 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Human in the loop approaches in multi-modal conversational task guidance system development
Nov 03, 2022
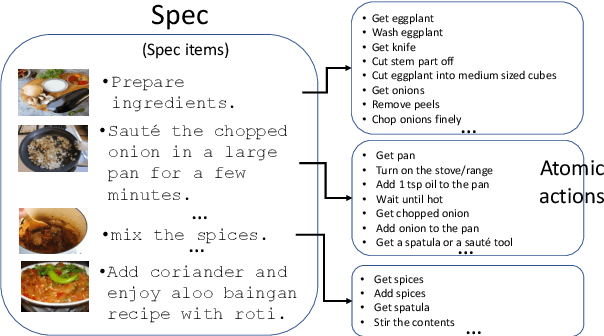
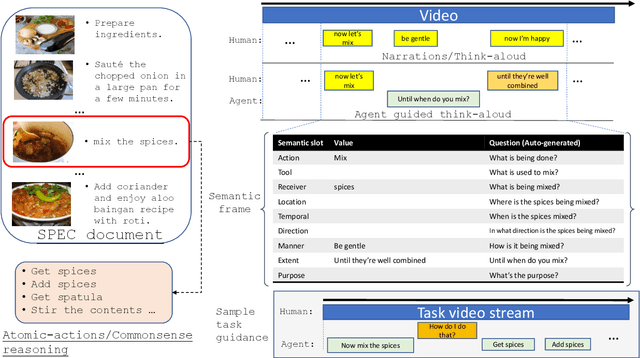
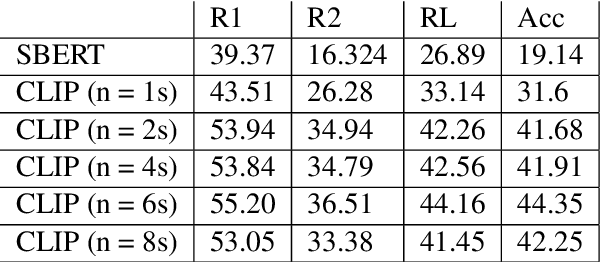
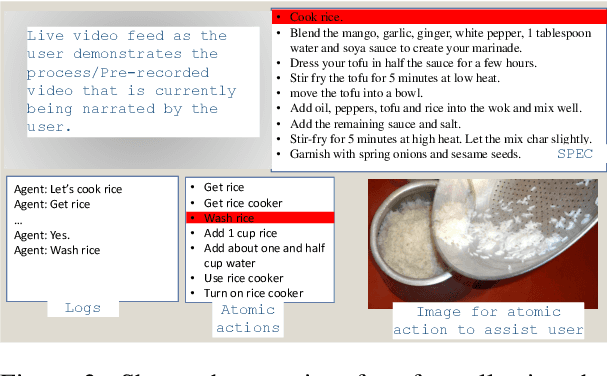
Development of task guidance systems for aiding humans in a situated task remains a challenging problem. The role of search (information retrieval) and conversational systems for task guidance has immense potential to help the task performers achieve various goals. However, there are several technical challenges that need to be addressed to deliver such conversational systems, where common supervised approaches fail to deliver the expected results in terms of overall performance, user experience and adaptation to realistic conditions. In this preliminary work we first highlight some of the challenges involved during the development of such systems. We then provide an overview of existing datasets available and highlight their limitations. We finally develop a model-in-the-loop wizard-of-oz based data collection tool and perform a pilot experiment.
