 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Problem Behaviors Recognition in Videos using Language-Assisted Deep Learning Model for Children with Autism
Nov 17, 2022


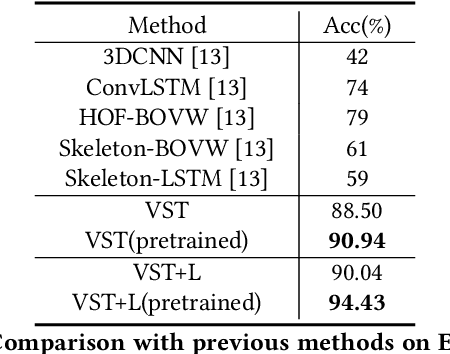
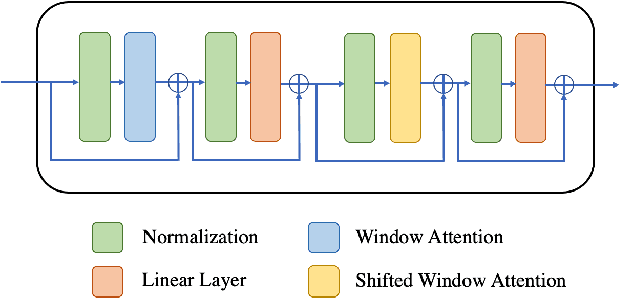
Correctly recognizing the behaviors of children with Autism Spectrum Disorder (ASD) is of vital importance for the diagnosis of Autism and timely early intervention. However, the observation and recording during the treatment from the parents of autistic children may not be accurate and objective. In such cases, automatic recognition systems based on computer vision and machine learning (in particular deep learning) technology can alleviate this issue to a large extent. Existing human action recognition models can now achieve persuasive performance on challenging activity datasets, e.g. daily activity, and sports activity. However, problem behaviors in children with ASD are very different from these general activities, and recognizing these problem behaviors via computer vision is less studied. In this paper, we first evaluate a strong baseline for action recognition, i.e. Video Swin Transformer, on two autism behaviors datasets (SSBD and ESBD) and show that it can achieve high accuracy and outperform the previous methods by a large margin, demonstrating the feasibility of vision-based problem behaviors recognition. Moreover, we propose language-assisted training to further enhance the action recognition performance. Specifically, we develop a two-branch multimodal deep learning framework by incorporating the "freely available" language description for each type of problem behavior. Experimental results demonstrate that incorporating additional language supervision can bring an obvious performance boost for the autism problem behaviors recognition task as compared to using the video information only (i.e. 3.49% improvement on ESBD and 1.46% on SSBD).
Layout Aware Inpainting for Automated Furniture Removal in Indoor Scenes
Oct 27, 2022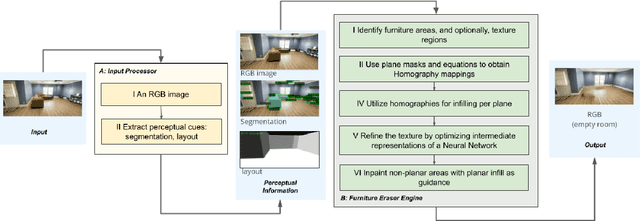



We address the problem of detecting and erasing furniture from a wide angle photograph of a room. Inpainting large regions of an indoor scene often results in geometric inconsistencies of background elements within the inpaint mask. To address this problem, we utilize perceptual information (e.g. instance segmentation, and room layout) to produce a geometrically consistent empty version of a room. We share important details to make this system viable, such as per-plane inpainting, automatic rectification, and texture refinement. We provide detailed ablation along with qualitative examples, justifying our design choices. We show an application of our system by removing real furniture from a room and redecorating it with virtual furniture.
