 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
Nov 18, 2022


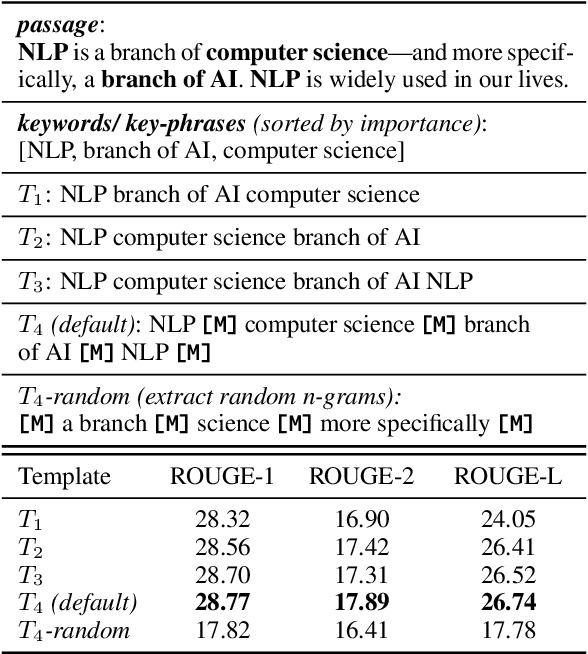

We introduce GENIUS: a conditional text generation model using sketches as input, which can fill in the missing contexts for a given sketch (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel reconstruction from sketch objective using an extreme and selective masking strategy, enabling it to generate diverse and high-quality texts given sketches. Comparison with other competitive conditional language models (CLMs) reveals the superiority of GENIUS's text generation quality. We further show that GENIUS can be used as a strong and ready-to-use data augmentation tool for various natural language processing (NLP) tasks. Most existing textual data augmentation methods are either too conservative, by making small changes to the original text, or too aggressive, by creating entirely new samples. With GENIUS, we propose GeniusAug, which first extracts the target-aware sketches from the original training set and then generates new samples based on the sketches. Empirical experiments on 6 text classification datasets show that GeniusAug significantly improves the models' performance in both in-distribution (ID) and out-of-distribution (OOD) settings. We also demonstrate the effectiveness of GeniusAug on named entity recognition (NER) and machine reading comprehension (MRC) tasks. (Code and models are publicly available at https://github.com/microsoft/SCGLab and https://github.com/beyondguo/genius)
Multiuser-MIMO Systems Using Comparator Network-Aided Receivers With 1-Bit Quantization
Nov 18, 2022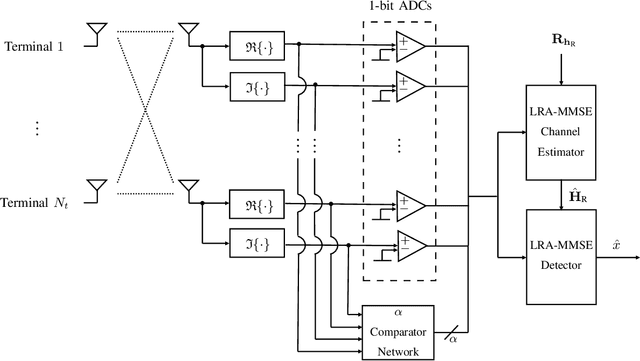
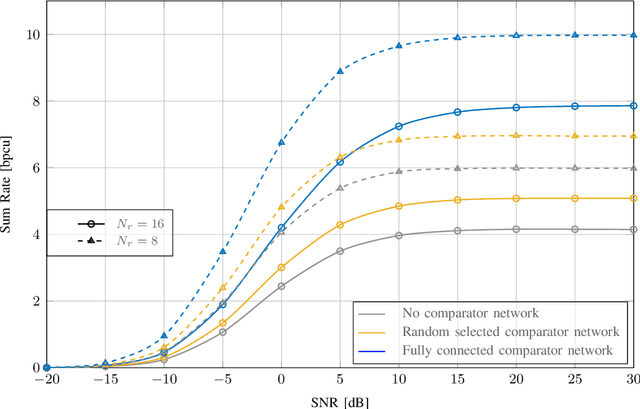
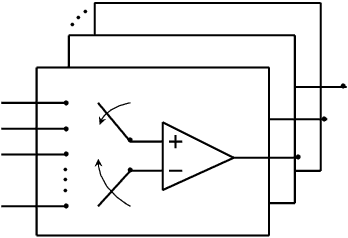
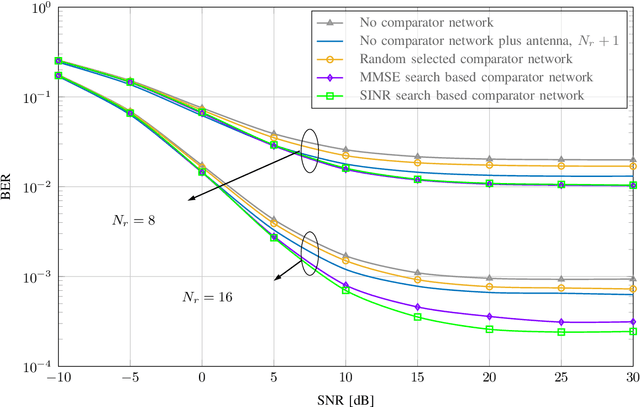
Low-resolution analog-to-digital converters (ADCs) are promising for reducing energy consumption and costs of multiuser multiple-input multiple-output (MIMO) systems with many antennas. We propose low-resolution multiuser MIMO receivers where the signals are simultaneously processed by 1-bit ADCs and a comparator network, which can be interpreted as additional virtual channels with binary outputs. We distinguish the proposed comparator networks in fully and partially connected. For such receivers, we develop the low-resolution aware linear minimum mean-squared error (LRA-LMMSE) channel estimator and detector according to the Bussgang theorem. We also develop a robust detector which takes into account the channel state information (CSI) mismatch