 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-Coherent Over-the-Air Decentralized Stochastic Gradient Descent
Nov 19, 2022
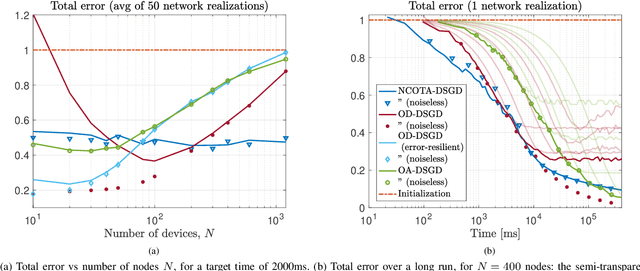
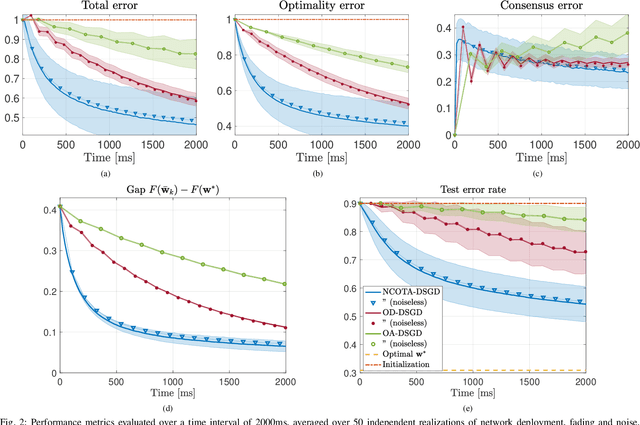
This paper proposes a Decentralized Stochastic Gradient Descent (DSGD) algorithm to solve distributed machine-learning tasks over wirelessly-connected systems, without the coordination of a base station. It combines local stochastic gradient descent steps with a Non-Coherent Over-The-Air (NCOTA) consensus scheme at the receivers, that enables concurrent transmissions by leveraging the waveform superposition properties of the wireless channels. With NCOTA, local optimization signals are mapped to a mixture of orthogonal preamble sequences and transmitted concurrently over the wireless channel under half-duplex constraints. Consensus is estimated by non-coherently combining the received signals with the preamble sequences and mitigating the impact of noise and fading via a consensus stepsize. NCOTA-DSGD operates without channel state information (typically used in over-the-air computation schemes for channel inversion) and leverages the channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization). It is shown that, with a suitable tuning of decreasing consensus and learning stepsizes, the error (measured as Euclidean distance) between the local and globally optimum models vanishes with rate $\mathcal O(k^{-1/4})$ after $k$ iterations. NCOTA-DSGD is evaluated numerically by solving an image classification task on the MNIST dataset, cast as a regularized cross-entropy loss minimization. Numerical results depict faster convergence vis-\`a-vis running time than implementations of the classical DSGD algorithm over digital and analog orthogonal channels, when the number of learning devices is large, under stringent delay constraints.
