 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
High-resolution embedding extractor for speaker diarisation
Nov 08, 2022
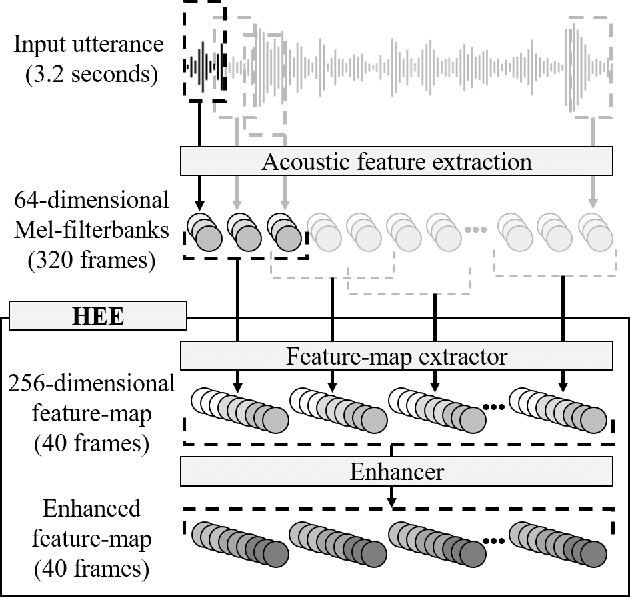
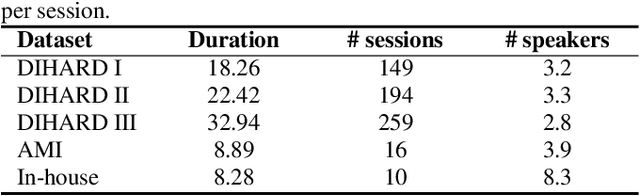
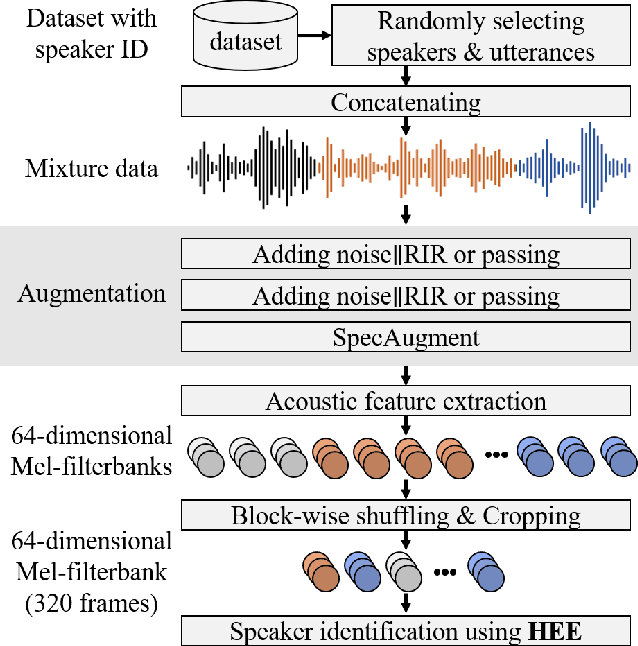
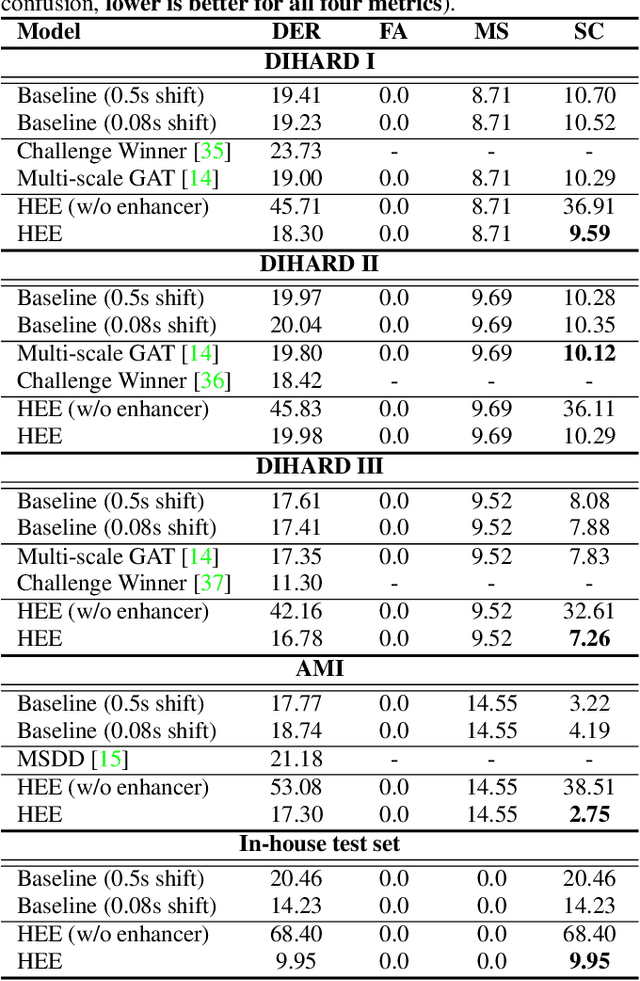
Speaker embedding extractors significantly influence the performance of clustering-based speaker diarisation systems. Conventionally, only one embedding is extracted from each speech segment. However, because of the sliding window approach, a segment easily includes two or more speakers owing to speaker change points. This study proposes a novel embedding extractor architecture, referred to as a high-resolution embedding extractor (HEE), which extracts multiple high-resolution embeddings from each speech segment. Hee consists of a feature-map extractor and an enhancer, where the enhancer with the self-attention mechanism is the key to success. The enhancer of HEE replaces the aggregation process; instead of a global pooling layer, the enhancer combines relative information to each frame via attention leveraging the global context. Extracted dense frame-level embeddings can each represent a speaker. Thus, multiple speakers can be represented by different frame-level features in each segment. We also propose an artificially generating mixture data training framework to train the proposed HEE. Through experiments on five evaluation sets, including four public datasets, the proposed HEE demonstrates at least 10% improvement on each evaluation set, except for one dataset, which we analyse that rapid speaker changes less exist.