CL-CrossVQA: A Continual Learning Benchmark for Cross-Domain Visual Question Answering
Nov 19, 2022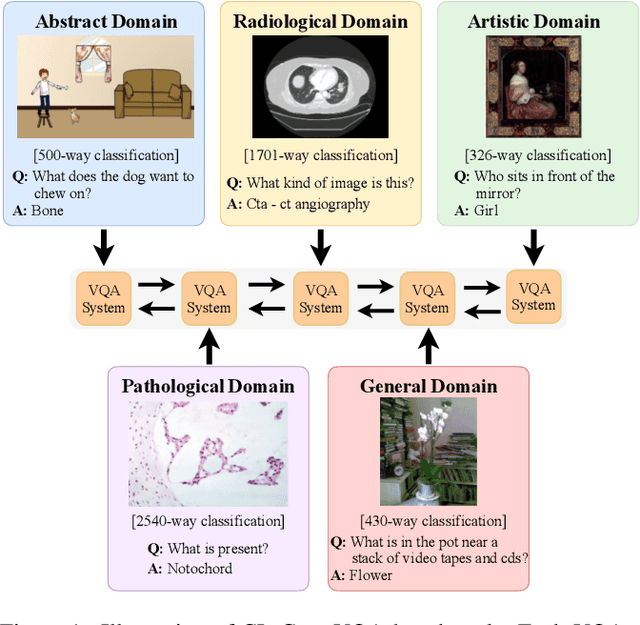


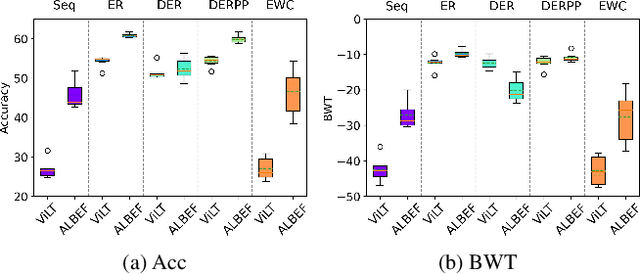
Visual Question Answering (VQA) is a multi-discipline research task. To produce the right answer, it requires an understanding of the visual content of images, the natural language questions, as well as commonsense reasoning over the information contained in the image and world knowledge. Recently, large-scale Vision-and-Language Pre-trained Models (VLPMs) have been the mainstream approach to VQA tasks due to their superior performance. The standard practice is to fine-tune large-scale VLPMs pre-trained on huge general-domain datasets using the domain-specific VQA datasets. However, in reality, the application domain can change over time, necessitating VLPMs to continually learn and adapt to new domains without forgetting previously acquired knowledge. Most existing continual learning (CL) research concentrates on unimodal tasks, whereas a more practical application scenario, i.e, CL on cross-domain VQA, has not been studied. Motivated by this, we introduce CL-CrossVQA, a rigorous Continual Learning benchmark for Cross-domain Visual Question Answering, through which we conduct extensive experiments on 4 VLPMs, 4 CL approaches, and 5 VQA datasets from different domains. In addition, by probing the forgetting phenomenon of the intermediate layers, we provide insights into how model architecture affects CL performance, why CL approaches can help mitigate forgetting in VLPMs to some extent, and how to design CL approaches suitable for VLPMs in this challenging continual learning environment. To facilitate future work on CL for cross-domain VQA, we will release our datasets and code.
Non-Coherent Over-the-Air Decentralized Stochastic Gradient Descent
Nov 19, 2022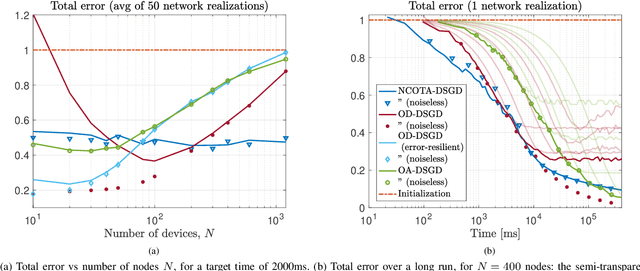
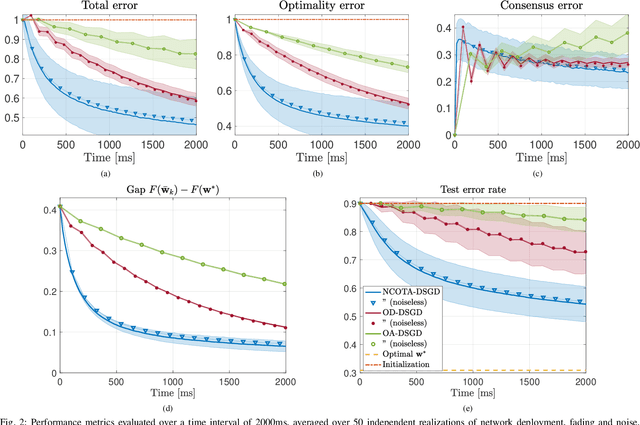
This paper proposes a Decentralized Stochastic Gradient Descent (DSGD) algorithm to solve distributed machine-learning tasks over wirelessly-connected systems, without the coordination of a base station. It combines local stochastic gradient descent steps with a Non-Coherent Over-The-Air (NCOTA) consensus scheme at the receivers, that enables concurrent transmissions by leveraging the waveform superposition properties of the wireless channels. With NCOTA, local optimization signals are mapped to a mixture of orthogonal preamble sequences and transmitted concurrently over the wireless channel under half-duplex constraints. Consensus is estimated by non-coherently combining the received signals with the preamble sequences and mitigating the impact of noise and fading via a consensus stepsize. NCOTA-DSGD operates without channel state information (typically used in over-the-air computation schemes for channel inversion) and leverages the channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization). It is shown that, with a suitable tuning of decreasing consensus and learning stepsizes, the error (measured as Euclidean distance) between the local and globally optimum models vanishes with rate $\mathcal O(k^{-1/4})$ after $k$ iterations. NCOTA-DSGD is evaluated numerically by solving an image classification task on the MNIST dataset, cast as a regularized cross-entropy loss minimization. Numerical results depict faster convergence vis-\`a-vis running time than implementations of the classical DSGD algorithm over digital and analog orthogonal channels, when the number of learning devices is large, under stringent delay constraints.
BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022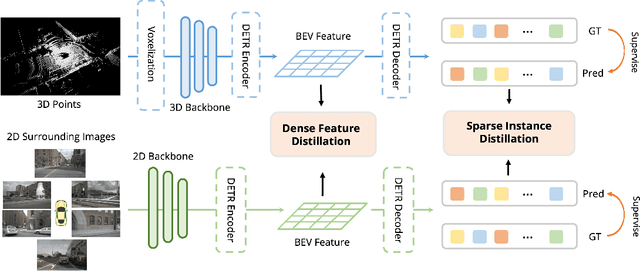
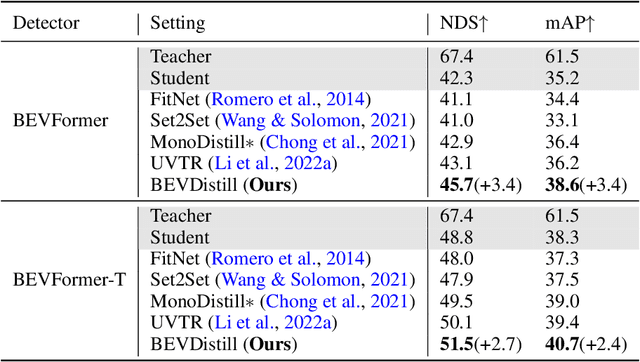
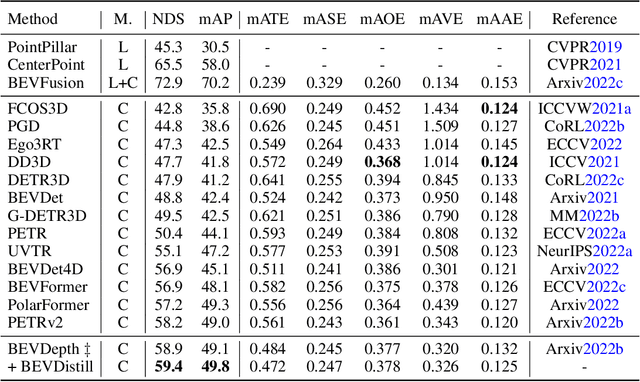

3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
EfficientTrain: Exploring Generalized Curriculum Learning for Training Visual Backbones
Nov 17, 2022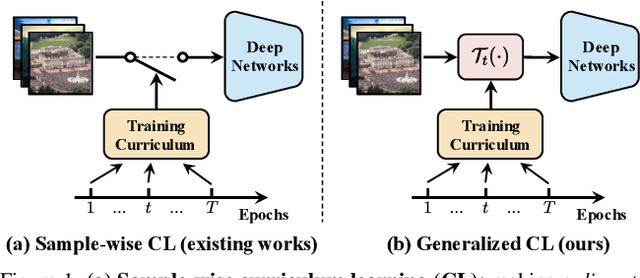
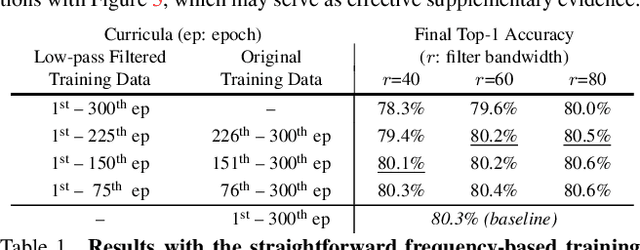
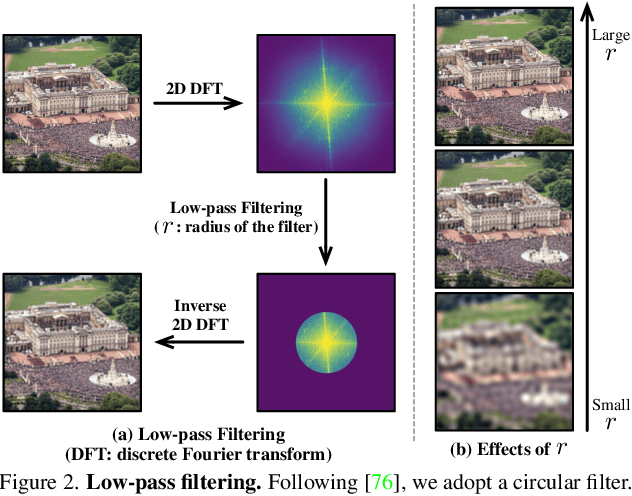
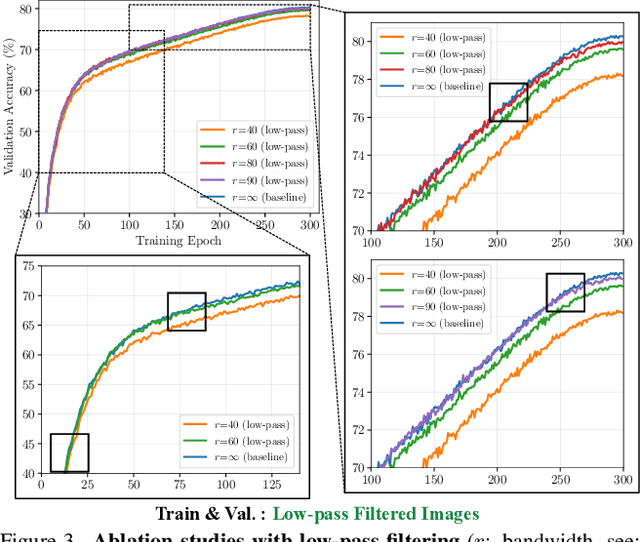
The superior performance of modern deep networks usually comes at the price of a costly training procedure. In this paper, we present a novel curriculum learning approach for the efficient training of visual backbones (e.g., vision Transformers). The proposed method is inspired by the phenomenon that deep networks mainly learn to recognize some 'easier-to-learn' discriminative patterns within each example at earlier stages of training, e.g., the lower-frequency components of images and the original information before data augmentation. Driven by this observation, we propose a curriculum where the model always leverages all the training data at each epoch, while the curriculum starts with only exposing the 'easier-to-learn' patterns of each example, and introduces gradually more difficult patterns. To implement this idea, we 1) introduce a cropping operation in the Fourier spectrum of the inputs, which enables the model to learn from only the lower-frequency components efficiently, and 2) demonstrate that exposing the features of original images amounts to adopting weaker data augmentation. Our resulting algorithm, EfficientTrain, is simple, general, yet surprisingly effective. For example, it reduces the training time of a wide variety of popular models (e.g., ConvNeXts, DeiT, PVT, and Swin/CSWin Transformers) by more than ${1.5\times}$ on ImageNet-1K/22K without sacrificing the accuracy. It is effective for self-supervised learning (i.e., MAE) as well. Code is available at https://github.com/LeapLabTHU/EfficientTrain.
