 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From Causal Pairs to Causal Graphs
Nov 08, 2022


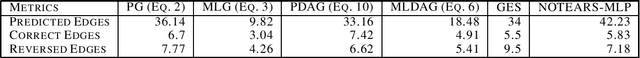

Causal structure learning from observational data remains a non-trivial task due to various factors such as finite sampling, unobserved confounding factors, and measurement errors. Constraint-based and score-based methods tend to suffer from high computational complexity due to the combinatorial nature of estimating the directed acyclic graph (DAG). Motivated by the `Cause-Effect Pair' NIPS 2013 Workshop on Causality Challenge, in this paper, we take a different approach and generate a probability distribution over all possible graphs informed by the cause-effect pair features proposed in response to the workshop challenge. The goal of the paper is to propose new methods based on this probabilistic information and compare their performance with traditional and state-of-the-art approaches. Our experiments, on both synthetic and real datasets, show that our proposed methods not only have statistically similar or better performances than some traditional approaches but also are computationally faster.
Modelling Quantum Channels Carrying Classical Information
Dec 05, 2021We use the concept of coupled quantum harmonic oscillators to model the propagation environment in which a quantum link carrying either classical or quantum information operates. Using the analogy between the paraxial optical wave equation and the stationary Schrodinger equation and applying the Caldirola-Kanai Hamiltonian for solving the time-dependent Schrodinger equation; we calculate the propagation field strength and the corresponding average received signal energy.
3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for V2X Orchestration
Nov 12, 2022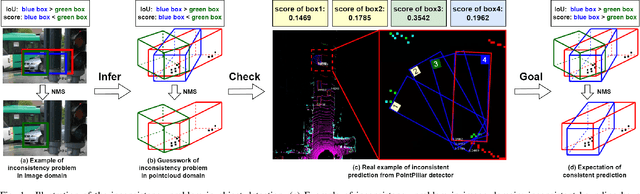

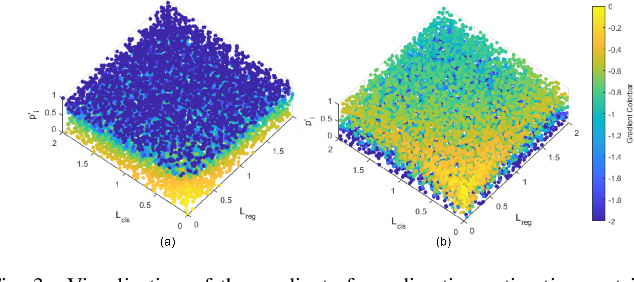
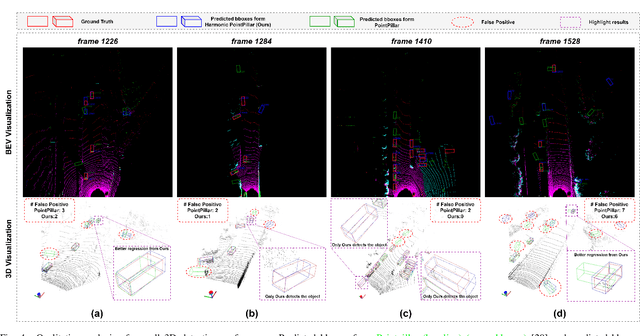
Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency.
