 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DCANet: Differential Convolution Attention Network for RGB-D Semantic Segmentation
Oct 13, 2022
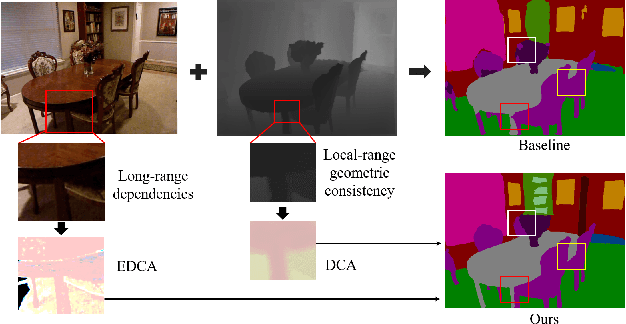
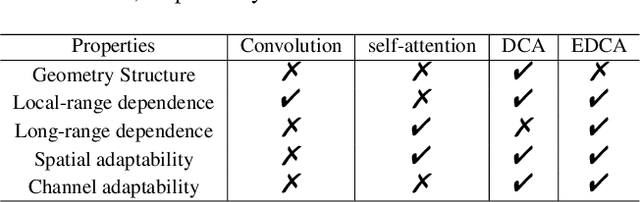
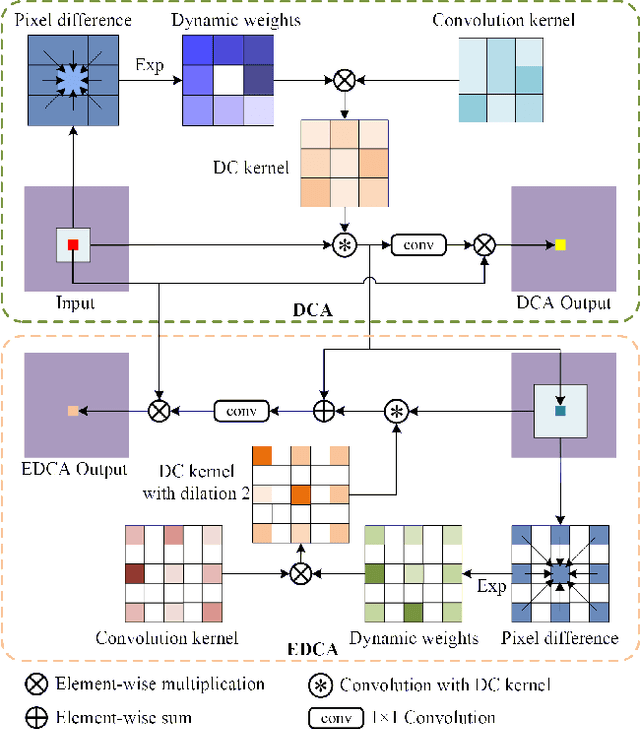
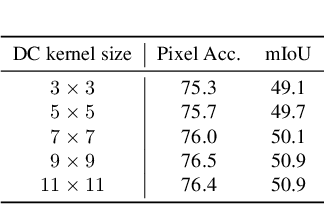
Combining RGB images and the corresponding depth maps in semantic segmentation proves the effectiveness in the past few years. Existing RGB-D modal fusion methods either lack the non-linear feature fusion ability or treat both modal images equally, regardless of the intrinsic distribution gap or information loss. Here we find that depth maps are suitable to provide intrinsic fine-grained patterns of objects due to their local depth continuity, while RGB images effectively provide a global view. Based on this, we propose a pixel differential convolution attention (DCA) module to consider geometric information and local-range correlations for depth data. Furthermore, we extend DCA to ensemble differential convolution attention (EDCA) which propagates long-range contextual dependencies and seamlessly incorporates spatial distribution for RGB data. DCA and EDCA dynamically adjust convolutional weights by pixel difference to enable self-adaptive in local and long range, respectively. A two-branch network built with DCA and EDCA, called Differential Convolutional Network (DCANet), is proposed to fuse local and global information of two-modal data. Consequently, the individual advantage of RGB and depth data are emphasized. Our DCANet is shown to set a new state-of-the-art performance for RGB-D semantic segmentation on two challenging benchmark datasets, i.e., NYUDv2 and SUN-RGBD.
