 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CabViT: Cross Attention among Blocks for Vision Transformer
Nov 14, 2022
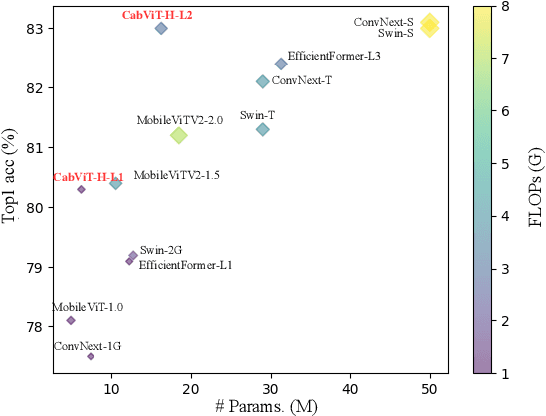
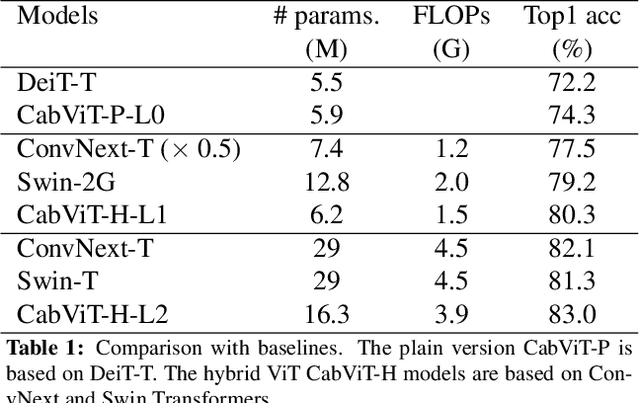
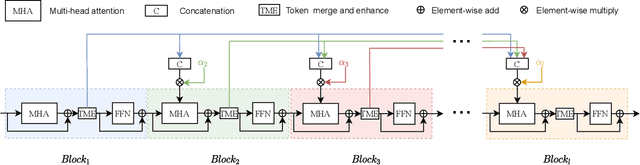
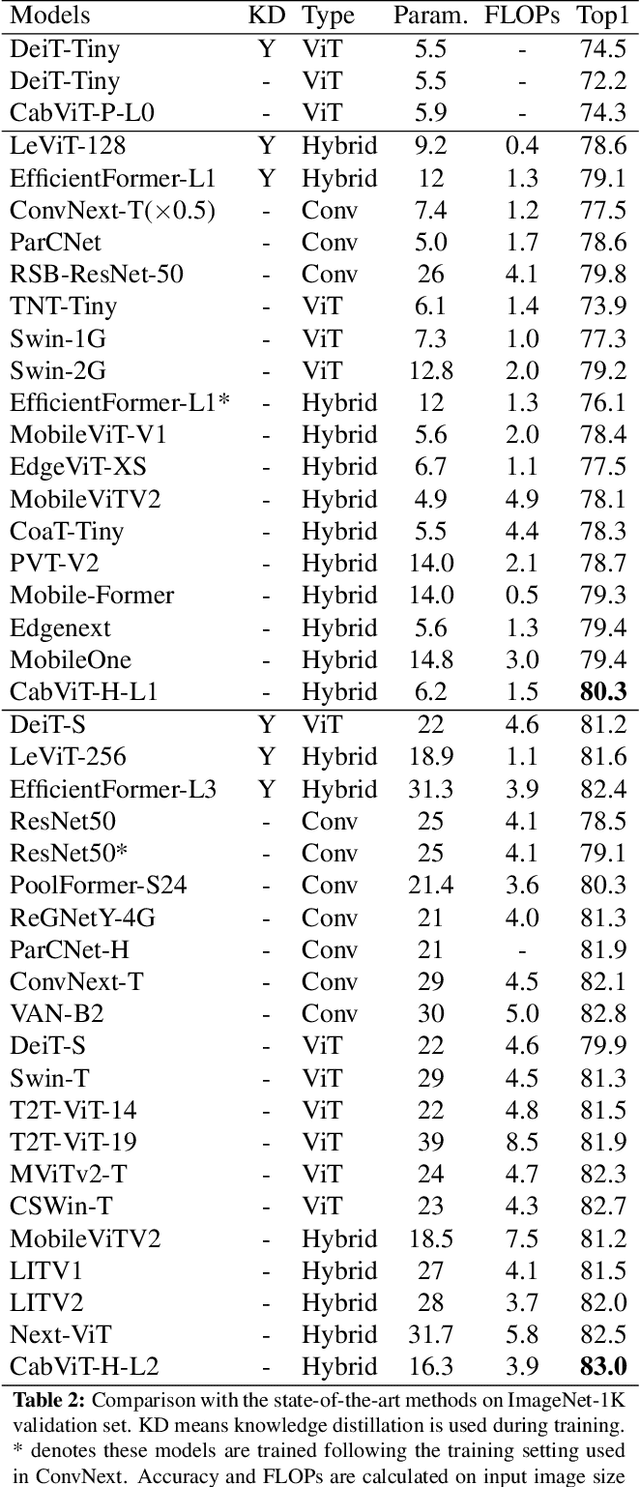
Since the vision transformer (ViT) has achieved impressive performance in image classification, an increasing number of researchers pay their attentions to designing more efficient vision transformer models. A general research line is reducing computational cost of self attention modules by adopting sparse attention or using local attention windows. In contrast, we propose to design high performance transformer based architectures by densifying the attention pattern. Specifically, we propose cross attention among blocks of ViT (CabViT), which uses tokens from previous blocks in the same stage as extra input to the multi-head attention of transformers. The proposed CabViT enhances the interactions of tokens across blocks with potentially different semantics, and encourages more information flows to the lower levels, which together improves model performance and model convergence with limited extra cost. Based on the proposed CabViT, we design a series of CabViT models which achieve the best trade-off between model size, computational cost and accuracy. For instance without the need of knowledge distillation to strength the training, CabViT achieves 83.0% top-1 accuracy on Imagenet with only 16.3 million parameters and about 3.9G FLOPs, saving almost half parameters and 13% computational cost while gaining 0.9% higher accuracy compared with ConvNext, use 52% of parameters but gaining 0.6% accuracy compared with distilled EfficientFormer