Hybrid HMM Decoder For Convolutional Codes By Joint Trellis-Like Structure and Channel Prior
Nov 12, 2022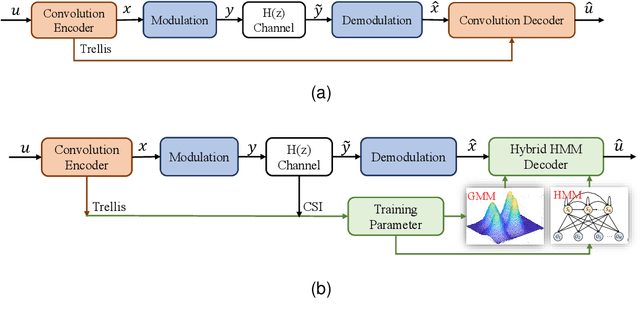
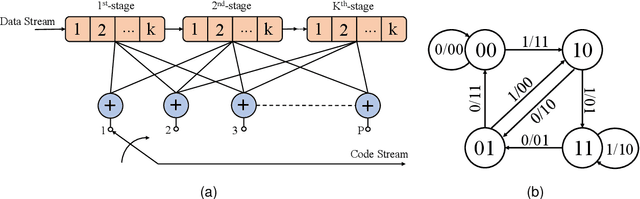
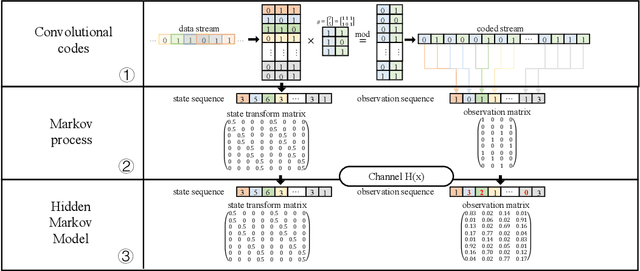
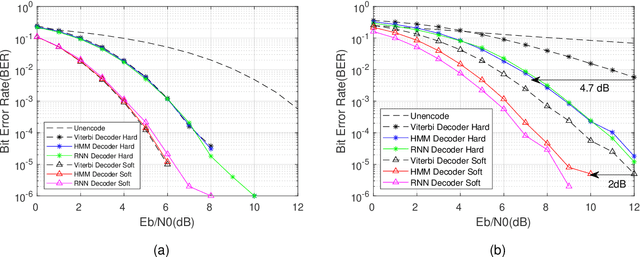
The anti-interference capability of wireless links is a physical layer problem for edge computing. Although convolutional codes have inherent error correction potential due to the redundancy introduced in the data, the performance of the convolutional code is drastically degraded due to multipath effects on the channel. In this paper, we propose the use of a Hidden Markov Model (HMM) for the reconstruction of convolutional codes and decoding by the Viterbi algorithm. Furthermore, to implement soft-decision decoding, the observation of HMM is replaced by Gaussian mixture models (GMM). Our method provides superior error correction potential than the standard method because the model parameters contain channel state information (CSI). We evaluated the performance of the method compared to standard Viterbi decoding by numerical simulation. In the multipath channel, the hybrid HMM decoder can achieve a performance gain of 4.7 dB and 2 dB when using hard-decision and soft-decision decoding, respectively. The HMM decoder also achieves significant performance gains for the RSC code, suggesting that the method could be extended to turbo codes.
* 12 pages, 8 figures
Investigations in Audio Captioning: Addressing Vocabulary Imbalance and Evaluating Suitability of Language-Centric Performance Metrics
Nov 12, 2022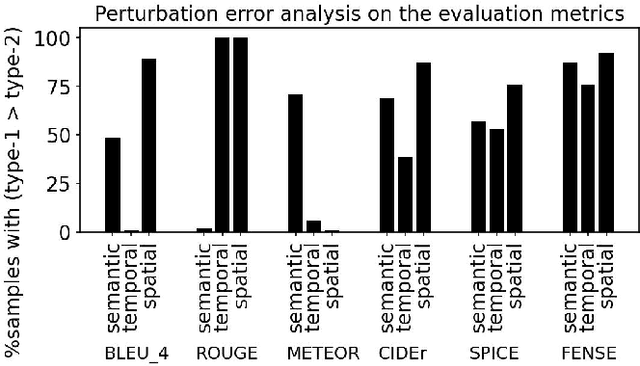
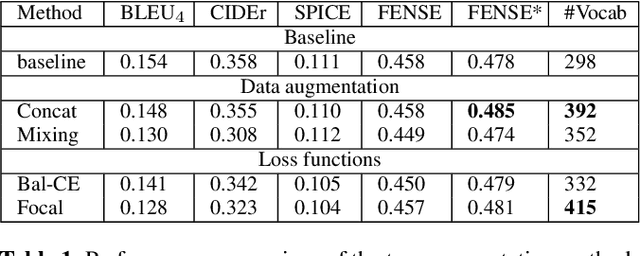
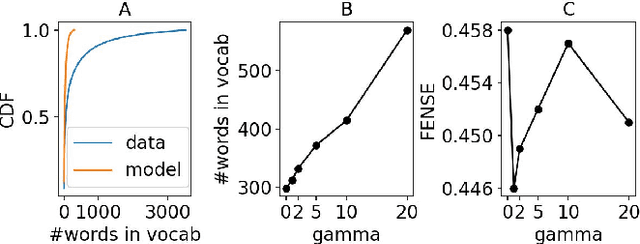
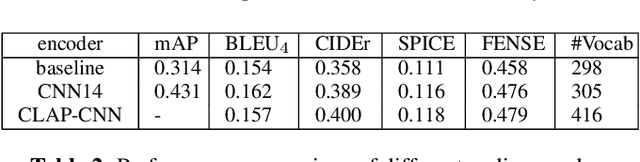
