 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical Relational Learning for Few-Shot Knowledge Graph Completion
Sep 16, 2022
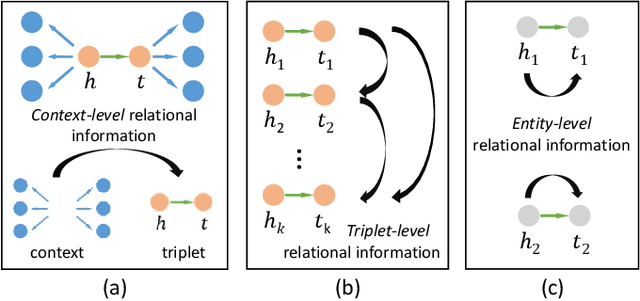
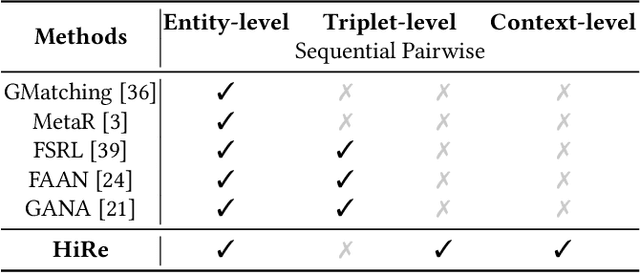

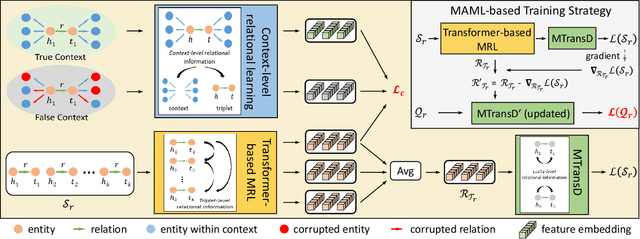
Knowledge graphs (KGs) are known for their large scale and knowledge inference ability, but are also notorious for the incompleteness associated with them. Due to the long-tail distribution of the relations in KGs, few-shot KG completion has been proposed as a solution to alleviate incompleteness and expand the coverage of KGs. It aims to make predictions for triplets involving novel relations when only a few training triplets are provided as reference. Previous methods have mostly focused on designing local neighbor aggregators to learn entity-level information and/or imposing sequential dependency assumption at the triplet level to learn meta relation information. However, valuable pairwise triplet-level interactions and context-level relational information have been largely overlooked for learning meta representations of few-shot relations. In this paper, we propose a hierarchical relational learning method (HiRe) for few-shot KG completion. By jointly capturing three levels of relational information (entity-level, triplet-level and context-level), HiRe can effectively learn and refine the meta representation of few-shot relations, and consequently generalize very well to new unseen relations. Extensive experiments on two benchmark datasets validate the superiority of HiRe against other state-of-the-art methods.
A Uniform Representation Learning Method for OCT-based Fingerprint Presentation Attack Detection and Reconstruction
Sep 25, 2022
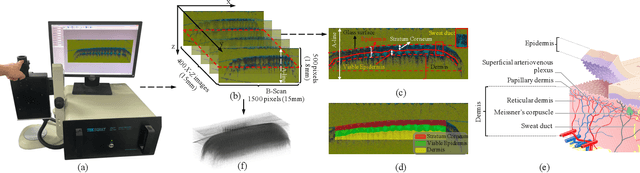

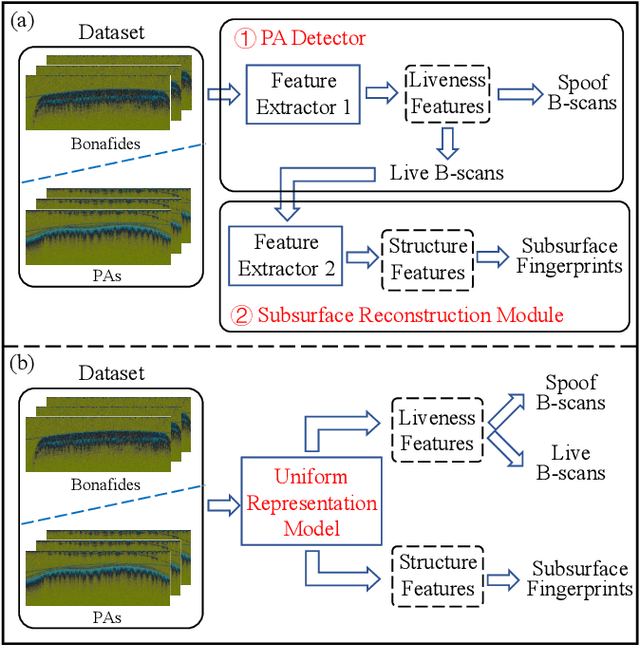
The technology of optical coherence tomography (OCT) to fingerprint imaging opens up a new research potential for fingerprint recognition owing to its ability to capture depth information of the skin layers. Developing robust and high security Automated Fingerprint Recognition Systems (AFRSs) are possible if the depth information can be fully utilized. However, in existing studies, Presentation Attack Detection (PAD) and subsurface fingerprint reconstruction based on depth information are treated as two independent branches, resulting in high computation and complexity of AFRS building.Thus, this paper proposes a uniform representation model for OCT-based fingerprint PAD and subsurface fingerprint reconstruction. Firstly, we design a novel semantic segmentation network which only trained by real finger slices of OCT-based fingerprints to extract multiple subsurface structures from those slices (also known as B-scans). The latent codes derived from