SimOn: A Simple Framework for Online Temporal Action Localization
Nov 08, 2022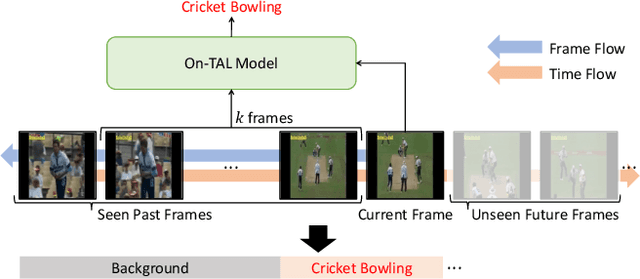
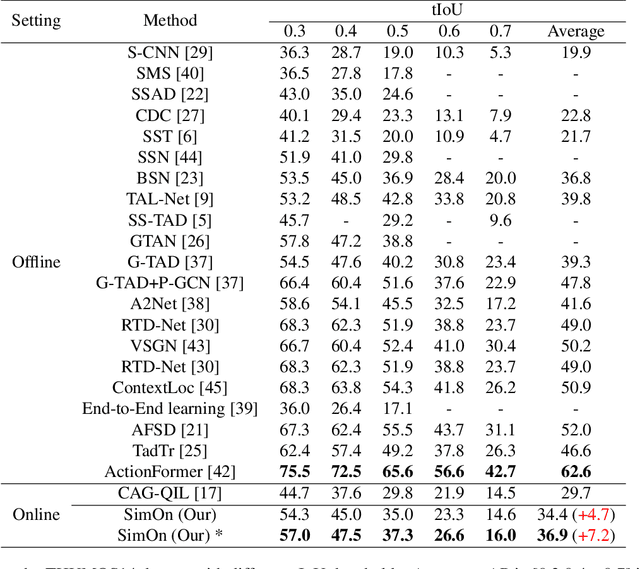
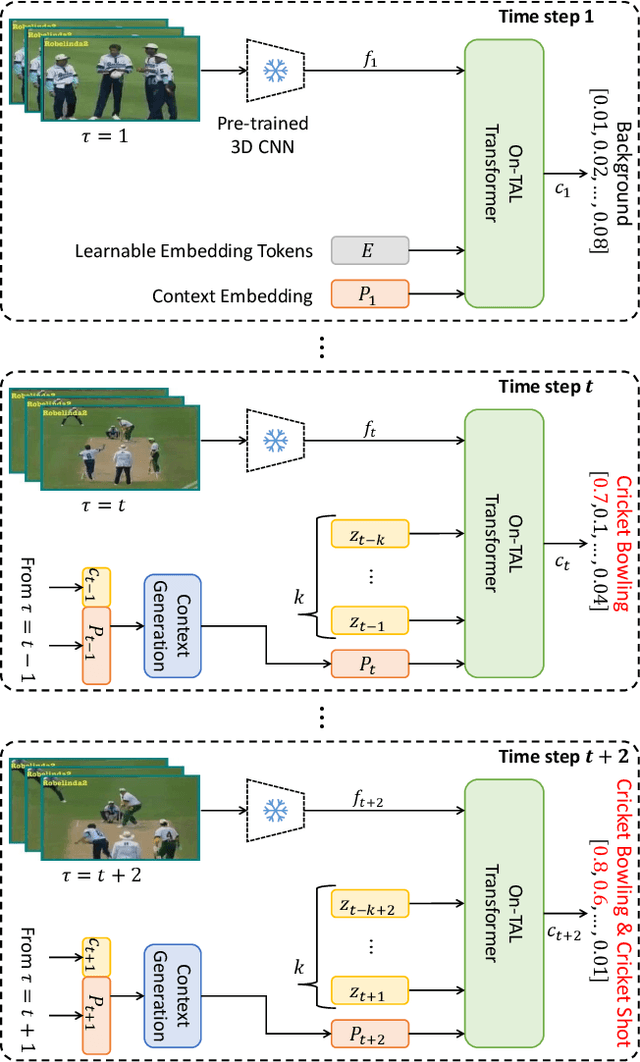
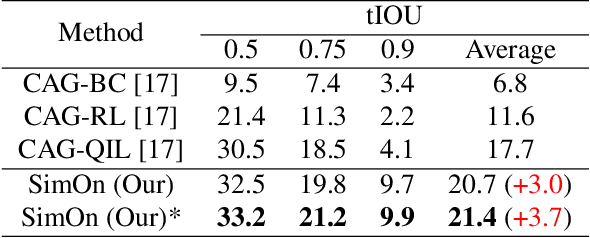
Online Temporal Action Localization (On-TAL) aims to immediately provide action instances from untrimmed streaming videos. The model is not allowed to utilize future frames and any processing techniques to modify past predictions, making On-TAL much more challenging. In this paper, we propose a simple yet effective framework, termed SimOn, that learns to predict action instances using the popular Transformer architecture in an end-to-end manner. Specifically, the model takes the current frame feature as a query and a set of past context information as keys and values of the Transformer. Different from the prior work that uses a set of outputs of the model as past contexts, we leverage the past visual context and the learnable context embedding for the current query. Experimental results on the THUMOS14 and ActivityNet1.3 datasets show that our model remarkably outperforms the previous methods, achieving a new state-of-the-art On-TAL performance. In addition, the evaluation for Online Detection of Action Start (ODAS) demonstrates the effectiveness and robustness of our method in the online setting. The code is available at https://github.com/TuanTNG/SimOn
Graph Summarization via Node Grouping: A Spectral Algorithm
