 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Breaking the Symmetry: Resolving Symmetry Ambiguities in Equivariant Neural Networks
Oct 29, 2022
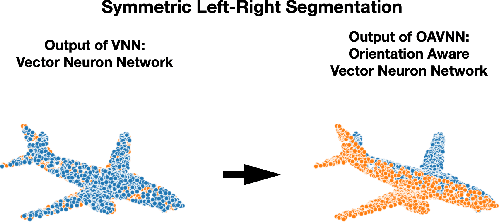
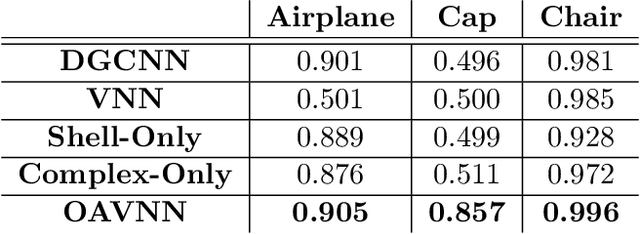
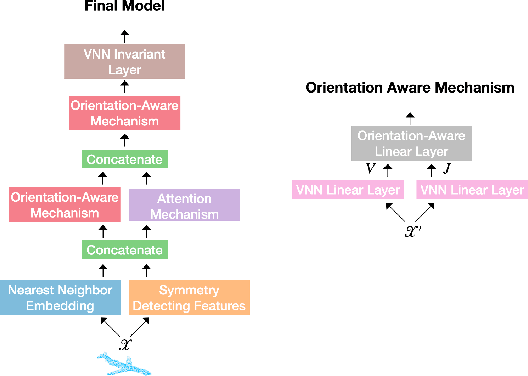
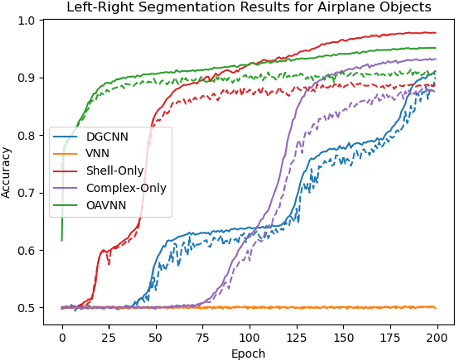
Equivariant networks have been adopted in many 3-D learning areas. Here we identify a fundamental limitation of these networks: their ambiguity to symmetries. Equivariant networks cannot complete symmetry-dependent tasks like segmenting a left-right symmetric object into its left and right sides. We tackle this problem by adding components that resolve symmetry ambiguities while preserving rotational equivariance. We present OAVNN: Orientation Aware Vector Neuron Network, an extension of the Vector Neuron Network. OAVNN is a rotation equivariant network that is robust to planar symmetric inputs. Our network consists of three key components. 1) We introduce an algorithm to calculate symmetry detecting features. 2) We create a symmetry-sensitive orientation aware linear layer. 3) We construct an attention mechanism that relates directional information across points. We evaluate the network using left-right segmentation and find that the network quickly obtains accurate segmentations. We hope this work motivates investigations on the expressivity of equivariant networks on symmetric objects.
