 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
When and why vision-language models behave like bag-of-words models, and what to do about it?
Oct 04, 2022
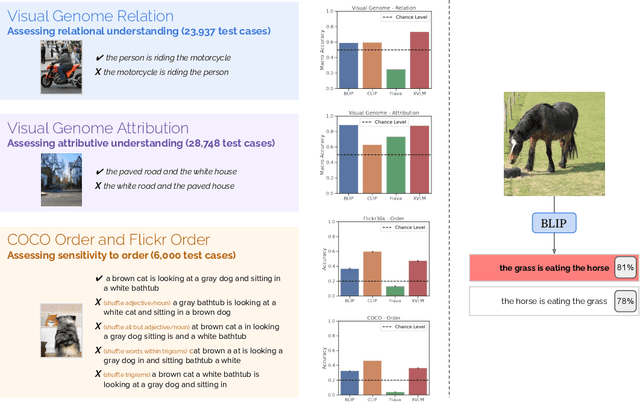

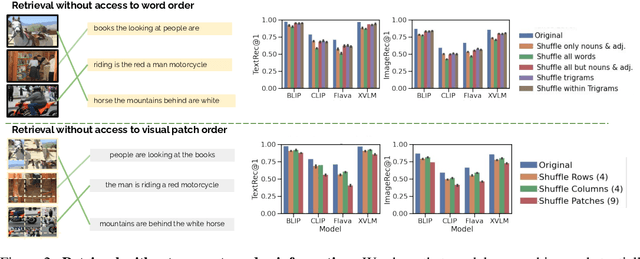
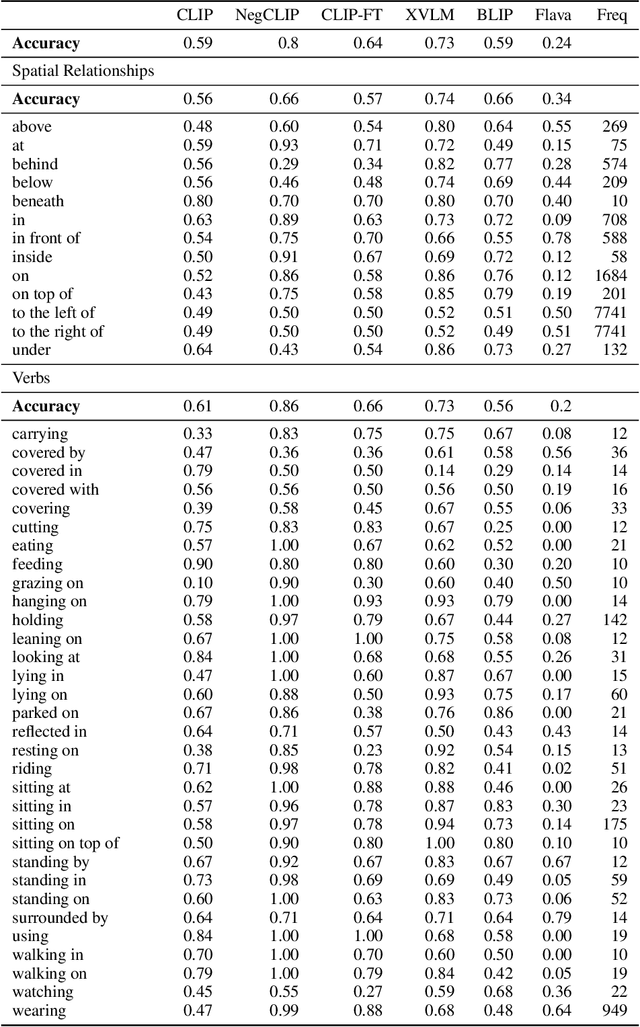
Despite the success of large vision and language models (VLMs) in many downstream applications, it is unclear how well they encode compositional information. Here, we create the Attribution, Relation, and Order (ARO) benchmark to systematically evaluate the ability of VLMs to understand different types of relationships, attributes, and order. ARO consists of Visual Genome Attribution, to test the understanding of objects' properties; Visual Genome Relation, to test for relational understanding; and COCO & Flickr30k-Order, to test for order sensitivity. ARO is orders of magnitude larger than previous benchmarks of compositionality, with more than 50,000 test cases. We show where state-of-the-art VLMs have poor relational understanding, can blunder when linking objects to their attributes, and demonstrate a severe lack of order sensitivity. VLMs are predominantly trained and evaluated on large datasets with rich compositional structure in the images and captions. Yet, training on these datasets has not been enough to address the lack of compositional understanding, and evaluating on these datasets has failed to surface this deficiency. To understand why these limitations emerge and are not represented in the standard tests, we zoom into the evaluation and training procedures. We demonstrate that it is possible to perform well on retrieval over existing datasets without using the composition and order information. Given that contrastive pretraining optimizes for retrieval on datasets with similar shortcuts, we hypothesize that this can explain why the models do not need to learn to represent compositional information. This finding suggests a natural solution: composition-aware hard negative mining. We show that a simple-to-implement modification of contrastive learning significantly improves the performance on tasks requiring understanding of order and compositionality.
Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate
Oct 14, 2022
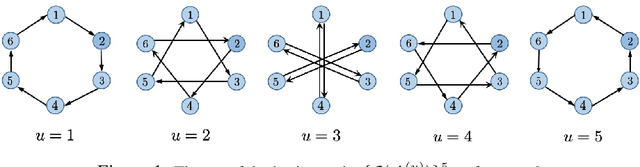
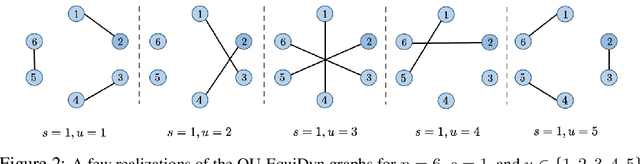

Decentralized optimization is an emerging paradigm in distributed learning in which agents achieve network-wide solutions by peer-to-peer communication without the central server. Since communication tends to be slower than computation, when each agent communicates with only a few neighboring agents per iteration, they can complete iterations faster than with more agents or a central server. However, the total number of iterations to reach a network-wide solution is affected by the speed at which the agents' information is ``mixed'' by communication. We found that popular communication topologies either have large maximum degrees (such as stars and complete graphs) or are ineffective at mixing information (such as rings and grids). To address this problem, we propose a new family of topologies, EquiTopo, which has an (almost) constant degree and a network-size-independent consensus rate that is used to measure the mixing efficiency. In the proposed family, EquiStatic has a degree of $\Theta(\ln(n))$, where $n$ is the network size, and a series of time-dependent one-peer topologies, EquiDyn, has a constant degree of 1. We generate EquiDyn through a certain random sampling procedure. Both of them achieve an $n$-independent consensus rate. We apply them to decentralized SGD and decentralized gradient tracking and obtain faster communication and better convergence, theoretically and empirically. Our code is implemented through BlueFog and available at \url{https://github.com/kexinjinnn/EquiTopo}
Weakly-Supervised Multi-Granularity Map Learning for Vision-and-Language Navigation
Oct 14, 2022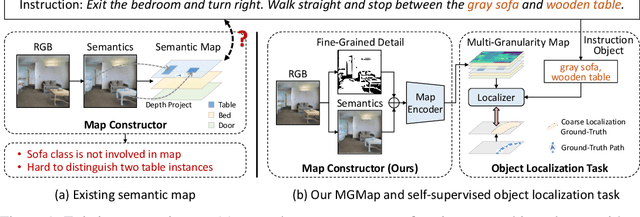
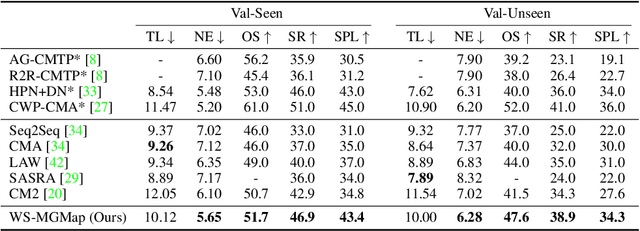
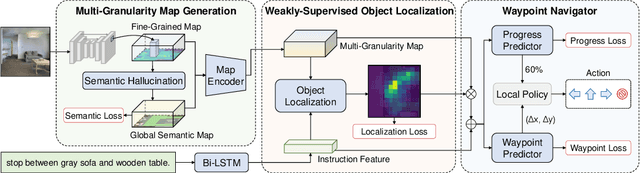
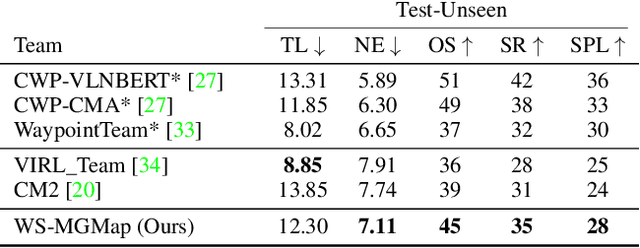
We address a practical yet challenging problem of training robot agents to navigate in an environment following a path described by some language instructions. The instructions often contain descriptions of objects in the environment. To achieve accurate and efficient navigation, it is critical to build a map that accurately represents both spatial location and the semantic information of the environment objects. However, enabling a robot to build a map that well represents the environment is extremely challenging as the environment often involves diverse objects with various attributes. In this paper, we propose a multi-granularity map, which contains both object