 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NeuMap: Neural Coordinate Mapping by Auto-Transdecoder for Camera Localization
Nov 21, 2022
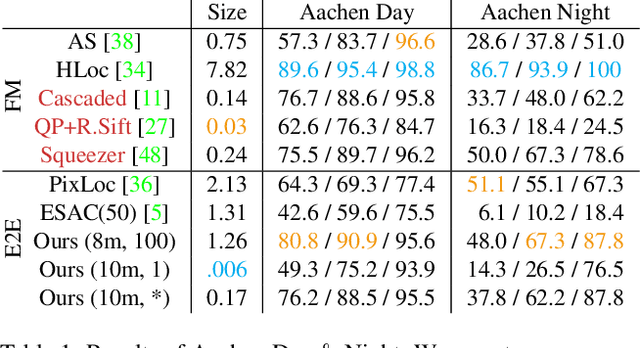
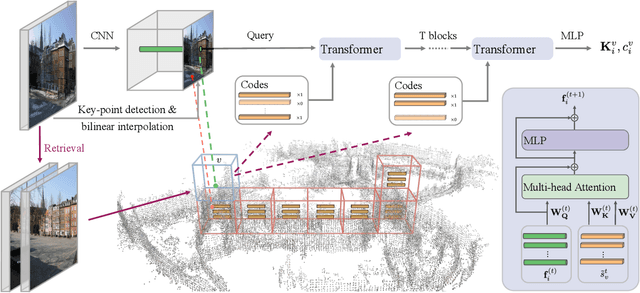


This paper presents an end-to-end neural mapping method for camera localization, encoding a whole scene into a grid of latent codes, with which a Transformer-based auto-decoder regresses 3D coordinates of query pixels. State-of-the-art camera localization methods require each scene to be stored as a 3D point cloud with per-point features, which takes several gigabytes of storage per scene. While compression is possible, the performance drops significantly at high compression rates. NeuMap achieves extremely high compression rates with minimal performance drop by using 1) learnable latent codes to store scene information and 2) a scene-agnostic Transformer-based auto-decoder to infer coordinates for a query pixel. The scene-agnostic network design also learns robust matching priors by training with large-scale data, and further allows us to just optimize the codes quickly for a new scene while fixing the network weights. Extensive evaluations with five benchmarks show that NeuMap outperforms all the other coordinate regression methods significantly and reaches similar performance as the feature matching methods while having a much smaller scene representation size. For example, NeuMap achieves 39.1% accuracy in Aachen night benchmark with only 6MB of data, while other compelling methods require 100MB or a few gigabytes and fail completely under high compression settings. The codes are available at https://github.com/Tangshitao/NeuMap.
Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification
Nov 21, 2022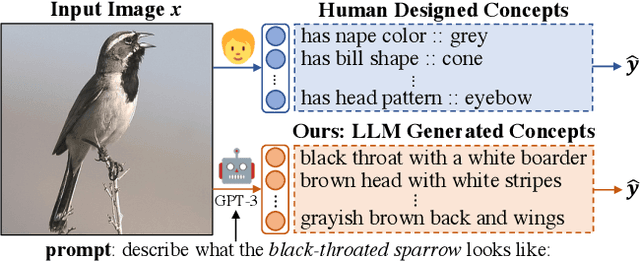

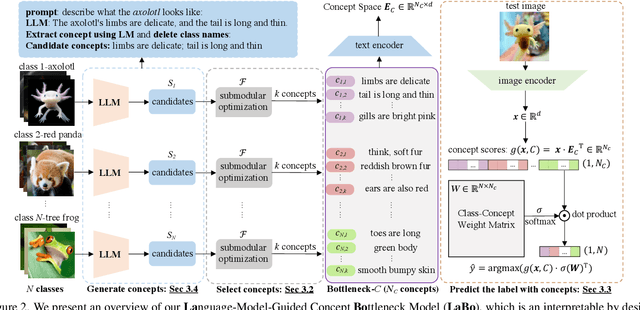

Concept Bottleneck Models (CBM) are inherently interpretable models that factor model decisions into human-readable concepts. They allow people to easily understand why a model is failing, a critical feature for high-stakes applications. CBMs require manually specified concepts and often under-perform their black box counterparts, preventing their broad adoption. We address these shortcomings and are first to show how to construct high-performance CBMs without manual specification of similar accuracy to black box models. Our approach, Language Guided Bottlenecks (LaBo), leverages a language model, GPT-3, to define a large space of possible bottlenecks. Given a problem domain, LaBo uses GPT-3 to produce factual sentences about categories to form candidate concepts. LaBo efficiently searches possible bottlenecks through a novel submodular utility that promotes the selection of discriminative and diverse information. Ultimately, GPT-3's sentential concepts can be aligned to images using CLIP, to form a bottleneck layer. Experiments demonstrate that LaBo is a highly effective prior for concepts important to visual recognition. In the evaluation with 11 diverse datasets, LaBo bottlenecks excel at few-shot classification: they are 11.7% more accurate than black box linear probes at 1 shot and comparable with more data. Overall, LaBo demonstrates that inherently interpretable models can be widely applied at similar, or better, performance than black box approaches.
