 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large Language Models in Fire Engineering: An Examination of Technical Questions Against Domain Knowledge
Mar 04, 2024
This communication presents preliminary findings from comparing two recent chatbots, OpenAI's ChatGPT and Google's Bard, in the context of fire engineering by evaluating their responses in handling fire safety related queries. A diverse range of fire engineering questions and scenarios were created and examined, including structural fire design, fire prevention strategies, evacuation, building code compliance, and fire suppression systems (some of which resemble those commonly present in the Fire Protection exam (FPE)). The results reveal some key differences in the performance of the chatbots, with ChatGPT demonstrating a relatively superior performance. Then, this communication highlights the potential for chatbot technology to revolutionize fire engineering practices by providing instant access to critical information while outlining areas for further improvement and research. Evidently, and when it matures, this technology will likely be elemental to our engineers' practice and education.
Knockoff-Guided Feature Selection via A Single Pre-trained Reinforced Agent
Mar 06, 2024
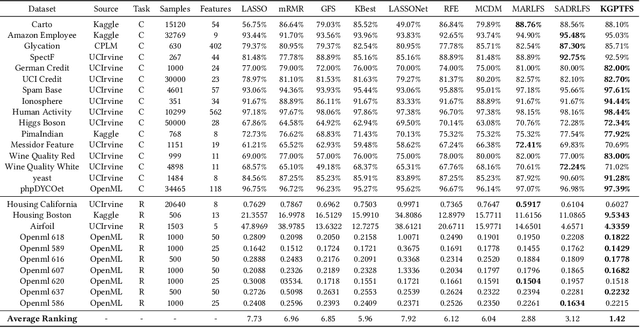
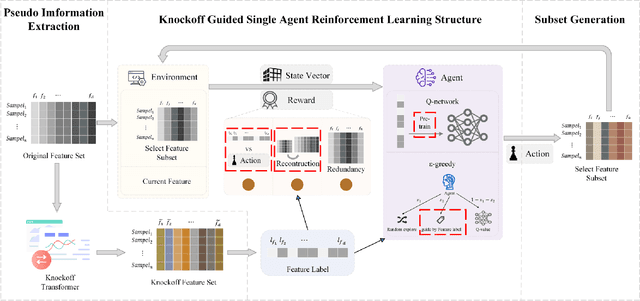
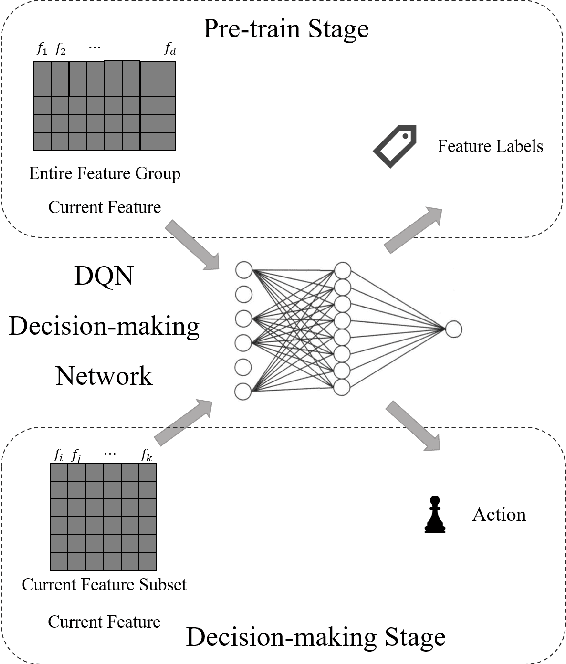
Feature selection prepares the AI-readiness of data by eliminating redundant features. Prior research falls into two primary categories: i) Supervised Feature Selection, which identifies the optimal feature subset based on their relevance to the target variable; ii) Unsupervised Feature Selection, which reduces the feature space dimensionality by capturing the essential information within the feature set instead of using target variable. However, SFS approaches suffer from time-consuming processes and limited generalizability due to the dependence on the target variable and downstream ML tasks. UFS methods are constrained by the deducted feature space is latent and untraceable. To address these challenges, we introduce an innovative framework for feature selection, which is guided by knockoff features and optimized through reinforcement learning, to identify the optimal and effective feature subset. In detail, our method involves generating "knockoff" features that replicate the distribution and characteristics of the original features but are independent of the target variable. Each feature is then assigned a pseudo label based on its correlation with all the knockoff features, serving as a novel metric for feature evaluation. Our approach utilizes these pseudo labels to guide the feature selection process in 3 novel ways, optimized by a single reinforced agent: 1). A deep Q-network, pre-trained with the original features and their corresponding pseudo labels, is employed to improve the efficacy of the exploration process in feature selection. 2). We introduce unsupervised rewards to evaluate the feature subset quality based on the pseudo labels and the feature space reconstruction loss to reduce dependencies on the target variable. 3). A new {\epsilon}-greedy strategy is used, incorporating insights from the pseudo labels to make the feature selection process more effective.
