 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond Ensemble Averages: Leveraging Climate Model Ensembles for Subseasonal Forecasting
Nov 29, 2022
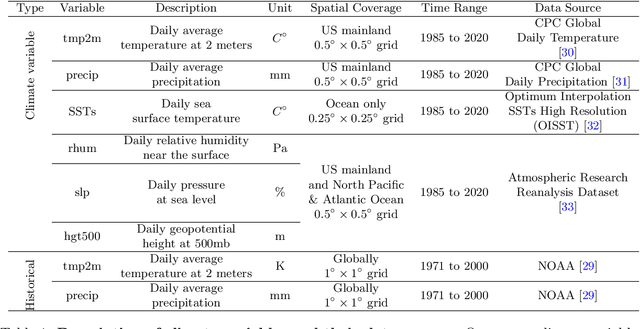
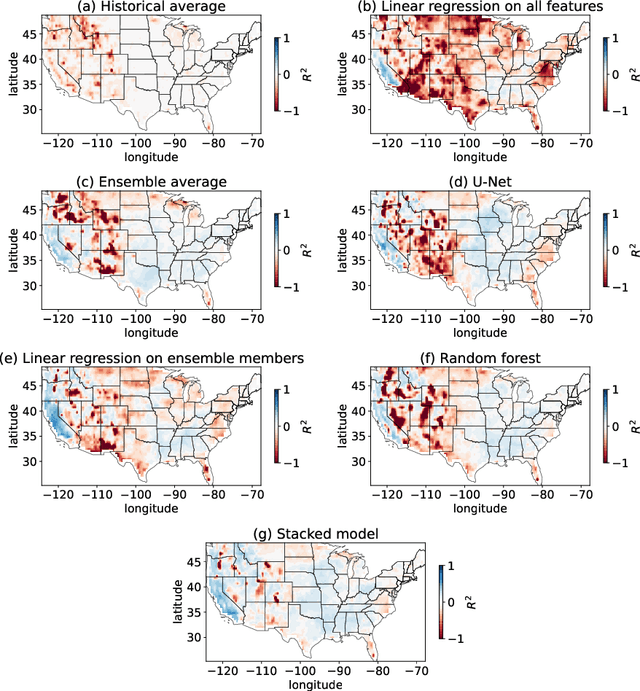
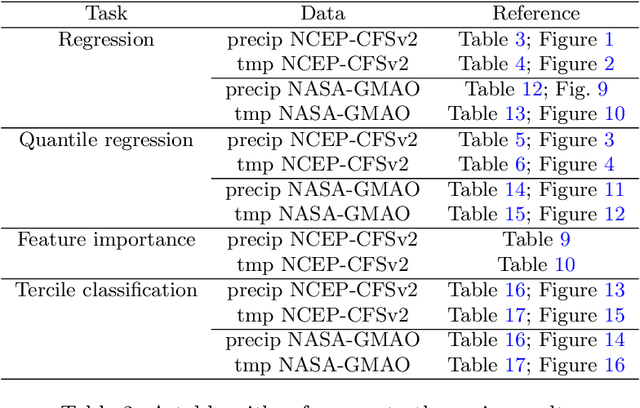

Producing high-quality forecasts of key climate variables such as temperature and precipitation on subseasonal time scales has long been a gap in operational forecasting. Recent studies have shown promising results using machine learning (ML) models to advance subseasonal forecasting (SSF), but several open questions remain. First, several past approaches use the average of an ensemble of physics-based forecasts as an input feature of these models. However, ensemble forecasts contain information that can aid prediction beyond only the ensemble mean. Second, past methods have focused on average performance, whereas forecasts of extreme events are far more important for planning and mitigation purposes. Third, climate forecasts correspond to a spatially-varying collection of forecasts, and different methods account for spatial variability in the response differently. Trade-offs between different approaches may be mitigated with model stacking. This paper describes the application of a variety of ML methods used to predict monthly average precipitation and two meter temperature using physics-based predictions (ensemble forecasts) and observational data such as relative humidity, pressure at sea level, or geopotential height, two weeks in advance for the whole continental United States. Regression, quantile regression, and tercile classification tasks using linear models, random forests, convolutional neural networks, and stacked models are considered. The proposed models outperform common baselines such as historical averages (or quantiles) and ensemble averages (or quantiles). This paper further includes an investigation of feature importance, trade-offs between using the full ensemble or only the ensemble average, and different modes of accounting for spatial variability.