Harmonic-Copuled Riccati Equations and its Applications in Distributed Filtering
Nov 21, 2022
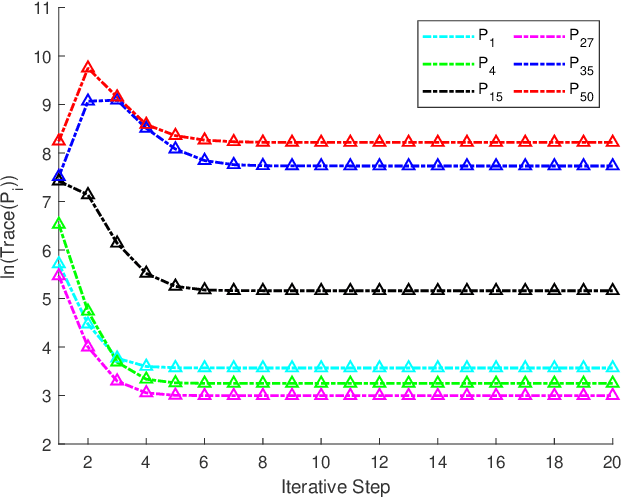
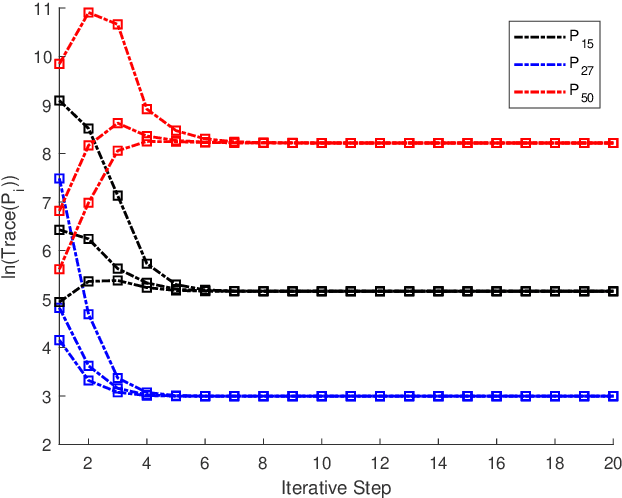
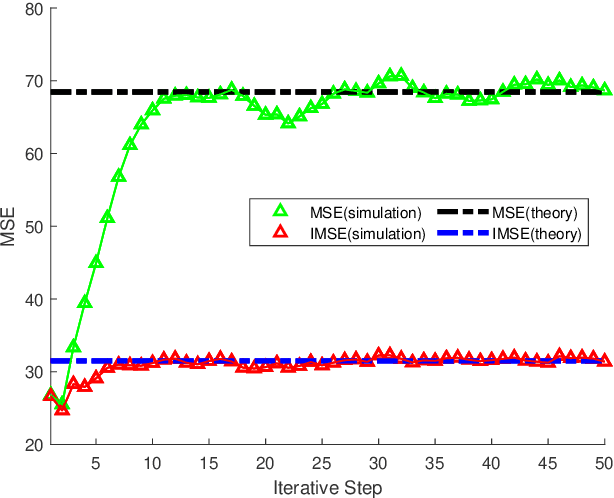
The coupled Riccati equations are cosisted of multiple Riccati-like equations with solutions coupled with each other, which can be applied to depict the properties of more complex systems such as markovian systems or multi-agent systems. This paper manages to formulate and investigate a new kind of coupled Riccati equations, called harmonic-coupled Riccati equations (HCRE), from the matrix iterative law of the consensus on information-based distributed filtering (CIDF) algortihm proposed in [1], where the solutions of the equations are coupled with harmonic means. Firstly, mild conditions of the existence and uniqueness of the solution to HCRE are induced with collective observability and primitiviness of weighting matrix. Then, it is proved that the matrix iterative law of CIDF will converge to the unique solution of the corresponding HCRE, hence can be used to obtain the solution to HCRE. Moreover, through applying the novel theory of HCRE, it is pointed out that the real estimation error covariance of CIDF will also become steady-state and the convergent value is simplified as the solution to a discrete time Lyapunov equation (DLE). Altogether, these new results develop the theory of the coupled Riccati equations, and provide a novel perspective on the performance analysis of CIDF algorithm, which sufficiently reduces the conservativeness of the evaluation techniques in the literature. Finally, the theoretical results are verified with numerical experiments.