the network are directly used to effectively detect the PA since they contain abundant subsurface biological information, which is independent with PA materials and has strong robustness for unknown PAs. Meanwhile, the segmented subsurface structures are adopted to reconstruct multiple subsurface 2D fingerprints. Recognition can be easily achieved by using existing mature technologies based on traditional 2D fingerprints. Extensive experiments are carried on our own established database, which is the largest public OCT-based fingerprint database with 2449 volumes. In PAD task, our method can improve 0.33% Acc from the state-of-the-art method. For reconstruction performance, our method achieves the best performance with 0.834 mIOU and 0.937 PA. By comparing with the recognition performance on surface 2D fingerprints, the effectiveness of our proposed method on high quality subsurface fingerprint reconstruction is further proved.
Detecting Disengagement in Virtual Learning as an Anomaly
Nov 13, 2022
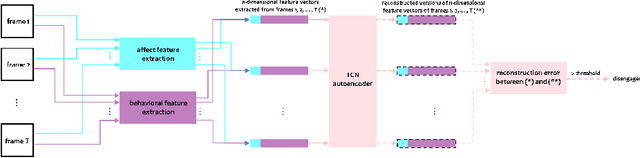

Student engagement is an important factor in meeting the goals of virtual learning programs. Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Many existing approaches solve video-based engagement measurement using the traditional frameworks of binary classification (classifying video snippets into engaged or disengaged classes), multi-class classification (classifying video snippets into multiple classes corresponding to different levels of engagement), or regression (estimating a continuous value corresponding to the level of engagement). However, we observe that while the engagement behaviour is mostly well-defined (e.g., focused, not distracted), disengagement can be expressed in various ways. In addition, in some cases, the data for disengaged classes may not be sufficient to train generalizable binary or multi-class classifiers. To handle this situation, in this paper, for the first time, we formulate detecting disengagement in virtual learning as an anomaly detection problem. We design various autoencoders, including temporal convolutional network autoencoder, long-short-term memory autoencoder, and feedforward autoencoder using different behavioral and affect features for video-based student disengagement detection. The result of our experiments on two publicly available student engagement datasets, DAiSEE and EmotiW, shows the superiority of the proposed approach for disengagement detection as an anomaly compared to binary classifiers for classifying videos into engaged versus disengaged classes (with an average improvement of 9% on the area under the curve of the receiver operating characteristic curve and 22% on the area under the curve of the precision-recall curve).
