 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
JoJoNet: Joint-contrast and Joint-sampling-and-reconstruction Network for Multi-contrast MRI
Oct 27, 2022
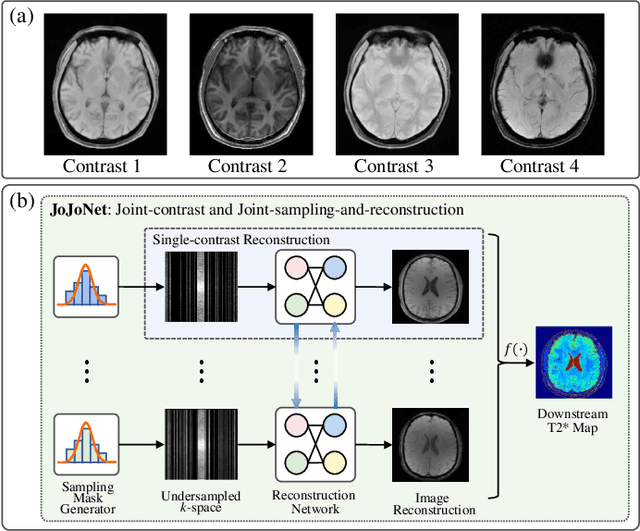
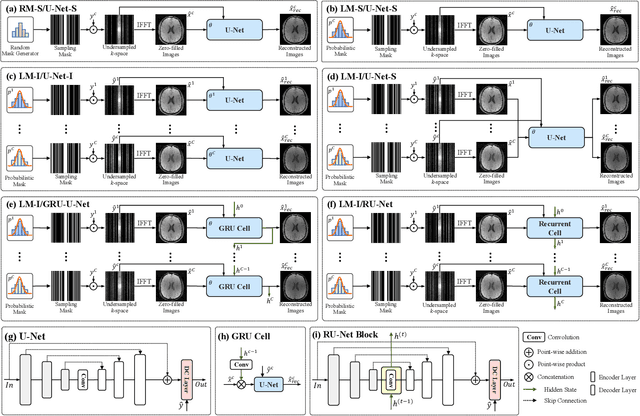
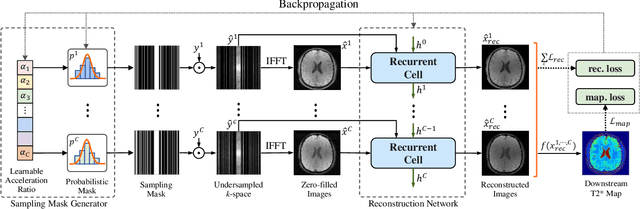
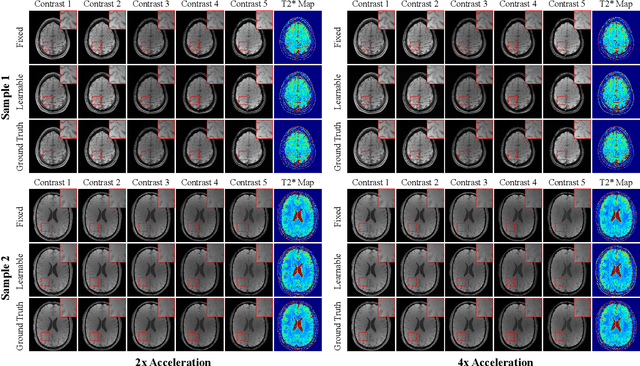
Multi-contrast Magnetic Resonance Imaging (MRI) generates multiple medical images with rich and complementary information for routine clinical use; however, it suffers from a long acquisition time. Recent works for accelerating MRI, mainly designed for single contrast, may not be optimal for multi-contrast scenario since the inherent correlations among the multi-contrast images are not exploited. In addition, independent reconstruction of each contrast usually does not translate to optimal performance of downstream tasks. Motivated by these aspects, in this paper we design an end-to-end framework for accelerating multi-contrast MRI which simultaneously optimizes the entire MR imaging workflow including sampling, reconstruction and downstream tasks to achieve the best overall outcomes. The proposed framework consists of a sampling mask generator for each image contrast and a reconstructor exploiting the inter-contrast correlations with a recurrent structure which enables the information sharing in a holistic way. The sampling mask generator and the reconstructor are trained jointly across the multiple image contrasts. The acceleration ratio of each image contrast is also learnable and can be driven by a downstream task performance. We validate our approach on a multi-contrast brain dataset and a multi-contrast knee dataset. Experiments show that (1) our framework consistently outperforms the baselines designed for single contrast on both datasets; (2) our newly designed recurrent reconstruction network effectively improves the reconstruction quality for multi-contrast images; (3) the learnable acceleration ratio improves the downstream task performance significantly. Overall, this work has potentials to open up new avenues for optimizing the entire multi-contrast MR imaging workflow.