The analysis, processing, and extraction of meaningful information from sounds all around us is the subject of the broader area of audio analytics. Audio captioning is a recent addition to the domain of audio analytics, a cross-modal translation task that focuses on generating natural descriptions from sound events occurring in an audio stream. In this work, we identify and improve on three main challenges in automated audio captioning: i) data scarcity, ii) imbalance or limitations in the audio captions vocabulary, and iii) the proper performance evaluation metric that can best capture both auditory and semantic characteristics. We find that generally adopted loss functions can result in an unfair vocabulary imbalance during model training. We propose two audio captioning augmentation methods that enrich the training dataset and the vocabulary size. We further underline the need for in-domain pretraining by exploring the suitability of audio encoders that were previously trained on different audio tasks. Finally, we systematically explore five performance metrics borrowed from the image captioning domain and highlight their limitations for the audio domain.
A heterogeneous group CNN for image super-resolution
Sep 26, 2022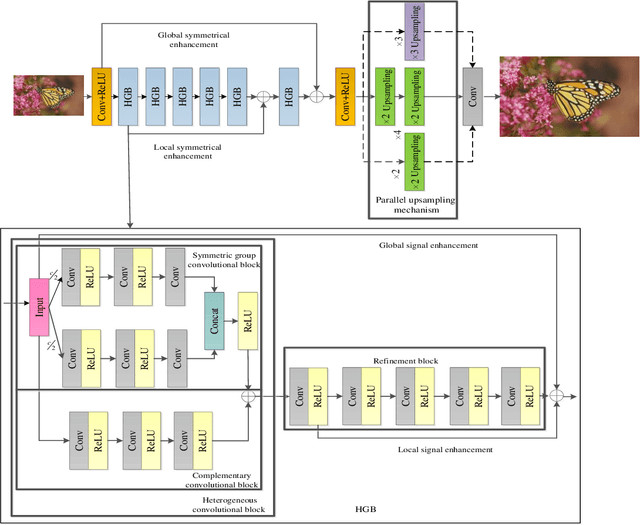
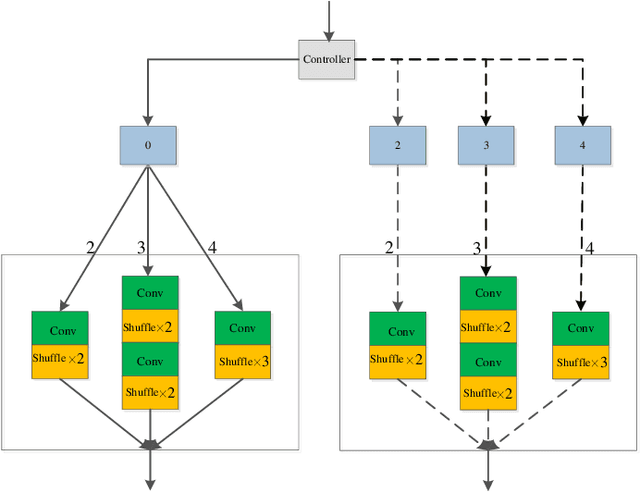


Convolutional neural networks (CNNs) have obtained remarkable performance via deep architectures. However, these CNNs often achieve poor robustness for image super-resolution (SR) under complex scenes. In this paper, we present a heterogeneous group SR CNN (HGSRCNN) via leveraging structure information of different types to obtain a high-quality image. Specifically, each heterogeneous group block (HGB) of HGSRCNN uses a heterogeneous architecture containing a symmetric group convolutional block and a complementary convolutional block in a parallel way to enhance internal and external relations of different channels for facilitating richer low-frequency structure information of different types. To prevent appearance of obtained redundant features, a refinement block with signal enhancements in a serial way is designed to filter useless information. To prevent loss of original information, a multi-level enhancement mechanism guides a CNN