 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cluster consistency: Simple yet effect robust learning algorithm on large-scale photoplethysmography for atrial fibrillation detection in the presence of real-world label noise
Nov 07, 2022
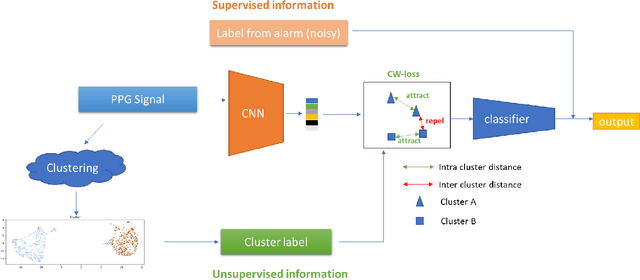
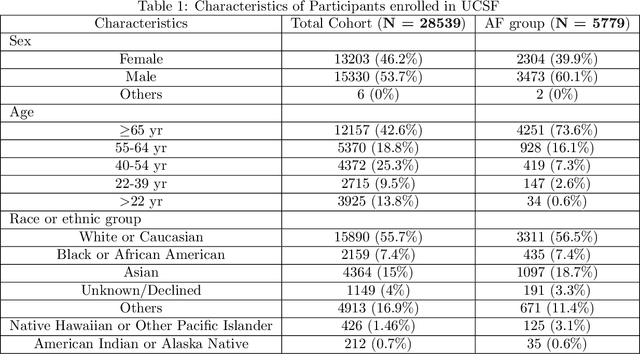
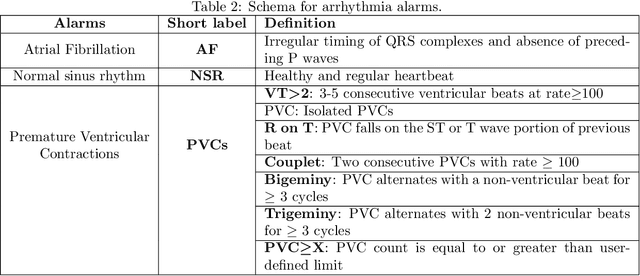
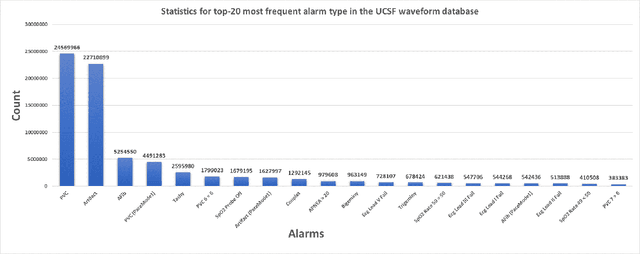
Obtaining large-scale well-annotated is always a daunting challenge, especially in the medical research domain because of the shortage of domain expert. Instead of human annotation, in this work, we use the alarm information generated from bed-side monitor to get the pseudo label for the co-current photoplethysmography (PPG) signal. Based on this strategy, we end up with over 8 million 30-second PPG segment. To solve the label noise caused by false alarms, we propose the cluster consistency, which use an unsupervised auto-encoder (hence not subject to label noise) approach to cluster training samples into a finite number of clusters. Then the learned cluster membership is used in the subsequent supervised learning phase to force the distance in the latent space of samples in the same cluster to be small while that of samples in different clusters to be big. In the experiment, we compare with the state-of-the-art algorithms and test on external datasets. The results show the superiority of our method in both classification performance and efficiency.