statistics. By exploiting knowledge of the channel coefficients we devise a mean-square error (MSE) greedy search and a sequential signal-to-interference-plus-noise ratio (SINR) search for optimization of partially connected networks. Numerical results show that a system with extra virtual channels can outperform a system with additional receive antennas, in terms of bit error rate (BER). Furthermore, by employing the proposed channel estimation with its error statistics, we construct a lower bound on the ergodic sum rate for a linear receiver. Simulation results confirm that the proposed approach outperforms the conventional 1-bit MIMO system in terms of BER, MSE and sum rate.
Using Supervised Deep-Learning to Model Edge-FBG Shape Sensors
Oct 28, 2022Continuum robots in robot-assisted minimally invasive surgeries provide adequate access to target anatomies that are not directly reachable through small incisions. Achieving precise and reliable motion control of such snake-like manipulators necessitates an accurate navigation system that requires no line-of-sight and is immune to electromagnetic noises. Fiber Bragg Grating (FBG) shape sensors, particularly edge-FBGs, are promising tools for this task. However, in edge-FBG sensors, the intensity ratio between Bragg wavelengths carries the strain information that can be affected by undesired bending-related phenomena, making standard characterization techniques less suitable for these sensors. We showed in our previous work that a deep learning model has the potential to extract the strain information from the full edge-FBG spectrum and accurately predict the sensor's shape. In this paper, we conduct a more thorough investigation to find a suitable architectural design with lower prediction errors. We use the Hyperband algorithm to search for optimal hyperparameters in two steps. First, we limit the search space to layer settings, where the best-performing configuration gets selected. Then, we modify the search space for tuning the training and loss calculation hyperparameters. We also analyze various data transformations on the input and output variables, as data rescaling can directly influence the model's performance. Moreover, we performed discriminative training using Siamese network architecture that employs two CNNs with identical parameters to learn similarity metrics between the spectra of similar target values. The best-performing network architecture among all evaluated configurations can predict the sensor's shape with a median tip error of 3.11 mm.
