 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Locate Visual Answer in Video Corpus Using Question
Oct 11, 2022
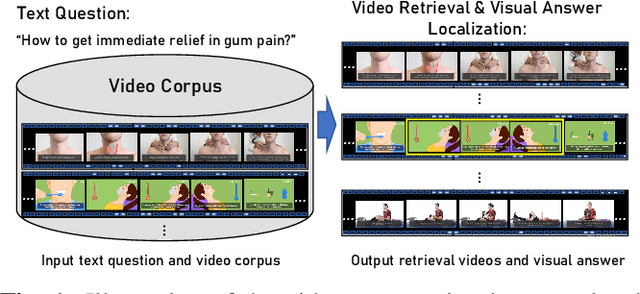
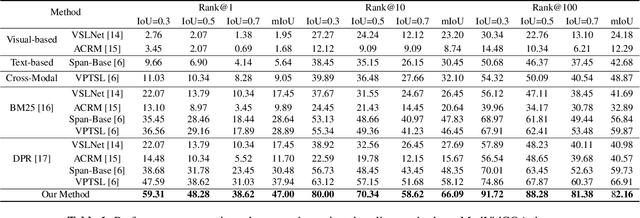
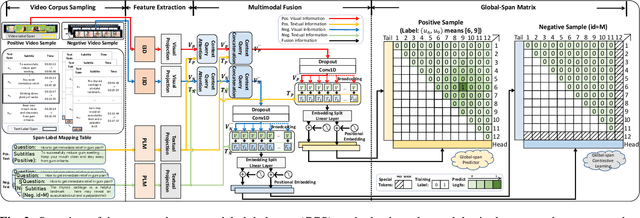

We introduce a novel task, named video corpus visual answer localization (VCVAL), which aims to locate the visual answer in a large collection of untrimmed, unsegmented instructional videos using a natural language question. This task requires a range of skills - the interaction between vision and language, video retrieval, passage comprehension, and visual answer localization. To solve these, we propose a cross-modal contrastive global-span (CCGS) method for the VCVAL, jointly training the video corpus retrieval and visual answer localization tasks. More precisely, we enhance the video question-answer semantic by adding element-wise visual information into the pre-trained language model, and designing a novel global-span predictor through fusion information to locate the visual answer point. The Global-span contrastive learning is adopted to differentiate the span point in the positive and negative samples with the global-span matrix. We have reconstructed a new dataset named MedVidCQA and benchmarked the VCVAL task, where the proposed method achieves state-of-the-art (SOTA) both in the video corpus retrieval and visual answer localization tasks. Most importantly, we pave a new path for understanding the instructional videos, performing detailed analyses on extensive experiments, which ushers in further research.
SEE-Few: Seed, Expand and Entail for Few-shot Named Entity Recognition
Oct 11, 2022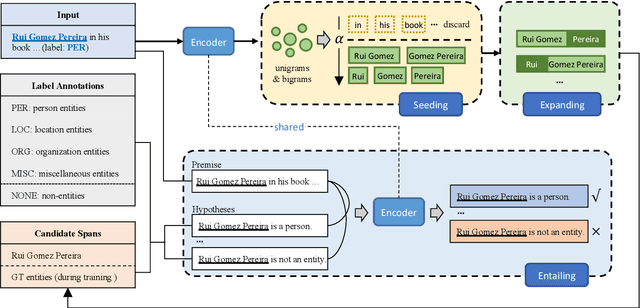
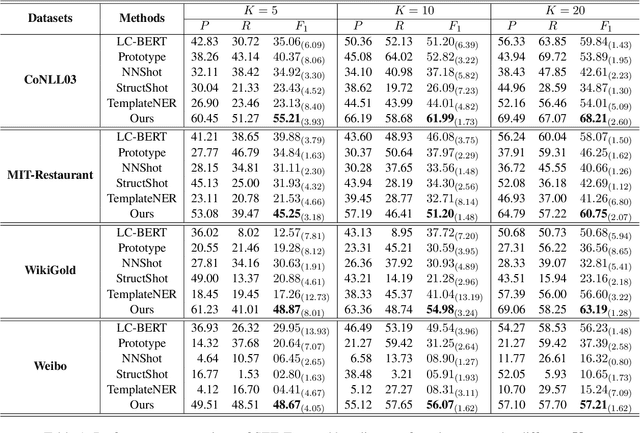
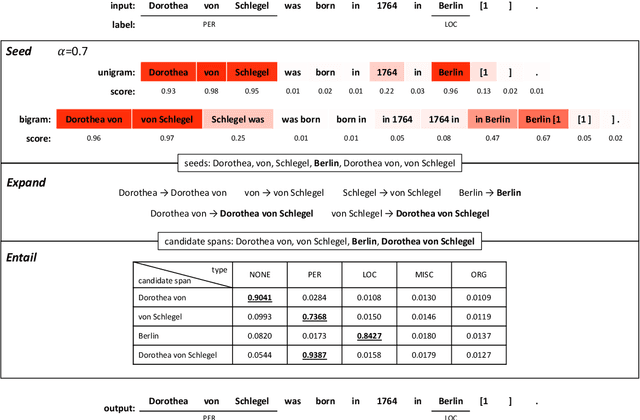
Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Current few-shot NER methods focus on leveraging existing datasets in the rich-resource domains which might fail in a training-from-scratch setting where no source-domain data is used. To tackle training-from-scratch setting, it is crucial to make full use of the annotation information (the boundaries and entity types). Therefore, in this paper, we propose a novel multi-task (Seed, Expand and