Nov 08, 2022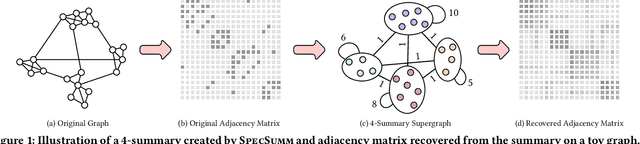
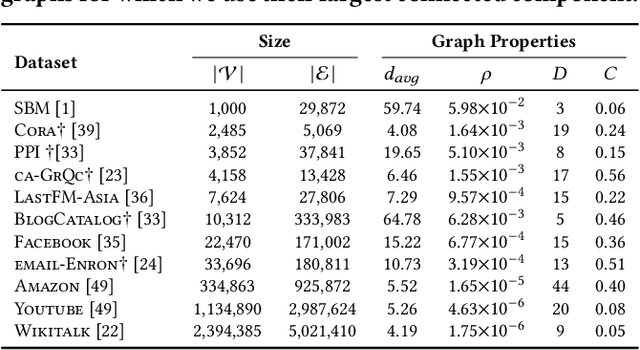
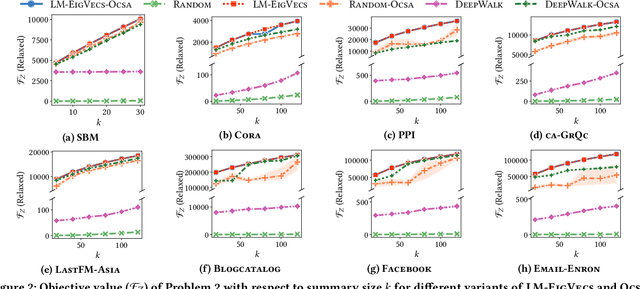
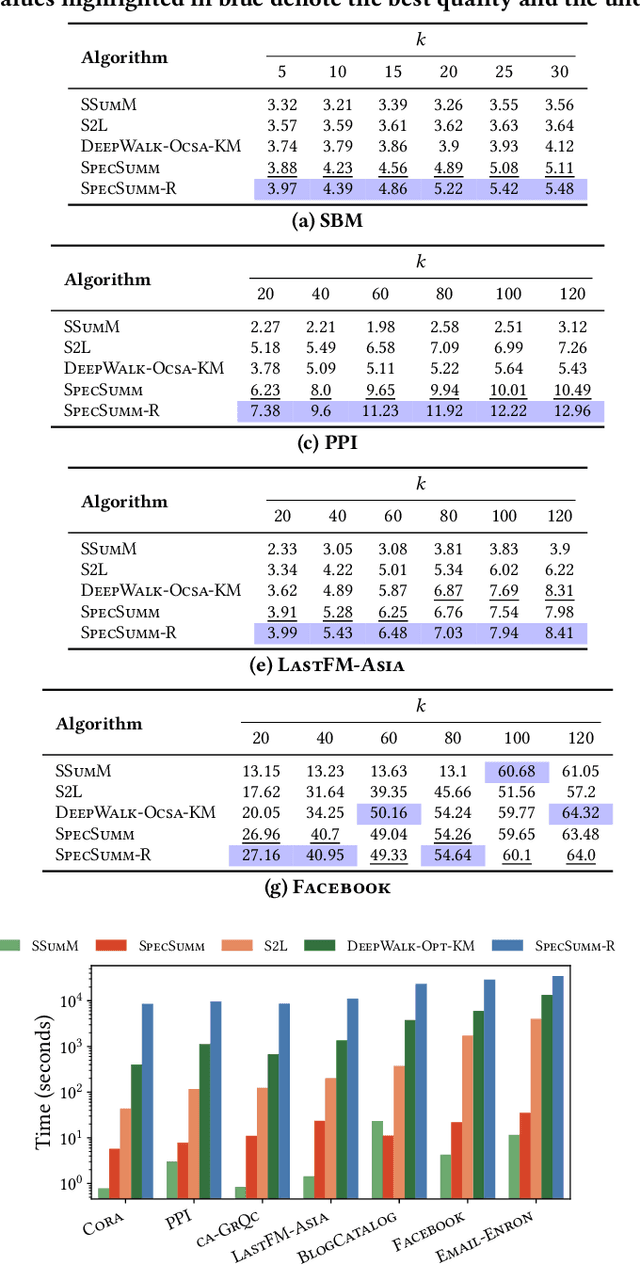
Graph summarization via node grouping is a popular method to build concise graph representations by grouping nodes from the original graph into supernodes and encoding edges into superedges such that the loss of adjacency information is minimized. Such summaries have immense applications in large-scale graph analytics due to their small size and high query processing efficiency. In this paper, we reformulate the loss minimization problem for summarization into an equivalent integer maximization problem. By initially allowing relaxed (fractional) solutions for integer maximization, we analytically expose the underlying connections to the spectral properties of the adjacency matrix. Consequently, we design an algorithm called SpecSumm that consists of two phases. In the first phase, motivated by spectral graph theory, we apply k-means clustering on the k largest (in magnitude) eigenvectors of the adjacency matrix to assign nodes to supernodes. In the second phase, we propose a greedy heuristic that updates the initial assignment to further improve summary quality. Finally, via extensive experiments on 11 datasets, we show that SpecSumm efficiently produces high-quality summaries compared to state-of-the-art summarization algorithms and scales to graphs with millions of nodes.