fine-grained details (e.g., color, texture) and semantic classes, to represent objects more comprehensively. Moreover, we propose a weakly-supervised auxiliary task, which requires the agent to localize instruction-relevant objects on the map. Through this task, the agent not only learns to localize the instruction-relevant objects for navigation but also is encouraged to learn a better map representation that reveals object information. We then feed the learned map and instruction to a waypoint predictor to determine the next navigation goal. Experimental results show our method outperforms the state-of-the-art by 4.0% and 4.6% w.r.t. success rate both in seen and unseen environments, respectively on VLN-CE dataset. Code is available at https://github.com/PeihaoChen/WS-MGMap.
A Dynamic Model for Bus Arrival Time Estimation based on Spatial Patterns using Machine Learning
Oct 03, 2022
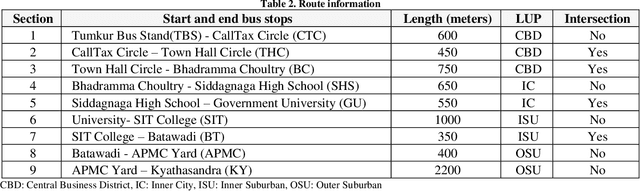
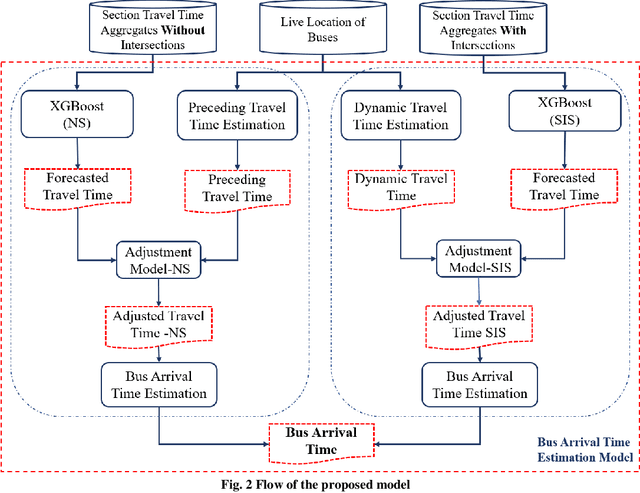

The notion of smart cities is being adapted globally to provide a better quality of living. A smart city's smart mobility component focuses on providing smooth and safe commuting for its residents and promotes eco-friendly and sustainable alternatives such as public transit (bus). Among several smart applications, a system that provides up-to-the-minute information like bus arrival, travel duration, schedule, etc., improves the reliability of public transit services. Still, this application needs live information on traffic flow, accidents, events, and the location of the buses. Most cities lack the infrastructure to provide these data. In this context, a bus arrival prediction model is proposed for forecasting the arrival time using limited data sets. The location data of public transit buses and spatial characteristics are used for the study. One of the routes of Tumakuru city service, Tumakuru, India, is selected and divided into two spatial patterns: sections with intersections and sections without intersections. The machine learning model XGBoost is modeled for both spatial patterns individually. A model to dynamically predict bus arrival time is developed using the preceding trip information and the machine learning model to estimate the arrival time at a downstream bus stop. The performance of models is compared based on the R-squared values of the predictions made, and the proposed model established superior results. It is suggested to predict bus arrival in the study area. The proposed model can also be extended to other similar cities with limited traffic-related infrastructure.
SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image
Oct 03, 2022

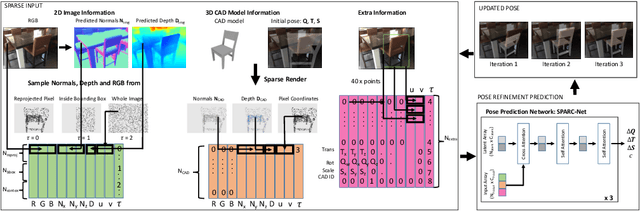
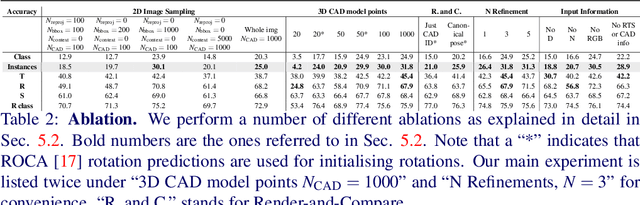
Estimating 3D shapes and poses of static objects from a single image has important applications for robotics, augmented reality and digital content creation. Often this is done through direct mesh predictions which produces unrealistic, overly tessellated shapes or by formulating shape prediction as a retrieval task followed by CAD model alignment. Directly predicting CAD model poses from 2D image features is difficult and inaccurate. Some works, such as ROCA, regress normalised object coordinates and use those for computing poses. While this can produce more accurate pose estimates, predicting normalised object coordinates is susceptible to systematic failure. Leveraging efficient transformer architectures we demonstrate that a sparse, iterative, render-and-compare approach is more accurate and robust than relying on normalised object coordinates. For this we combine 2D image information including sparse depth and surface normal values which we estimate directly from the image with 3D CAD model information in early fusion. In particular, we reproject points sampled from the CAD model in an initial, random pose and compute their depth and surface normal values. This combined information is the input to a pose prediction network, SPARC-Net which we train to predict a 9 DoF CAD model pose update. The CAD model is reprojected again and the next pose update is predicted. Our alignment procedure converges after just 3 iterations, improving the state-of-the-art performance on the challenging real-world dataset ScanNet from 25.0% to 31.8% instance alignment accuracy. Code will be released at https://github.com/florianlanger/SPARC .
Estimating Conditional Average Treatment Effects with Missing Treatment Information
Mar 02, 2022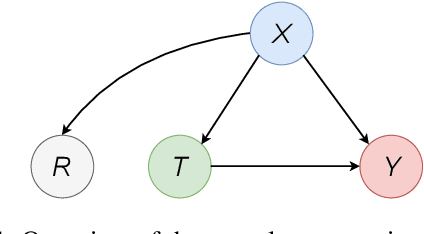
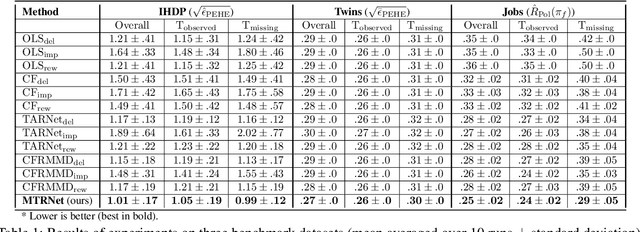
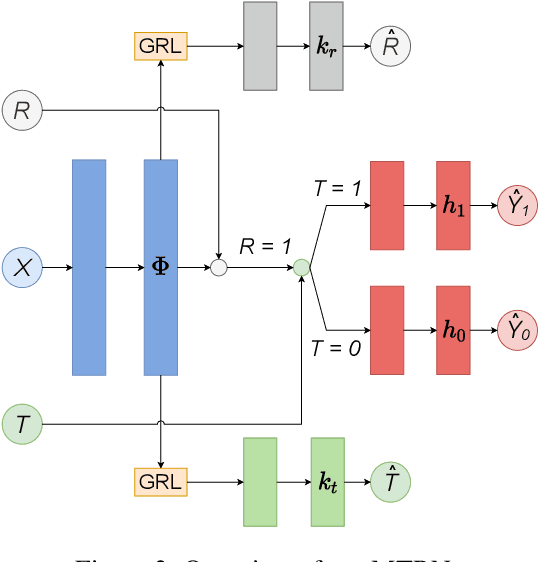
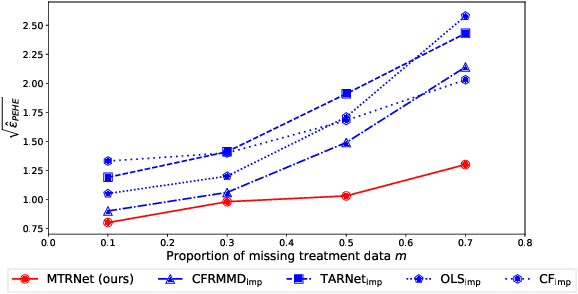
Estimating conditional average treatment effects (CATE) is challenging, especially when treatment information is missing. Although this is a widespread problem in practice, CATE estimation with missing treatments has received little attention. In this paper, we analyze CATE estimation in the setting with missing treatments where, thus, unique challenges arise in the form of covariate shifts. We identify two covariate shifts in our setting: (i) a covariate shift between the treated and control population; and (ii) a covariate shift between the observed and missing treatment population. We first theoretically show the effect of these covariate shifts by deriving a generalization bound for estimating CATE in our setting with missing treatments. Then, motivated by our bound, we develop the missing treatment representation network (MTRNet), a novel CATE estimation algorithm that learns a balanced representation of covariates using domain adaptation. By using balanced representations, MTRNet provides more reliable CATE estimates in the covariate domains where the data are not fully observed. In various experiments with semi-synthetic and real-world data, we show that our algorithm improves over the state-of-the-art by a substantial margin.
