 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decomposing User-APP Graph into Subgraphs for Effective APP and User Embedding Learning
Oct 13, 2022
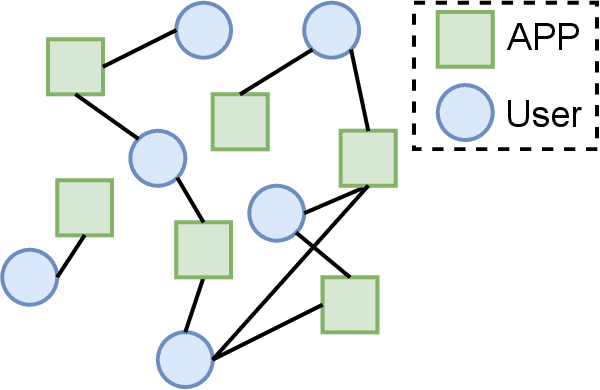
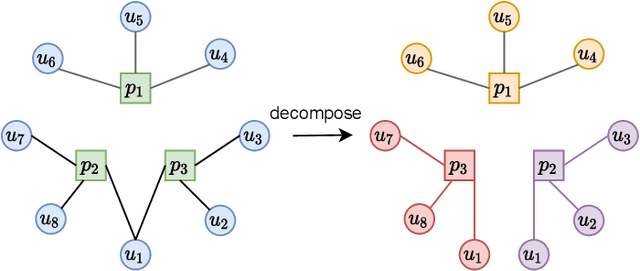
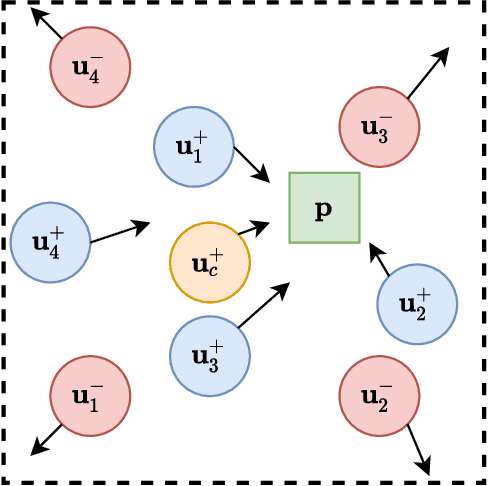
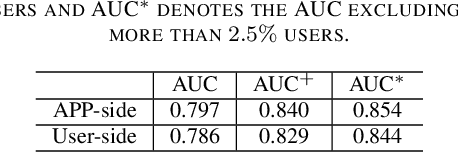
APP-installation information is helpful to describe the user's characteristics. The users with similar APPs installed might share several common interests and behave similarly in some scenarios. In this work, we learn a user embedding vector based on each user's APP-installation information. Since the user APP-installation embedding is learnable without dependency on the historical intra-APP behavioral data of the user, it complements the intra-APP embedding learned within each specific APP. Thus, they considerably help improve the effectiveness of the personalized advertising in each APP, and they are particularly beneficial for the cold start of the new users in the APP. In this paper, we formulate the APP-installation user embedding learning into a bipartite graph embedding problem. The main challenge in learning an effective APP-installation user embedding is the imbalanced data distribution. In this case, graph learning tends to be dominated by the popular APPs, which billions of users have installed. In other words, some niche/specialized APPs might have a marginal influence on graph learning. To effectively exploit the valuable information from the niche APPs, we decompose the APP-installation graph into a set of subgraphs. Each subgraph contains only one APP node and the users who install the APP. For each mini-batch, we only sample the users from the same subgraph in the training process. Thus, each APP can be involved in the training process in a more balanced manner. After integrating the learned APP-installation user embedding into our online personal advertising platform, we obtained a considerable boost in CTR, CVR, and revenue.