Learn from Yesterday: A Semi-Supervised Continual Learning Method for Supervision-Limited Text-to-SQL Task Streams
Nov 21, 2022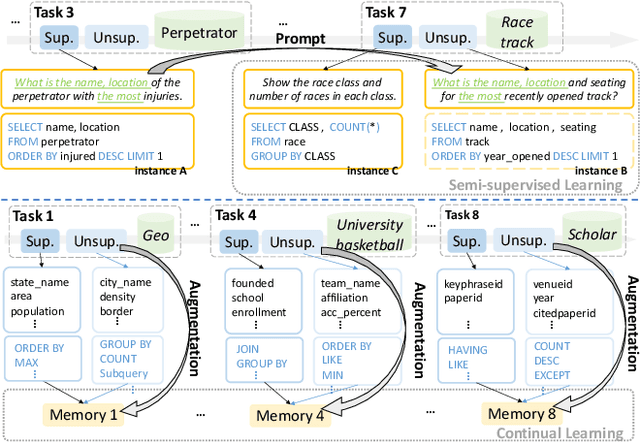
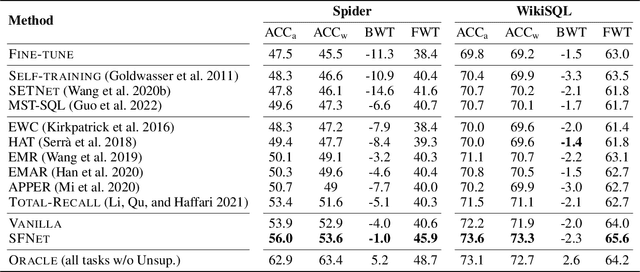
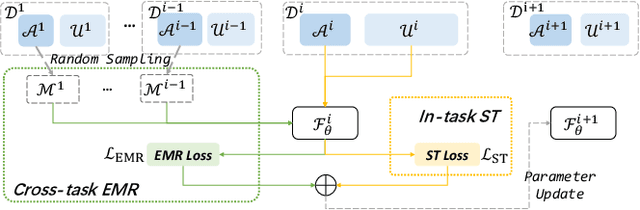
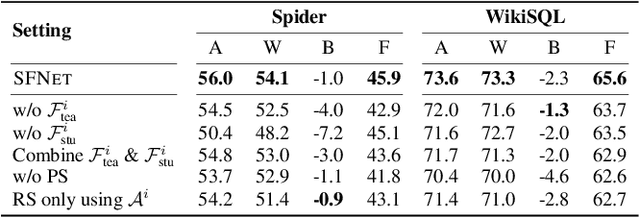
Conventional text-to-SQL studies are limited to a single task with a fixed-size training and test set. When confronted with a stream of tasks common in real-world applications, existing methods struggle with the problems of insufficient supervised data and high retraining costs. The former tends to cause overfitting on unseen databases for the new task, while the latter makes a full review of instances from past tasks impractical for the model, resulting in forgetting of learned SQL structures and database schemas. To address the problems, this paper proposes integrating semi-supervised learning (SSL) and continual learning (CL) in a stream of text-to-SQL tasks and offers two promising solutions in turn. The first solution Vanilla is to perform self-training, augmenting the supervised training data with predicted pseudo-labeled instances of the current task, while replacing the full volume retraining with episodic memory replay to balance the training efficiency with the performance of previous tasks. The improved solution SFNet takes advantage of the intrinsic connection between CL and SSL. It uses in-memory past information to help current SSL, while adding high-quality pseudo instances in memory to improve future replay. The experiments on two datasets shows that SFNet outperforms the widely-used SSL-only and CL-only baselines on multiple metrics.