Decentralized Complete Dictionary Learning via $\ell^{4}$-Norm Maximization
Nov 07, 2022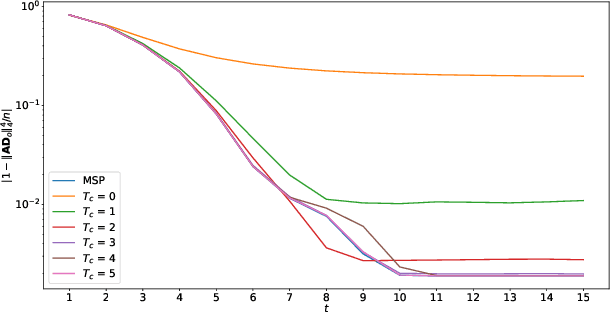
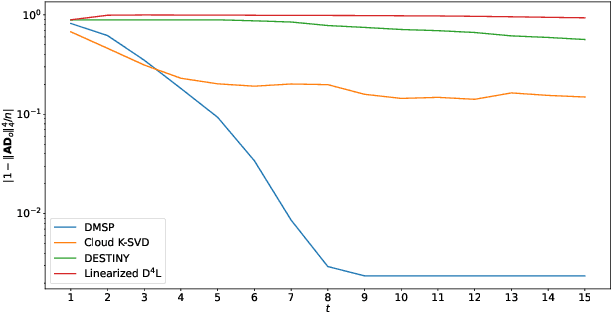


With the rapid development of information technologies, centralized data processing is subject to many limitations, such as computational overheads, communication delays, and data privacy leakage. Decentralized data processing over networked terminal nodes becomes an important technology in the era of big data. Dictionary learning is a powerful representation learning method to exploit the low-dimensional structure from the high-dimensional data. By exploiting the low-dimensional structure, the storage and the processing overhead of data can be effectively reduced. In this paper, we propose a novel decentralized complete dictionary learning algorithm, which is based on $\ell^{4}$-norm maximization. Compared with existing decentralized dictionary learning algorithms, comprehensive numerical experiments show that the novel algorithm has significant advantages in terms of per-iteration computational complexity, communication cost, and convergence rate in many scenarios. Moreover, a rigorous theoretical analysis shows that the dictionaries learned by the proposed algorithm can converge to the one learned by a centralized dictionary learning algorithm at a linear rate with high probability under certain conditions.
Discrete Distribution Estimation under User-level Local Differential Privacy
Nov 07, 2022
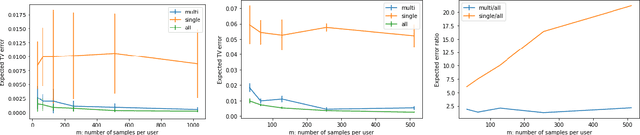
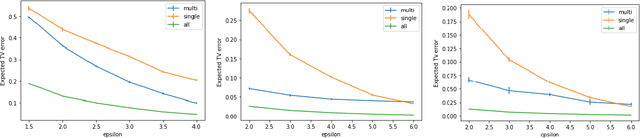
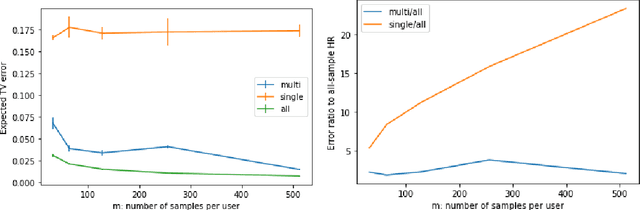
We study discrete distribution estimation under user-level local differential privacy (LDP). In user-level $\varepsilon$-LDP, each user has $m\ge1$ samples and the privacy of all $m$ samples must be preserved simultaneously. We resolve the following dilemma: While on the one hand having more samples per user should provide more information about the underlying distribution, on the other hand, guaranteeing the privacy of all $m$ samples should make the estimation task more difficult. We obtain tight bounds for this problem under almost all parameter regimes. Perhaps surprisingly, we show that in suitable parameter regimes, having $m$ samples per user is equivalent to having $m$ times more users, each with only one sample. Our results demonstrate interesting phase transitions for $m$ and the privacy parameter $\varepsilon$ in the estimation risk. Finally, connecting with recent results on shuffled DP, we show that combined with random shuffling, our algorithm leads to optimal error guarantees (up to logarithmic factors) under the central model of user-level DP in certain parameter regimes. We provide several simulations to verify our theoretical findings.
