 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GIU-GANs: Global Information Utilization for Generative Adversarial Networks
Jan 25, 2022
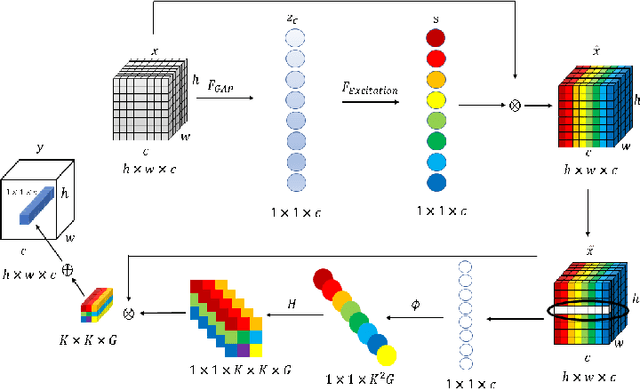

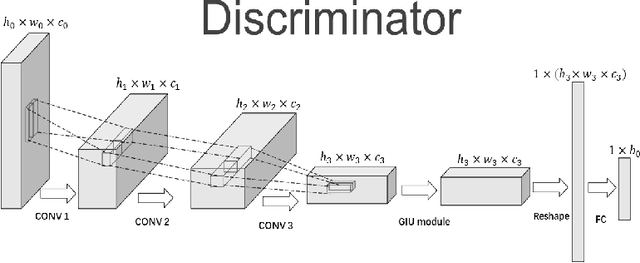

In recent years, with the rapid development of artificial intelligence, image generation based on deep learning has dramatically advanced. Image generation based on Generative Adversarial Networks (GANs) is a promising study. However, since convolutions are limited by spatial-agnostic and channel-specific, features extracted by traditional GANs based on convolution are constrained. Therefore, GANs are unable to capture any more details per image. On the other hand, straightforwardly stacking of convolutions causes too many parameters and layers in GANs, which will lead to a high risk of overfitting. To overcome the aforementioned limitations, in this paper, we propose a new GANs called Involution Generative Adversarial Networks (GIU-GANs). GIU-GANs leverages a brand new module called the Global Information Utilization (GIU) module, which integrates Squeeze-and-Excitation Networks (SENet) and involution to focus on global information by channel attention mechanism, leading to a higher quality of generated images. Meanwhile, Batch Normalization(BN) inevitably ignores the representation differences among noise sampled by the generator, and thus degrade the generated image quality. Thus we introduce Representative Batch Normalization(RBN) to the GANs architecture for this issue. The CIFAR-10 and CelebA datasets are employed to demonstrate the effectiveness of our proposed model. A large number of experiments prove that our model achieves state-of-the-art competitive performance.
A Unified Framework of Medical Information Annotation and Extraction for Chinese Clinical Text
Mar 08, 2022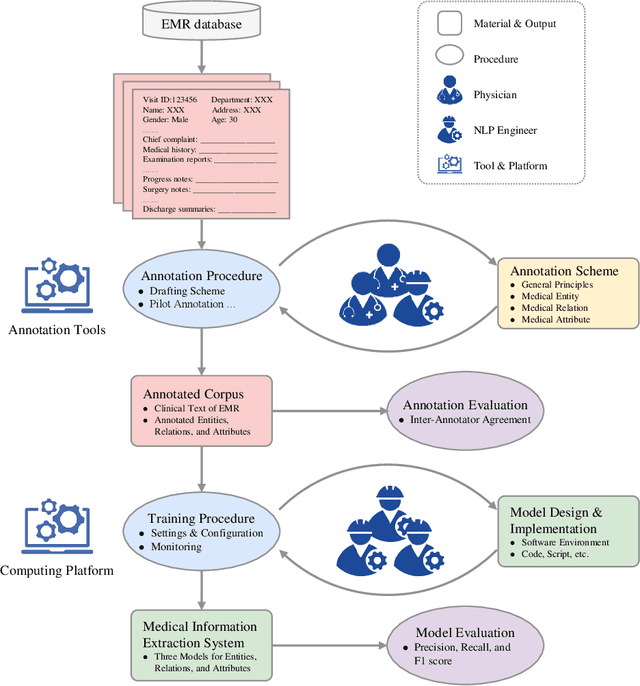
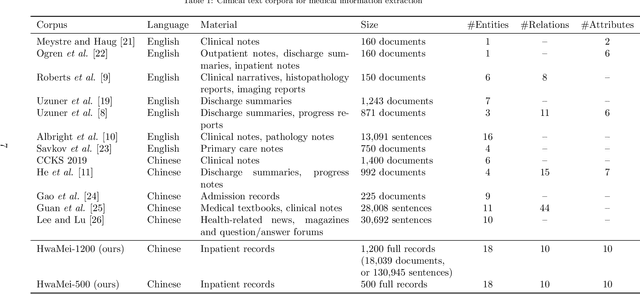
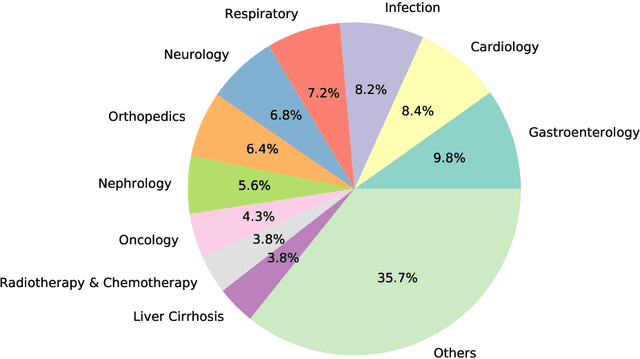
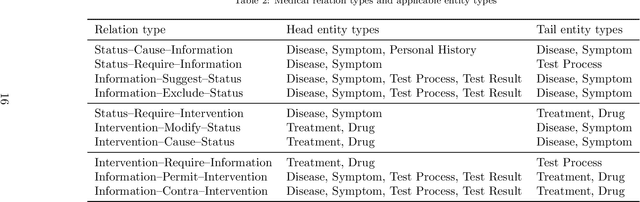
Medical information extraction consists of a group of natural language processing (NLP) tasks, which collaboratively convert clinical text to pre-defined structured formats. Current state-of-the-art (SOTA) NLP models are highly integrated with deep learning techniques and thus require massive annotated linguistic data. This study presents an engineering framework of medical entity recognition, relation extraction and attribute extraction, which are unified in annotation, modeling and