You Only Label Once: 3D Box Adaptation from Point Cloud to Image via Semi-Supervised Learning
Nov 17, 2022

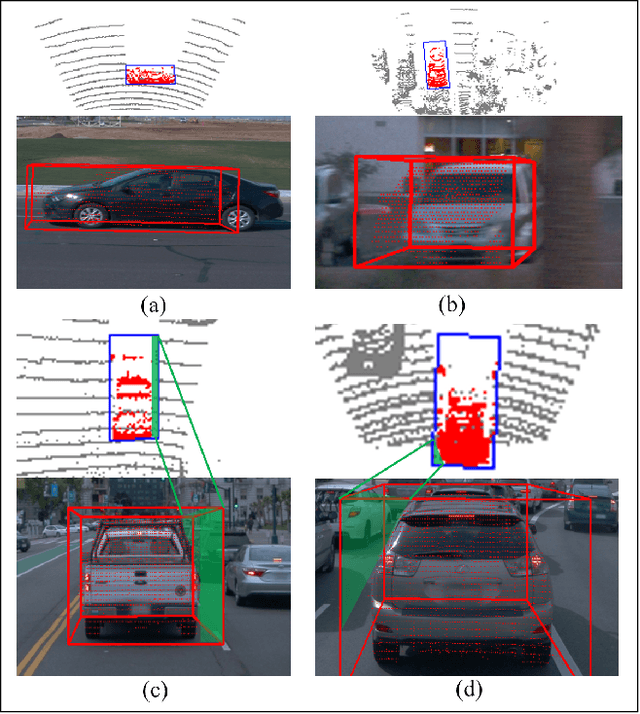
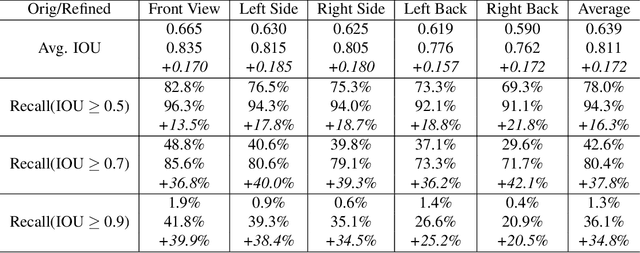
The image-based 3D object detection task expects that the predicted 3D bounding box has a ``tightness'' projection (also referred to as cuboid), which fits the object contour well on the image while still keeping the geometric attribute on the 3D space, e.g., physical dimension, pairwise orthogonal, etc. These requirements bring significant challenges to the annotation. Simply projecting the Lidar-labeled 3D boxes to the image leads to non-trivial misalignment, while directly drawing a cuboid on the image cannot access the original 3D information. In this work, we propose a learning-based 3D box adaptation approach that automatically adjusts minimum parameters of the 360$^{\circ}$ Lidar 3D bounding box to perfectly fit the image appearance of panoramic cameras. With only a few 2D boxes annotation as guidance during the training phase, our network can produce accurate image-level cuboid annotations with 3D properties from Lidar boxes. We call our method ``you only label once'', which means labeling on the point cloud once and automatically adapting to all surrounding cameras. As far as we know, we are the first to focus on image-level cuboid refinement, which balances the accuracy and efficiency well and dramatically reduces the labeling effort for accurate cuboid annotation. Extensive experiments on the public Waymo and NuScenes datasets show that our method can produce human-level cuboid annotation on the image without needing manual adjustment.