Towards Understanding Omission in Dialogue Summarization
Nov 14, 2022
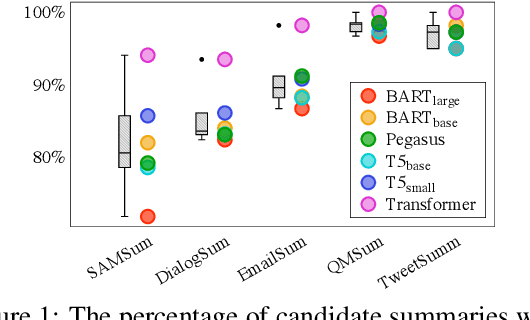
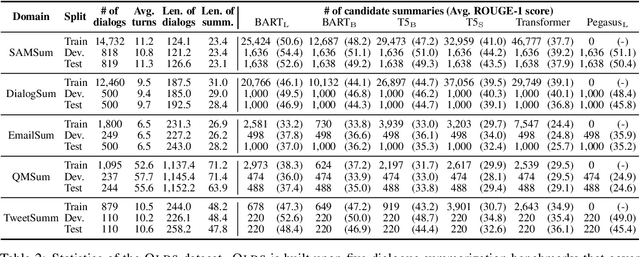
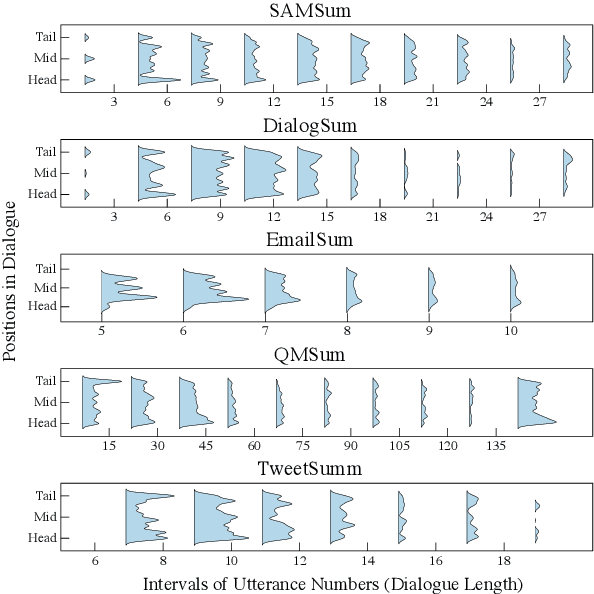
Dialogue summarization aims to condense the lengthy dialogue into a concise summary, and has recently achieved significant progress. However, the result of existing methods is still far from satisfactory. Previous works indicated that omission is a major factor in affecting the quality of summarization, but few of them have further explored the omission problem, such as how omission affects summarization results and how to detect omission, which is critical for reducing omission and improving summarization quality. Moreover, analyzing and detecting omission relies on summarization datasets with omission labels (i.e., which dialogue utterances are omitted in the summarization), which are not available in the current literature. In this paper, we propose the OLDS dataset, which provides high-quality Omission Labels for Dialogue Summarization. By analyzing this dataset, we find that a large improvement in summarization quality can be achieved by providing ground-truth omission labels for the summarization model to recover omission information, which demonstrates the importance of omission detection for omission mitigation in dialogue summarization. Therefore, we formulate an omission detection task and demonstrate our proposed dataset can support the training and evaluation of this task well. We also call for research action on omission detection based on our proposed datasets. Our dataset and codes are publicly available.