evaluation. Specifically, the annotation scheme is comprehensive, and compatible between tasks, especially for the medical relations. The resulted annotated corpus includes 1,200 full medical records (or 18,039 broken-down documents), and achieves inter-annotator agreements (IAAs) of 94.53%, 73.73% and 91.98% F 1 scores for the three tasks. Three task-specific neural network models are developed within a shared structure, and enhanced by SOTA NLP techniques, i.e., pre-trained language models. Experimental results show that the system can retrieve medical entities, relations and attributes with F 1 scores of 93.47%, 67.14% and 90.89%, respectively. This study, in addition to our publicly released annotation scheme and code, provides solid and practical engineering experience of developing an integrated medical information extraction system.
Distribution inference risks: Identifying and mitigating sources of leakage
Sep 18, 2022

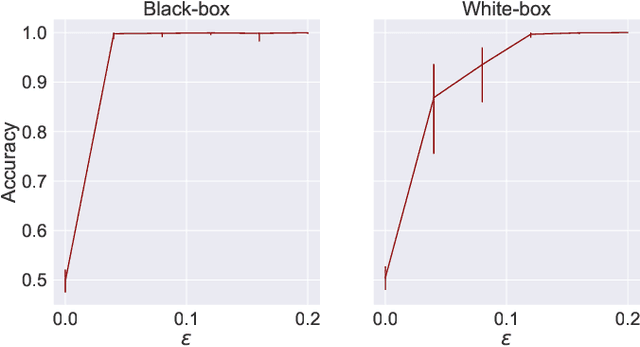
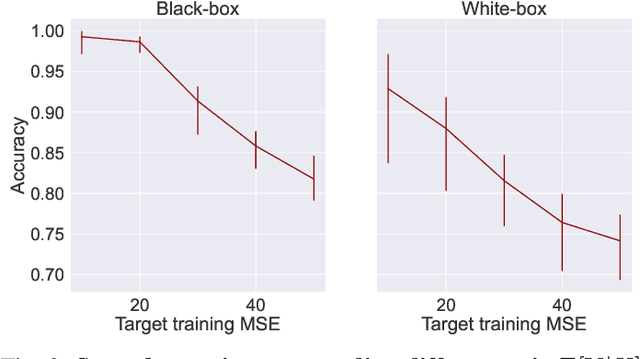
A large body of work shows that machine learning (ML) models can leak sensitive or confidential information about their training data. Recently, leakage due to distribution inference (or property inference) attacks is gaining attention. In this attack, the goal of an adversary is to infer distributional information about the training data. So far, research on distribution inference has focused on demonstrating successful attacks, with little attention given to identifying the potential causes of the leakage and to proposing mitigations. To bridge this gap, as our main contribution, we theoretically and empirically analyze the sources of information leakage that allows an adversary to perpetrate distribution inference attacks. We identify three sources of leakage: (1) memorizing specific information about the $\mathbb{E}[Y|X]$ (expected label given the feature values) of interest to the adversary, (2) wrong inductive bias of the model, and (3) finiteness of the training data. Next, based on our analysis, we propose principled mitigation techniques against distribution inference attacks. Specifically, we demonstrate that causal learning techniques are more resilient to a particular type of distribution inference risk termed distributional membership inference than associative learning methods. And lastly, we present a formalization of distribution inference that allows for reasoning about more general adversaries than was previously possible.
