 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TCNL: Transparent and Controllable Network Learning Via Embedding Human-Guided Concepts
Oct 07, 2022
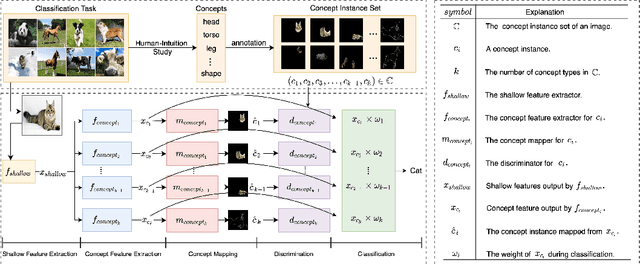


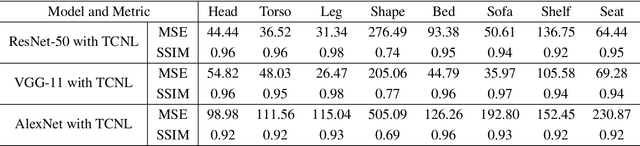
Explaining deep learning models is of vital importance for understanding artificial intelligence systems, improving safety, and evaluating fairness. To better understand and control the CNN model, many methods for transparency-interpretability have been proposed. However, most of these works are less intuitive for human understanding and have insufficient human control over the CNN model. We propose a novel method, Transparent and Controllable Network Learning (TCNL), to overcome such challenges. Towards the goal of improving transparency-interpretability, in TCNL, we define some concepts for specific classification tasks through scientific human-intuition study and incorporate concept information into the CNN model. In TCNL, the shallow feature extractor gets preliminary features first. Then several concept feature extractors are built right after the shallow feature extractor to learn high-dimensional concept representations. The concept feature extractor is encouraged to encode information related to the predefined concepts. We also build the concept mapper to visualize features extracted by the concept extractor in a human-intuitive way. TCNL provides a generalizable approach to transparency-interpretability. Researchers can define concepts corresponding to certain classification tasks and encourage the model to encode specific concept information, which to a certain extent improves transparency-interpretability and the controllability of the CNN model. The datasets (with concept sets) for our experiments will also be released (https://github.com/bupt-ai-cz/TCNL).
Contrastive Representation Learning for Conversational Question Answering over Knowledge Graphs
Oct 09, 2022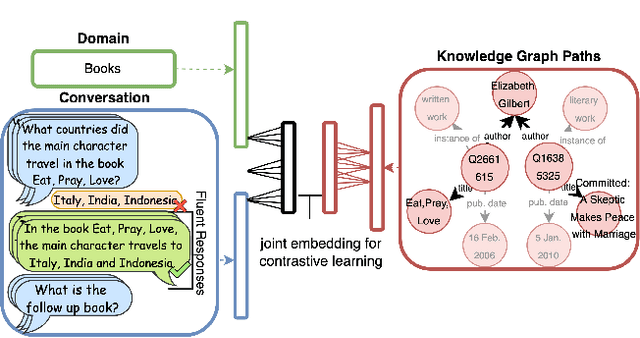
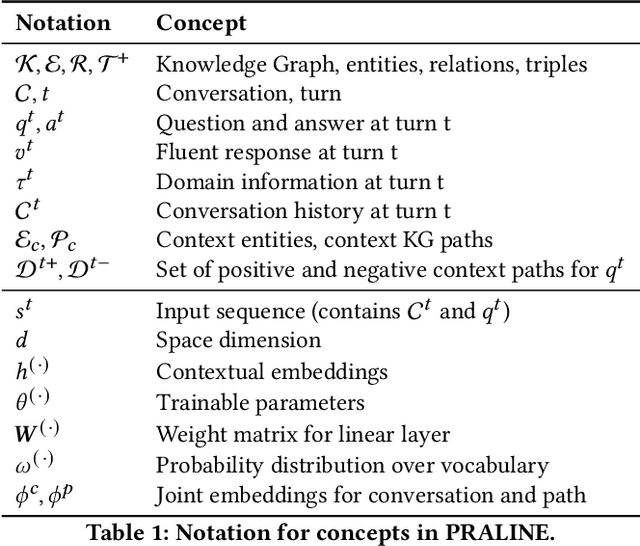
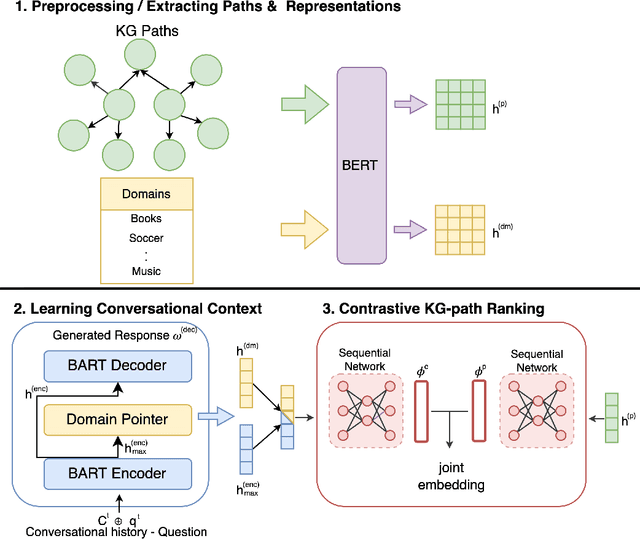