State of the Art of User Simulation approaches for conversational information retrieval
Jan 10, 2022Conversational Information Retrieval (CIR) is an emerging field of Information Retrieval (IR) at the intersection of interactive IR and dialogue systems for open domain information needs. In order to optimize these interactions and enhance the user experience, it is necessary to improve IR models by taking into account sequential heterogeneous user-system interactions. Reinforcement learning has emerged as a paradigm particularly suited to optimize sequential decision making in many domains and has recently appeared in IR. However, training these systems by reinforcement learning on users is not feasible. One solution is to train IR systems on user simulations that model the behavior of real users. Our contribution is twofold: 1)reviewing the literature on user modeling and user simulation for information access, and 2) discussing the different research perspectives for user simulations in the context of CIR
LVOS: A Benchmark for Long-term Video Object Segmentation
Nov 18, 2022
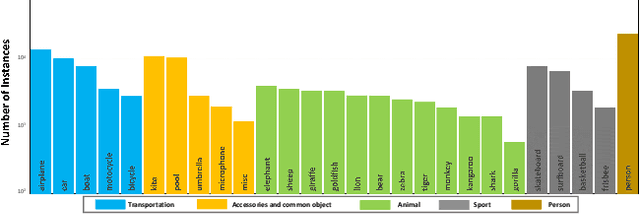
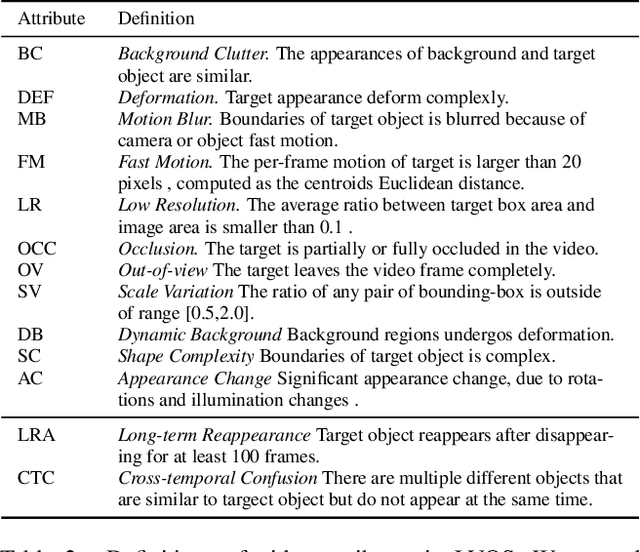
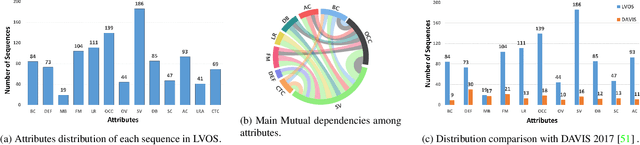
Existing video object segmentation (VOS) benchmarks focus on short-term videos which just last about 3-5 seconds and where objects are visible most of the time. These videos are poorly representative of practical applications, and the absence of long-term datasets restricts further investigation of VOS on the application in realistic scenarios. So, in this paper, we present a new benchmark dataset and evaluation methodology named LVOS, which consists of 220 videos with a total duration of 421 minutes. To the best of our knowledge, LVOS is the first densely annotated long-term VOS dataset. The videos in our LVOS last 1.59 minutes on average, which is 20 times longer than videos in existing VOS datasets. Each video includes various attributes, especially challenges deriving from the wild, such as long-term reappearing and cross-temporal similar objeccts. Moreover, we provide additional language descriptions to encourage the exploration of integrating linguistic and visual features for video object segmentation. Based on LVOS, we assess existing video object segmentation algorithms and propose a Diverse Dynamic Memory network (DDMemory) that consists of three complementary memory banks to exploit temporal information adequately. The experiment results demonstrate the strength and weaknesses of prior methods, pointing promising directions for further study. Our objective is to provide the community with a large and varied benchmark to boost the advancement of long-term VOS. Data and code are available at \url{https://lingyihongfd.github.io/lvos.github.io/}.
