 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Object-Category Aware Reinforcement Learning
Oct 13, 2022
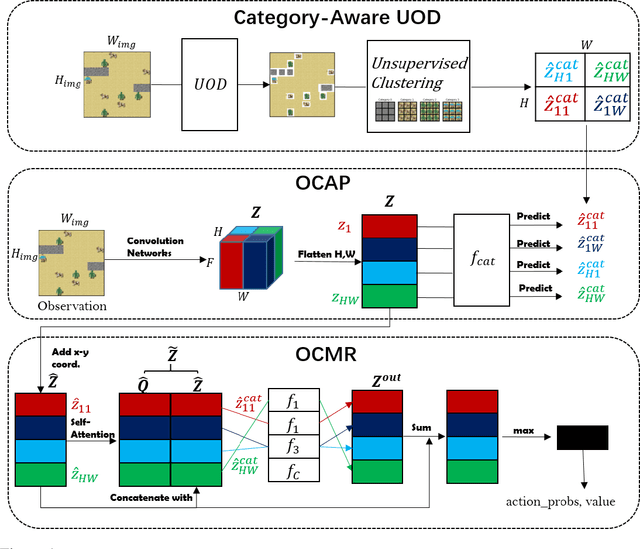

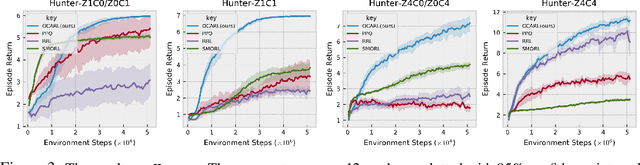

Object-oriented reinforcement learning (OORL) is a promising way to improve the sample efficiency and generalization ability over standard RL. Recent works that try to solve OORL tasks without additional feature engineering mainly focus on learning the object representations and then solving tasks via reasoning based on these object representations. However, none of these works tries to explicitly model the inherent similarity between different object instances of the same category. Objects of the same category should share similar functionalities; therefore, the category is the most critical property of an object. Following this insight, we propose a novel framework named Object-Category Aware Reinforcement Learning (OCARL), which utilizes the category information of objects to facilitate both perception and reasoning. OCARL consists of three parts: (1) Category-Aware Unsupervised Object Discovery (UOD), which discovers the objects as well as their corresponding categories; (2) Object-Category Aware Perception, which encodes the category information and is also robust to the incompleteness of (1) at the same time; (3) Object-Centric Modular Reasoning, which adopts multiple independent and object-category-specific networks when reasoning based on objects. Our experiments show that OCARL can improve both the sample efficiency and generalization in the OORL domain.
Few-Shot Learning for Biometric Verification
Nov 12, 2022
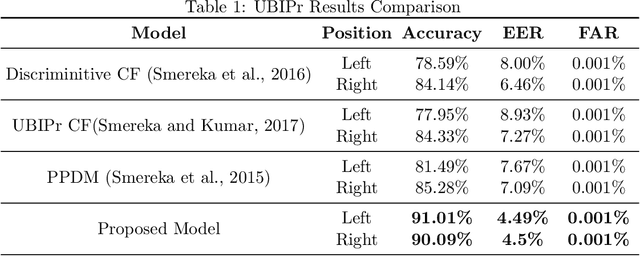
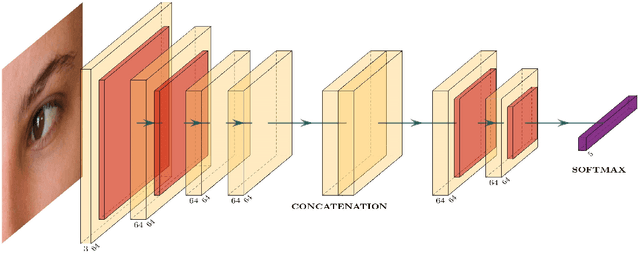
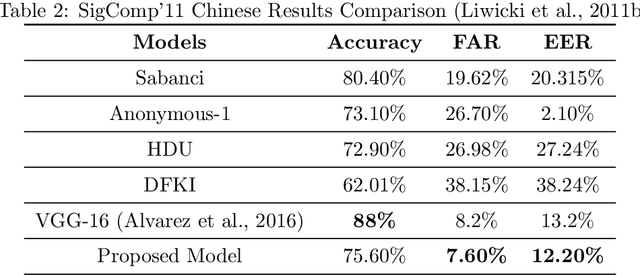
In machine learning applications, it is common practice to feed as much information as possible. In most cases, the model can handle large data sets that allow to predict more accurately. In the presence of data scarcity, a Few-Shot learning (FSL) approach aims to build more accurate algorithms with limited training data. We propose a novel end-to-end lightweight architecture