Security-Preserving Federated Learning via Byzantine-Sensitive Triplet Distance
Oct 29, 2022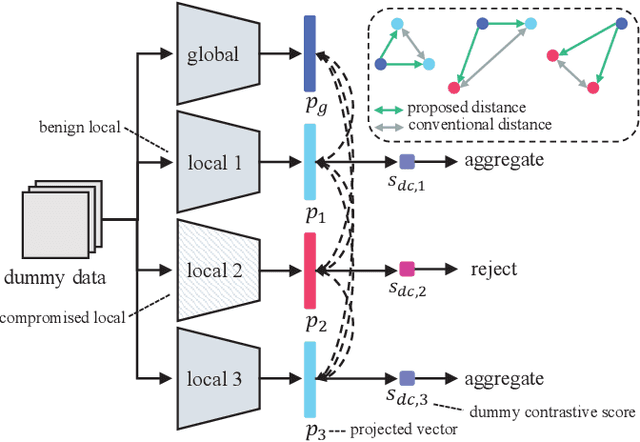
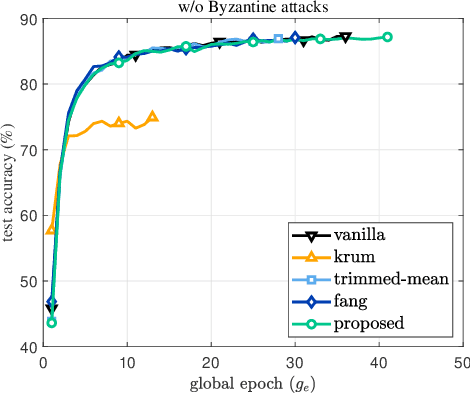
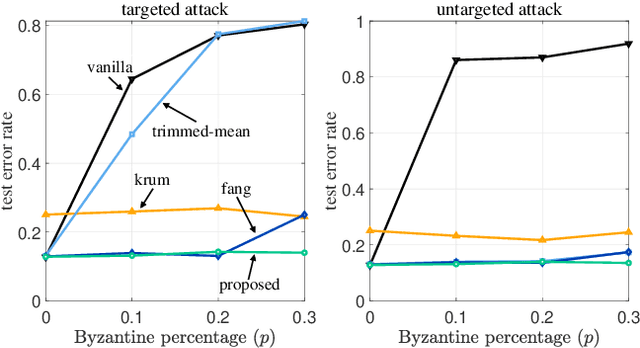
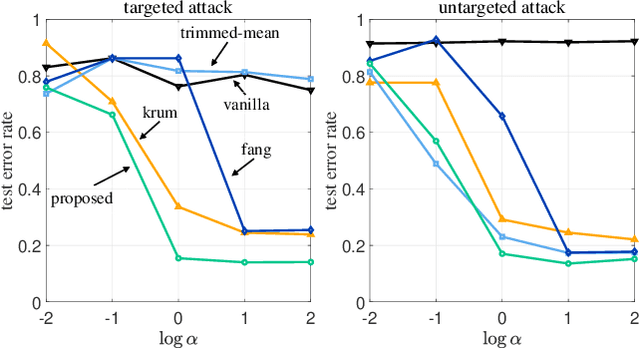
While being an effective framework of learning a shared model across multiple edge devices, federated learning (FL) is generally vulnerable to Byzantine attacks from adversarial edge devices. While existing works on FL mitigate such compromised devices by only aggregating a subset of the local models at the server side, they still cannot successfully ignore the outliers due to imprecise scoring rule. In this paper, we propose an effective Byzantine-robust FL framework, namely dummy contrastive aggregation, by defining a novel scoring function that sensitively discriminates whether the model has been poisoned or not. Key idea is to extract essential information from every local models along with the previous global model to define a distance measure in a manner similar to triplet loss. Numerical results validate the advantage of the proposed approach by showing improved performance as compared to the state-of-the-art Byzantine-resilient aggregation methods, e.g., Krum, Trimmed-mean, and Fang.
