 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Principled Data-Driven Decision Support for Cyber-Forensic Investigations
Nov 23, 2022

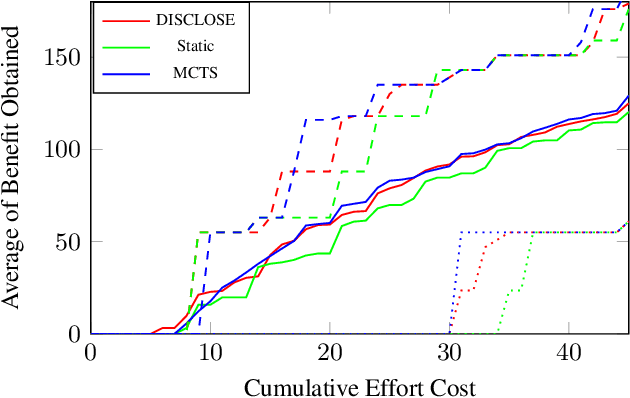
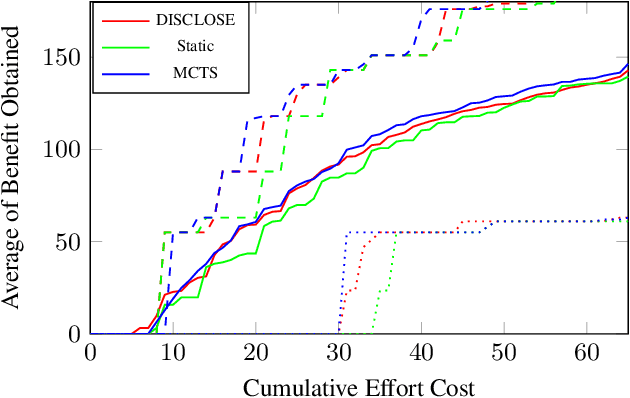
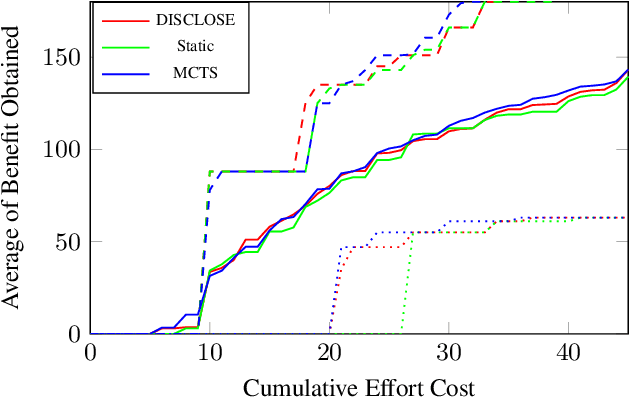
In the wake of a cybersecurity incident, it is crucial to promptly discover how the threat actors breached security in order to assess the impact of the incident and to develop and deploy countermeasures that can protect against further attacks. To this end, defenders can launch a cyber-forensic investigation, which discovers the techniques that the threat actors used in the incident. A fundamental challenge in such an investigation is prioritizing the investigation of particular techniques since the investigation of each technique requires time and effort, but forensic analysts cannot know which ones were actually used before investigating them. To ensure prompt discovery, it is imperative to provide decision support that can help forensic analysts with this prioritization. A recent study demonstrated that data-driven decision support, based on a dataset of prior incidents, can provide state-of-the-art prioritization. However, this data-driven approach, called DISCLOSE, is based on a heuristic that utilizes only a subset of the available information and does not approximate optimal decisions. To improve upon this heuristic, we introduce a principled approach for data-driven decision support for cyber-forensic investigations. We formulate the decision-support problem using a Markov decision process, whose states represent the states of a forensic investigation. To solve the decision problem, we propose a Monte Carlo tree search based method, which relies on a k-NN regression over prior incidents to estimate state-transition probabilities. We evaluate our proposed approach on multiple versions of the MITRE ATT&CK dataset, which is a knowledge base of adversarial techniques and tactics based on real-world cyber incidents, and demonstrate that our approach outperforms DISCLOSE in terms of techniques discovered per effort spent.