FreDSNet: Joint Monocular Depth and Semantic Segmentation with Fast Fourier Convolutions
Oct 04, 2022
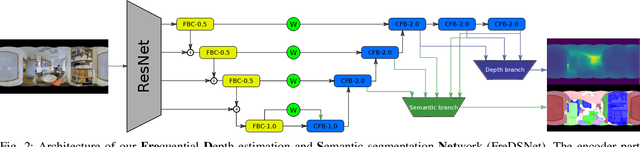


In this work we present FreDSNet, a deep learning solution which obtains semantic 3D understanding of indoor environments from single panoramas. Omnidirectional images reveal task-specific advantages when addressing scene understanding problems due to the 360-degree contextual information about the entire environment they provide. However, the inherent characteristics of the omnidirectional images add additional problems to obtain an accurate detection and segmentation of objects or a good depth estimation. To overcome these problems, we exploit convolutions in the frequential domain obtaining a wider receptive field in each convolutional layer. These convolutions allow to leverage the whole context information from omnidirectional images. FreDSNet is the first network that jointly provides monocular depth estimation and semantic segmentation from a single panoramic image exploiting fast Fourier convolutions. Our experiments show that FreDSNet has similar performance as specific state of the art methods for semantic segmentation and depth estimation. FreDSNet code is publicly available in https://github.com/Sbrunoberenguel/FreDSNet
Active Learning for Regression with Aggregated Outputs
Oct 04, 2022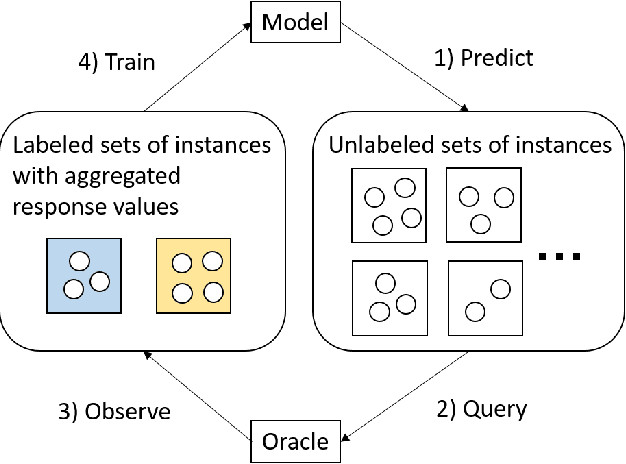

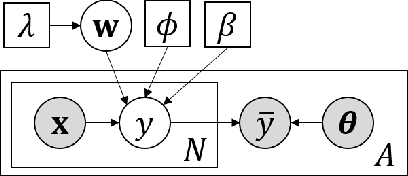
Due to the privacy protection or the difficulty of data collection, we cannot observe individual outputs for each instance, but we can observe aggregated outputs that are summed over multiple instances in a set in some real-world applications. To reduce the labeling cost for training regression models for such aggregated data, we propose an active learning method that sequentially selects sets to be labeled to improve the predictive performance with fewer labeled sets. For the selection measurement, the proposed method uses the mutual information, which quantifies the reduction of the uncertainty of the model parameters by observing the aggregated output. With Bayesian linear basis functions for modeling outputs given an input, which include approximated Gaussian processes and neural networks, we can efficiently calculate the mutual information in a closed form. With the experiments using various datasets, we demonstrate that the proposed method achieves better predictive performance with fewer labeled sets than existing methods.
