 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Suffix Retrieval-Augmented Language Modeling
Nov 06, 2022
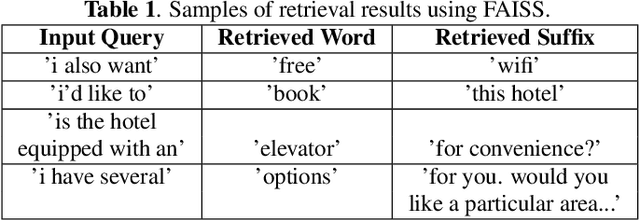
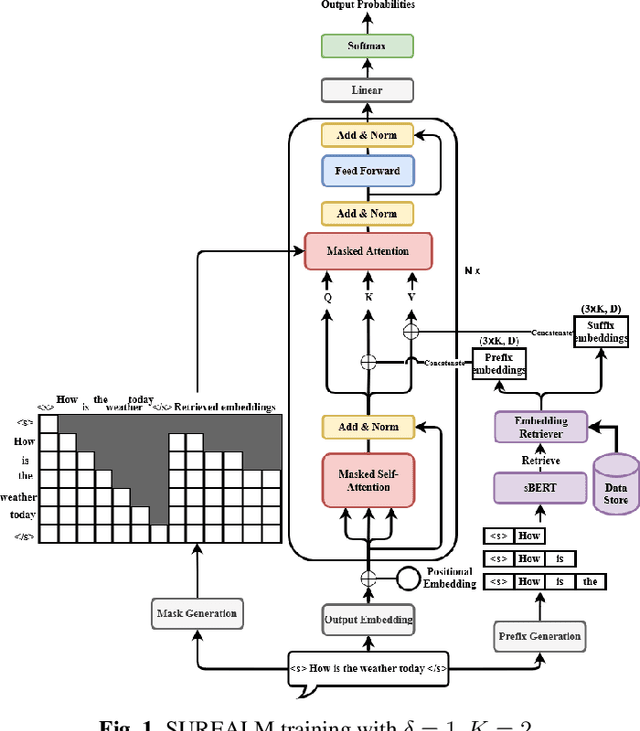
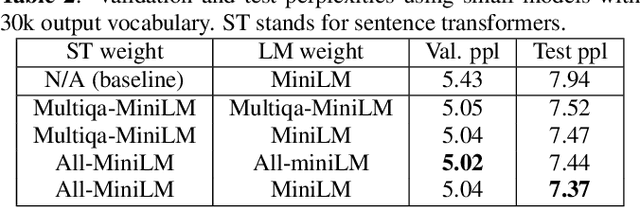

Causal language modeling (LM) uses word history to predict the next word. BERT, on the other hand, makes use of bi-directional word information in a sentence to predict words at masked positions. While BERT is effective in sequence encoding, it is non-causal by nature and is not designed for sequence generation. In this paper, we propose a novel language model, SUffix REtrieval-Augmented LM (SUREALM), that simulates a bi-directional contextual effect in an autoregressive manner. SUREALM employs an embedding retriever to search for training sentences in a data store that share similar word history during sequence generation. In particular, the suffix portions of the retrieved sentences mimick the "future" context. We evaluated our proposed model on the DSTC9 spoken dialogue corpus and showed promising word perplexity reduction on the validation and test set compared to competitive baselines.