Multimodal Contrastive Learning via Uni-Modal Coding and Cross-Modal Prediction for Multimodal Sentiment Analysis
Oct 26, 2022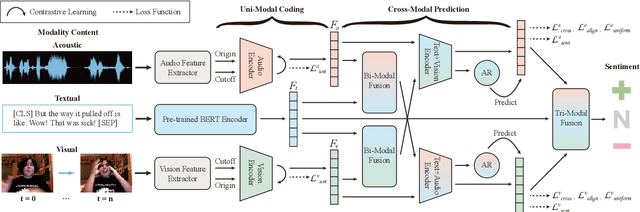
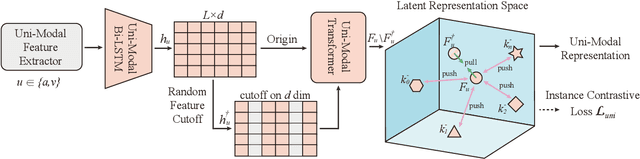
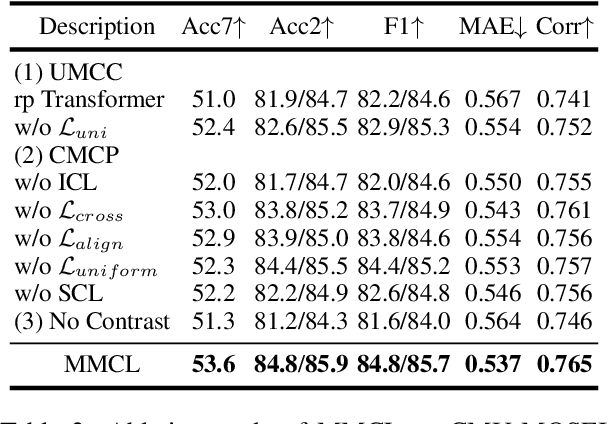
Multimodal representation learning is a challenging task in which previous work mostly focus on either uni-modality pre-training or cross-modality fusion. In fact, we regard modeling multimodal representation as building a skyscraper, where laying stable foundation and designing the main structure are equally essential. The former is like encoding robust uni-modal representation while the later is like integrating interactive information among different modalities, both of which are critical to learning an effective multimodal representation. Recently, contrastive learning has been successfully applied in representation learning, which can be utilized as the pillar of the skyscraper and benefit the model to extract the most important features contained in the multimodal data. In this paper, we propose a novel framework named MultiModal Contrastive Learning (MMCL) for multimodal representation to capture intra- and inter-modality dynamics simultaneously. Specifically, we devise uni-modal contrastive coding with an efficient uni-modal feature augmentation strategy to filter inherent noise contained in acoustic and visual modality and acquire more robust uni-modality representations. Besides, a pseudo siamese network is presented to predict representation across different modalities, which successfully captures cross-modal dynamics. Moreover, we design two contrastive learning tasks, instance- and sentiment-based contrastive learning, to promote the process of prediction and learn more interactive information related to sentiment. Extensive experiments conducted on two public datasets demonstrate that our method surpasses the state-of-the-art methods.
Quantum Differential Privacy: An Information Theory Perspective
Feb 22, 2022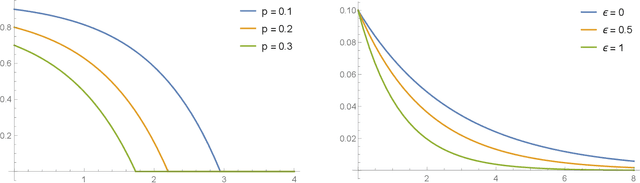
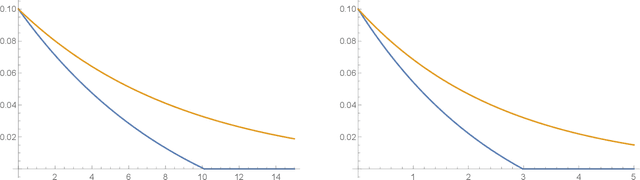
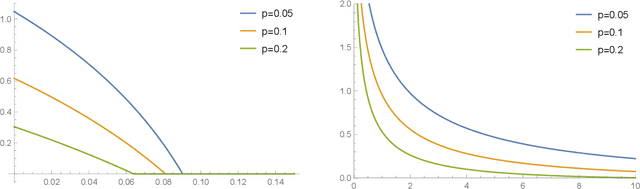
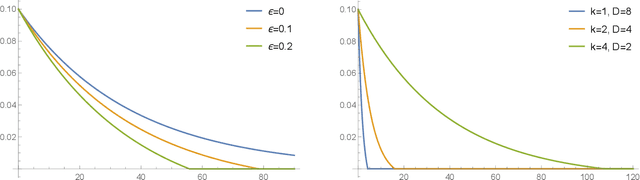
Differential privacy has been an exceptionally successful concept when it comes to providing provable security guarantees for classical computations. More recently, the concept was generalized to quantum computations. While classical computations are essentially noiseless and differential privacy is often achieved by artificially adding noise, near-term quantum computers are inherently