Recent Advances in Algebraic Geometry and Bayesian Statistics
Nov 18, 2022This article is a review of theoretical advances in the research field of algebraic geometry and Bayesian statistics in the last two decades. Many statistical models and learning machines which contain hierarchical structures or latent variables are called nonidentifiable, because the map from a parameter to a statistical model is not one-to-one. In nonidentifiable models, both the likelihood function and the posterior distribution have singularities in general, hence it was difficult to analyze their statistical properties. However, from the end of the 20th century, new theory and methodology based on algebraic geometry have been established which enables us to investigate such models and machines in the real world. In this article, the following results in recent advances are reported. First, we explain the framework of Bayesian statistics and introduce a new perspective from the birational geometry. Second, two mathematical solutions are derived based on algebraic geometry. An appropriate parameter space can be found by a resolution map, which makes the posterior distribution be normal crossing and the log likelihood ratio function be well-defined. Third, three applications to statistics are introduced. The posterior distribution is represented by the renormalized form, the asymptotic free energy is derived, and the universal formula among the generalization loss, the cross validation, and the information criterion is established. Two mathematical solutions and three applications to statistics based on algebraic geometry reported in this article are now being used in many practical fields in data science and artificial intelligence.
Improving Feature-based Visual Localization by Geometry-Aided Matching
Nov 16, 2022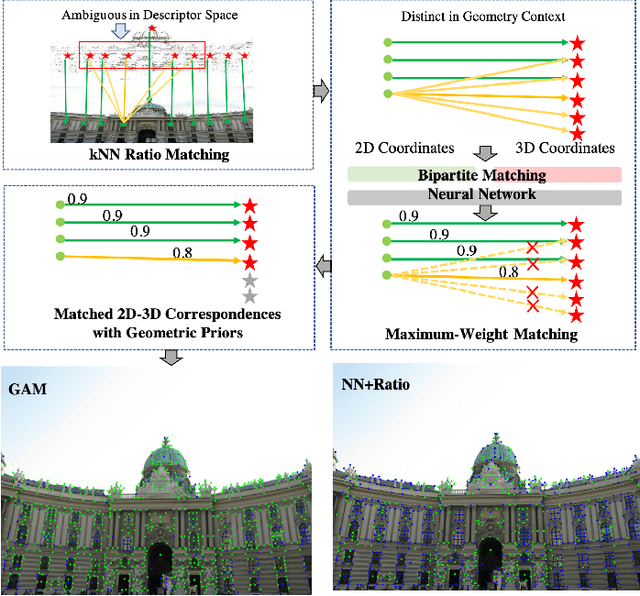
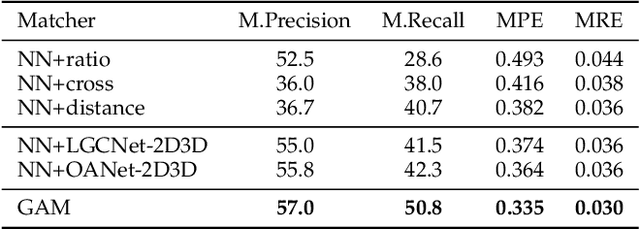
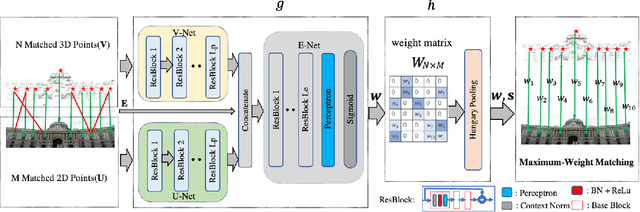
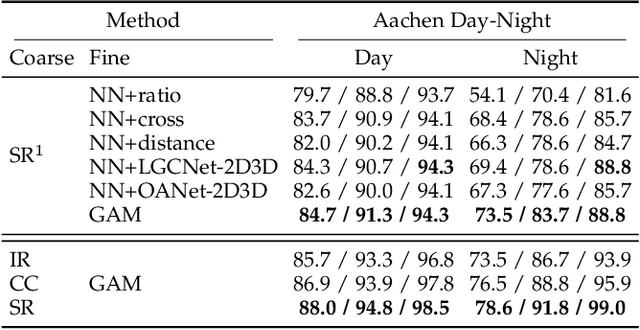