Forecasting Graph Signals with Recursive MIMO Graph Filters
Oct 27, 2022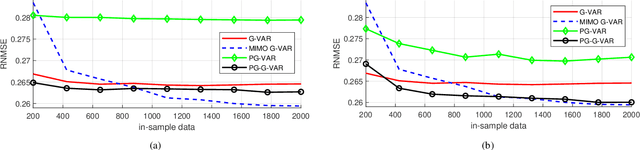
Forecasting time series on graphs is a fundamental problem in graph signal processing. When each entity of the network carries a vector of values for each time stamp instead of a scalar one, existing approaches resort to the use of product graphs to combine this multidimensional information, at the expense of creating a larger graph. In this paper, we show the limitations of such approaches, and propose extensions to tackle them. Then, we propose a recursive multiple-input multiple-output graph filter which encompasses many already existing models in the literature while being more flexible. Numerical simulations on a real world data set show the effectiveness of the proposed models.
Leveraging Intrinsic Gradient Information for Machine Learning Model Training
Nov 30, 2021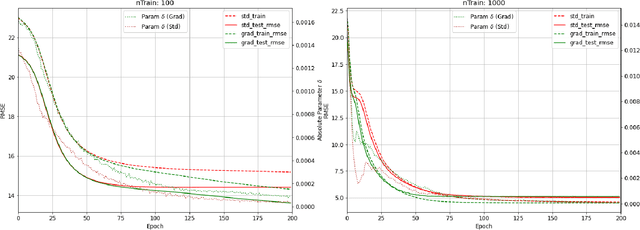
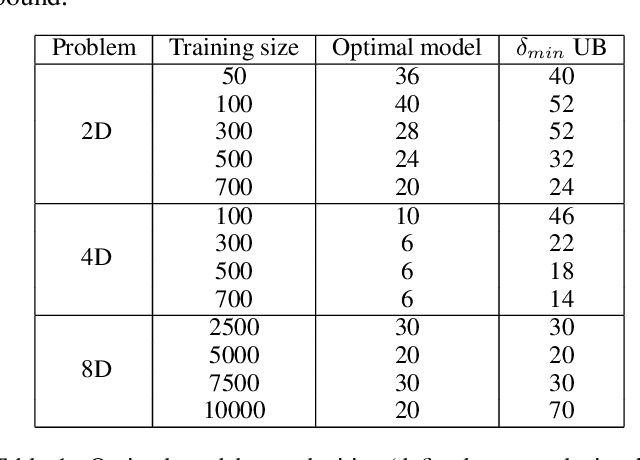
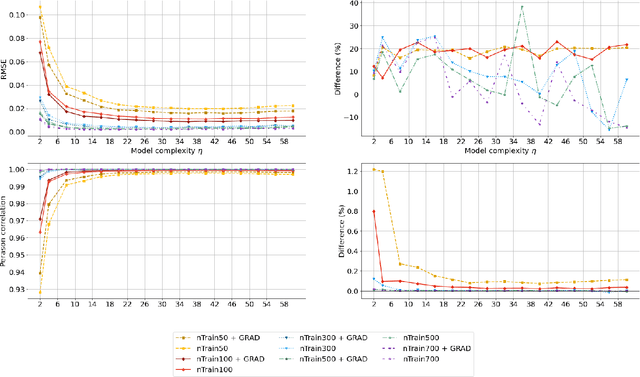

Designing models that produce accurate predictions is the fundamental objective of machine learning. This work presents methods demonstrating that when the derivatives of target variables with respect to inputs can be extracted from processes of interest, they can be leveraged to improve the accuracy of differentiable machine learning models. Four key ideas are explored: (1) Improving the predictive accuracy of linear regression models and feed-forward neural networks (NNs); (2) Using the difference between the performance of feedforward NNs trained with and without gradient information to tune NN complexity (in the form of hidden node number); (3) Using gradient information to regularise linear regression; and (4) Using gradient information to improve generative image models. Across this variety of applications, gradient information is shown to enhance each predictive model, demonstrating its value for a variety of applications.