noisy and it was observed that this leads to natural differential privacy as a feature. In this work we discuss quantum differential privacy in an information theoretic framework by casting it as a quantum divergence. A main advantage of this approach is that differential privacy becomes a property solely based on the output states of the computation, without the need to check it for every measurement. This leads to simpler proofs and generalized statements of its properties as well as several new bounds for both, general and specific, noise models. In particular, these include common representations of quantum circuits and quantum machine learning concepts. Here, we focus on the difference in the amount of noise required to achieve certain levels of differential privacy versus the amount that would make any computation useless. Finally, we also generalize the classical concepts of local differential privacy, R\'enyi differential privacy and the hypothesis testing interpretation to the quantum setting, providing several new properties and insights.
A heterogeneous group CNN for image super-resolution
Sep 26, 2022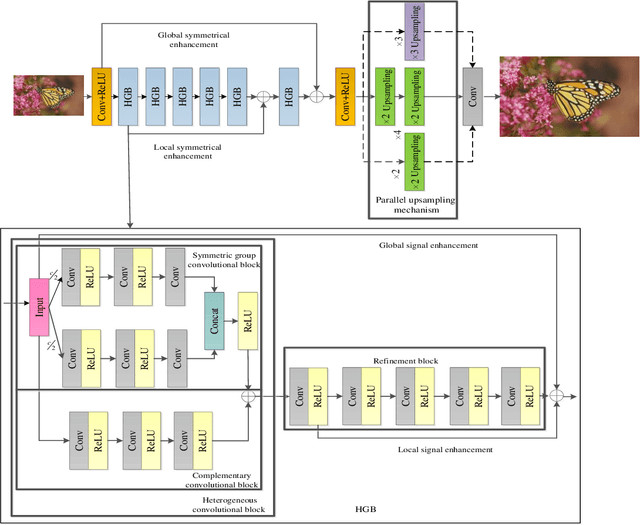
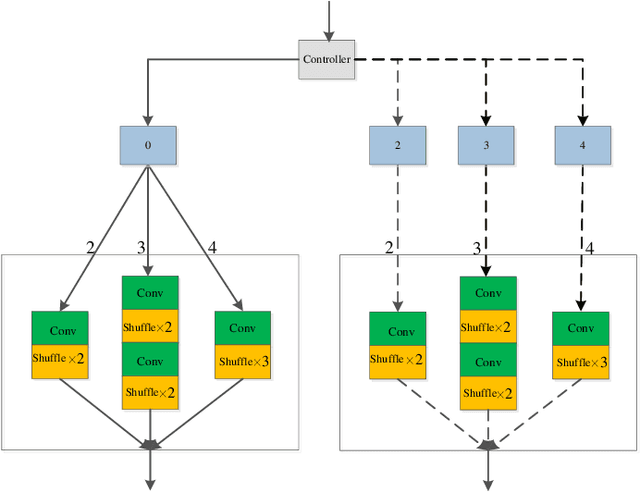


Convolutional neural networks (CNNs) have obtained remarkable performance via deep architectures. However, these CNNs often achieve poor robustness for image super-resolution (SR) under complex scenes. In this paper, we present a heterogeneous group SR CNN (HGSRCNN) via leveraging structure information of different types to obtain a high-quality image. Specifically, each heterogeneous group block (HGB) of HGSRCNN uses a heterogeneous architecture containing a symmetric group convolutional block and a complementary convolutional block in a parallel way to enhance internal and external relations of different channels for facilitating richer low-frequency structure information of different types. To prevent appearance of obtained redundant features, a refinement block with signal enhancements in a serial way is designed to filter useless information. To prevent loss of original information, a multi-level enhancement mechanism guides a CNN to achieve a symmetric architecture for promoting expressive ability of HGSRCNN. Besides, a parallel up-sampling mechanism is developed to train a blind SR model. Extensive experiments illustrate that the proposed HGSRCNN has obtained excellent SR performance in terms of both quantitative and qualitative analysis. Codes can be accessed at https://github.com/hellloxiaotian/HGSRCNN.