Monocular BEV Perception of Road Scenes via Front-to-Top View Projection
Nov 15, 2022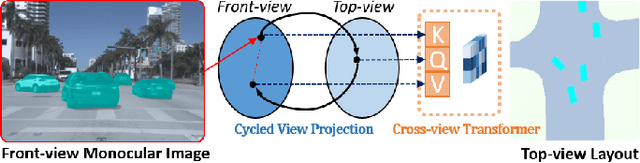
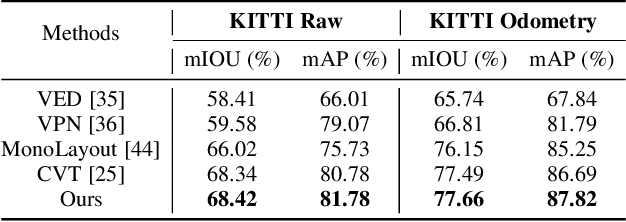
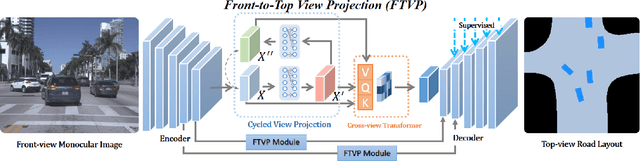
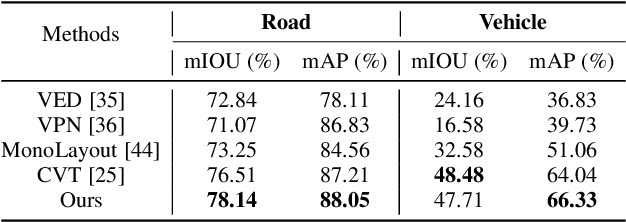
HD map reconstruction is crucial for autonomous driving. LiDAR-based methods are limited due to expensive sensors and time-consuming computation. Camera-based methods usually need to perform road segmentation and view transformation separately, which often causes distortion and missing content. To push the limits of the technology, we present a novel framework that reconstructs a local map formed by road layout and vehicle occupancy in the bird's-eye view given a front-view monocular image only. We propose a front-to-top view projection (FTVP) module, which takes the constraint of cycle consistency between views into account and makes full use of their correlation to strengthen the view transformation and scene understanding. In addition, we also apply multi-scale FTVP modules to propagate the rich spatial information of low-level features to mitigate spatial deviation of the predicted object location. Experiments on public benchmarks show that our method achieves the state-of-the-art performance in the tasks of road layout estimation, vehicle occupancy estimation, and multi-class semantic estimation. For multi-class semantic estimation, in particular, our model outperforms all competitors by a large margin. Furthermore, our model runs at 25 FPS on a single GPU, which is efficient and applicable for real-time panorama HD map reconstruction.
DIGEST: Deeply supervIsed knowledGE tranSfer neTwork learning for brain tumor segmentation with incomplete multi-modal MRI scans
Nov 15, 2022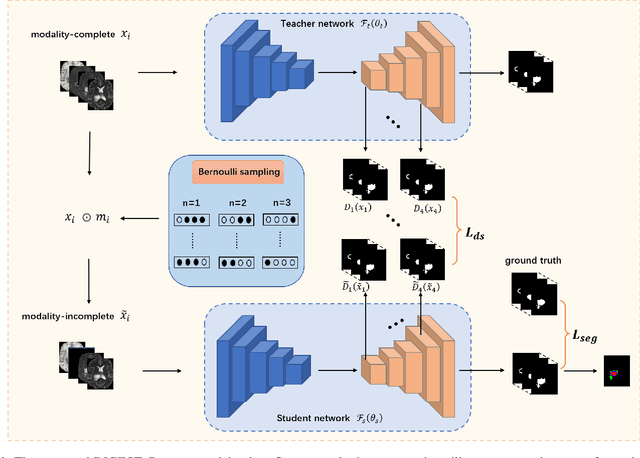
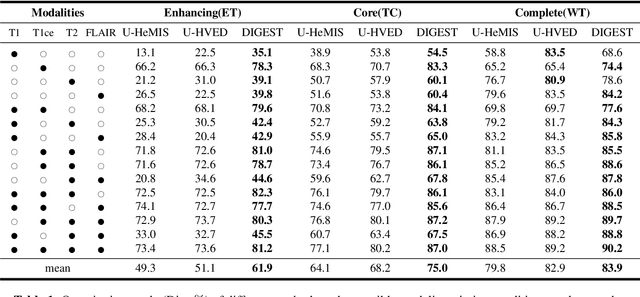
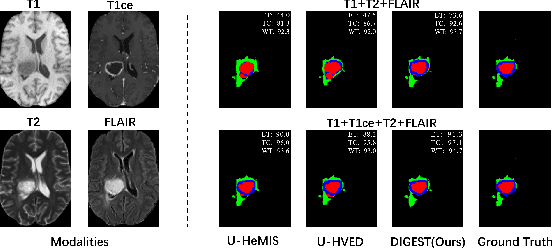
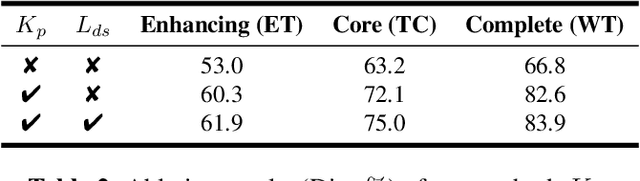
Brain tumor segmentation based on multi-modal magnetic resonance imaging (MRI) plays a pivotal role in assisting brain cancer diagnosis, treatment, and postoperative evaluations. Despite the achieved inspiring performance by existing automatic segmentation methods, multi-modal MRI data are still unavailable in real-world clinical applications due to quite a few uncontrollable factors (e.g. different imaging protocols, data corruption, and patient condition limitations), which lead to a large performance drop during practical applications. In this work, we propose a Deeply