Age of Information in the Presence of an Adversary
Feb 08, 2022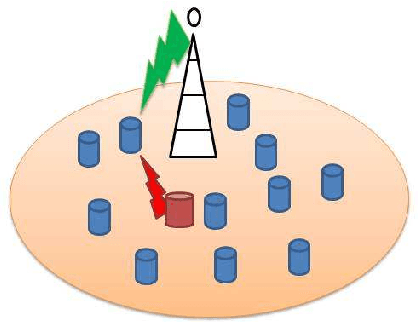
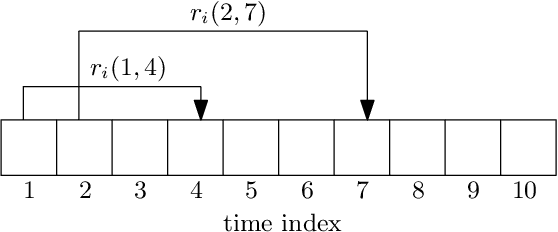
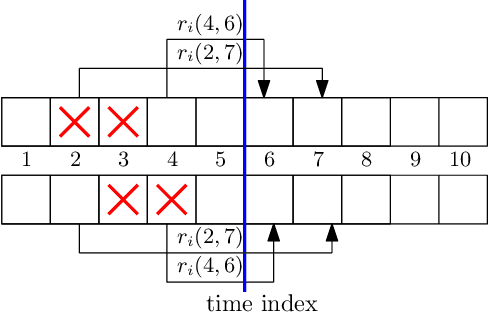
We consider a communication system where a base station serves $N$ users, one user at a time, over a wireless channel. We consider the timeliness of the communication of each user via the age of information metric. A constrained adversary can block at most a given fraction, $\alpha$, of the time slots over a horizon of $T$ slots, i.e., it can block at most $\alpha T$ slots. We show that an optimum adversary blocks $\alpha T$ consecutive time slots of a randomly selected user. The interesting consecutive property of the blocked time slots is due to the cumulative nature of the age metric.
Mining Word Boundaries in Speech as Naturally Annotated Word Segmentation Data
Oct 31, 2022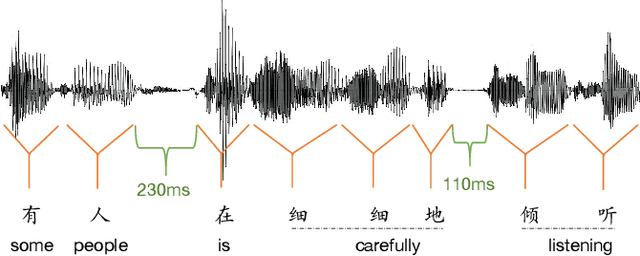
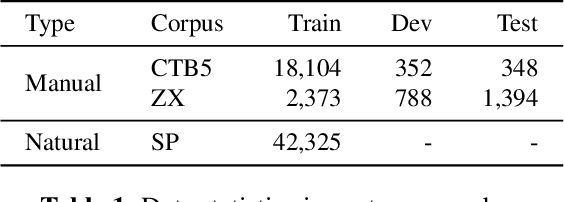
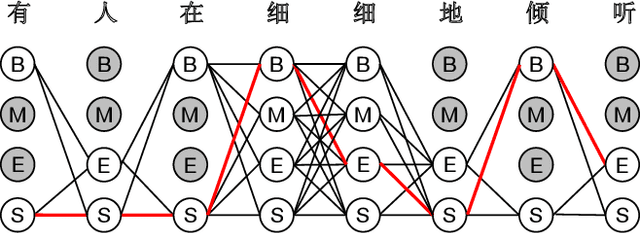
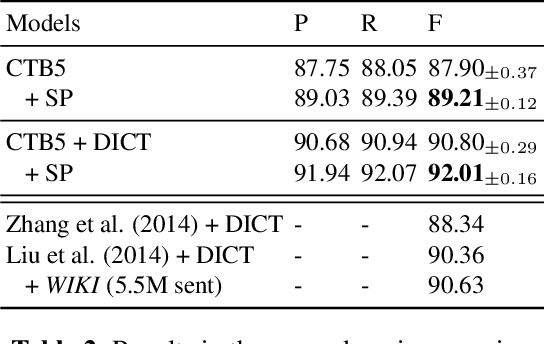
Chinese word segmentation (CWS) models have achieved very high performance when the training data is sufficient and in-domain. However, the performance drops drastically when shifting to cross-domain and low-resource scenarios due to data sparseness issues. Considering that constructing large-scale manually annotated data is time-consuming and labor-intensive, in this work, we for the first time propose to mine word boundary information from pauses in speech to efficiently obtain large-scale CWS naturally annotated data. We present a simple yet effective complete-then-train method to utilize these natural annotations from speech for CWS model training. Extensive experiments demonstrate that the CWS performance in cross-domain and low-resource scenarios can be significantly improved by leveraging our naturally annotated data extracted from speech.