An adaptive multi-fidelity framework for safety analysis of connected and automated vehicles
Oct 25, 2022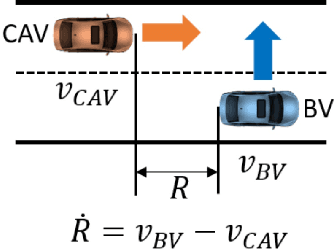
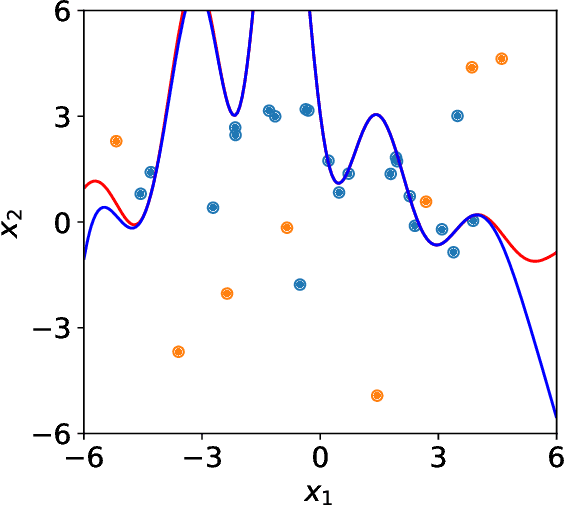
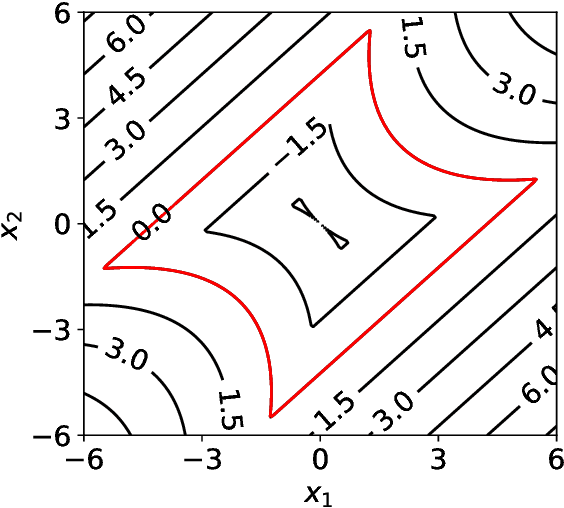
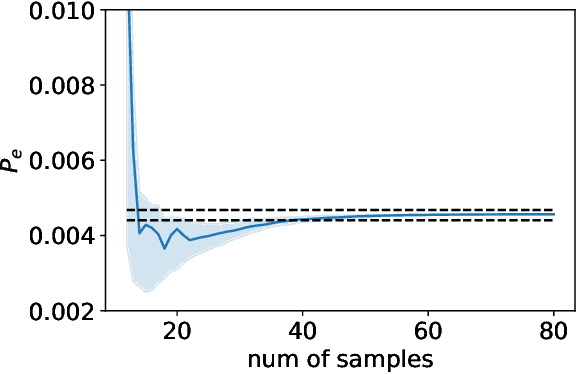
Testing and evaluation are expensive but critical steps in the development and deployment of connected and automated vehicles (CAVs). In this paper, we develop an adaptive sampling framework to efficiently evaluate the accident rate of CAVs, particularly for scenario-based tests where the probability distribution of input parameters is known from the Naturalistic Driving Data. Our framework relies on a surrogate model to approximate the CAV performance and a novel acquisition function to maximize the benefit (information to accident rate) of the next sample formulated through an information-theoretic consideration. In addition to the standard application with only a single high-fidelity model of CAV performance, we also extend our approach to the bi-fidelity context where an additional low-fidelity model can be used at a lower computational cost to approximate the CAV performance. Accordingly for the second case, our approach is formulated such that it allows the choice of the next sample, in terms of both fidelity level (i.e., which model to use) and sampling location to maximize the benefit per cost. Our framework is tested in a widely-considered two-dimensional cut-in problem for CAVs, where Intelligent Driving Model (IDM) with different time resolutions are used to construct the high and low-fidelity models. We show that our single-fidelity method outperforms the existing approach for the same problem, and the bi-fidelity method can further save half of the computational cost to reach a similar accuracy in estimating the accident rate.