A Dataset and Model for Crossing Indian Roads
Nov 15, 2022

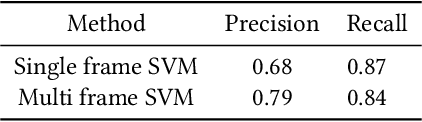
Roads in medium-sized Indian towns often have lots of traffic but no (or disregarded) traffic stops. This makes it hard for the blind to cross roads safely, because vision is crucial to determine when crossing is safe. Automatic and reliable image-based safety classifiers thus have the potential to help the blind to cross Indian roads. Yet, we currently lack datasets collected on Indian roads from the pedestrian point-of-view, labelled with road crossing safety information. Existing classifiers from other countries are often intended for crossroads, and hence rely on the detection and presence of traffic lights, which is not applicable in Indian conditions. We introduce INDRA (INdian Dataset for RoAd crossing), the first dataset capturing videos of Indian roads from the pedestrian point-of-view. INDRA contains 104 videos comprising of 26k 1080p frames, each annotated with a binary road crossing safety label and vehicle bounding boxes. We train various classifiers to predict road crossing safety on this data, ranging from SVMs to convolutional neural networks (CNNs). The best performing model DilatedRoadCrossNet is a novel single-image architecture tailored for deployment on the Nvidia Jetson Nano. It achieves 79% recall at 90% precision on unseen images. Lastly, we present a wearable road crossing assistant running DilatedRoadCrossNet, which can help the blind cross Indian roads in real-time. The project webpage is http://roadcross-assistant.github.io/Website/.
An Automatic ICD Coding Network Using Partition-Based Label Attention
Nov 15, 2022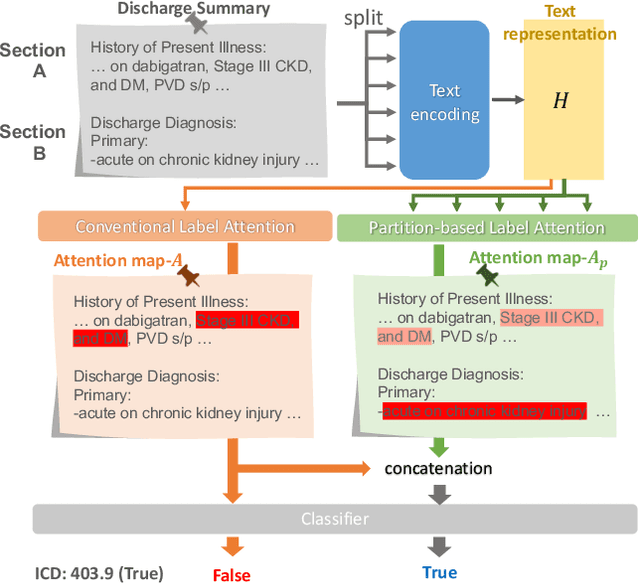
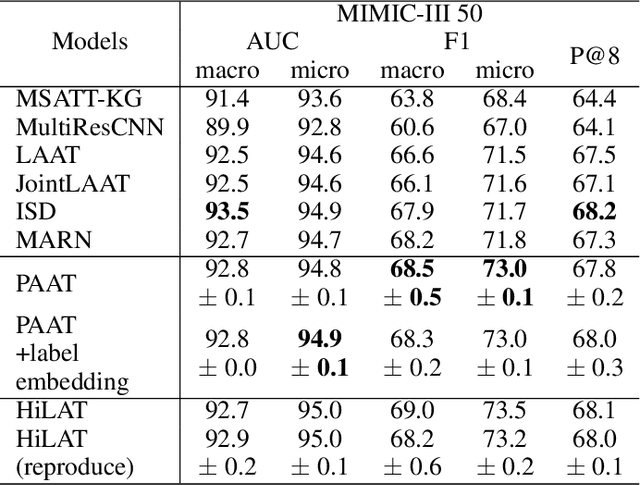
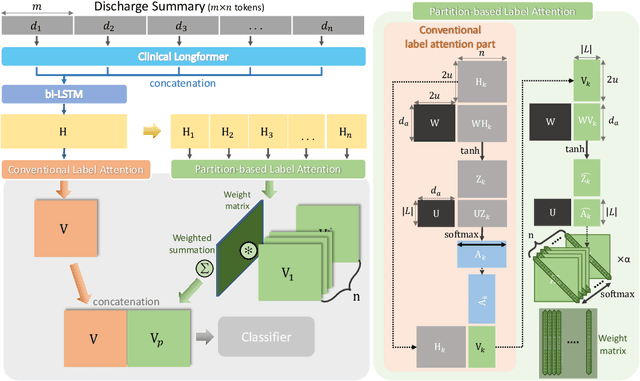
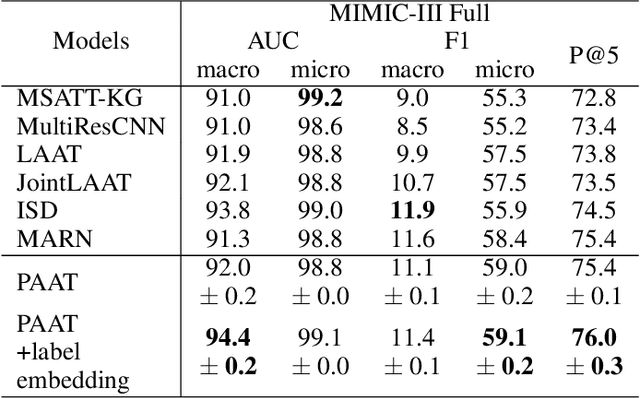
International Classification of Diseases (ICD) is a global medical classification system which provides unique codes for diagnoses and procedures appropriate to a patient's clinical record. However, manual coding by human coders is expensive and error-prone. Automatic ICD coding has the potential to solve this problem. With the advancement of deep learning technologies, many deep learning-based methods for automatic ICD coding are being developed. In particular, a label attention mechanism