Out-of-Distribution Detection using Neural Activation Prior
Mar 06, 2024Out-of-distribution detection (OOD) is a crucial technique for deploying machine learning models in the real world to handle the unseen scenarios. In this paper, we first propose a simple yet effective Neural Activation Prior (NAP) for OOD detection. Our neural activation prior is based on a key observation that, for a channel before the global pooling layer of a fully trained neural network, the probability of a few neurons being activated with a large response by an in-distribution (ID) sample is significantly higher than that by an OOD sample. An intuitive explanation is that for a model fully trained on ID dataset, each channel would play a role in detecting a certain pattern in the ID dataset, and a few neurons can be activated with a large response when the pattern is detected in an input sample. Then, a new scoring function based on this prior is proposed to highlight the role of these strongly activated neurons in OOD detection. Our approach is plug-and-play and does not lead to any performance degradation on ID data classification and requires no extra training or statistics from training or external datasets. Notice that previous methods primarily rely on post-global-pooling features of the neural networks, while the within-channel distribution information we leverage would be discarded by the global pooling operator. Consequently, our method is orthogonal to existing approaches and can be effectively combined with them in various applications. Experimental results show that our method achieves the state-of-the-art performance on CIFAR benchmark and ImageNet dataset, which demonstrates the power of the proposed prior. Finally, we extend our method to Transformers and the experimental findings indicate that NAP can also significantly enhance the performance of OOD detection on Transformers, thereby demonstrating the broad applicability of this prior knowledge.
Wildest Dreams: Reproducible Research in Privacy-preserving Neural Network Training
Mar 06, 2024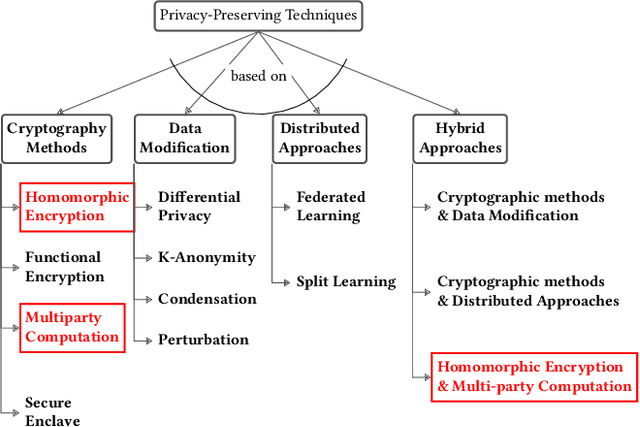
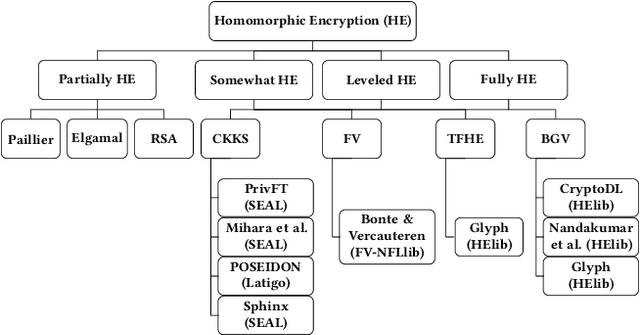
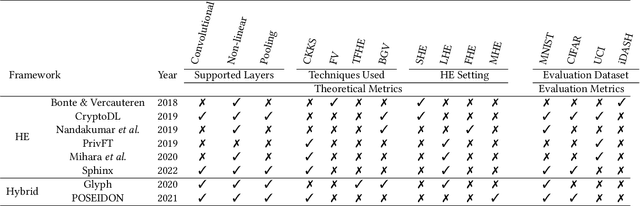
Machine Learning (ML), addresses a multitude of complex issues in multiple disciplines, including social sciences, finance, and medical research. ML models require substantial computing power and are only as powerful as the data utilized. Due to high computational cost of ML methods, data scientists frequently use Machine Learning-as-a-Service (MLaaS) to outsource computation to external servers. However, when working with private information, like financial data or health records, outsourcing the computation might result in privacy issues. Recent advances in Privacy-Preserving Techniques (PPTs) have enabled ML training and inference over protected data through the use of Privacy-Preserving Machine Learning (PPML). However, these techniques are still at a preliminary stage and their application in real-world situations is demanding. In order to comprehend discrepancy between theoretical