Tracking Dataset IP Use in Deep Neural Networks
Nov 24, 2022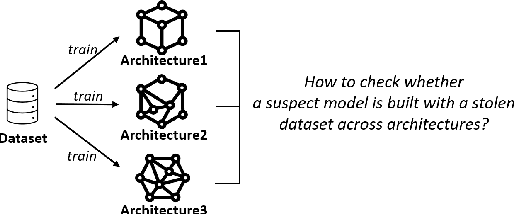
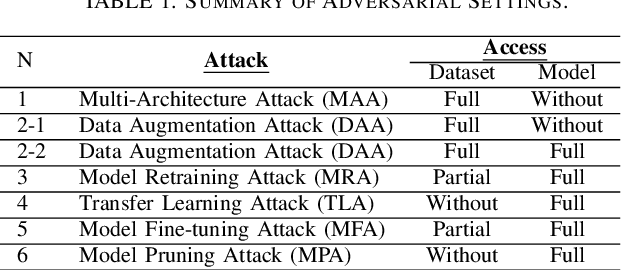
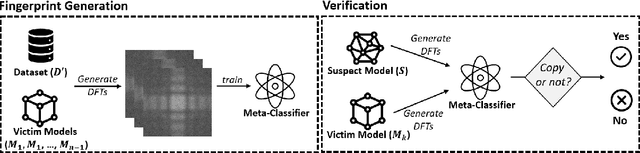
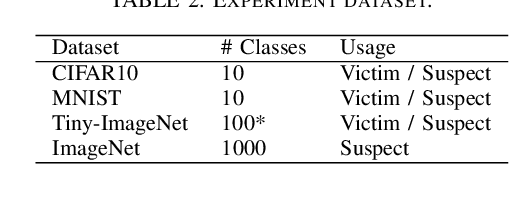
Training highly performant deep neural networks (DNNs) typically requires the collection of a massive dataset and the use of powerful computing resources. Therefore, unauthorized redistribution of private pre-trained DNNs may cause severe economic loss for model owners. For protecting the ownership of DNN models, DNN watermarking schemes have been proposed by embedding secret information in a DNN model and verifying its presence for model ownership. However, existing DNN watermarking schemes compromise the model utility and are vulnerable to watermark removal attacks because a model is modified with a watermark. Alternatively, a new approach dubbed DEEPJUDGE was introduced to measure the similarity between a suspect model and a victim model without modifying the victim model. However, DEEPJUDGE would only be designed to detect the case where a suspect model's architecture is the same as a victim model's. In this work, we propose a novel DNN fingerprinting technique dubbed DEEPTASTER to prevent a new attack scenario in which a victim's data is stolen to build a suspect model. DEEPTASTER can effectively detect such data theft attacks even when a suspect model's architecture differs from a victim model's. To achieve this goal, DEEPTASTER generates a few adversarial images with perturbations, transforms them into the Fourier frequency domain, and uses the transformed images to identify the dataset used in a suspect model. The intuition is that those adversarial images can be used to capture the characteristics of DNNs built on a specific dataset. We evaluated the detection accuracy of DEEPTASTER on three datasets with three model architectures under various attack scenarios, including transfer learning, pruning, fine-tuning, and data augmentation. Overall, DEEPTASTER achieves a balanced accuracy of 94.95%, which is significantly better than 61.11% achieved by DEEPJUDGE in the same settings.
BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022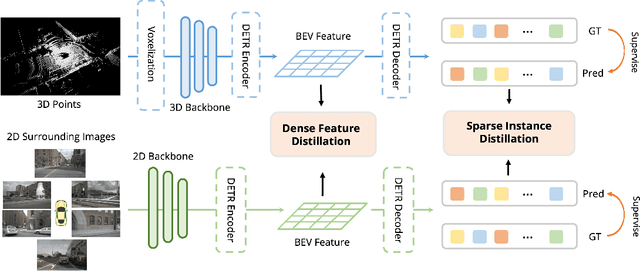
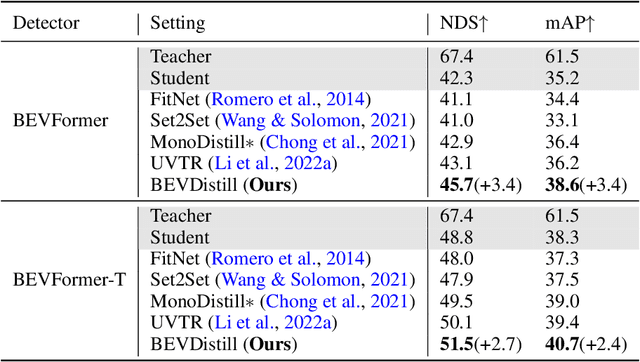
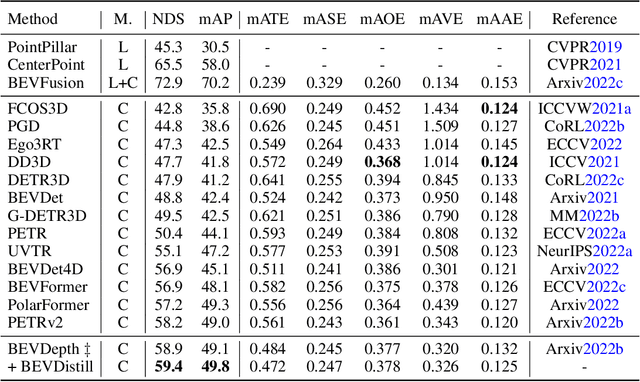

3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
EfficientTrain: Exploring Generalized Curriculum Learning for Training Visual Backbones
Nov 17, 2022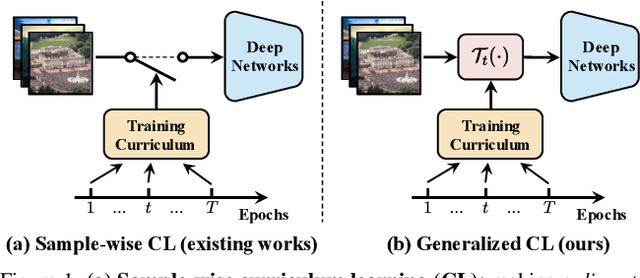
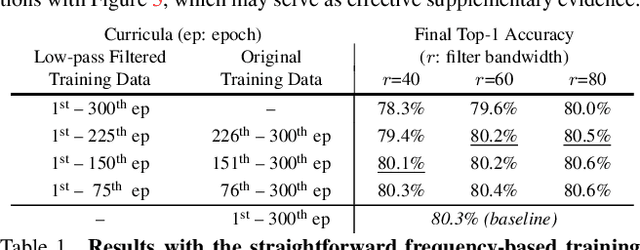
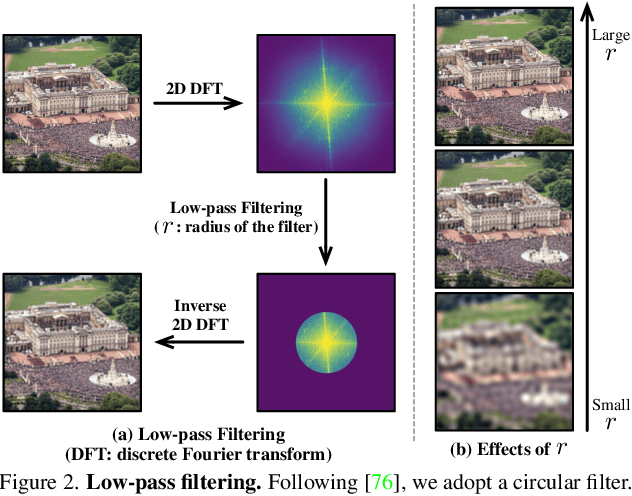
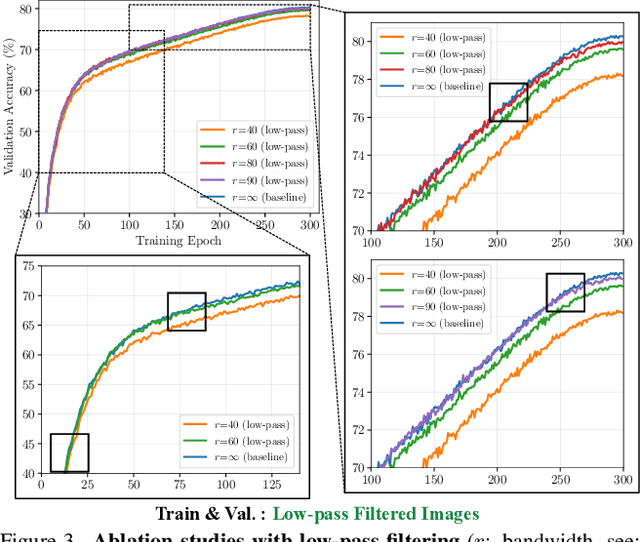
The superior performance of modern deep networks usually comes at the price of a costly training procedure. In this paper, we present a novel curriculum learning approach for the efficient training of visual backbones (e.g., vision Transformers). The proposed method is inspired by the phenomenon that deep networks mainly learn to recognize some 'easier-to-learn' discriminative patterns within each example at earlier stages of training, e.g., the lower-frequency components of images and the original information before data augmentation. Driven by this observation, we propose a curriculum where the model always leverages all the training data at each epoch, while the curriculum starts with only exposing the 'easier-to-learn' patterns of each example, and introduces gradually more difficult patterns. To implement this idea, we 1) introduce a cropping operation in the Fourier spectrum of the inputs, which enables the model to learn from only the lower-frequency components efficiently, and 2) demonstrate that exposing the features of original images amounts to adopting weaker data augmentation. Our resulting algorithm, EfficientTrain, is simple, general, yet surprisingly effective. For example, it reduces the training time of a wide variety of popular