A Stream Learning Approach for Real-Time Identification of False Data Injection Attacks in Cyber-Physical Power Systems
Oct 13, 2022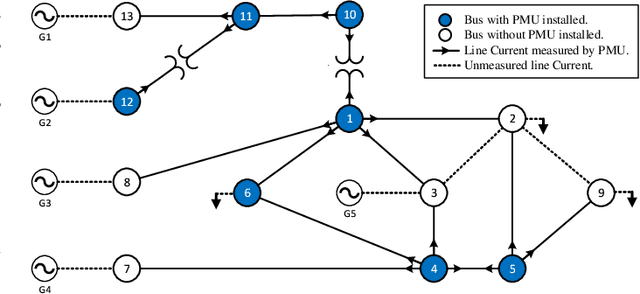
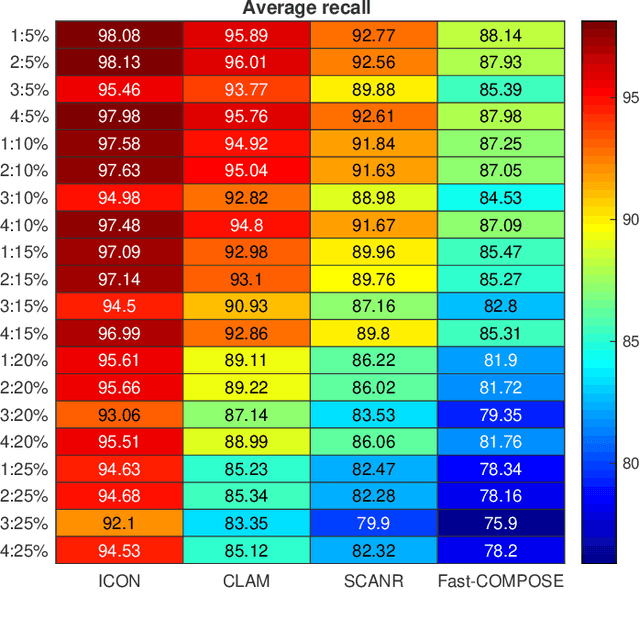
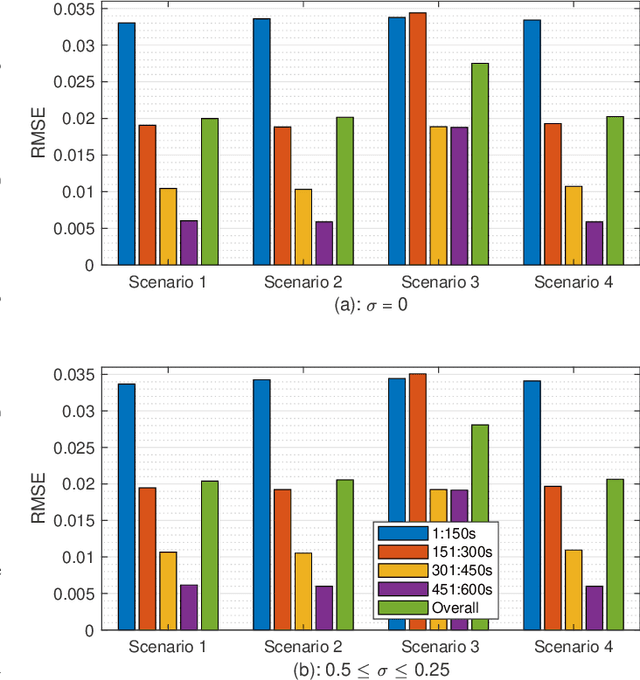
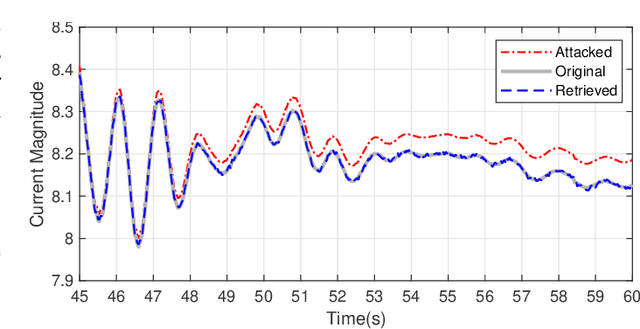
This paper presents a novel data-driven framework to aid in system state estimation when the power system is under unobservable false data injection attacks. The proposed framework dynamically detects and classifies false data injection attacks. Then, it retrieves the control signal using the acquired information. This process is accomplished in three main modules, with novel designs, for detection, classification, and control signal retrieval. The detection module monitors historical changes in phasor measurements and captures any deviation pattern caused by an attack on a complex plane. This approach can help to reveal characteristics of the attacks including the direction, magnitude, and ratio of the injected false data. Using this information, the signal retrieval module can easily recover the original control signal and remove the injected false data. Further information regarding the attack type can be obtained through the classifier module. The proposed ensemble learner is compatible with harsh learning conditions including the lack of labeled data, concept drift, concept evolution, recurring classes, and independence from external updates. The proposed novel classifier can dynamically learn from data and classify attacks under all these harsh learning conditions. The introduced framework is evaluated w.r.t. real-world data captured from the Central New York Power System. The obtained results indicate the efficacy and stability of the proposed framework.