MMSpeech: Multi-modal Multi-task Encoder-Decoder Pre-training for Speech Recognition
Nov 29, 2022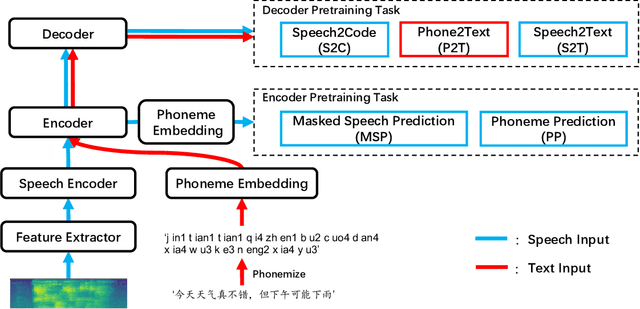
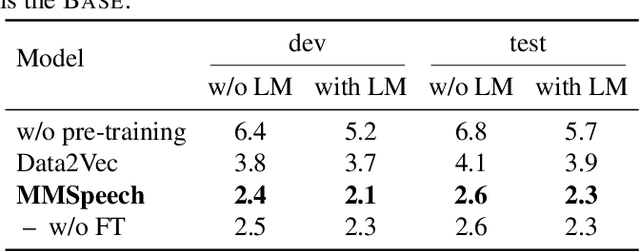
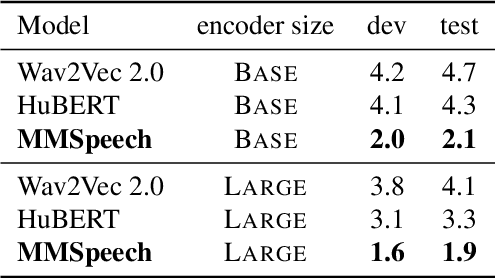

In this paper, we propose a novel multi-modal multi-task encoder-decoder pre-training framework (MMSpeech) for Mandarin automatic speech recognition (ASR), which employs both unlabeled speech and text data. The main difficulty in speech-text joint pre-training comes from the significant difference between speech and text modalities, especially for Mandarin speech and text. Unlike English and other languages with an alphabetic writing system, Mandarin uses an ideographic writing system where character and sound are not tightly mapped to one another. Therefore, we propose to introduce the phoneme modality into pre-training, which can help capture modality-invariant information between Mandarin speech and text. Specifically, we employ a multi-task learning framework including five self-supervised and supervised tasks with speech and text data. For end-to-end pre-training, we introduce self-supervised speech-to-pseudo-codes (S2C) and phoneme-to-text (P2T) tasks utilizing unlabeled speech and text data, where speech-pseudo-codes pairs and phoneme-text pairs are a supplement to the supervised speech-text pairs. To train the encoder to learn better speech representation, we introduce self-supervised masked speech prediction (MSP) and supervised phoneme prediction (PP) tasks to learn to map speech into phonemes. Besides, we directly add the downstream supervised speech-to-text (S2T) task into the pre-training process, which can further improve the pre-training performance and achieve better recognition results even without fine-tuning. Experiments on AISHELL-1 show that our proposed method achieves state-of-the-art performance, with a more than 40% relative improvement compared with other pre-training methods.