models (e.g., ConvNeXts, DeiT, PVT, and Swin/CSWin Transformers) by more than ${1.5\times}$ on ImageNet-1K/22K without sacrificing the accuracy. It is effective for self-supervised learning (i.e., MAE) as well. Code is available at https://github.com/LeapLabTHU/EfficientTrain.
You Only Label Once: 3D Box Adaptation from Point Cloud to Image via Semi-Supervised Learning
Nov 17, 2022

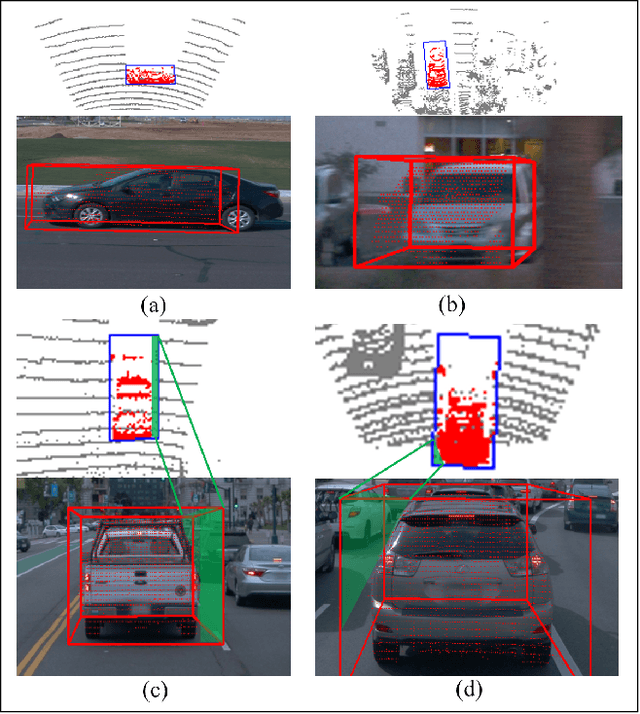
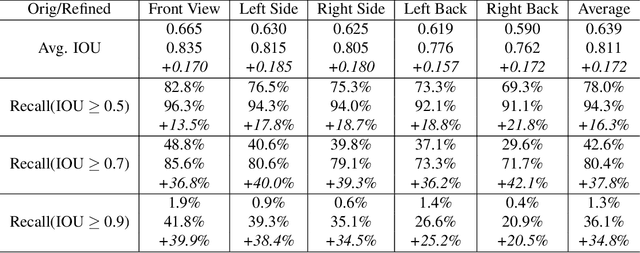
The image-based 3D object detection task expects that the predicted 3D bounding box has a ``tightness'' projection (also referred to as cuboid), which fits the object contour well on the image while still keeping the geometric attribute on the 3D space, e.g., physical dimension, pairwise orthogonal, etc. These requirements bring significant challenges to the annotation. Simply projecting the Lidar-labeled 3D boxes to the image leads to non-trivial misalignment, while directly drawing a cuboid on the image cannot access the original 3D information. In this work, we propose a learning-based 3D box adaptation approach that automatically adjusts minimum parameters of the 360$^{\circ}$ Lidar 3D bounding box to perfectly fit the image appearance of panoramic cameras. With only a few 2D boxes annotation as guidance during the training phase, our network can produce accurate image-level cuboid annotations with 3D properties from Lidar boxes. We call our method ``you only label once'', which means labeling on the point cloud once and automatically adapting to all surrounding cameras. As far as we know, we are the first to focus on image-level cuboid refinement, which balances the accuracy and efficiency well and dramatically reduces the labeling effort for accurate cuboid annotation. Extensive experiments on the public Waymo and NuScenes datasets show that our method can produce human-level cuboid annotation on the image without needing manual adjustment.