A Dataset for Greek Traditional and Folk Music: Lyra
Nov 21, 2022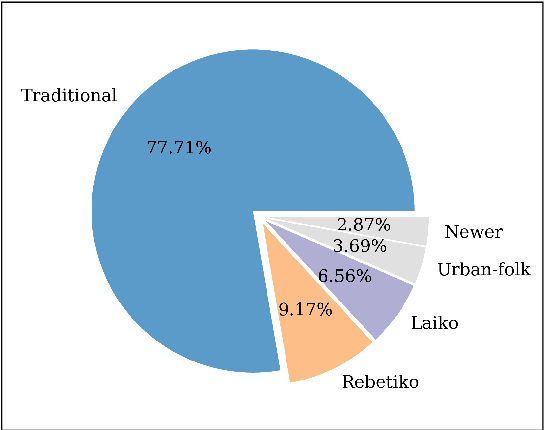
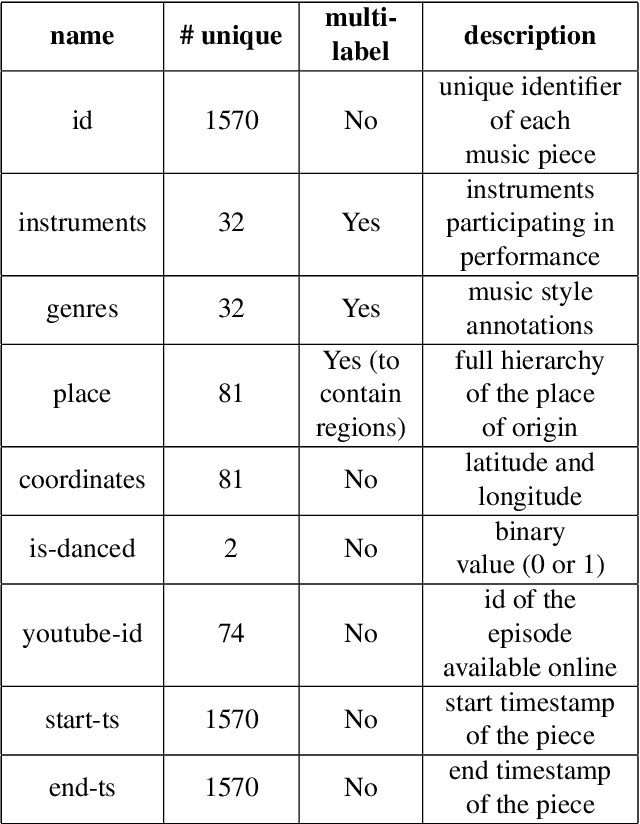
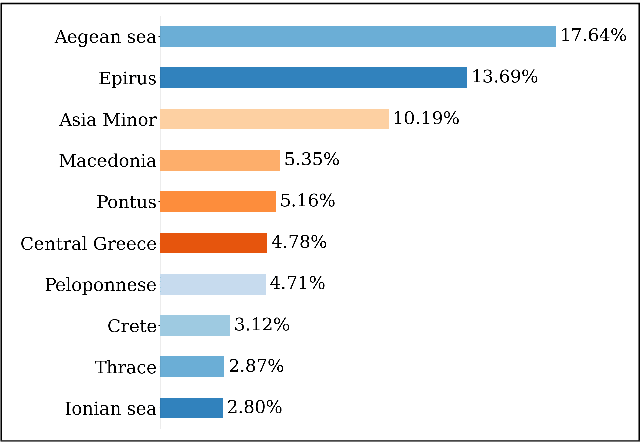
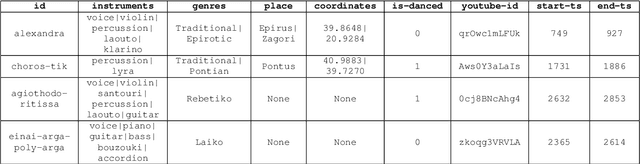
Studying under-represented music traditions under the MIR scope is crucial, not only for developing novel analysis tools, but also for unveiling musical functions that might prove useful in studying world musics. This paper presents a dataset for Greek Traditional and Folk music that includes 1570 pieces, summing in around 80 hours of data. The dataset incorporates YouTube timestamped links for retrieving audio and video, along with rich metadata information with regards to instrumentation, geography and genre, among others. The content has been collected from a Greek documentary series that is available online, where academics present music traditions of Greece with live music and dance performance during the show, along with discussions about social, cultural and musicological aspects of the presented music. Therefore, this procedure has resulted in a significant wealth of descriptions regarding a variety of aspects, such as musical genre, places of origin and musical instruments. In addition, the audio recordings were performed under strict production-level specifications, in terms of recording equipment, leading to very clean and homogeneous audio content. In this work, apart from presenting the dataset in detail, we propose a baseline deep-learning classification approach to recognize the involved musicological attributes. The dataset, the baseline classification methods and the models are provided in public repositories. Future directions for further refining the dataset are also discussed.