StuArt: Individualized Classroom Observation of Students with Automatic Behavior Recognition and Tracking
Nov 06, 2022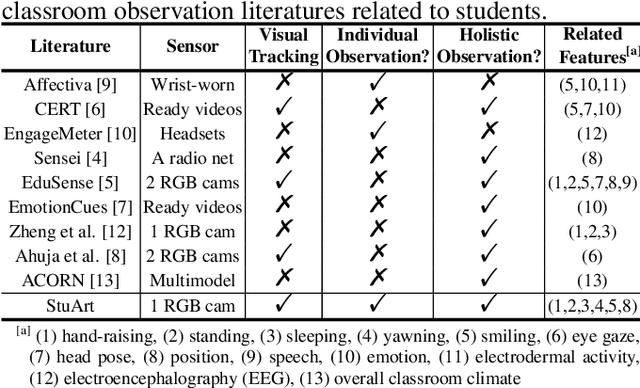
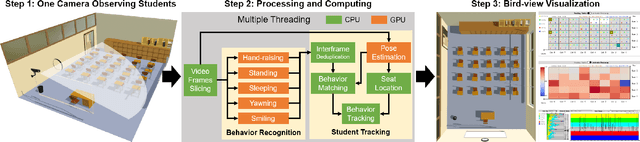

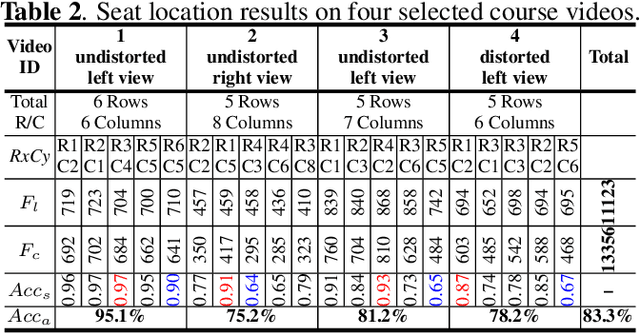
Each student matters, but it is hardly for instructors to observe all the students during the courses and provide helps to the needed ones immediately. In this paper, we present StuArt, a novel automatic system designed for the individualized classroom observation, which empowers instructors to concern the learning status of each student. StuArt can recognize five representative student behaviors (hand-raising, standing, sleeping, yawning, and smiling) that are highly related to the engagement and track their variation trends during the course. To protect the privacy of students, all the variation trends are indexed by the seat numbers without any personal identification information. Furthermore, StuArt adopts various user-friendly visualization designs to help instructors quickly understand the individual and whole learning status. Experimental results on real classroom videos have demonstrated the superiority and robustness of the embedded algorithms. We expect our system promoting the development of large-scale individualized guidance of students.
Tracking Dataset IP Use in Deep Neural Networks
Nov 24, 2022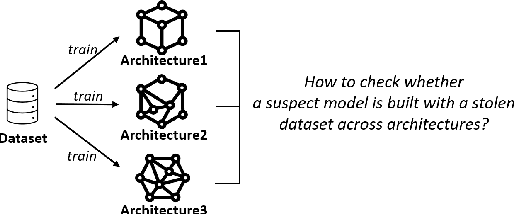
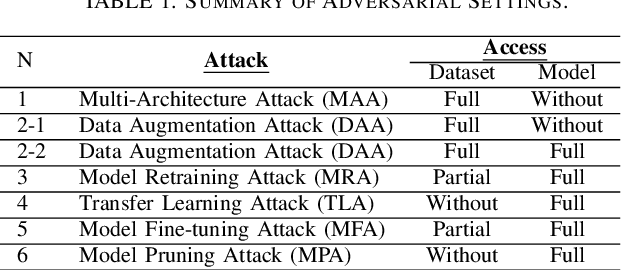
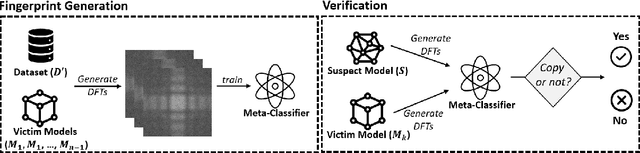
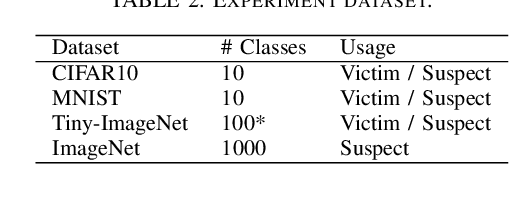
Training highly performant deep neural networks (DNNs) typically requires the collection of a massive dataset and the use of powerful computing resources. Therefore, unauthorized redistribution of private pre-trained DNNs may cause severe economic loss for model owners. For protecting the ownership of DNN models, DNN watermarking schemes have been proposed by embedding secret information in a DNN model and verifying its presence for model ownership. However, existing DNN watermarking schemes compromise the model utility and are vulnerable to watermark removal attacks because a model is modified with a watermark. Alternatively, a new approach dubbed DEEPJUDGE was introduced to measure the similarity between a suspect model and a victim model without modifying the victim model. However, DEEPJUDGE would only be designed to detect the case where a suspect model's architecture is the same as a victim model's. In this work, we propose a novel DNN fingerprinting technique dubbed DEEPTASTER to prevent a new attack scenario in which a victim's data is stolen to build a suspect model. DEEPTASTER can effectively detect such data theft attacks even when a suspect model's architecture differs from a victim model's. To achieve this goal, DEEPTASTER generates a few adversarial images with perturbations, transforms them into the Fourier frequency domain, and uses the transformed images to identify the dataset used in a suspect model. The intuition is that those adversarial images can be used to capture the characteristics of DNNs built on a specific dataset. We evaluated the detection accuracy of DEEPTASTER on three datasets with three model architectures under various attack scenarios, including transfer learning, pruning, fine-tuning, and data augmentation. Overall, DEEPTASTER achieves a balanced accuracy of 94.95%, which is significantly better than 61.11% achieved by DEEPJUDGE in the same settings.