Complementary consistency semi-supervised learning for 3D left atrial image segmentation
Oct 04, 2022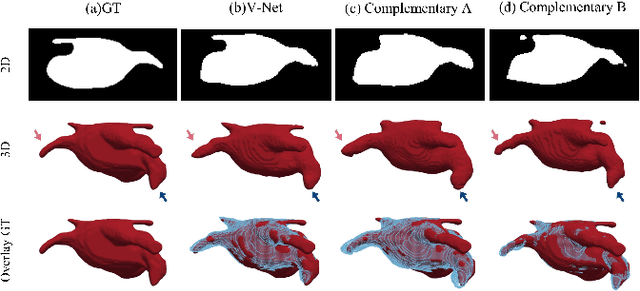
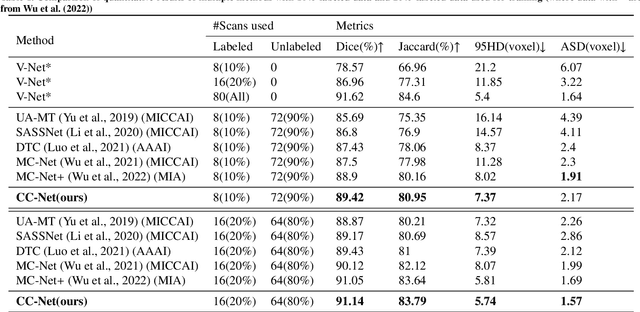
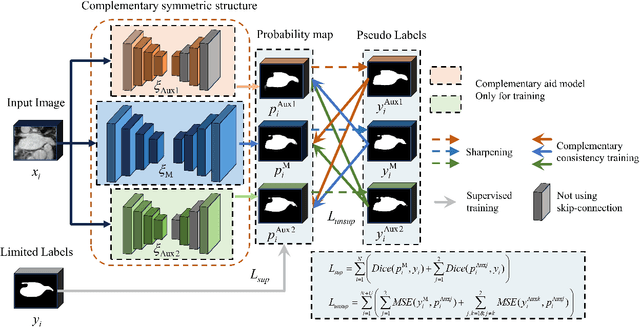
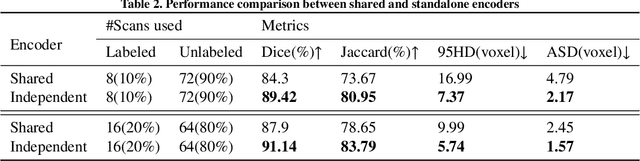
A network based on complementary consistency training (CC-Net) is proposed for semi-supervised left atrial image segmentation in this paper. From the perspective of complementary information, CC-Net effectively utilizes unlabeled data and resolves the problem that semi-supervised segmentation algorithms currently in use have a limited capacity to extract information from unlabeled data. A primary model and two complementary auxiliary models are part of the complementary symmetric structure of the CC-Net. A complementary consistency training is formed by the inter-model perturbation between the primary model and the auxiliary models. The main model is better able to concentrate on the ambiguous region due to the complementary information provided by the two auxiliary models. Additionally, forcing consistency between the primary model and the auxiliary models makes it easier to obtain decision boundaries with little uncertainty. CC-Net was validated in the benchmark dataset of 2018 left atrial segmentation challenge, reaching Dice of 89.42% with 10% labeled data training and 91.14% with 20% labeled data training. By comparing with current state-of-the-art algorithms, CC-Net has the best segmentation performance and robustness. Our code is publicly available at https://github.com/Cuthbert-Huang/CC-Net.
