 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Outcome-Oriented Prescriptive Process Monitoring Based on Temporal Logic Patterns
Nov 14, 2022

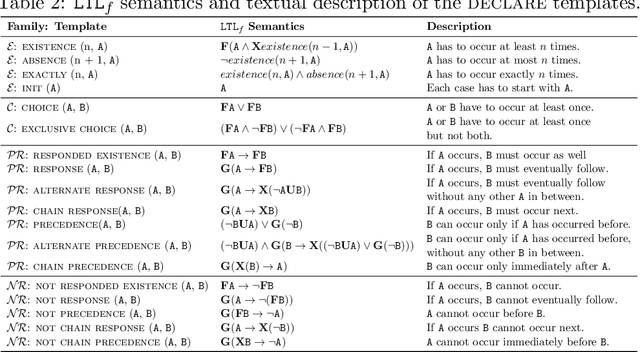
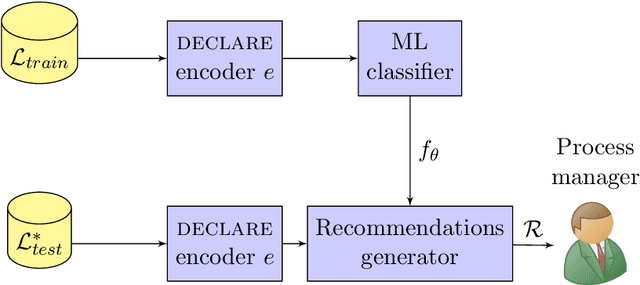

Prescriptive Process Monitoring systems recommend, during the execution of a business process, interventions that, if followed, prevent a negative outcome of the process. Such interventions have to be reliable, that is, they have to guarantee the achievement of the desired outcome or performance, and they have to be flexible, that is, they have to avoid overturning the normal process execution or forcing the execution of a given activity. Most of the existing Prescriptive Process Monitoring solutions, however, while performing well in terms of recommendation reliability, provide the users with very specific (sequences of) activities that have to be executed without caring about the feasibility of these recommendations. In order to face this issue, we propose a new Outcome-Oriented Prescriptive Process Monitoring system recommending temporal relations between activities that have to be guaranteed during the process execution in order to achieve a desired outcome. This softens the mandatory execution of an activity at a given point in time, thus leaving more freedom to the user in deciding the interventions to put in place. Our approach defines these temporal relations with Linear Temporal Logic over finite traces patterns that are used as features to describe the historical process data recorded in an event log by the information systems supporting the execution of the process. Such encoded log is used to train a Machine Learning classifier to learn a mapping between the temporal patterns and the outcome of a process execution. The classifier is then queried at runtime to return as recommendations the most salient temporal patterns to be satisfied to maximize the likelihood of a certain outcome for an input ongoing process execution. The proposed system is assessed using a pool of 22 real-life event logs that have already been used as a benchmark in the Process Mining community.
Retrieval Augmentation for T5 Re-ranker using External Sources
Oct 11, 2022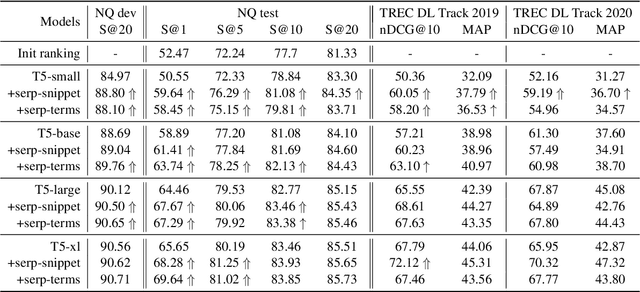
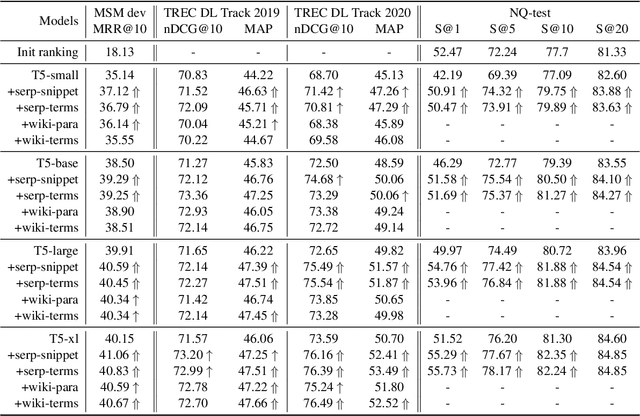
Retrieval augmentation has shown promising improvements in different tasks. However, whether such augmentation can assist a large language model based re-ranker remains unclear. We investigate how to augment T5-based re-rankers using high-quality information retrieved from two external corpora -- a commercial web search engine and Wikipedia. We empirically demonstrate how retrieval augmentation can substantially improve the effectiveness of T5-based re-rankers for both in-domain and zero-shot out-of-domain re-ranking tasks.
