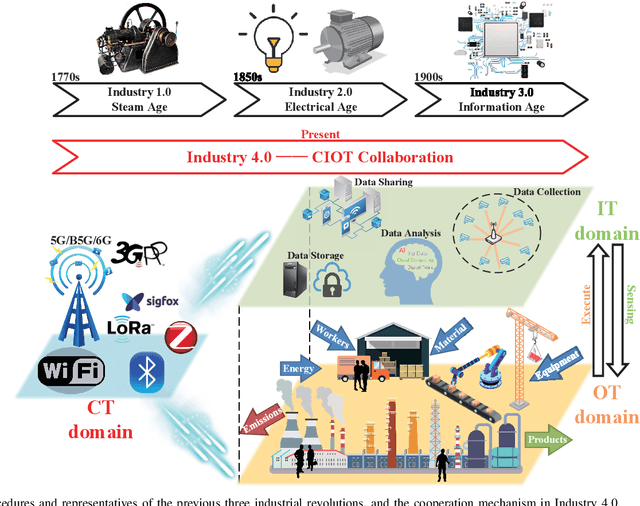
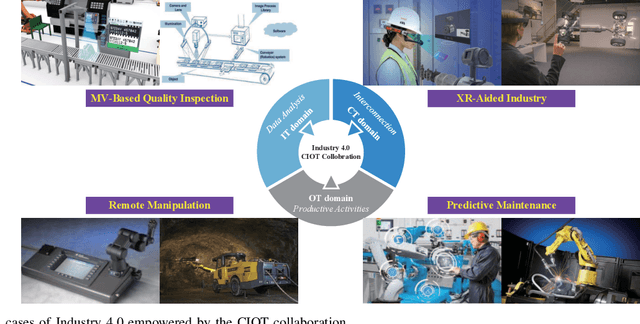
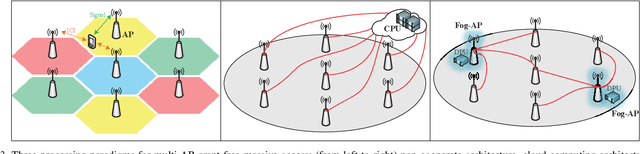
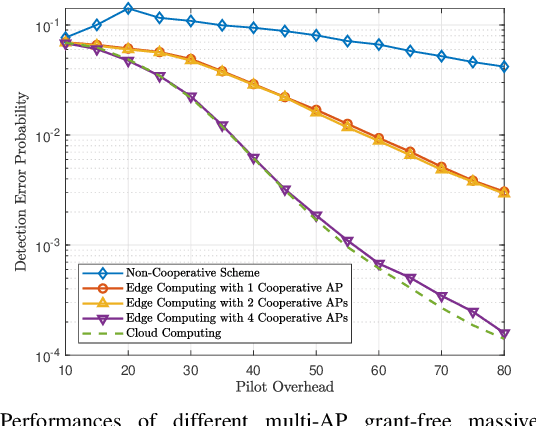
The fourth industrial revolution, i.e., Industry 4.0, is evolving all around the globe. In this article, we introduce the landscape of Industry 4.0 and beyond empowered by the seamless collaboration of communication technology (CT), information technology (IT), and operation technology (OT), i.e., CIOT collaboration. Specifically, CIOT collaboration is regarded as a main improvement of Industry 4.0 compared to the previous industrial revolutions. We commence by reviewing the previous three industrial revolutions and we argue that the key feature of Industry 4.0 is the CIOT collaboration. More particularly, CT domain supports ubiquitous connectivity of the industrial elements and further bridges the physical world and the cyber world, which is a pivotal prerequisite. Then, we present the potential impacts of CIOT collaboration on typical industrial use cases with the objective of creating a more intelligent and human-friendly industry. Furthermore, the technical challenges of paving the way for the CIOT collaboration with an emphasis on the CT domain are discussed. Finally, we shed light on a roadmap for Industry 4.0 and beyond. The salient steps to be taken in the future CIOT collaboration are highlighted, which may be expected to expedite the paradigm shift towards the next industrial revolution.