OReX: Object Reconstruction from Planner Cross-sections Using Neural Fields
Nov 23, 2022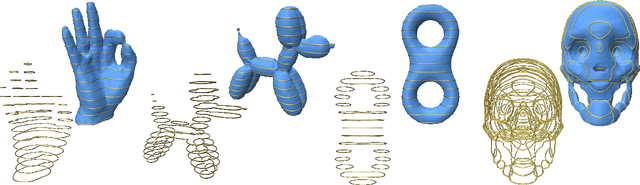

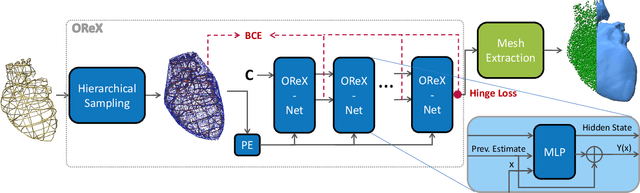
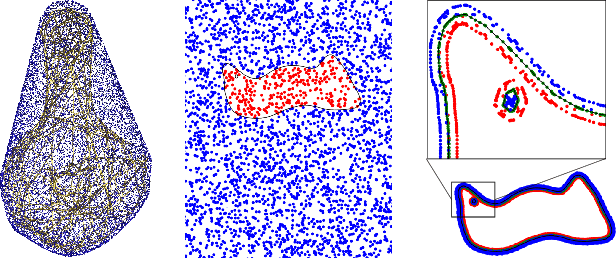
Reconstructing 3D shapes from planar cross-sections is a challenge inspired by downstream applications like medical imaging and geographic informatics. The input is an in/out indicator function fully defined on a sparse collection of planes in space, and the output is an interpolation of the indicator function to the entire volume. Previous works addressing this sparse and ill-posed problem either produce low quality results, or rely on additional priors such as target topology, appearance information, or input normal directions. In this paper, we present OReX, a method for 3D shape reconstruction from slices alone, featuring a Neural Field as the interpolation prior. A simple neural network is trained on the input planes to receive a 3D coordinate and return an inside/outside estimate for the query point. This prior is powerful in inducing smoothness and self-similarities. The main challenge for this approach is high-frequency details, as the neural prior is overly smoothing. To alleviate this, we offer an iterative estimation architecture and a hierarchical input sampling scheme that encourage coarse-to-fine training, allowing focusing on high frequencies at later stages. In addition, we identify and analyze a common ripple-like effect stemming from the mesh extraction step. We mitigate it by regularizing the spatial gradients of the indicator function around input in/out boundaries, cutting the problem at the root. Through extensive qualitative and quantitative experimentation, we demonstrate our method is robust, accurate, and scales well with the size of the input. We report state-of-the-art results compared to previous approaches and recent potential solutions, and demonstrate the benefit of our individual contributions through analysis and ablation studies.
