 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022
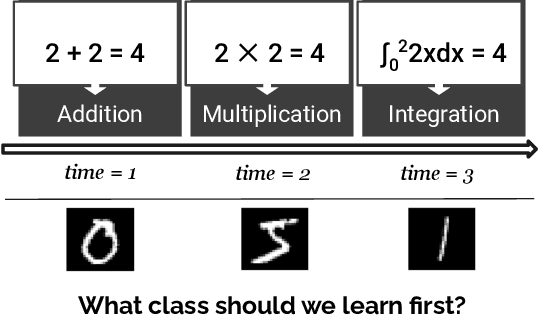
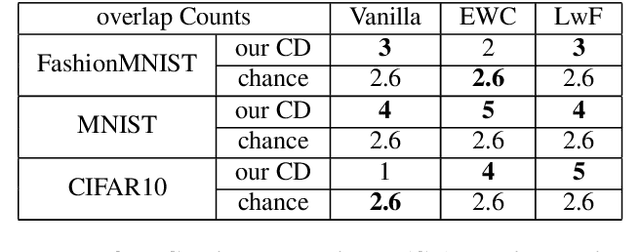
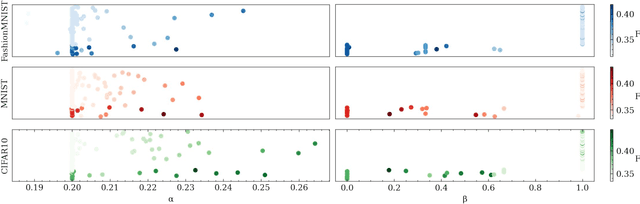
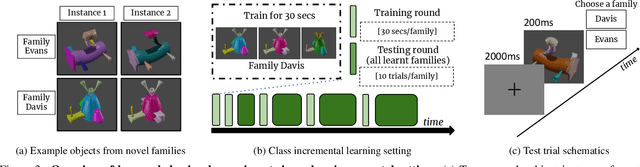
Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.
N2-SAGE: Narrow-beam Near-field SAGE Algorithm for Channel Parameter Estimation in mmWave and THz Direction-scan Measurements
Nov 28, 2022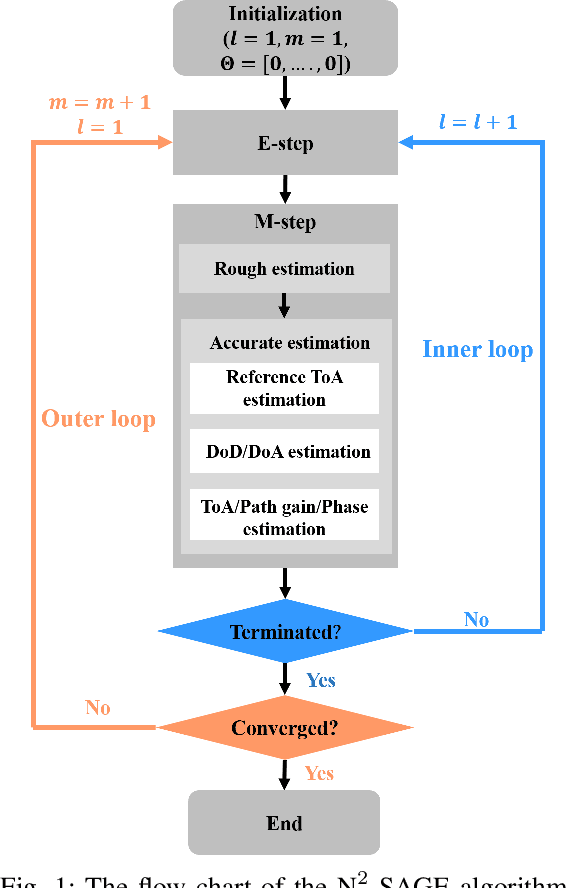
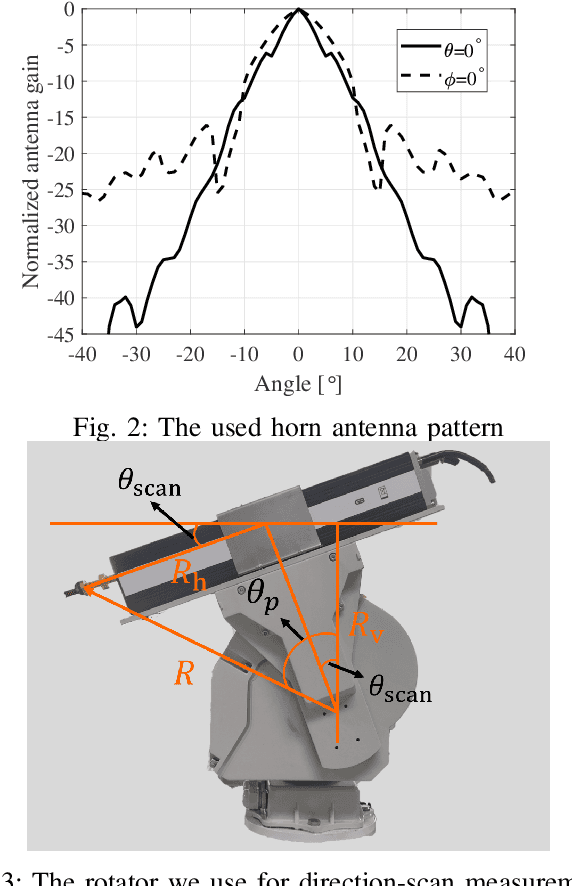
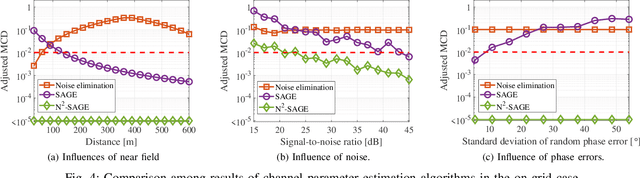
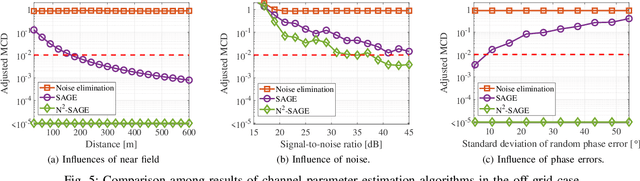
To extract channel characteristics and conduct channel modeling in millimeter-wave (mmWave) and Terahertz (THz) bands, accurate estimations of multi-path component (MPC) parameters in measured results are fundamental. However, due to high frequency and narrow antenna beams in mmWave and THz direction-scan measurements, existing channel parameter estimation algorithms are no longer effective. In this paper, a novel narrow-beam near-field space-alternating generalized expectation-maximization (N2-SAGE) algorithm is proposed, which is derived by carefully considering the features of mmWave and THz direction-scan measurement campaigns, such as near field propagation, narrow antenna beams as well as asynchronous measurements in different scanning directions. The delays of MPCs are calculated using spherical wave front (SWF), which depends on delay and angles of MPCs, resulting in a high-dimensional estimation problem. To overcome this, a novel two-phase estimation process is proposed, including a rough estimation phase and an accurate estimation phase. Moreover, considering the narrow antenna beams used for mmWave and THz direction-scan measurements, the usage of partial information alleviates influence of background noises. Additionally, the phases of MPCs in different scanning directions are treated as random variables, which are estimated and reused during the estimation process, making the algorithm immune to possible phase errors. Furthermore, performance of the proposed N2-SAGE algorithm is validated and compared with existing channel parameter estimation algorithms, based on simulations and measured data. Results show that the proposed N2-SAGE algorithm greatly outperforms existing channel parameter estimation algorithms in terms of estimation accuracy. By using the N2-SAGE algorithm, the channel is characterized more correctly and reasonably.