is effective for multi-label classification, i.e., the ICD coding. It effectively obtains the label-specific representations from the input clinical records. However, because the existing label attention mechanism finds key tokens in the entire text at once, the important information dispersed in each paragraph may be omitted from the attention map. To overcome this, we propose a novel neural network architecture composed of two parts of encoders and two kinds of label attention layers. The input text is segmentally encoded in the former encoder and integrated by the follower. Then, the conventional and partition-based label attention mechanisms extract important global and local feature representations. Our classifier effectively integrates them to enhance the ICD coding performance. We verified the proposed method using the MIMIC-III, a benchmark dataset of the ICD coding. Our results show that our network improves the ICD coding performance based on the partition-based mechanism.
Discovering material information using hierarchical Reformer model on financial regulatory filings
Mar 28, 2022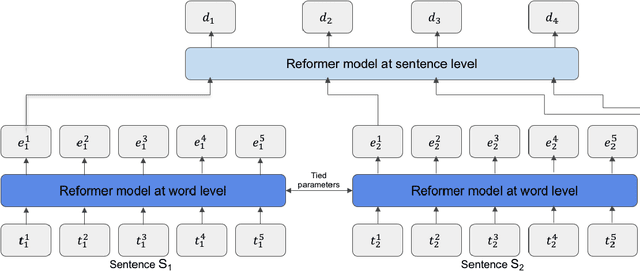

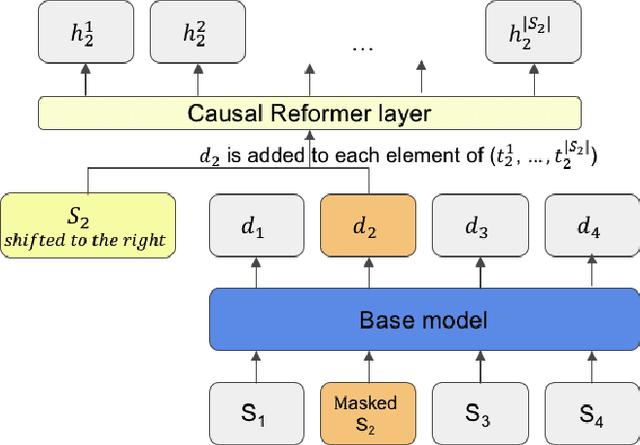

Most applications of machine learning for finance are related to forecasting tasks for investment decisions. Instead, we aim to promote a better understanding of financial markets with machine learning techniques. Leveraging the tremendous progress in deep learning models for natural language processing, we construct a hierarchical Reformer ([15]) model capable of processing a large document level dataset, SEDAR, from canadian financial regulatory filings. Using this model, we show that it is possible to predict trade volume changes using regulatory filings. We adapt the pretraining task of HiBERT ([36]) to obtain good sentence level representations using a large unlabelled document dataset. Finetuning the model to successfully predict trade volume changes indicates that the model captures a view from financial markets and processing regulatory filings is beneficial. Analyzing the attention patterns of our model reveals that it is able to detect some indications of material information without explicit training, which is highly relevant for investors and also for the market surveillance mandate of financial regulators.