Finite Sample Identification of Wide Shallow Neural Networks with Biases
Nov 08, 2022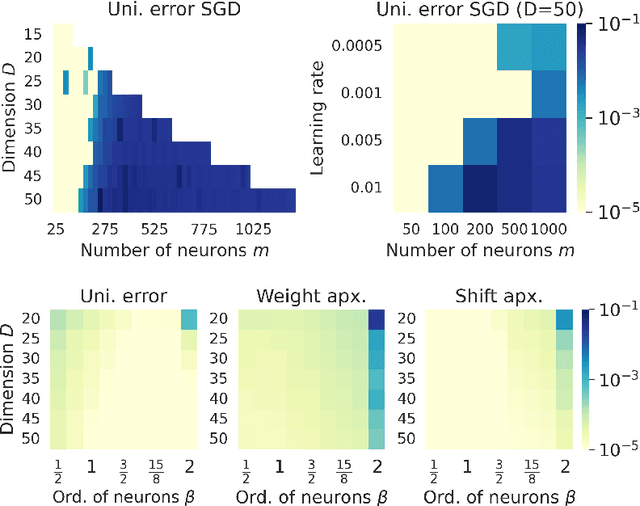
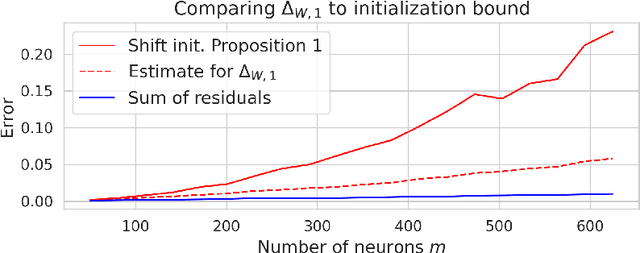
Artificial neural networks are functions depending on a finite number of parameters typically encoded as weights and biases. The identification of the parameters of the network from finite samples of input-output pairs is often referred to as the \emph{teacher-student model}, and this model has represented a popular framework for understanding training and generalization. Even if the problem is NP-complete in the worst case, a rapidly growing literature -- after adding suitable distributional assumptions -- has established finite sample identification of two-layer networks with a number of neurons $m=\mathcal O(D)$, $D$ being the input dimension. For the range $D<m<D^2$ the problem becomes harder, and truly little is known for networks parametrized by biases as well. This paper fills the gap by providing constructive methods and theoretical guarantees of finite sample identification for such wider shallow networks with biases. Our approach is based on a two-step pipeline: first, we recover the direction of the weights, by exploiting second order information; next, we identify the signs by suitable algebraic evaluations, and we recover the biases by empirical risk minimization via gradient descent. Numerical results demonstrate the effectiveness of our approach.