Graph Neural Networks for Breast Cancer Data Integration
Nov 28, 2022
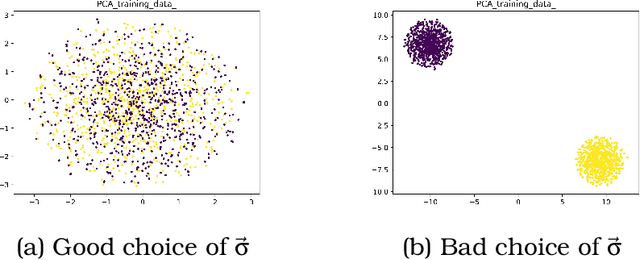
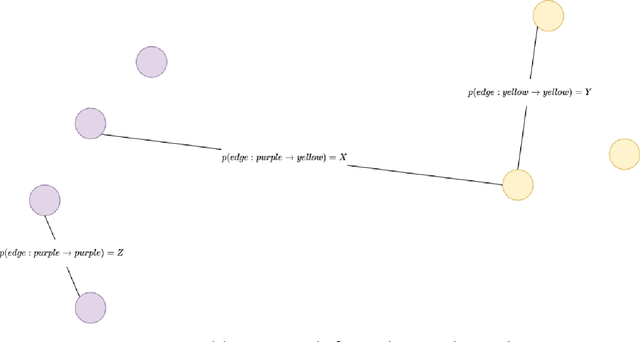
International initiatives such as METABRIC (Molecular Taxonomy of Breast Cancer International Consortium) have collected several multigenomic and clinical data sets to identify the undergoing molecular processes taking place throughout the evolution of various cancers. Numerous Machine Learning and statistical models have been designed and trained to analyze these types of data independently, however, the integration of such differently shaped and sourced information streams has not been extensively studied. To better integrate these data sets and generate meaningful representations that can ultimately be leveraged for cancer detection tasks could lead to giving well-suited treatments to patients. Hence, we propose a novel learning pipeline comprising three steps - the integration of cancer data modalities as graphs, followed by the application of Graph Neural Networks in an unsupervised setting to generate lower-dimensional embeddings from the combined data, and finally feeding the new representations on a cancer sub-type classification model for evaluation. The graph construction algorithms are described in-depth as METABRIC does not store relationships between the patient modalities, with a discussion of their influence over the quality of the generated embeddings. We also present the models used to generate the lower-latent space representations: Graph Neural Networks, Variational Graph Autoencoders and Deep Graph Infomax. In parallel, the pipeline is tested on a synthetic dataset to demonstrate that the characteristics of the underlying data, such as homophily levels, greatly influence the performance of the pipeline, which ranges between 51\% to 98\% accuracy on artificial data, and 13\% and 80\% on METABRIC. This project has the potential to improve cancer data understanding and encourages the transition of regular data sets to graph-shaped data.
Provably Efficient Model-free RL in Leader-Follower MDP with Linear Function Approximation
Nov 28, 2022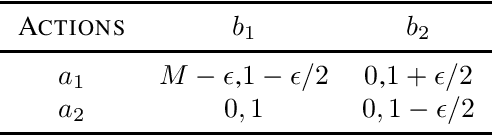
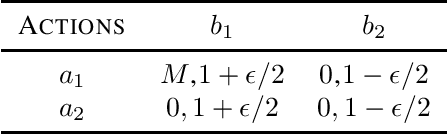
We consider a multi-agent episodic MDP setup where an agent (leader) takes action at each step of the episode followed by another agent (follower). The state evolution and rewards depend on the joint action pair of the leader and the follower. Such type of interactions can find applications in many domains such as smart grids, mechanism design, security, and policymaking. We are interested in how to learn policies for both the players with provable performance guarantee under a bandit feedback setting. We focus on a setup where both the leader and followers are {\em non-myopic}, i.e., they both seek to maximize their rewards over the entire episode and consider a linear MDP which can model continuous state-space which is very common in many RL applications. We propose a {\em model-free} RL algorithm and show that $\tilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret bounds can be achieved for both the leader and the follower, where $d$ is the dimension of the feature mapping, $H$ is the length of the episode, and $T$ is the total number of steps under the bandit feedback information setup. Thus, our result holds even when the number of states becomes infinite. The algorithm relies on {\em novel} adaptation of the LSVI-UCB algorithm. Specifically, we replace the standard greedy policy (as the best response) with the soft-max policy for both the leader and the follower. This turns out to be key in establishing uniform concentration bound for the value functions. To the best of our knowledge, this is the first sub-linear regret bound guarantee for the Markov games with non-myopic followers with function approximation.
