 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MIXER: Multiattribute, Multiway Fusion of Uncertain Pairwise Affinities
Oct 15, 2022
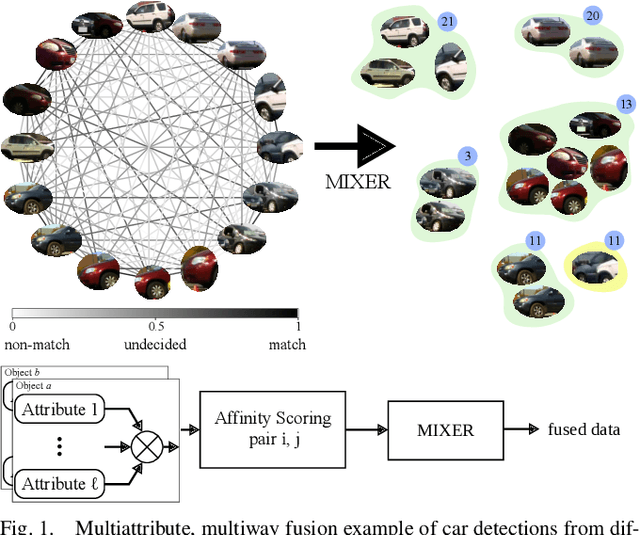
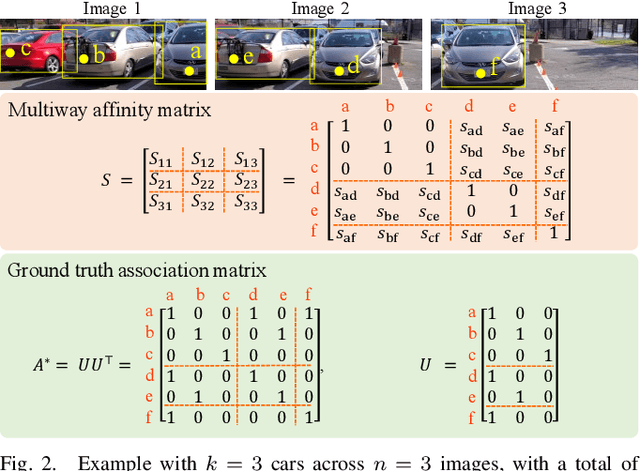
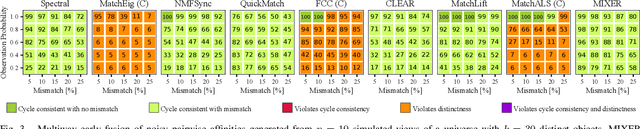
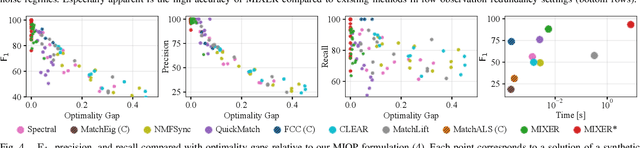
We present a multiway fusion algorithm capable of directly processing uncertain pairwise affinities. In contrast to existing works that require initial pairwise associations, our MIXER algorithm improves accuracy by leveraging the additional information provided by pairwise affinities. Our main contribution is a multiway fusion formulation that is particularly suited to processing non-binary affinities and a novel continuous relaxation whose solutions are guaranteed to be binary, thus avoiding the typical, but potentially problematic, solution binarization steps that may cause infeasibility. A crucial insight of our formulation is that it allows for three modes of association, ranging from non-match, undecided, and match. Exploiting this insight allows fusion to be delayed for some data pairs until more information is available, which is an effective feature for fusion of data with multiple attributes/information sources. We evaluate MIXER on typical synthetic data and benchmark datasets and show increased accuracy against the state of the art in multiway matching, especially in noisy regimes with low observation redundancy. Additionally, we