Context-Aware Query Rewriting for Improving Users' Search Experience on E-commerce Websites
Sep 24, 2022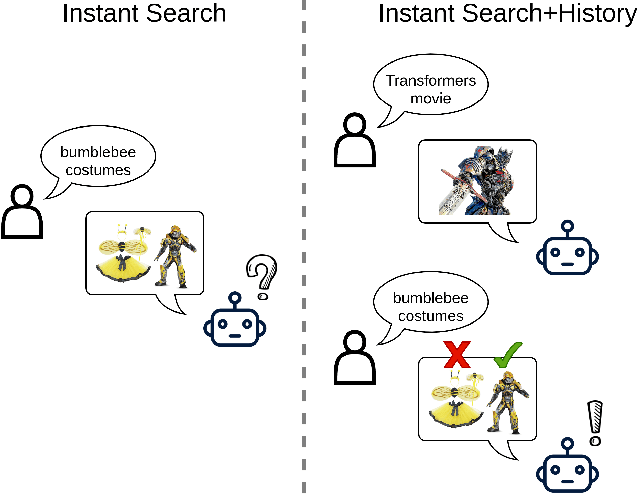
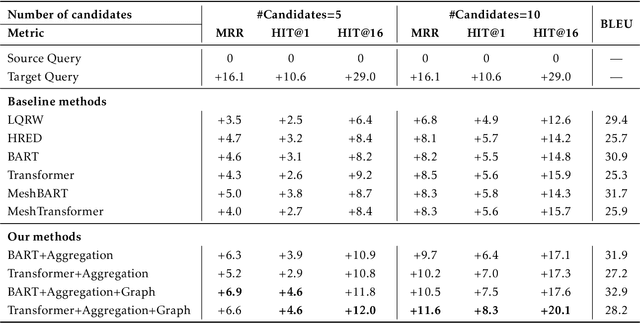
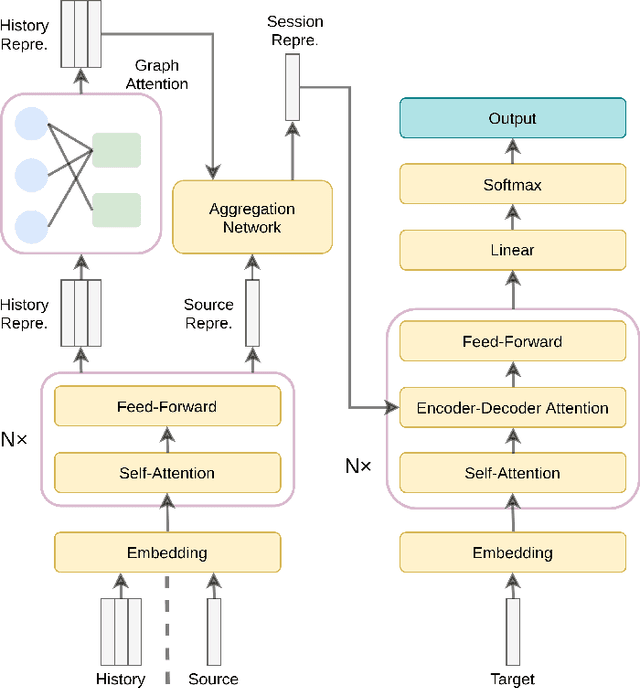
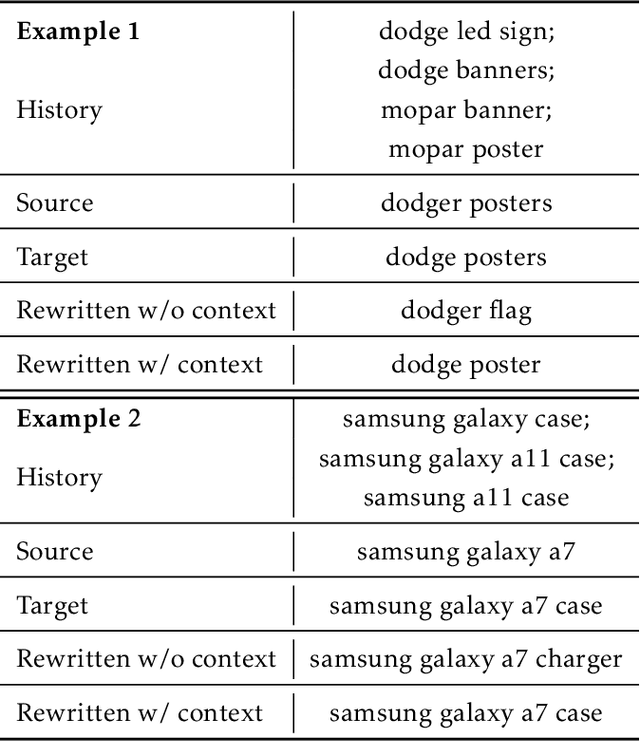
E-commerce queries are often short and ambiguous. Consequently, query understanding often uses query rewriting to disambiguate user-input queries. While using e-commerce search tools, users tend to enter multiple searches, which we call context, before purchasing. These history searches contain contextual insights about users' true shopping intents. Therefore, modeling such contextual information is critical to a better query rewriting model. However, existing query rewriting models ignore users' history behaviors and consider only the instant search query, which is often a short string offering limited information about the true shopping intent. We propose an end-to-end context-aware query rewriting model to bridge this gap, which takes the search context into account. Specifically, our model builds a session graph using the history search queries and their contained words. We then employ a graph attention mechanism that models cross-query relations and computes contextual information of the session. The model subsequently calculates session representations by combining the contextual information with the instant search query using an aggregation network. The session representations are then decoded to generate rewritten queries. Empirically, we demonstrate the superiority of our method to state-of-the-art approaches under various metrics. On in-house data from an online shopping platform, by introducing contextual information, our model achieves 11.6% improvement under the MRR (Mean Reciprocal Rank) metric and 20.1% improvement under the HIT@16 metric (a hit rate metric), in comparison with the best baseline method (Transformer-based model).