Latent Prompt Tuning for Text Summarization
Nov 03, 2022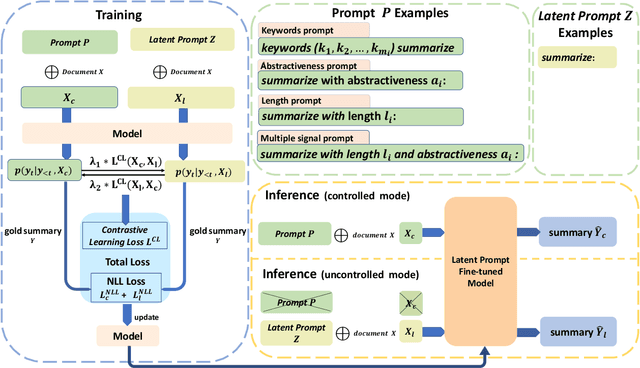
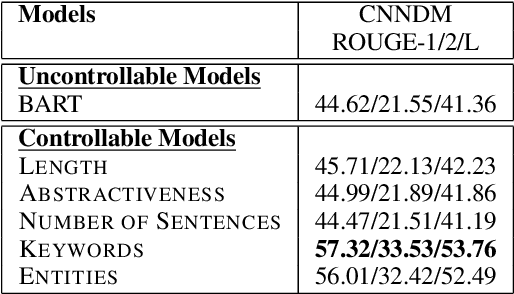
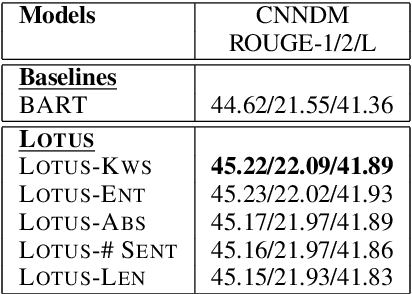
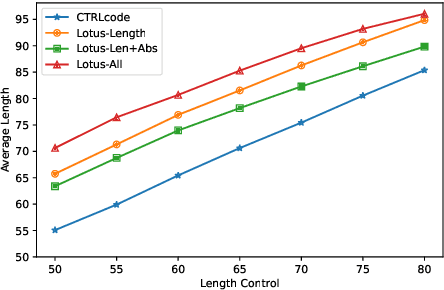
Prompts with different control signals (e.g., length, keywords, etc.) can be used to control text summarization. When control signals are available, they can control the properties of generated summaries and potentially improve summarization quality (since more information are given). Unfortunately, control signals are not already available during inference time. In this paper, we propose Lotus (shorthand for Latent Prompt Tuning for Summarization), which is a single model that can be applied in both controlled and uncontrolled (without control signals) modes. During training, Lotus learns latent prompt representations from prompts with gold control signals using a contrastive learning objective. Experiments show Lotus in uncontrolled mode consistently improves upon strong (uncontrollable) summarization models across four different summarization datasets. We also demonstrate generated summaries can be controlled using prompts with user specified control tokens.