ReSel: N-ary Relation Extraction from Scientific Text and Tables by Learning to Retrieve and Select
Oct 26, 2022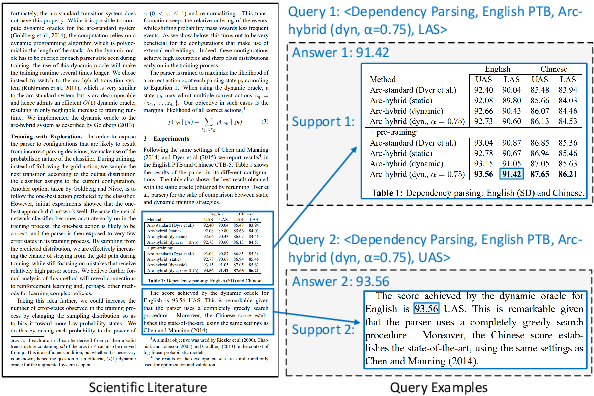
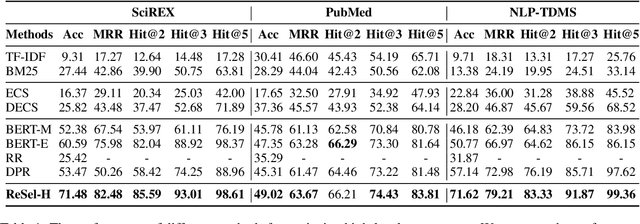
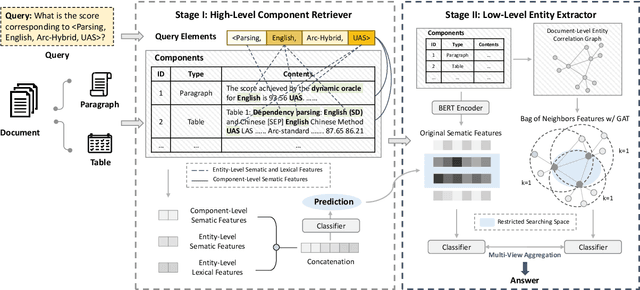
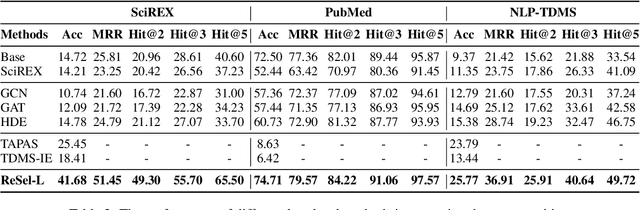
We study the problem of extracting N-ary relation tuples from scientific articles. This task is challenging because the target knowledge tuples can reside in multiple parts and modalities of the document. Our proposed method ReSel decomposes this task into a two-stage procedure that first retrieves the most relevant paragraph/table and then selects the target entity from the retrieved component. For the high-level retrieval stage, ReSel designs a simple and effective feature set, which captures multi-level lexical and semantic similarities between the query and components. For the low-level selection stage, ReSel designs a cross-modal entity correlation graph along with a multi-view architecture, which models both semantic and document-structural relations between entities. Our experiments on three scientific information extraction datasets show that ReSel outperforms state-of-the-art baselines significantly.
Adaptive scaling of the learning rate by second order automatic differentiation
Oct 26, 2022

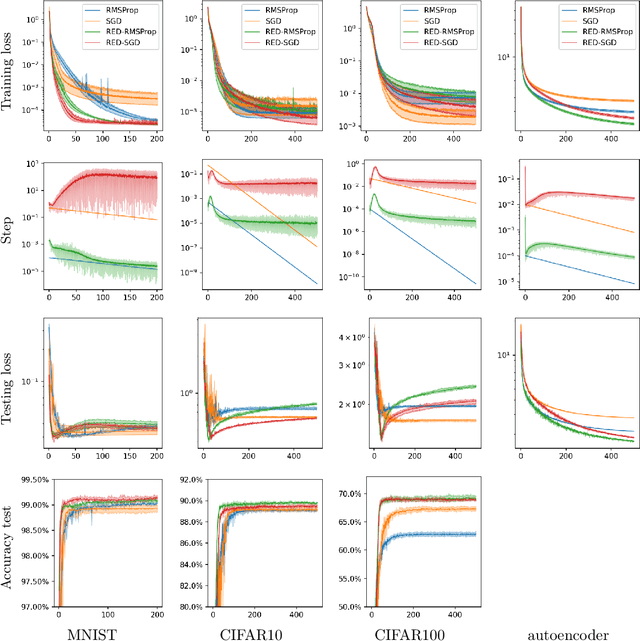
In the context of the optimization of Deep Neural Networks, we propose to rescale the learning rate using a new technique of automatic differentiation. This technique relies on the computation of the {\em curvature}, a second order information whose computational complexity is in between the computation of the gradient and the one of the Hessian-vector product. If (1C,1M) represents respectively the computational time and memory footprint of the gradient method, the new technique increase the overall cost to either (1.5C,2M) or (2C,1M). This rescaling has the appealing characteristic of having a natural interpretation, it allows the practitioner to choose between exploration of the parameters set and convergence of the algorithm. The rescaling is adaptive, it depends on the data and on the direction of descent. The numerical experiments highlight the different exploration/convergence regimes.