Supervised Contrastive Learning with TPE-based Bayesian Optimization of Tabular Data for Imbalanced Learning
Oct 19, 2022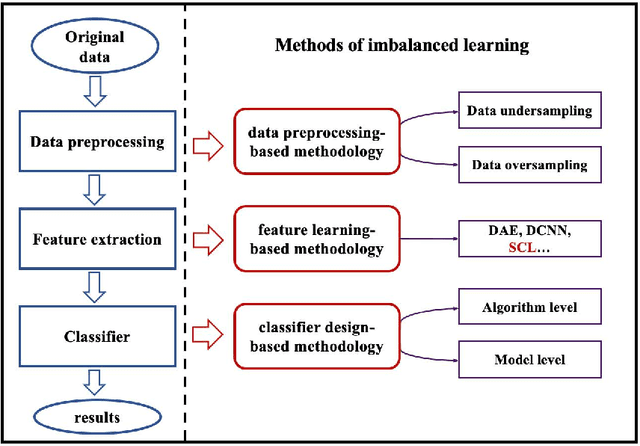
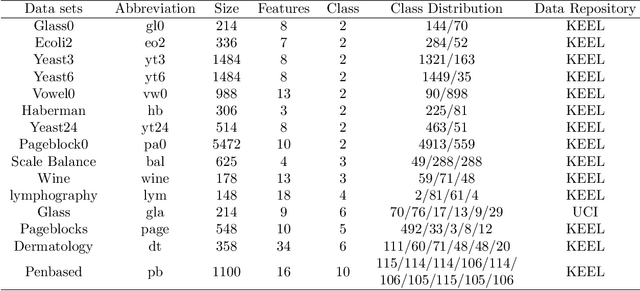
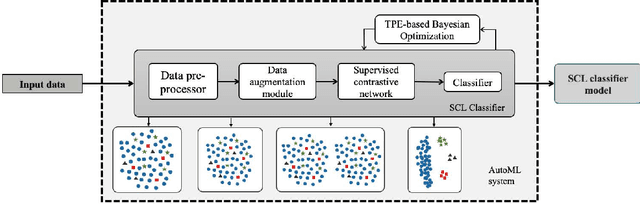
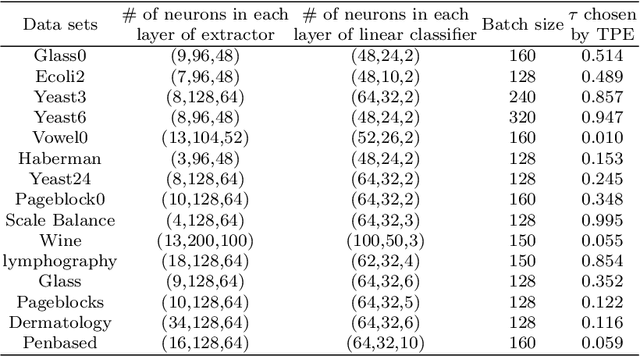
Class imbalance has a detrimental effect on the predictive performance of most supervised learning algorithms as the imbalanced distribution can lead to a bias preferring the majority class. To solve this problem, we propose a Supervised Contrastive Learning (SCL) method with Bayesian optimization technique based on Tree-structured Parzen Estimator (TPE) for imbalanced tabular datasets. Compared with supervised learning, contrastive learning can avoid "label bias" by extracting the information hidden in data. Based on contrastive loss, SCL can exploit the label information to address insufficient data augmentation of tabular data, and is thus used in the proposed SCL-TPE method to learn a discriminative representation of data. Additionally, as the hyper-parameter temperature has a decisive influence on the SCL performance and is difficult to tune, TPE-based Bayesian optimization is introduced to automatically select the best temperature. Experiments are conducted on both binary and multi-class imbalanced tabular datasets. As shown in the results obtained, TPE outperforms other hyper-parameter optimization (HPO) methods such as grid search, random search, and genetic algorithm. More importantly, the proposed SCL-TPE method achieves much-improved performance compared with the state-of-the-art methods.