Unifying Data Perspectivism and Personalization: An Application to Social Norms
Oct 31, 2022
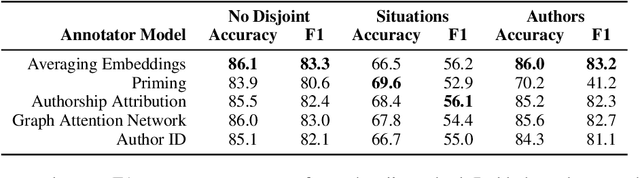
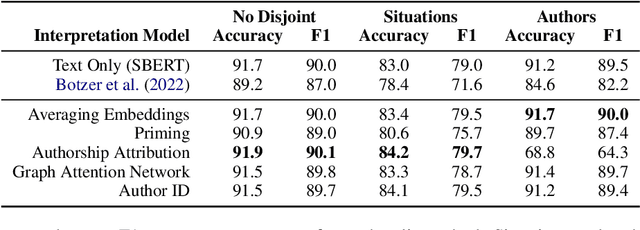
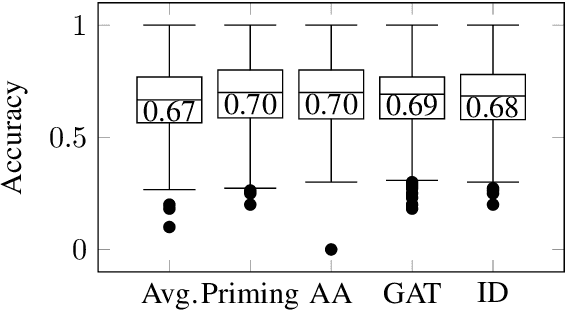
Instead of using a single ground truth for language processing tasks, several recent studies have examined how to represent and predict the labels of the set of annotators. However, often little or no information about annotators is known, or the set of annotators is small. In this work, we examine a corpus of social media posts about conflict from a set of 13k annotators and 210k judgements of social norms. We provide a novel experimental setup that applies personalization methods to the modeling of annotators and compare their effectiveness for predicting the perception of social norms. We further provide an analysis of performance across subsets of social situations that vary by the closeness of the relationship between parties in conflict, and assess where personalization helps the most.
Efficient View Path Planning for Autonomous Implicit Reconstruction
Sep 27, 2022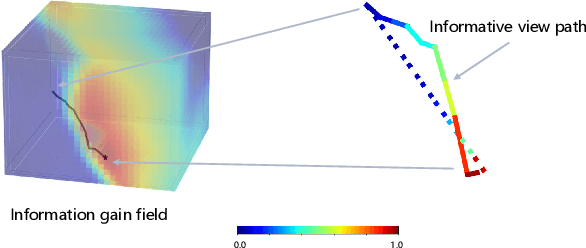
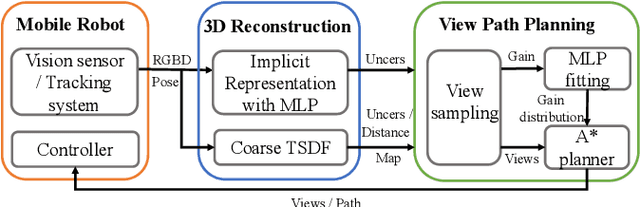


Implicit neural representations have shown promising potential for the 3D scene reconstruction. Recent work applies it to autonomous 3D reconstruction by learning information gain for view path planning. Effective as it is, the computation of the information gain is expensive, and compared with that using volumetric representations, collision checking using the implicit representation for a 3D point is much slower. In the paper, we propose to 1) leverage a neural network as an implicit function approximator for the information gain field and 2) combine the implicit fine-grained representation with coarse volumetric representations to improve efficiency. Further with the improved efficiency, we propose a novel informative path planning based on a graph-based planner. Our method demonstrates significant improvements in the reconstruction quality and planning efficiency compared with autonomous reconstructions with implicit and explicit representations. We deploy the method on a real UAV and the results show that our method can plan informative views and reconstruct a scene with high quality.