APAUNet: Axis Projection Attention UNet for Small Target in 3D Medical Segmentation
Oct 04, 2022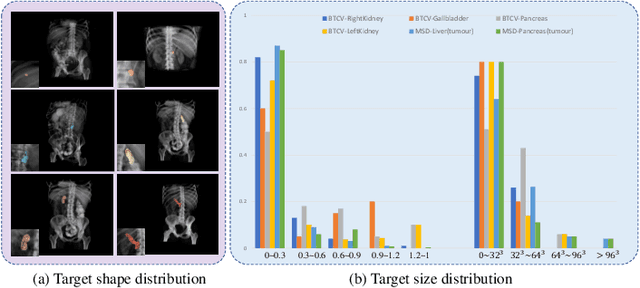
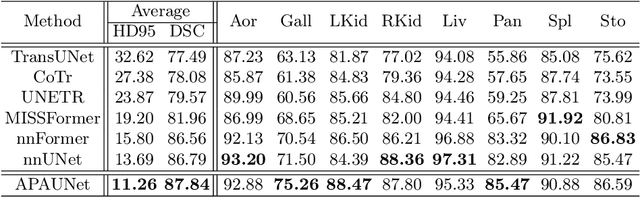
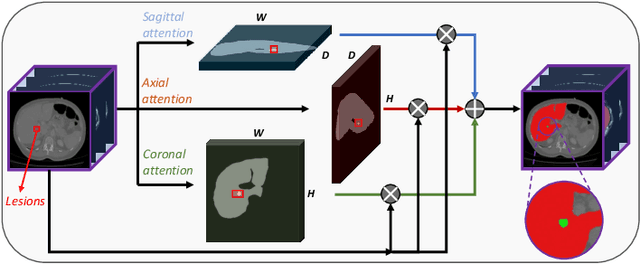
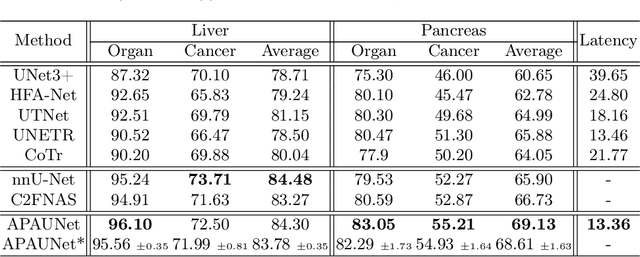
In 3D medical image segmentation, small targets segmentation is crucial for diagnosis but still faces challenges. In this paper, we propose the Axis Projection Attention UNet, named APAUNet, for 3D medical image segmentation, especially for small targets. Considering the large proportion of the background in the 3D feature space, we introduce a projection strategy to project the 3D features into three orthogonal 2D planes to capture the contextual attention from different views. In this way, we can filter out the redundant feature information and mitigate the loss of critical information for small lesions in 3D scans. Then we utilize a dimension hybridization strategy to fuse the 3D features with attention from different axes and merge them by a weighted summation to adaptively learn the importance of different perspectives. Finally, in the APA Decoder, we concatenate both high and low resolution features in the 2D projection process, thereby obtaining more precise multi-scale information, which is vital for small lesion segmentation. Quantitative and qualitative experimental results on two public datasets (BTCV and MSD) demonstrate that our proposed APAUNet outperforms the other methods. Concretely, our APAUNet achieves an average dice score of 87.84 on BTCV, 84.48 on MSD-Liver and 69.13 on MSD-Pancreas, and significantly surpass the previous SOTA methods on small targets.