Query Refinement Prompts for Closed-Book Long-Form Question Answering
Oct 31, 2022


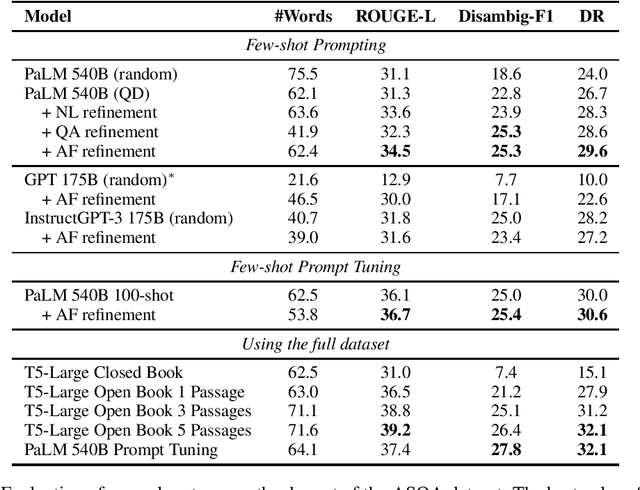
Large language models (LLMs) have been shown to perform well in answering questions and in producing long-form texts, both in few-shot closed-book settings. While the former can be validated using well-known evaluation metrics, the latter is difficult to evaluate. We resolve the difficulties to evaluate long-form output by doing both tasks at once -- to do question answering that requires long-form answers. Such questions tend to be multifaceted, i.e., they may have ambiguities and/or require information from multiple sources. To this end, we define query refinement prompts that encourage LLMs to explicitly express the multifacetedness in questions and generate long-form answers covering multiple facets of the question. Our experiments on two long-form question answering datasets, ASQA and AQuAMuSe, show that using our prompts allows us to outperform fully finetuned models in the closed book setting, as well as achieve results comparable to retrieve-then-generate open-book models.