Pareto-optimal clustering with the primal deterministic information bottleneck
Apr 05, 2022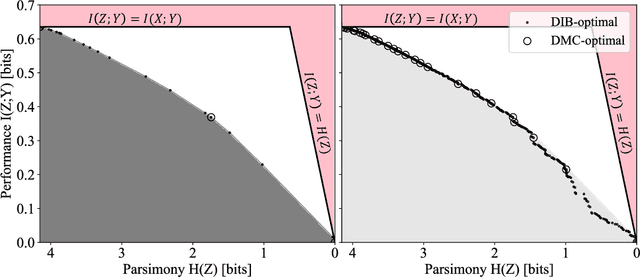
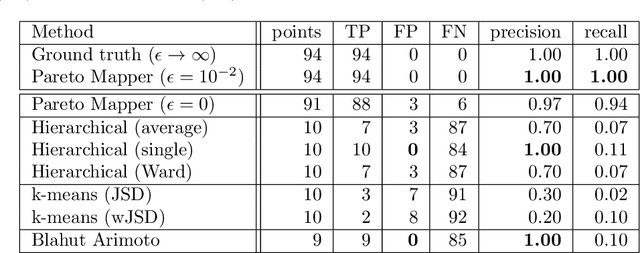
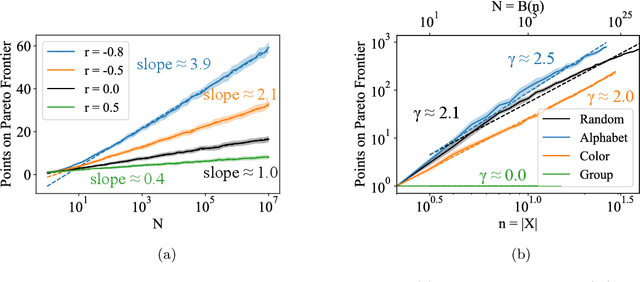
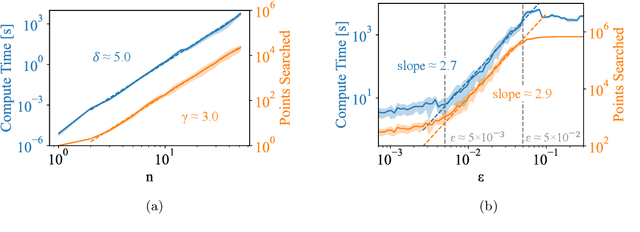
At the heart of both lossy compression and clustering is a trade-off between the fidelity and size of the learned representation. Our goal is to map out and study the Pareto frontier that quantifies this trade-off. We focus on the Deterministic Information Bottleneck (DIB) formulation of lossy compression, which can be interpreted as a clustering problem. To this end, we introduce the {\it primal} DIB problem, which we show results in a much richer frontier than its previously studied dual counterpart. We present an algorithm for mapping out the Pareto frontier of the primal DIB trade-off that is also applicable to most other two-objective clustering problems. We study general properties of the Pareto frontier, and give both analytic and numerical evidence for logarithmic sparsity of the frontier in general. We provide evidence that our algorithm has polynomial scaling despite the super-exponential search space; and additionally propose a modification to the algorithm that can be used where sampling noise is expected to be significant. Finally, we use our algorithm to map the DIB frontier of three different tasks: compressing the English alphabet, extracting informative color classes from natural images, and compressing a group theory inspired dataset, revealing interesting features of frontier, and demonstrating how the structure of the frontier can be used for model selection with a focus on points previously hidden by the cloak of the convex hull.