Data-Efficient Information Extraction from Form-Like Documents
Jan 07, 2022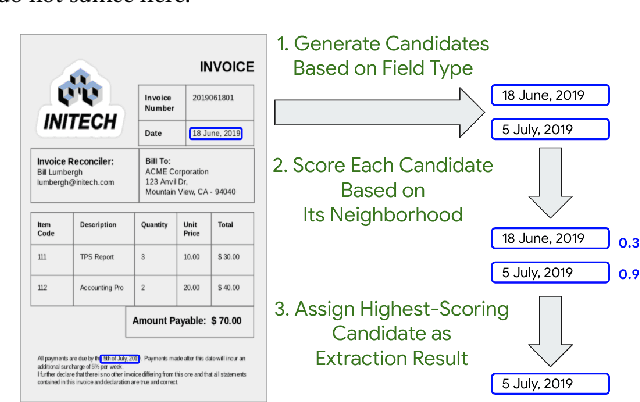
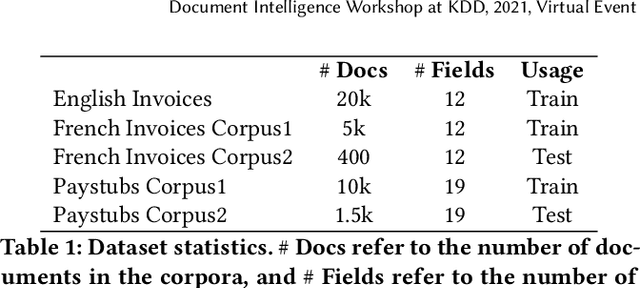
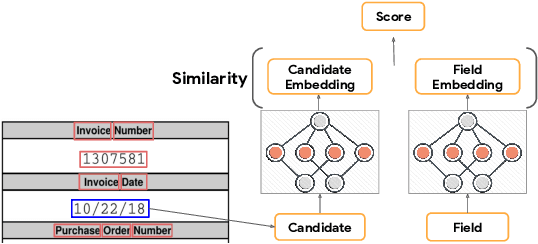
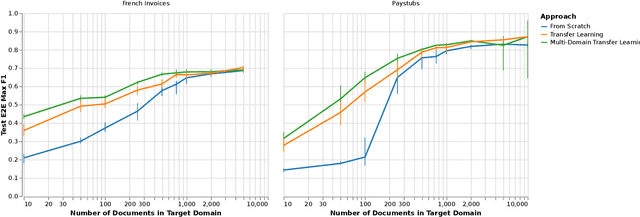
Automating information extraction from form-like documents at scale is a pressing need due to its potential impact on automating business workflows across many industries like financial services, insurance, and healthcare. The key challenge is that form-like documents in these business workflows can be laid out in virtually infinitely many ways; hence, a good solution to this problem should generalize to documents with unseen layouts and languages. A solution to this problem requires a holistic understanding of both the textual segments and the visual cues within a document, which is non-trivial. While the natural language processing and computer vision communities are starting to tackle this problem, there has not been much focus on (1) data-efficiency, and (2) ability to generalize across different document types and languages. In this paper, we show that when we have only a small number of labeled documents for training (~50), a straightforward transfer learning approach from a considerably structurally-different larger labeled corpus yields up to a 27 F1 point improvement over simply training on the small corpus in the target domain. We improve on this with a simple multi-domain transfer learning approach, that is currently in production use, and show that this yields up to a further 8 F1 point improvement. We make the case that data efficiency is critical to enable information extraction systems to scale to handle hundreds of different document-types, and learning good representations is critical to accomplishing this.