Mapping Extended Landmarks for Radar SLAM
Oct 31, 2022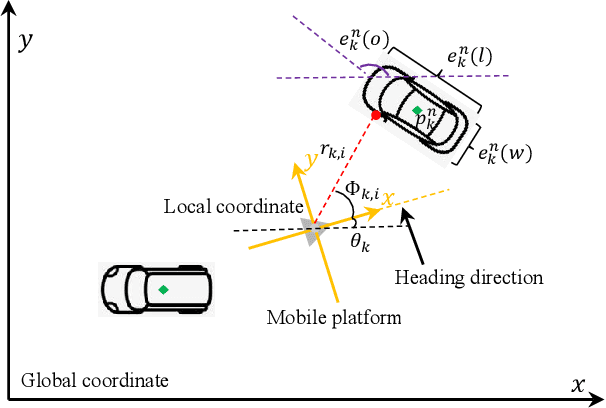

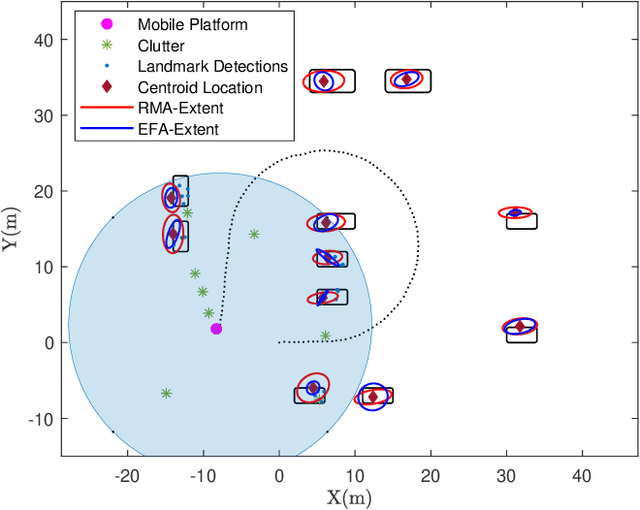
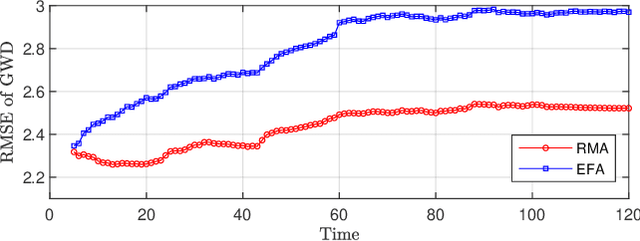
Simultaneous localization and mapping (SLAM) using automotive radar sensors can provide enhanced sensing capabilities for autonomous systems. In SLAM applications, with a greater requirement for the environment map, information on the extent of landmarks is vital for precise navigation and path planning. Although object extent estimation has been successfully applied in target tracking, its adaption to SLAM remains unaddressed due to the additional uncertainty of the sensor platform, bias in the odometer reading, as well as the measurement non-linearity. In this paper, we propose to incorporate the Bayesian random matrix approach to estimate the extent of landmarks in radar SLAM. We describe the details for implementation of landmark extent initialization, prediction and update. To validate the performance of our proposed approach we compare with the model-free ellipse fitting algorithm with results showing more consistent extent estimation. We also demonstrate that exploiting the landmark extent in the state update can improve localization accuracy.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022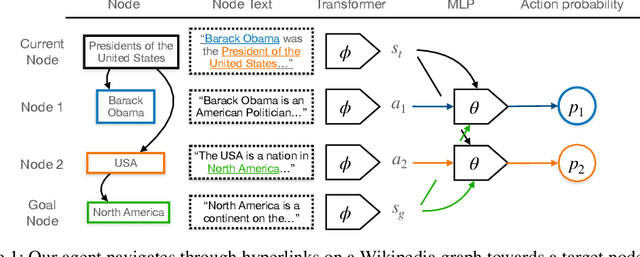

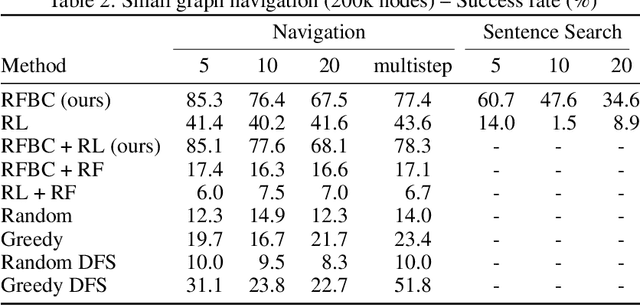
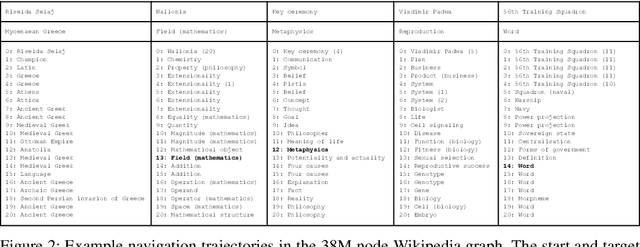