Multimodal Learning for Non-small Cell Lung Cancer Prognosis
Nov 07, 2022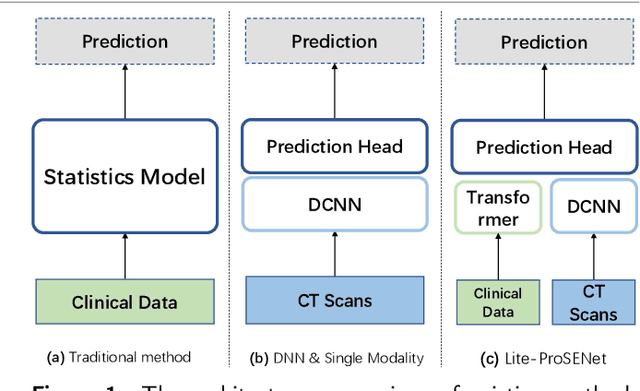
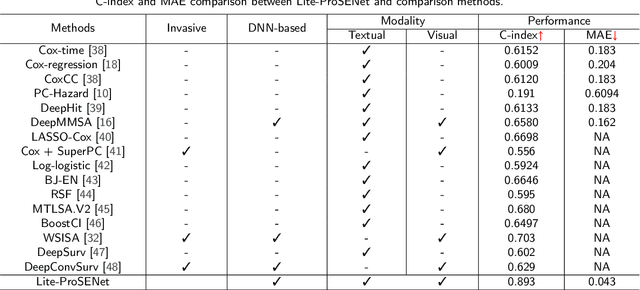
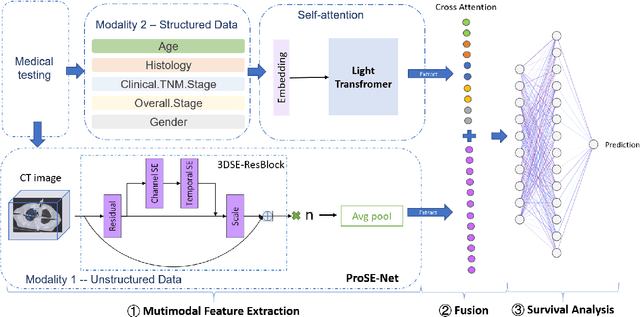
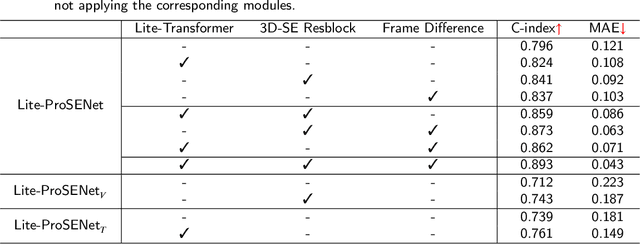
This paper focuses on the task of survival time analysis for lung cancer. Although much progress has been made in this problem in recent years, the performance of existing methods is still far from satisfactory. Traditional and some deep learning-based survival time analyses for lung cancer are mostly based on textual clinical information such as staging, age, histology, etc. Unlike existing methods that predicting on the single modality, we observe that a human clinician usually takes multimodal data such as text clinical data and visual scans to estimate survival time. Motivated by this, in this work, we contribute a smart cross-modality network for survival analysis network named Lite-ProSENet that simulates a human's manner of decision making. Extensive experiments were conducted using data from 422 NSCLC patients from The Cancer Imaging Archive (TCIA). The results show that our Lite-ProSENet outperforms favorably again all comparison methods and achieves the new state of the art with the 89.3% on concordance. The code will be made publicly available.