Unifying Graph Contrastive Learning with Flexible Contextual Scopes
Oct 17, 2022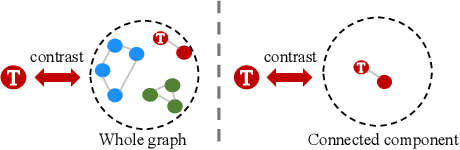
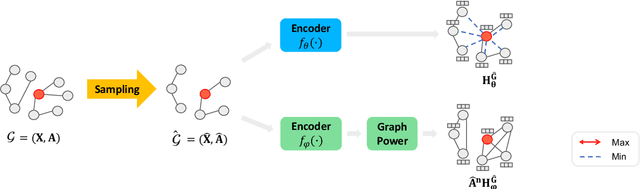
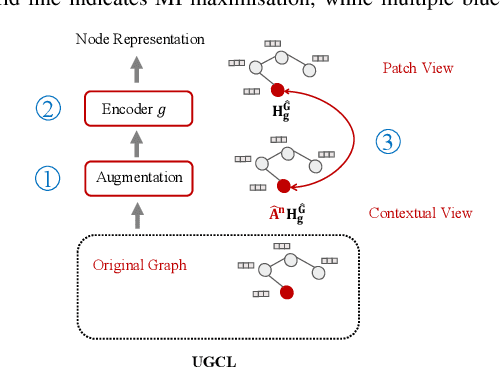
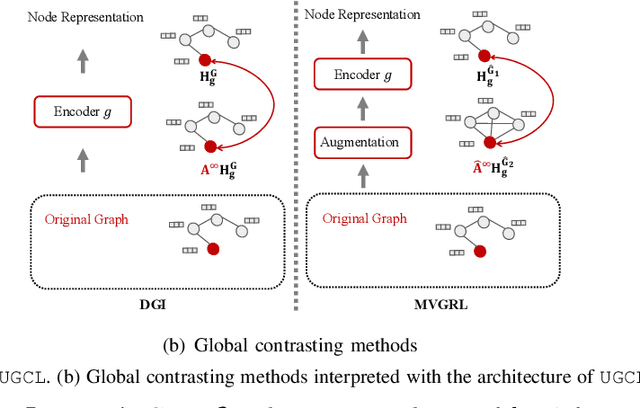
Graph contrastive learning (GCL) has recently emerged as an effective learning paradigm to alleviate the reliance on labelling information for graph representation learning. The core of GCL is to maximise the mutual information between the representation of a node and its contextual representation (i.e., the corresponding instance with similar semantic information) summarised from the contextual scope (e.g., the whole graph or 1-hop neighbourhood). This scheme distils valuable self-supervision signals for GCL training. However, existing GCL methods still suffer from limitations, such as the incapacity or inconvenience in choosing a suitable contextual scope for different datasets and building biased contrastiveness. To address aforementioned problems, we present a simple self-supervised learning method termed Unifying Graph Contrastive Learning with Flexible Contextual Scopes (UGCL for short). Our algorithm builds flexible contextual representations with tunable contextual scopes by controlling the power of an adjacency matrix. Additionally, our method ensures contrastiveness is built within connected components to reduce the bias of contextual representations. Based on representations from both local and contextual scopes, UGCL optimises a very simple contrastive loss function for graph representation learning. Essentially, the architecture of UGCL can be considered as a general framework to unify existing GCL methods. We have conducted intensive experiments and achieved new state-of-the-art performance in six out of eight benchmark datasets compared with self-supervised graph representation learning baselines. Our code has been open-sourced.
How Does Pseudo-Labeling Affect the Generalization Error of the Semi-Supervised Gibbs Algorithm?
Oct 15, 2022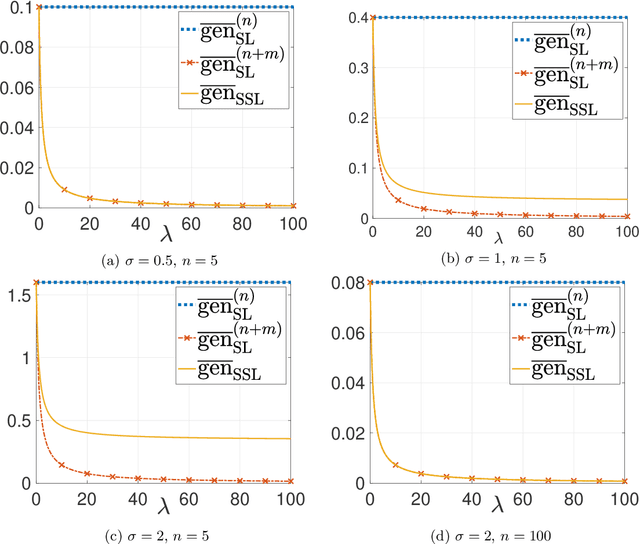
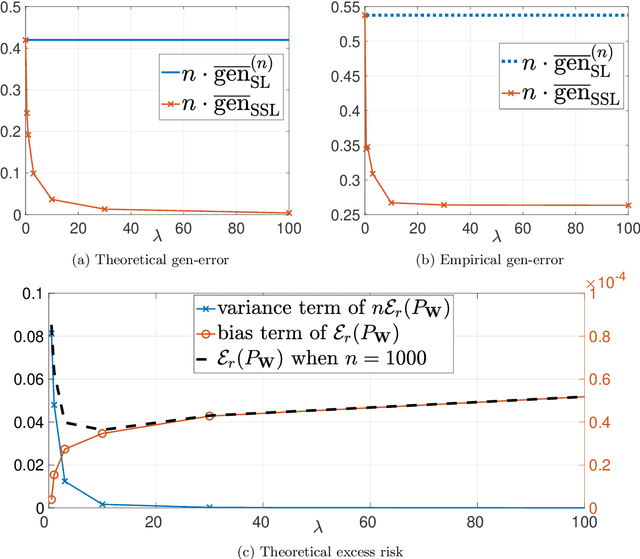
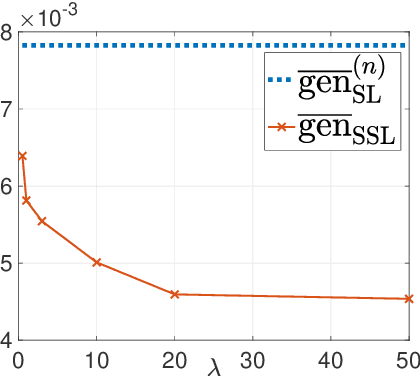
This paper provides an exact characterization of the expected generalization error (gen-error) for semi-supervised learning (SSL) with pseudo-labeling via the Gibbs algorithm. This characterization is expressed in terms of the symmetrized KL information between the output hypothesis, the pseudo-labeled dataset, and the labeled dataset. It can be applied to obtain distribution-free upper and lower bounds on the gen-error. Our findings offer new insights that the generalization performance of SSL with pseudo-labeling is affected not only by the information between the output hypothesis and input training data but also by the information {\em shared} between the {\em