supervIsed knowledGE tranSfer neTwork (DIGEST), which achieves accurate brain tumor segmentation under different modality-missing scenarios. Specifically, a knowledge transfer learning frame is constructed, enabling a student model to learn modality-shared semantic information from a teacher model pretrained with the complete multi-modal MRI data. To simulate all the possible modality-missing conditions under the given multi-modal data, we generate incomplete multi-modal MRI samples based on Bernoulli sampling. Finally, a deeply supervised knowledge transfer loss is designed to ensure the consistency of the teacher-student structure at different decoding stages, which helps the extraction of inherent and effective modality representations. Experiments on the BraTS 2020 dataset demonstrate that our method achieves promising results for the incomplete multi-modal MR image segmentation task.
Region Embedding with Intra and Inter-View Contrastive Learning
Nov 15, 2022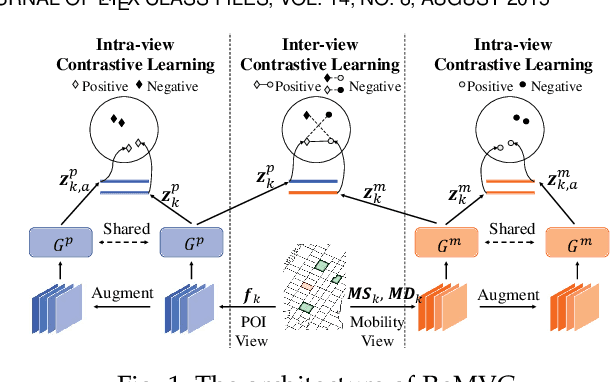
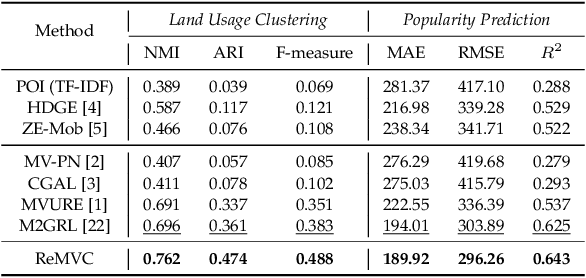
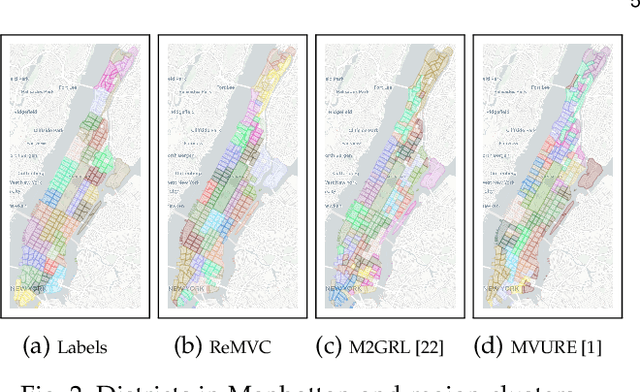
Unsupervised region representation learning aims to extract dense and effective features from unlabeled urban data. While some efforts have been made for solving this problem based on multiple views, existing methods are still insufficient in extracting representations in a view and/or incorporating representations from different views. Motivated by the success of contrastive learning for representation learning, we propose to leverage it for multi-view region representation learning and design a model called ReMVC (Region Embedding with Multi-View Contrastive Learning) by following two guidelines: i) comparing a region with others within each view for effective representation extraction and ii) comparing a region with itself across different views for cross-view information sharing. We design the intra-view contrastive learning module which helps to learn distinguished region embeddings and the inter-view contrastive learning module which serves as a soft co-regularizer to constrain the embedding parameters and transfer knowledge across multi-views. We exploit the learned region embeddings in two downstream tasks named land usage clustering and region popularity prediction. Extensive experiments demonstrate that our model achieves impressive improvements compared with seven state-of-the-art baseline methods, and the margins are over 30% in the land usage clustering task.