research suggestions and actual applications, this work examines the past and present of PPML, focusing on Homomorphic Encryption (HE) and Secure Multi-party Computation (SMPC) applied to ML. This work primarily focuses on the ML model's training phase, where maintaining user data privacy is of utmost importance. We provide a solid theoretical background that eases the understanding of current approaches and their limitations. In addition, we present a SoK of the most recent PPML frameworks for model training and provide a comprehensive comparison in terms of the unique properties and performances on standard benchmarks. Also, we reproduce the results for some of the papers and examine at what level existing works in the field provide support for open science. We believe our work serves as a valuable contribution by raising awareness about the current gap between theoretical advancements and real-world applications in PPML, specifically regarding open-source availability, reproducibility, and usability.
Mixer is more than just a model
Feb 28, 2024Recently, MLP structures have regained popularity, with MLP-Mixer standing out as a prominent example. In the field of computer vision, MLP-Mixer is noted for its ability to extract data information from both channel and token perspectives, effectively acting as a fusion of channel and token information. Indeed, Mixer represents a paradigm for information extraction that amalgamates channel and token information. The essence of Mixer lies in its ability to blend information from diverse perspectives, epitomizing the true concept of "mixing" in the realm of neural network architectures. Beyond channel and token considerations, it is possible to create more tailored mixers from various perspectives to better suit specific task requirements. This study focuses on the domain of audio recognition, introducing a novel model named Audio Spectrogram Mixer with Roll-Time and Hermit FFT (ASM-RH) that incorporates insights from both time and frequency domains. Experimental results demonstrate that ASM-RH is particularly well-suited for audio data and yields promising outcomes across multiple classification tasks.
Loss-Free Machine Unlearning
Feb 29, 2024We present a machine unlearning approach that is both retraining- and label-free. Most existing machine unlearning approaches require a model to be fine-tuned to remove information while preserving performance. This is computationally expensive and necessitates the storage of the whole dataset for the lifetime of the model. Retraining-free approaches often utilise Fisher information, which is derived from the loss and requires labelled data which may not be available. Thus, we present an extension to the Selective Synaptic Dampening algorithm, substituting the diagonal of the Fisher information matrix for the gradient of the l2 norm of the model output to approximate sensitivity. We evaluate our method in a range of experiments using ResNet18 and Vision Transformer. Results show our label-free method is competitive with existing state-of-the-art approaches.