Entail) learning framework, SEE-Few, for Few-shot NER without using source domain data. The seeding and expanding modules are responsible for providing as accurate candidate spans as possible for the entailing module. The entailing module reformulates span classification as a textual entailment task, leveraging both the contextual clues and entity type information. All the three modules share the same text encoder and are jointly learned. Experimental results on four benchmark datasets under the training-from-scratch setting show that the proposed method outperformed state-of-the-art few-shot NER methods with a large margin. Our code is available at \url{https://github.com/unveiled-the-red-hat/SEE-Few}.
MFCCA:Multi-Frame Cross-Channel attention for multi-speaker ASR in Multi-party meeting scenario
Oct 11, 2022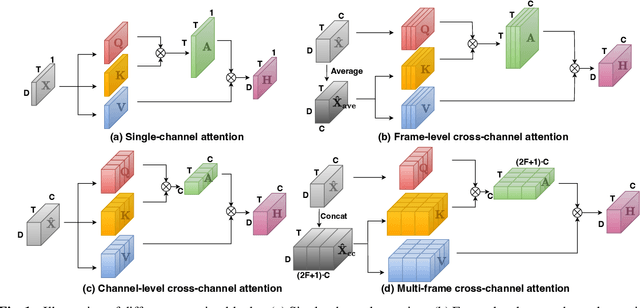
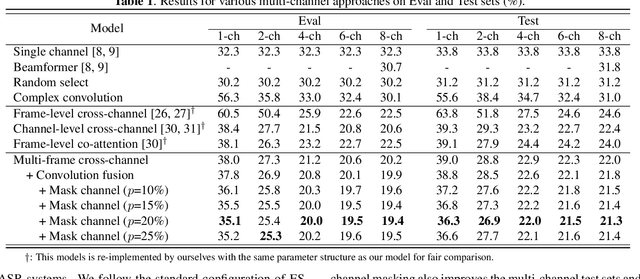
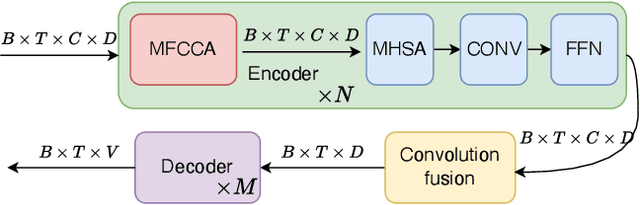
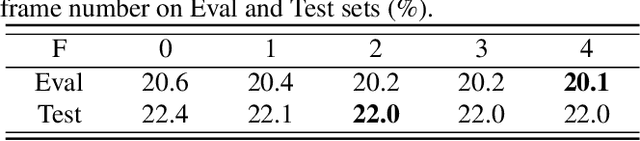
Recently cross-channel attention, which better leverages multi-channel signals from microphone array, has shown promising results in the multi-party meeting scenario. Cross-channel attention focuses on either learning global correlations between sequences of different channels or exploiting fine-grained channel-wise information effectively at each time step. Considering the delay of microphone array receiving sound, we propose a multi-frame cross-channel attention, which models cross-channel information between adjacent frames to exploit the complementarity of both frame-wise and channel-wise knowledge. Besides, we also propose a multi-layer convolutional mechanism to fuse the multi-channel output and a channel masking strategy to combat the channel number mismatch problem between training and inference. Experiments on the AliMeeting, a real-world corpus, reveal that our proposed model outperforms single-channel model by 31.7\% and 37.0\% CER reduction on Eval and Test sets. Moreover, with comparable model parameters and training data, our proposed model achieves a new SOTA performance on the AliMeeting corpus, as compared with the top ranking systems in the ICASSP2022 M2MeT challenge, a recently held multi-channel multi-speaker ASR challenge.