APAUNet: Axis Projection Attention UNet for Small Target in 3D Medical Segmentation
Oct 04, 2022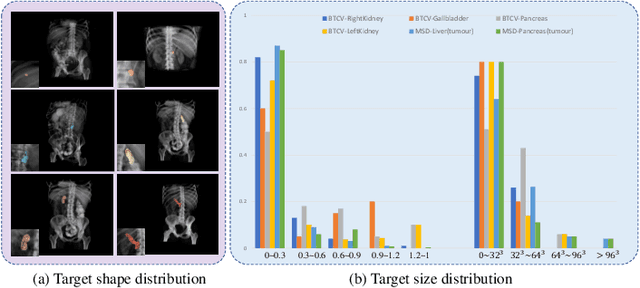
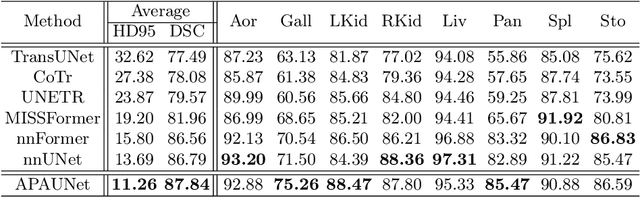
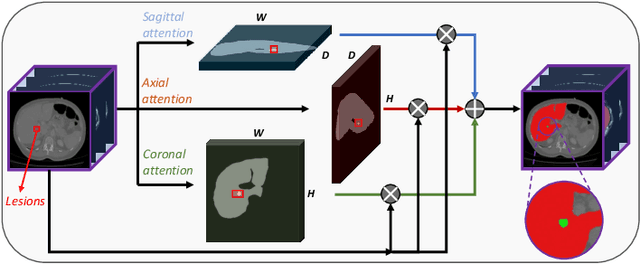
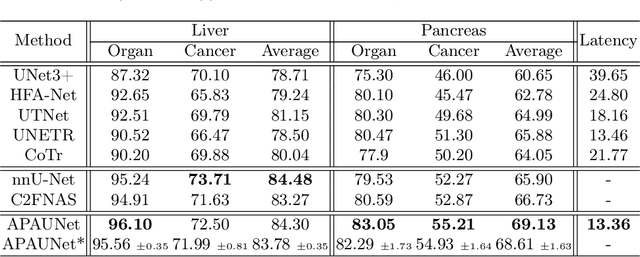
In 3D medical image segmentation, small targets segmentation is crucial for diagnosis but still faces challenges. In this paper, we propose the Axis Projection Attention UNet, named APAUNet, for 3D medical image segmentation, especially for small targets. Considering the large proportion of the background in the 3D feature space, we introduce a projection strategy to project the 3D features into three orthogonal 2D planes to capture the contextual attention from different views. In this way, we can filter out the redundant feature information and mitigate the loss of critical information for small lesions in 3D scans. Then we utilize a dimension hybridization strategy to fuse the 3D features with attention from different axes and merge them by a weighted summation to adaptively learn the importance of different perspectives. Finally, in the APA Decoder, we concatenate both high and low resolution features in the 2D projection process, thereby obtaining more precise multi-scale information, which is vital for small lesion segmentation. Quantitative and qualitative experimental results on two public datasets (BTCV and MSD) demonstrate that our proposed APAUNet outperforms the other methods. Concretely, our APAUNet achieves an average dice score of 87.84 on BTCV, 84.48 on MSD-Liver and 69.13 on MSD-Pancreas, and significantly surpass the previous SOTA methods on small targets.