Depth Monocular Estimation with Attention-based Encoder-Decoder Network from Single Image
Oct 24, 2022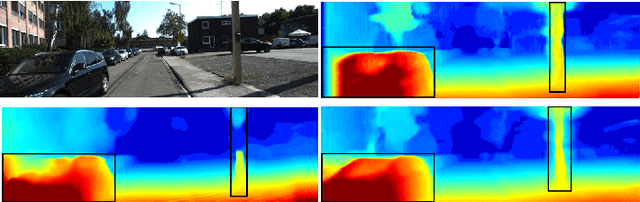
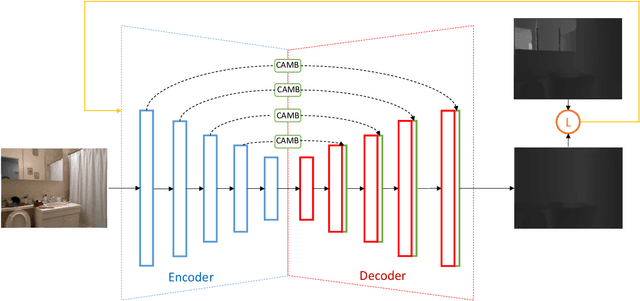
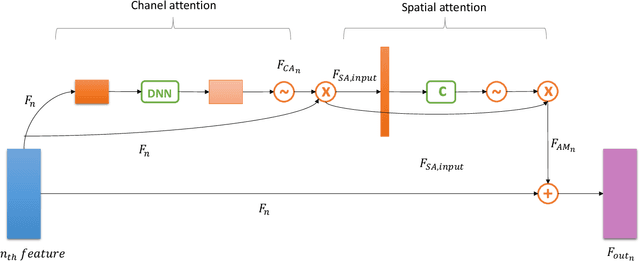
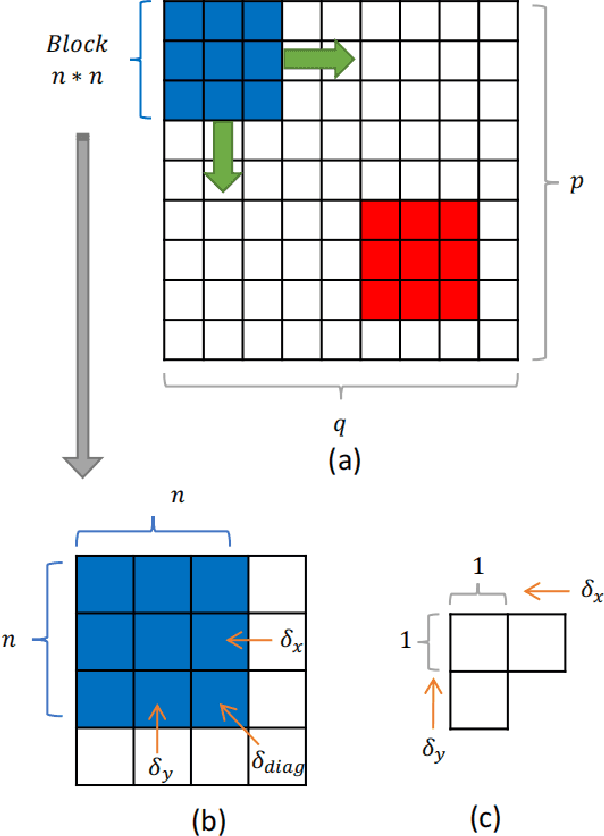
Depth information is the foundation of perception, essential for autonomous driving, robotics, and other source-constrained applications. Promptly obtaining accurate and efficient depth information allows for a rapid response in dynamic environments. Sensor-based methods using LIDAR and RADAR obtain high precision at the cost of high power consumption, price, and volume. While due to advances in deep learning, vision-based approaches have recently received much attention and can overcome these drawbacks. In this work, we explore an extreme scenario in vision-based settings: estimate a depth map from one monocular image severely plagued by grid artifacts and blurry edges. To address this scenario, We first design a convolutional attention mechanism block (CAMB) which consists of channel attention and spatial attention sequentially and insert these CAMBs into skip connections. As a result, our novel approach can find the focus of current image with minimal overhead and avoid losses of depth features. Next, by combining the depth value, the gradients of X axis, Y axis and diagonal directions, and the structural similarity index measure (SSIM), we propose our novel loss function. Moreover, we utilize pixel blocks to accelerate the computation of the loss function. Finally, we show, through comprehensive experiments on two large-scale image datasets, i.e. KITTI and NYU-V2, that our method outperforms several representative baselines.
Modelling Quantum Channels Carrying Classical Information
Dec 05, 2021We use the concept of coupled quantum harmonic oscillators to model the propagation environment in which a quantum link carrying either classical or quantum information operates. Using the analogy between the paraxial optical wave equation and the stationary Schrodinger equation and applying the Caldirola-Kanai Hamiltonian for solving the time-dependent Schrodinger equation; we calculate the propagation field strength and the corresponding average received signal energy.