Empowering the Fact-checkers! Automatic Identification of Claim Spans on Twitter
Oct 11, 2022
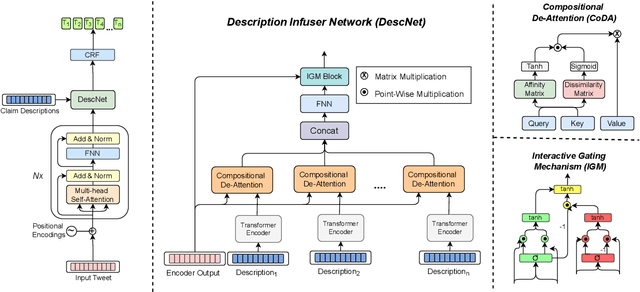
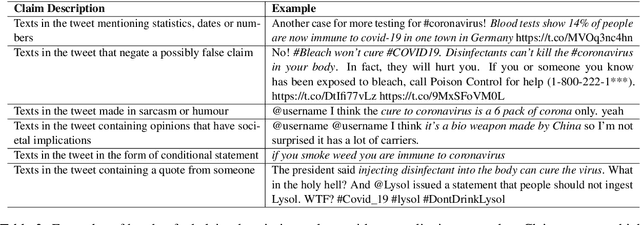
The widespread diffusion of medical and political claims in the wake of COVID-19 has led to a voluminous rise in misinformation and fake news. The current vogue is to employ manual fact-checkers to efficiently classify and verify such data to combat this avalanche of claim-ridden misinformation. However, the rate of information dissemination is such that it vastly outpaces the fact-checkers' strength. Therefore, to aid manual fact-checkers in eliminating the superfluous content, it becomes imperative to automatically identify and extract the snippets of claim-worthy (mis)information present in a post. In this work, we introduce the novel task of Claim Span Identification (CSI). We propose CURT, a large-scale Twitter corpus with token-level claim spans on more than 7.5k tweets. Furthermore, along with the standard token classification baselines, we benchmark our dataset with DABERTa, an adapter-based variation of RoBERTa. The experimental results attest that DABERTa outperforms the baseline systems across several evaluation metrics, improving by about 1.5 points. We also report detailed error analysis to validate the model's performance along with the ablation studies. Lastly, we release our comprehensive span annotation guidelines for public use.
Toward Reliable Neural Specifications
Nov 14, 2022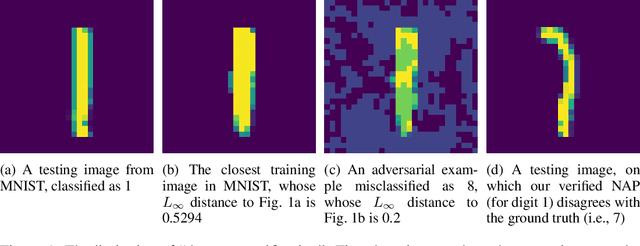


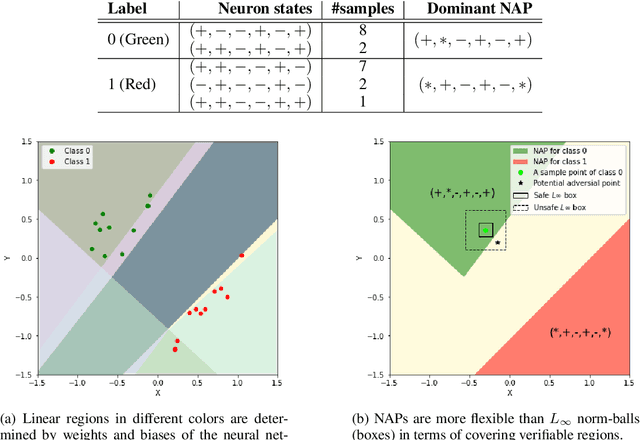
Having reliable specifications is an unavoidable challenge in achieving verifiable correctness, robustness, and interpretability of AI systems. Existing specifications for neural networks are in the paradigm of data as specification. That is, the local neighborhood centering around a reference input is considered to be correct (or robust). However, our empirical study shows that such a specification is extremely overfitted since usually no data points from the testing set lie in the certified region of the reference input, making them impractical for real-world applications. We propose a new family of specifications called neural representation as specification, which uses the intrinsic information of neural networks - neural activation patterns (NAP), rather than input data to specify the correctness and/or robustness of neural network predictions. We present a simple statistical approach to mining dominant neural activation patterns. We analyze NAPs from a statistical point of view and find that a single NAP can cover a large number of training and testing data points whereas ad hoc data-as-specification only covers the given reference data point. To show the effectiveness of discovered NAPs, we formally verify several important properties, such as various types of misclassifications will never happen for a given NAP, and there is no-ambiguity between different NAPs. We show that by using NAP, we can verify the prediction of the entire input space, while still recalling 84% of the data. Thus, we argue that using NAPs is a more reliable and extensible specification for neural network verification.