Micro and Macro Level Graph Modeling for Graph Variational Auto-Encoders
Oct 30, 2022
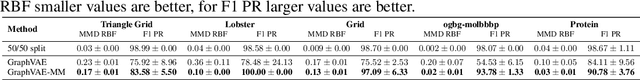
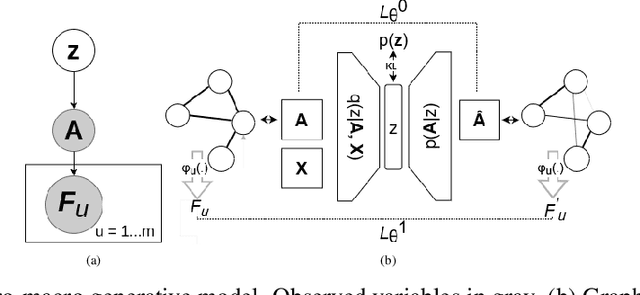
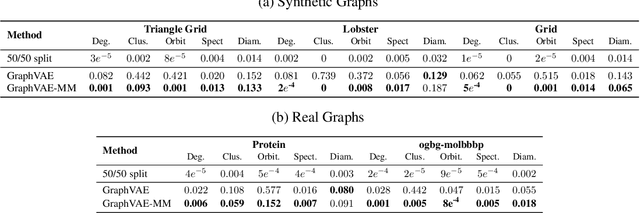
Generative models for graph data are an important research topic in machine learning. Graph data comprise two levels that are typically analyzed separately: node-level properties such as the existence of a link between a pair of nodes, and global aggregate graph-level statistics, such as motif counts. This paper proposes a new multi-level framework that jointly models node-level properties and graph-level statistics, as mutually reinforcing sources of information. We introduce a new micro-macro training objective for graph generation that combines node-level and graph-level losses. We utilize the micro-macro objective to improve graph generation with a GraphVAE, a well-established model based on graph-level latent variables, that provides fast training and generation time for medium-sized graphs. Our experiments show that adding micro-macro modeling to the GraphVAE model improves graph quality scores up to 2 orders of magnitude on five benchmark datasets, while maintaining the GraphVAE generation speed advantage.