Circular Pythagorean fuzzy sets and applications to multi-criteria decision making
Oct 27, 2022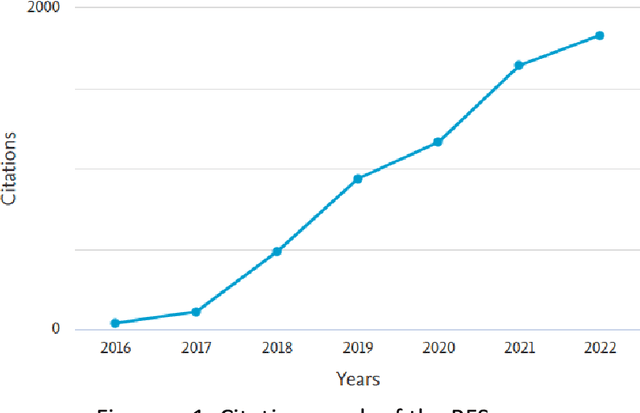
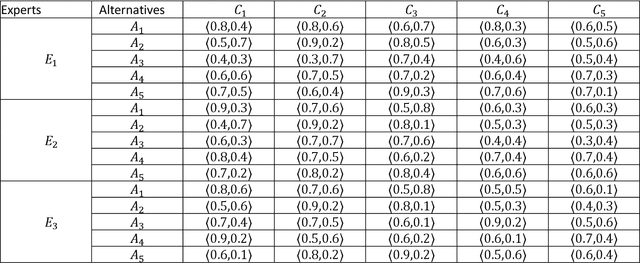
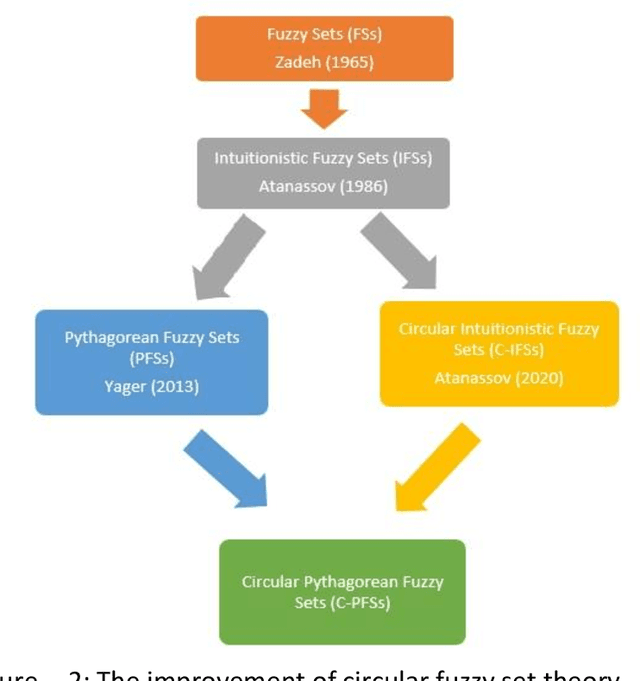
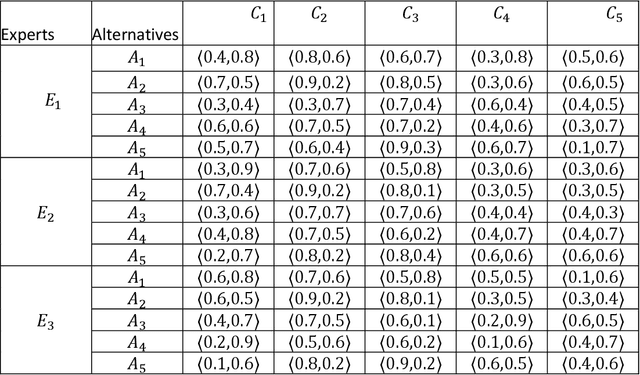
In this paper, we introduce the concept of circular Pythagorean fuzzy set (value) (C-PFS(V)) as a new generalization of both circular intuitionistic fuzzy sets (C-IFSs) proposed by Atannassov and Pythagorean fuzzy sets (PFSs) proposed by Yager. A circular Pythagorean fuzzy set is represented by a circle that represents the membership degree and the non-membership degree and whose center consists of non-negative real numbers $\mu$ and $\nu$ with the condition $\mu^2+\nu^2\leq 1$. A C-PFS models the fuzziness of the uncertain information more properly thanks to its structure that allows modelling the information with points of a circle of a certain center and a radius. Therefore, a C-PFS lets decision makers to evaluate objects in a larger and more flexible region and thus more sensitive decisions can be made. After defining the concept of C-PFS we define some fundamental set operations between C-PFSs and propose some algebraic operations between C-PFVs via general $t$-norms and $t$-conorms. By utilizing these algebraic operations, we introduce some weighted aggregation operators to transform input values represented by C-PFVs to a single output value. Then to determine the degree of similarity between C-PFVs we define a cosine similarity measure based on radius. Furthermore, we develop a method to transform a collection of Pythagorean fuzzy values to a PFS. Finally, a method is given to solve multi-criteria decision making problems in circular Pythagorean fuzzy environment and the proposed method is practiced to a problem about selecting the best photovoltaic cell from the literature. We also study the comparison analysis and time complexity of the proposed method.