Multi-view Local Co-occurrence and Global Consistency Learning Improve Mammogram Classification Generalisation
Sep 21, 2022When analysing screening mammograms, radiologists can naturally process information across two ipsilateral views of each breast, namely the cranio-caudal (CC) and mediolateral-oblique (MLO) views. These multiple related images provide complementary diagnostic information and can improve the radiologist's classification accuracy. Unfortunately, most existing deep learning systems, trained with globally-labelled images, lack the ability to jointly analyse and integrate global and local information from these multiple views. By ignoring the potentially valuable information present in multiple images of a screening episode, one limits the potential accuracy of these systems. Here, we propose a new multi-view global-local analysis method that mimics the radiologist's reading procedure, based on a global consistency learning and local co-occurrence learning of ipsilateral views in mammograms. Extensive experiments show that our model outperforms competing methods, in terms of classification accuracy and generalisation, on a large-scale private dataset and two publicly available datasets, where models are exclusively trained and tested with global labels.
Designing Efficient Pair-Trading Strategies Using Cointegration for the Indian Stock Market
Nov 14, 2022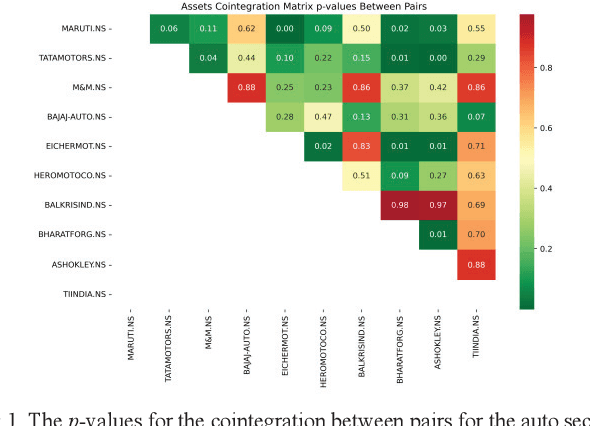
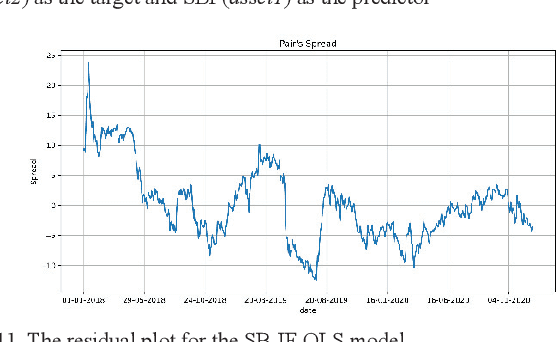
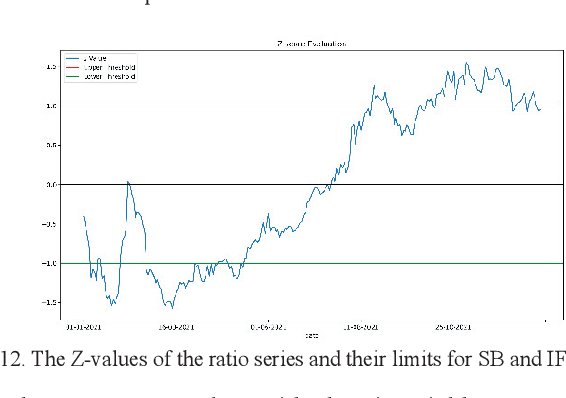
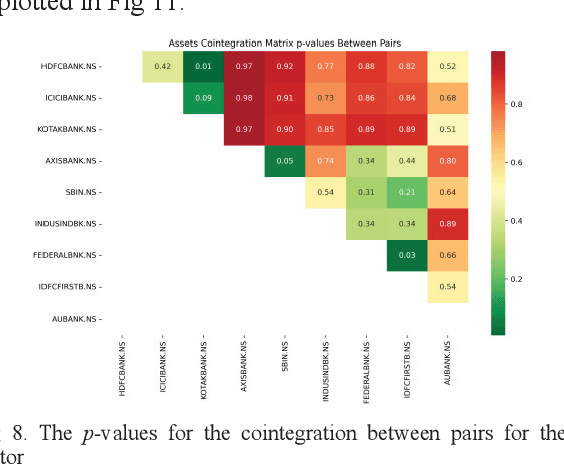
A pair-trading strategy is an approach that utilizes the fluctuations between prices of a pair of stocks in a short-term time frame, while in the long-term the pair may exhibit a strong association and co-movement pattern. When the prices of the stocks exhibit significant divergence, the shares of the stock that gains in price are sold (a short strategy) while the shares of the other stock whose price falls are bought (a long strategy). This paper presents a cointegration-based approach that identifies stocks listed in the five sectors of the National Stock Exchange (NSE) of India for designing efficient pair-trading portfolios. Based on the stock prices from Jan 1, 2018, to Dec 31, 2020, the cointegrated stocks are identified and the pairs are formed. The pair-trading portfolios are evaluated on their annual returns for the year 2021. The results show that the pairs of stocks from the auto and the realty sectors, in general, yielded the highest returns among the five sectors studied in the work. However, two among the five pairs from the information technology (IT) sector are found to have yielded negative returns.