labeled} and {\em pseudo-labeled} data samples. To deepen our understanding, we further explore two examples -- mean estimation and logistic regression. In particular, we analyze how the ratio of the number of unlabeled to labeled data $\lambda$ affects the gen-error under both scenarios. As $\lambda$ increases, the gen-error for mean estimation decreases and then saturates at a value larger than when all the samples are labeled, and the gap can be quantified {\em exactly} with our analysis, and is dependent on the \emph{cross-covariance} between the labeled and pseudo-labeled data sample. In logistic regression, the gen-error and the variance component of the excess risk also decrease as $\lambda$ increases.
DCDetector: An IoT terminal vulnerability mining system based on distributed deep ensemble learning under source code representation
Nov 29, 2022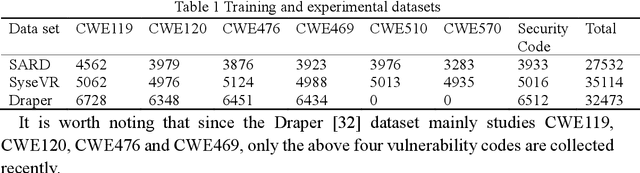

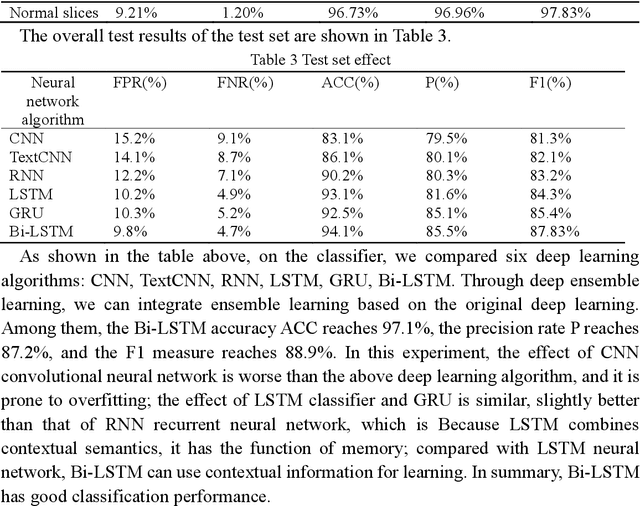
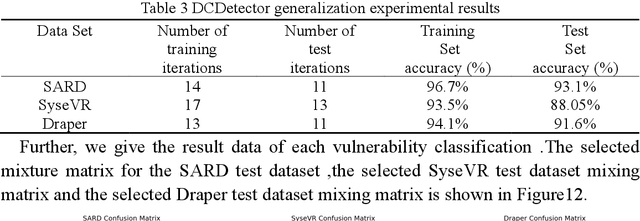
Context: The IoT system infrastructure platform facility vulnerability attack has become the main battlefield of network security attacks. Most of the traditional vulnerability mining methods rely on vulnerability detection tools to realize vulnerability discovery. However, due to the inflexibility of tools and the limitation of file size, its scalability It is relatively low and cannot be applied to large-scale power big data fields. Objective: The goal of the research is to intelligently detect vulnerabilities in source codes of high-level languages such as C/C++. This enables us to propose a code representation of sensitive sentence-related slices of source code, and to detect vulnerabilities by designing a distributed deep ensemble learning model. Method: In this paper, a new directional vulnerability mining method of parallel ensemble learning is proposed to solve the problem of large-scale data vulnerability mining. By extracting sensitive functions and statements, a sensitive statement library of vulnerable codes is formed. The AST stream-based vulnerability code slice with higher granularity performs doc2vec sentence vectorization on the source code through the random sampling module, obtains different classification results through distributed training through the Bi-LSTM trainer, and obtains the final classification result by voting. Results: This method designs and implements a distributed deep ensemble learning system software vulnerability mining system called DCDetector. It can make accurate predictions by using the syntactic information of the code, and is an effective method for analyzing large-scale vulnerability data. Conclusion: Experiments show that this method can reduce the false positive rate of traditional static analysis and improve the performance and accuracy of machine learning.