Deep Learning-Driven Edge Video Analytics: A Survey
Nov 28, 2022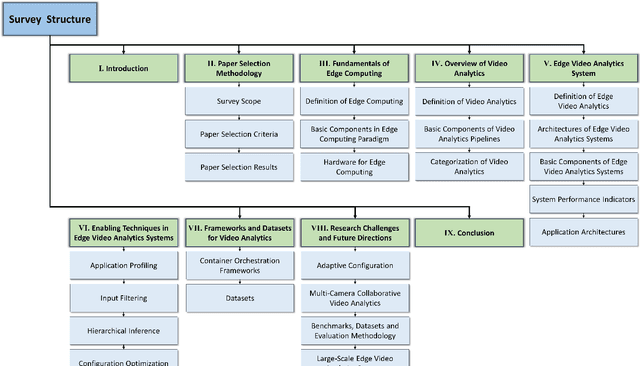
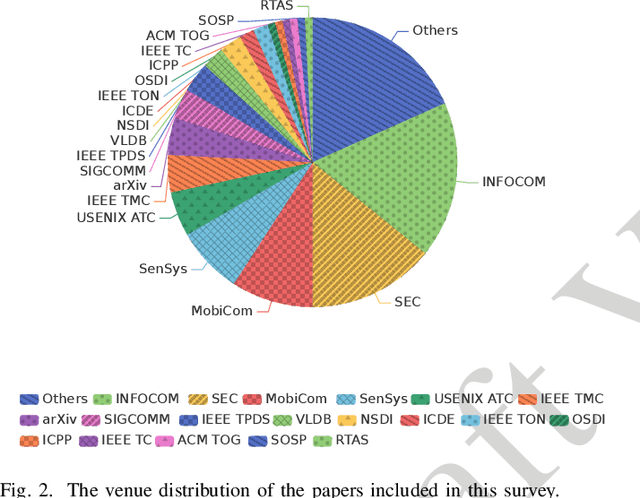
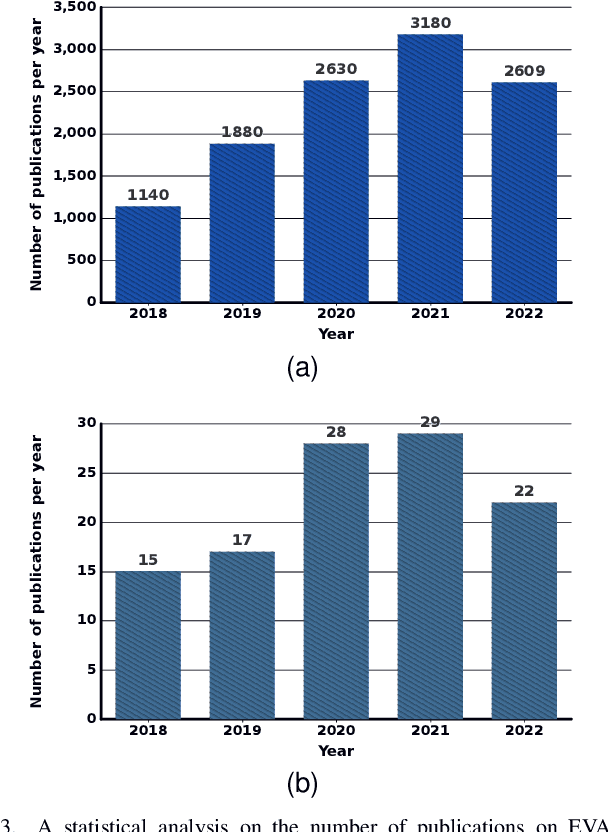
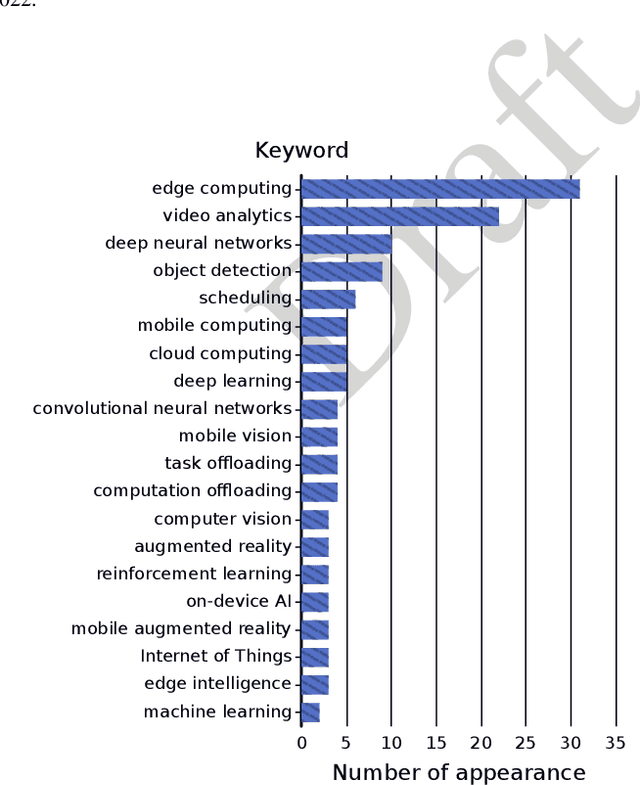
Video, as a key driver in the global explosion of digital information, can create tremendous benefits for human society. Governments and enterprises are deploying innumerable cameras for a variety of applications, e.g., law enforcement, emergency management, traffic control, and security surveillance, all facilitated by video analytics (VA). This trend is spurred by the rapid advancement of deep learning (DL), which enables more precise models for object classification, detection, and tracking. Meanwhile, with the proliferation of Internet-connected devices, massive amounts of data are generated daily, overwhelming the cloud. Edge computing, an emerging paradigm that moves workloads and services from the network core to the network edge, has been widely recognized as a promising solution. The resulting new intersection, edge video analytics (EVA), begins to attract widespread attention. Nevertheless, only a few loosely-related surveys exist on this topic. A dedicated venue for collecting and summarizing the latest advances of EVA is highly desired by the community. Besides, the basic concepts of EVA (e.g., definition, architectures, etc.) are ambiguous and neglected by these surveys due to the rapid development of this domain. A thorough clarification is needed to facilitate a consensus on these concepts. To fill in these gaps, we conduct a comprehensive survey of the recent efforts on EVA. In this paper, we first review the fundamentals of edge computing, followed by an overview of VA. The EVA system and its enabling techniques are discussed next. In addition, we introduce prevalent frameworks and datasets to aid future researchers in the development of EVA systems. Finally, we discuss existing challenges and foresee future research directions. We believe this survey will help readers comprehend the relationship between VA and edge computing, and spark new ideas on EVA.