Feature matching is an essential step in visual localization, where the accuracy of camera pose is mainly determined by the established 2D-3D correspondence. Due to the noise, solving the camera pose accurately requires a sufficient number of well-distributed 2D-3D correspondences. Existing 2D-3D feature matching is typically achieved by finding the nearest neighbors in the feature space, and then removing the outliers by some hand-crafted heuristics. However, this may lead to a large number of potentially true matches being missed or the established correct matches being filtered out. In this work, we introduce a novel 2D-3D matching method, Geometry-Aided Matching (GAM), which uses both appearance information and geometric context to improve 2D-3D feature matching. GAM can greatly strengthen the recall of 2D-3D matches while maintaining high precision. We insert GAM into a hierarchical visual localization pipeline and show that GAM can effectively improve the robustness and accuracy of localization. Extensive experiments show that GAM can find more correct matches than hand-crafted heuristics and learning baselines. Our proposed localization method achieves state-of-the-art results on multiple visual localization datasets. Experiments on Cambridge Landmarks dataset show that our method outperforms the existing state-of-the-art methods and is six times faster than the top-performed method.
Prediction and Uncertainty Quantification of SAFARI-1 Axial Neutron Flux Profiles with Neural Networks
Nov 16, 2022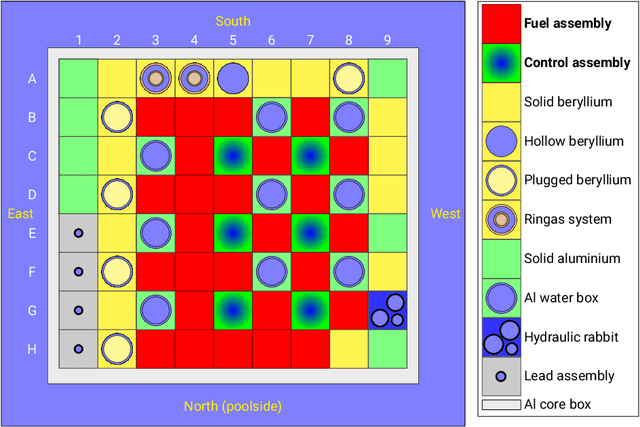
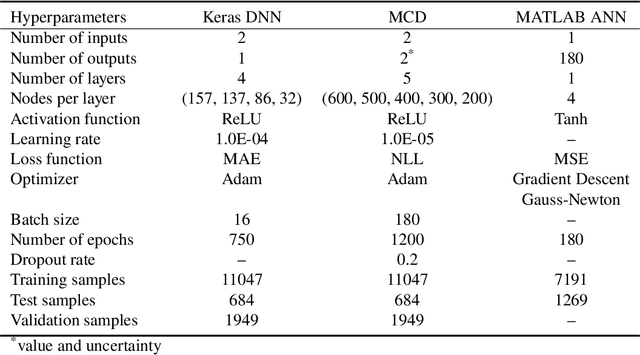
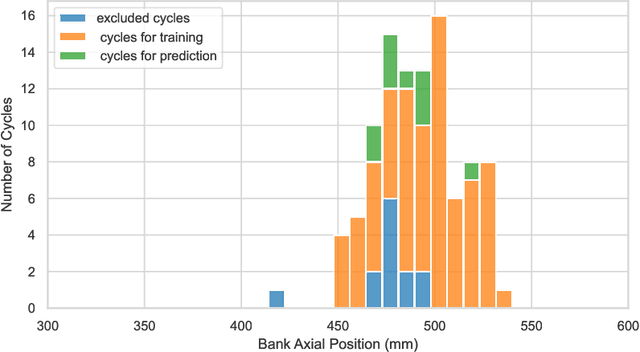
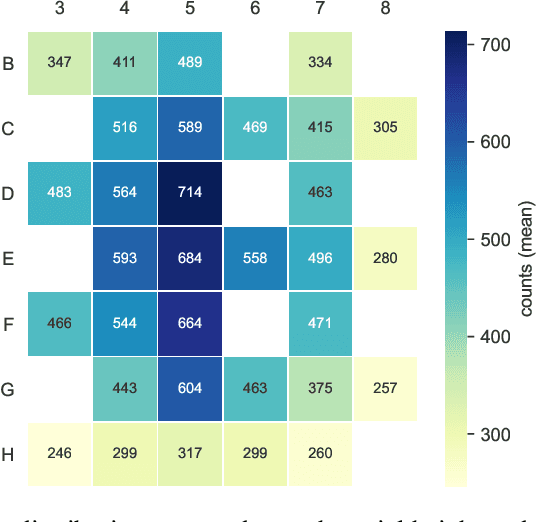
Artificial Neural Networks (ANNs) have been successfully used in various nuclear engineering applications, such as predicting reactor physics parameters within reasonable time and with a high level of accuracy. Despite this success, they cannot provide information about the model prediction uncertainties, making it difficult to assess ANN prediction credibility, especially in extrapolated domains. In this study, Deep Neural Networks (DNNs) are used to predict the assembly axial neutron flux profiles in the SAFARI-1 research reactor, with quantified uncertainties in the ANN predictions and extrapolation to cycles not used in the training process. The training dataset consists of copper-wire activation measurements, the axial measurement locations and the measured control bank positions obtained from the reactor's historical cycles. Uncertainty