Feature Correlation-guided Knowledge Transfer for Federated Self-supervised Learning
Nov 14, 2022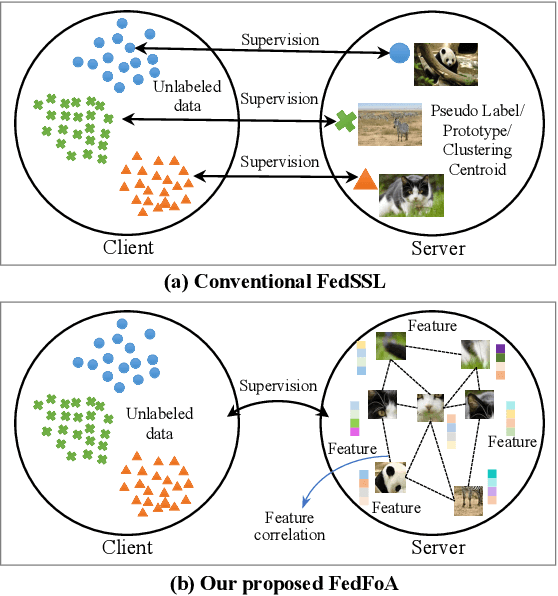
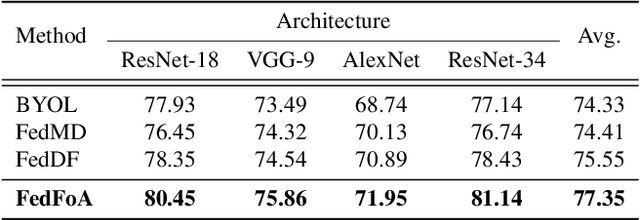
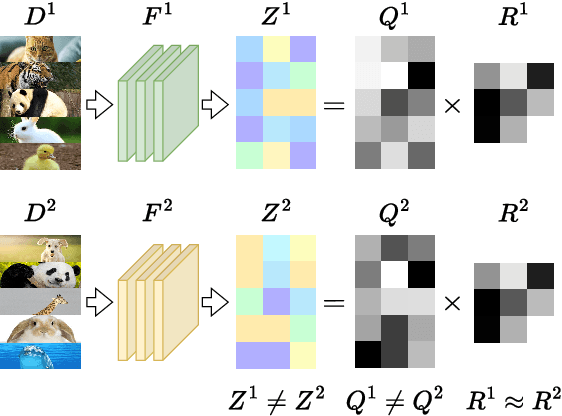
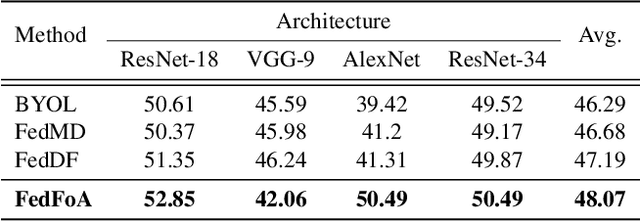
To eliminate the requirement of fully-labeled data for supervised model training in traditional Federated Learning (FL), extensive attention has been paid to the application of Self-supervised Learning (SSL) approaches on FL to tackle the label scarcity problem. Previous works on Federated SSL generally fall into two categories: parameter-based model aggregation (i.e., FedAvg, applicable to homogeneous cases) or data-based feature sharing (i.e., knowledge distillation, applicable to heterogeneous cases) to achieve knowledge transfer among multiple unlabeled clients. Despite the progress, all of them inevitably rely on some assumptions, such as homogeneous models or the existence of an additional public dataset, which hinder the universality of the training frameworks for more general scenarios. Therefore, in this paper, we propose a novel and general method named Federated Self-supervised Learning with Feature-correlation based Aggregation (FedFoA) to tackle the above limitations in a communication-efficient and privacy-preserving manner. Our insight is to utilize feature correlation to align the feature mappings and calibrate the local model updates across clients during their local training process. More specifically, we design a factorization-based method to extract the cross-feature relation matrix from the local representations. Then, the relation matrix can be regarded as a carrier of semantic information to perform the aggregation phase. We prove that FedFoA is a model-agnostic training framework and can be easily compatible with state-of-the-art unsupervised FL methods. Extensive empirical experiments demonstrate that our proposed approach outperforms the state-of-the-art methods by a significant margin.