SA-DPSGD: Differentially Private Stochastic Gradient Descent based on Simulated Annealing
Nov 14, 2022
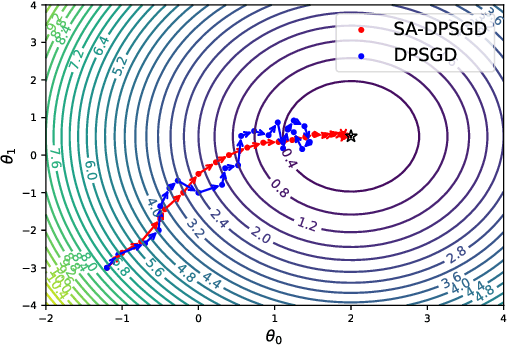

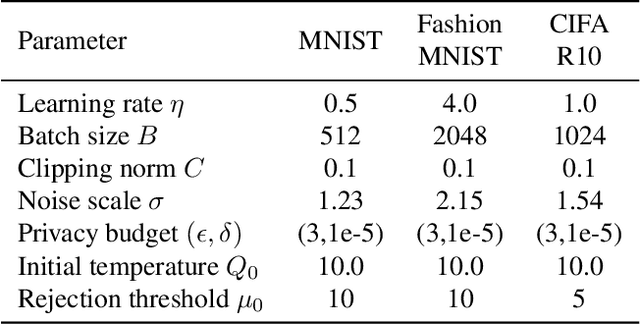
Differential privacy (DP) provides a formal privacy guarantee that prevents adversaries with access to machine learning models from extracting information about individual training points. Differentially private stochastic gradient descent (DPSGD) is the most popular training method with differential privacy in image recognition. However, existing DPSGD schemes lead to significant performance degradation, which prevents the application of differential privacy. In this paper, we propose a simulated annealing-based differentially private stochastic gradient descent scheme (SA-DPSGD) which accepts a candidate update with a probability that depends both on the update quality and on the number of iterations. Through this random update screening, we make the differentially private gradient descent proceed in the right direction in each iteration, and result in a more accurate model finally. In our experiments, under the same hyperparameters, our scheme achieves test accuracies 98.35%, 87.41% and 60.92% on datasets MNIST, FashionMNIST and CIFAR10, respectively, compared to the state-of-the-art result of 98.12%, 86.33% and 59.34%. Under the freely adjusted hyperparameters, our scheme achieves even higher accuracies, 98.89%, 88.50% and 64.17%. We believe that our method has a great contribution for closing the accuracy gap between private and non-private image classification.