Quantification of the regular DNN models' predictions is performed using Monte Carlo Dropout (MCD) and Bayesian Neural Networks solved by Variational Inference (BNN VI). The regular DNNs, DNNs solved with MCD and BNN VI results agree very well among each other as well as with the new measured dataset not used in the training process, thus indicating good prediction and generalization capability. The uncertainty bands produced by MCD and BNN VI agree very well, and in general, they can fully envelop the noisy measurement data points. The developed ANNs are useful in supporting the experimental measurements campaign and neutronics code Verification and Validation (V&V).
A Review of Intelligent Music Generation Systems
Nov 16, 2022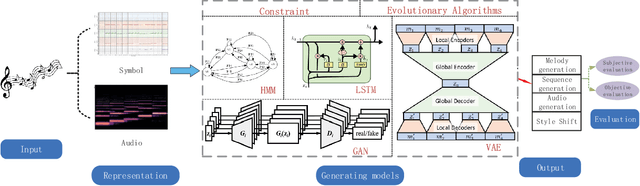

Intelligent music generation, one of the most popular subfields of computer creativity, can lower the creative threshold for non-specialists and increase the efficiency of music creation. In the last five years, the quality of algorithm-based automatic music generation has increased significantly, motivated by the use of modern generative algorithms to learn the patterns implicit within a piece of music based on rule constraints or a musical corpus, thus generating music samples in various styles. Some of the available literature reviews lack a systematic benchmark of generative models and are traditional and conservative in their perspective, resulting in a vision of the future development of the field that is not deeply integrated with the current rapid scientific progress. In this paper, we conduct a comprehensive survey and analysis of recent intelligent music generation techniques,provide a critical discussion, explicitly identify their respective characteristics, and present them in a general table. We first introduce how music as a stream of information is encoded and the relevant datasets, then compare different types of generation algorithms, summarize their strengths and weaknesses, and discuss existing methods for evaluation. Finally, the development of artificial intelligence in composition is studied, especially by comparing the different characteristics of music generation techniques in the East and West and analyzing the development prospects in this field.