Adversarial Graph Contrastive Learning with Information Regularization
Feb 14, 2022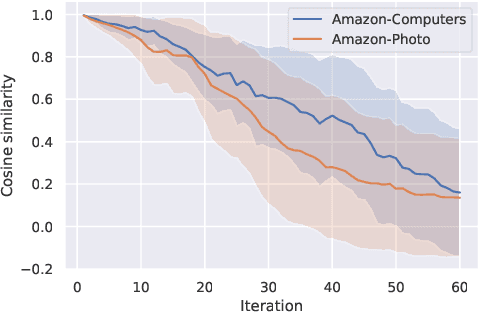
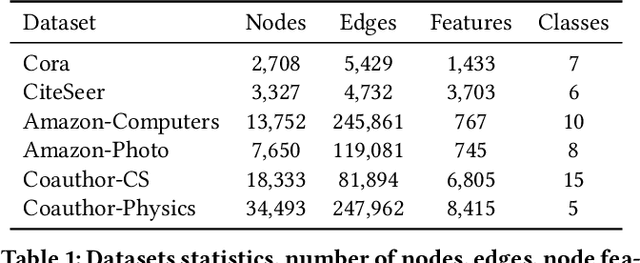
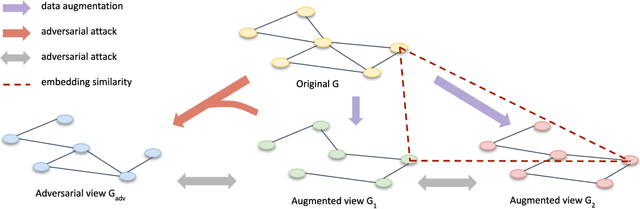
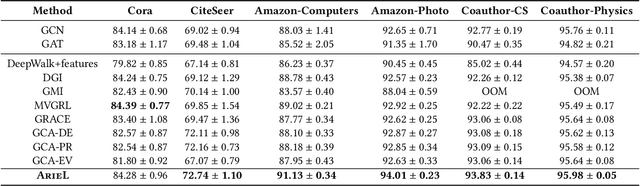
Contrastive learning is an effective unsupervised method in graph representation learning. Recently, the data augmentation based contrastive learning method has been extended from images to graphs. However, most prior works are directly adapted from the models designed for images. Unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which are the key to the performance of contrastive learning models. This leaves much space for improvement over the existing graph contrastive learning frameworks. In this work, by introducing an adversarial graph view and an information regularizer, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within a reasonable constraint. It consistently outperforms the current graph contrastive learning methods in the node classification task over various real-world datasets and further improves the robustness of graph contrastive learning.
ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications
Nov 08, 2022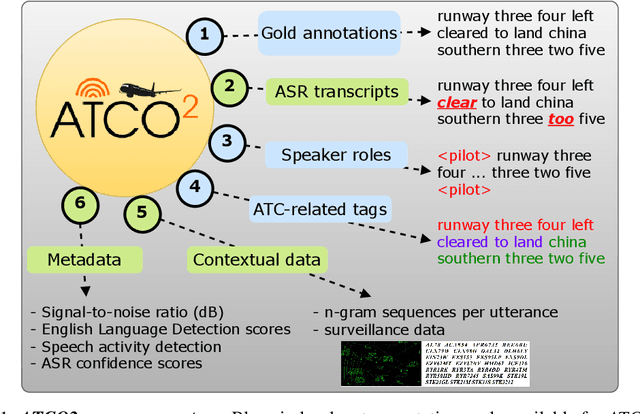
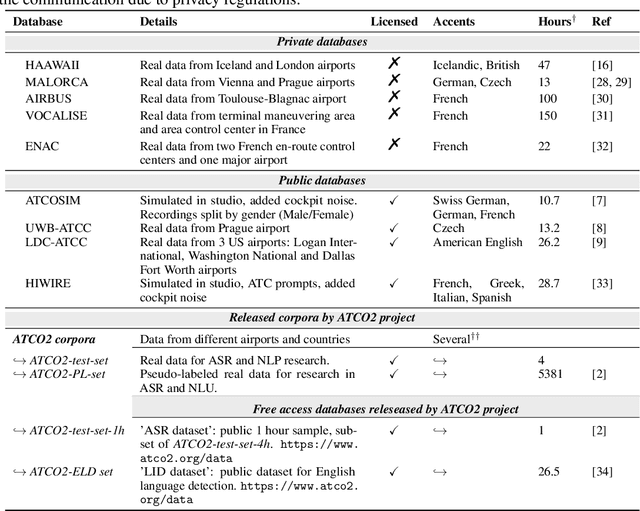
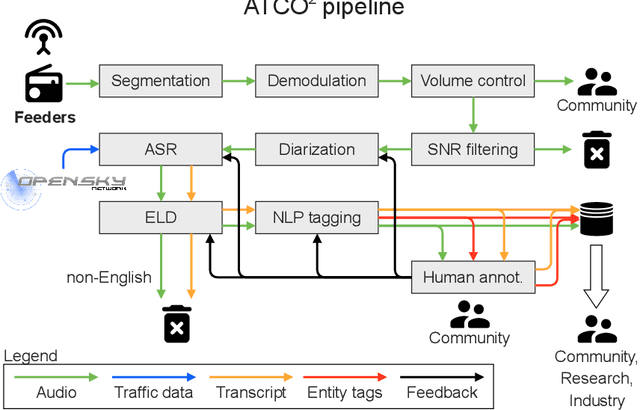

Personal assistants, automatic speech recognizers and dialogue understanding systems are becoming more critical in our interconnected digital world. A clear example is air traffic control (ATC) communications. ATC aims at guiding aircraft and controlling the airspace in a safe and optimal manner. These voice-based dialogues are carried between an air traffic controller (ATCO) and pilots via very-high frequency radio channels. In order to incorporate these novel technologies into ATC (low-resource domain), large-scale annotated datasets are required to develop the data-driven AI systems. Two examples are automatic speech recognition (ASR) and natural language understanding (NLU). In this paper, we introduce the ATCO2 corpus, a dataset that aims at fostering research on the challenging ATC field, which has lagged behind due to lack of annotated data. The ATCO2 corpus covers 1) data collection and pre-processing, 2) pseudo-annotations of speech data, and 3) extraction of ATC-related named entities. The ATCO2 corpus is split into three subsets. 