Bayesian Reconstruction and Differential Testing of Excised mRNA
Nov 14, 2022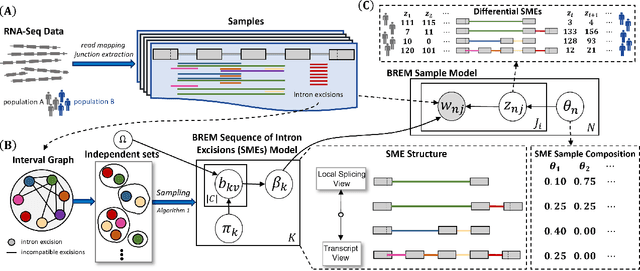
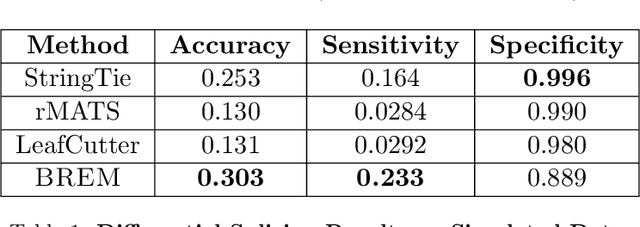

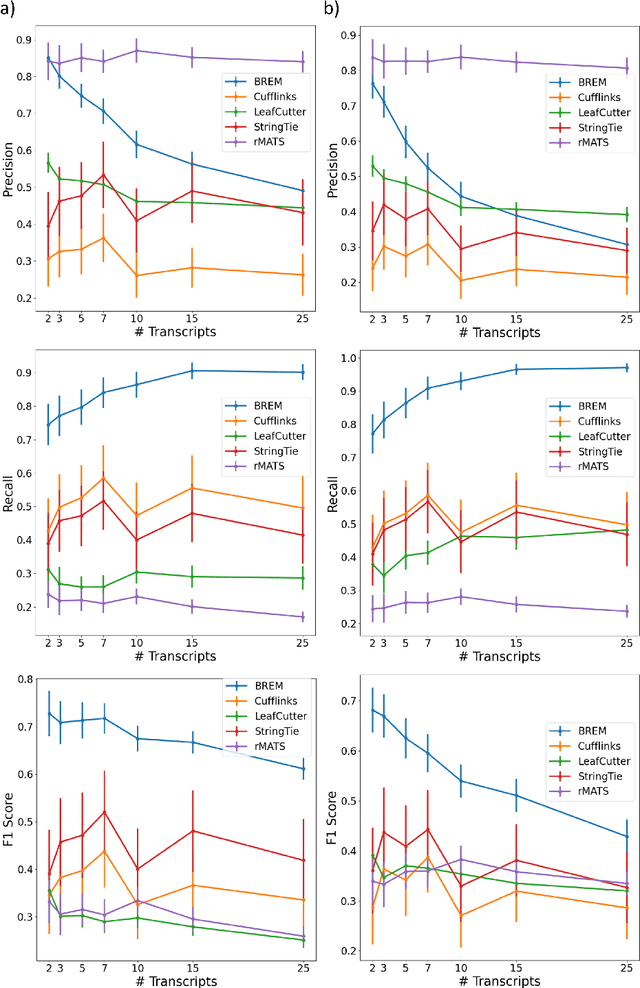
Characterizing the differential excision of mRNA is critical for understanding the functional complexity of a cell or tissue, from normal developmental processes to disease pathogenesis. Most transcript reconstruction methods infer full-length transcripts from high-throughput sequencing data. However, this is a challenging task due to incomplete annotations and the differential expression of transcripts across cell-types, tissues, and experimental conditions. Several recent methods circumvent these difficulties by considering local splicing events, but these methods lose transcript-level splicing information and may conflate transcripts. We develop the first probabilistic model that reconciles the transcript and local splicing perspectives. First, we formalize the sequence of mRNA excisions (SME) reconstruction problem, which aims to assemble variable-length sequences of mRNA excisions from RNA-sequencing data. We then present a novel hierarchical Bayesian admixture model for the Reconstruction of Excised mRNA (BREM). BREM interpolates between local splicing events and full-length transcripts and thus focuses only on SMEs that have high posterior probability. We develop posterior inference algorithms based on Gibbs sampling and local search of independent sets and characterize differential SME usage using generalized linear models based on converged BREM model parameters. We show that BREM achieves higher F1 score for reconstruction tasks and improved accuracy and sensitivity in differential splicing when compared with four state-of-the-art transcript and local splicing methods on simulated data. Lastly, we evaluate BREM on both bulk and scRNA sequencing data based on transcript reconstruction, novelty of transcripts produced, model sensitivity to hyperparameters, and a functional analysis of differentially expressed SMEs, demonstrating that BREM captures relevant biological signal.