UniASM: Binary Code Similarity Detection without Fine-tuning
Nov 07, 2022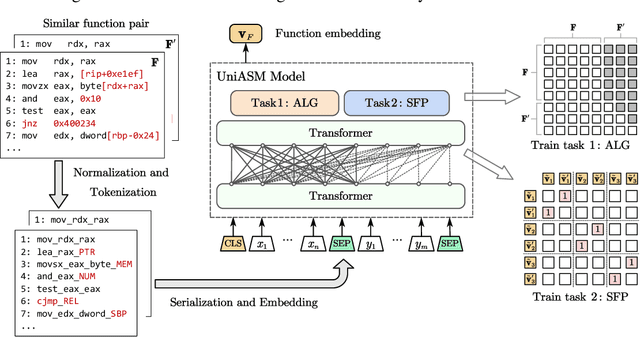
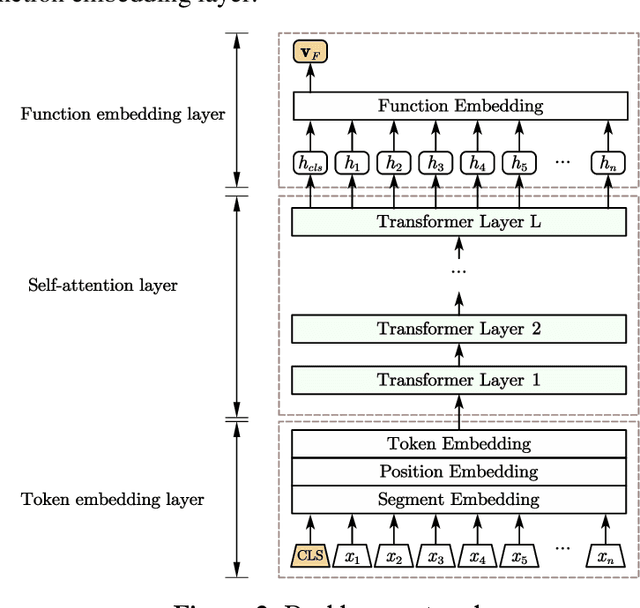

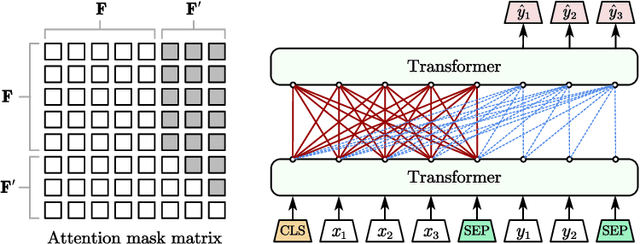
Binary code similarity detection (BCSD) is widely used in various binary analysis tasks such as vulnerability search, malware detection, clone detection, and patch analysis. Recent studies have shown that the learning-based binary code embedding models perform better than the traditional feature-based approaches. In this paper, we proposed a novel transformer-based binary code embedding model, named UniASM, to learn representations of the binary functions. We designed two new training tasks to make the spatial distribution of the generated vectors more uniform, which can be used directly in BCSD without any fine-tuning. In addition, we proposed a new tokenization approach for binary functions, increasing the token's semantic information while mitigating the out-of-vocabulary (OOV) problem. The experimental results show that UniASM outperforms state-of-the-art (SOTA) approaches on the evaluation dataset. We achieved the average scores of recall@1 on cross-compilers, cross-optimization-levels and cross-obfuscations are 0.72, 0.63, and 0.77, which is higher than existing SOTA baselines. In a real-world task of known vulnerability searching, UniASM outperforms all the current baselines.
Self-supervised video pretraining yields strong image representations
Oct 12, 2022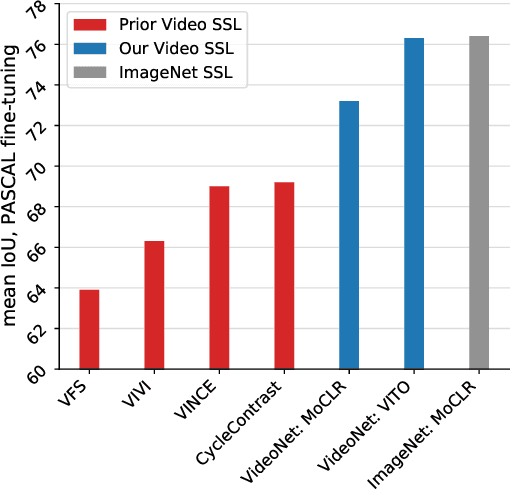
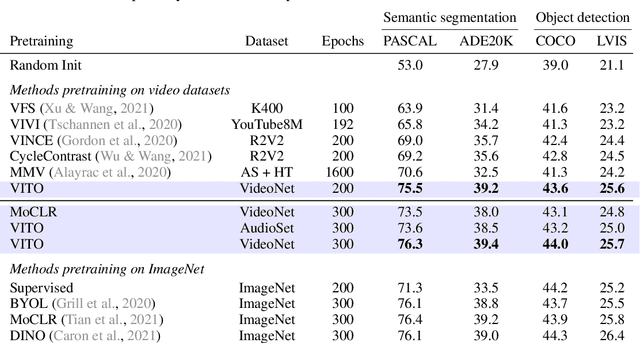
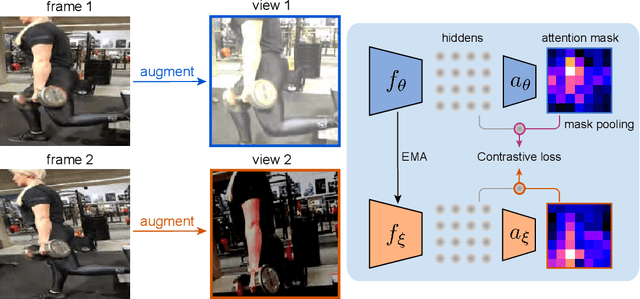