GNS: A generalizable Graph Neural Network-based simulator for particulate and fluid modeling
Nov 18, 2022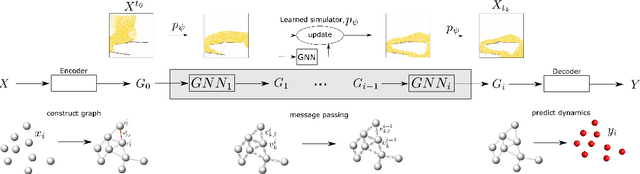
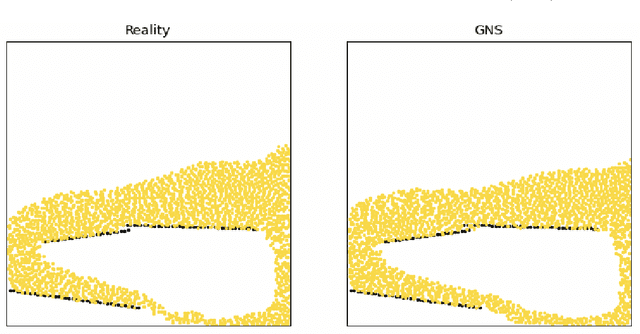
We develop a PyTorch-based Graph Network Simulator (GNS) that learns physics and predicts the flow behavior of particulate and fluid systems. GNS discretizes the domain with nodes representing a collection of material points and the links connecting the nodes representing the local interaction between particles or clusters of particles. The GNS learns the interaction laws through message passing on the graph. GNS has three components: (a) Encoder, which embeds particle information to a latent graph, the edges are learned functions; (b) Processor, which allows data propagation and computes the nodal interactions across steps; and (c) Decoder, which extracts the relevant dynamics (e.g., particle acceleration) from the graph. We introduce physics-inspired simple inductive biases, such as an inertial frame that allows learning algorithms to prioritize one solution (constant gravitational acceleration) over another, reducing learning time. The GNS implementation uses semi-implicit Euler integration to update the next state based on the predicted accelerations. GNS trained on trajectory data is generalizable to predict particle kinematics in complex boundary conditions not seen during training. The trained model accurately predicts within a 5\% error of its associated material point method (MPM) simulation. The predictions are 5,000x faster than traditional MPM simulations (2.5 hours for MPM simulations versus 20 s for GNS simulation of granular flow). GNS surrogates are popular for solving optimization, control, critical-region prediction for in situ viz, and inverse-type problems. The GNS code is available under the open-source MIT license at https://github.com/geoelements/gns.
Doubly Inhomogeneous Reinforcement Learning
Nov 12, 2022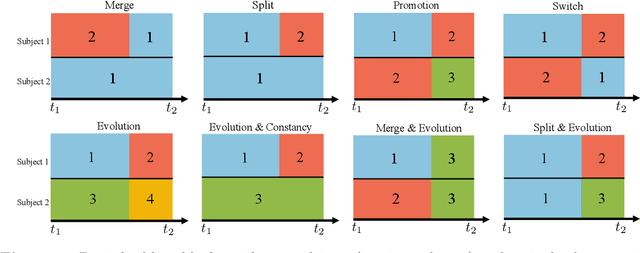
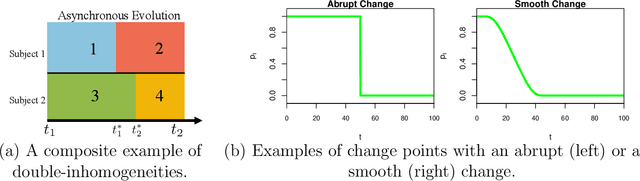

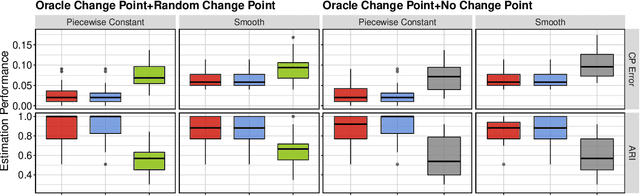
This paper studies reinforcement learning (RL) in doubly inhomogeneous environments under temporal non-stationarity and subject heterogeneity. In a number of applications, it is commonplace to encounter datasets generated by system dynamics that may change over time and population, challenging high-quality sequential decision making. Nonetheless, most existing RL solutions require either temporal stationarity or subject homogeneity, which would result in sub-optimal policies if both assumptions were violated. To address both challenges simultaneously, we propose an original algorithm to determine the ``best data chunks" that display similar dynamics over time and across individuals for policy learning, which alternates between most recent change point detection and cluster identification. Our method is general, and works with a wide range of clustering and change point detection algorithms. It is multiply robust in the sense that it takes multiple initial estimators as input and only requires one of them to be consistent. Moreover, by borrowing information over time and population, it allows us to detect weaker signals and has better convergence properties when compared to applying the clustering algorithm per time or the change point detection algorithm per subject. Empirically, we demonstrate the usefulness of our method through extensive simulations and a real data application.