Autoregressive Structured Prediction with Language Models
Oct 26, 2022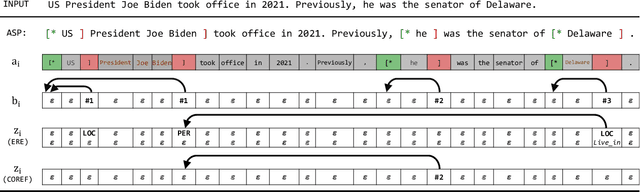

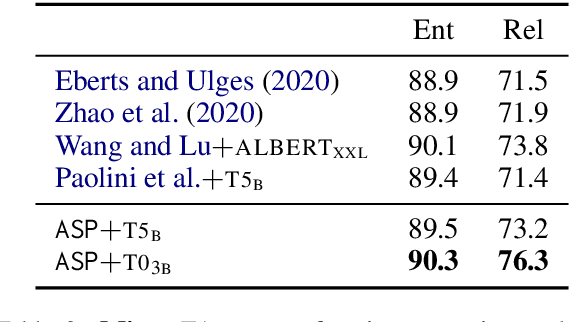
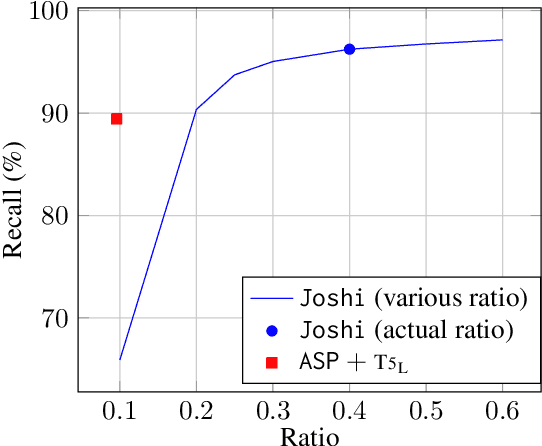
Recent years have seen a paradigm shift in NLP towards using pretrained language models ({PLM}) for a wide range of tasks. However, there are many difficult design decisions to represent structures (e.g. tagged text, coreference chains) in a way such that they can be captured by PLMs. Prior work on structured prediction with PLMs typically flattens the structured output into a sequence, which limits the quality of structural information being learned and leads to inferior performance compared to classic discriminative models. In this work, we describe an approach to model structures as sequences of actions in an autoregressive manner with PLMs, allowing in-structure dependencies to be learned without any loss. Our approach achieves the new state-of-the-art on all the structured prediction tasks we looked at, namely, named entity recognition, end-to-end relation extraction, and coreference resolution.
Relational Proxies: Emergent Relationships as Fine-Grained Discriminators
Oct 05, 2022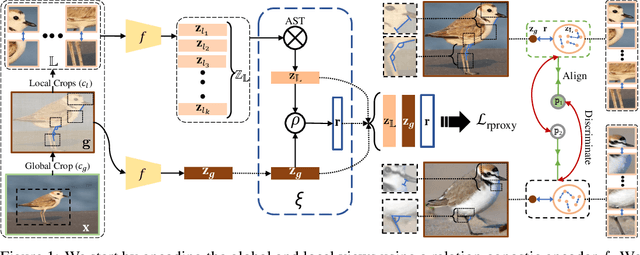
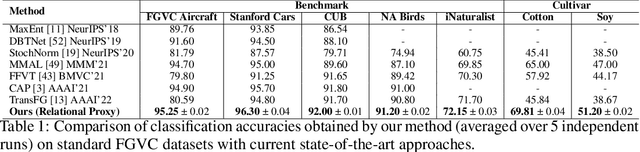


Fine-grained categories that largely share the same set of parts cannot be discriminated based on part information alone, as they mostly differ in the way the local parts relate to the overall global structure of the object. We propose Relational Proxies, a novel approach that leverages the relational information between the global and local views of an object for encoding its semantic label. Starting with a rigorous formalization of the notion of distinguishability between fine-grained categories, we prove the necessary and sufficient conditions that a model must satisfy in order to learn the underlying decision boundaries in the fine-grained setting. We design Relational Proxies based on our theoretical findings and evaluate it on seven challenging fine-grained benchmark datasets and achieve state-of-the-art results on all of them, surpassing the performance of all existing works with a margin exceeding 4% in some cases. We also experimentally validate our theory on fine-grained distinguishability and obtain consistent results across multiple benchmarks. Implementation is available at https://github.com/abhrac/relational-proxies.