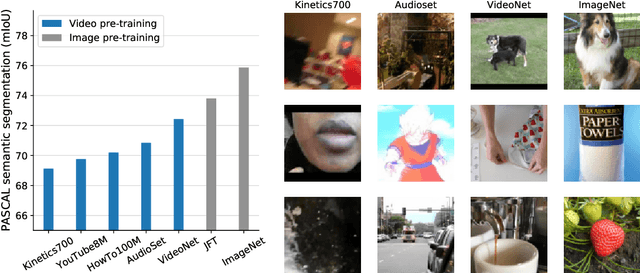
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.
Centralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning
Oct 12, 2022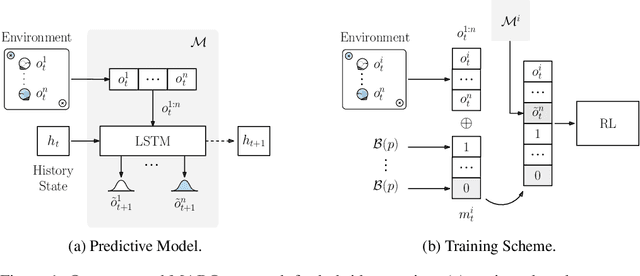
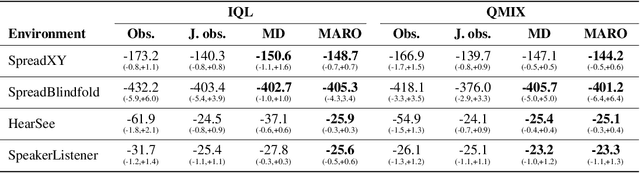
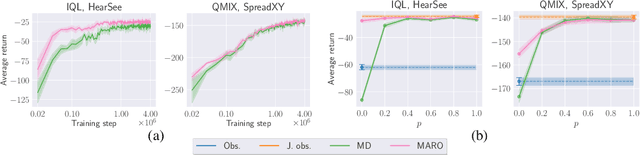
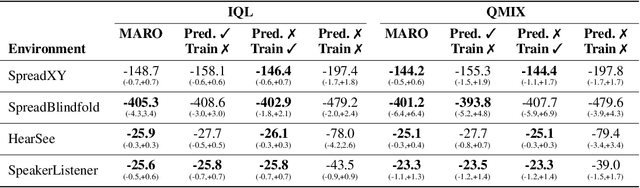
We introduce hybrid execution in multi-agent reinforcement learning (MARL), a new paradigm in which agents aim to successfully perform cooperative tasks with any communication level at execution time by taking advantage of information-sharing among the agents. Under hybrid execution, the communication level can range from a setting in which no communication is allowed between agents (fully decentralized), to a setting featuring full communication (fully centralized). To formalize our setting, we define a new class of multi-agent partially observable Markov decision processes (POMDPs) that we name hybrid-POMDPs, which explicitly models a communication process between the agents. We contribute MARO, an approach that combines an autoregressive predictive model to estimate missing agents' observations, and a dropout-based RL training scheme that simulates different communication levels during the centralized training phase. We evaluate MARO on standard scenarios and extensions of previous benchmarks tailored to emphasize the negative impact of partial observability in MARL. Experimental results show that our method consistently outperforms baselines, allowing agents to act with faulty communication while successfully exploiting shared information.