A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
Convolution-Based Channel-Frequency Attention for Text-Independent Speaker Verification
Oct 31, 2022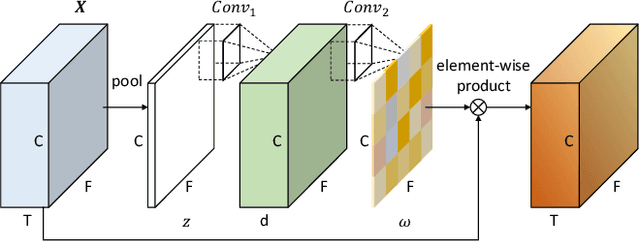
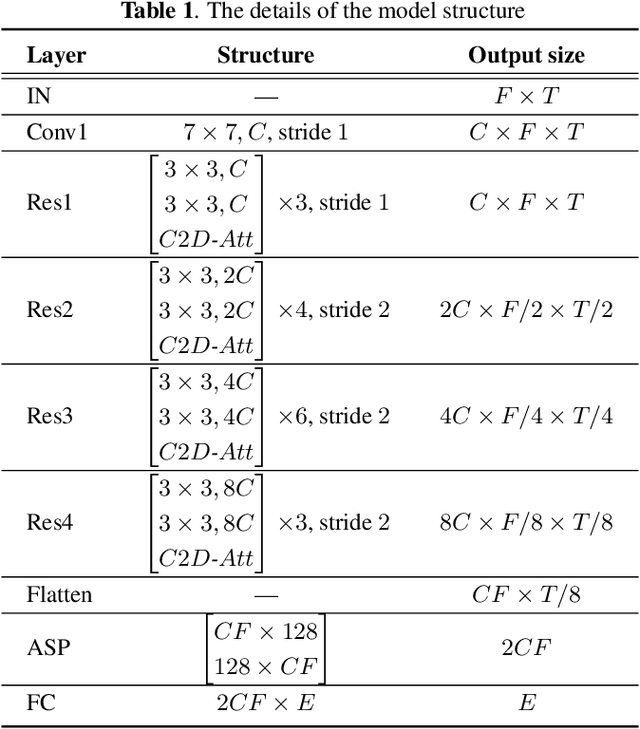
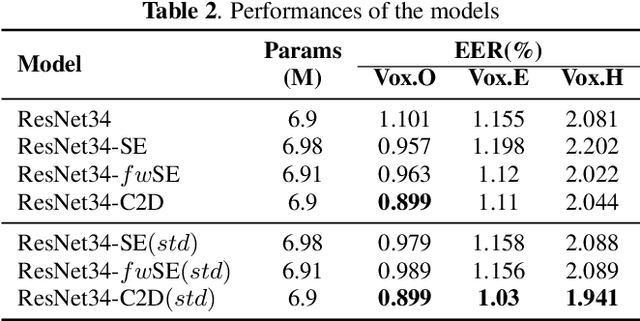
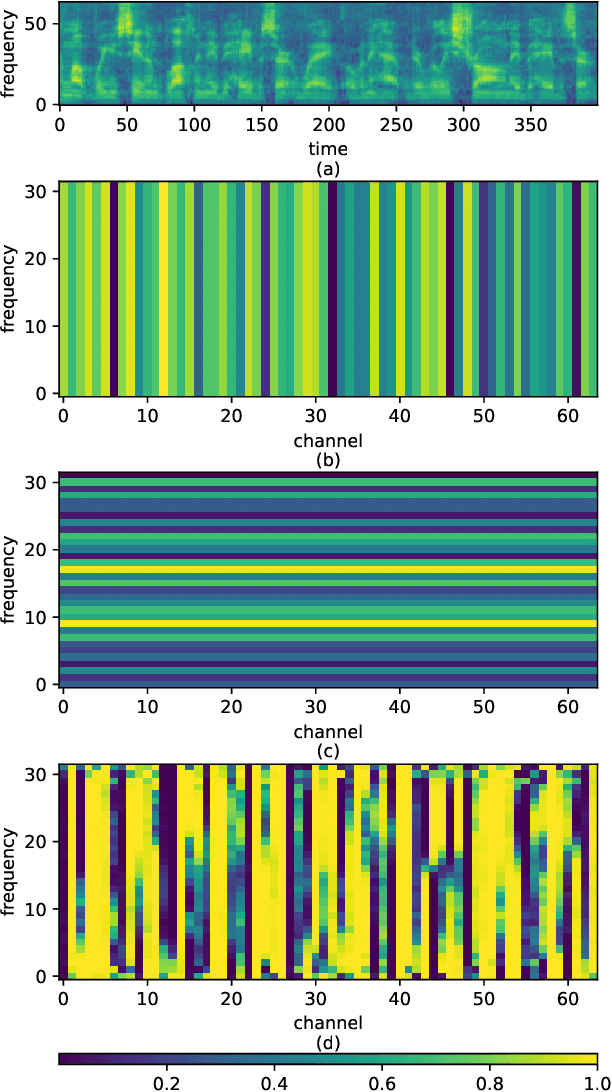
Deep convolutional neural networks (CNNs) have been applied to extracting speaker embeddings with significant success in speaker verification. Incorporating the attention mechanism has shown to be effective in improving the model performance. This paper presents an efficient two-dimensional convolution-based attention module, namely C2D-Att. The interaction between the convolution channel and frequency is involved in the attention calculation by lightweight convolution layers. This requires only a small number of parameters. Fine-grained attention weights are produced to represent channel and frequency-specific information. The weights are imposed on the input features to improve the representation ability for speaker modeling. The C2D-Att is integrated into a modified version of ResNet for speaker embedding extraction. Experiments are conducted on VoxCeleb datasets. The results show that C2DAtt is effective in generating discriminative attention maps and outperforms other attention methods. The proposed model shows robust performance with different scales of model size and achieves state-of-the-art results.