BLADERUNNER: Rapid Countermeasure for Synthetic (AI-Generated) StyleGAN Faces
Oct 14, 2022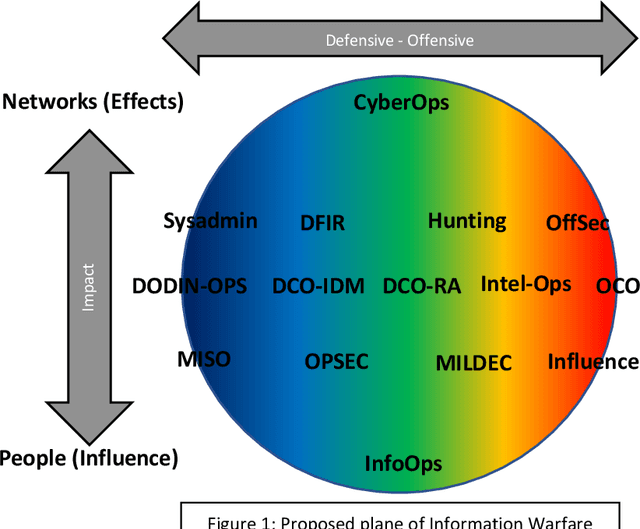
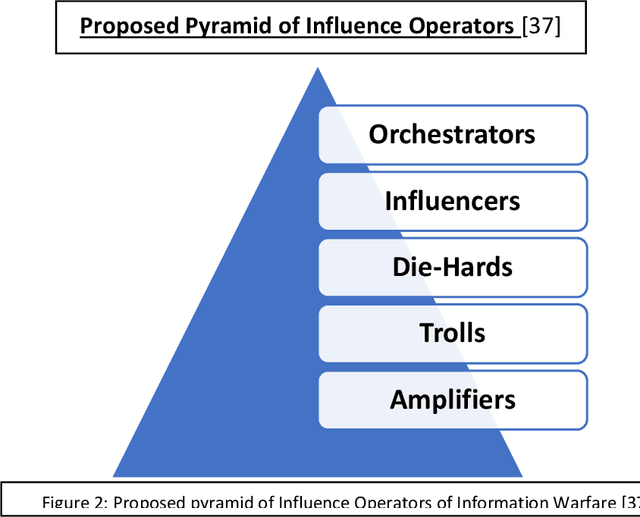


StyleGAN is the open-sourced TensorFlow implementation made by NVIDIA. It has revolutionized high quality facial image generation. However, this democratization of Artificial Intelligence / Machine Learning (AI/ML) algorithms has enabled hostile threat actors to establish cyber personas or sock-puppet accounts in social media platforms. These ultra-realistic synthetic faces. This report surveys the relevance of AI/ML with respect to Cyber & Information Operations. The proliferation of AI/ML algorithms has led to a rise in DeepFakes and inauthentic social media accounts. Threats are analyzed within the Strategic and Operational Environments. Existing methods of identifying synthetic faces exists, but they rely on human beings to visually scrutinize each photo for inconsistencies. However, through use of the DLIB 68-landmark pre-trained file, it is possible to analyze and detect synthetic faces by exploiting repetitive behaviors in StyleGAN images. Project Blade Runner encompasses two scripts necessary to counter StyleGAN images. Through PapersPlease acting as the analyzer, it is possible to derive indicators-of-attack (IOA) from scraped image samples. These IOAs can be fed back into Among_Us acting as the detector to identify synthetic faces from live operational samples. The opensource copy of Blade Runner may lack additional unit tests and some functionality, but the open-source copy is a redacted version, far leaner, better optimized, and a proof-of-concept for the information security community. The desired end-state will be to incrementally add automation to stay on-par with its closed-source predecessor.