that verifies biometric data by producing competitive results as compared to state-of-the-art accuracies through Few-Shot learning methods. The dense layers add to the complexity of state-of-the-art deep learning models which inhibits them to be used in low-power applications. In presented approach, a shallow network is coupled with a conventional machine learning technique that exploits hand-crafted features to verify biometric images from multi-modal sources such as signatures, periocular region, iris, face, fingerprints etc. We introduce a self-estimated threshold that strictly monitors False Acceptance Rate (FAR) while generalizing its results hence eliminating user-defined thresholds from ROC curves that are likely to be biased on local data distribution. This hybrid model benefits from few-shot learning to make up for scarcity of data in biometric use-cases. We have conducted extensive experimentation with commonly used biometric datasets. The obtained results provided an effective solution for biometric verification systems.
Ice Core Dating using Probabilistic Programming
Oct 29, 2022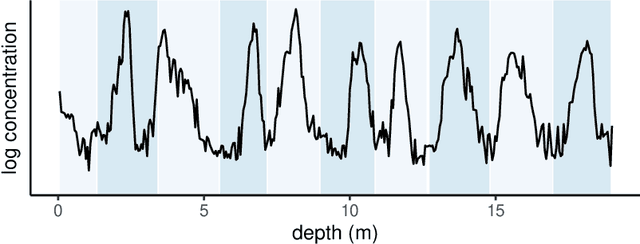
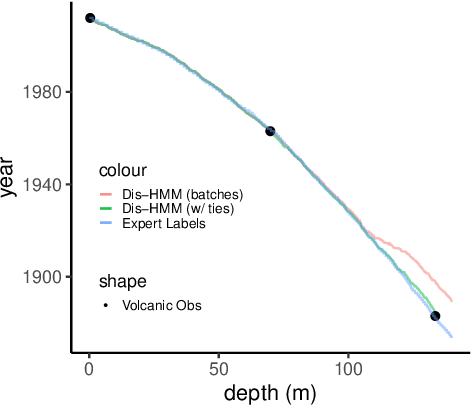
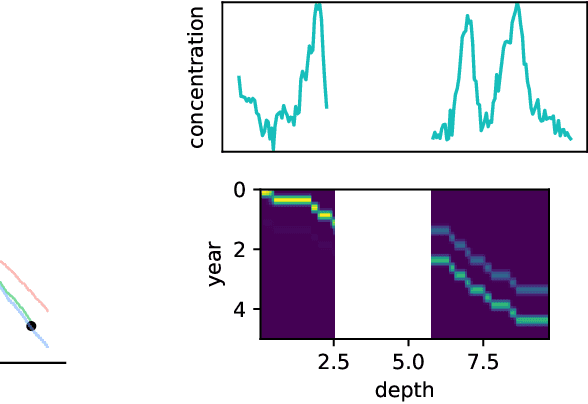
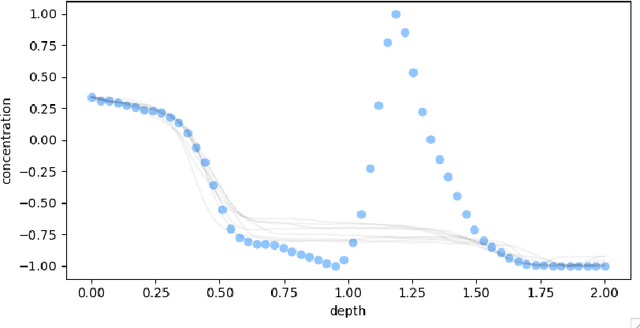
Ice cores record crucial information about past climate. However, before ice core data can have scientific value, the chronology must be inferred by estimating the age as a function of depth. Under certain conditions, chemicals locked in the ice display quasi-periodic cycles that delineate annual layers. Manually counting these noisy seasonal patterns to infer the chronology can be an imperfect and time-consuming process, and does not capture uncertainty in a principled fashion. In addition, several ice cores may be collected from a region, introducing an aspect of spatial correlation between them. We present an exploration of the use of probabilistic models for automatic dating of ice cores, using probabilistic programming to showcase its use for prototyping, automatic inference and maintainability, and demonstrate common failure modes of these tools.