Embedded Multi-label Feature Selection via Orthogonal Regression
Mar 01, 2024
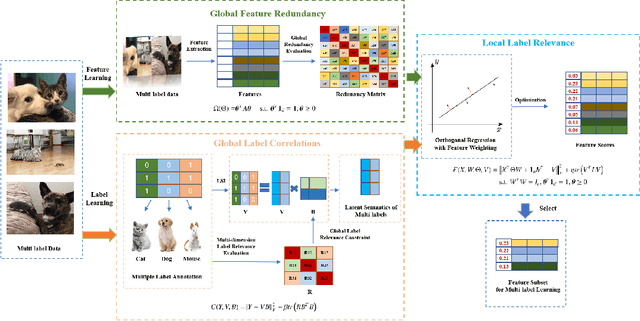


In the last decade, embedded multi-label feature selection methods, incorporating the search for feature subsets into model optimization, have attracted considerable attention in accurately evaluating the importance of features in multi-label classification tasks. Nevertheless, the state-of-the-art embedded multi-label feature selection algorithms based on least square regression usually cannot preserve sufficient discriminative information in multi-label data. To tackle the aforementioned challenge, a novel embedded multi-label feature selection method, termed global redundancy and relevance optimization in orthogonal regression (GRROOR), is proposed to facilitate the multi-label feature selection. The method employs orthogonal regression with feature weighting to retain sufficient statistical and structural information related to local label correlations of the multi-label data in the feature learning process. Additionally, both global feature redundancy and global label relevancy information have been considered in the orthogonal regression model, which could contribute to the search for discriminative and non-redundant feature subsets in the multi-label data. The cost function of GRROOR is an unbalanced orthogonal Procrustes problem on the Stiefel manifold. A simple yet effective scheme is utilized to obtain an optimal solution. Extensive experimental results on ten multi-label data sets demonstrate the effectiveness of GRROOR.
Dual Mean-Teacher: An Unbiased Semi-Supervised Framework for Audio-Visual Source Localization
Mar 05, 2024
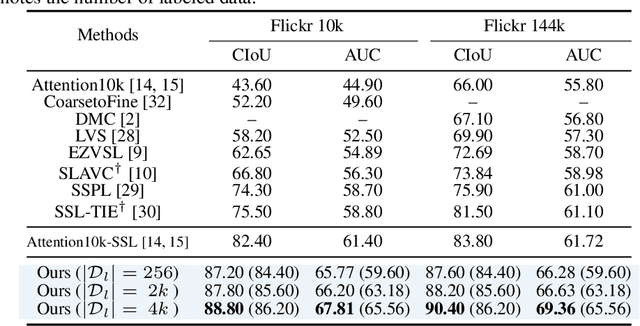
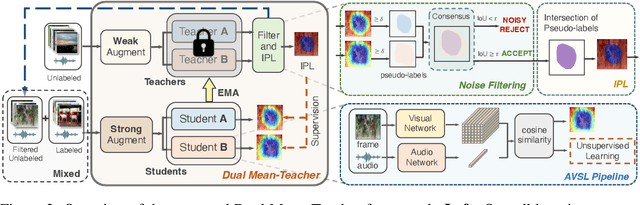
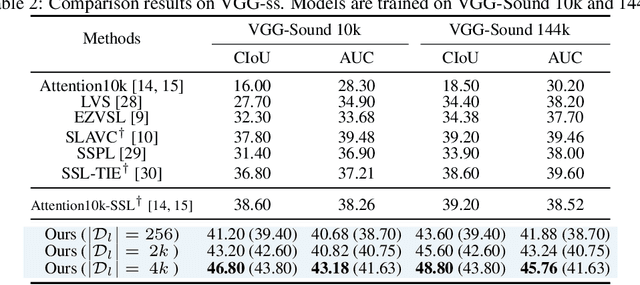
Audio-Visual Source Localization (AVSL) aims to locate sounding objects within video frames given the paired audio clips. Existing methods predominantly rely on self-supervised contrastive learning of audio-visual correspondence. Without any bounding-box annotations, they struggle to achieve precise localization, especially for small objects, and suffer from blurry boundaries and false positives. Moreover, the naive semi-supervised method is poor in fully leveraging the information of abundant unlabeled data. In this paper, we propose a novel semi-supervised learning framework for AVSL, namely Dual Mean-Teacher (DMT), comprising two teacher-student structures to circumvent the confirmation bias issue. Specifically, two