Disentangled Speech Representation Learning for One-Shot Cross-lingual Voice Conversion Using $β$-VAE
Oct 25, 2022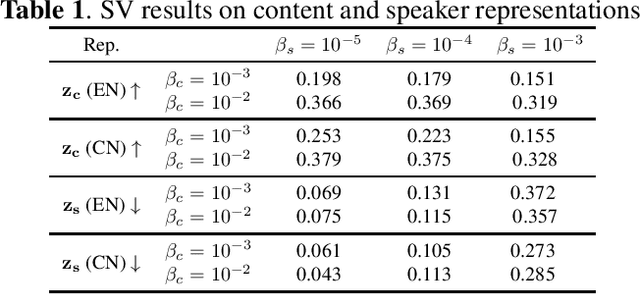
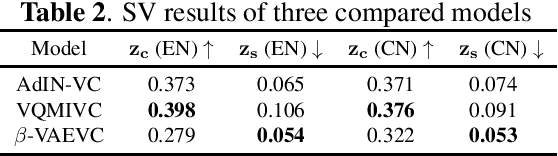
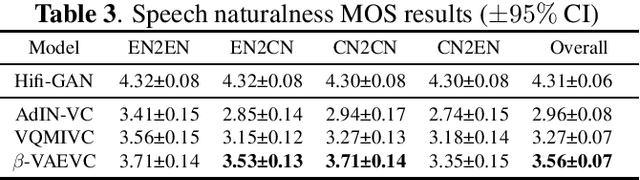
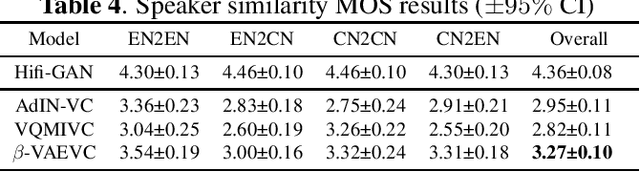
We propose an unsupervised learning method to disentangle speech into content representation and speaker identity representation. We apply this method to the challenging one-shot cross-lingual voice conversion task to demonstrate the effectiveness of the disentanglement. Inspired by $\beta$-VAE, we introduce a learning objective that balances between the information captured by the content and speaker representations. In addition, the inductive biases from the architectural design and the training dataset further encourage the desired disentanglement. Both objective and subjective evaluations show the effectiveness of the proposed method in speech disentanglement and in one-shot cross-lingual voice conversion.
Efficient View Path Planning for Autonomous Implicit Reconstruction
Sep 27, 2022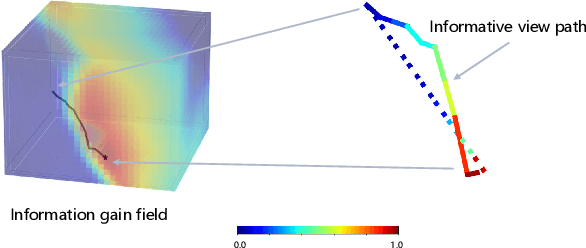
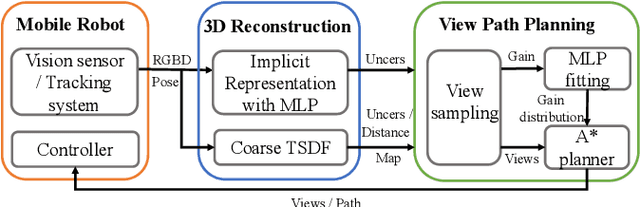


Implicit neural representations have shown promising potential for the 3D scene reconstruction. Recent work applies it to autonomous 3D reconstruction by learning information gain for view path planning. Effective as it is, the computation of the information gain is expensive, and compared with that using volumetric representations, collision checking using the implicit representation for a 3D point is much slower. In the paper, we propose to 1) leverage a neural network as an implicit function approximator for the information gain field and 2) combine the implicit fine-grained representation with coarse volumetric representations to improve efficiency. Further with the improved efficiency, we propose a novel informative path planning based on a graph-based planner. Our method demonstrates significant improvements in the reconstruction quality and planning efficiency compared with autonomous reconstructions with implicit and explicit representations. We deploy the method on a real UAV and the results show that our method can plan informative views and reconstruct a scene with high quality.