Motif-guided Time Series Counterfactual Explanations
Nov 08, 2022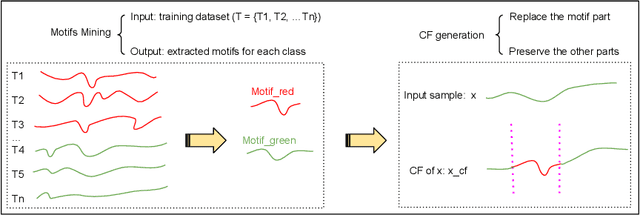
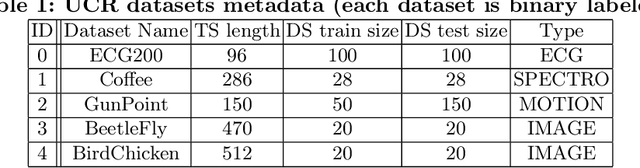
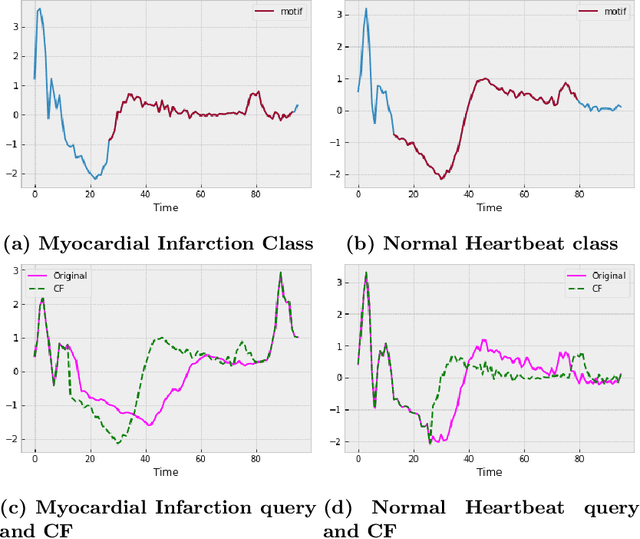
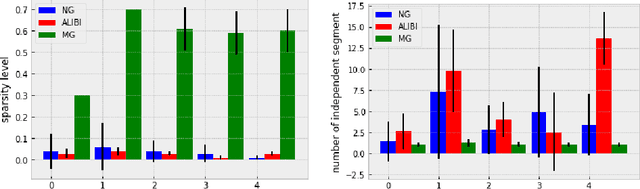
With the rising need of interpretable machine learning methods, there is a necessity for a rise in human effort to provide diverse explanations of the influencing factors of the model decisions. To improve the trust and transparency of AI-based systems, the EXplainable Artificial Intelligence (XAI) field has emerged. The XAI paradigm is bifurcated into two main categories: feature attribution and counterfactual explanation methods. While feature attribution methods are based on explaining the reason behind a model decision, counterfactual explanation methods discover the smallest input changes that will result in a different decision. In this paper, we aim at building trust and transparency in time series models by using motifs to generate counterfactual explanations. We propose Motif-Guided Counterfactual Explanation (MG-CF), a novel model that generates intuitive post-hoc counterfactual explanations that make full use of important motifs to provide interpretive information in decision-making processes. To the best of our knowledge, this is the first effort that leverages motifs to guide the counterfactual explanation generation. We validated our model using five real-world time-series datasets from the UCR repository. Our experimental results show the superiority of MG-CF in balancing all the desirable counterfactual explanations properties in comparison with other competing state-of-the-art baselines.