Hyperbolic Cosine Transformer for LiDAR 3D Object Detection
Nov 10, 2022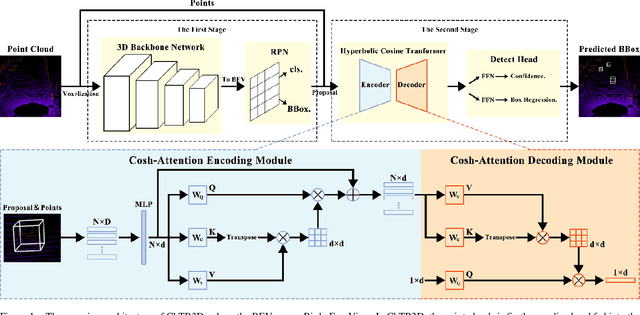
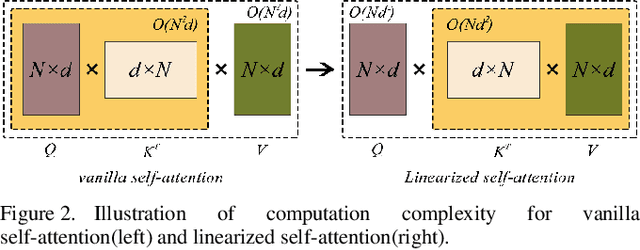
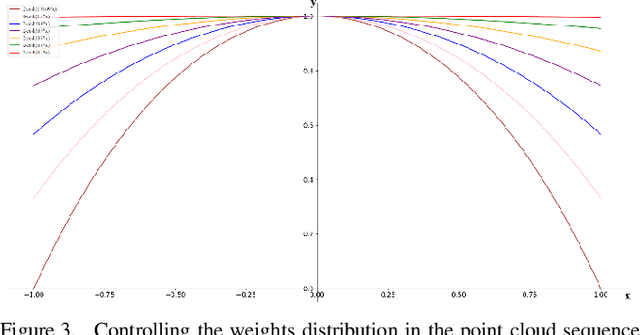
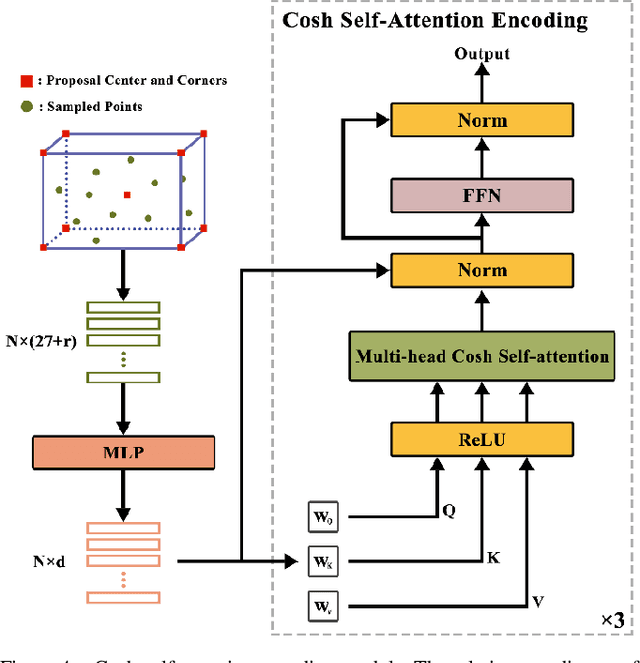
Recently, Transformer has achieved great success in computer vision. However, it is constrained because the spatial and temporal complexity grows quadratically with the number of large points in 3D object detection applications. Previous point-wise methods are suffering from time consumption and limited receptive fields to capture information among points. In this paper, we propose a two-stage hyperbolic cosine transformer (ChTR3D) for 3D object detection from LiDAR point clouds. The proposed ChTR3D refines proposals by applying cosh-attention in linear computation complexity to encode rich contextual relationships among points. The cosh-attention module reduces the space and time complexity of the attention operation. The traditional softmax operation is replaced by non-negative ReLU activation and hyperbolic-cosine-based operator with re-weighting mechanism. Extensive experiments on the widely used KITTI dataset demonstrate that, compared with vanilla attention, the cosh-attention significantly improves the inference speed with competitive performance. Experiment results show that, among two-stage state-of-the-art methods using point-level features, the proposed ChTR3D is the fastest one.