This paper addresses the task of conversational question answering (ConvQA) over knowledge graphs (KGs). The majority of existing ConvQA methods rely on full supervision signals with a strict assumption of the availability of gold logical forms of queries to extract answers from the KG. However, creating such a gold logical form is not viable for each potential question in a real-world scenario. Hence, in the case of missing gold logical forms, the existing information retrieval-based approaches use weak supervision via heuristics or reinforcement learning, formulating ConvQA as a KG path ranking problem. Despite missing gold logical forms, an abundance of conversational contexts, such as entire dialog history with fluent responses and domain information, can be incorporated to effectively reach the correct KG path. This work proposes a contrastive representation learning-based approach to rank KG paths effectively. Our approach solves two key challenges. Firstly, it allows weak supervision-based learning that omits the necessity of gold annotations. Second, it incorporates the conversational context (entire dialog history and domain information) to jointly learn its homogeneous representation with KG paths to improve contrastive representations for effective path ranking. We evaluate our approach on standard datasets for ConvQA, on which it significantly outperforms existing baselines on all domains and overall. Specifically, in some cases, the Mean Reciprocal Rank (MRR) and Hit@5 ranking metrics improve by absolute 10 and 18 points, respectively, compared to the state-of-the-art performance.
A Detailed Study of Interpretability of Deep Neural Network based Top Taggers
Oct 09, 2022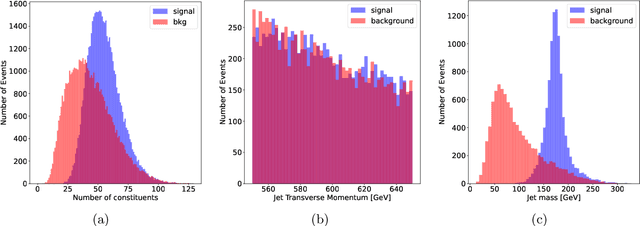
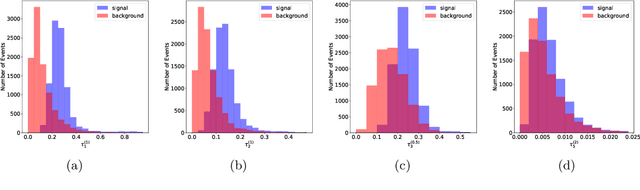
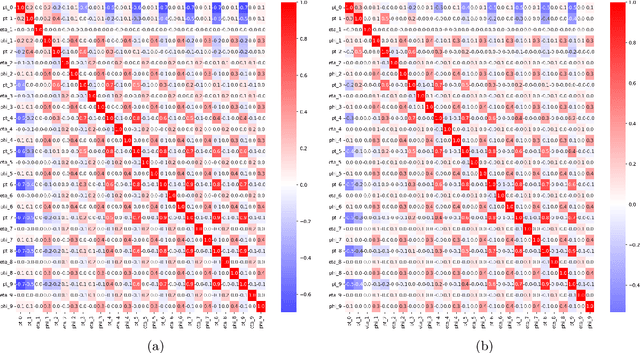
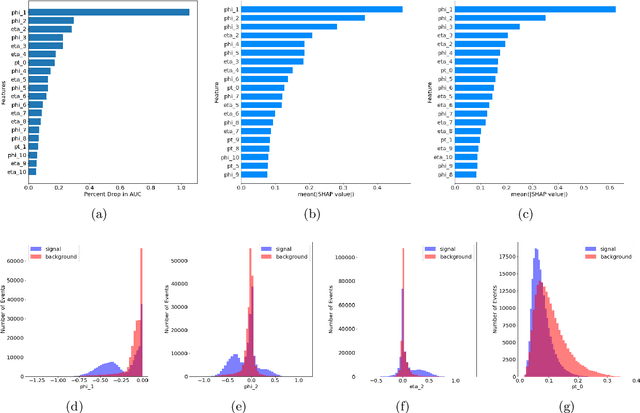
Recent developments in the methods of explainable AI (xAI) methods allow us to explore the inner workings of deep neural networks (DNNs), revealing crucial information about input-output relationships and realizing how data connects with machine learning models. In this paper we explore interpretability of DNN models designed for identifying jets coming from top quark decay in the high energy proton-proton collisions at the Large Hadron Collider (LHC). We review a subset of existing such top tagger models and explore different quantitative methods to identify which features play the most important roles in identifying the top jets. We also investigate how and why feature importance varies across