teachers, pre-trained on limited labeled data, are employed to filter out noisy samples via the consensus between their predictions, and then generate high-quality pseudo-labels by intersecting their confidence maps. The sufficient utilization of both labeled and unlabeled data and the proposed unbiased framework enable DMT to outperform current state-of-the-art methods by a large margin, with CIoU of 90.4% and 48.8% on Flickr-SoundNet and VGG-Sound Source, obtaining 8.9%, 9.6% and 4.6%, 6.4% improvements over self- and semi-supervised methods respectively, given only 3% positional-annotations. We also extend our framework to some existing AVSL methods and consistently boost their performance.
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Mar 05, 2024Face Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable sorely using the dominant modality. To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients. Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source code and protocols will be released on https://github.com/OMGGGGG/mmdg.
Improving Event Definition Following For Zero-Shot Event Detection
Mar 05, 2024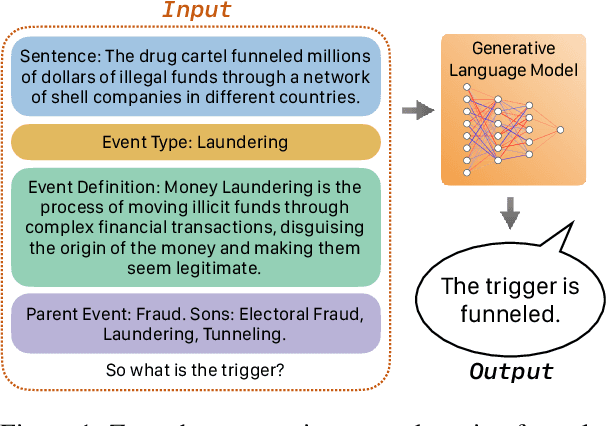

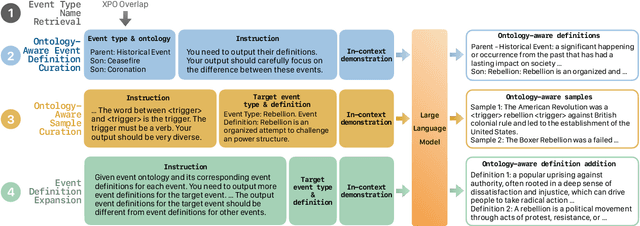

Existing approaches on zero-shot event detection usually train models on datasets annotated with known event types, and prompt them with unseen event definitions. These approaches yield sporadic successes, yet generally fall short of expectations. In this work, we aim to improve zero-shot event detection by training models to better follow event definitions. We hypothesize that a diverse set of event types and definitions are the key for models to learn to follow event definitions while existing event extraction datasets focus on annotating many high-quality examples for a few event types. To verify our hypothesis, we construct an automatically generated Diverse Event Definition (DivED) dataset and conduct comparative studies. Our experiments reveal that a large number of event types (200) and diverse event definitions can significantly boost event extraction performance; on the other hand, the performance does not scale with over ten examples per event type. Beyond scaling, we incorporate event ontology information and hard-negative samples during training, further boosting the performance. Based on these findings, we fine-tuned a LLaMA-2-7B model on our DivED dataset, yielding performance that surpasses SOTA large language models like GPT-3.5 across three open benchmarks on zero-shot event detection.