C3: Cross-instance guided Contrastive Clustering
Nov 14, 2022
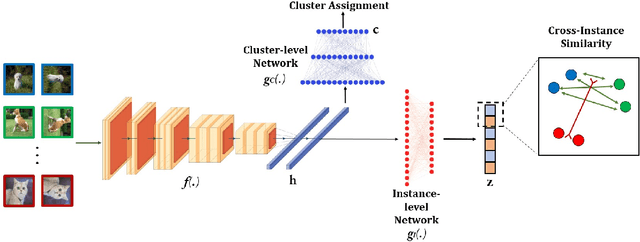
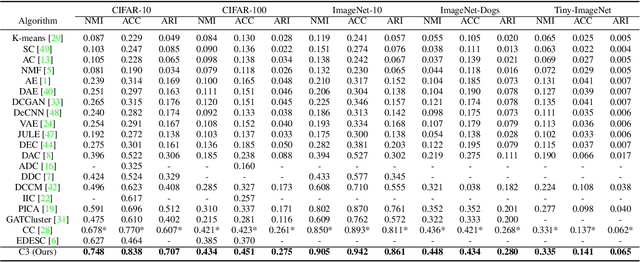
Clustering is the task of gathering similar data samples into clusters without using any predefined labels. It has been widely studied in machine learning literature, and recent advancements in deep learning have revived interest in this field. Contrastive clustering (CC) models are a staple of deep clustering in which positive and negative pairs of each data instance are generated through data augmentation. CC models aim to learn a feature space where instance-level and cluster-level representations of positive pairs are grouped together. Despite improving the SOTA, these algorithms ignore the cross-instance patterns, which carry essential information for improving clustering performance. In this paper, we propose a novel contrastive clustering method, Cross-instance guided Contrastive Clustering (C3), that considers the cross-sample relationships to increase the number of positive pairs. In particular, we define a new loss function that identifies similar instances using the instance-level representation and encourages them to aggregate together. Extensive experimental evaluations show that our proposed method can outperform state-of-the-art algorithms on benchmark computer vision datasets: we improve the clustering accuracy by 6.8%, 2.8%, 4.9%, 1.3% and 0.4% on CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-Dogs, and Tiny-ImageNet, respectively.
Pilot-Aided Distributed Multi-Group Multicast Precoding Design for Cell-Free Massive MIMO
Nov 14, 2022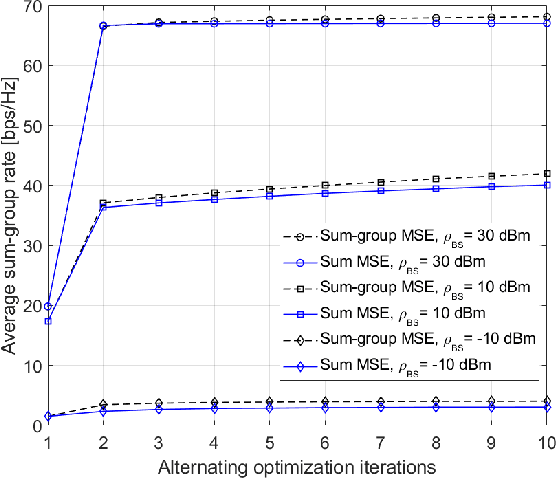
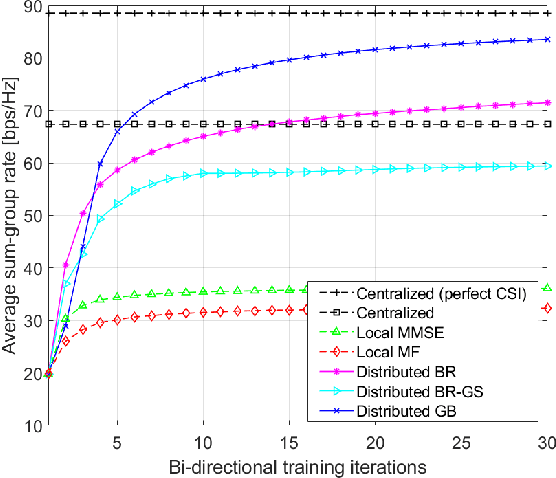
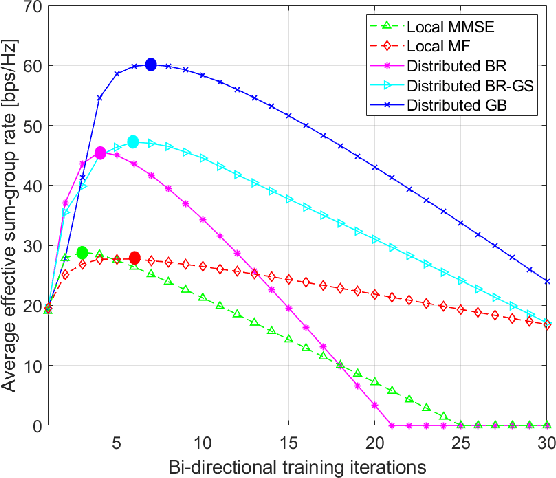
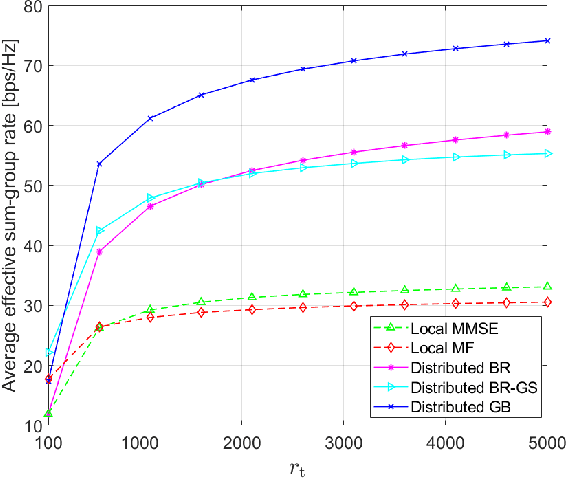
We propose fully distributed multi-group multicast precoding designs for cell-free massive multiple-input multiple-output (MIMO) systems with modest training overhead. We target the minimization of the sum of the maximum mean squared errors (MSEs) over the multicast groups, which is then approximated with a weighted sum MSE minimization to simplify the computation and signaling. To design the joint network-wide multi-group multicast precoders at the base stations (BSs) and the combiners