different xAI metrics, how feature correlations impact their explainability, and how latent space representations encode information as well as correlate with physically meaningful quantities. Our studies uncover some major pitfalls of existing xAI methods and illustrate how they can be overcome to obtain consistent and meaningful interpretation of these models. We additionally illustrate the activity of hidden layers as Neural Activation Pattern (NAP) diagrams and demonstrate how they can be used to understand how DNNs relay information across the layers and how this understanding can help us to make such models significantly simpler by allowing effective model reoptimization and hyperparameter tuning. While the primary focus of this work remains a detailed study of interpretability of DNN-based top tagger models, it also features state-of-the art performance obtained from modified implementation of existing networks.
Reconstruction from edge image combined with color and gradient difference for industrial surface anomaly detection
Oct 26, 2022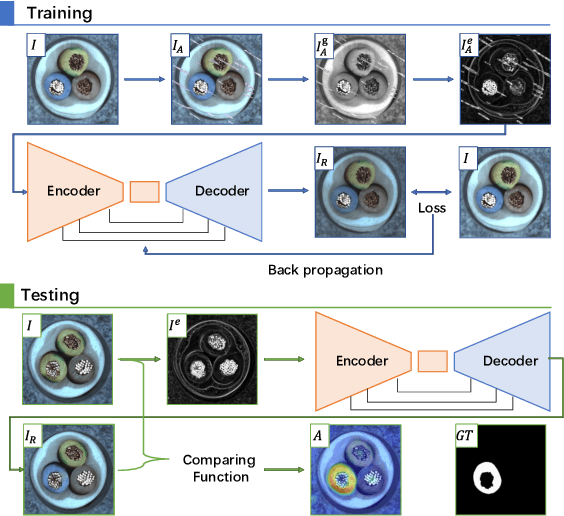
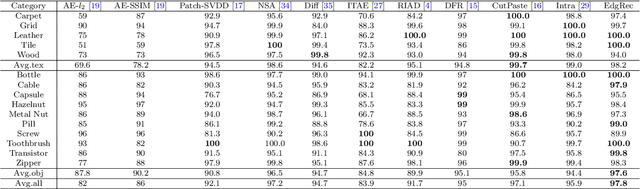
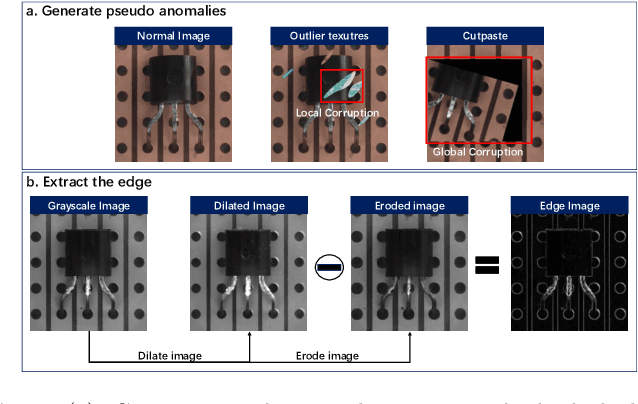
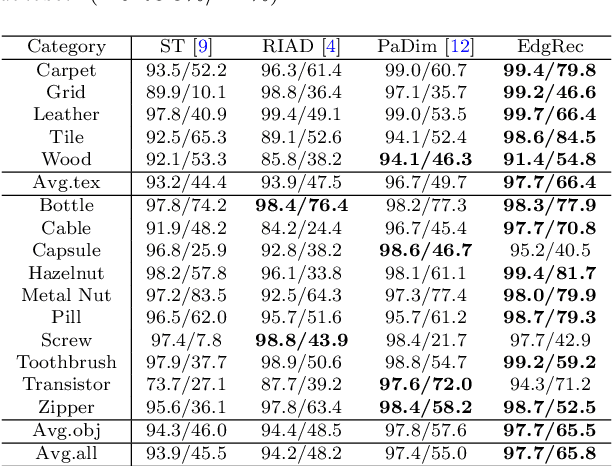
Reconstruction-based methods are widely explored in industrial visual anomaly detection. Such methods commonly require the model to well reconstruct the normal patterns but fail in the anomalies, and thus the anomalies can be detected by evaluating the reconstruction errors. However, in practice, it's usually difficult to control the generalization boundary of the model. The model with an overly strong generalization capability can even well reconstruct the abnormal regions, making them less distinguishable, while the model with a poor generalization capability can not reconstruct those changeable high-frequency components in the normal regions, which ultimately leads to false positives. To tackle the above issue, we propose a new reconstruction network where we reconstruct the original RGB image from its gray value edges (EdgRec). Specifically, this is achieved by an UNet-type denoising autoencoder with skip connections. The input edge and skip connections can well preserve the high-frequency information in the original image. Meanwhile, the proposed restoration task can force the