Cross-Mode Knowledge Adaptation for Bike Sharing Demand Prediction using Domain-Adversarial Graph Neural Networks
Nov 16, 2022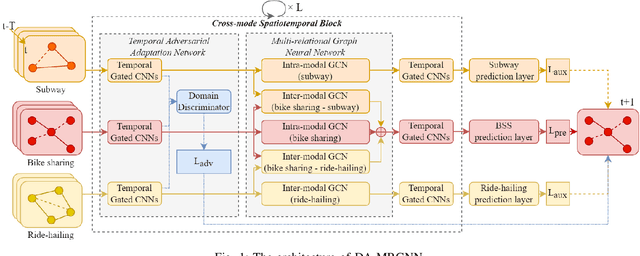
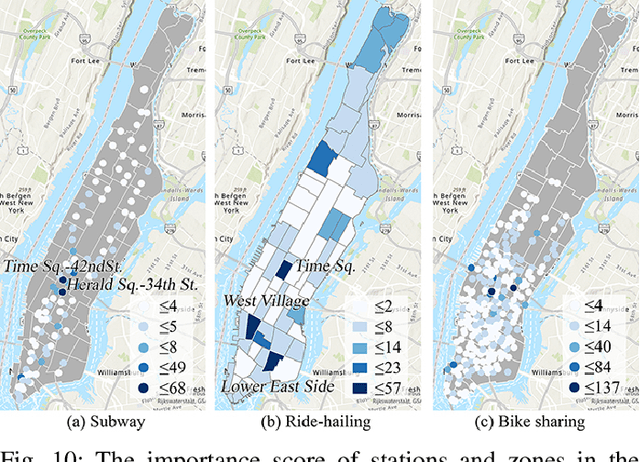
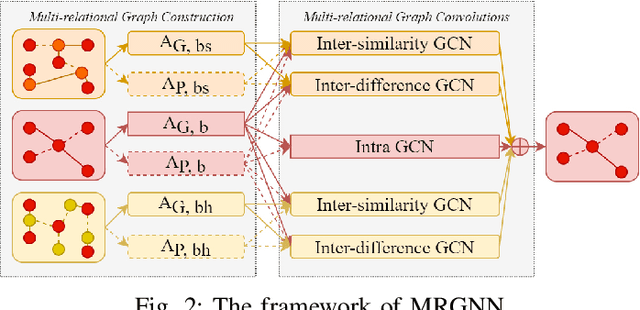
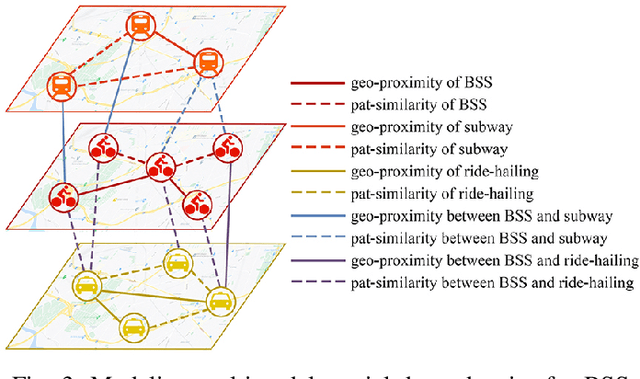
For bike sharing systems, demand prediction is crucial to ensure the timely re-balancing of available bikes according to predicted demand. Existing methods for bike sharing demand prediction are mostly based on its own historical demand variation, essentially regarding it as a closed system and neglecting the interaction between different transportation modes. This is particularly important for bike sharing because it is often used to complement travel through other modes (e.g., public transit). Despite some recent progress, no existing method is capable of leveraging spatiotemporal information from multiple modes and explicitly considers the distribution discrepancy between them, which can easily lead to negative transfer. To address these challenges, this study proposes a domain-adversarial multi-relational graph neural network (DA-MRGNN) for bike sharing demand prediction with multimodal historical data as input. A temporal adversarial adaptation network is introduced to extract shareable features from demand patterns of different modes. To capture correlations between spatial units across modes, we adapt a multi-relational graph neural network (MRGNN) considering both cross-mode similarity and difference. In addition, an explainable GNN technique is developed to understand how our proposed model makes predictions. Extensive experiments are conducted using real-world bike sharing, subway and ride-hailing data from New York City. The results demonstrate the superior performance of our proposed approach compared to existing methods and the effectiveness of different model components.