SMiLE: Schema-augmented Multi-level Contrastive Learning for Knowledge Graph Link Prediction
Oct 10, 2022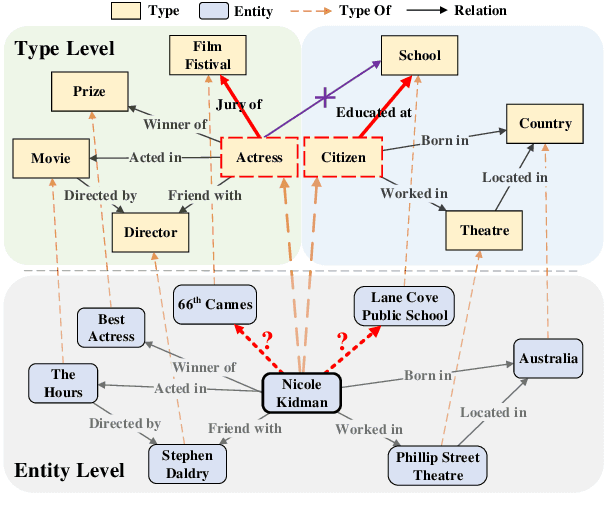
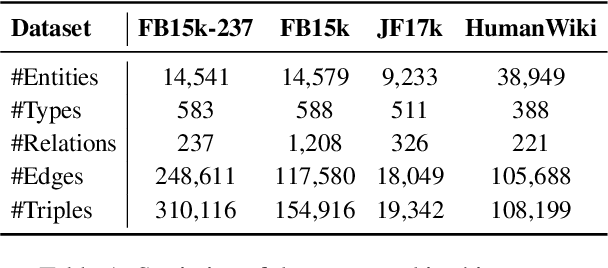
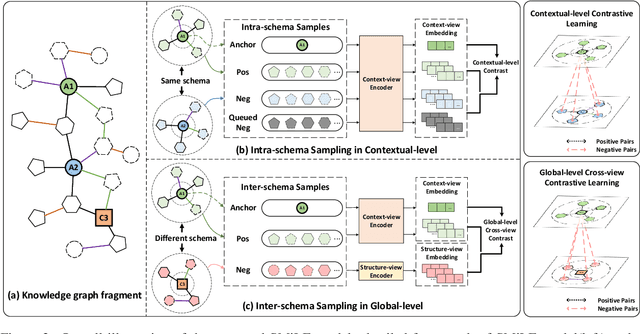
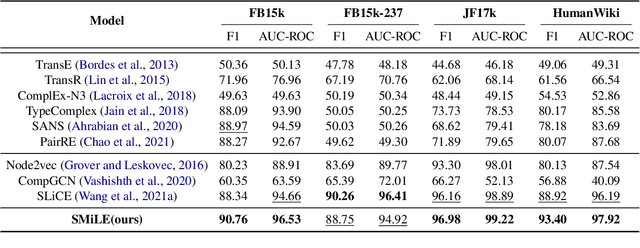
Link prediction is the task of inferring missing links between entities in knowledge graphs. Embedding-based methods have shown effectiveness in addressing this problem by modeling relational patterns in triples. However, the link prediction task often requires contextual information in entity neighborhoods, while most existing embedding-based methods fail to capture it. Additionally, little attention is paid to the diversity of entity representations in different contexts, which often leads to false prediction results. In this situation, we consider that the schema of knowledge graph contains the specific contextual information, and it is beneficial for preserving the consistency of entities across contexts. In this paper, we propose a novel schema-augmented multi-level contrastive learning framework (SMiLE) to conduct knowledge graph link prediction. Specifically, we first exploit network schema as the prior constraint to sample negatives and pre-train our model by employing a multi-level contrastive learning method to yield both prior schema and contextual information. Then we fine-tune our model under the supervision of individual triples to learn subtler representations for link prediction. Extensive experimental results on four knowledge graph datasets with thorough analysis of each component demonstrate the effectiveness of our proposed framework against state-of-the-art baselines.