Tracking Accuracy Based Generation Rules of Collective Perception Messages
Sep 28, 2022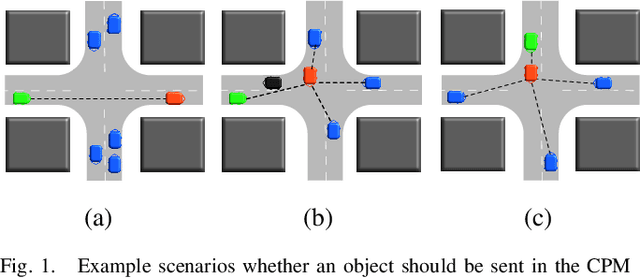
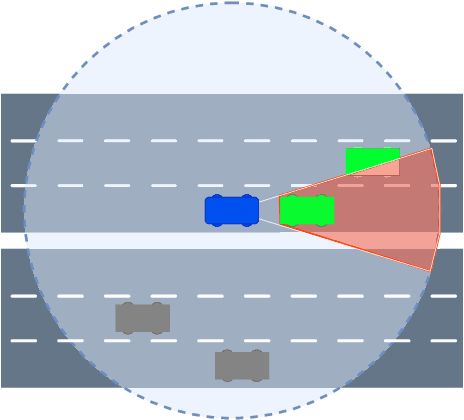
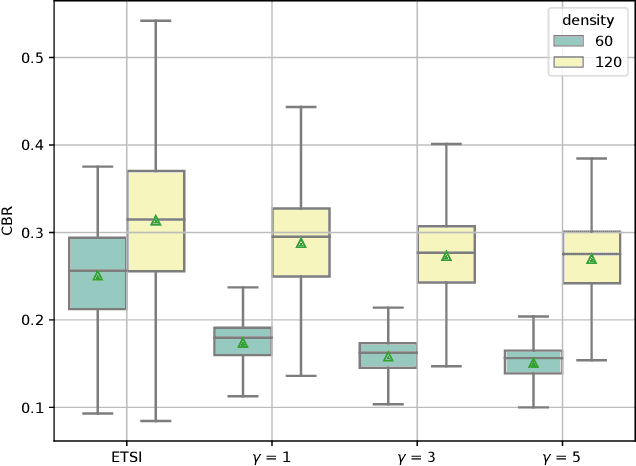
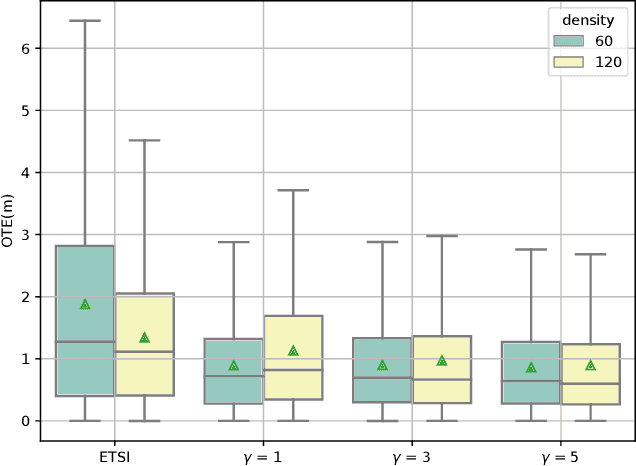
The Collective Perception Service (CPS) enables the enhancement of environmental awareness of Intelligent Transport System Stations (ITS-S) through the exchange of tracking information between stations. As the market penetration of CPS is growing, the intelligent distribution of the limited communication resources becomes more and more challenging. To address this problem, the ETSI CPS proposes dynamic-based object selection to generate Collective Perception Messages. However, this approach has limits and barely considers detection accuracy and the recent information available at other ITS-Ss in the transmission range. We show a proposal considering the current object tracking accuracy in the local environment and the object tracking from messages received by other stations in order to intelligently decide whether to include an object in a CPM. The algorithm decides based on the relative entropy between the local and V2X tracking accuracy if the object information is valuable for the nearby stations. Our simulation according to the ITS-G5 standard shows that the Channel Busy Ratio (CBR) can be reduced with accuracy-based generation of CPM while improving Object Tracking Accuracy (OTA) compared to generation based on ETSI rules.
