 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-view Multi-label Anomaly Network Traffic Classification based on MLP-Mixer Neural Network
Nov 08, 2022
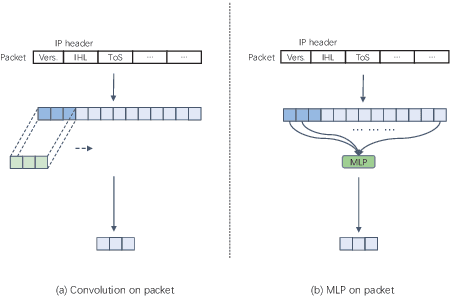
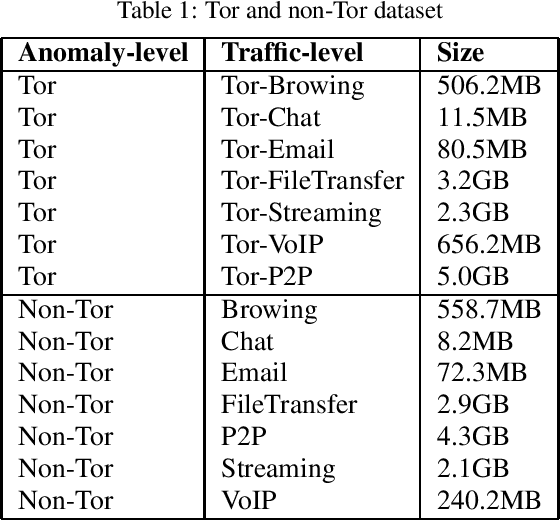

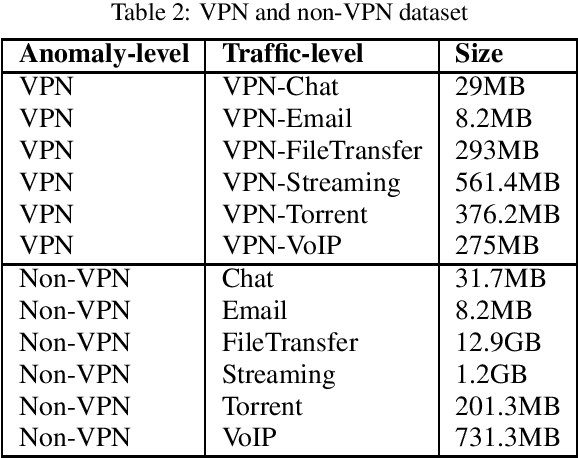
Network traffic classification is the basis of many network security applications and has attracted enough attention in the field of cyberspace security. Existing network traffic classification based on convolutional neural networks (CNNs) often emphasizes local patterns of traffic data while ignoring global information associations. In this paper, we propose a MLP-Mixer based multi-view multi-label neural network for network traffic classification. Compared with the existing CNN-based methods, our method adopts the MLP-Mixer structure, which is more in line with the structure of the packet than the conventional convolution operation. In our method, the packet is divided into the packet header and the packet body, together with the flow features of the packet as input from different views. We utilize a multi-label setting to learn different scenarios simultaneously to improve the classification performance by exploiting the correlations between different scenarios. Taking advantage of the above characteristics, we propose an end-to-end network traffic classification method. We conduct experiments on three public datasets, and the experimental results show that our method can achieve superior performance.