On Inferring User Socioeconomic Status with Mobility Records
Nov 15, 2022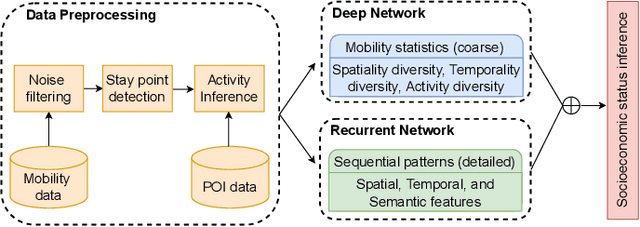
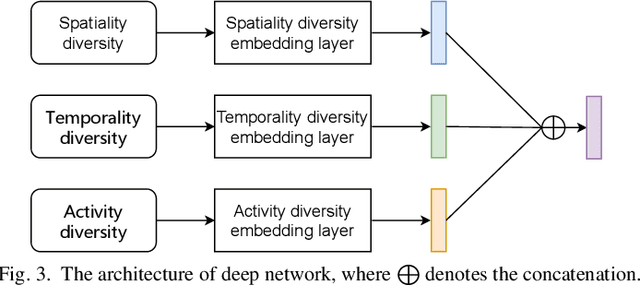
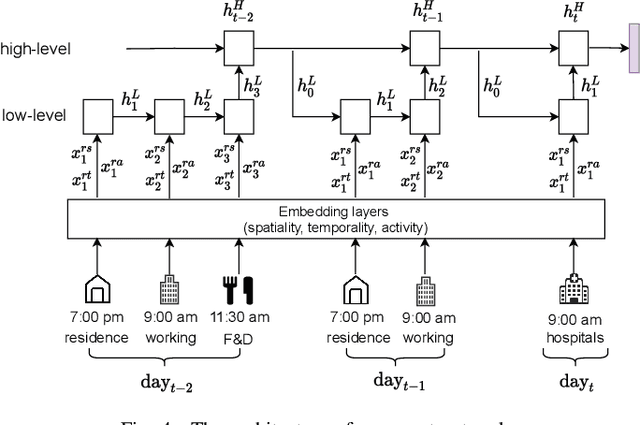
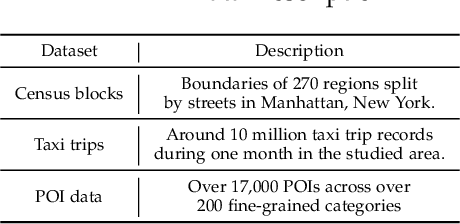
When users move in a physical space (e.g., an urban space), they would have some records called mobility records (e.g., trajectories) generated by devices such as mobile phones and GPS devices. Naturally, mobility records capture essential information of how users work, live and entertain in their daily lives, and therefore, they have been used in a wide range of tasks such as user profile inference, mobility prediction and traffic management. In this paper, we expand this line of research by investigating the problem of inferring user socioeconomic statuses (such as prices of users' living houses as a proxy of users' socioeconomic statuses) based on their mobility records, which can potentially be used in real-life applications such as the car loan business. For this task, we propose a socioeconomic-aware deep model called DeepSEI. The DeepSEI model incorporates two networks called deep network and recurrent network, which extract the features of the mobility records from three aspects, namely spatiality, temporality and activity, one at a coarse level and the other at a detailed level. We conduct extensive experiments on real mobility records data, POI data and house prices data. The results verify that the DeepSEI model achieves superior performance than existing studies. All datasets used in this paper will be made publicly available.