Social Media Personal Event Notifier Using NLP and Machine Learning
Oct 10, 2022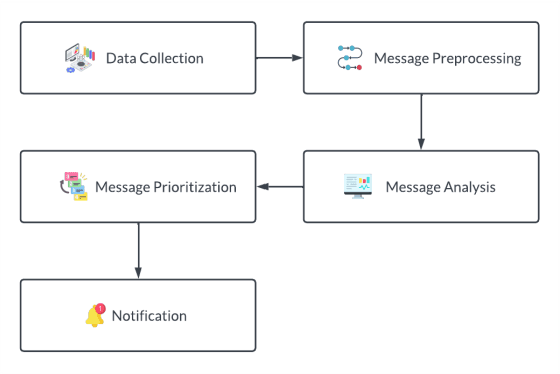
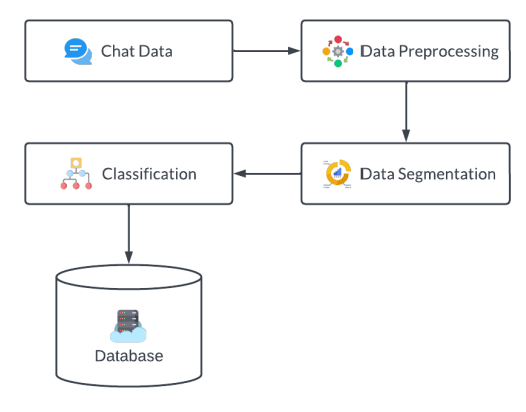
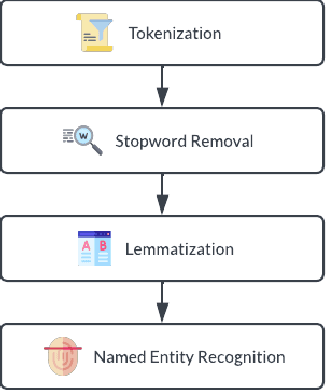
Social media apps have become very promising and omnipresent in daily life. Most social media apps are used to deliver vital information to those nearby and far away. As our lives become more hectic, many of us strive to limit our usage of social media apps because they are too addictive, and the majority of us have gotten preoccupied with our daily lives. Because of this, we frequently overlook crucial information, such as invitations to weddings, interviews, birthday parties, etc., or find ourselves unable to attend the event. In most cases, this happens because users are more likely to discover the invitation or information only before the event, giving them little time to prepare. To solve this issue, in this study, we created a system that will collect social media chat and filter it using Natural Language Processing (NLP) methods like Tokenization, Stop Words Removal, Lemmatization, Segmentation, and Named Entity Recognition (NER). Also, Machine Learning Algorithms such as K-Nearest Neighbor (KNN) Algorithm are implemented to prioritize the received invitation and to sort the level of priority. Finally, a customized notification will be delivered to the users where they acknowledge the upcoming event. So, the chances of missing the event are less or can be planned.
Unsupervised Deep Learning-based clustering for Human Activity Recognition
Nov 10, 2022
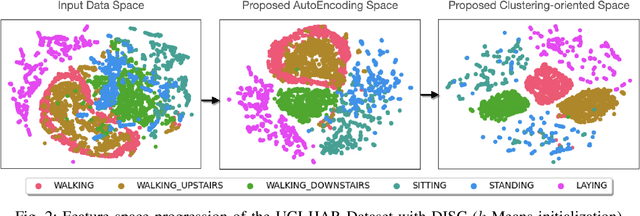
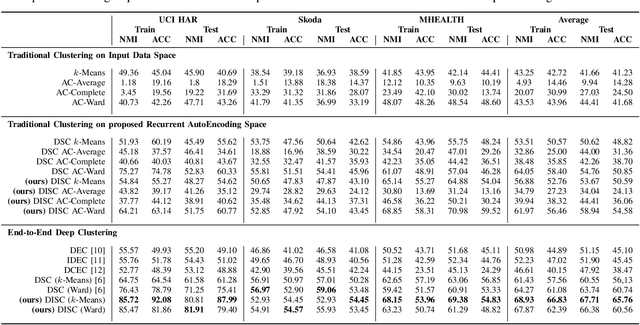
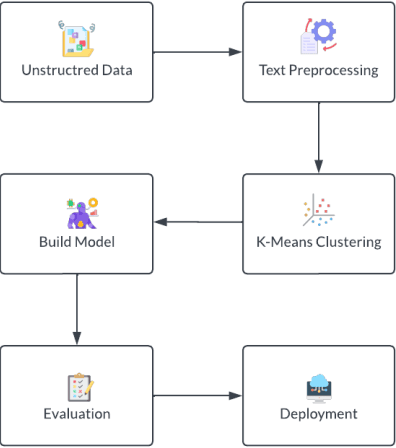
One of the main problems in applying deep learning techniques to recognize activities of daily living (ADLs) based on inertial sensors is the lack of appropriately large labelled datasets to train deep learning-based models. A large amount of data would be available due to the wide spread of mobile devices equipped with inertial sensors that can collect data to recognize human activities. Unfortunately, this data is not labelled. The paper proposes DISC (Deep Inertial Sensory Clustering), a DL-based clustering architecture that automatically labels multi-dimensional inertial signals. In particular, the architecture combines a recurrent AutoEncoder and a clustering criterion to predict unlabelled human activities-related signals. The proposed architecture is evaluated on three publicly available HAR datasets and compared with four well-known end-to-end deep clustering approaches. The experiments demonstrate the effectiveness of DISC on both clustering accuracy and normalized mutual information metrics.