Multimodal Transformer Distillation for Audio-Visual Synchronization
Oct 27, 2022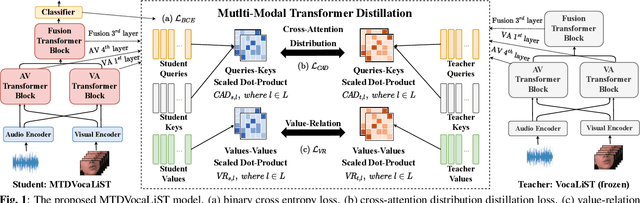
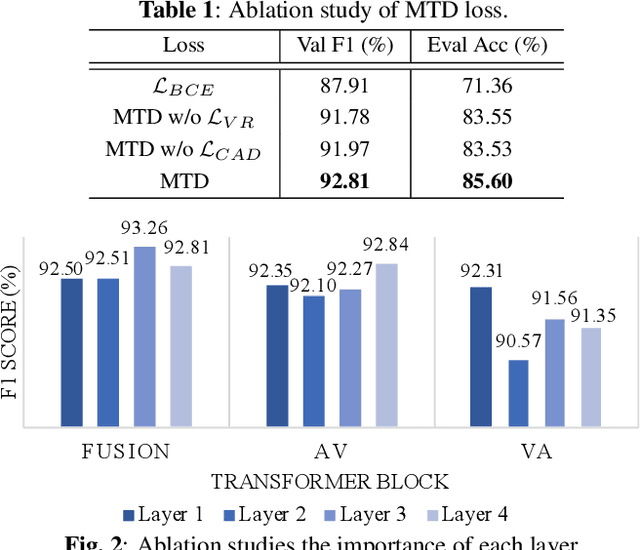
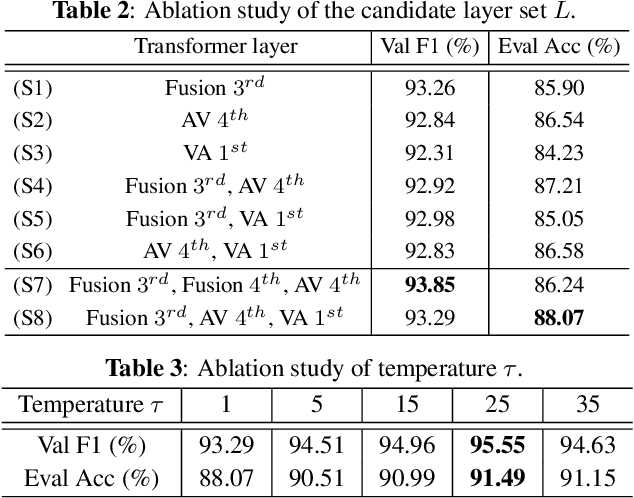
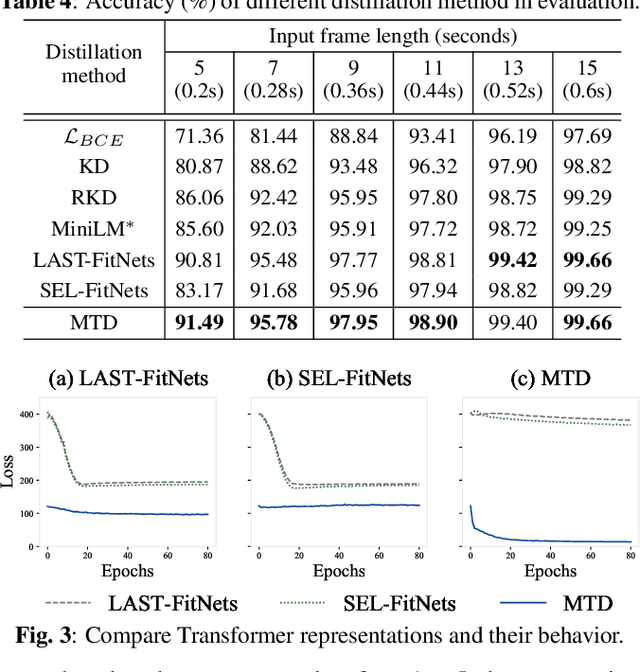
Audio-visual synchronization aims to determine whether the mouth movements and speech in the video are synchronized. VocaLiST reaches state-of-the-art performance by incorporating multimodal Transformers to model audio-visual interact information. However, it requires high computing resources, making it impractical for real-world applications. This paper proposed an MTDVocaLiST model, which is trained by our proposed multimodal Transformer distillation (MTD) loss. MTD loss enables MTDVocaLiST model to deeply mimic the cross-attention distribution and value-relation in the Transformer of VocaLiST. Our proposed method is effective in two aspects: From the distillation method perspective, MTD loss outperforms other strong distillation baselines. From the distilled model's performance perspective: 1) MTDVocaLiST outperforms similar-size SOTA models, SyncNet, and PM models by 15.69% and 3.39%; 2) MTDVocaLiST reduces the model size of VocaLiST by 83.52%, yet still maintaining similar performance.