network to memorize the normal low-frequency and color information. Besides, the denoising design can prevent the model from directly copying the original high-frequent components. To evaluate the anomalies, we further propose a new interpretable hand-crafted evaluation function that considers both the color and gradient differences. Our method achieves competitive results on the challenging benchmark MVTec AD (97.8\% for detection and 97.7\% for localization, AUROC). In addition, we conduct experiments on the MVTec 3D-AD dataset and show convincing results using RGB images only. Our code will be available at https://github.com/liutongkun/EdgRec.
Resource Allocation for Uplink Cell-Free Massive MIMO enabled URLLC in a Smart Factory
Nov 22, 2022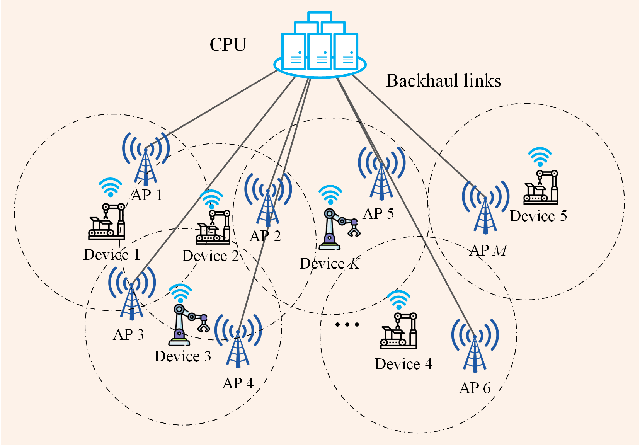
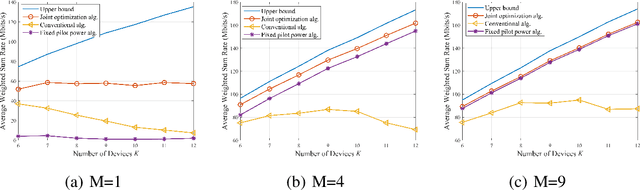
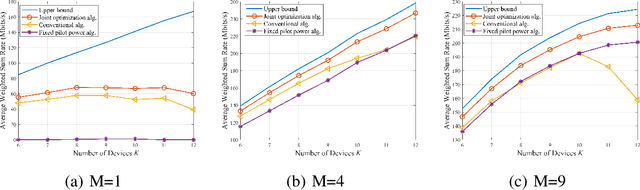
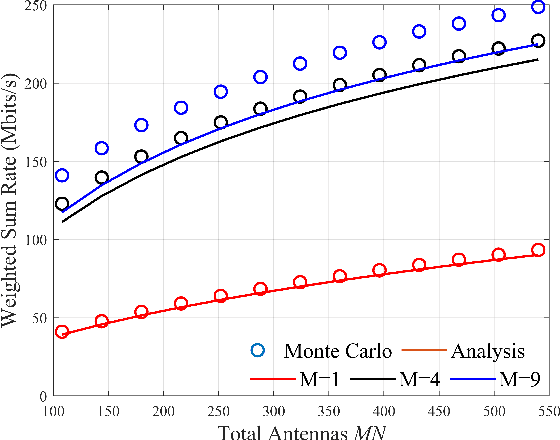
Smart factories need to support the simultaneous communication of multiple industrial Internet-of-Things (IIoT) devices with ultra-reliability and low-latency communication (URLLC). Meanwhile, short packet transmission for IIoT applications incurs performance loss compared to traditional long packet transmission for human-to-human communications. On the other hand, cell-free massive multiple-input and multiple-output (CF mMIMO) technology can provide uniform services for all devices by deploying distributed access points (APs). In this paper, we adopt CF mMIMO to support URLLC in a smart factory. Specifically, we first derive the lower bound (LB) on achievable uplink data rate under the finite blocklength (FBL) with imperfect channel state information (CSI) for both maximum-ratio combining (MRC) and full-pilot zero-forcing (FZF) decoders. \textcolor{black}{The derived LB rates based on the MRC case have the same trends as the ergodic rate, while LB rates using the FZF decoder tightly match the ergodic rates}, which means that resource allocation can be performed based on the LB data rate rather the exact ergodic data rate under FBL. The \textcolor{black}{log-function method} and successive convex approximation (SCA) are then used to approximately transform the non-convex weighted sum rate problem into a series of geometric program (GP) problems, and an iterative algorithm is proposed to