Efficacy of MRI data harmonization in the age of machine learning. A multicenter study across 36 datasets
Nov 08, 2022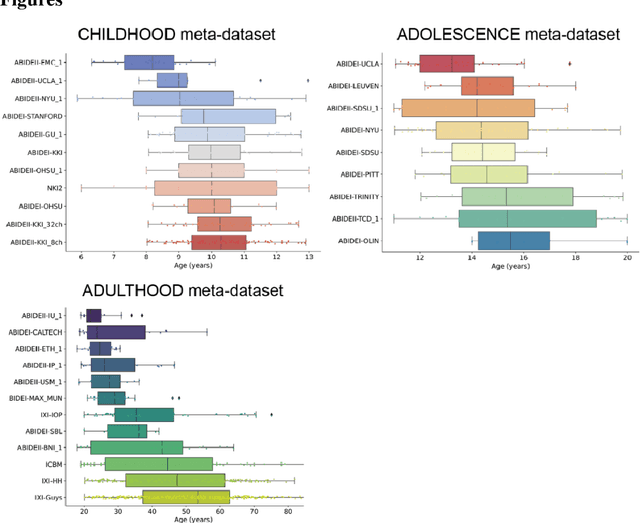
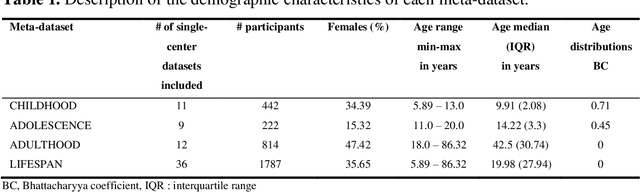
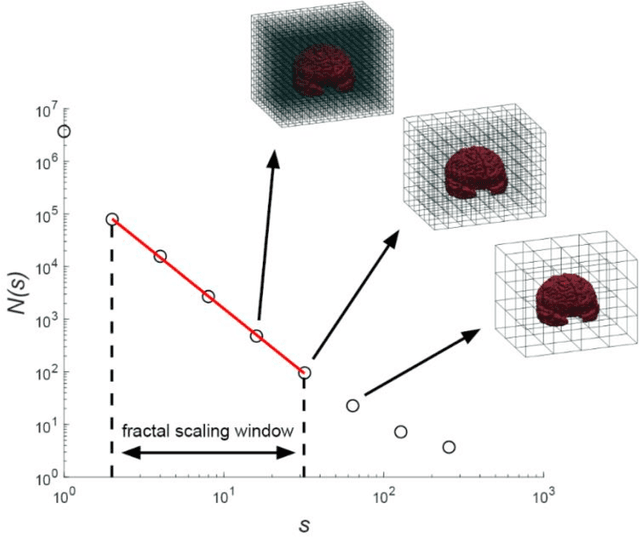
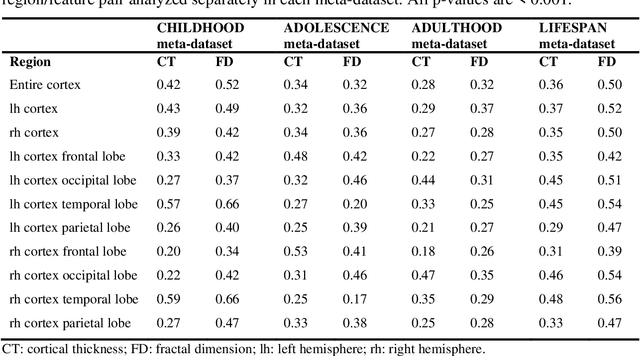
Pooling publicly-available MRI data from multiple sites allows to assemble extensive groups of subjects, increase statistical power, and promote data reuse with machine learning techniques. The harmonization of multicenter data is necessary to reduce the confounding effect associated with non-biological sources of variability in the data. However, when applied to the entire dataset before machine learning, the harmonization leads to data leakage, because information outside the training set may affect model building, and potentially falsely overestimate performance. We propose a 1) measurement of the efficacy of data harmonization; 2) harmonizer transformer, i.e., an implementation of the ComBat harmonization allowing its encapsulation among the preprocessing steps of a machine learning pipeline, avoiding data leakage. We tested these tools using brain T1-weighted MRI data from 1740 healthy subjects acquired at 36 sites. After harmonization, the site effect was removed or reduced, and we measured the data leakage effect in predicting individual age from MRI data, highlighting that introducing the harmonizer transformer into a machine learning pipeline allows for avoiding data leakage.