Indefinite causal order for quantum metrology with quantum thermal noise
Nov 03, 2022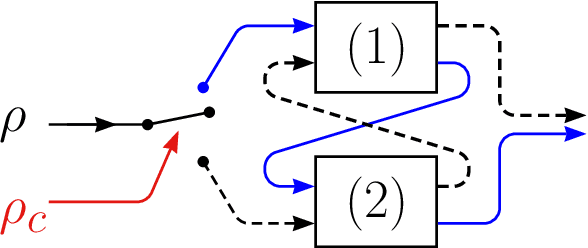

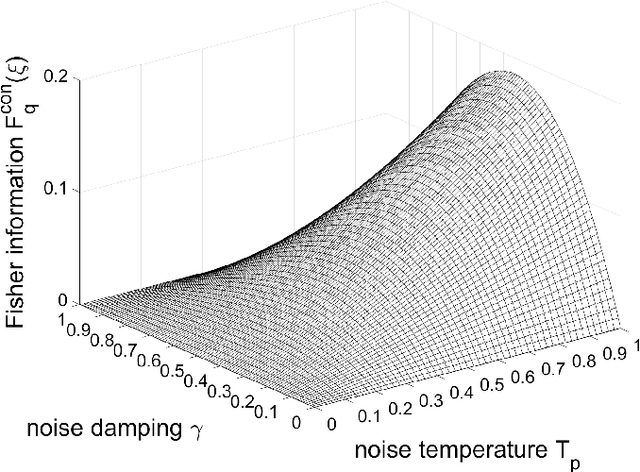
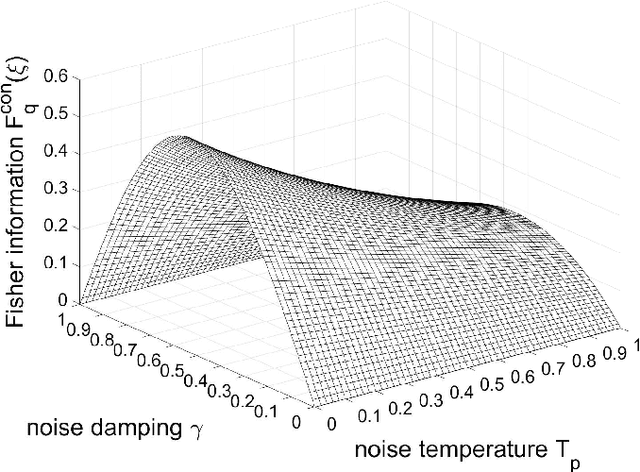
A switched quantum channel with indefinite causal order is studied for the fundamental metrological task of phase estimation on a qubit unitary operator affected by quantum thermal noise. Specific capabilities are reported in the switched channel with indefinite order, not accessible with conventional estimation approaches with definite order. Phase estimation can be performed by measuring the control qubit alone, although it does not actively interact with the unitary process -- only the probe qubit doing so. Also, phase estimation becomes possible with a fully depolarized input probe or with an input probe aligned with the rotation axis of the unitary, while this is never possible with conventional approaches. The present study extends to thermal noise, investigations previously carried out with the more symmetric and isotropic qubit depolarizing noise, and it contributes to the timely exploration of properties of quantum channels with indefinite causal order relevant to quantum signal and information processing.