1) ATCO2-test-set corpus contains 4 hours of ATC speech with manual transcripts and a subset with gold annotations for named-entity recognition (callsign, command, value). 2) The ATCO2-PL-set corpus consists of 5281 hours of unlabeled ATC data enriched with automatic transcripts from an in-domain speech recognizer, contextual information, speaker turn information, signal-to-noise ratio estimate and English language detection score per sample. Both available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. 3) The ATCO2-test-set-1h corpus is a one-hour subset from the original test set corpus, that we are offering for free at https://www.atco2.org/data. We expect the ATCO2 corpus will foster research on robust ASR and NLU not only in the field of ATC communications but also in the general research community.
Bayesian model calibration for block copolymer self-assembly: Likelihood-free inference and expected information gain computation via measure transport
Jun 22, 2022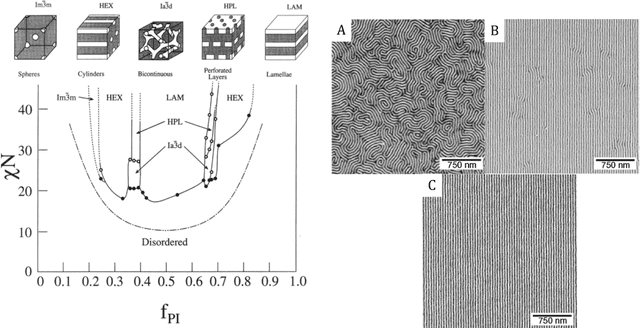
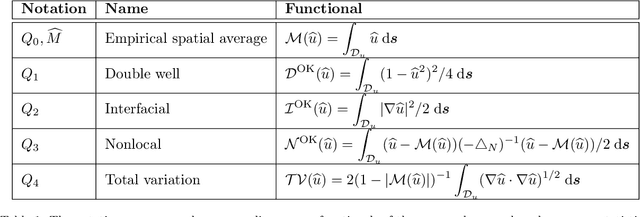
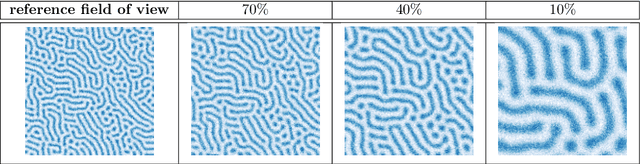
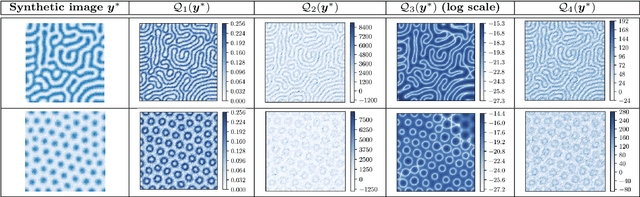
We consider the Bayesian calibration of models describing the phenomenon of block copolymer (BCP) self-assembly using image data produced by microscopy or X-ray scattering techniques. To account for the random long-range disorder in BCP equilibrium structures, we introduce auxiliary variables to represent this aleatory uncertainty. These variables, however, result in an integrated likelihood for high-dimensional image data that is generally intractable to evaluate. We tackle this challenging Bayesian inference problem using a likelihood-free approach based on measure transport together with the construction of summary statistics for the image data. We also show that expected information gains (EIGs) from the observed data about the model parameters can be computed with no significant additional cost. Lastly, we present a numerical case study based on the Ohta--Kawasaki model for diblock copolymer thin film self-assembly and top-down microscopy characterization. For calibration, we introduce several domain-specific energy- and Fourier-based summary statistics, and quantify their informativeness using EIG. We demonstrate the power of the proposed approach to study the effect of data corruptions and experimental designs on the calibration results.