Prior-enhanced Temporal Action Localization using Subject-aware Spatial Attention
Nov 10, 2022
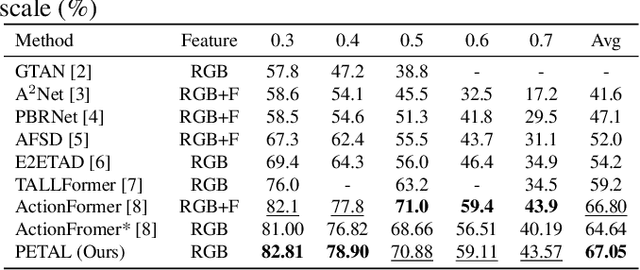
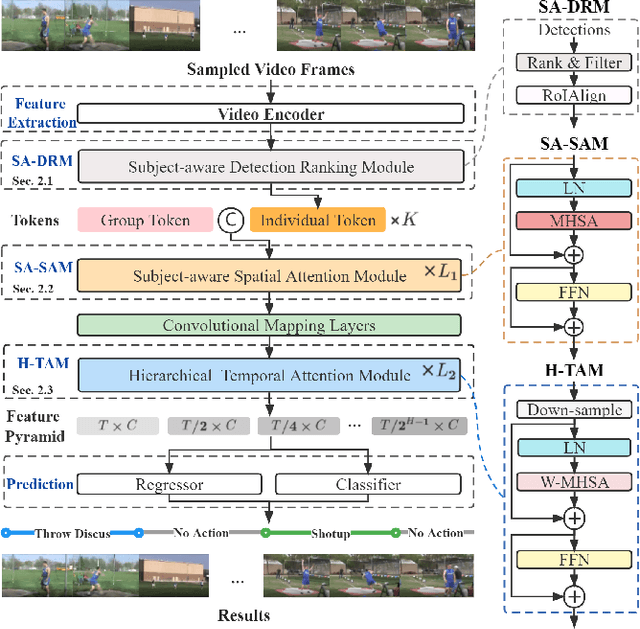
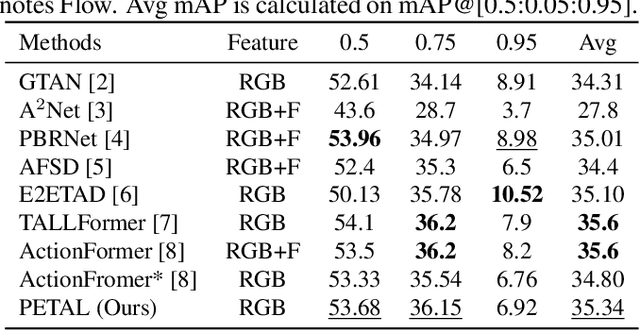
Temporal action localization (TAL) aims to detect the boundary and identify the class of each action instance in a long untrimmed video. Current approaches treat video frames homogeneously, and tend to give background and key objects excessive attention. This limits their sensitivity to localize action boundaries. To this end, we propose a prior-enhanced temporal action localization method (PETAL), which only takes in RGB input and incorporates action subjects as priors. This proposal leverages action subjects' information with a plug-and-play subject-aware spatial attention module (SA-SAM) to generate an aggregated and subject-prioritized representation. Experimental results on THUMOS-14 and ActivityNet-1.3 datasets demonstrate that the proposed PETAL achieves competitive performance using only RGB features, e.g., boosting mAP by 2.41% or 0.25% over the state-of-the-art approach that uses RGB features or with additional optical flow features on the THUMOS-14 dataset.