Mr. Right: Multimodal Retrieval on Representation of ImaGe witH Text
Sep 28, 2022
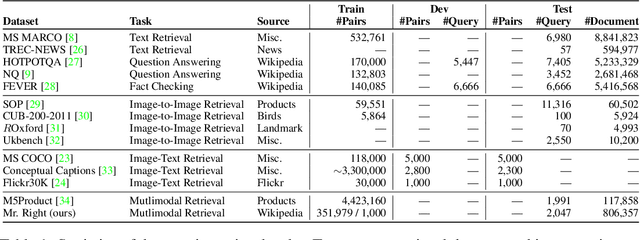
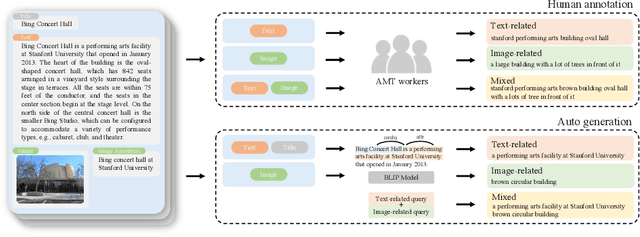
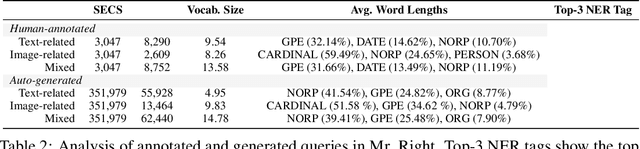
Multimodal learning is a recent challenge that extends unimodal learning by generalizing its domain to diverse modalities, such as texts, images, or speech. This extension requires models to process and relate information from multiple modalities. In Information Retrieval, traditional retrieval tasks focus on the similarity between unimodal documents and queries, while image-text retrieval hypothesizes that most texts contain the scene context from images. This separation has ignored that real-world queries may involve text content, image captions, or both. To address this, we introduce Multimodal Retrieval on Representation of ImaGe witH Text (Mr. Right), a novel and comprehensive dataset for multimodal retrieval. We utilize the Wikipedia dataset with rich text-image examples and generate three types of text-based queries with different modality information: text-related, image-related, and mixed. To validate the effectiveness of our dataset, we provide a multimodal training paradigm and evaluate previous text retrieval and image retrieval frameworks. The results show that proposed multimodal retrieval can improve retrieval performance, but creating a well-unified document representation with texts and images is still a challenge. We hope Mr. Right allows us to broaden current retrieval systems better and contributes to accelerating the advancement of multimodal learning in the Information Retrieval.