Information-Theoretic Measures of Dataset Difficulty
Oct 16, 2021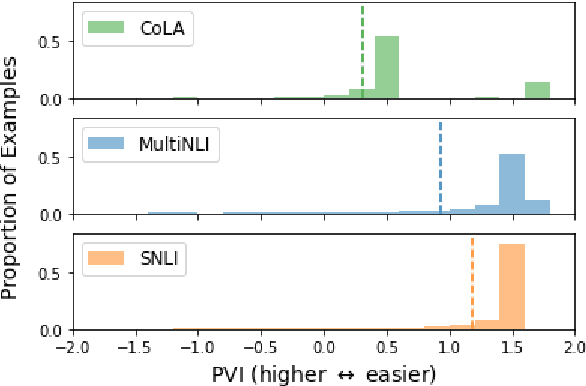
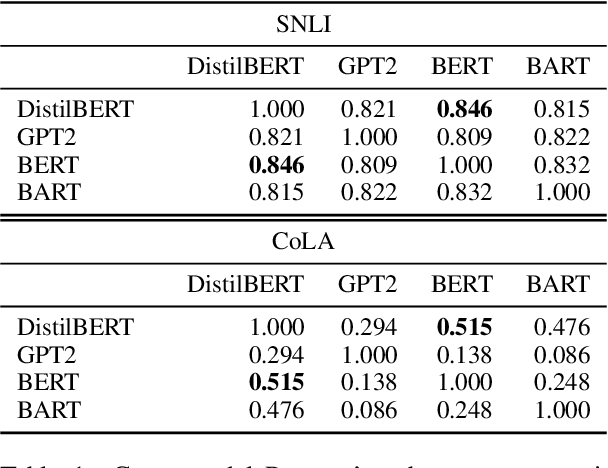
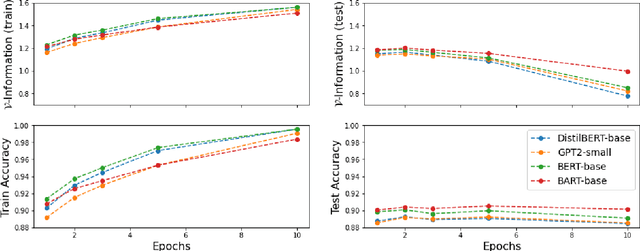
Estimating the difficulty of a dataset typically involves comparing state-of-the-art models to humans; the bigger the performance gap, the harder the dataset is said to be. Not only is this framework informal, but it also provides little understanding of how difficult each instance is, or what attributes make it difficult for a given model. To address these problems, we propose an information-theoretic perspective, framing dataset difficulty as the absence of $\textit{usable information}$. Measuring usable information is as easy as measuring performance, but has certain theoretical advantages. While the latter only allows us to compare different models w.r.t the same dataset, the former also allows us to compare different datasets w.r.t the same model. We then introduce $\textit{pointwise}$ $\mathcal{V}-$$\textit{information}$ (PVI) for measuring the difficulty of individual instances, where instances with higher PVI are easier for model $\mathcal{V}$. By manipulating the input before measuring usable information, we can understand $\textit{why}$ a dataset is easy or difficult for a given model, which we use to discover annotation artefacts in widely-used benchmarks.