GRATIS: Deep Learning Graph Representation with Task-specific Topology and Multi-dimensional Edge Features
Nov 19, 2022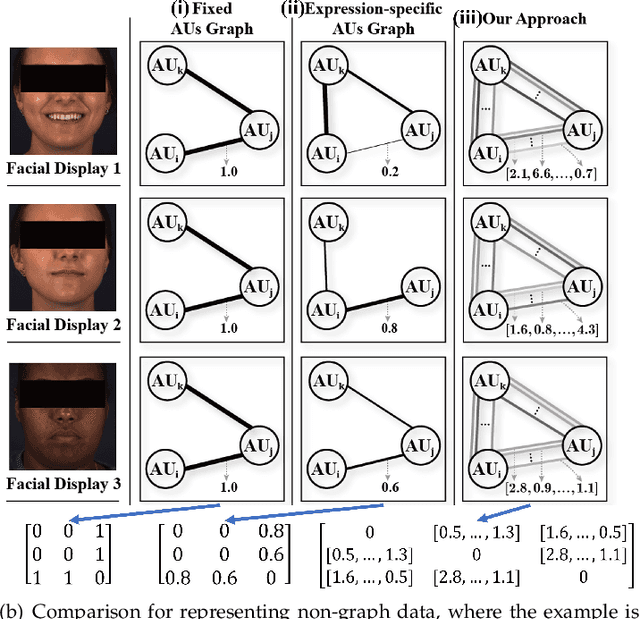
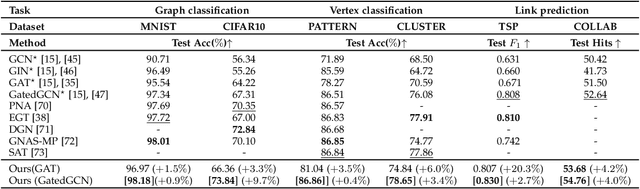
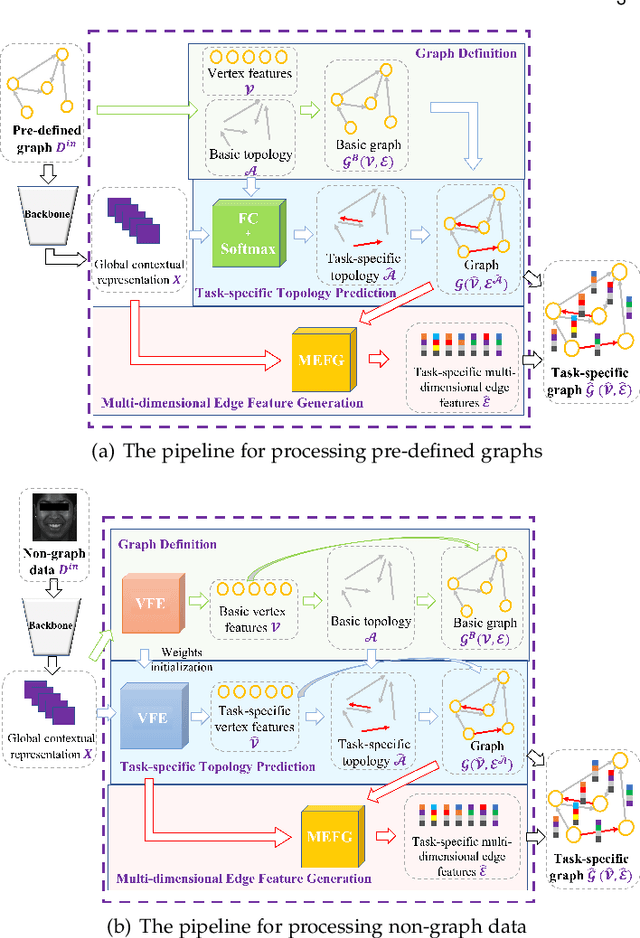
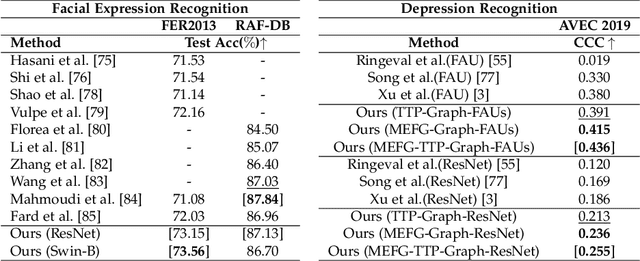
Graph is powerful for representing various types of real-world data. The topology (edges' presence) and edges' features of a graph decides the message passing mechanism among vertices within the graph. While most existing approaches only manually define a single-value edge to describe the connectivity or strength of association between a pair of vertices, task-specific and crucial relationship cues may be disregarded by such manually defined topology and single-value edge features. In this paper, we propose the first general graph representation learning framework (called GRATIS) which can generate a strong graph representation with a task-specific topology and task-specific multi-dimensional edge features from any arbitrary input. To learn each edge's presence and multi-dimensional feature, our framework takes both of the corresponding vertices pair and their global contextual information into consideration, enabling the generated graph representation to have a globally optimal message passing mechanism for different down-stream tasks. The principled investigation results achieved for various graph analysis tasks on 11 graph and non-graph datasets show that our GRATIS can not only largely enhance pre-defined graphs but also learns a strong graph representation for non-graph data, with clear performance improvements on all tasks. In particular, the learned topology and multi-dimensional edge features provide complementary task-related cues for graph analysis tasks. Our framework is effective, robust and flexible, and is a plug-and-play module that can be combined with