Structure-based drug design with geometric deep learning
Oct 19, 2022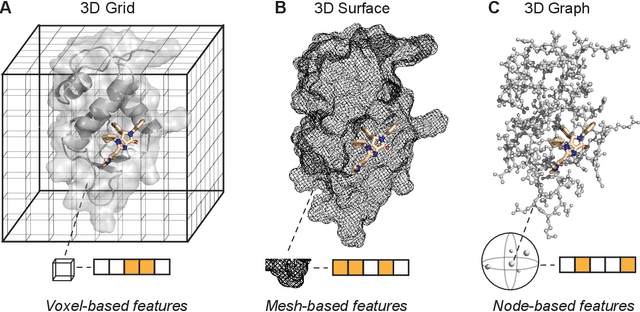
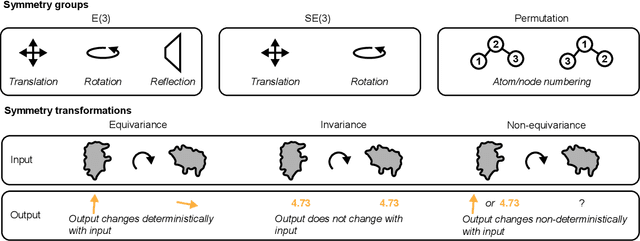
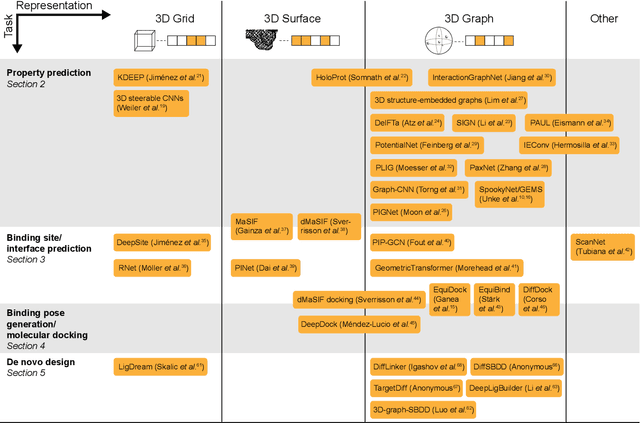
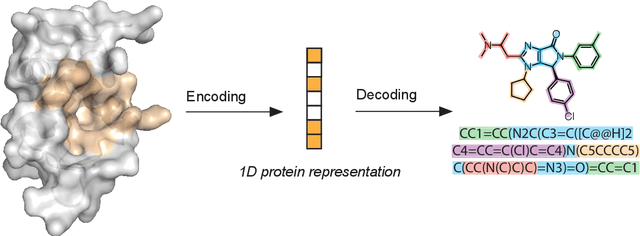
Structure-based drug design uses three-dimensional geometric information of macromolecules, such as proteins or nucleic acids, to identify suitable ligands. Geometric deep learning, an emerging concept of neural-network-based machine learning, has been applied to macromolecular structures. This review provides an overview of the recent applications of geometric deep learning in bioorganic and medicinal chemistry, highlighting its potential for structure-based drug discovery and design. Emphasis is placed on molecular property prediction, ligand binding site and pose prediction, and structure-based de novo molecular design. The current challenges and opportunities are highlighted, and a forecast of the future of geometric deep learning for drug discovery is presented.