Learned Distributed Image Compression with Multi-Scale Patch Matching in Feature Domai
Sep 06, 2022
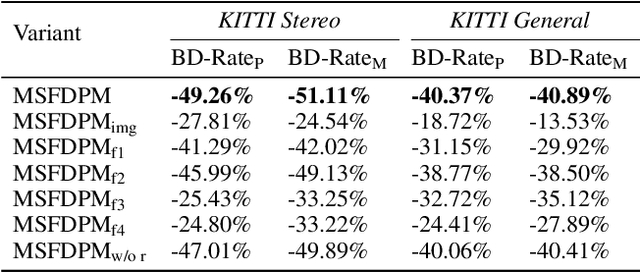
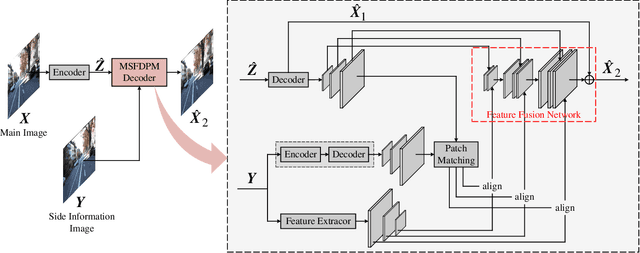

Beyond achieving higher compression efficiency over classical image compression codecs, deep image compression is expected to be improved with additional side information, e.g., another image from a different perspective of the same scene. To better utilize the side information under the distributed compression scenario, the existing method (Ayzik and Avidan 2020) only implements patch matching at the image domain to solve the parallax problem caused by the difference in viewing points. However, the patch matching at the image domain is not robust to the variance of scale, shape, and illumination caused by the different viewing angles, and can not make full use of the rich texture information of the side information image. To resolve this issue, we propose Multi-Scale Feature Domain Patch Matching (MSFDPM) to fully utilizes side information at the decoder of the distributed image compression model. Specifically, MSFDPM consists of a side information feature extractor, a multi-scale feature domain patch matching module, and a multi-scale feature fusion network. Furthermore, we reuse inter-patch correlation from the shallow layer to accelerate the patch matching of the deep layer. Finally, we nd that our patch matching in a multi-scale feature domain further improves compression rate by about 20% compared with the patch matching method at image domain (Ayzik and Avidan 2020).
LP-BFGS attack: An adversarial attack based on the Hessian with limited pixels
Oct 26, 2022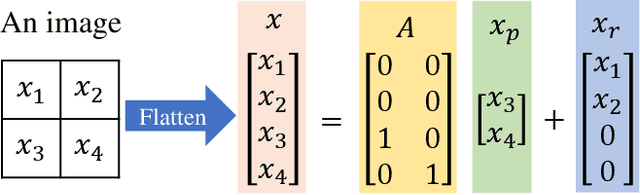
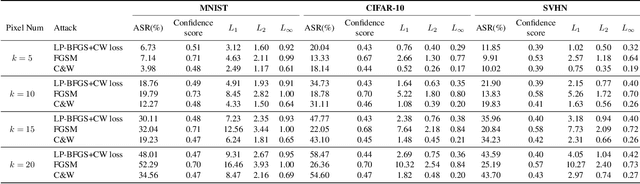

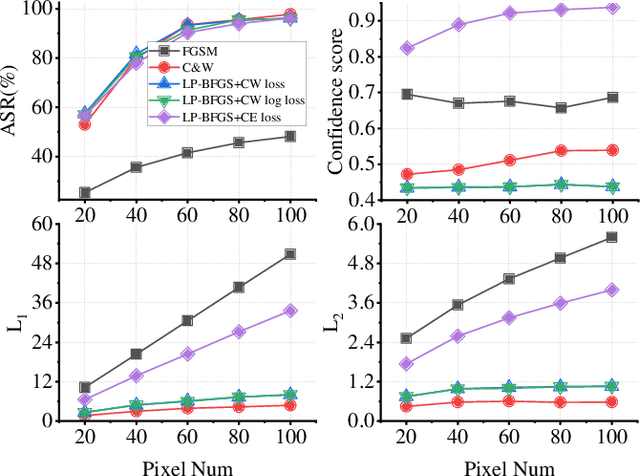
Deep neural networks are vulnerable to adversarial attacks. Most white-box attacks are based on the gradient of models to the input. Since the computation and memory budget, adversarial attacks based on the Hessian information are not paid enough attention. In this work, we study the attack performance and computation cost of the attack method based on the Hessian with a limited perturbation pixel number. Specifically, we propose the Limited Pixel BFGS (LP-BFGS) attack method by incorporating the BFGS algorithm. Some pixels are selected as perturbation pixels by the Integrated Gradient algorithm, which are regarded as optimization variables of the LP-BFGS attack. Experimental results across different networks and datasets with various perturbation pixel numbers demonstrate our approach has a comparable attack with an acceptable computation compared with existing solutions.