Inferring Class Label Distribution of Training Data from Classifiers: An Accuracy-Augmented Meta-Classifier Attack
Nov 08, 2022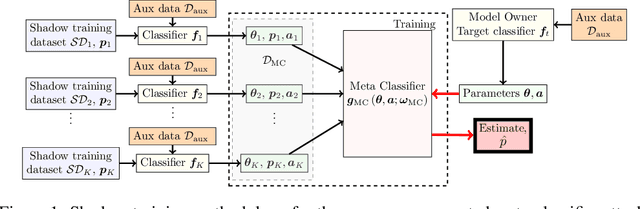


Property inference attacks against machine learning (ML) models aim to infer properties of the training data that are unrelated to the primary task of the model, and have so far been formulated as binary decision problems, i.e., whether or not the training data have a certain property. However, in industrial and healthcare applications, the proportion of labels in the training data is quite often also considered sensitive information. In this paper we introduce a new type of property inference attack that unlike binary decision problems in literature, aim at inferring the class label distribution of the training data from parameters of ML classifier models. We propose a method based on \emph{shadow training} and a \emph{meta-classifier} trained on the parameters of the shadow classifiers augmented with the accuracy of the classifiers on auxiliary data. We evaluate the proposed approach for ML classifiers with fully connected neural network architectures. We find that the proposed \emph{meta-classifier} attack provides a maximum relative improvement of $52\%$ over state of the art.
Learning advisor networks for noisy image classification
Nov 08, 2022In this paper, we introduced the novel concept of advisor network to address the problem of noisy labels in image classification. Deep neural networks (DNN) are prone to performance reduction and overfitting problems on training data with noisy annotations. Weighting loss methods aim to mitigate the influence of noisy labels during the training, completely removing their contribution. This discarding process prevents DNNs from learning wrong associations between images and their correct labels but reduces the amount of data used, especially when most of the samples have noisy labels. Differently, our method weighs the feature extracted directly from the classifier without altering the loss value of each data. The advisor helps to focus only on some part of the information present in mislabeled examples, allowing the classifier to leverage that data as well. We trained it with a meta-learning strategy so that it can adapt throughout the training of the main model. We tested our method on CIFAR10 and CIFAR100 with synthetic noise, and on Clothing1M which contains real-world noise, reporting state-of-the-art results.
* Paper published as Poster at ICIAP21
PAC-Bayes Information Bottleneck
Oct 04, 2021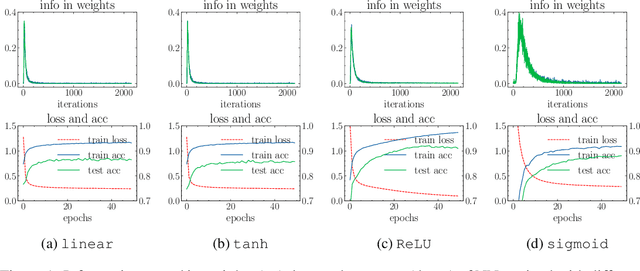
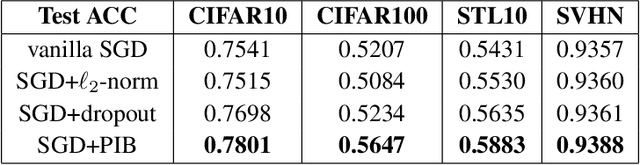
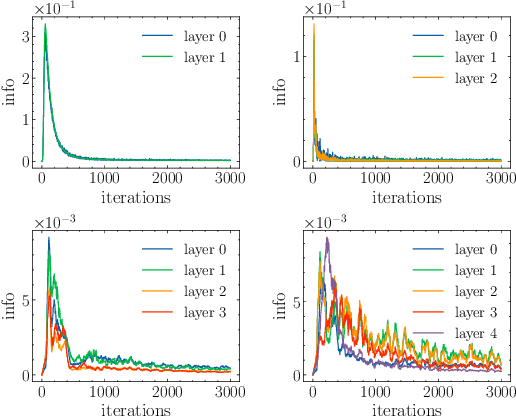
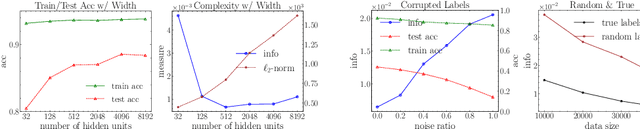
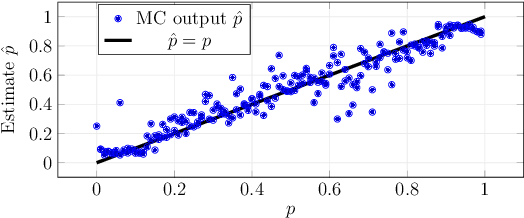