collect RGB data of cars in a parking lot to demonstrate MIXER's ability to fuse data having multiple attributes (color, visual appearance, and bounding box). On this challenging dataset, MIXER achieves 74% F1 accuracy and is 49x faster than the next best algorithm, which has 42% accuracy.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022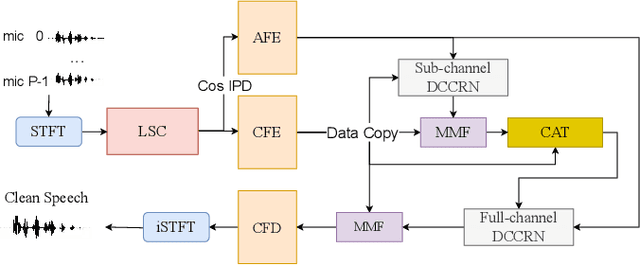
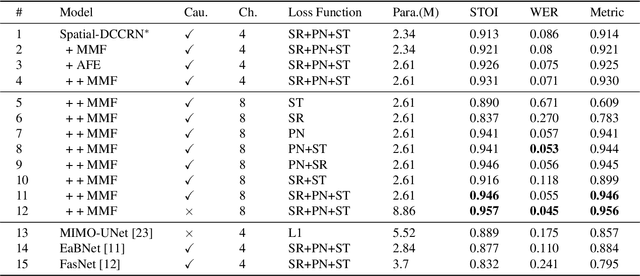
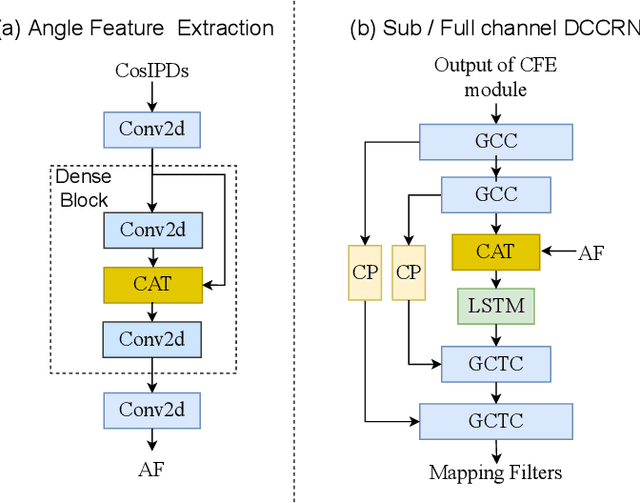
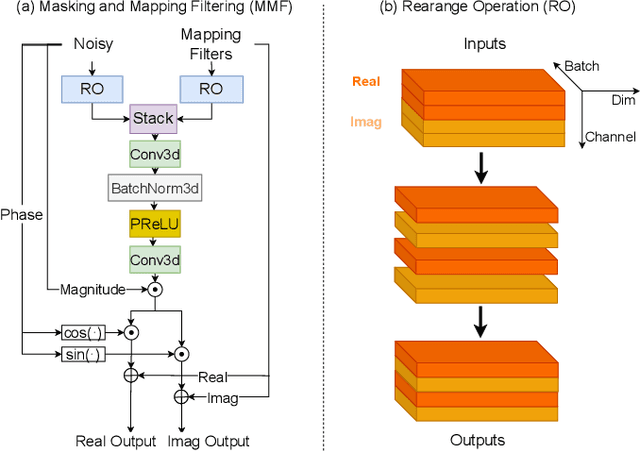
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
Robust Online Video Instance Segmentation with Track Queries
Nov 16, 2022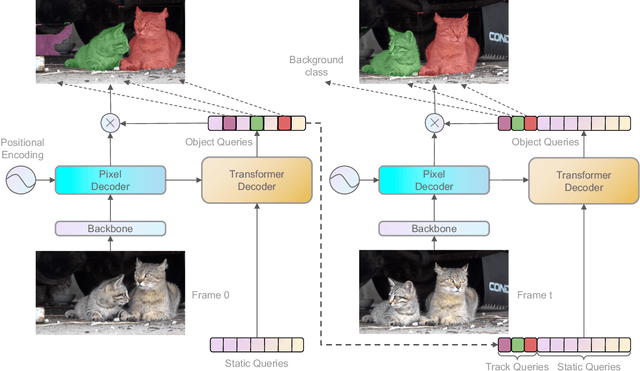
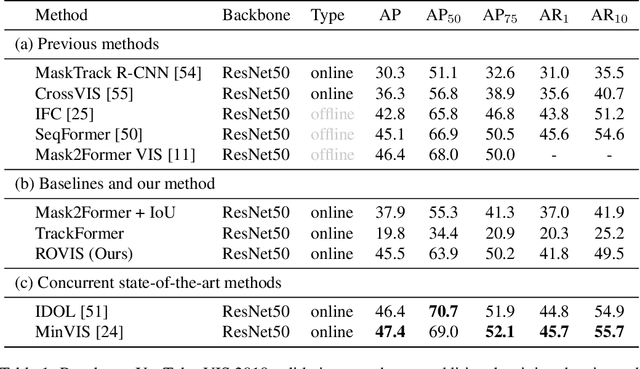

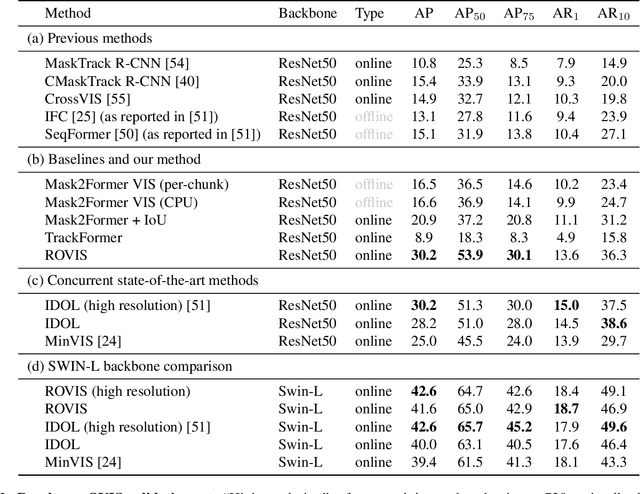
Recently, transformer-based methods have achieved impressive results on Video Instance Segmentation (VIS). However, most of these top-performing methods run in an offline manner by processing the entire video clip at once to predict instance mask volumes. This makes them incapable of handling the long videos that appear in challenging new video instance segmentation datasets like UVO and OVIS. We propose a fully online transformer-based video instance segmentation model that performs comparably to top offline methods on the YouTube-VIS 2019 benchmark and considerably outperforms them on UVO and OVIS. This method, called Robust Online Video Segmentation (ROVIS), augments the