Navigating Connected Memories with a Task-oriented Dialog System
Nov 15, 2022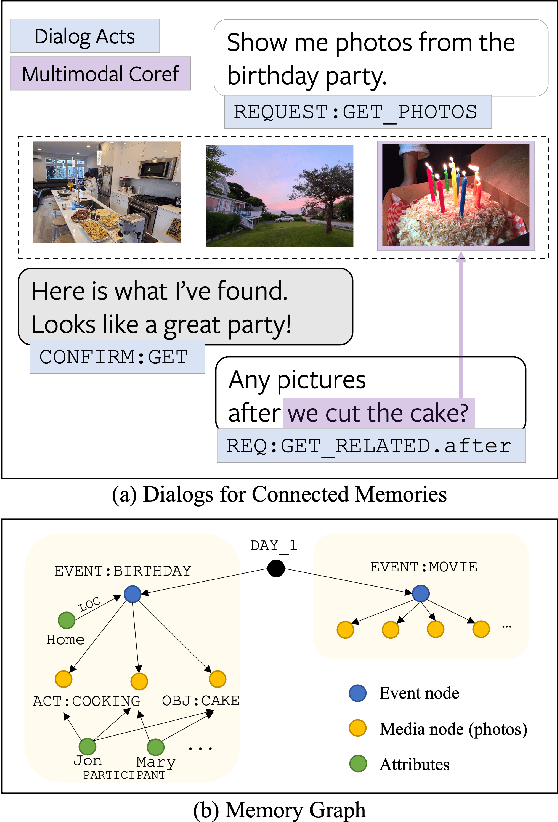

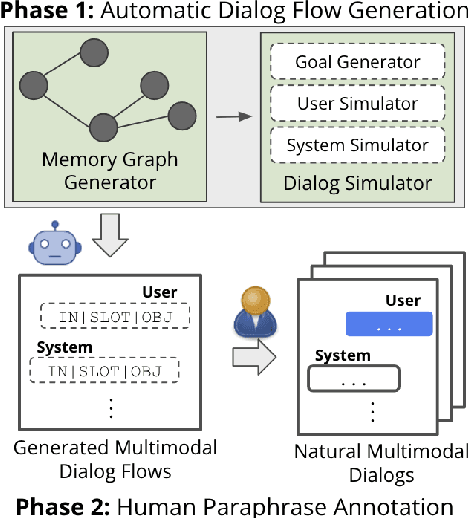

Recent years have seen an increasing trend in the volume of personal media captured by users, thanks to the advent of smartphones and smart glasses, resulting in large media collections. Despite conversation being an intuitive human-computer interface, current efforts focus mostly on single-shot natural language based media retrieval to aid users query their media and re-live their memories. This severely limits the search functionality as users can neither ask follow-up queries nor obtain information without first formulating a single-turn query. In this work, we propose dialogs for connected memories as a powerful tool to empower users to search their media collection through a multi-turn, interactive conversation. Towards this, we collect a new task-oriented dialog dataset COMET, which contains $11.5k$ user<->assistant dialogs (totaling $103k$ utterances), grounded in simulated personal memory graphs. We employ a resource-efficient, two-phase data collection pipeline that uses: (1) a novel multimodal dialog simulator that generates synthetic dialog flows grounded in memory graphs, and, (2) manual paraphrasing to obtain natural language utterances. We analyze COMET, formulate four main tasks to benchmark meaningful progress, and adopt state-of-the-art language models as strong baselines, in order to highlight the multimodal challenges captured by our dataset.