to achieve a symmetric architecture for promoting expressive ability of HGSRCNN. Besides, a parallel up-sampling mechanism is developed to train a blind SR model. Extensive experiments illustrate that the proposed HGSRCNN has obtained excellent SR performance in terms of both quantitative and qualitative analysis. Codes can be accessed at https://github.com/hellloxiaotian/HGSRCNN.
Mr. Right: Multimodal Retrieval on Representation of ImaGe witH Text
Sep 28, 2022
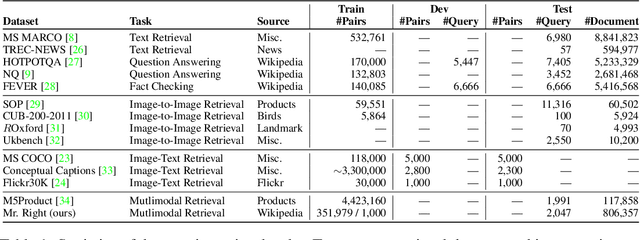
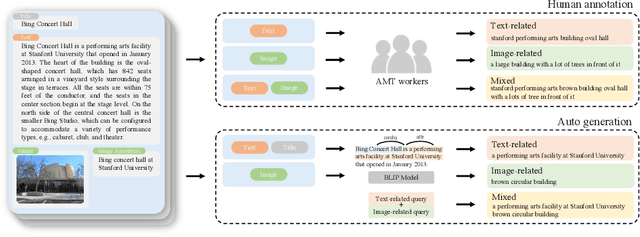
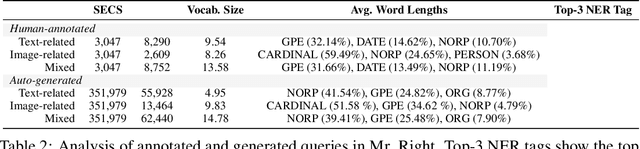
Multimodal learning is a recent challenge that extends unimodal learning by generalizing its domain to diverse modalities, such as texts, images, or speech. This extension requires models to process and relate information from multiple modalities. In Information Retrieval, traditional retrieval tasks focus on the similarity between unimodal documents and queries, while image-text retrieval hypothesizes that most texts contain the scene context from images. This separation has ignored that real-world queries may involve text content, image captions, or both. To address this, we introduce Multimodal Retrieval on Representation of ImaGe witH Text (Mr. Right), a novel and comprehensive dataset for multimodal retrieval. We utilize the Wikipedia dataset with rich text-image examples and generate three types of text-based queries with different modality information: text-related, image-related, and mixed. To validate the effectiveness of our dataset, we provide a multimodal training paradigm and evaluate previous text retrieval and image retrieval frameworks. The results show that proposed multimodal retrieval can improve retrieval performance, but creating a well-unified document representation with texts and images is still a challenge. We hope Mr. Right allows us to broaden current retrieval systems better and contributes to accelerating the advancement of multimodal learning in the Information Retrieval.