different backbones and Graph Neural Networks (GNNs) to generate a task-specific graph representation from various graph and non-graph data. Our code is made publicly available at https://github.com/SSYSteve/Learning-Graph-Representation-with-Task-specific-Topology-and-Multi-dimensional-Edge-Features.
Spikeformer: A Novel Architecture for Training High-Performance Low-Latency Spiking Neural Network
Nov 19, 2022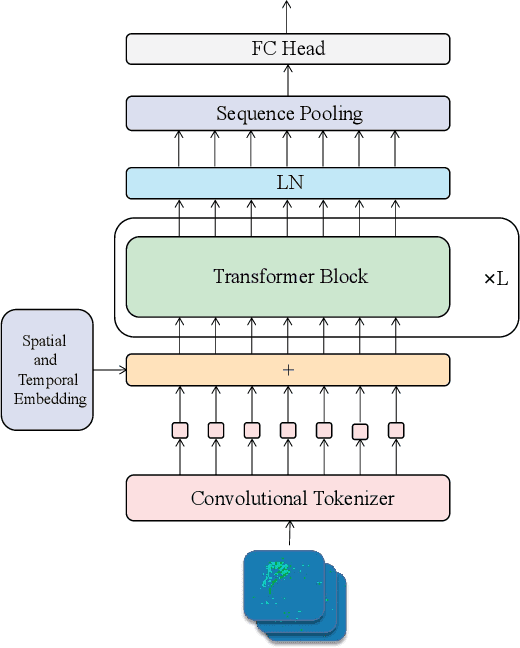
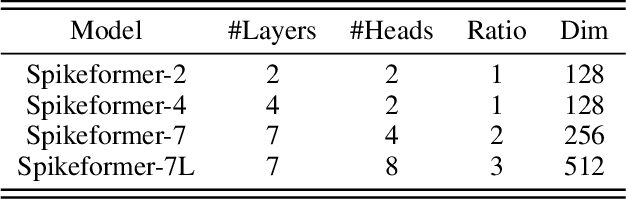
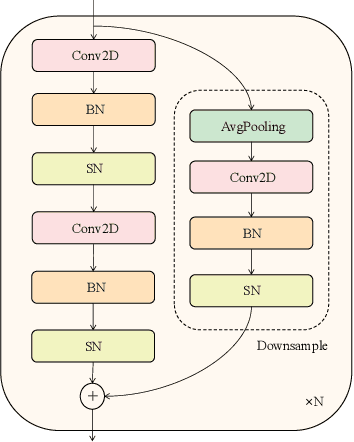

Spiking neural networks (SNNs) have made great progress on both performance and efficiency over the last few years,but their unique working pattern makes it hard to train a high-performance low-latency SNN.Thus the development of SNNs still lags behind traditional artificial neural networks (ANNs).To compensate this gap,many extraordinary works have been proposed.Nevertheless,these works are mainly based on the same kind of network structure (i.e.CNN) and their performance is worse than their ANN counterparts,which limits the applications of SNNs.To this end,we propose a novel Transformer-based SNN,termed "Spikeformer",which outperforms its ANN counterpart on both static dataset and neuromorphic dataset and may be an alternative architecture to CNN for training high-performance SNNs.First,to deal with the problem of "data hungry" and the unstable training period exhibited in the vanilla model,we design the Convolutional Tokenizer (CT) module,which improves the accuracy of the original model on DVS-Gesture by more than 16%.Besides,in order to better incorporate the attention mechanism inside Transformer and the spatio-temporal information inherent to SNN,we adopt spatio-temporal attention (STA) instead of spatial-wise or temporal-wise attention.With our proposed method,we achieve competitive or state-of-the-art (SOTA) SNN