Distributed Coordination Based on Quantum Entanglement
Oct 19, 2022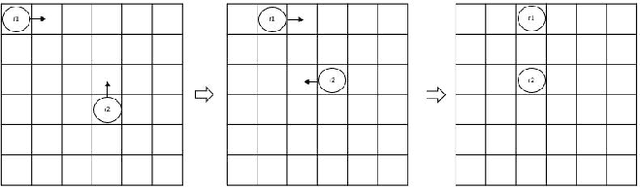
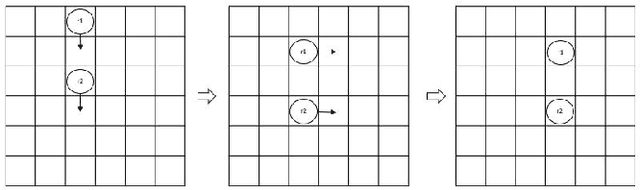
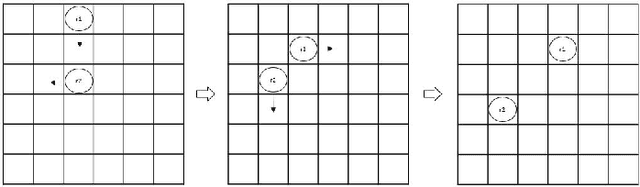
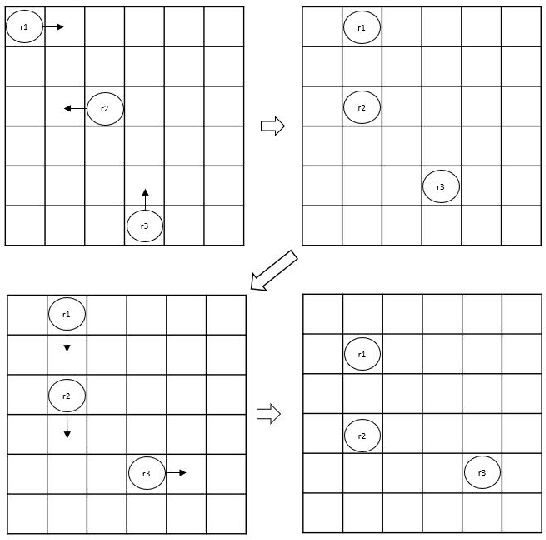
This paper demonstrates and proves that the coordination of actions in a distributed swarm can be enhanced by using quantum entanglement. In particular, we focus on - Global and local simultaneous random walks, using entangled qubits that collapse into the same (or opposite) direction, either random direction or totally controlled simultaneous movements. - Identifying eavesdropping from malicious eavesdroppers aimed at disturbing the simultaneous random walks by using entangled qubits that were sent at random or with predefined bases. - Identifying Byzantine robots or malicious robots that are trying to gain secret information or are attacking the system using entangled qubits. - The use of Pseudo Telepathy to coordinate robots' actions.
CEntRE: A paragraph-level Chinese dataset for Relation Extraction among Enterprises
Oct 19, 2022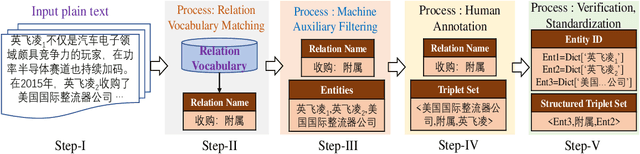

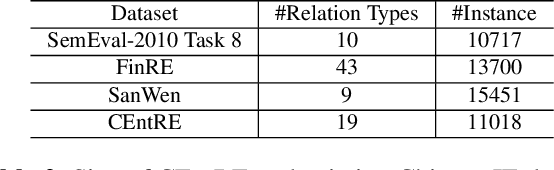

Enterprise relation extraction aims to detect pairs of enterprise entities and identify the business relations between them from unstructured or semi-structured text data, and it is crucial for several real-world applications such as risk analysis, rating research and supply chain security. However, previous work mainly focuses on getting attribute information about enterprises like personnel and corporate business, and pays little attention to enterprise relation extraction. To encourage further progress in the research, we introduce the CEntRE, a new dataset constructed from publicly available business news data with careful human annotation and intelligent data processing. Extensive experiments on CEntRE with six excellent models demonstrate the challenges of our proposed dataset.