Beyond the density operator and Tr(ρA): Exploiting the higher-order statistics of random-coefficient pure states for quantum information processing
Apr 21, 2022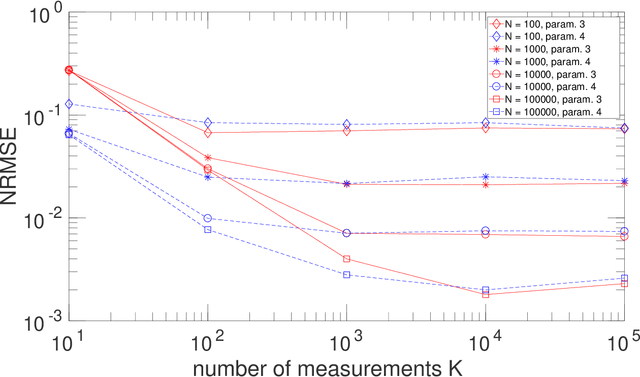
Two types of states are widely used in quantum mechanics, namely (deterministic-coefficient) pure states and statistical mixtures. A density operator can be associated with each of them. We here address a third type of states, that we previously introduced in a more restricted framework. These states generalize pure ones by replacing each of their deterministic ket coefficients by a random variable. We therefore call them Random-Coefficient Pure States, or RCPS. We analyze their properties and their relationships with both types of usual states. We show that RCPS contain much richer information than the density operator and mean of observables that we associate with them. This occurs because the latter operator only exploits the second-order statistics of the random state coefficients, whereas their higher-order statistics contain additional information. That information can be accessed in practice with the multiple-preparation procedure that we propose for RCPS, by using second-order and higher-order statistics of associated random probabilities of measurement outcomes. Exploiting these higher-order statistics opens the way to a very general approach for performing advanced quantum information processing tasks. We illustrate the relevance of this approach with a generic example, dealing with the estimation of parameters of a quantum process and thus related to quantum process tomography. This parameter estimation is performed in the non-blind (i.e. supervised) or blind (i.e. unsupervised) mode. We show that this problem cannot be solved by using only the density operator \rho of an RCPS and the associated mean value Tr(\rho A) of the operator A that corresponds to the considered physical quantity. We succeed in solving this problem by exploiting a fourth-order statistical parameter of state coefficients, in addition to second-order statistics. Numerical tests validate this result.
StyleSwap: Style-Based Generator Empowers Robust Face Swapping
Sep 27, 2022
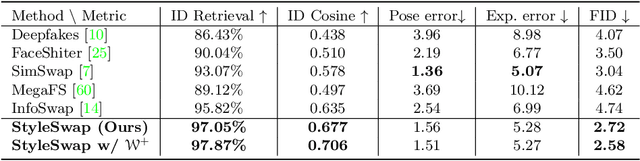
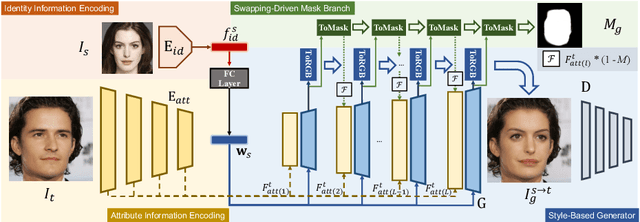

Numerous attempts have been made to the task of person-agnostic face swapping given its wide applications. While existing methods mostly rely on tedious network and loss designs, they still struggle in the information balancing between the source and target faces, and tend to produce visible artifacts. In this work, we introduce a concise and effective framework named StyleSwap. Our core idea is to leverage a style-based generator to empower high-fidelity and robust face swapping, thus the generator's advantage can be adopted for optimizing identity similarity. We identify that with only minimal modifications, a StyleGAN2 architecture can successfully handle the desired information from both source and target. Additionally, inspired by the ToRGB layers, a Swapping-Driven Mask Branch is further devised to improve information blending. Furthermore, the advantage of StyleGAN inversion can be adopted. Particularly, a Swapping-Guided ID Inversion strategy is proposed to optimize identity similarity. Extensive experiments validate that our framework generates high-quality face swapping results that outperform state-of-the-art methods both qualitatively and quantitatively.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.