Efficient Compressed Ratio Estimation using Online Sequential Learning for Edge Computing
Nov 08, 2022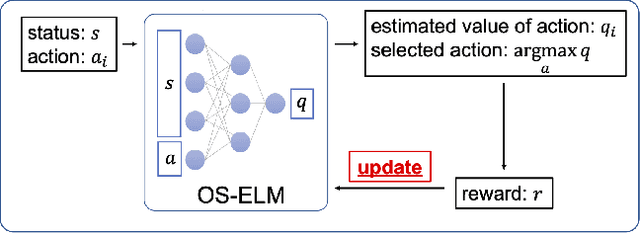
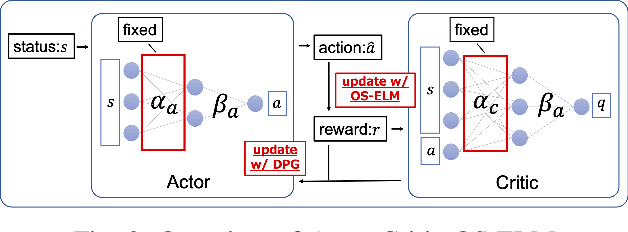
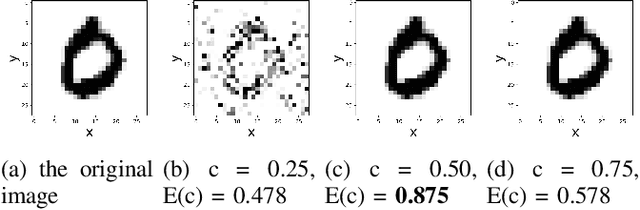
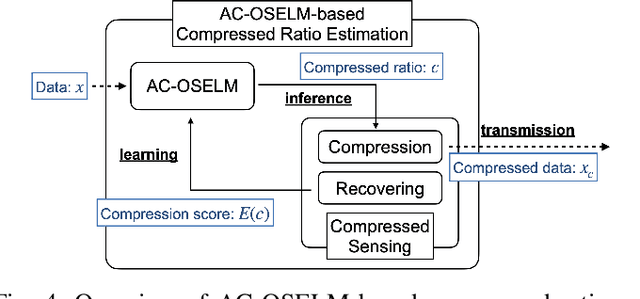
Owing to the widespread adoption of the Internet of Things, a vast amount of sensor information is being acquired in real time. Accordingly, the communication cost of data from edge devices is increasing. Compressed sensing (CS), a data compression method that can be used on edge devices, has been attracting attention as a method to reduce communication costs. In CS, estimating the appropriate compression ratio is important. There is a method to adaptively estimate the compression ratio for the acquired data using reinforcement learning. However, the computational costs associated with existing reinforcement learning methods that can be utilized on edges are expensive. In this study, we developed an efficient reinforcement learning method for edge devices, referred to as the actor--critic online sequential extreme learning machine (AC-OSELM), and a system to compress data by estimating an appropriate compression ratio on the edge using AC-OSELM. The performance of the proposed method in estimating the compression ratio is evaluated by comparing it with other reinforcement learning methods for edge devices. The experimental results show that AC-OSELM achieved the same or better compression performance and faster compression ratio estimation than the existing methods.
IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022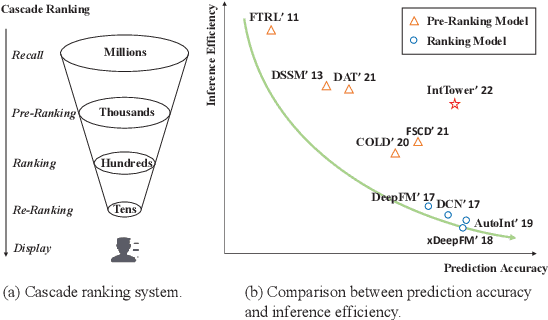
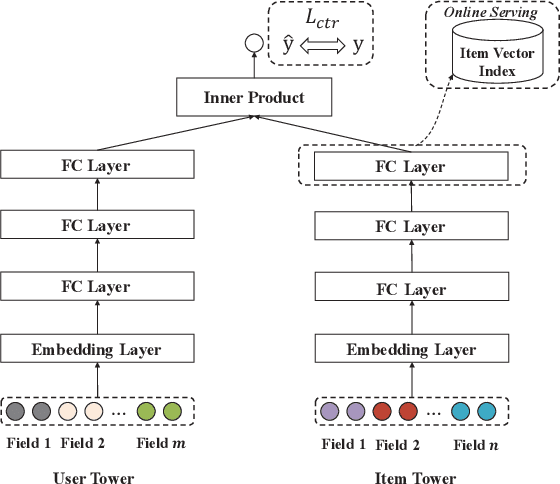
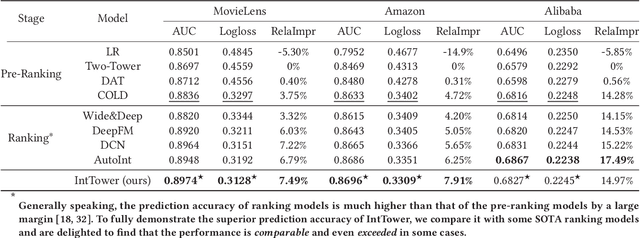
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}
Spatio-Temporal-based Context Fusion for Video Anomaly Detection
Oct 18, 2022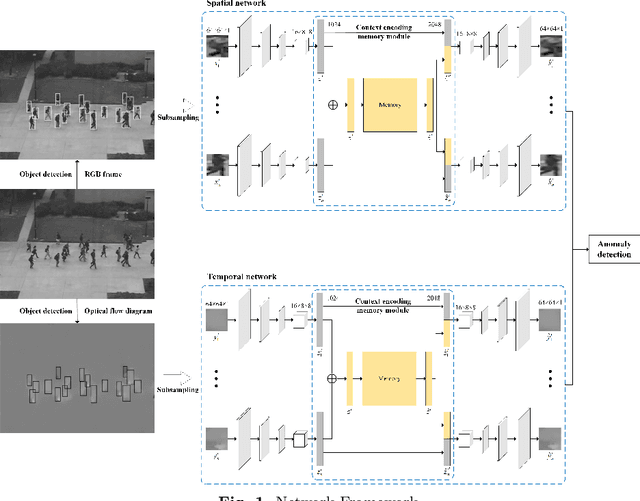
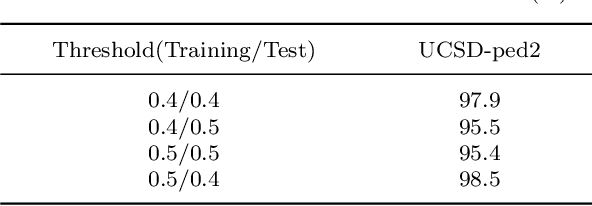
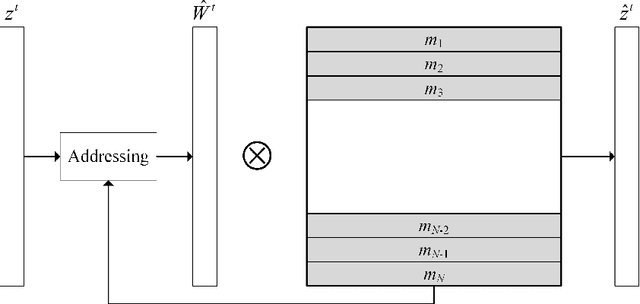
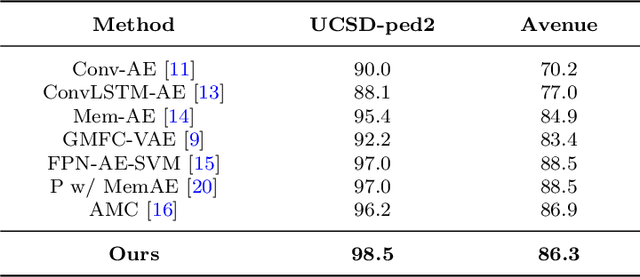
Video anomaly detection aims to discover abnormal events in videos, and the principal objects are target objects such as people and vehicles. Each target in the video data has rich spatio-temporal context information. Most existing methods only focus on the temporal context, ignoring the role of the spatial context in anomaly detection. The spatial context information represents the relationship between the detection target and surrounding targets. Anomaly detection makes a lot of sense. To this end, a video anomaly detection algorithm based on target spatio-temporal context fusion is proposed. Firstly, the target in the video frame is extracted through the target detection network to reduce background interference. Then the optical flow map of two adjacent