performance on DVS-CIFAR10,DVS-Gesture,and ImageNet datasets with the least simulation time steps (i.e.low latency).Remarkably,our Spikeformer outperforms other SNNs on ImageNet by a large margin (i.e.more than 5%) and even outperforms its ANN counterpart by 3.1% and 2.2% on DVS-Gesture and ImageNet respectively,indicating that Spikeformer is a promising architecture for training large-scale SNNs and may be more suitable for SNNs compared to CNN.We believe that this work shall keep the development of SNNs in step with ANNs as much as possible.Code will be available.
Video Event Extraction via Tracking Visual States of Arguments
Nov 05, 2022
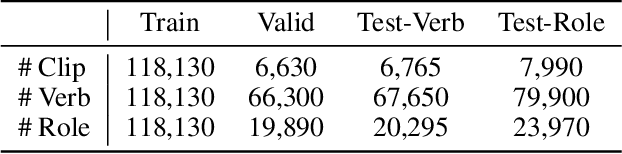

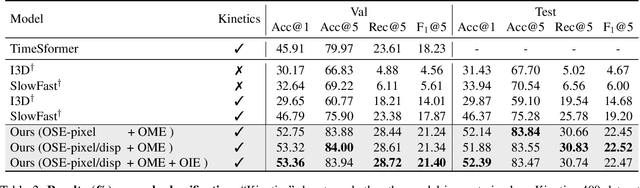
Video event extraction aims to detect salient events from a video and identify the arguments for each event as well as their semantic roles. Existing methods focus on capturing the overall visual scene of each frame, ignoring fine-grained argument-level information. Inspired by the definition of events as changes of states, we propose a novel framework to detect video events by tracking the changes in the visual states of all involved arguments, which are expected to provide the most informative evidence for the extraction of video events. In order to capture the visual state changes of arguments, we decompose them into changes in pixels within objects, displacements of objects, and interactions among multiple arguments. We further propose Object State Embedding, Object Motion-aware Embedding and Argument Interaction Embedding to encode and track these changes respectively. Experiments on various video event extraction tasks demonstrate significant improvements compared to state-of-the-art models. In particular, on verb classification, we achieve 3.49% absolute gains (19.53% relative gains) in F1@5 on Video Situation Recognition.