Body Part-Based Representation Learning for Occluded Person Re-Identification
Nov 07, 2022
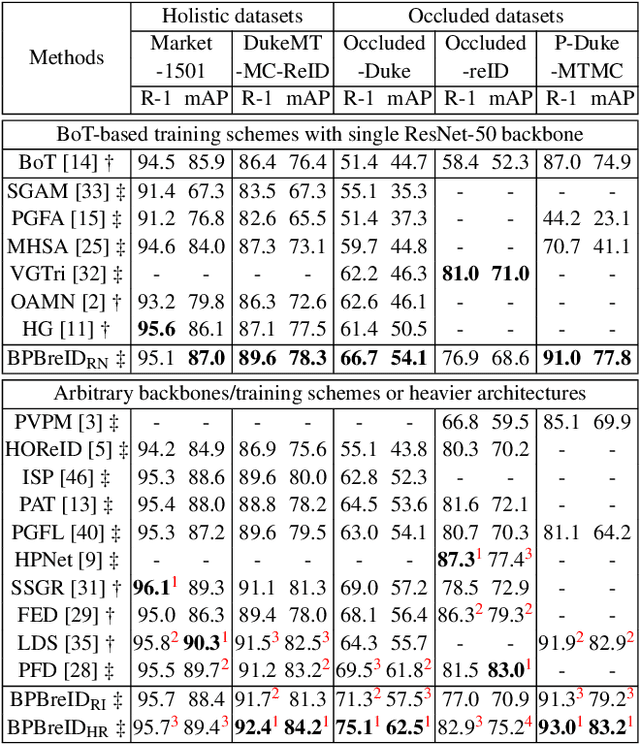
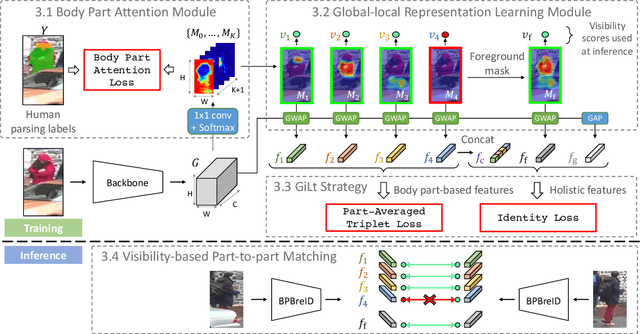
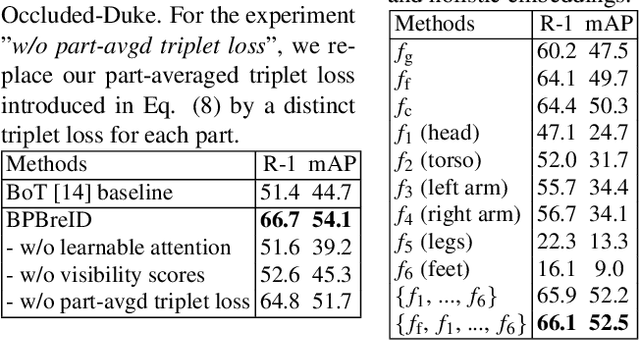
Occluded person re-identification (ReID) is a person retrieval task which aims at matching occluded person images with holistic ones. For addressing occluded ReID, part-based methods have been shown beneficial as they offer fine-grained information and are well suited to represent partially visible human bodies. However, training a part-based model is a challenging task for two reasons. Firstly, individual body part appearance is not as discriminative as global appearance (two distinct IDs might have the same local appearance), this means standard ReID training objectives using identity labels are not adapted to local feature learning. Secondly, ReID datasets are not provided with human topographical annotations. In this work, we propose BPBreID, a body part-based ReID model for solving the above issues. We first design two modules for predicting body part attention maps and producing body part-based features of the ReID target. We then propose GiLt, a novel training scheme for learning part-based representations that is robust to occlusions and non-discriminative local appearance. Extensive experiments on popular holistic and occluded datasets show the effectiveness of our proposed method, which outperforms state-of-the-art methods by 0.7% mAP and 5.6% rank-1 accuracy on the challenging Occluded-Duke dataset. Our code is available at https://github.com/VlSomers/bpbreid.