Breakpoint Transformers for Modeling and Tracking Intermediate Beliefs
Nov 15, 2022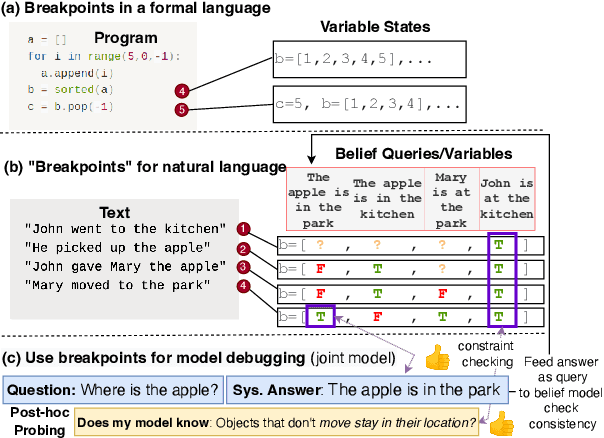

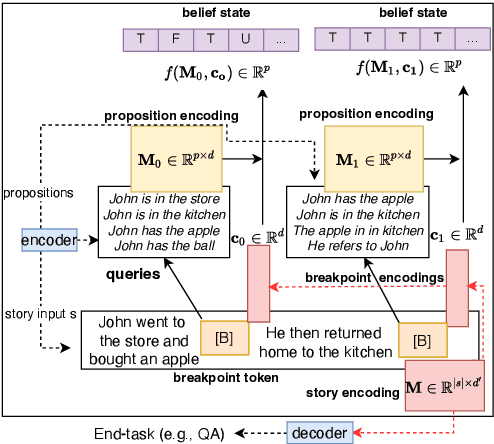
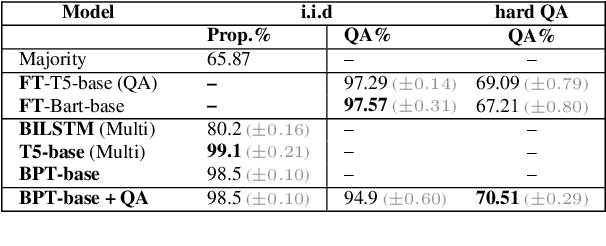
Can we teach natural language understanding models to track their beliefs through intermediate points in text? We propose a representation learning framework called breakpoint modeling that allows for learning of this type. Given any text encoder and data marked with intermediate states (breakpoints) along with corresponding textual queries viewed as true/false propositions (i.e., the candidate beliefs of a model, consisting of information changing through time) our approach trains models in an efficient and end-to-end fashion to build intermediate representations that facilitate teaching and direct querying of beliefs at arbitrary points alongside solving other end tasks. To show the benefit of our approach, we experiment with a diverse set of NLU tasks including relational reasoning on CLUTRR and narrative understanding on bAbI. Using novel belief prediction tasks for both tasks, we show the benefit of our main breakpoint transformer, based on T5, over conventional representation learning approaches in terms of processing efficiency, prediction accuracy and prediction consistency, all with minimal to no effect on corresponding QA end tasks. To show the feasibility of incorporating our belief tracker into more complex reasoning pipelines, we also obtain SOTA performance on the three-tiered reasoning challenge for the TRIP benchmark (around 23-32% absolute improvement on Tasks 2-3).