Mask2Former image instance segmentation model with track queries, a lightweight mechanism for carrying track information from frame to frame, originally introduced by the TrackFormer method for multi-object tracking. We show that, when combined with a strong enough image segmentation architecture, track queries can exhibit impressive accuracy while not being constrained to short videos.
Multilingual Speech Emotion Recognition With Multi-Gating Mechanism and Neural Architecture Search
Nov 16, 2022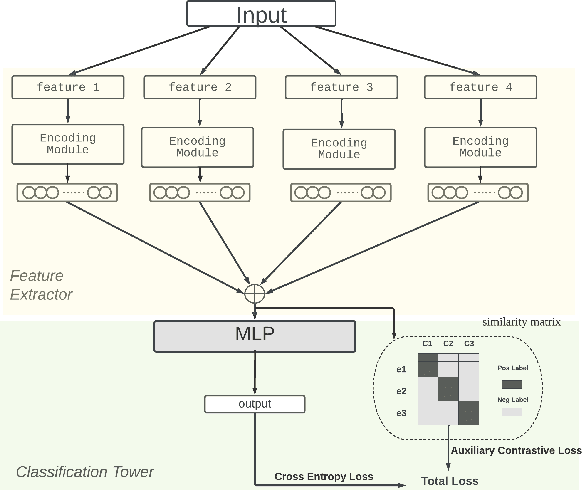

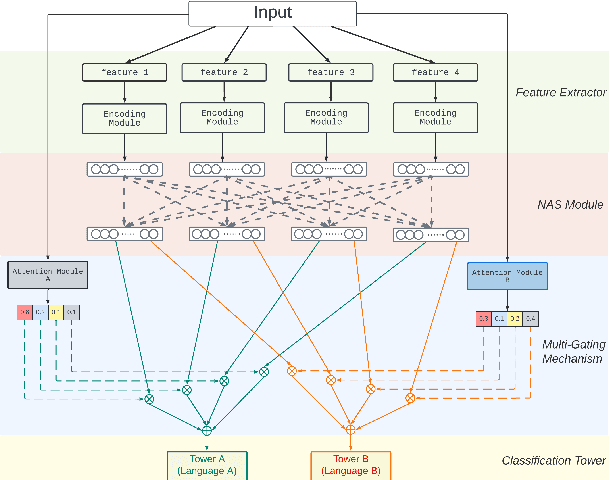

Speech emotion recognition (SER) classifies audio into emotion categories such as Happy, Angry, Fear, Disgust and Neutral. While Speech Emotion Recognition (SER) is a common application for popular languages, it continues to be a problem for low-resourced languages, i.e., languages with no pretrained speech-to-text recognition models. This paper firstly proposes a language-specific model that extract emotional information from multiple pre-trained speech models, and then designs a multi-domain model that simultaneously performs SER for various languages. Our multidomain model employs a multi-gating mechanism to generate unique weighted feature combination for each language, and also searches for specific neural network structure for each language through a neural architecture search module. In addition, we introduce a contrastive auxiliary loss to build more separable representations for audio data. Our experiments show that our model raises the state-of-the-art accuracy by 3% for German and 14.3% for French.