frames is calculated. Motion features are used multiple targets in the video frame to construct spatial context simultaneously, re-encoding the target appearance and motion features, and finally reconstructing the above features through the spatio-temporal dual-stream network, and using the reconstruction error to represent the abnormal score. The algorithm achieves frame-level AUCs of 98.5% and 86.3% on the UCSDped2 and Avenue datasets, respectively. On the UCSDped2 dataset, the spatio-temporal dual-stream network improves frames by 5.1% and 0.3%, respectively, compared to the temporal and spatial stream networks. After using spatial context encoding, the frame-level AUC is enhanced by 1%, which verifies the method's effectiveness.
The Design and Realization of Multi-agent Obstacle Avoidance based on Reinforcement Learning
Oct 24, 2022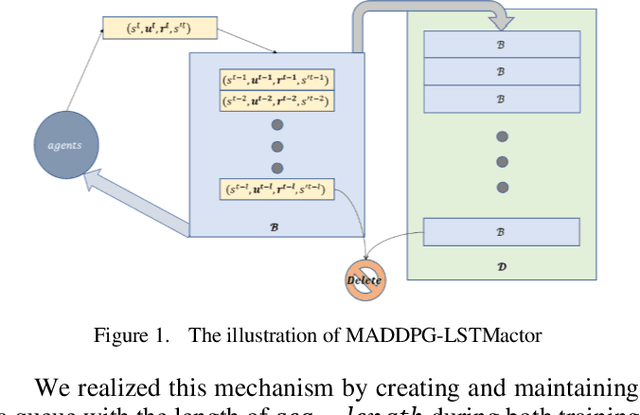
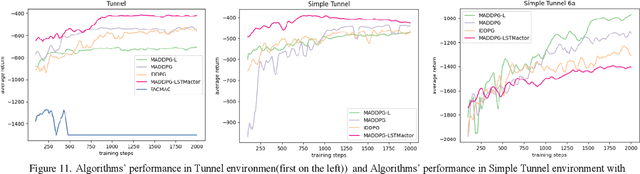
Intelligence agents and multi-agent systems play important roles in scenes like the control system of grouped drones, and multi-agent navigation and obstacle avoidance which is the foundational function of advanced application has great importance. In multi-agent navigation and obstacle avoidance tasks, the decision-making interactions and dynamic changes of agents are difficult for traditional route planning algorithms or reinforcement learning algorithms with the increased complexity of the environment. The classical multi-agent reinforcement learning algorithm, Multi-agent deep deterministic policy gradient(MADDPG), solved precedent algorithms' problems of having unstationary training process and unable to deal with environment randomness. However, MADDPG ignored the temporal message hidden beneath agents' interaction with the environment. Besides, due to its CTDE technique which let each agent's critic network to calculate over all agents' action and the whole environment information, it lacks ability to scale to larger amount of agents. To deal with MADDPG's ignorance of the temporal information of the data, this article proposes a new algorithm called MADDPG-LSTMactor, which combines MADDPG with Long short term memory (LSTM). By using agent's observations of continuous timesteps as the input of its policy network, it allows the LSTM layer to process the hidden temporal message. Experimental result demonstrated that this algorithm had better performance in scenarios where the amount of agents is small. Besides, to solve MADDPG's drawback of not being efficient in scenarios where agents are too many, this article puts forward a light-weight MADDPG (MADDPG-L) algorithm, which simplifies the input of critic network. The result of experiments showed that this algorithm had better performance than MADDPG when the amount of agents was large.