at the user equipments (UEs) in a fully distributed fashion, we adopt an iterative bi-directional training scheme with UE-specific or group-specific precoded uplink pilots and group-specific precoded downlink pilots. To this end, we introduce a new group-specific uplink training resource that entirely eliminates the need for backhaul signaling for the channel state information (CSI) exchange. The precoders are optimized locally at each BS by means of either best-response or gradient-based updates, and the convergence of the two approaches is analyzed with respect to the centralized implementation with perfect CSI. Finally, numerical results show that the proposed distributed methods greatly outperform conventional cell-free massive MIMO precoding designs that rely solely on local CSI.
Label-only Model Inversion Attack: The Attack that Requires the Least Information
Mar 13, 2022
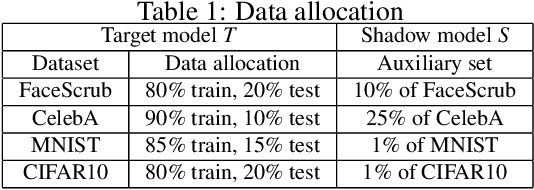
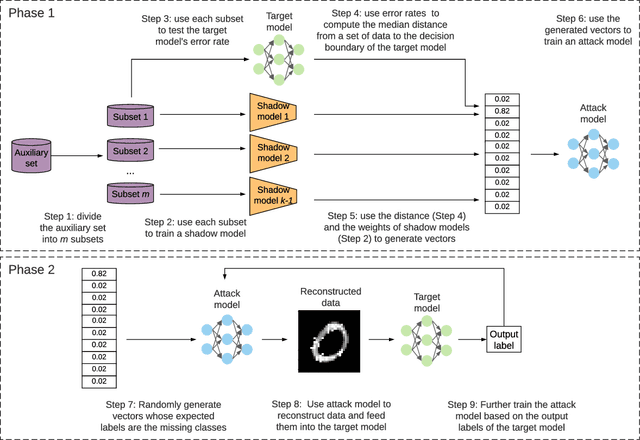
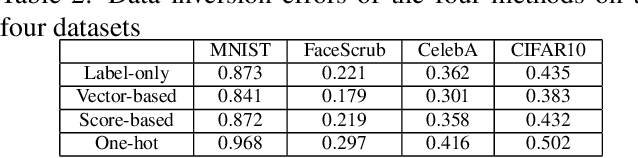
In a model inversion attack, an adversary attempts to reconstruct the data records, used to train a target model, using only the model's output. In launching a contemporary model inversion attack, the strategies discussed are generally based on either predicted confidence score vectors, i.e., black-box attacks, or the parameters of a target model, i.e., white-box attacks. However, in the real world, model owners usually only give out the predicted labels; the confidence score vectors and model parameters are hidden as a defense mechanism to prevent such attacks. Unfortunately, we have found a model inversion method that can reconstruct the input data records based only on the output labels. We believe this is the attack that requires the least information to succeed and, therefore, has the best applicability. The key idea is to exploit the error rate of the target model to compute the median distance from a set of data records to the decision boundary of the target model. The distance, then, is used to generate confidence score vectors which are adopted to train an attack model to reconstruct the data records. The experimental results show that highly recognizable data records can be reconstructed with far less information than existing methods.