mOKB6: A Multilingual Open Knowledge Base Completion Benchmark
Nov 13, 2022

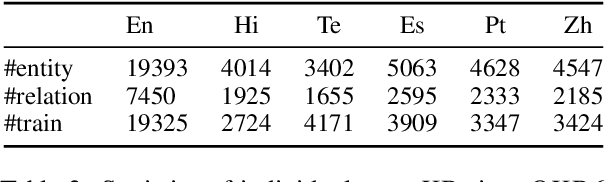
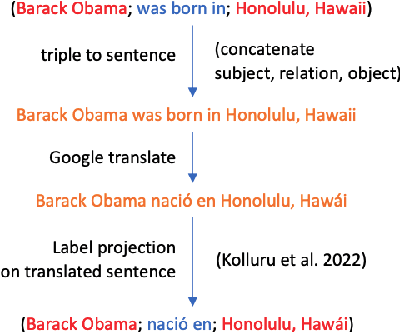
Automated completion of open knowledge bases (KBs), which are constructed from triples of the form (subject phrase, relation phrase, object phrase) obtained via open information extraction (IE) from text, is useful for discovering novel facts that may not directly be present in the text. However, research in open knowledge base completion (KBC) has so far been limited to resource-rich languages like English. Using the latest advances in multilingual open IE, we construct the first multilingual open KBC dataset, called mOKB6, that contains facts from Wikipedia in six languages (including English). Improving the previous open KB construction pipeline by doing multilingual coreference resolution and keeping only entity-linked triples, we create a dense open KB. We experiment with several baseline models that have been proposed for both open and closed KBs and observe a consistent benefit of using knowledge gained from other languages. The dataset and accompanying code will be made publicly available.
Digital Twin-Assisted Collaborative Transcoding for Better User Satisfaction in Live Streaming
Nov 13, 2022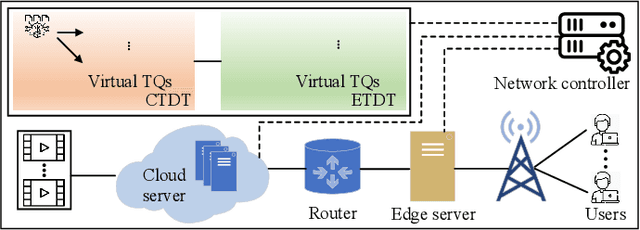
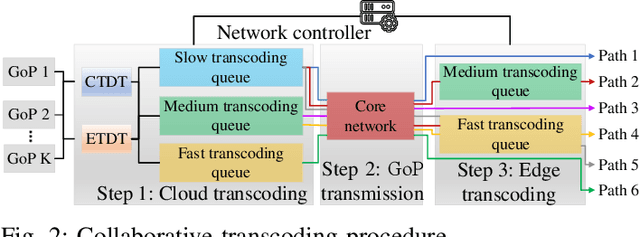
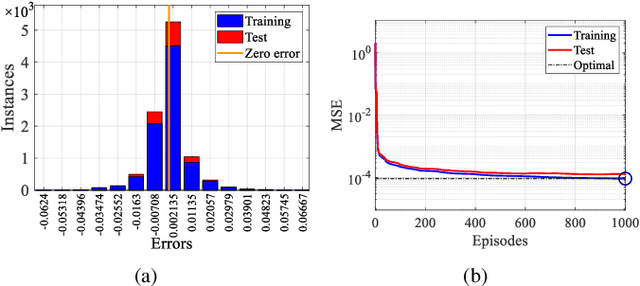
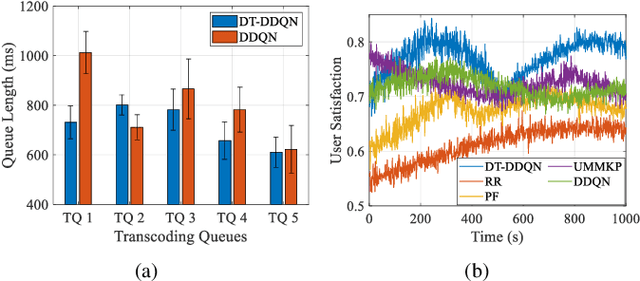
In this paper, we propose a digital twin (DT)-assisted cloud-edge collaborative transcoding scheme to enhance user satisfaction in live streaming. We first present a DT-assisted transcoding workload estimation (TWE) model for the cloud-edge collaborative transcoding. Particularly, two DTs are constructed for emulating the cloud-edge collaborative transcoding process by analyzing spatial-temporal information of individual videos and transcoding configurations of