Sequence learning in a spiking neuronal network with memristive synapses
Nov 29, 2022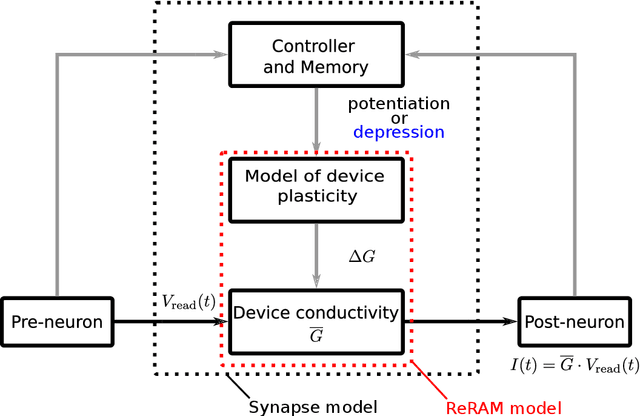
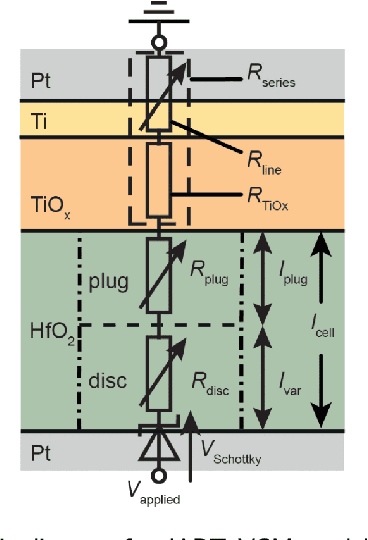
Brain-inspired computing proposes a set of algorithmic principles that hold promise for advancing artificial intelligence. They endow systems with self learning capabilities, efficient energy usage, and high storage capacity. A core concept that lies at the heart of brain computation is sequence learning and prediction. This form of computation is essential for almost all our daily tasks such as movement generation, perception, and language. Understanding how the brain performs such a computation is not only important to advance neuroscience but also to pave the way to new technological brain-inspired applications. A previously developed spiking neural network implementation of sequence prediction and recall learns complex, high-order sequences in an unsupervised manner by local, biologically inspired plasticity rules. An emerging type of hardware that holds promise for efficiently running this type of algorithm is neuromorphic hardware. It emulates the way the brain processes information and maps neurons and synapses directly into a physical substrate. Memristive devices have been identified as potential synaptic elements in neuromorphic hardware. In particular, redox-induced resistive random access memories (ReRAM) devices stand out at many aspects. They permit scalability, are energy efficient and fast, and can implement biological plasticity rules. In this work, we study the feasibility of using ReRAM devices as a replacement of the biological synapses in the sequence learning model. We implement and simulate the model including the ReRAM plasticity using the neural simulator NEST. We investigate the effect of different device properties on the performance characteristics of the sequence learning model, and demonstrate resilience with respect to different on-off ratios, conductance resolutions, device variability, and synaptic failure.