Information bottleneck (IB) depicts a trade-off between the accuracy and conciseness of encoded representations. IB has succeeded in explaining the objective and behavior of neural networks (NNs) as well as learning better representations. However, there are still critics of the universality of IB, e.g., phase transition usually fades away, representation compression is not causally related to generalization, and IB is trivial in deterministic cases. In this work, we build a new IB based on the trade-off between the accuracy and complexity of learned weights of NNs. We argue that this new IB represents a more solid connection to the objective of NNs since the information stored in weights (IIW) bounds their PAC-Bayes generalization capability, hence we name it as PAC-Bayes IB (PIB). On IIW, we can identify the phase transition phenomenon in general cases and solidify the causality between compression and generalization. We then derive a tractable solution of PIB and design a stochastic inference algorithm by Markov chain Monte Carlo sampling. We empirically verify our claims through extensive experiments. We also substantiate the superiority of the proposed algorithm on training NNs.
Beyond the density operator and Tr(ρA): Exploiting the higher-order statistics of random-coefficient pure states for quantum information processing
Apr 21, 2022
Two types of states are widely used in quantum mechanics, namely (deterministic-coefficient) pure states and statistical mixtures. A density operator can be associated with each of them. We here address a third type of states, that we previously introduced in a more restricted framework. These states generalize pure ones by replacing each of their deterministic ket coefficients by a random variable. We therefore call them Random-Coefficient Pure States, or RCPS. We analyze their properties and their relationships with both types of usual states. We show that RCPS contain much richer information than the density operator and mean of observables that we associate with them. This occurs because the latter operator only exploits the second-order statistics of the random state coefficients, whereas their higher-order statistics contain additional information. That information can be accessed in practice with the multiple-preparation procedure that we propose for RCPS, by using second-order and higher-order statistics of associated random probabilities of measurement outcomes. Exploiting these higher-order statistics opens the way to a very general approach for performing advanced quantum information processing tasks. We illustrate the relevance of this approach with a generic example, dealing with the estimation of parameters of a quantum process and thus related to quantum process tomography. This parameter estimation is performed in the non-blind (i.e. supervised) or blind (i.e. unsupervised) mode. We show that this problem cannot be solved by using only the density operator \rho of an RCPS and the associated mean value Tr(\rho A) of the operator A that corresponds to the considered physical quantity. We succeed in solving this problem by exploiting a fourth-order statistical parameter of state coefficients, in addition to second-order statistics. Numerical tests validate this result.