Elastic Weight Consolidation Improves the Robustness of Self-Supervised Learning Methods under Transfer
Oct 28, 2022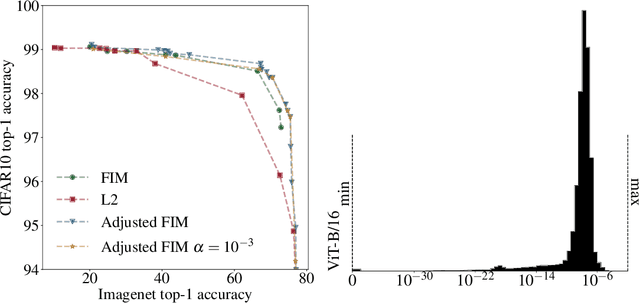
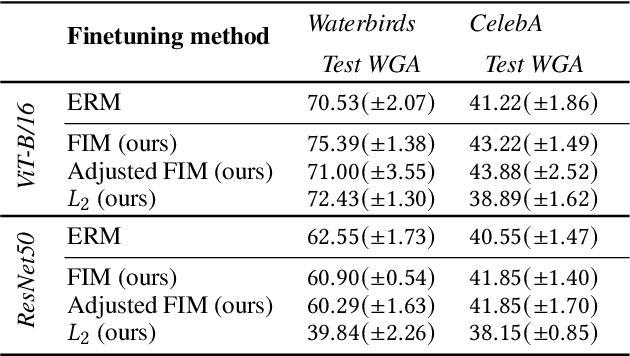
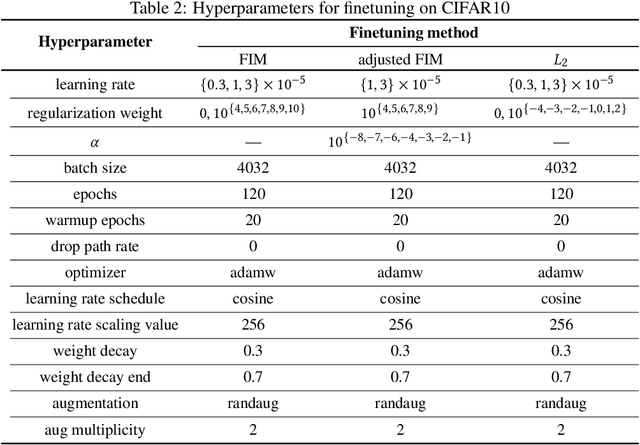
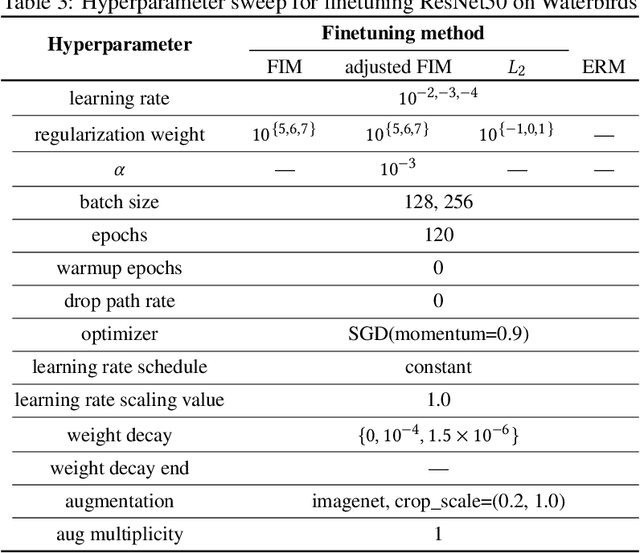
Self-supervised representation learning (SSL) methods provide an effective label-free initial condition for fine-tuning downstream tasks. However, in numerous realistic scenarios, the downstream task might be biased with respect to the target label distribution. This in turn moves the learned fine-tuned model posterior away from the initial (label) bias-free self-supervised model posterior. In this work, we re-interpret SSL fine-tuning under the lens of Bayesian continual learning and consider regularization through the Elastic Weight Consolidation (EWC) framework. We demonstrate that self-regularization against an initial SSL backbone improves worst sub-group performance in Waterbirds by 5% and Celeb-A by 2% when using the ViT-B/16 architecture. Furthermore, to help simplify the use of EWC with SSL, we pre-compute and publicly release the Fisher Information Matrix (FIM), evaluated with 10,000 ImageNet-1K variates evaluated on large modern SSL architectures including ViT-B/16 and ResNet50 trained with DINO.