Multiple Signal Classification Based Joint Communication and Sensing System
Nov 08, 2022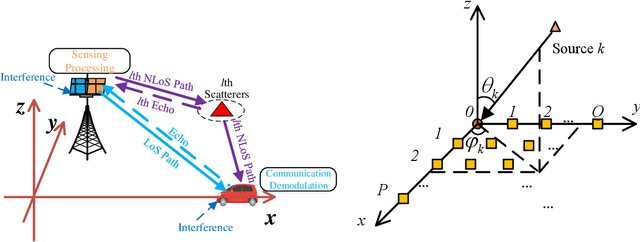
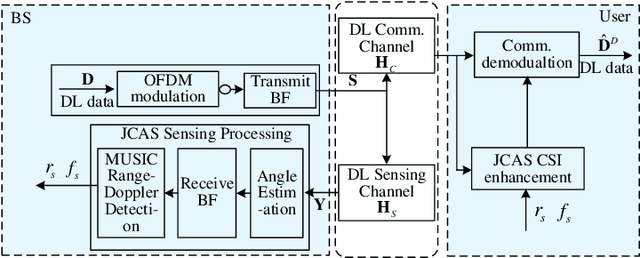
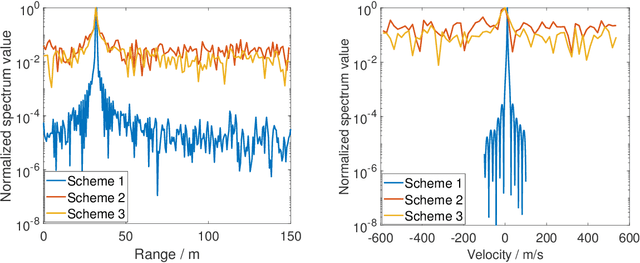
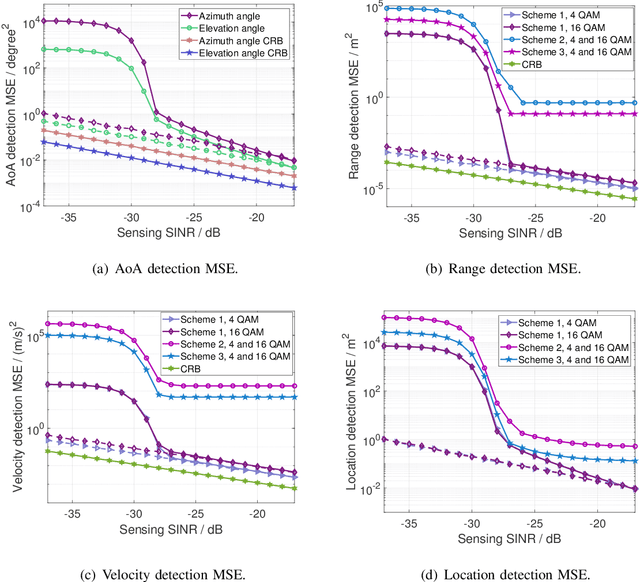
Joint communication and sensing (JCS) has become a promising technology for mobile networks because of its higher spectrum and energy efficiency. Up to now, the prevalent fast Fourier transform (FFT)-based sensing method for mobile JCS networks is on-grid based, and the grid interval determines the resolution. Because the mobile network usually has limited consecutive OFDM symbols in a downlink (DL) time slot, the sensing accuracy is restricted by the limited resolution, especially for velocity estimation. In this paper, we propose a multiple signal classification (MUSIC)-based JCS system that can achieve higher sensing accuracy for the angle of arrival, range, and velocity estimation, compared with the traditional FFT-based JCS method. We further propose a JCS channel state information (CSI) enhancement method by leveraging the JCS sensing results. Finally, we derive a theoretical lower bound for sensing mean square error (MSE) by using perturbation analysis. Simulation results show that in terms of the sensing MSE performance, the proposed MUSIC-based JCS outperforms the FFT-based one by more than 20 dB. Moreover, the bit error rate (BER) of communication demodulation using the proposed JCS CSI enhancement method is significantly reduced compared with communication using the originally estimated CSI.