Label-only Model Inversion Attack: The Attack that Requires the Least Information
Mar 13, 2022
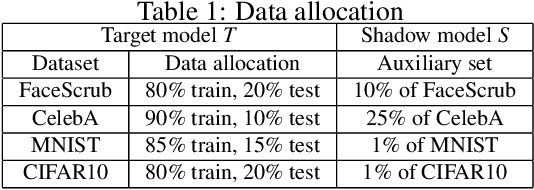
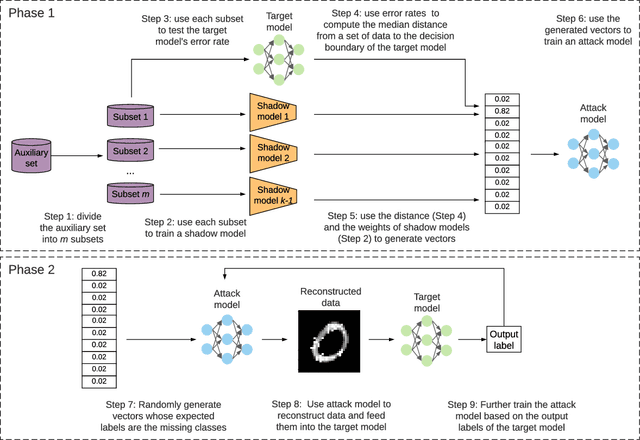
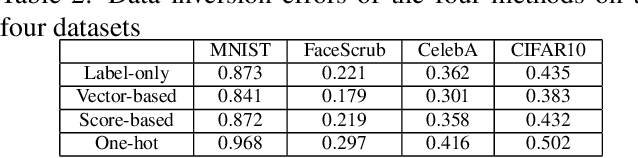
In a model inversion attack, an adversary attempts to reconstruct the data records, used to train a target model, using only the model's output. In launching a contemporary model inversion attack, the strategies discussed are generally based on either predicted confidence score vectors, i.e., black-box attacks, or the parameters of a target model, i.e., white-box attacks. However, in the real world, model owners usually only give out the predicted labels; the confidence score vectors and model parameters are hidden as a defense mechanism to prevent such attacks. Unfortunately, we have found a model inversion method that can reconstruct the input data records based only on the output labels. We believe this is the attack that requires the least information to succeed and, therefore, has the best applicability. The key idea is to exploit the error rate of the target model to compute the median distance from a set of data records to the decision boundary of the target model. The distance, then, is used to generate confidence score vectors which are adopted to train an attack model to reconstruct the data records. The experimental results show that highly recognizable data records can be reconstructed with far less information than existing methods.
SpanProto: A Two-stage Span-based Prototypical Network for Few-shot Named Entity Recognition
Oct 17, 2022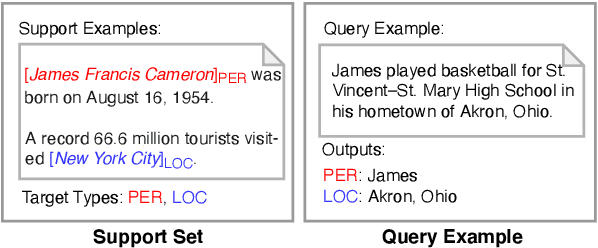