Entity-centered Cross-document Relation Extraction
Oct 29, 2022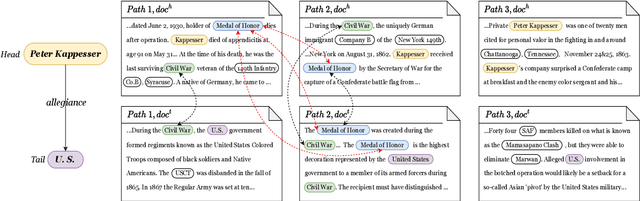
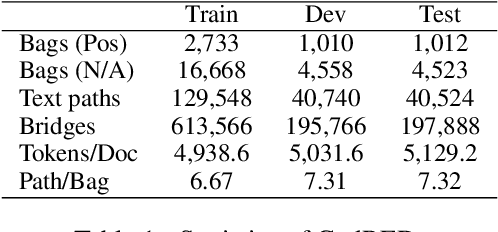
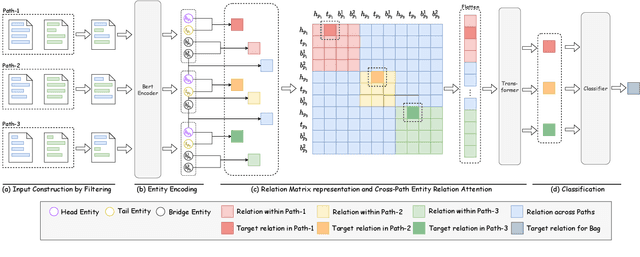

Relation Extraction (RE) is a fundamental task of information extraction, which has attracted a large amount of research attention. Previous studies focus on extracting the relations within a sentence or document, while currently researchers begin to explore cross-document RE. However, current cross-document RE methods directly utilize text snippets surrounding target entities in multiple given documents, which brings considerable noisy and non-relevant sentences. Moreover, they utilize all the text paths in a document bag in a coarse-grained way, without considering the connections between these text paths.In this paper, we aim to address both of these shortages and push the state-of-the-art for cross-document RE. First, we focus on input construction for our RE model and propose an entity-based document-context filter to retain useful information in the given documents by using the bridge entities in the text paths. Second, we propose a cross-document RE model based on cross-path entity relation attention, which allow the entity relations across text paths to interact with each other. We compare our cross-document RE method with the state-of-the-art methods in the dataset CodRED. Our method outperforms them by at least 10% in F1, thus demonstrating its effectiveness.
Medical Image Segmentation Review: The success of U-Net
Nov 27, 2022Automatic medical image segmentation is a crucial topic in the medical domain and successively a critical counterpart in the computer-aided diagnosis paradigm. U-Net is the most widespread image segmentation architecture due to its flexibility, optimized modular design, and success in all medical image modalities. Over the years, the U-Net model achieved tremendous attention from academic and industrial researchers. Several extensions of this network have been proposed to address the scale and complexity created by medical tasks. Addressing the deficiency of the naive U-Net model is the foremost step for vendors to utilize the proper U-Net variant model for their business. Having a compendium of different variants in one place makes it easier for builders to identify the relevant research. Also, for ML researchers it will help them understand the challenges of the biological tasks that challenge the model. To address this, we discuss the practical aspects of the U-Net model and suggest a taxonomy to categorize each network variant. Moreover, to measure the performance of these strategies in a clinical application, we propose fair evaluations of some unique and famous designs on well-known datasets. We provide a comprehensive implementation library with trained models for future research. In addition, for ease of future studies, we created an online list of U-Net papers with their possible official implementation. All information is gathered in https://github.com/NITR098/Awesome-U-Net repository.