Adma-GAN: Attribute-Driven Memory Augmented GANs for Text-to-Image Generation
Sep 28, 2022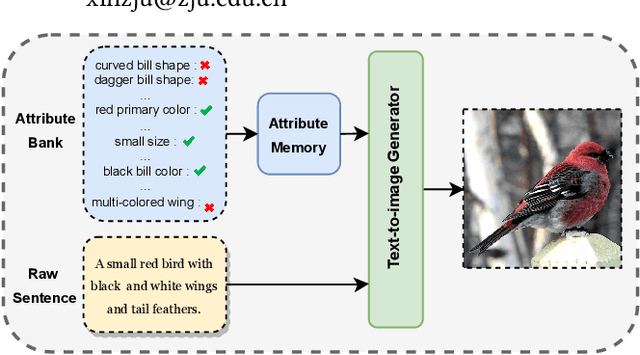
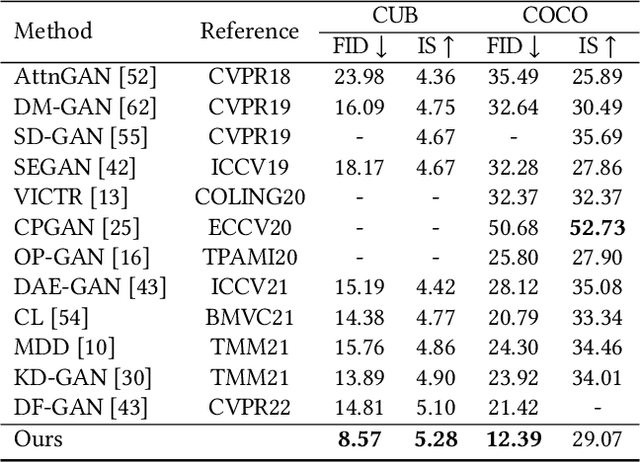
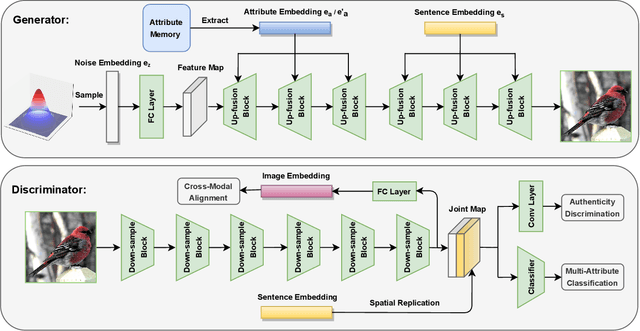
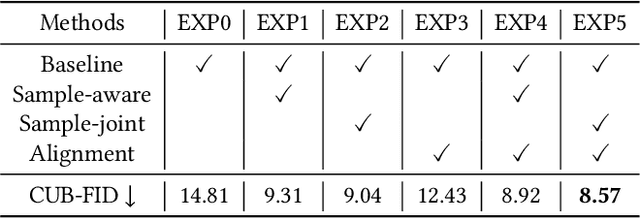
As a challenging task, text-to-image generation aims to generate photo-realistic and semantically consistent images according to the given text descriptions. Existing methods mainly extract the text information from only one sentence to represent an image and the text representation effects the quality of the generated image well. However, directly utilizing the limited information in one sentence misses some key attribute descriptions, which are the crucial factors to describe an image accurately. To alleviate the above problem, we propose an effective text representation method with the complements of attribute information. Firstly, we construct an attribute memory to jointly control the text-to-image generation with sentence input. Secondly, we explore two update mechanisms, sample-aware and sample-joint mechanisms, to dynamically optimize a generalized attribute memory. Furthermore, we design an attribute-sentence-joint conditional generator learning scheme to align the feature embeddings among multiple representations, which promotes the cross-modal network training. Experimental results illustrate that the proposed method obtains substantial performance improvements on both the CUB (FID from 14.81 to 8.57) and COCO (FID from 21.42 to 12.39) datasets.
Application of Deep Learning in Generating Structured Radiology Reports: A Transformer-Based Technique
Sep 25, 2022Since radiology reports needed for clinical practice and research are written and stored in free-text narrations, extraction of relative information for further analysis is difficult. In these circumstances, natural language processing (NLP) techniques can facilitate automatic information extraction and transformation of free-text formats to structured data. In recent years, deep learning (DL)-based models have been adapted for NLP experiments with promising results. Despite the significant potential of DL models based on artificial neural networks (ANN) and convolutional neural networks (CNN), the models face some limitations to implement in clinical practice. Transformers, another new DL architecture, have been increasingly applied to improve the process. Therefore, in this study, we propose a transformer-based fine-grained named entity recognition (NER) architecture for clinical information extraction. We collected 88 abdominopelvic sonography reports in free-text formats and annotated them based on our developed information schema. The text-to-text transfer transformer model (T5) and Scifive, a pre-trained domain-specific adaptation of the T5 model, were applied for fine-tuning to extract entities and relations and transform the input into a structured format. Our transformer-based model in this study outperformed previously applied approaches such as ANN and CNN models based on ROUGE-1, ROUGE-2, ROUGE-L, and BLEU scores of 0.816, 0.668, 0.528, and 0.743, respectively, while providing an interpretable structured report.