Assessing Phrase Break of ESL speech with Pre-trained Language Models
Oct 28, 2022

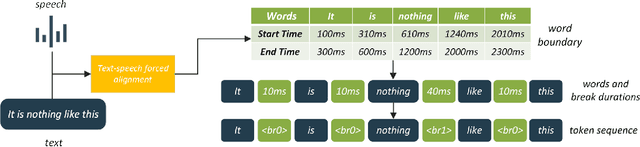
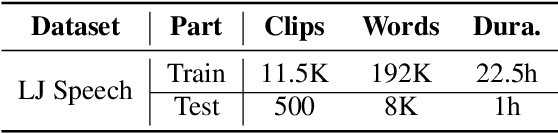
This work introduces an approach to assessing phrase break in ESL learners' speech with pre-trained language models (PLMs). Different with traditional methods, this proposal converts speech to token sequences, and then leverages the power of PLMs. There are two sub-tasks: overall assessment of phrase break for a speech clip; fine-grained assessment of every possible phrase break position. Speech input is first force-aligned with texts, then pre-processed to a token sequence, including words and associated phrase break information. The token sequence is then fed into the pre-training and fine-tuning pipeline. In pre-training, a replaced break token detection module is trained with token data where each token has a certain percentage chance to be randomly replaced. In fine-tuning, overall and fine-grained scoring are optimized with text classification and sequence labeling pipeline, respectively. With the introduction of PLMs, the dependence on labeled training data has been greatly reduced, and performance has improved.
Object Segmentation of Cluttered Airborne LiDAR Point Clouds
Oct 28, 2022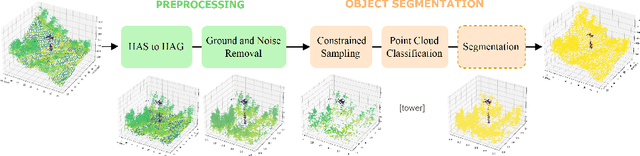
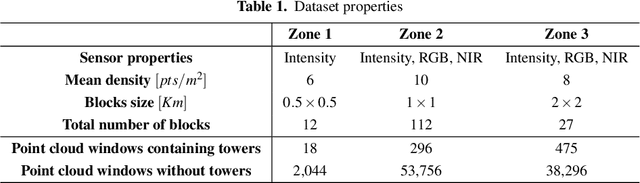

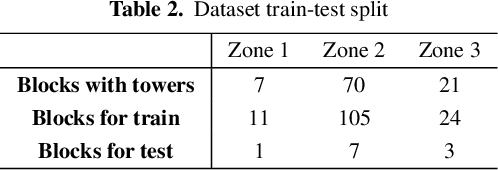
Airborne topographic LiDAR is an active remote sensing technology that emits near-infrared light to map objects on the Earth's surface. Derived products of LiDAR are suitable to service a wide range of applications because of their rich three-dimensional spatial information and their capacity to obtain multiple returns. However, processing point cloud data still requires a significant effort in manual editing. Certain human-made objects are difficult to detect because of their variety of shapes, irregularly-distributed point clouds, and low number of class samples. In this work, we propose an end-to-end deep learning framework to automatize the detection and segmentation of objects defined by an arbitrary number of LiDAR points surrounded by clutter. Our method is based on a light version of PointNet that achieves good performance on both object recognition and segmentation tasks. The results are tested against manually delineated power transmission towers and show promising accuracy.
* proceedings of the 24th International Conference of the Catalan Association for Artificial Intelligence (CCIA 2022)
Comparison of Stereo Matching Algorithms for the Development of Disparity Map
Oct 28, 2022
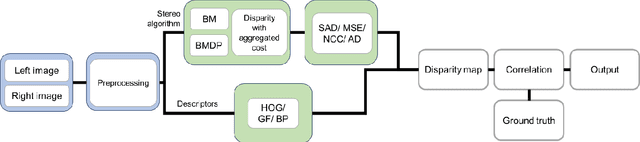
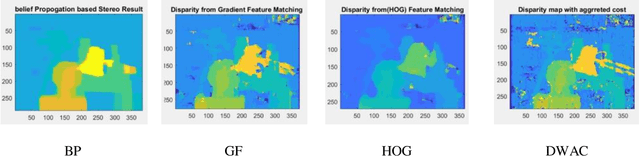
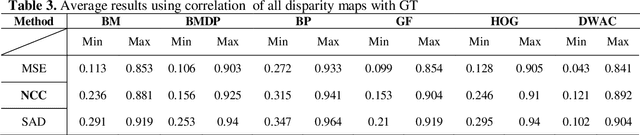
Stereo Matching is one of the classical problems in computer vision for the extraction of 3D information but still controversial for accuracy and processing costs. The use of matching techniques and cost functions is crucial in the development of the disparity map. This paper presents a comparative study of six different stereo matching algorithms including Block Matching (BM), Block Matching with Dynamic Programming (BMDP), Belief Propagation (BP), Gradient Feature Matching (GF), Histogram of Oriented Gradient (HOG), and the proposed method. Also three cost functions namely Mean Squared Error (MSE), Sum of Absolute Differences (SAD), Normalized Cross-Correlation (NCC) were used and compared. The stereo images used in this study were from the Middlebury Stereo Datasets provided with perfect and imperfect calibrations. Results show that the selection of matching function is quite important and also depends on the images properties. Results showed that the BP algorithm in most cases provided better results getting accuracies over 95%.