Cross-Domain Local Characteristic Enhanced Deepfake Video Detection
Nov 07, 2022
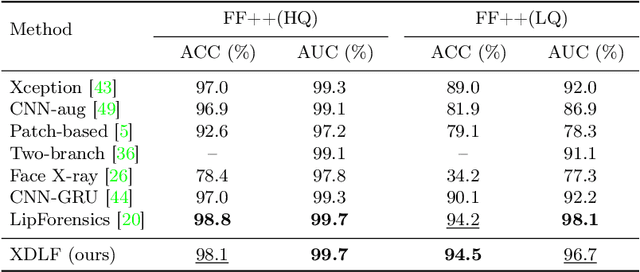
As ultra-realistic face forgery techniques emerge, deepfake detection has attracted increasing attention due to security concerns. Many detectors cannot achieve accurate results when detecting unseen manipulations despite excellent performance on known forgeries. In this paper, we are motivated by the observation that the discrepancies between real and fake videos are extremely subtle and localized, and inconsistencies or irregularities can exist in some critical facial regions across various information domains. To this end, we propose a novel pipeline, Cross-Domain Local Forensics (XDLF), for more general deepfake video detection. In the proposed pipeline, a specialized framework is presented to simultaneously exploit local forgery patterns from space, frequency, and time domains, thus learning cross-domain features to detect forgeries. Moreover, the framework leverages four high-level forgery-sensitive local regions of a human face to guide the model to enhance subtle artifacts and localize potential anomalies. Extensive experiments on several benchmark datasets demonstrate the impressive performance of our method, and we achieve superiority over several state-of-the-art methods on cross-dataset generalization. We also examined the factors that contribute to its performance through ablations, which suggests that exploiting cross-domain local characteristics is a noteworthy direction for developing more general deepfake detectors.
CELLS: A Parallel Corpus for Biomedical Lay Language Generation
Nov 07, 2022
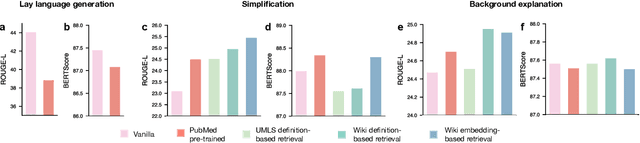
Recent lay language generation systems have used Transformer models trained on a parallel corpus to increase health information accessibility. However, the applicability of these models is constrained by the limited size and topical breadth of available corpora. We introduce CELLS, the largest (63k pairs) and broadest-ranging (12 journals) parallel corpus for lay language generation. The abstract and the corresponding lay language summary are written by domain experts, assuring the quality of our dataset. Furthermore, qualitative evaluation of expert-authored plain language summaries has revealed background explanation as a key strategy to increase accessibility. Such explanation is challenging for neural models to generate because it goes beyond simplification by adding content absent from the source. We derive two specialized paired corpora from CELLS to address key challenges in lay language generation: generating background explanations and simplifying the original abstract. We adopt retrieval-augmented models as an intuitive fit for the task of background explanation generation, and show improvements in summary quality and simplicity while maintaining factual correctness. Taken together, this work presents the first comprehensive study of background explanation for lay language generation, paving the path for disseminating scientific knowledge to a broader audience. CELLS is publicly available at: https://github.com/LinguisticAnomalies/pls_retrieval.