Small Language Models for Tabular Data
Nov 05, 2022

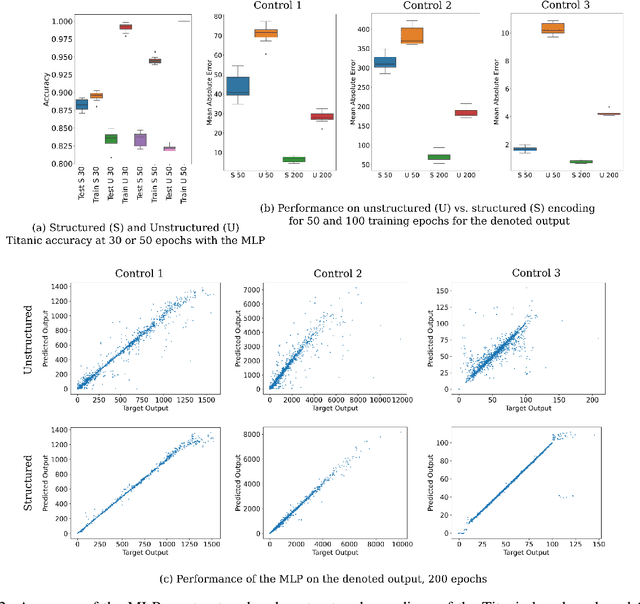
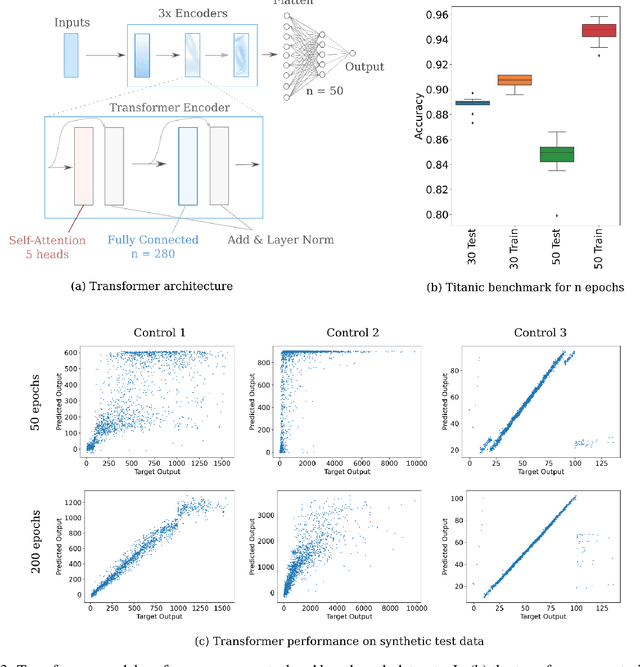
Supervised deep learning is most commonly applied to difficult problems defined on large and often extensively curated datasets. Here we demonstrate the ability of deep representation learning to address problems of classification and regression from small and poorly formed tabular datasets by encoding input information as abstracted sequences composed of a fixed number of characters per input field. We find that small models have sufficient capacity for approximation of various functions and achieve record classification benchmark accuracy. Such models are shown to form useful embeddings of various input features in their hidden layers, even if the learned task does not explicitly require knowledge of those features. These models are also amenable to input attribution, allowing for an estimation of the importance of each input element to the model output as well as of which inputs features are effectively embedded in the model. We present a proof-of-concept for the application of small language models to mixed tabular data without explicit feature engineering, cleaning, or preprocessing, relying on the model to perform these tasks as part of the representation learning process.