jointly optimize the pilot and payload power allocation. Simulation results demonstrate that CF mMIMO significantly improves the average weighted sum rate (AWSR) compared to centralized mMIMO. An interesting observation is that increasing the number of devices improves the AWSR for CF mMIMO whilst the AWSR remains relatively constant for centralized mMIMO.
One for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation
Nov 22, 2022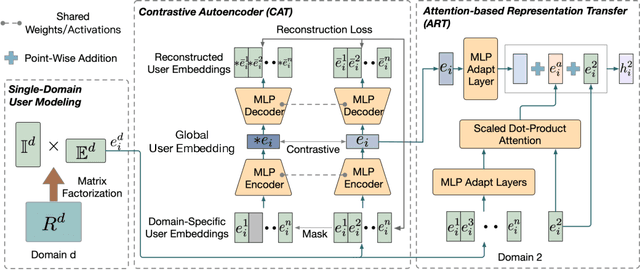
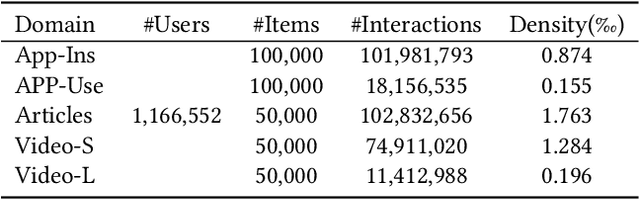
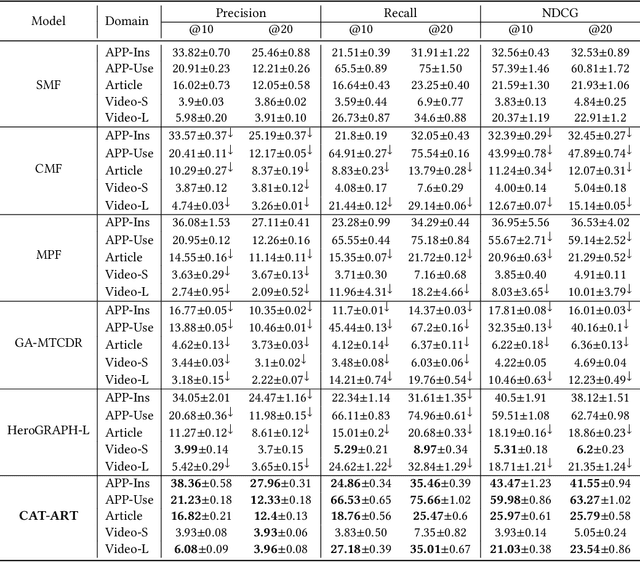
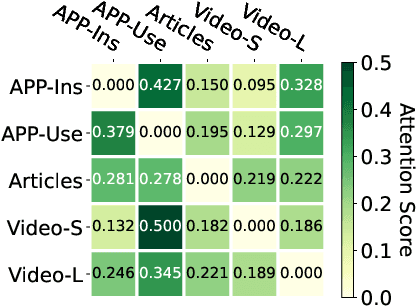
Cross-domain recommendation is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing techniques focus on single-target or dual-target cross-domain recommendation (CDR) and are hard to be generalized to CDR with multiple target domains. In addition, the negative transfer problem is prevalent in CDR, where the recommendation performance in a target domain may not always be enhanced by knowledge learned from a source domain, especially when the source domain has sparse data. In this study, we propose CAT-ART, a multi-target CDR method that learns to improve recommendations in all participating domains through representation learning and embedding transfer. Our method consists of two parts: a self-supervised Contrastive AuToencoder (CAT) framework to generate global user embeddings based on information from all participating domains, and an Attention-based Representation Transfer (ART) framework which transfers domain-specific user embeddings from other domains to assist with target domain recommendation. CAT-ART boosts the recommendation performance in any target domain through the combined use of the learned global user representation and knowledge transferred from other domains, in addition to the original user embedding in the target domain. We conducted extensive experiments on a collected real-world CDR dataset spanning 5 domains and involving a million users. Experimental results demonstrate the superiority of the proposed method over a range of prior arts. We further conducted ablation studies to verify the effectiveness of the proposed components. Our collected dataset will be open-sourced to facilitate future research in the field of multi-domain recommender systems and user modeling.