Asymmetric Distillation Post-Segmentation Method for Image Anomaly Detection
Oct 19, 2022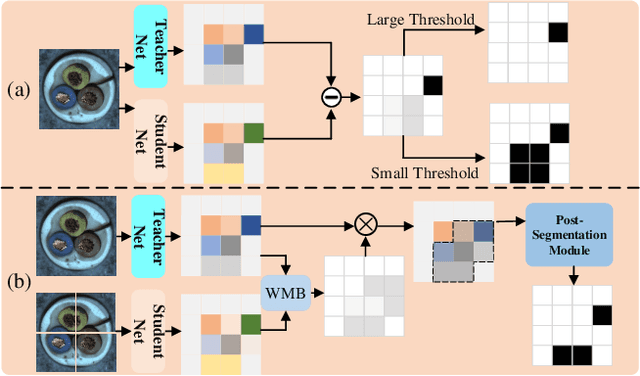
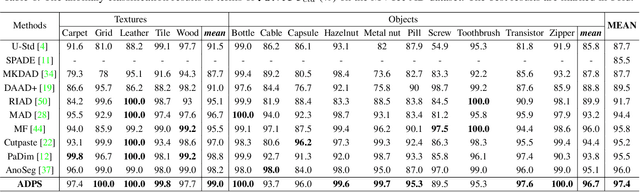
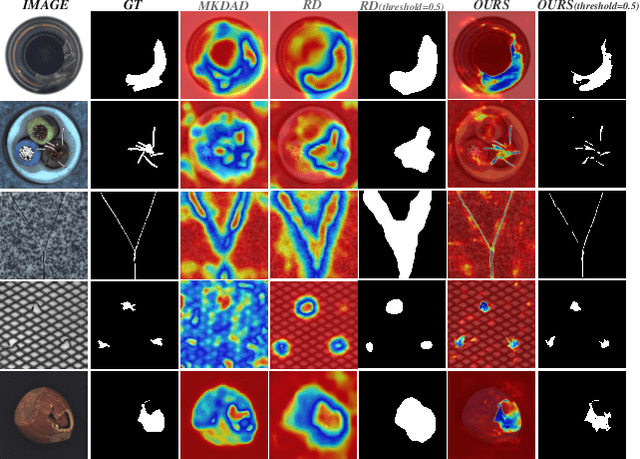
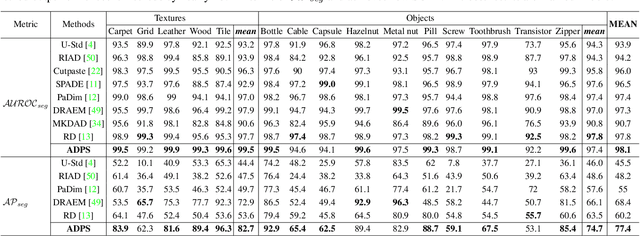
Knowledge distillation-based anomaly detection methods generate same outputs for unknown classes due to the symmetric form of the input and ignore the powerful semantic information of the output of the teacher network since it is only used as a "reference standard". Towards this end, this work proposes a novel Asymmetric Distillation Post-Segmentation (ADPS) method to effectively explore the asymmetric structure of the input and the discriminative features of the teacher network. Specifically, a simple yet effective asymmetric input approach is proposed to make different data flows through the teacher and student networks. The student network enables to have different inductive and expressive abilities, which can generate different outputs in anomalous regions. Besides, to further explore the semantic information of the teacher network and obtain effective discriminative boundaries, the Weight Mask Block (WMB) and the post-segmentation module are proposede. WMB leverages a weighted strategy by exploring teacher-student feature maps to highlight anomalous features. The post-segmentation module further learns the anomalous features and obtains valid discriminative boundaries. Experimental results on three benchmark datasets demonstrate that the proposed ADPS achieves state-of-the-art anomaly segmentation results.