ToolFlowNet: Robotic Manipulation with Tools via Predicting Tool Flow from Point Clouds
Nov 16, 2022
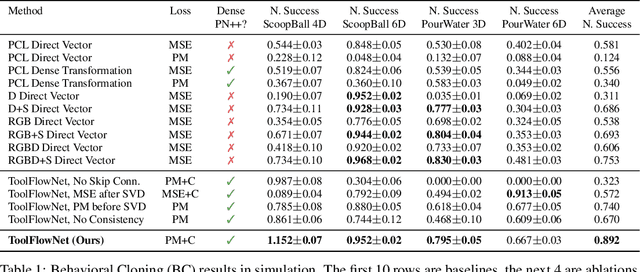
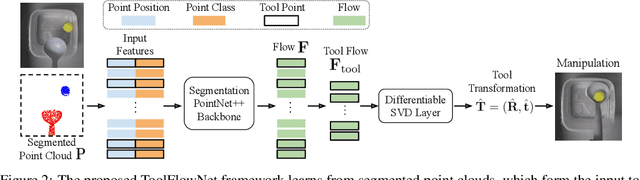
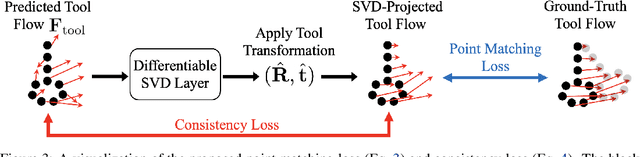
Point clouds are a widely available and canonical data modality which convey the 3D geometry of a scene. Despite significant progress in classification and segmentation from point clouds, policy learning from such a modality remains challenging, and most prior works in imitation learning focus on learning policies from images or state information. In this paper, we propose a novel framework for learning policies from point clouds for robotic manipulation with tools. We use a novel neural network, ToolFlowNet, which predicts dense per-point flow on the tool that the robot controls, and then uses the flow to derive the transformation that the robot should execute. We apply this framework to imitation learning of challenging deformable object manipulation tasks with continuous movement of tools, including scooping and pouring, and demonstrate significantly improved performance over baselines which do not use flow. We perform 50 physical scooping experiments with ToolFlowNet and attain 82% scooping success. See https://tinyurl.com/toolflownet for supplementary material.