A Transformer-based deep neural network model for SSVEP classification
Oct 09, 2022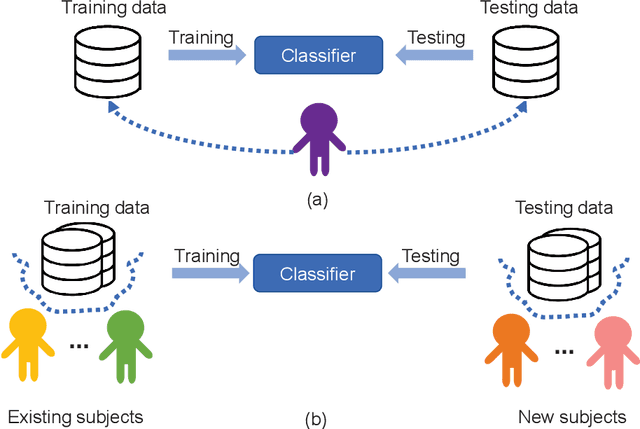
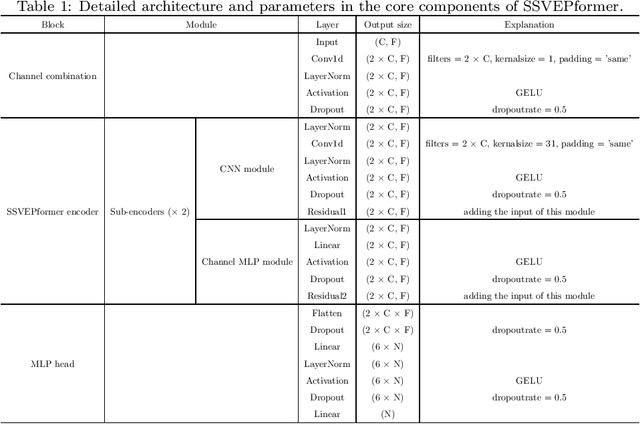
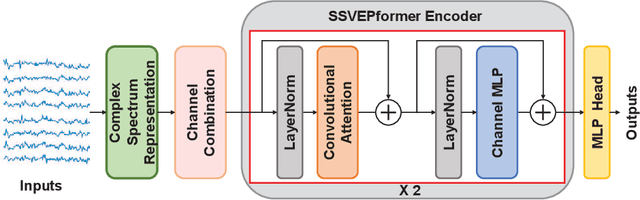
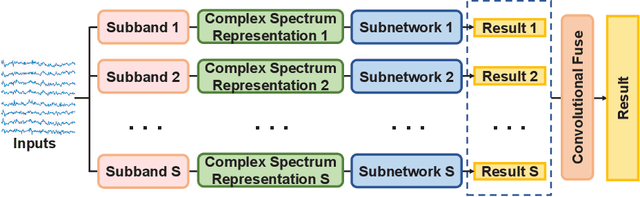
Steady-state visual evoked potential (SSVEP) is one of the most commonly used control signal in the brain-computer interface (BCI) systems. However, the conventional spatial filtering methods for SSVEP classification highly depend on the subject-specific calibration data. The need for the methods that can alleviate the demand for the calibration data become urgent. In recent years, developing the methods that can work in inter-subject classification scenario has become a promising new direction. As the popular deep learning model nowadays, Transformer has excellent performance and has been used in EEG signal classification tasks. Therefore, in this study, we propose a deep learning model for SSVEP classification based on Transformer structure in inter-subject classification scenario, termed as SSVEPformer, which is the first application of the transformer to the classification of SSVEP. Inspired by previous studies, the model adopts the frequency spectrum of SSVEP data as input, and explores the spectral and spatial domain information for classification. Furthermore, to fully utilize the harmonic information, an extended SSVEPformer based on the filter bank technology (FB-SSVEPformer) is proposed to further improve the classification performance. Experiments were conducted using two open datasets (Dataset 1: 10 subjects, 12-class task; Dataset 2: 35 subjects, 40-class task) in the inter-subject classification scenario. The experimental results show that the proposed models could achieve better results in terms of classification accuracy and information transfer rate, compared with other baseline methods. The proposed model validates the feasibility of deep learning models based on Transformer structure for SSVEP classification task, and could serve as a potential model to alleviate the calibration procedure in the practical application of SSVEP-based BCI systems.