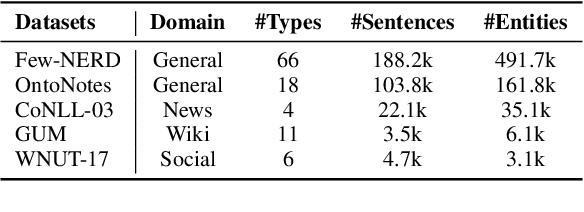
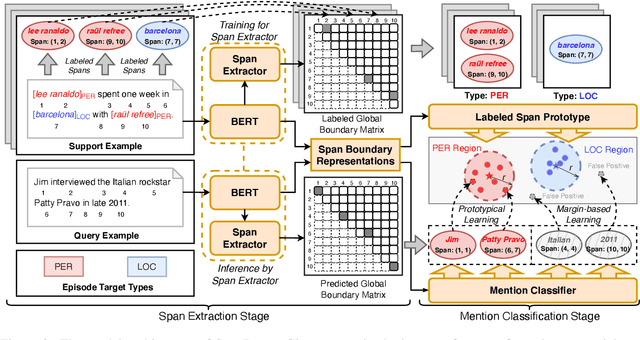
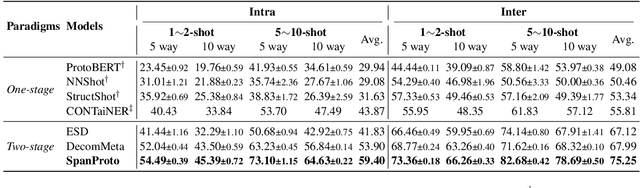
Few-shot Named Entity Recognition (NER) aims to identify named entities with very little annotated data. Previous methods solve this problem based on token-wise classification, which ignores the information of entity boundaries, and inevitably the performance is affected by the massive non-entity tokens. To this end, we propose a seminal span-based prototypical network (SpanProto) that tackles few-shot NER via a two-stage approach, including span extraction and mention classification. In the span extraction stage, we transform the sequential tags into a global boundary matrix, enabling the model to focus on the explicit boundary information. For mention classification, we leverage prototypical learning to capture the semantic representations for each labeled span and make the model better adapt to novel-class entities. To further improve the model performance, we split out the false positives generated by the span extractor but not labeled in the current episode set, and then present a margin-based loss to separate them from each prototype region. Experiments over multiple benchmarks demonstrate that our model outperforms strong baselines by a large margin.
Context-Aware Query Rewriting for Improving Users' Search Experience on E-commerce Websites
Sep 24, 2022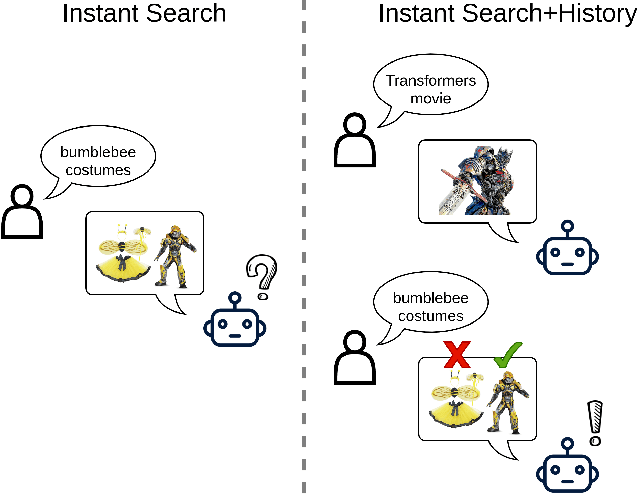
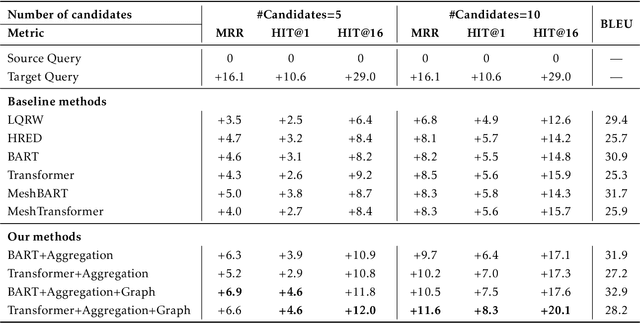
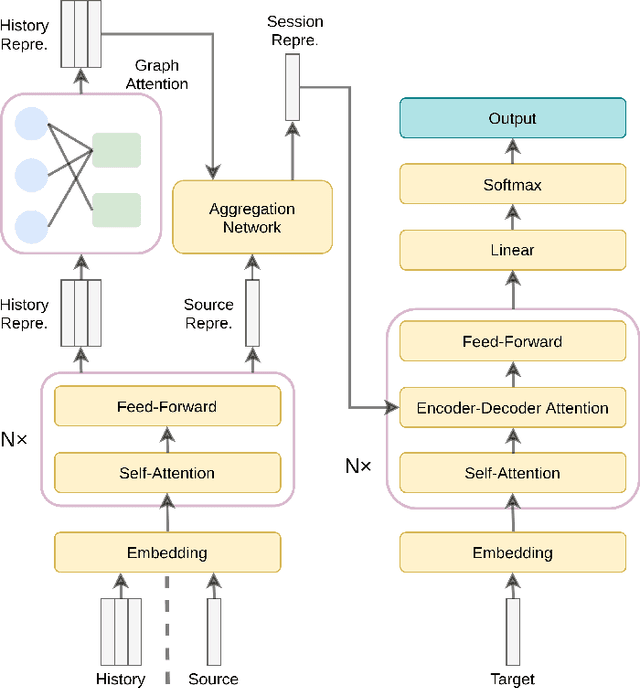
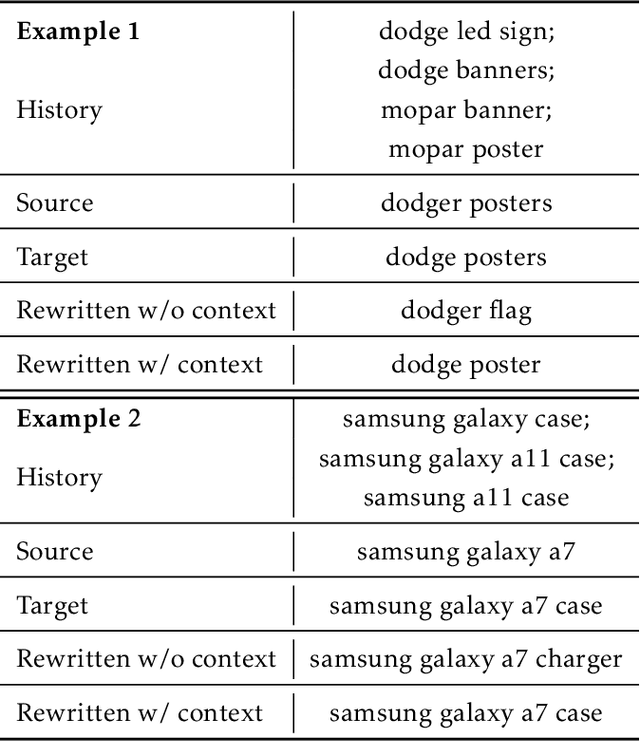
E-commerce queries are often short and ambiguous. Consequently, query understanding often uses query rewriting to disambiguate user-input queries. While using e-commerce search tools, users tend to enter multiple searches, which we call context, before purchasing. These history searches contain contextual insights about users' true shopping intents. Therefore, modeling such contextual information is critical to a better query rewriting model. However, existing query rewriting models ignore users' history behaviors and consider only the instant search query, which is often a short string offering limited information about the true shopping intent. We propose an end-to-end context-aware query rewriting model to bridge this gap, which takes the search context into account. Specifically, our model builds a session graph using the history search queries and their contained words. We then employ a graph attention mechanism that models cross-query relations and computes contextual information of the session. The model subsequently calculates session representations by combining the contextual information with the instant search query using an aggregation network. The session representations are then decoded to generate rewritten queries. Empirically, we demonstrate the superiority of our method to state-of-the-art approaches under various metrics. On in-house data from an online shopping platform, by introducing contextual information, our model achieves 11.6% improvement under the MRR (Mean Reciprocal Rank) metric and 20.1% improvement under the HIT@16 metric (a hit rate metric), in comparison with the best baseline method (Transformer-based model).