RetroMAE v2: Duplex Masked Auto-Encoder For Pre-Training Retrieval-Oriented Language Models
Nov 16, 2022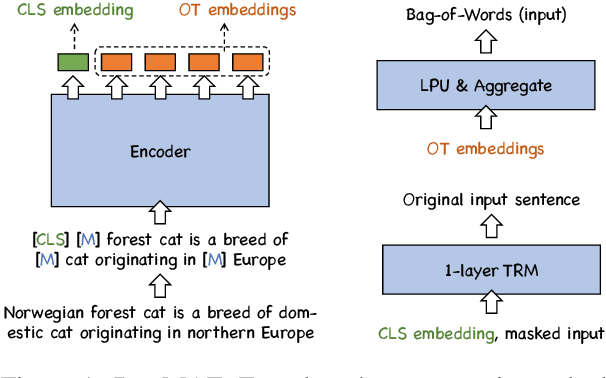
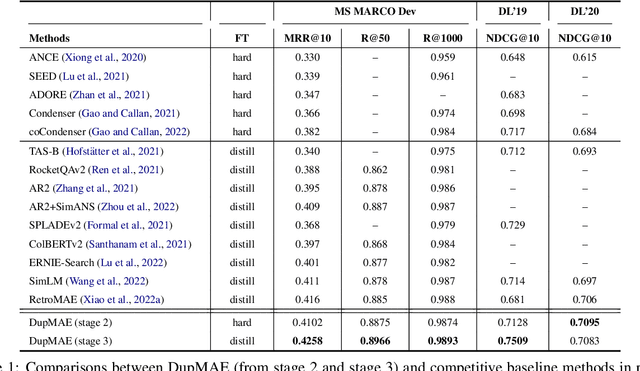
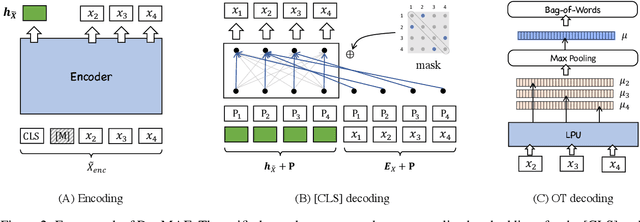
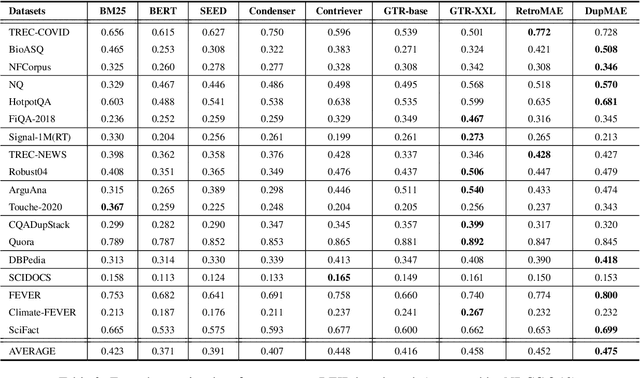
To better support retrieval applications such as web search and question answering, growing effort is made to develop retrieval-oriented language models. Most of the existing works focus on improving the semantic representation capability for the contextualized embedding of [CLS] token. However, recent study shows that the ordinary tokens besides [CLS] may provide extra information, which helps to produce a better representation effect. As such, it's necessary to extend the current methods where all contextualized embeddings can be jointly pre-trained for the retrieval tasks. With this motivation, we propose a new pre-training method: duplex masked auto-encoder, a.k.a. DupMAE, which targets on improving the semantic representation capacity for the contextualized embeddings of both [CLS] and ordinary tokens. It introduces two decoding tasks: one is to reconstruct the original input sentence based on the [CLS] embedding, the other one is to minimize the bag-of-words loss (BoW) about the input sentence based on the entire ordinary tokens' embeddings. The two decoding losses are added up to train a unified encoding model. The embeddings from [CLS] and ordinary tokens, after dimension reduction and aggregation, are concatenated as one unified semantic representation for the input. DupMAE is simple but empirically competitive: with a small decoding cost, it substantially contributes to the model's representation capability and transferability, where remarkable improvements are achieved on MS MARCO and BEIR benchmarks.