High-Resolution Boundary Detection for Medical Image Segmentation with Piece-Wise Two-Sample T-Test Augmented Loss
Nov 04, 2022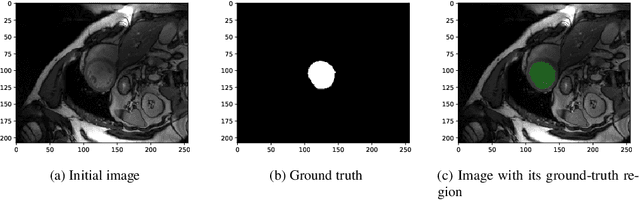
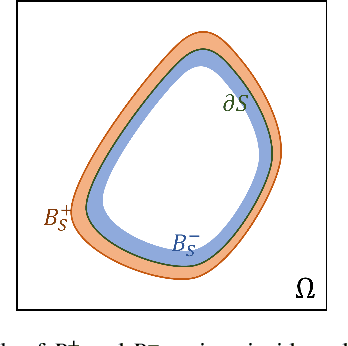
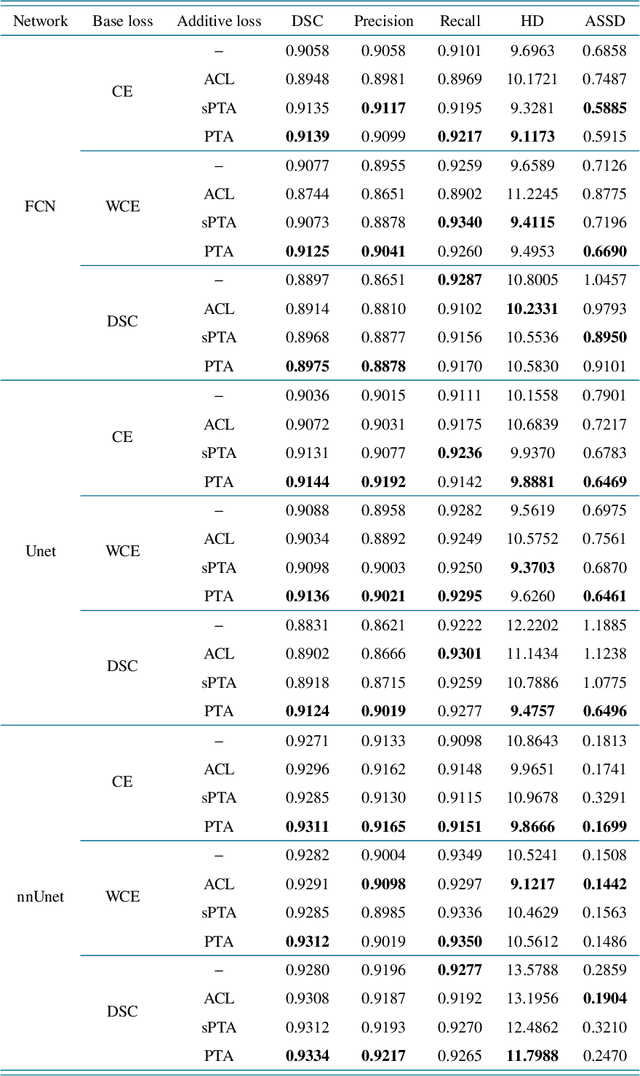
Deep learning methods have contributed substantially to the rapid advancement of medical image segmentation, the quality of which relies on the suitable design of loss functions. Popular loss functions, including the cross-entropy and dice losses, often fall short of boundary detection, thereby limiting high-resolution downstream applications such as automated diagnoses and procedures. We developed a novel loss function that is tailored to reflect the boundary information to enhance the boundary detection. As the contrast between segmentation and background regions along the classification boundary naturally induces heterogeneity over the pixels, we propose the piece-wise two-sample t-test augmented (PTA) loss that is infused with the statistical test for such heterogeneity. We demonstrate the improved boundary detection power of the PTA loss compared to benchmark losses without a t-test component.
Reconciliation of Pre-trained Models and Prototypical Neural Networks in Few-shot Named Entity Recognition
Nov 07, 2022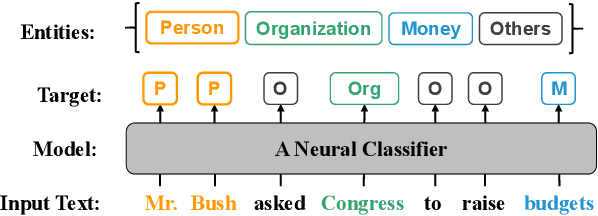
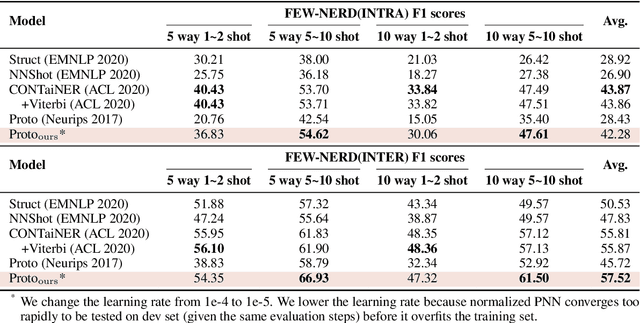
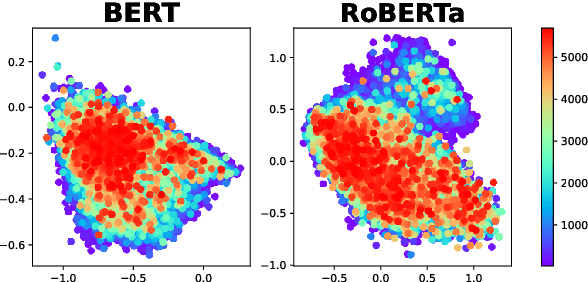
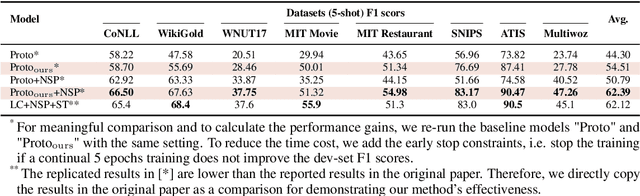
Incorporating large-scale pre-trained models with the prototypical neural networks is a de-facto paradigm in few-shot named entity recognition. Existing methods, unfortunately, are not aware of the fact that embeddings from pre-trained models contain a prominently large amount of information regarding word frequencies, biasing prototypical neural networks against learning word