OLGA : An Ontology and LSTM-based approach for generating Arithmetic Word Problems (AWPs) of transfer type
Nov 22, 2022


Machine generation of Arithmetic Word Problems (AWPs) is challenging as they express quantities and mathematical relationships and need to be consistent. ML-solvers require a large annotated training set of consistent problems with language variations. Exploiting domain-knowledge is needed for consistency checking whereas LSTM-based approaches are good for producing text with language variations. Combining these we propose a system, OLGA, to generate consistent word problems of TC (Transfer-Case) type, involving object transfers among agents. Though we provide a dataset of consistent 2-agent TC-problems for training, only about 36% of the outputs of an LSTM-based generator are found consistent. We use an extension of TC-Ontology, proposed by us previously, to determine the consistency of problems. Among the remaining 64%, about 40% have minor errors which we repair using the same ontology. To check consistency and for the repair process, we construct an instance-specific representation (ABox) of an auto-generated problem. We use a sentence classifier and BERT models for this task. The training set for these LMs is problem-texts where sentence-parts are annotated with ontology class-names. As three-agent problems are longer, the percentage of consistent problems generated by an LSTM-based approach drops further. Hence, we propose an ontology-based method that extends consistent 2-agent problems into consistent 3-agent problems. Overall, our approach generates a large number of consistent TC-type AWPs involving 2 or 3 agents. As ABox has all the information of a problem, any annotations can also be generated. Adopting the proposed approach to generate other types of AWPs is interesting future work.
GitFL: Adaptive Asynchronous Federated Learning using Version Control
Nov 22, 2022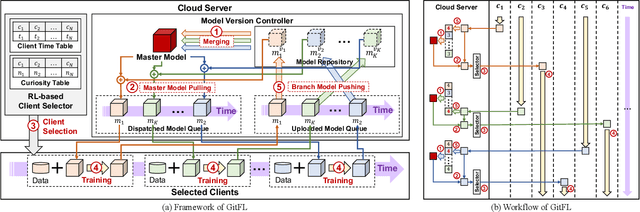
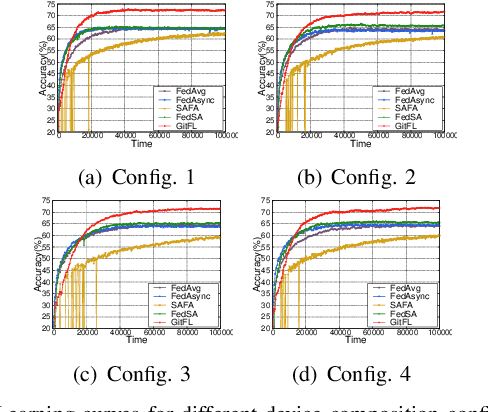
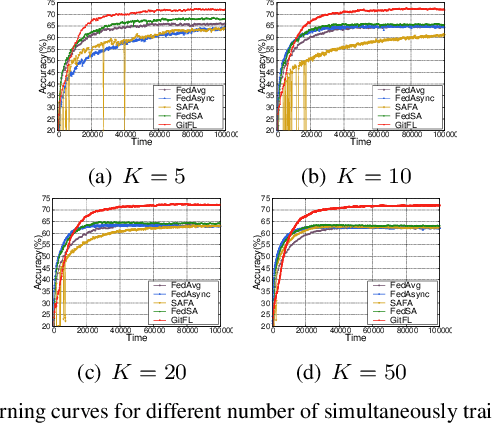
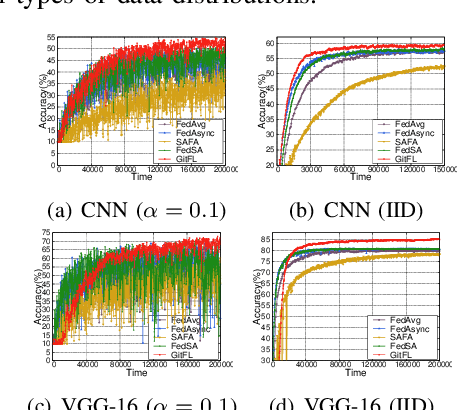
As a promising distributed machine learning paradigm that enables collaborative training without compromising data privacy, Federated Learning (FL) has been increasingly used in AIoT (Artificial Intelligence of Things) design. However, due to the lack of efficient management of straggling devices, existing FL methods greatly suffer from the problems of low inference accuracy and long training time. Things become even worse when taking various uncertain factors (e.g., network delays, performance variances caused by process variation) existing in AIoT scenarios into account. To address this issue, this