Generalization of generative model for neuronal ensemble inference method
Nov 07, 2022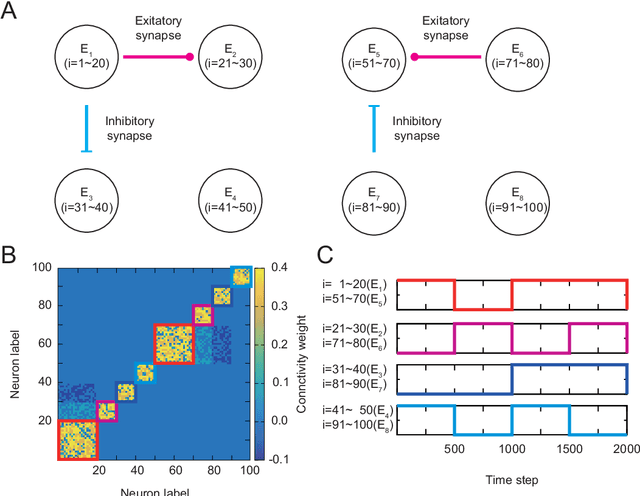

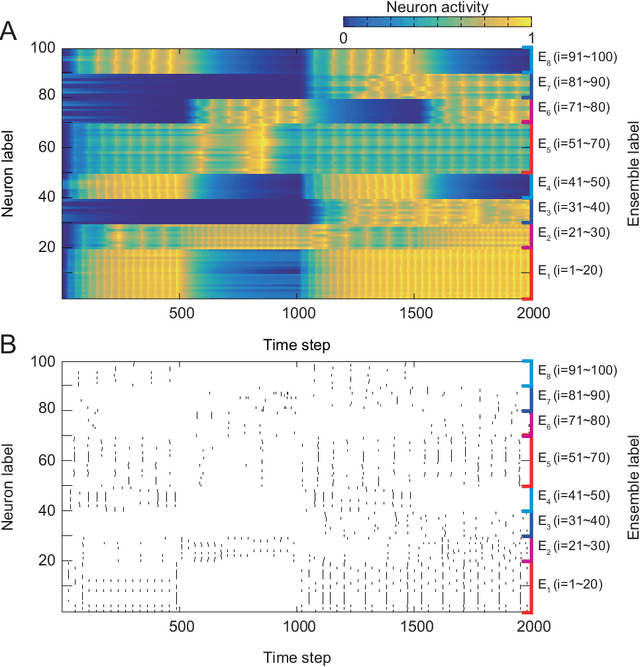
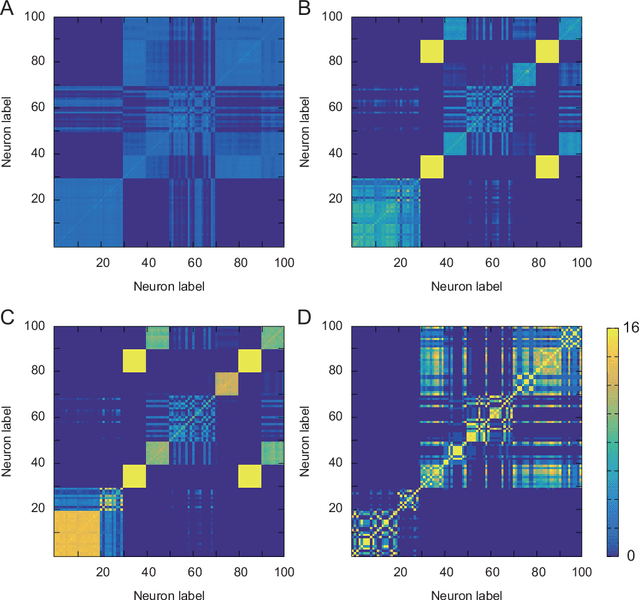
Various brain functions that are necessary to maintain life activities materialize through the interaction of countless neurons. Therefore, it is important to analyze the structure of functional neuronal network. To elucidate the mechanism of brain function, many studies are being actively conducted on the structure of functional neuronal ensemble and hub, including all areas of neuroscience. In addition, recent study suggests that the existence of functional neuronal ensembles and hubs contributes to the efficiency of information processing. For these reasons, there is a demand for methods to infer functional neuronal ensembles from neuronal activity data, and methods based on Bayesian inference have been proposed. However, there is a problem in modeling the activity in Bayesian inference. The features of each neuron's activity have non-stationarity depending on physiological experimental conditions. As a result, the assumption of stationarity in Bayesian inference model impedes inference, which leads to destabilization of inference results and degradation of inference accuracy. In this study, we extend the expressivity of the model in the previous study and improve it to a soft clustering method, which can be applied to activity data with non-stationarity. In addition, for the effectiveness of the method, we apply the developed method to synthetic data generated by the leaky-integrate-and-fire model, and discuss the result.