entities. This discrepancy constrains the two models' synergy. Thus, we propose a one-line-code normalization method to reconcile such a mismatch with empirical and theoretical grounds. Our experiments based on nine benchmark datasets show the superiority of our method over the counterpart models and are comparable to the state-of-the-art methods. In addition to the model enhancement, our work also provides an analytical viewpoint for addressing the general problems in few-shot name entity recognition or other tasks that rely on pre-trained models or prototypical neural networks.
AX-MABSA: A Framework for Extremely Weakly Supervised Multi-label Aspect Based Sentiment Analysis
Nov 07, 2022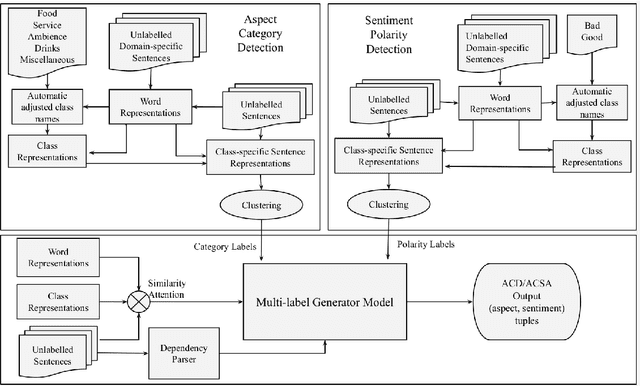
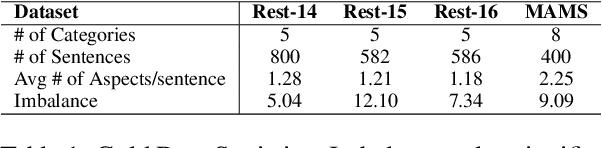

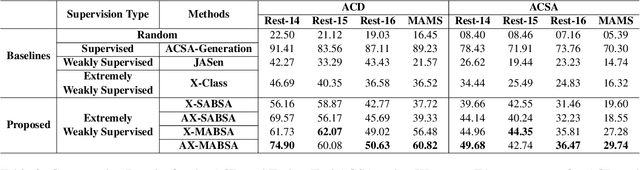
Aspect Based Sentiment Analysis is a dominant research area with potential applications in social media analytics, business, finance, and health. Prior works in this area are primarily based on supervised methods, with a few techniques using weak supervision limited to predicting a single aspect category per review sentence. In this paper, we present an extremely weakly supervised multi-label Aspect Category Sentiment Analysis framework which does not use any labelled data. We only rely on a single word per class as an initial indicative information. We further propose an automatic word selection technique to choose these seed categories and sentiment words. We explore unsupervised language model post-training to improve the overall performance, and propose a multi-label generator model to generate multiple aspect category-sentiment pairs per review sentence. Experiments conducted on four benchmark datasets showcase our method to outperform other weakly supervised baselines by a significant margin.