Downlink and Uplink Cooperative Joint Communication and Sensing
Nov 08, 2022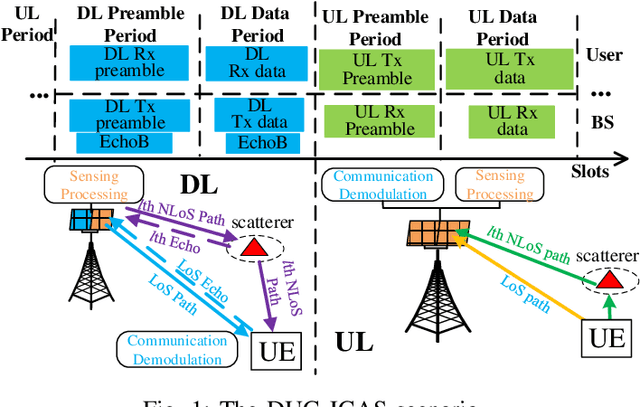
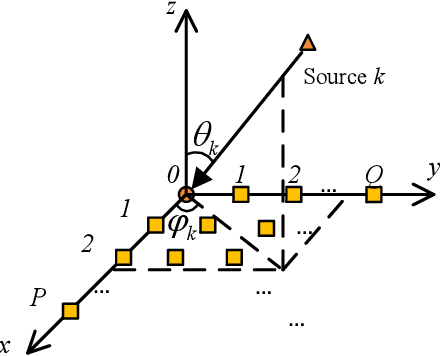
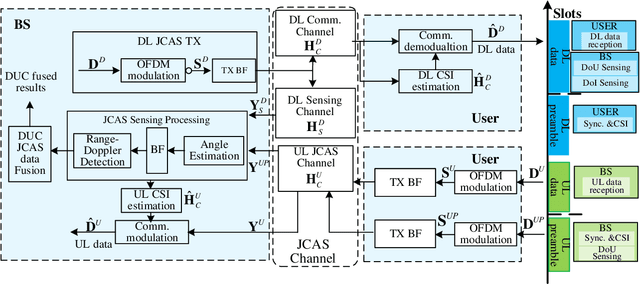
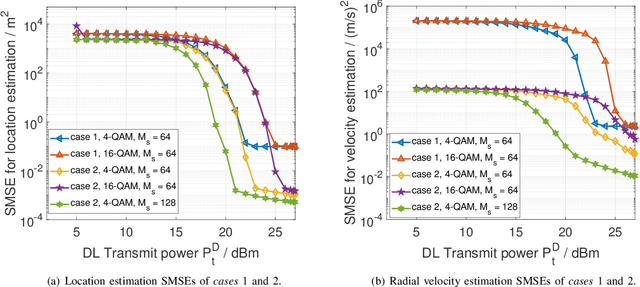
Downlink (DL) and uplink (UL) joint communication and sensing (JCAS) technologies have been individually studied for realizing sensing using DL and UL communication signals, respectively. Since the spatial environment and JCAS channels in the consecutive DL and UL JCAS time slots are generally unchanged, DL and UL JCAS may be jointly designed to achieve better sensing performance. In this paper, we propose a novel DL and UL cooperative (DUC) JCAS scheme, including a unified multiple signal classification (MUSIC)-based JCAS sensing scheme for both DL and UL JCAS and a DUC JCAS fusion method. The unified MUSIC JCAS sensing scheme can accurately estimate AoA, range, and Doppler based on a unified MUSIC-based sensing module. The DUC JCAS fusion method can distinguish between the sensing results of the communication user and other dumb targets. Moreover, by exploiting the channel reciprocity, it can also improve the sensing and channel state information (CSI) estimation accuracy. Extensive simulation results validate the proposed DUC JCAS scheme. It is shown that the minimum location and velocity estimation mean square errors of the proposed DUC JCAS scheme are about 20 dB lower than those of the state-of-the-art separated DL and UL JCAS schemes.