PINNet: a deep neural network with pathway prior knowledge for Alzheimer's disease
Nov 27, 2022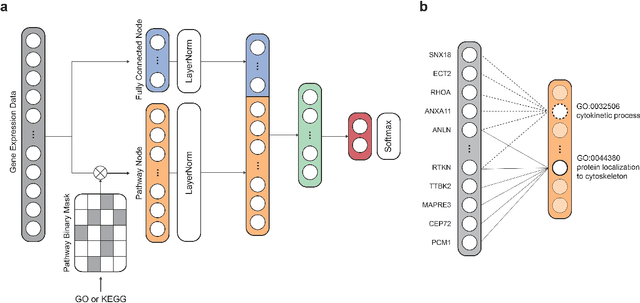

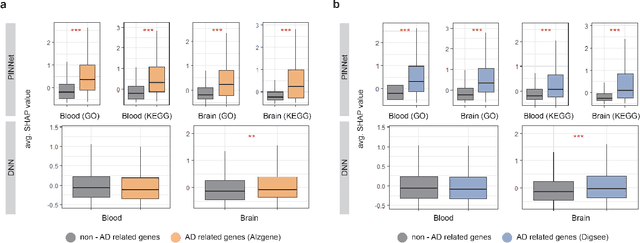

Identification of Alzheimer's Disease (AD)-related transcriptomic signatures from blood is important for early diagnosis of the disease. Deep learning techniques are potent classifiers for AD diagnosis, but most have been unable to identify biomarkers because of their lack of interpretability. To address these challenges, we propose a pathway information-based neural network (PINNet) to predict AD patients and analyze blood and brain transcriptomic signatures using an interpretable deep learning model. PINNet is a deep neural network (DNN) model with pathway prior knowledge from either the Gene Ontology or Kyoto Encyclopedia of Genes and Genomes databases. Then, a backpropagation-based model interpretation method was applied to reveal essential pathways and genes for predicting AD. We compared the performance of PINNet with a DNN model without a pathway. Performances of PINNet outperformed or were similar to those of DNN without a pathway using blood and brain gene expressions, respectively. Moreover, PINNet considers more AD-related genes as essential features than DNN without a pathway in the learning process. Pathway analysis of protein-protein interaction modules of highly contributed genes showed that AD-related genes in blood were enriched with cell migration, PI3K-Akt, MAPK signaling, and apoptosis in blood. The pathways enriched in the brain module included cell migration, PI3K-Akt, MAPK signaling, apoptosis, protein ubiquitination, and t-cell activation. Collectively, with prior knowledge about pathways, PINNet reveals essential pathways related to AD.
MGDoc: Pre-training with Multi-granular Hierarchy for Document Image Understanding
Nov 27, 2022
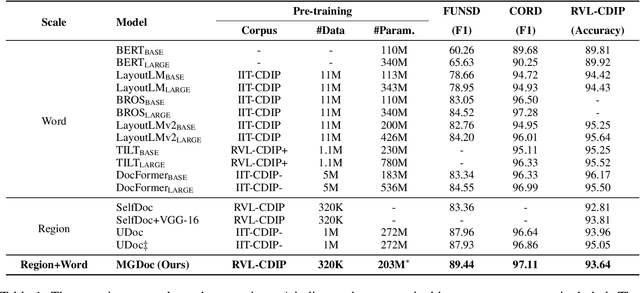
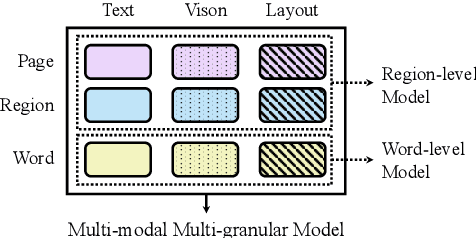
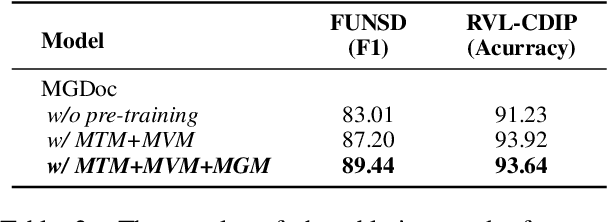
Document images are a ubiquitous source of data where the text is organized in a complex hierarchical structure ranging from fine granularity (e.g., words), medium granularity (e.g., regions such as paragraphs or figures), to coarse granularity (e.g., the whole page). The spatial hierarchical relationships between content at different levels of granularity are crucial for document image understanding tasks. Existing methods learn features from either word-level or region-level but fail to consider both simultaneously. Word-level models are restricted by the fact that they originate from pure-text language models, which only encode the word-level context. In contrast, region-level models attempt to encode regions corresponding to paragraphs or text blocks into a single embedding, but they perform worse with additional word-level features. To deal with these issues, we propose MGDoc, a new multi-modal multi-granular pre-training framework that encodes page-level, region-level, and word-level information at the same time. MGDoc uses a unified text-visual encoder to obtain multi-modal features across different granularities, which makes it possible to project the multi-granular features into the same hyperspace. To model the region-word correlation, we design a cross-granular attention mechanism and specific pre-training tasks for our model to reinforce the model of learning the hierarchy between regions and words. Experiments demonstrate that our proposed model can learn better features that perform well across granularities and lead to improvements in downstream tasks.