GeoGCN: Geometric Dual-domain Graph Convolution Network for Point Cloud Denoising
Oct 28, 2022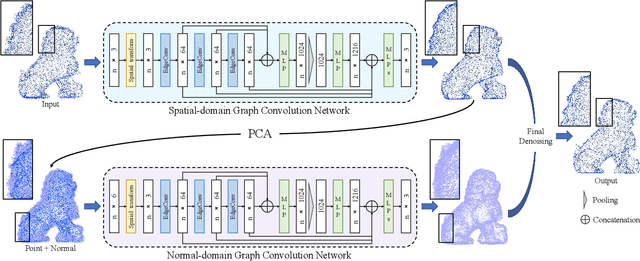
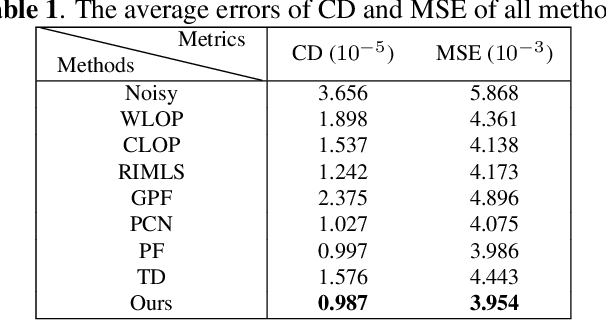


We propose GeoGCN, a novel geometric dual-domain graph convolution network for point cloud denoising (PCD). Beyond the traditional wisdom of PCD, to fully exploit the geometric information of point clouds, we define two kinds of surface normals, one is called Real Normal (RN), and the other is Virtual Normal (VN). RN preserves the local details of noisy point clouds while VN avoids the global shape shrinkage during denoising. GeoGCN is a new PCD paradigm that, 1) first regresses point positions by spatialbased GCN with the help of VNs, 2) then estimates initial RNs by performing Principal Component Analysis on the regressed points, and 3) finally regresses fine RNs by normalbased GCN. Unlike existing PCD methods, GeoGCN not only exploits two kinds of geometry expertise (i.e., RN and VN) but also benefits from training data. Experiments validate that GeoGCN outperforms SOTAs in terms of both noise-robustness and local-and-global feature preservation.
SEMPAI: a Self-Enhancing Multi-Photon Artificial Intelligence for prior-informed assessment of muscle function and pathology
Oct 28, 2022Deep learning (DL) shows notable success in biomedical studies. However, most DL algorithms work as a black box, exclude biomedical experts, and need extensive data. We introduce the Self-Enhancing Multi-Photon Artificial Intelligence (SEMPAI), that integrates hypothesis-driven priors in a data-driven DL approach for research on multiphoton microscopy (MPM) of muscle fibers. SEMPAI utilizes meta-learning to optimize prior integration, data representation, and neural network architecture simultaneously. This allows hypothesis testing and provides interpretable feedback about the origin of biological information in MPM images. SEMPAI performs joint learning of several tasks to enable prediction for small datasets. The method is applied on an extensive multi-study dataset resulting in the largest joint analysis of pathologies and function for single muscle fibers. SEMPAI outperforms state-of-the-art biomarkers in six of seven predictive tasks, including those with scarce data. SEMPAI's DL models with integrated priors are superior to those without priors and to prior-only machine learning approaches.