Synthetic Model Combination: An Instance-wise Approach to Unsupervised Ensemble Learning
Oct 11, 2022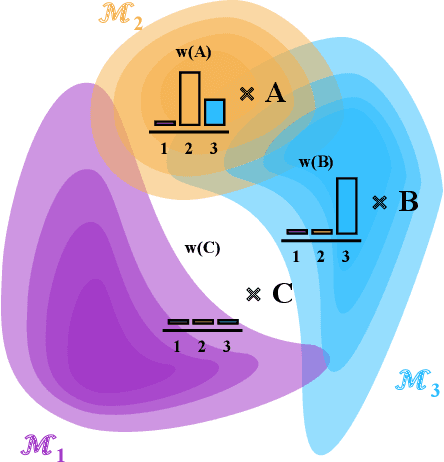

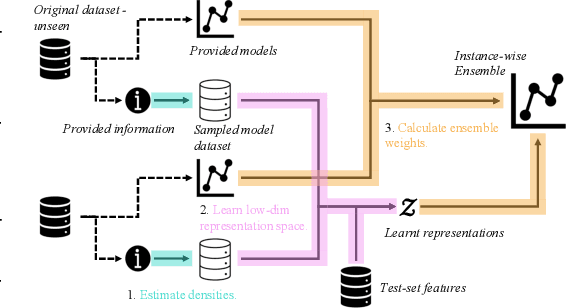
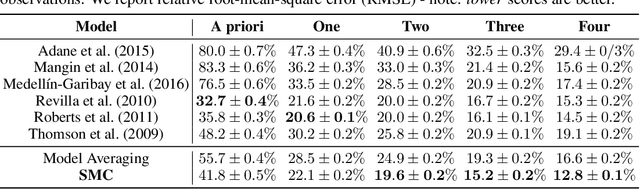
Consider making a prediction over new test data without any opportunity to learn from a training set of labelled data - instead given access to a set of expert models and their predictions alongside some limited information about the dataset used to train them. In scenarios from finance to the medical sciences, and even consumer practice, stakeholders have developed models on private data they either cannot, or do not want to, share. Given the value and legislation surrounding personal information, it is not surprising that only the models, and not the data, will be released - the pertinent question becoming: how best to use these models? Previous work has focused on global model selection or ensembling, with the result of a single final model across the feature space. Machine learning models perform notoriously poorly on data outside their training domain however, and so we argue that when ensembling models the weightings for individual instances must reflect their respective domains - in other words models that are more likely to have seen information on that instance should have more attention paid to them. We introduce a method for such an instance-wise ensembling of models, including a novel representation learning step for handling sparse high-dimensional domains. Finally, we demonstrate the need and generalisability of our method on classical machine learning tasks as well as highlighting a real world use case in the pharmacological setting of vancomycin precision dosing.
Dynamic MLP for Fine-Grained Image Classification by Leveraging Geographical and Temporal Information
Mar 07, 2022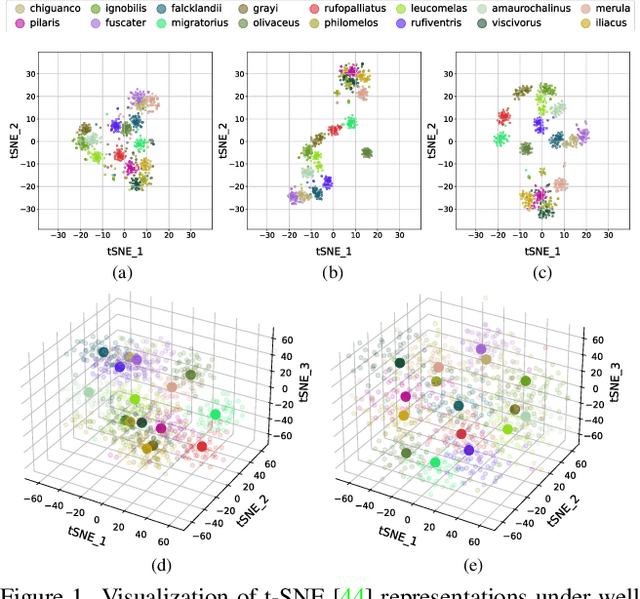
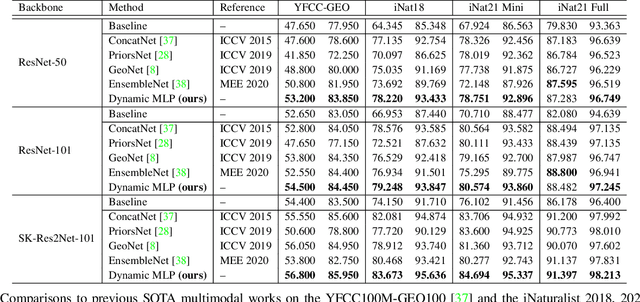
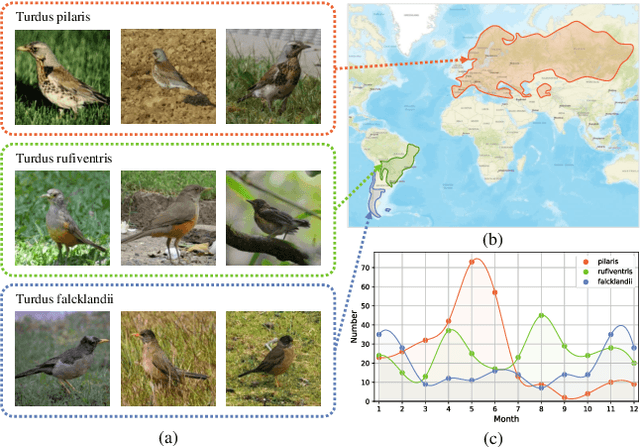
Fine-grained image classification is a challenging computer vision task where various species share similar visual appearances, resulting in misclassification if merely based on visual clues. Therefore, it is helpful to leverage additional information, e.g., the locations and dates for data shooting, which can be easily accessible but rarely exploited. In this paper, we first demonstrate that existing multimodal methods fuse multiple features only on a single dimension, which essentially has insufficient help in feature discrimination. To fully explore the potential of multimodal information, we propose a dynamic MLP on top of the image representation, which interacts with multimodal features at a higher and broader dimension. The dynamic MLP is