G-CMP: Graph-enhanced Contextual Matrix Profile for unsupervised anomaly detection in sensor-based remote health monitoring
Nov 29, 2022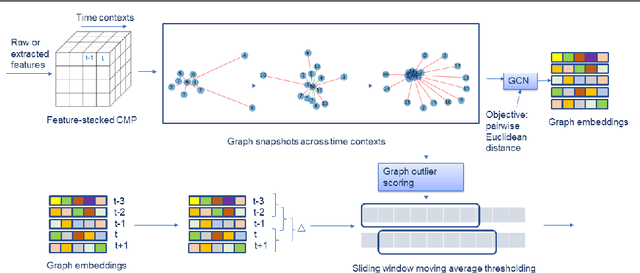

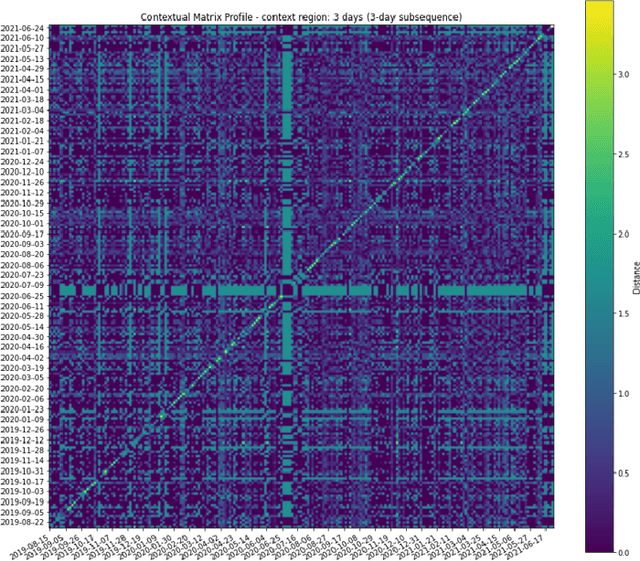

Sensor-based remote health monitoring is used in industrial, urban and healthcare settings to monitor ongoing operation of equipment and human health. An important aim is to intervene early if anomalous events or adverse health is detected. In the wild, these anomaly detection approaches are challenged by noise, label scarcity, high dimensionality, explainability and wide variability in operating environments. The Contextual Matrix Profile (CMP) is a configurable 2-dimensional version of the Matrix Profile (MP) that uses the distance matrix of all subsequences of a time series to discover patterns and anomalies. The CMP is shown to enhance the effectiveness of the MP and other SOTA methods at detecting, visualising and interpreting true anomalies in noisy real world data from different domains. It excels at zooming out and identifying temporal patterns at configurable time scales. However, the CMP does not address cross-sensor information, and cannot scale to high dimensional data. We propose a novel, self-supervised graph-based approach for temporal anomaly detection that works on context graphs generated from the CMP distance matrix. The learned graph embeddings encode the anomalous nature of a time context. In addition, we evaluate other graph outlier algorithms for the same task. Given our pipeline is modular, graph construction, generation of graph embeddings, and pattern recognition logic can all be chosen based on the specific pattern detection application. We verified the effectiveness of graph-based anomaly detection and compared it with the CMP and 3 state-of-the art methods on two real-world healthcare datasets with different anomalies. Our proposed method demonstrated better recall, alert rate and generalisability.
BatmanNet: Bi-branch Masked Graph Transformer Autoencoder for Molecular Representation
Nov 29, 2022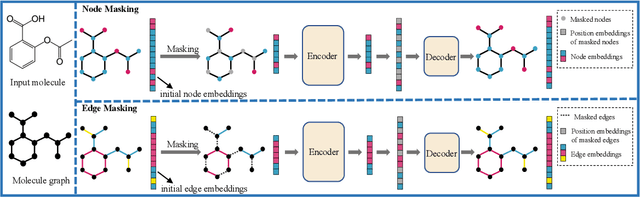
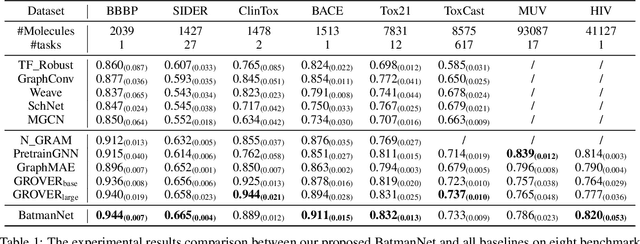
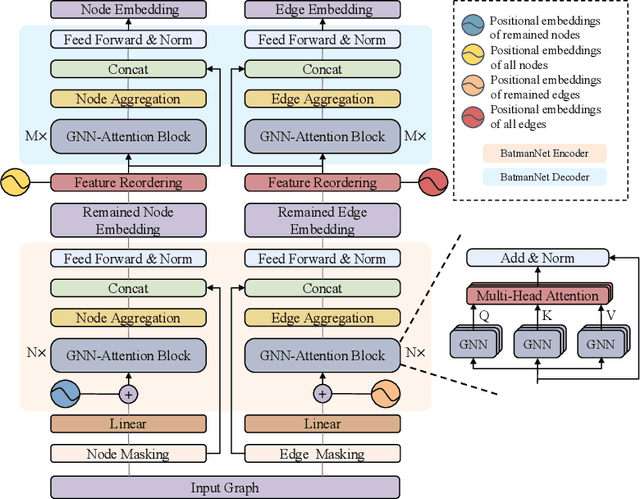

Although substantial efforts have been made using graph neural networks (GNNs) for AI-driven drug discovery (AIDD), effective molecular representation learning remains an open challenge, especially in the case of insufficient labeled molecules. Recent studies suggest that big GNN models pre-trained by self-supervised learning on unlabeled datasets enable better transfer performance in downstream molecular property prediction tasks. However, they often require large-scale datasets and considerable computational resources, which is time-consuming, computationally expensive, and environmentally unfriendly. To alleviate these limitations, we propose a novel pre-training model for molecular representation learning, Bi-branch Masked Graph Transformer Autoencoder (BatmanNet). BatmanNet features two tailored and complementary graph autoencoders to reconstruct the missing nodes and edges from a masked molecular graph. To our surprise, BatmanNet discovered that the highly masked proportion (60%) of the atoms and bonds achieved the best performance. We further propose an asymmetric graph-based encoder-decoder architecture for either nodes and edges, where a transformer-based encoder only takes the visible subset of nodes or edges, and a lightweight decoder reconstructs the original molecule from the latent representation and mask tokens. With this simple yet effective asymmetrical design, our BatmanNet can learn efficiently even from a much smaller-scale unlabeled molecular dataset to capture the underlying structural and semantic information, overcoming a major limitation of current deep neural networks for molecular representation learning. For instance, using only 250K unlabelled molecules as pre-training data, our BatmanNet with 2.575M parameters achieves a 0.5% improvement on the average AUC compared with the current state-of-the-art method with 100M parameters pre-trained on 11M molecules.