Visually Grounded VQA by Lattice-based Retrieval
Nov 15, 2022
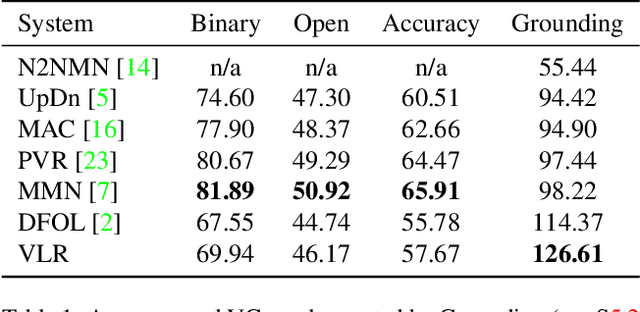

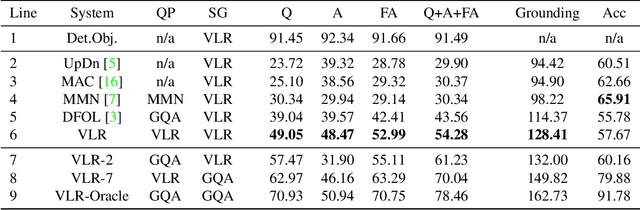
Visual Grounding (VG) in Visual Question Answering (VQA) systems describes how well a system manages to tie a question and its answer to relevant image regions. Systems with strong VG are considered intuitively interpretable and suggest an improved scene understanding. While VQA accuracy performances have seen impressive gains over the past few years, explicit improvements to VG performance and evaluation thereof have often taken a back seat on the road to overall accuracy improvements. A cause of this originates in the predominant choice of learning paradigm for VQA systems, which consists of training a discriminative classifier over a predetermined set of answer options. In this work, we break with the dominant VQA modeling paradigm of classification and investigate VQA from the standpoint of an information retrieval task. As such, the developed system directly ties VG into its core search procedure. Our system operates over a weighted, directed, acyclic graph, a.k.a. "lattice", which is derived from the scene graph of a given image in conjunction with region-referring expressions extracted from the question. We give a detailed analysis of our approach and discuss its distinctive properties and limitations. Our approach achieves the strongest VG performance among examined systems and exhibits exceptional generalization capabilities in a number of scenarios.
Tracking Dataset IP Use in Deep Neural Networks
Nov 24, 2022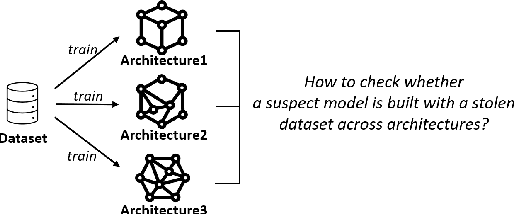
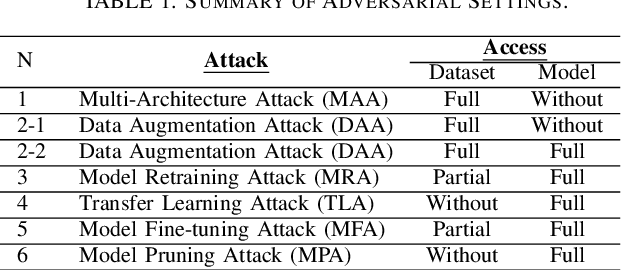
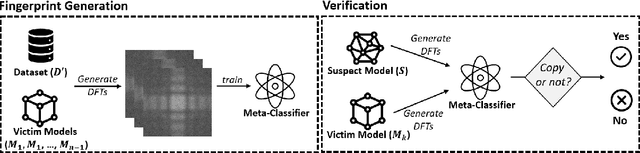
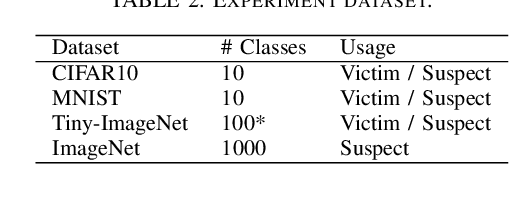
Training highly performant deep neural networks (DNNs) typically requires the collection of a massive dataset and the use of powerful computing resources. Therefore, unauthorized redistribution of private pre-trained DNNs may cause severe economic loss for model owners. For protecting the ownership of DNN models, DNN watermarking schemes have been proposed by embedding secret information in a DNN model and verifying its presence for model ownership. However, existing DNN watermarking schemes compromise the model utility and are vulnerable to watermark removal attacks because a model is modified with a watermark. Alternatively, a new approach dubbed DEEPJUDGE was introduced to measure the similarity between a suspect model and a victim model without modifying the victim model. However, DEEPJUDGE would only be designed to detect the case where a suspect model's architecture is the same as a