MixMask: Revisiting Masked Siamese Self-supervised Learning in Asymmetric Distance
Oct 20, 2022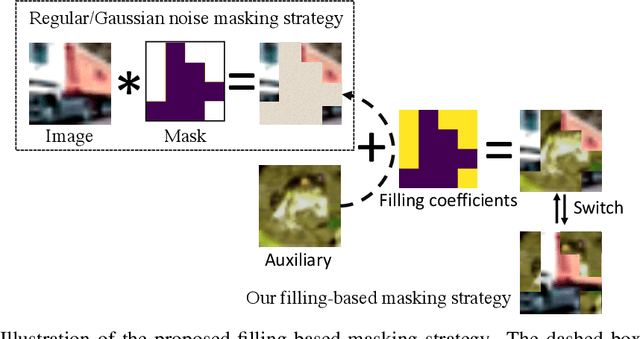
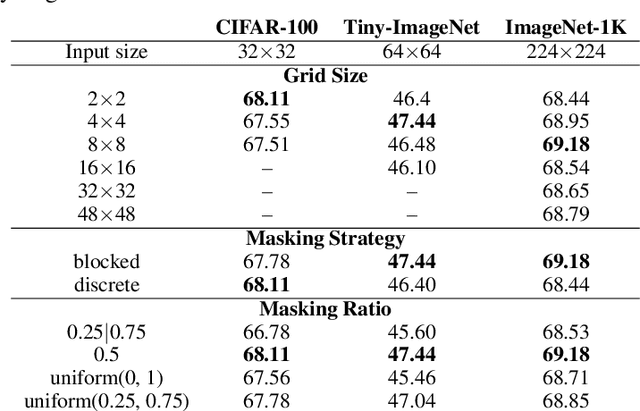
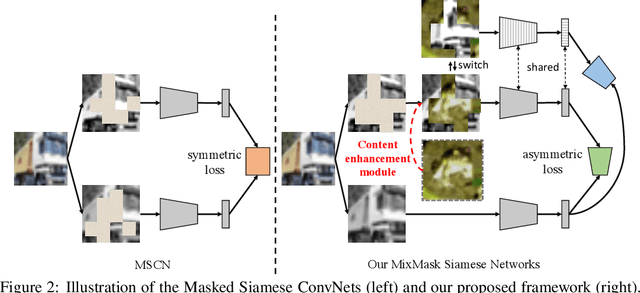

Recent advances in self-supervised learning integrate Masked Modeling and Siamese Networks into a single framework to fully reap the advantages of both the two techniques. However, previous erasing-based masking scheme in masked image modeling is not originally designed for siamese networks. Existing approaches simply inherit the default loss design from previous siamese networks, and ignore the information loss and distance change after employing masking operation in the frameworks. In this paper, we propose a filling-based masking strategy called MixMask to prevent information loss due to the randomly erased areas of an image in vanilla masking method. We further introduce a dynamic loss function design with soft distance to adapt the integrated architecture and avoid mismatches between transformed input and objective in Masked Siamese ConvNets (MSCN). The dynamic loss distance is calculated according to the proposed mix-masking scheme. Extensive experiments are conducted on various datasets of CIFAR-100, Tiny-ImageNet and ImageNet-1K. The results demonstrate that the proposed framework can achieve better accuracy on linear probing, semi-supervised and {supervised finetuning}, which outperforms the state-of-the-art MSCN by a significant margin. We also show the superiority on downstream tasks of object detection and segmentation. Our source code is available at https://github.com/LightnessOfBeing/MixMask.