Diffusion models for missing value imputation in tabular data
Oct 31, 2022
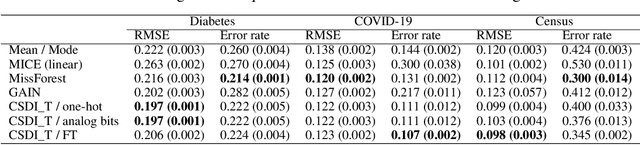
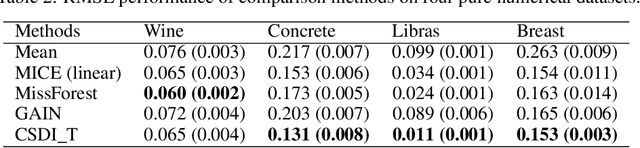
Missing value imputation in machine learning is the task of estimating the missing values in the dataset accurately using available information. In this task, several deep generative modeling methods have been proposed and demonstrated their usefulness, e.g., generative adversarial imputation networks. Recently, diffusion models have gained popularity because of their effectiveness in the generative modeling task in images, texts, audio, etc. To our knowledge, less attention has been paid to the investigation of the effectiveness of diffusion models for missing value imputation in tabular data. Based on recent development of diffusion models for time-series data imputation, we propose a diffusion model approach called "Conditional Score-based Diffusion Models for Tabular data" (CSDI_T). To effectively handle categorical variables and numerical variables simultaneously, we investigate three techniques: one-hot encoding, analog bits encoding, and feature tokenization. Experimental results on benchmark datasets demonstrated the effectiveness of CSDI_T compared with well-known existing methods, and also emphasized the importance of the categorical embedding techniques.
Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
Oct 31, 2022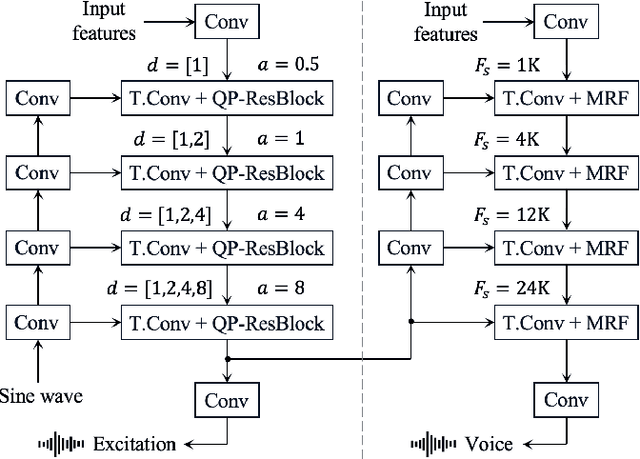
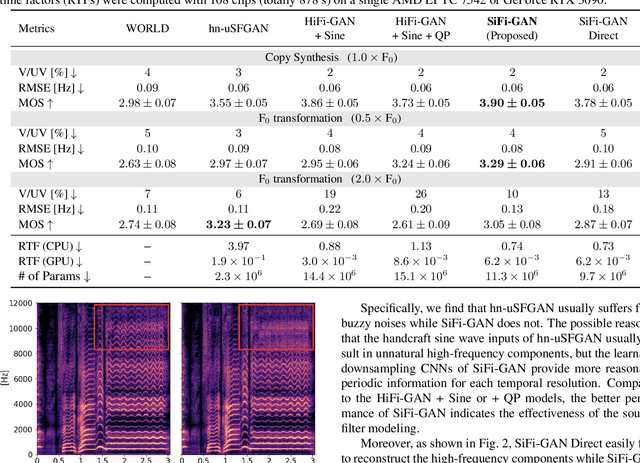
Our previous work, the unified source-filter GAN (uSFGAN) vocoder, introduced a novel architecture based on the source-filter theory into the parallel waveform generative adversarial network to achieve high voice quality and pitch controllability. However, the high temporal resolution inputs result in high computation costs. Although the HiFi-GAN vocoder achieves fast high-fidelity voice generation thanks to the efficient upsampling-based generator architecture, the pitch controllability is severely limited. To realize a fast and pitch-controllable high-fidelity neural vocoder, we introduce the source-filter theory into HiFi-GAN by hierarchically conditioning the resonance filtering network on a well-estimated source excitation information. According to the experimental results, our proposed method outperforms HiFi-GAN and uSFGAN on a singing voice generation in voice quality and synthesis speed on a single CPU. Furthermore, unlike the uSFGAN vocoder, the proposed method can be easily adopted/integrated in real-time applications and end-to-end systems.