Overcoming Barriers to Skill Injection in Language Modeling: Case Study in Arithmetic
Nov 03, 2022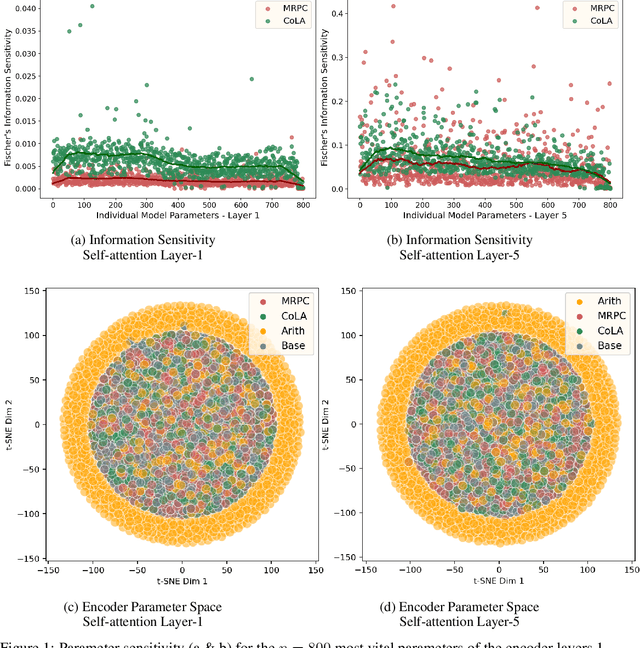

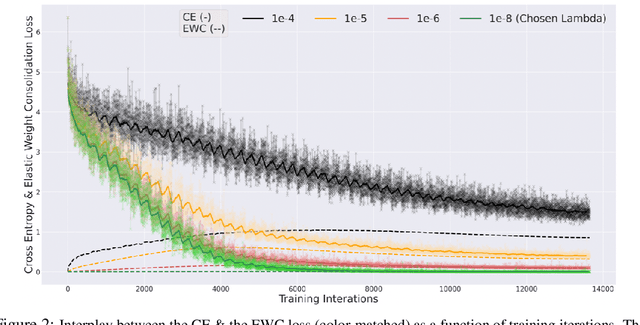
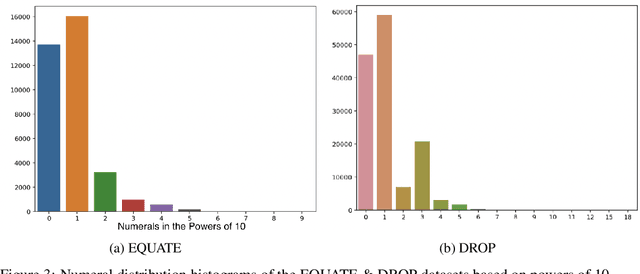
Through their transfer learning abilities, highly-parameterized large pre-trained language models have dominated the NLP landscape for a multitude of downstream language tasks. Though linguistically proficient, the inability of these models to incorporate the learning of non-linguistic entities (numerals and arithmetic reasoning) limits their usage for tasks that require numeric comprehension or strict mathematical reasoning. However, as we illustrate in this paper, building a general purpose language model that also happens to be proficient in mathematical reasoning is not as straight-forward as training it on a numeric dataset. In this work, we develop a novel framework that enables language models to be mathematically proficient while retaining their linguistic prowess. Specifically, we offer information-theoretic interventions to overcome the catastrophic forgetting of linguistic skills that occurs while injecting non-linguistic skills into language models.