paper proposes a novel asynchronous FL framework named GitFL, whose implementation is inspired by the famous version control system Git. Unlike traditional FL, the cloud server of GitFL maintains a master model (i.e., the global model) together with a set of branch models indicating the trained local models committed by selected devices, where the master model is updated based on both all the pushed branch models and their version information, and only the branch models after the pull operation are dispatched to devices. By using our proposed Reinforcement Learning (RL)-based device selection mechanism, a pulled branch model with an older version will be more likely to be dispatched to a faster and less frequently selected device for the next round of local training. In this way, GitFL enables both effective control of model staleness and adaptive load balance of versioned models among straggling devices, thus avoiding the performance deterioration. Comprehensive experimental results on well-known models and datasets show that, compared with state-of-the-art asynchronous FL methods, GitFL can achieve up to 2.64X training acceleration and 7.88% inference accuracy improvements in various uncertain scenarios.
Computationally Light Spectrally Normalized Memory Neuron Network based Estimator for GPS-Denied operation of Micro UAV
Nov 12, 2022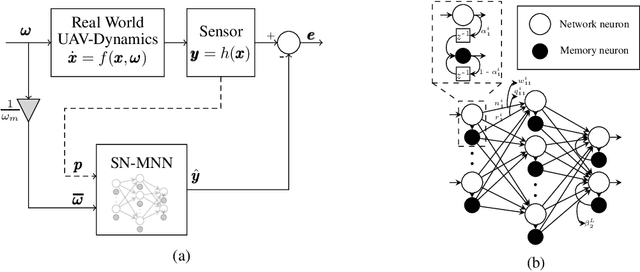

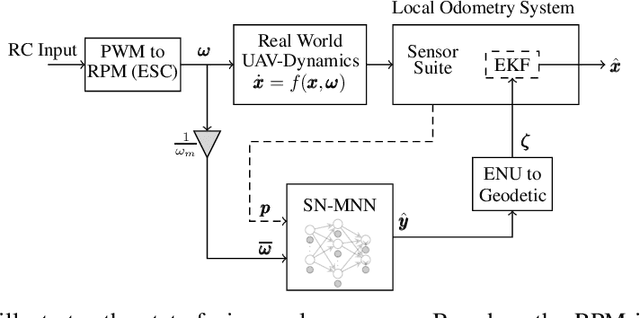

This paper addresses the problem of position estimation in UAVs operating in a cluttered environment where GPS information is unavailable. A model learning-based approach is proposed that takes in the rotor RPMs and past state as input and predicts the one-step-ahead position of the UAV using a novel spectral-normalized memory neural network (SN-MNN). The spectral normalization guarantees stable and reliable prediction performance. The predicted position is transformed to global coordinate frame which is then fused along with the odometry of other peripheral sensors like IMU, barometer, compass etc., using the onboard extended Kalman filter to estimate the states of the UAV. The experimental flight data collected from a motion capture facility using a micro-UAV is used to train the SN-MNN. The PX4-ECL library is used to replay the flight data using the proposed algorithm, and the estimated position is compared with actual ground truth data. The proposed algorithm doesn't require any additional onboard sensors, and is computationally light. The performance of the proposed approach is compared with the current state-of-art GPS-denied algorithms, and it can be seen that the proposed algorithm has the least RMSE for position estimates.