An Anatomy-aware Framework for Automatic Segmentation of Parotid Tumor from Multimodal MRI
Oct 04, 2022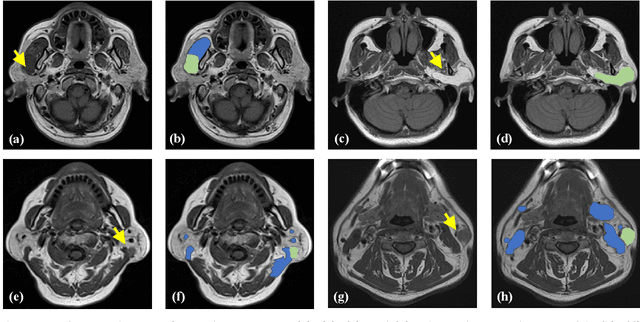

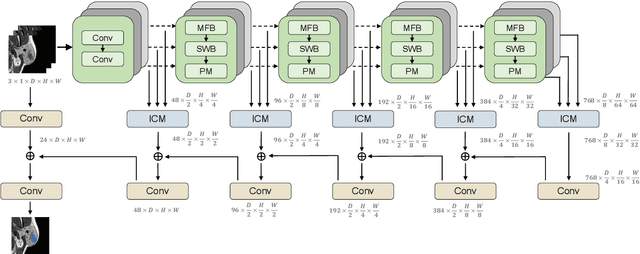

Magnetic Resonance Imaging (MRI) plays an important role in diagnosing the parotid tumor, where accurate segmentation of tumors is highly desired for determining appropriate treatment plans and avoiding unnecessary surgery. However, the task remains nontrivial and challenging due to ambiguous boundaries and various sizes of the tumor, as well as the presence of a large number of anatomical structures around the parotid gland that are similar to the tumor. To overcome these problems, we propose a novel anatomy-aware framework for automatic segmentation of parotid tumors from multimodal MRI. First, a Transformer-based multimodal fusion network PT-Net is proposed in this paper. The encoder of PT-Net extracts and fuses contextual information from three modalities of MRI from coarse to fine, to obtain cross-modality and multi-scale tumor information. The decoder stacks the feature maps of different modalities and calibrates the multimodal information using the channel attention mechanism. Second, considering that the segmentation model is prone to be disturbed by similar anatomical structures and make wrong predictions, we design anatomy-aware loss. By calculating the distance between the activation regions of the prediction segmentation and the ground truth, our loss function forces the model to distinguish similar anatomical structures with the tumor and make correct predictions. Extensive experiments with MRI scans of the parotid tumor showed that our PT-Net achieved higher segmentation accuracy than existing networks. The anatomy-aware loss outperformed state-of-the-art loss functions for parotid tumor segmentation. Our framework can potentially improve the quality of preoperative diagnosis and surgery planning of parotid tumors.