an efficient structure parameterized by the learned embeddings of variable locations and dates. It can be regarded as an adaptive nonlinear projection for generating more discriminative image representations in visual tasks. To our best knowledge, it is the first attempt to explore the idea of dynamic networks to exploit multimodal information in fine-grained image classification tasks. Extensive experiments demonstrate the effectiveness of our method. The t-SNE algorithm visually indicates that our technique improves the recognizability of image representations that are visually similar but with different categories. Furthermore, among published works across multiple fine-grained datasets, dynamic MLP consistently achieves SOTA results https://paperswithcode.com/dataset/inaturalist and takes third place in the iNaturalist challenge at FGVC8 https://www.kaggle.com/c/inaturalist-2021/leaderboard. Code is available at https://github.com/ylingfeng/DynamicMLP.git
Information Elicitation Meets Clustering
Oct 03, 2021
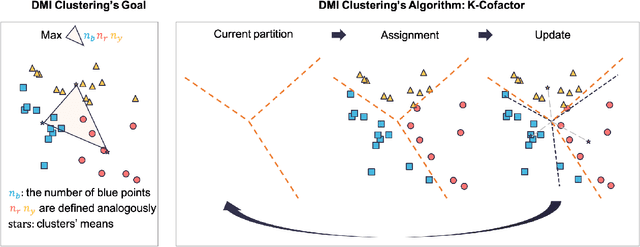
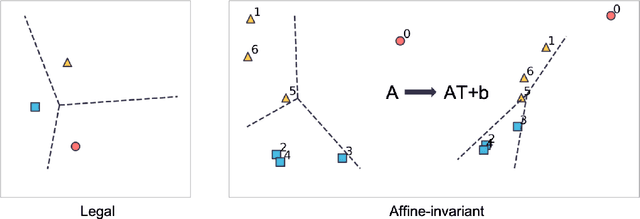
In the setting where we want to aggregate people's subjective evaluations, plurality vote may be meaningless when a large amount of low-effort people always report "good" regardless of the true quality. "Surprisingly popular" method, picking the most surprising answer compared to the prior, handle this issue to some extent. However, it is still not fully robust to people's strategies. Here in the setting where a large number of people are asked to answer a small number of multi-choice questions (multi-task, large group), we propose an information aggregation method that is robust to people's strategies. Interestingly, this method can be seen as a rotated "surprisingly popular". It is based on a new clustering method, Determinant MaxImization (DMI)-clustering, and a key conceptual idea that information elicitation without ground-truth can be seen as a clustering problem. Of independent interest, DMI-clustering is a general clustering method that aims to maximize the volume of the simplex consisting of each cluster's mean multiplying the product of the cluster sizes. We show that DMI-clustering is invariant to any non-degenerate affine transformation for all data points. When the data point's dimension is a constant, DMI-clustering can be solved in polynomial time. In general, we present a simple heuristic for DMI-clustering which is very similar to Lloyd's algorithm for k-means. Additionally, we also apply the clustering idea in the single-task setting and use the spectral method to propose a new aggregation method that utilizes the second-moment information elicited from the crowds.