Quantization Adaptor for Bit-Level Deep Learning-Based Massive MIMO CSI Feedback
Nov 05, 2022
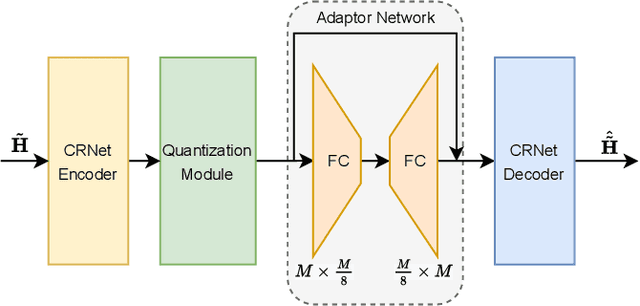
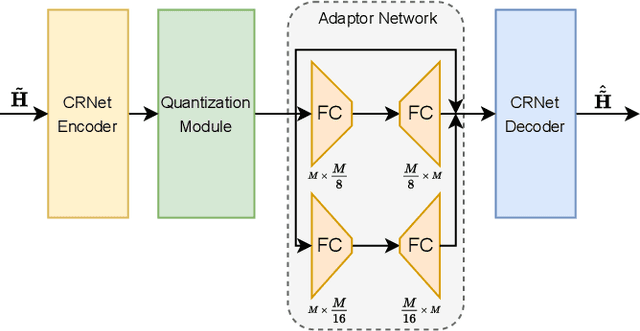
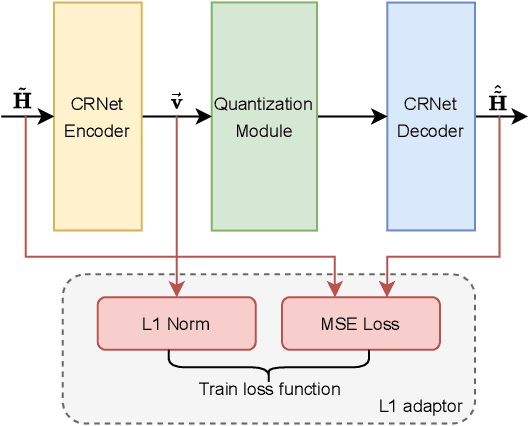
In massive multiple-input multiple-output (MIMO) systems, the user equipment (UE) needs to feed the channel state information (CSI) back to the base station (BS) for the following beamforming. But the large scale of antennas in massive MIMO systems causes huge feedback overhead. Deep learning (DL) based methods can compress the CSI at the UE and recover it at the BS, which reduces the feedback cost significantly. But the compressed CSI must be quantized into bit streams for transmission. In this paper, we propose an adaptor-assisted quantization strategy for bit-level DL-based CSI feedback. First, we design a network-aided adaptor and an advanced training scheme to adaptively improve the quantization and reconstruction accuracy. Moreover, for easy practical employment, we introduce the expert knowledge of data distribution and propose a pluggable and cost-free adaptor scheme. Experiments show that compared with the state-of-the-art feedback quantization method, this adaptor-aided quantization strategy can achieve better quantization accuracy and reconstruction performance with less or no additional cost. The open-source codes are available at https://github.com/zhangxd18/QCRNet.
Call-sign recognition and understanding for noisy air-traffic transcripts using surveillance information
Apr 13, 2022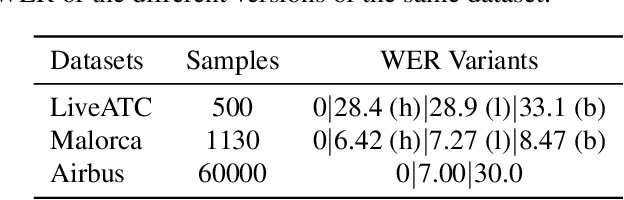

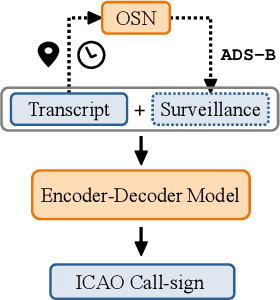
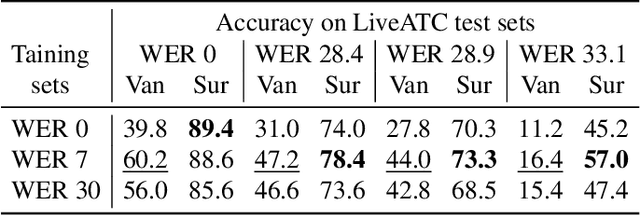
Air traffic control (ATC) relies on communication via speech between pilot and air-traffic controller (ATCO). The call-sign, as unique identifier for each flight, is used to address a specific pilot by the ATCO. Extracting the call-sign from the communication is a challenge because of the noisy ATC voice channel and the additional noise introduced by the receiver. A low signal-to-noise ratio (SNR) in the speech leads to high word error rate (WER) transcripts. We propose a new call-sign recognition and understanding (CRU) system that addresses this issue. The recognizer is trained to identify call-signs in noisy ATC transcripts and convert them into the standard International Civil Aviation Organization (ICAO) format. By incorporating surveillance information, we can multiply the call-sign accuracy (CSA) up to a factor of four. The introduced data augmentation adds additional performance on high WER transcripts and allows the adaptation of the model to unseen airspaces.