Detecting Unknown DGAs without Context Information
May 30, 2022
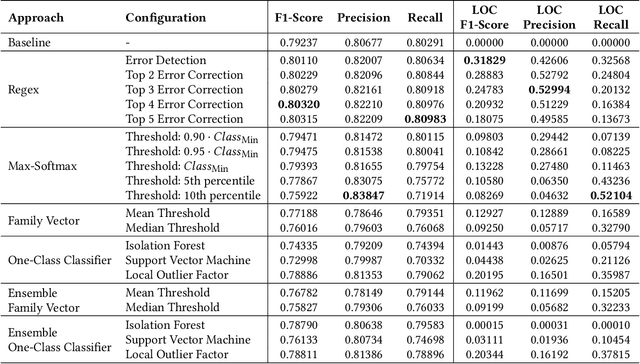
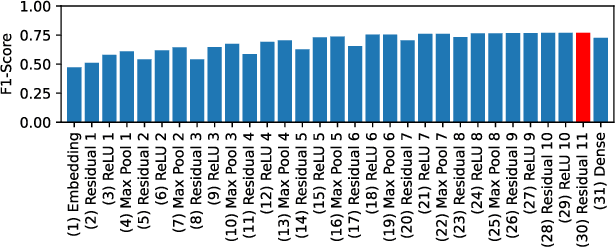
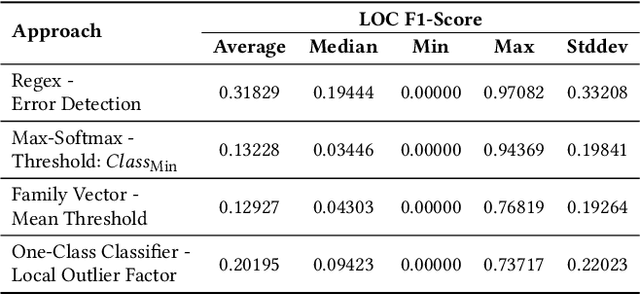
New malware emerges at a rapid pace and often incorporates Domain Generation Algorithms (DGAs) to avoid blocking the malware's connection to the command and control (C2) server. Current state-of-the-art classifiers are able to separate benign from malicious domains (binary classification) and attribute them with high probability to the DGAs that generated them (multiclass classification). While binary classifiers can label domains of yet unknown DGAs as malicious, multiclass classifiers can only assign domains to DGAs that are known at the time of training, limiting the ability to uncover new malware families. In this work, we perform a comprehensive study on the detection of new DGAs, which includes an evaluation of 59,690 classifiers. We examine four different approaches in 15 different configurations and propose a simple yet effective approach based on the combination of a softmax classifier and regular expressions (regexes) to detect multiple unknown DGAs with high probability. At the same time, our approach retains state-of-the-art classification performance for known DGAs. Our evaluation is based on a leave-one-group-out cross-validation with a total of 94 DGA families. By using the maximum number of known DGAs, our evaluation scenario is particularly difficult and close to the real world. All of the approaches examined are privacy-preserving, since they operate without context and exclusively on a single domain to be classified. We round up our study with a thorough discussion of class-incremental learning strategies that can adapt an existing classifier to newly discovered classes.
Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis
Oct 19, 2022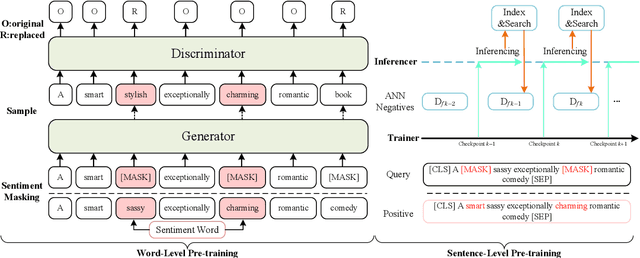
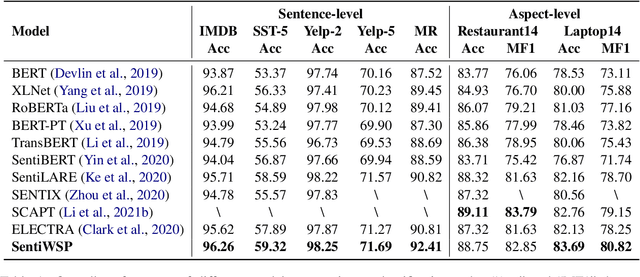
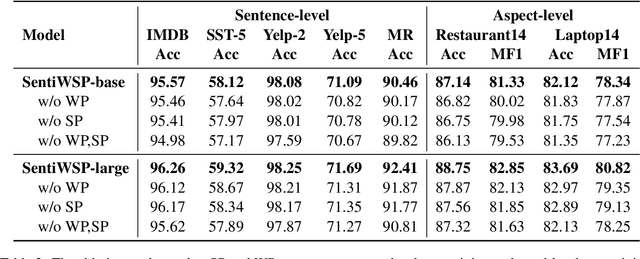
Most existing pre-trained language representation models (PLMs) are sub-optimal in sentiment analysis tasks, as they capture the sentiment information from word-level while under-considering sentence-level information. In this paper, we propose SentiWSP, a novel Sentiment-aware pre-trained language model with combined Word-level and Sentence-level Pre-training tasks. The word level pre-training task detects replaced sentiment words, via a generator-discriminator framework, to enhance the PLM's knowledge about sentiment words. The sentence level pre-training task further strengthens the discriminator via a contrastive learning framework, with similar sentences as negative samples, to encode sentiments in a sentence. Extensive experimental results show that SentiWSP achieves new state-of-the-art performance on various sentence-level and aspect-level sentiment classification benchmarks. We have made our code and model publicly available at https://github.com/XMUDM/SentiWSP.
Which Shortcut Solution Do Question Answering Models Prefer to Learn?
Nov 29, 2022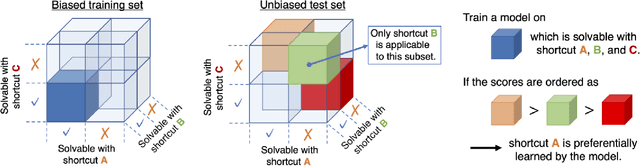
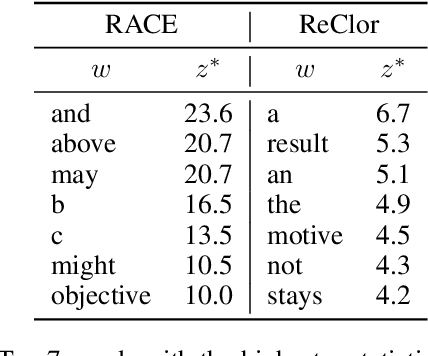
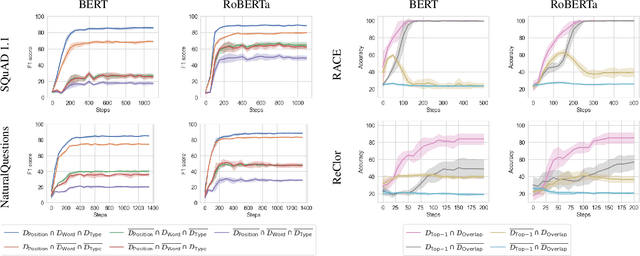
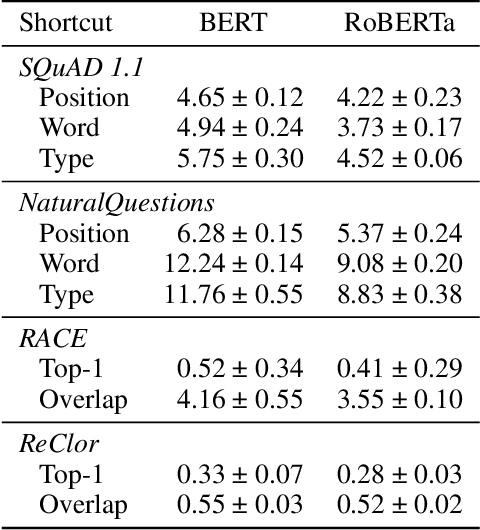
Question answering (QA) models for reading comprehension tend to learn shortcut solutions rather than the solutions intended by QA datasets. QA models that have learned shortcut solutions can achieve human-level performance in shortcut examples where shortcuts are valid, but these same behaviors degrade generalization potential on anti-shortcut examples where shortcuts are invalid. Various methods have been proposed to mitigate this problem, but they do not fully take the characteristics of shortcuts themselves into account. We assume that the learnability of shortcuts, i.e., how easy it is to learn a shortcut, is useful to mitigate the problem. Thus, we first examine the learnability of the representative shortcuts on extractive and multiple-choice QA datasets. Behavioral tests using biased training sets reveal that shortcuts that exploit answer positions and word-label correlations are preferentially learned for extractive and multiple-choice QA, respectively. We find that the more learnable a shortcut is, the flatter and deeper the loss landscape is around the shortcut solution in the parameter