Reliability in Time: Evaluating the Web Sources of Information on COVID-19 in Wikipedia across Various Language Editions from the Beginning of the Pandemic
Apr 29, 2022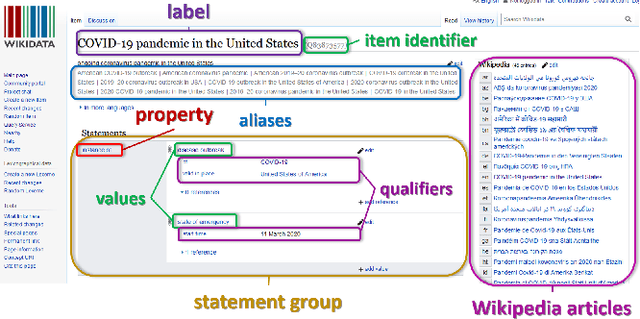
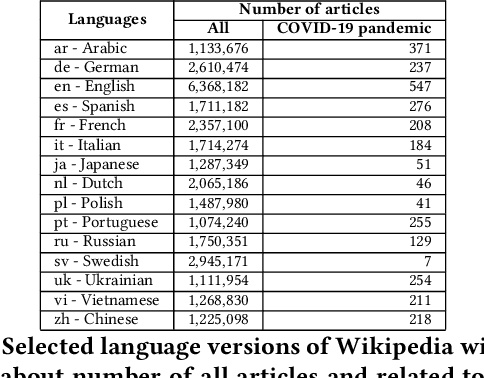
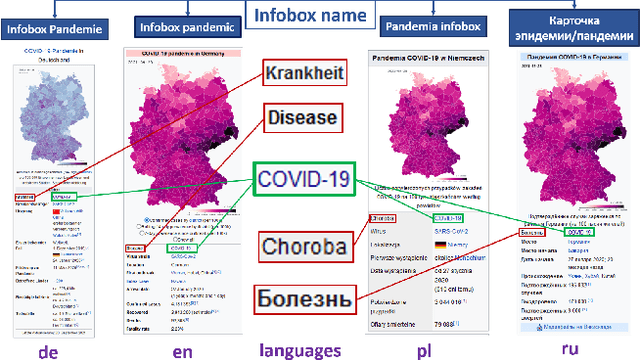
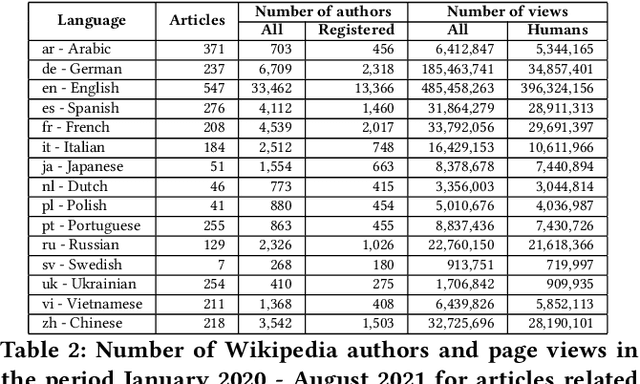
There are over a billion websites on the Internet that can potentially serve as sources of information on various topics. One of the most popular examples of such an online source is Wikipedia. This public knowledge base is co-edited by millions of users from all over the world. Information in each language version of Wikipedia can be created and edited independently. Therefore, we can observe certain inconsistencies in the statements and facts described therein - depending on language and topic. In accordance with the Wikipedia content authoring guidelines, information in Wikipedia articles should be based on reliable, published sources. So, based on data from such a collaboratively edited encyclopedia, we should also be able to find important sources on specific topics. This effect can be potentially useful for people and organizations. The reliability of a source in Wikipedia articles depends on the context. So the same source (website) may have various degrees of reliability in Wikipedia depending on topic and language version. Moreover, reliability of the same source can change over the time. The purpose of this study is to identify reliable sources on a specific topic - the COVID-19 pandemic. Such an analysis was carried out on real data from Wikipedia within selected language versions and within a selected time period.