Uplink Sensing Using CSI Ratio in Perceptive Mobile Networks
Nov 07, 2022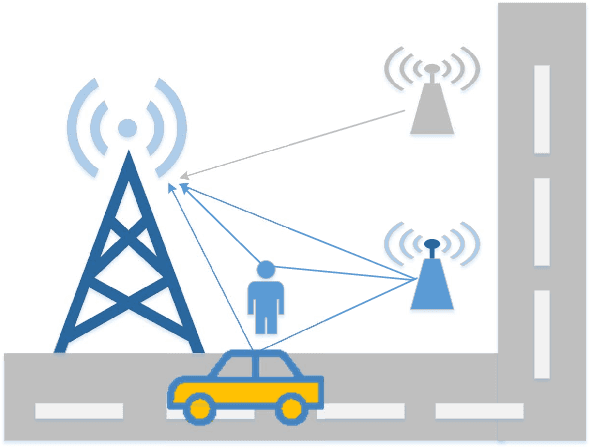
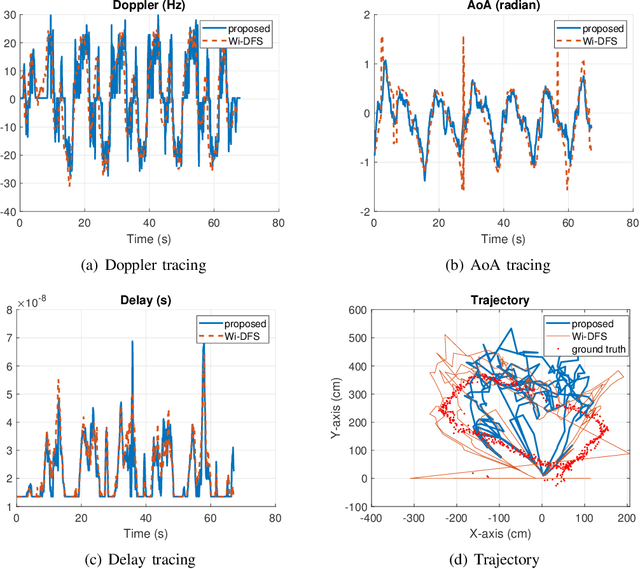
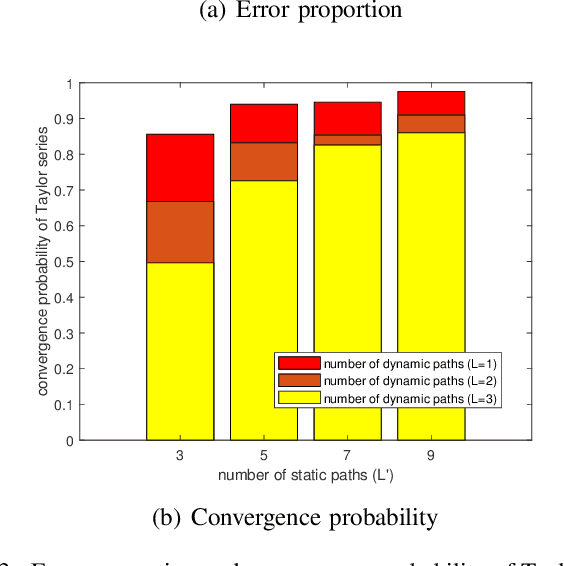
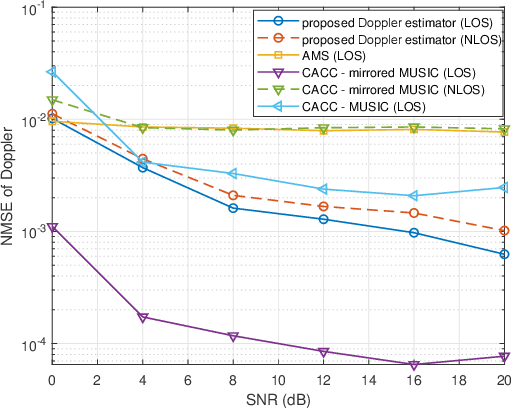
Uplink sensing in perceptive mobile networks (PMNs), which uses uplink communication signals for sensing the environment around a base station, faces challenging issues of clock asynchronism and the requirement of a line-of-sight (LOS) path between transmitters and receivers. The channel state information (CSI) ratio has been applied to resolve these issues, however, current research on the CSI ratio is limited to Doppler estimation in a single dynamic path. This paper proposes an advanced parameter estimation scheme that can extract multiple dynamic parameters, including Doppler frequency, angle-of-arrival (AoA), and delay, in a communication uplink channel and completes the localization of multiple moving targets. Our scheme is based on the multi-element Taylor series of the CSI ratio that converts a nonlinear function of sensing parameters to linear forms and enables the applications of traditional sensing algorithms. Using the truncated Taylor series, we develop novel multiple-signal-classification grid searching algorithms for estimating Doppler frequencies and AoAs and use the least-square method to obtain delays. Both experimental and simulation results are provided, demonstrating that our proposed scheme can achieve good performances for sensing both single and multiple dynamic paths, without requiring the presence of a LOS path.