Human in the loop approaches in multi-modal conversational task guidance system development
Nov 03, 2022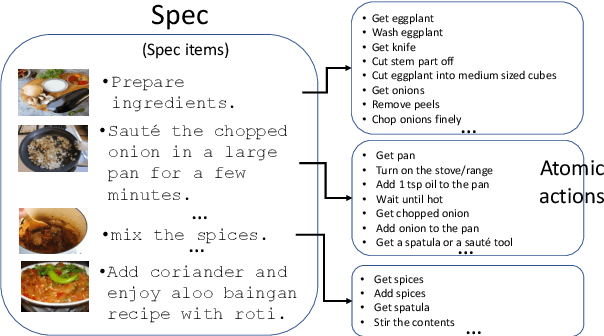
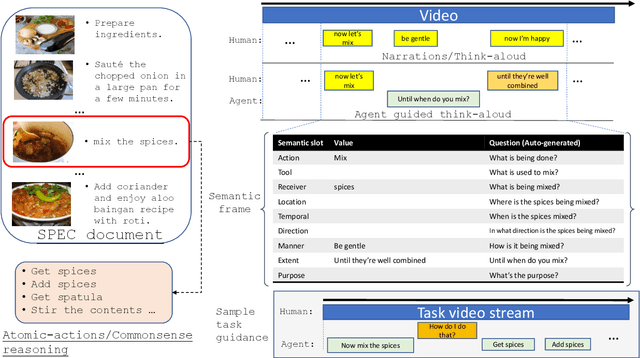
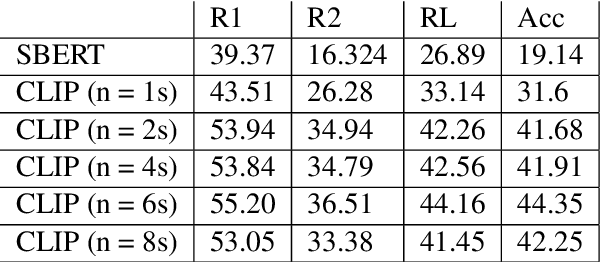
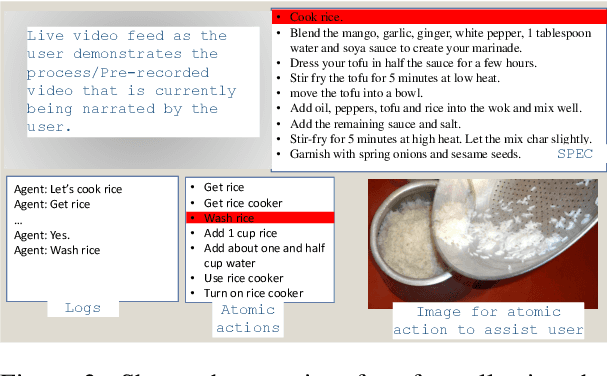
Development of task guidance systems for aiding humans in a situated task remains a challenging problem. The role of search (information retrieval) and conversational systems for task guidance has immense potential to help the task performers achieve various goals. However, there are several technical challenges that need to be addressed to deliver such conversational systems, where common supervised approaches fail to deliver the expected results in terms of overall performance, user experience and adaptation to realistic conditions. In this preliminary work we first highlight some of the challenges involved during the development of such systems. We then provide an overview of existing datasets available and highlight their limitations. We finally develop a model-in-the-loop wizard-of-oz based data collection tool and perform a pilot experiment.
Meta-Reinforcement Learning Using Model Parameters
Oct 27, 2022
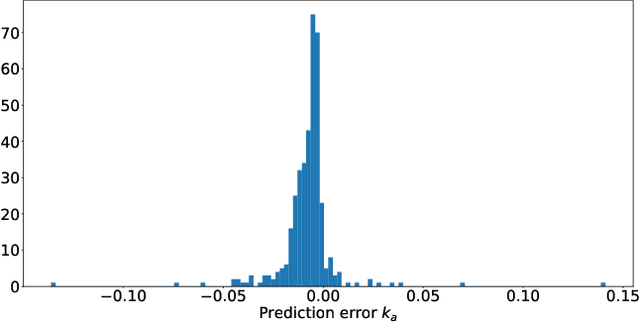
In meta-reinforcement learning, an agent is trained in multiple different environments and attempts to learn a meta-policy that can efficiently adapt to a new environment. This paper presents RAMP, a Reinforcement learning Agent using Model Parameters that utilizes the idea that a neural network trained to predict environment dynamics encapsulates the environment information. RAMP is constructed in two phases: in the first phase, a multi-environment parameterized dynamic model is learned. In the second phase, the model parameters of the dynamic model are used as context for the multi-environment policy of the model-free reinforcement learning agent.