Empirical Risk Minimization with Generalized Relative Entropy Regularization
Nov 12, 2022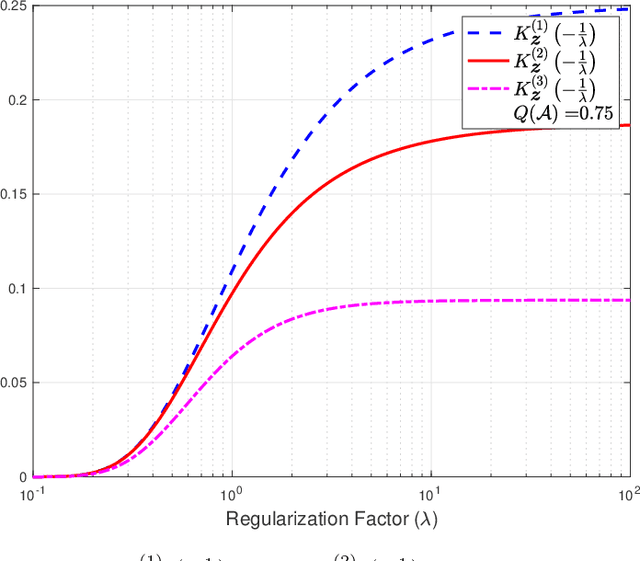
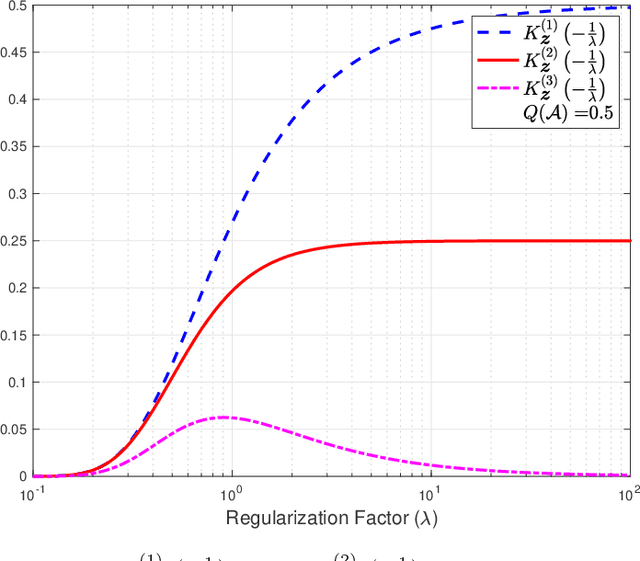
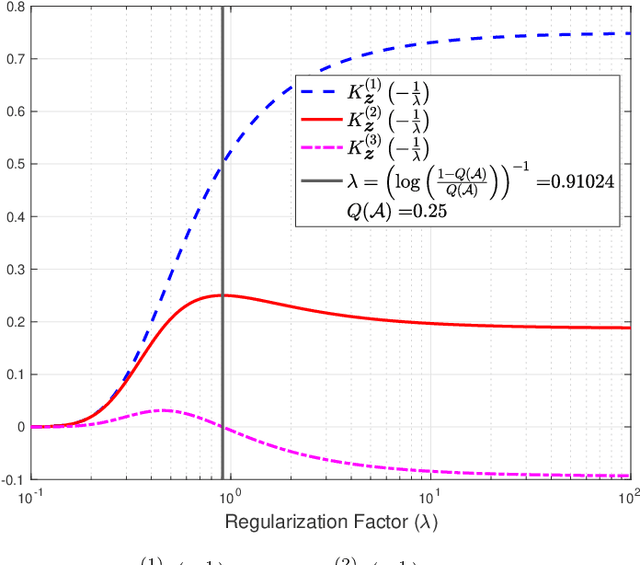
The empirical risk minimization (ERM) problem with relative entropy regularization (ERM-RER) is investigated under the assumption that the reference measure is a~$\sigma$-finite measure instead of a probability measure. This assumption leads to a generalization of the ERM-RER (g-ERM-RER) problem that allows for a larger degree of flexibility in the incorporation of prior knowledge over the set of models. The solution of the g-ERM-RER problem is shown to be a unique probability measure mutually absolutely continuous with the reference measure and to exhibit a probably-approximately-correct (PAC) guarantee for the ERM problem. For a given dataset, the empirical risk is shown to be a sub-Gaussian random variable when the models are sampled from the solution to the g-ERM-RER problem. Finally, the sensitivity of the expected empirical risk to deviations from the solution of the g-ERM-RER problem is studied. In particular, the expectation of the absolute value of sensitivity is shown to be upper bounded, up to a constant factor, by the square root of the lautum information between the models and the datasets.