* 10 pages, 7 figures, 52 references
MolE: a molecular foundation model for drug discovery
Nov 03, 2022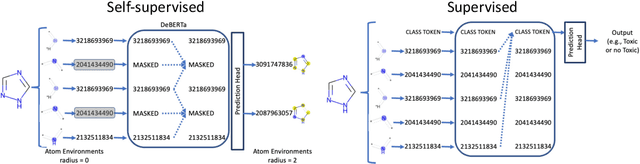

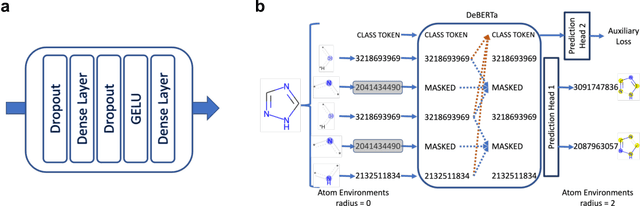
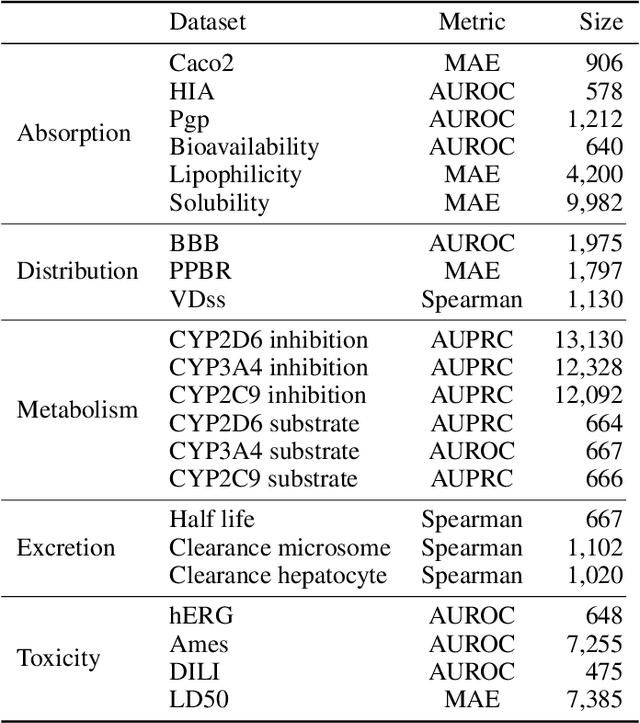
Models that accurately predict properties based on chemical structure are valuable tools in drug discovery. However, for many properties, public and private training sets are typically small, and it is difficult for the models to generalize well outside of the training data. Recently, large language models have addressed this problem by using self-supervised pretraining on large unlabeled datasets, followed by fine-tuning on smaller, labeled datasets. In this paper, we report MolE, a molecular foundation model that adapts the DeBERTa architecture to be used on molecular graphs together with a two-step pretraining strategy. The first step of pretraining is a self-supervised approach focused on learning chemical structures, and the second step is a massive multi-task approach to learn biological information. We show that fine-tuning pretrained MolE achieves state-of-the-art results on 9 of the 22 ADMET tasks included in the Therapeutic Data Commons.
StyleSwap: Style-Based Generator Empowers Robust Face Swapping
Sep 27, 2022
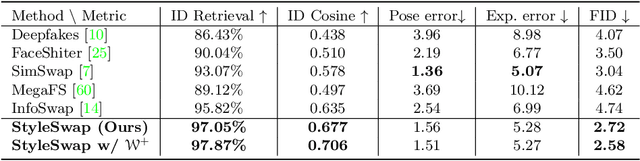
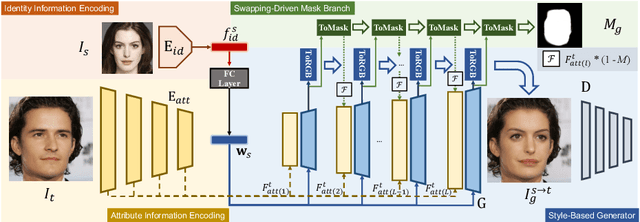

Numerous attempts have been made to the task of person-agnostic face swapping given its wide applications. While existing methods mostly rely on tedious network and loss designs, they still struggle in the information balancing between the source and target faces, and tend to produce visible artifacts. In this work, we introduce a concise and effective framework named StyleSwap. Our core idea is to leverage a style-based generator to empower high-fidelity and robust face swapping, thus the generator's advantage can be adopted for optimizing identity similarity. We identify that with only minimal modifications, a StyleGAN2 architecture can successfully handle the desired information from both source and target. Additionally, inspired by the ToRGB layers, a Swapping-Driven Mask Branch is further devised to improve information blending. Furthermore, the advantage of StyleGAN inversion can be adopted. Particularly, a Swapping-Guided ID Inversion strategy is proposed to optimize identity similarity. Extensive experiments validate that our framework generates high-quality face swapping results that outperform state-of-the-art methods both qualitatively and quantitatively.