Multimodal Contrastive Learning via Uni-Modal Coding and Cross-Modal Prediction for Multimodal Sentiment Analysis
Oct 26, 2022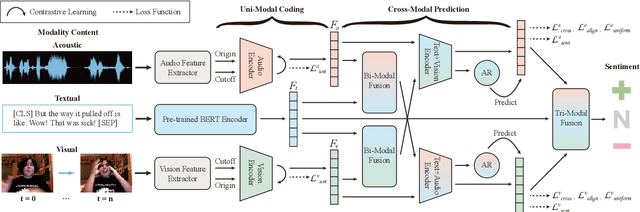
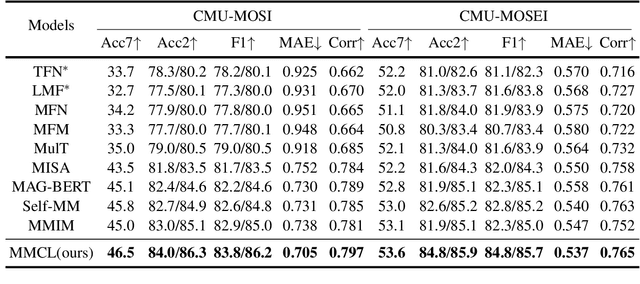
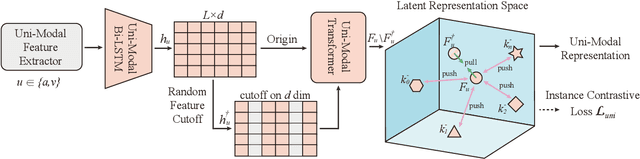
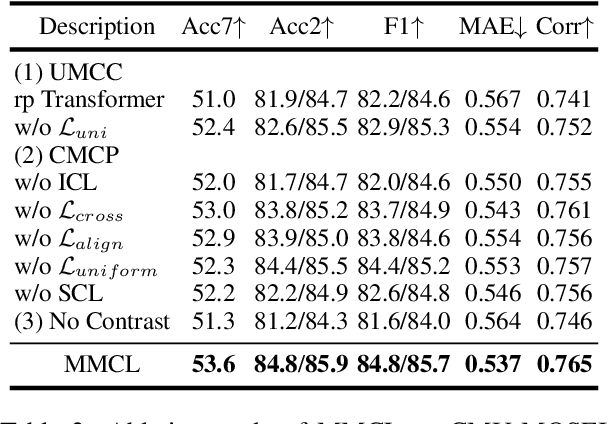
Multimodal representation learning is a challenging task in which previous work mostly focus on either uni-modality pre-training or cross-modality fusion. In fact, we regard modeling multimodal representation as building a skyscraper, where laying stable foundation and designing the main structure are equally essential. The former is like encoding robust uni-modal representation while the later is like integrating interactive information among different modalities, both of which are critical to learning an effective multimodal representation. Recently, contrastive learning has been successfully applied in representation learning, which can be utilized as the pillar of the skyscraper and benefit the model to extract the most important features contained in the multimodal data. In this paper, we propose a novel framework named MultiModal Contrastive Learning (MMCL) for multimodal representation to capture intra- and inter-modality dynamics simultaneously. Specifically, we devise uni-modal contrastive coding with an efficient uni-modal feature augmentation strategy to filter inherent noise contained in acoustic and visual modality and acquire more robust uni-modality representations. Besides, a pseudo siamese network is presented to predict representation across different modalities, which successfully captures cross-modal dynamics. Moreover, we design two contrastive learning tasks, instance- and sentiment-based contrastive learning, to promote the process of prediction and learn more interactive information related to sentiment. Extensive experiments conducted on two public datasets demonstrate that our method surpasses the state-of-the-art methods.