victim model's. In this work, we propose a novel DNN fingerprinting technique dubbed DEEPTASTER to prevent a new attack scenario in which a victim's data is stolen to build a suspect model. DEEPTASTER can effectively detect such data theft attacks even when a suspect model's architecture differs from a victim model's. To achieve this goal, DEEPTASTER generates a few adversarial images with perturbations, transforms them into the Fourier frequency domain, and uses the transformed images to identify the dataset used in a suspect model. The intuition is that those adversarial images can be used to capture the characteristics of DNNs built on a specific dataset. We evaluated the detection accuracy of DEEPTASTER on three datasets with three model architectures under various attack scenarios, including transfer learning, pruning, fine-tuning, and data augmentation. Overall, DEEPTASTER achieves a balanced accuracy of 94.95%, which is significantly better than 61.11% achieved by DEEPJUDGE in the same settings.
Self-supervised Amodal Video Object Segmentation
Oct 23, 2022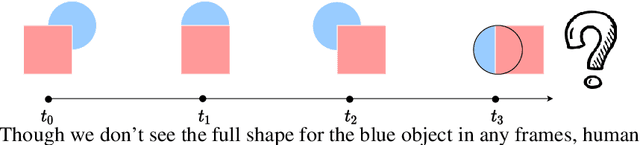
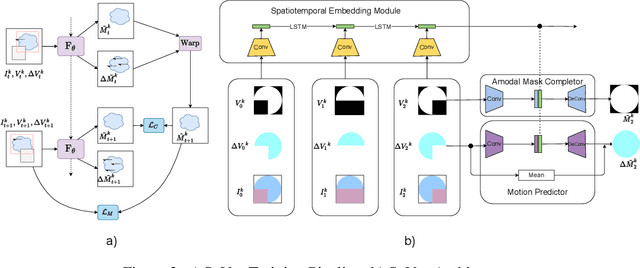
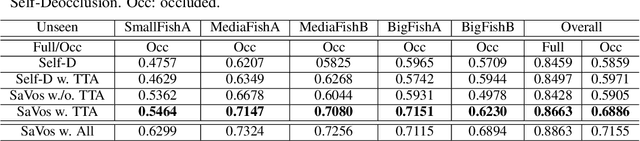

Amodal perception requires inferring the full shape of an object that is partially occluded. This task is particularly challenging on two levels: (1) it requires more information than what is contained in the instant retina or imaging sensor, (2) it is difficult to obtain enough well-annotated amodal labels for supervision. To this end, this paper develops a new framework of Self-supervised amodal Video object segmentation (SaVos). Our method efficiently leverages the visual information of video temporal sequences to infer the amodal mask of objects. The key intuition is that the occluded part of an object can be explained away if that part is visible in other frames, possibly deformed as long as the deformation can be reasonably learned. Accordingly, we derive a novel self-supervised learning paradigm that efficiently utilizes the visible object parts as the supervision to guide the training on videos. In addition to learning type prior to complete masks for known types, SaVos also learns the spatiotemporal prior, which is also useful for the amodal task and could generalize to unseen types. The proposed framework achieves the state-of-the-art performance on the synthetic amodal segmentation benchmark FISHBOWL and the real world benchmark KINS-Video-Car. Further, it lends itself well to being transferred to novel distributions using test-time adaptation, outperforming existing models even after the transfer to a new distribution.