space. We also find that the availability of the preferred shortcuts tends to make the task easier to perform from an information-theoretic viewpoint. Lastly, we experimentally show that the learnability of shortcuts can be utilized to construct an effective QA training set; the more learnable a shortcut is, the smaller the proportion of anti-shortcut examples required to achieve comparable performance on shortcut and anti-shortcut examples. We claim that the learnability of shortcuts should be considered when designing mitigation methods.
Beyond Ensemble Averages: Leveraging Climate Model Ensembles for Subseasonal Forecasting
Nov 29, 2022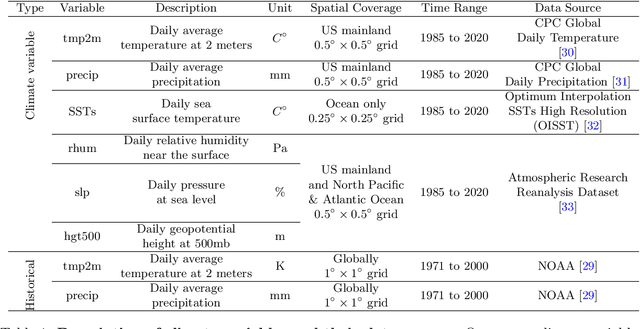
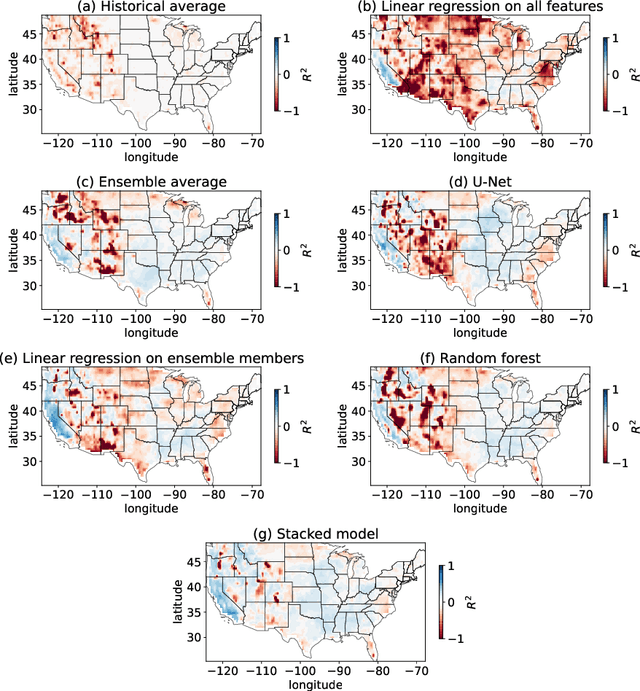

Producing high-quality forecasts of key climate variables such as temperature and precipitation on subseasonal time scales has long been a gap in operational forecasting. Recent studies have shown promising results using machine learning (ML) models to advance subseasonal forecasting (SSF), but several open questions remain. First, several past approaches use the average of an ensemble of physics-based forecasts as an input feature of these models. However, ensemble forecasts contain information that can aid prediction beyond only the ensemble mean. Second, past methods have focused on average performance, whereas forecasts of extreme events are far more important for planning and mitigation purposes. Third, climate forecasts correspond to a spatially-varying collection of forecasts, and different methods account for spatial variability in the response differently. Trade-offs between different approaches may be mitigated with model stacking. This paper describes the application of a variety of ML methods used to predict monthly average precipitation and two meter temperature using physics-based predictions (ensemble forecasts) and observational data such as relative humidity, pressure at sea level, or geopotential height, two weeks in advance for the whole continental United States. Regression, quantile regression, and tercile classification tasks using linear models, random forests, convolutional neural networks, and stacked models are considered. The proposed models outperform common baselines such as historical averages (or quantiles) and ensemble averages (or quantiles). This paper further includes an investigation of feature importance, trade-offs between using the full ensemble or only the ensemble average, and different modes of accounting for spatial variability.