Making Machine Learning Datasets and Models FAIR for HPC: A Methodology and Case Study
Nov 03, 2022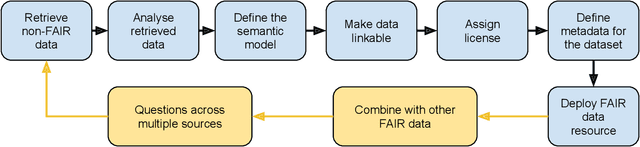
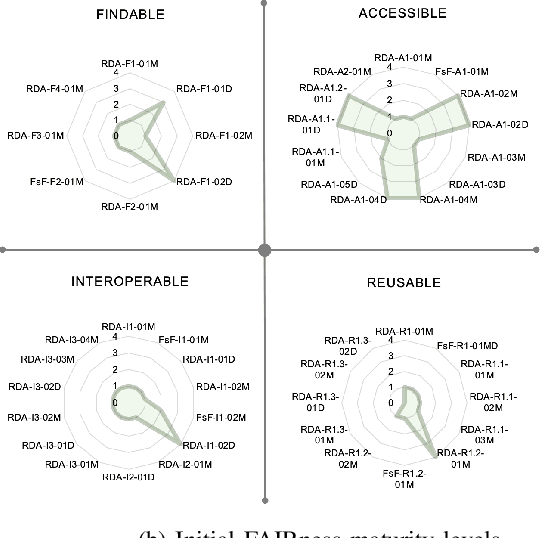
The FAIR Guiding Principles aim to improve the findability, accessibility, interoperability, and reusability of digital content by making them both human and machine actionable. However, these principles have not yet been broadly adopted in the domain of machine learning-based program analyses and optimizations for High-Performance Computing (HPC). In this paper, we design a methodology to make HPC datasets and machine learning models FAIR after investigating existing FAIRness assessment and improvement techniques. Our methodology includes a comprehensive, quantitative assessment for elected data, followed by concrete, actionable suggestions to improve FAIRness with respect to common issues related to persistent identifiers, rich metadata descriptions, license and provenance information. Moreover, we select a representative training dataset to evaluate our methodology. The experiment shows the methodology can effectively improve the dataset and model's FAIRness from an initial score of 19.1% to the final score of 83.0%.
Learning Dependencies of Discrete Speech Representations with Neural Hidden Markov Models
Oct 29, 2022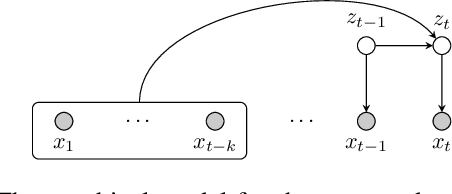
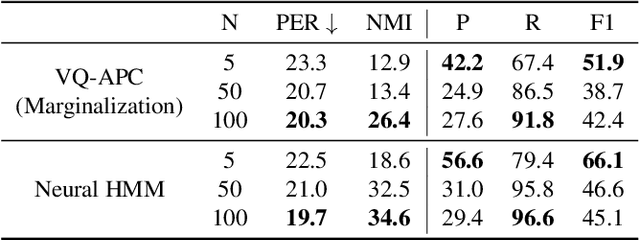
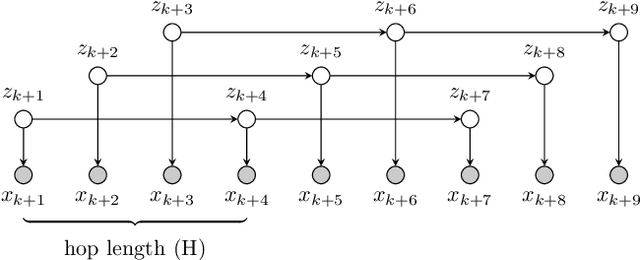
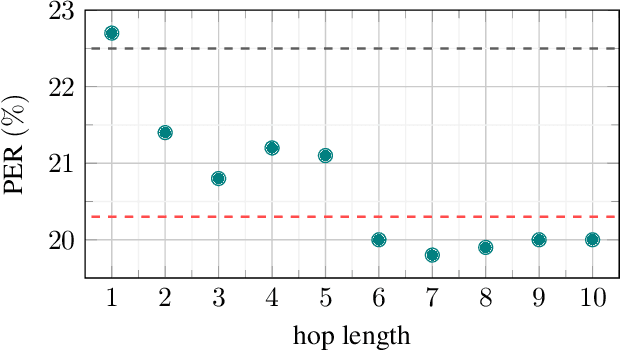
While discrete latent variable models have had great success in self-supervised learning, most models assume that frames are independent. Due to the segmental nature of phonemes in speech perception, modeling dependencies among latent variables at the frame level can potentially improve the learned representations on phonetic-related tasks. In this work, we assume Markovian dependencies among latent variables, and propose to learn speech representations with neural hidden Markov models. Our general framework allows us to compare to self-supervised models that assume independence, while keeping the number of parameters fixed. The added dependencies improve the accessibility of phonetic information, phonetic segmentation, and the cluster purity of phones, showcasing the benefit of the assumed dependencies.