transcoding queues, respectively. Two light-weight Bayesian neural networks are adopted to fit the TWE models in DTs, respectively. We then formulate a transcoding-path selection problem to maximize long-term user satisfaction within an average service delay threshold, taking into account the dynamics of video arrivals and video requests. The problem is transformed into a standard Markov decision process by using the Lyapunov optimization and solved by a deep reinforcement learning algorithm. Simulation results based on the real-world dataset demonstrate that the proposed scheme can effectively enhance user satisfaction compared with benchmark schemes.
A Scalable Graph Neural Network Decoder for Short Block Codes
Nov 13, 2022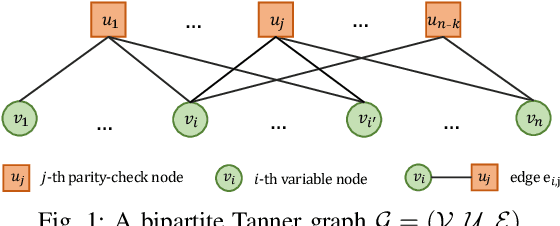
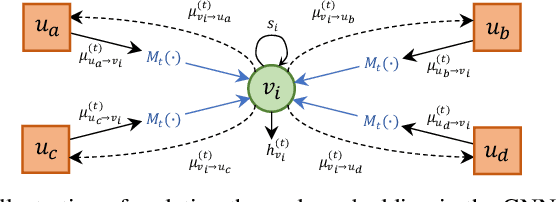
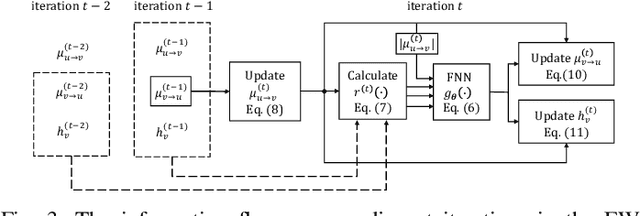
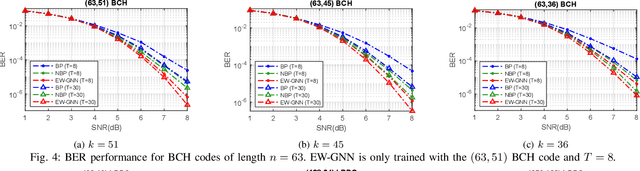
In this work, we propose a novel decoding algorithm for short block codes based on an edge-weighted graph neural network (EW-GNN). The EW-GNN decoder operates on the Tanner graph with an iterative message-passing structure, which algorithmically aligns with the conventional belief propagation (BP) decoding method. In each iteration, the "weight" on the message passed along each edge is obtained from a fully connected neural network that has the reliability information from nodes/edges as its input. Compared to existing deep-learning-based decoding schemes, the EW-GNN decoder is characterised by its scalability, meaning that 1) the number of trainable parameters is independent of the codeword length, and 2) an EW-GNN decoder trained with shorter/simple codes can be directly used for longer/sophisticated codes of different code rates. Furthermore, simulation results show that the EW-GNN decoder outperforms the BP and deep-learning-based BP methods from the literature in terms of the decoding error rate.