HERB: Measuring Hierarchical Regional Bias in Pre-trained Language Models
Nov 05, 2022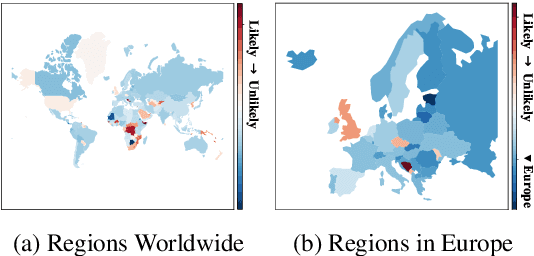
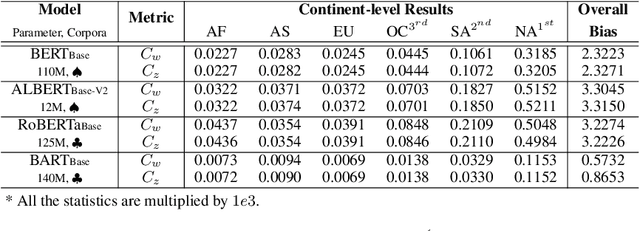
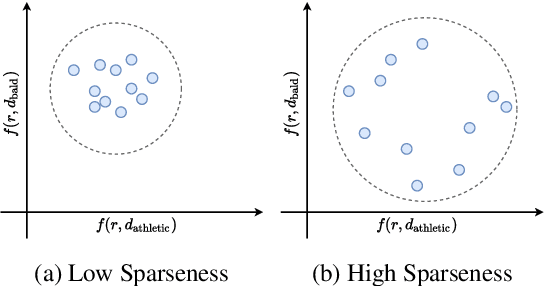
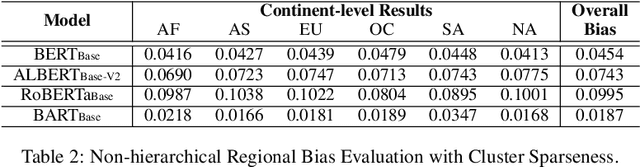
Fairness has become a trending topic in natural language processing (NLP), which addresses biases targeting certain social groups such as genders and religions. However, regional bias in language models (LMs), a long-standing global discrimination problem, still remains unexplored. This paper bridges the gap by analysing the regional bias learned by the pre-trained language models that are broadly used in NLP tasks. In addition to verifying the existence of regional bias in LMs, we find that the biases on regional groups can be strongly influenced by the geographical clustering of the groups. We accordingly propose a HiErarchical Regional Bias evaluation method (HERB) utilising the information from the sub-region clusters to quantify the bias in pre-trained LMs. Experiments show that our hierarchical metric can effectively evaluate the regional bias with respect to comprehensive topics and measure the potential regional bias that can be propagated to downstream tasks. Our codes are available at https://github.com/Bernard-Yang/HERB.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022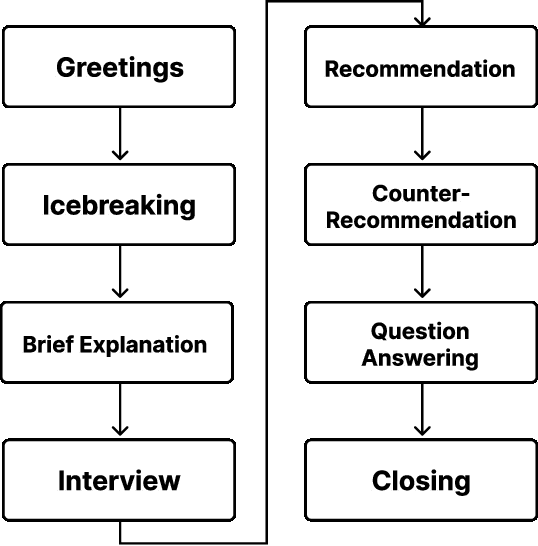



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.