MMSpeech: Multi-modal Multi-task Encoder-Decoder Pre-training for Speech Recognition
Nov 29, 2022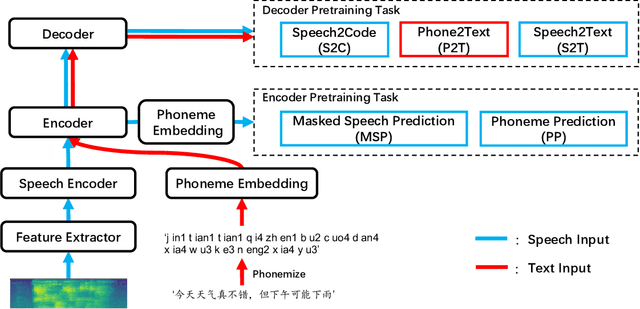
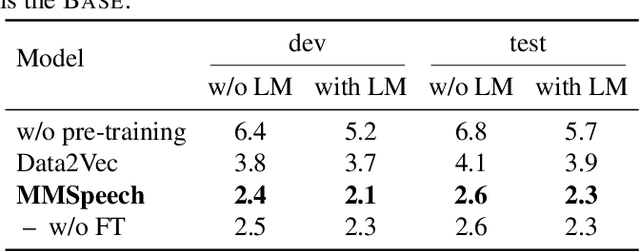
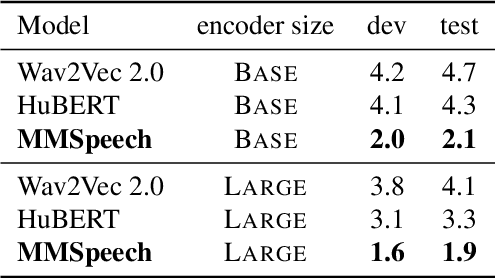

In this paper, we propose a novel multi-modal multi-task encoder-decoder pre-training framework (MMSpeech) for Mandarin automatic speech recognition (ASR), which employs both unlabeled speech and text data. The main difficulty in speech-text joint pre-training comes from the significant difference between speech and text modalities, especially for Mandarin speech and text. Unlike English and other languages with an alphabetic writing system, Mandarin uses an ideographic writing system where character and sound are not tightly mapped to one another. Therefore, we propose to introduce the phoneme modality into pre-training, which can help capture modality-invariant information between Mandarin speech and text. Specifically, we employ a multi-task learning framework including five self-supervised and supervised tasks with speech and text data. For end-to-end pre-training, we introduce self-supervised speech-to-pseudo-codes (S2C) and phoneme-to-text (P2T) tasks utilizing unlabeled speech and text data, where speech-pseudo-codes pairs and phoneme-text pairs are a supplement to the supervised speech-text pairs. To train the encoder to learn better speech representation, we introduce self-supervised masked speech prediction (MSP) and supervised phoneme prediction (PP) tasks to learn to map speech into phonemes. Besides, we directly add the downstream supervised speech-to-text (S2T) task into the pre-training process, which can further improve the pre-training performance and achieve better recognition results even without fine-tuning. Experiments on AISHELL-1 show that our proposed method achieves state-of-the-art performance, with a more than 40% relative improvement compared with other pre-training methods.