Dual Class-Aware Contrastive Federated Semi-Supervised Learning
Nov 16, 2022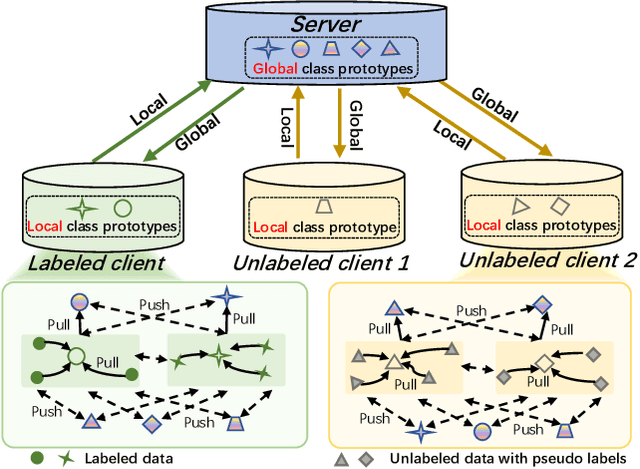
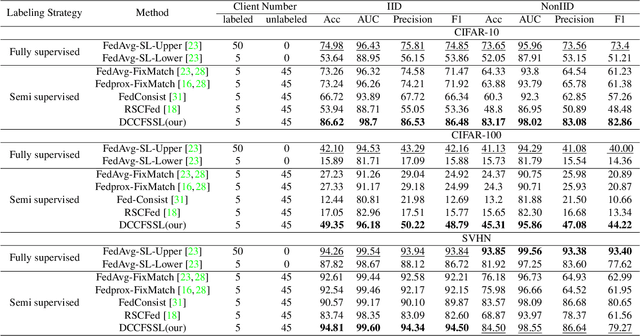
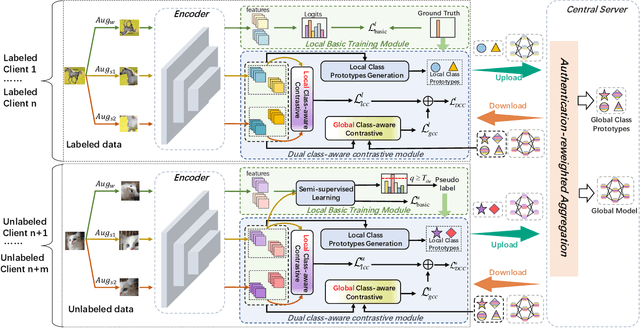
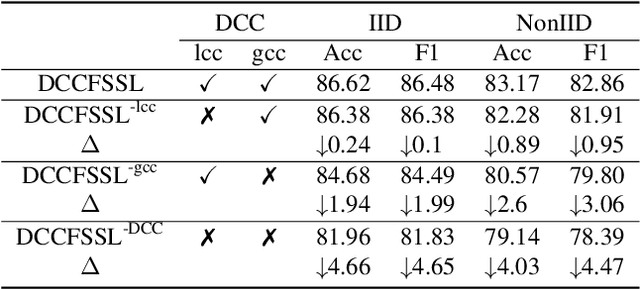
Federated semi-supervised learning (FSSL), facilitates labeled clients and unlabeled clients jointly training a global model without sharing private data. Existing FSSL methods mostly focus on pseudo-labeling and consistency regularization to leverage the knowledge of unlabeled data, which have achieved substantial success on raw data utilization. However, their training procedures suffer from the large deviation from local models of labeled clients and unlabeled clients and the confirmation bias induced by noisy pseudo labels, which seriously damage the performance of the global model. In this paper, we propose a novel FSSL method, named Dual Class-aware Contrastive Federated Semi-Supervised Learning (DCCFSSL), which considers the local class-aware distribution of individual client's data and the global class-aware distribution of all clients' data simultaneously in the feature space. By introducing a dual class-aware contrastive module, DCCFSSL builds a common training goal for different clients to reduce the large deviation and introduces contrastive information in the feature space to alleviate the confirmation bias. Meanwhile, DCCFSSL presents an authentication-reweighted aggregation method to enhance the robustness of the server's aggregation. Extensive experiments demonstrate that DCCFSSL not only outperforms state-of-the-art methods on three benchmarked datasets, but also surpasses the FedAvg with relabeled unlabeled clients on CIFAR-10 and CIFAR-100 datasets. To our best knowledge, we are the first to present the FSSL method that utilizes only 10\% labeled clients of all clients to achieve better performance than the standard federated supervised learning that uses all clients with labeled data.