Multi-view Local Co-occurrence and Global Consistency Learning Improve Mammogram Classification Generalisation
Sep 21, 2022When analysing screening mammograms, radiologists can naturally process information across two ipsilateral views of each breast, namely the cranio-caudal (CC) and mediolateral-oblique (MLO) views. These multiple related images provide complementary diagnostic information and can improve the radiologist's classification accuracy. Unfortunately, most existing deep learning systems, trained with globally-labelled images, lack the ability to jointly analyse and integrate global and local information from these multiple views. By ignoring the potentially valuable information present in multiple images of a screening episode, one limits the potential accuracy of these systems. Here, we propose a new multi-view global-local analysis method that mimics the radiologist's reading procedure, based on a global consistency learning and local co-occurrence learning of ipsilateral views in mammograms. Extensive experiments show that our model outperforms competing methods, in terms of classification accuracy and generalisation, on a large-scale private dataset and two publicly available datasets, where models are exclusively trained and tested with global labels.
A kinetic approach to consensus-based segmentation of biomedical images
Nov 08, 2022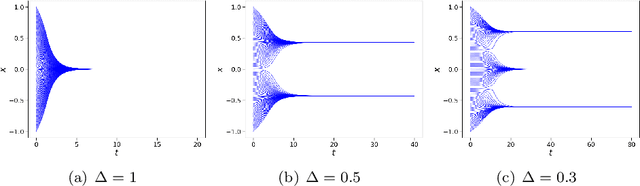
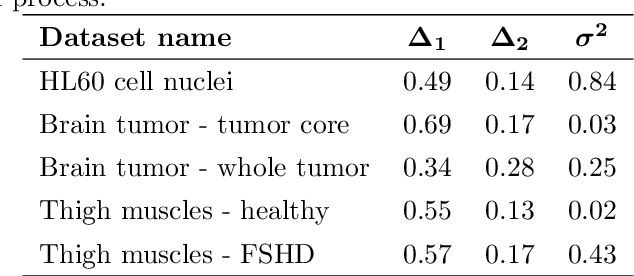
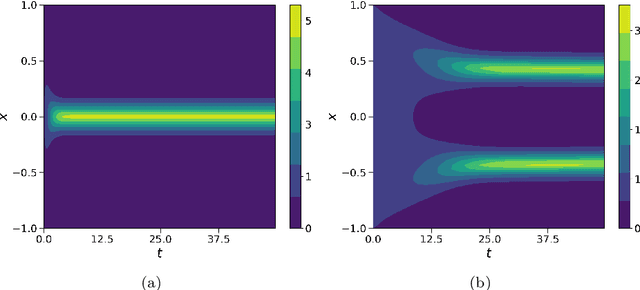
In this work, we apply a kinetic version of a bounded confidence consensus model to biomedical segmentation problems. In the presented approach, time-dependent information on the microscopic state of each particle/pixel includes its space position and a feature representing a static characteristic of the system, i.e. the gray level of each pixel. From the introduced microscopic model we derive a kinetic formulation of the model. The large time behavior of the system is then computed with the aid of a surrogate Fokker-Planck approach that can be obtained in the quasi-invariant scaling. We exploit the computational efficiency of direct simulation Monte Carlo methods for the obtained Boltzmann-type description of the problem for parameter identification tasks. Based on a suitable loss function measuring the distance between the ground truth segmentation mask and the evaluated mask, we minimize the introduced segmentation metric for a relevant set of 2D gray-scale images. Applications to biomedical segmentation concentrate on different imaging research contexts.