Review of coreference resolution in English and Persian
Nov 08, 2022
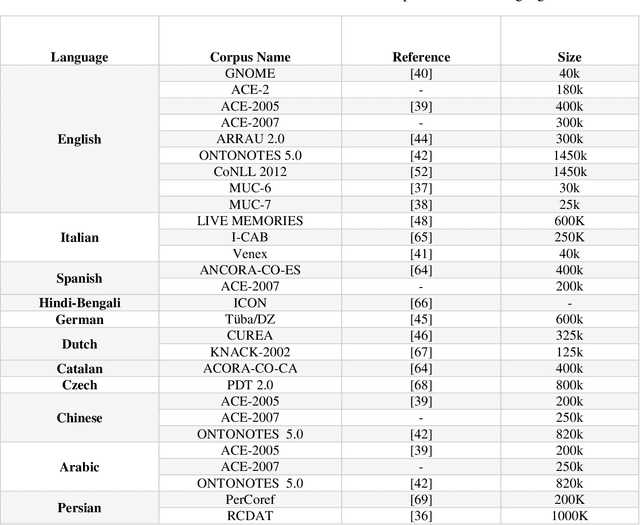
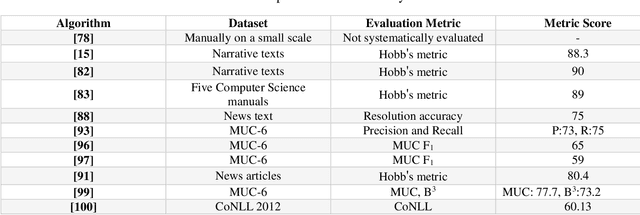
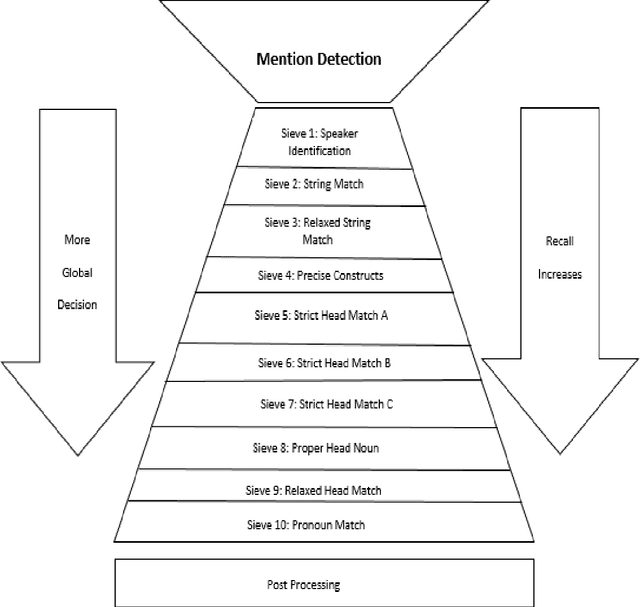
Coreference resolution (CR) is one of the most challenging areas of natural language processing. This task seeks to identify all textual references to the same real-world entity. Research in this field is divided into coreference resolution and anaphora resolution. Due to its application in textual comprehension and its utility in other tasks such as information extraction systems, document summarization, and machine translation, this field has attracted considerable interest. Consequently, it has a significant effect on the quality of these systems. This article reviews the existing corpora and evaluation metrics in this field. Then, an overview of the coreference algorithms, from rule-based methods to the latest deep learning techniques, is provided. Finally, coreference resolution and pronoun resolution systems in Persian are investigated.