DGRec: Graph Neural Network for Recommendation with Diversified Embedding Generation
Nov 18, 2022

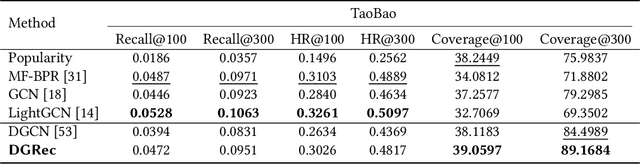
Graph Neural Network (GNN) based recommender systems have been attracting more and more attention in recent years due to their excellent performance in accuracy. Representing user-item interactions as a bipartite graph, a GNN model generates user and item representations by aggregating embeddings of their neighbors. However, such an aggregation procedure often accumulates information purely based on the graph structure, overlooking the redundancy of the aggregated neighbors and resulting in poor diversity of the recommended list. In this paper, we propose diversifying GNN-based recommender systems by directly improving the embedding generation procedure. Particularly, we utilize the following three modules: submodular neighbor selection to find a subset of diverse neighbors to aggregate for each GNN node, layer attention to assign attention weights for each layer, and loss reweighting to focus on the learning of items belonging to long-tail categories. Blending the three modules into GNN, we present DGRec(Diversified GNN-based Recommender System) for diversified recommendation. Experiments on real-world datasets demonstrate that the proposed method can achieve the best diversity while keeping the accuracy comparable to state-of-the-art GNN-based recommender systems.
EMOFAKE: An Initial Dataset For Emotion Fake Audio Detection
Nov 10, 2022
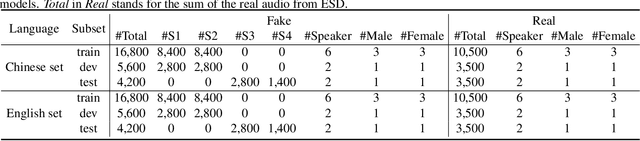
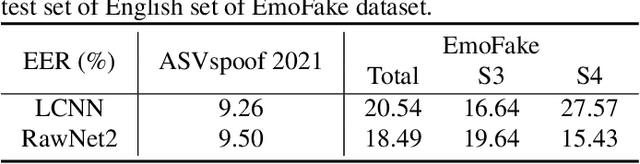
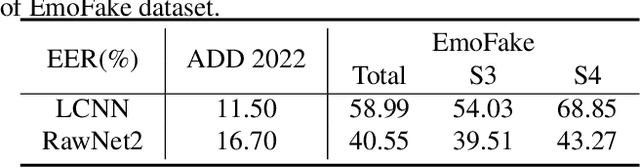
There are already some datasets used for fake audio detection, such as the ASVspoof and ADD datasets. However, these databases do not consider a situation that the emotion of the audio has been changed from one to another, while other information (e.g. speaker identity and content) remains the same. Changing emotions often leads to semantic changes. This may be a great threat to social stability. Therefore, this paper reports our progress in developing such an emotion fake audio detection dataset involving changing emotion state of the original audio. The dataset is named EmoFake. The fake audio in EmoFake is generated using the state-of-the-art emotion voice conversion models. Some benchmark experiments are conducted on this dataset. The results show that our designed dataset poses a challenge to the LCNN and RawNet2 baseline models of ASVspoof 2021.
Learning the shape of protein micro-environments with a holographic convolutional neural network
Nov 05, 2022Proteins play a central role in biology from immune recognition to brain activity. While major advances in machine learning have improved our ability to predict protein structure from sequence, determining protein function from structure remains a major challenge. Here, we introduce Holographic Convolutional Neural Network (H-CNN) for proteins, which is a physically motivated machine learning approach to model amino acid preferences in protein structures. H-CNN reflects physical interactions in a protein structure and recapitulates the functional information stored in evolutionary data. H-CNN accurately predicts the impact of mutations on protein function, including stability and binding of protein complexes. Our interpretable computational model for protein structure-function maps could guide design of novel proteins with desired function.