 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Unknown DGAs without Context Information
May 30, 2022

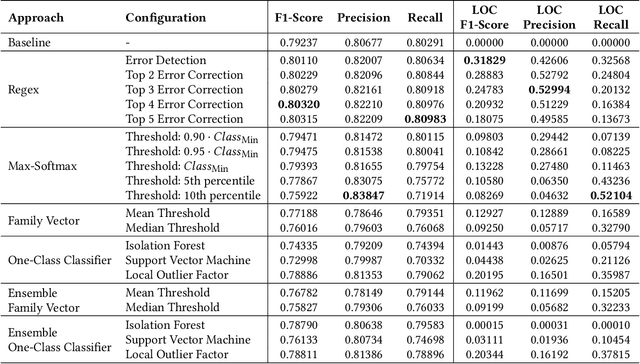
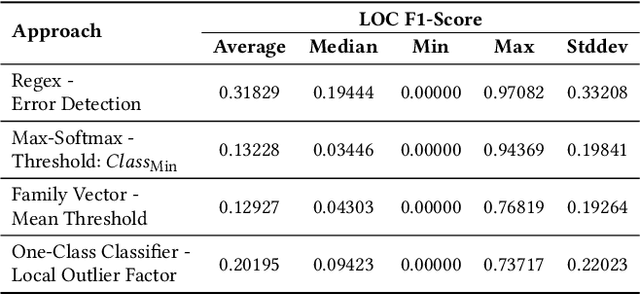
New malware emerges at a rapid pace and often incorporates Domain Generation Algorithms (DGAs) to avoid blocking the malware's connection to the command and control (C2) server. Current state-of-the-art classifiers are able to separate benign from malicious domains (binary classification) and attribute them with high probability to the DGAs that generated them (multiclass classification). While binary classifiers can label domains of yet unknown DGAs as malicious, multiclass classifiers can only assign domains to DGAs that are known at the time of training, limiting the ability to uncover new malware families. In this work, we perform a comprehensive study on the detection of new DGAs, which includes an evaluation of 59,690 classifiers. We examine four different approaches in 15 different configurations and propose a simple yet effective approach based on the combination of a softmax classifier and regular expressions (regexes) to detect multiple unknown DGAs with high probability. At the same time, our approach retains state-of-the-art classification performance for known DGAs. Our evaluation is based on a leave-one-group-out cross-validation with a total of 94 DGA families. By using the maximum number of known DGAs, our evaluation scenario is particularly difficult and close to the real world. All of the approaches examined are privacy-preserving, since they operate without context and exclusively on a single domain to be classified. We round up our study with a thorough discussion of class-incremental learning strategies that can adapt an existing classifier to newly discovered classes.
Language models and brain alignment: beyond word-level semantics and prediction
Dec 01, 2022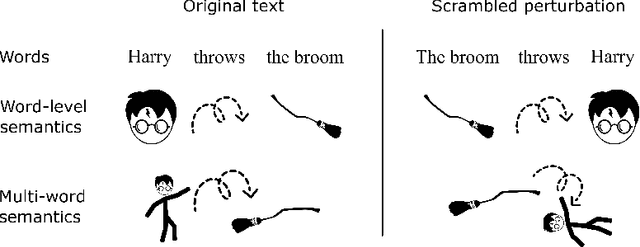
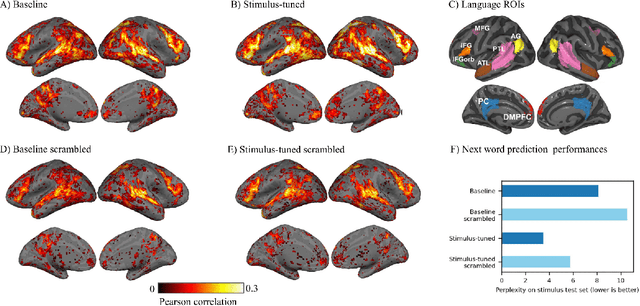
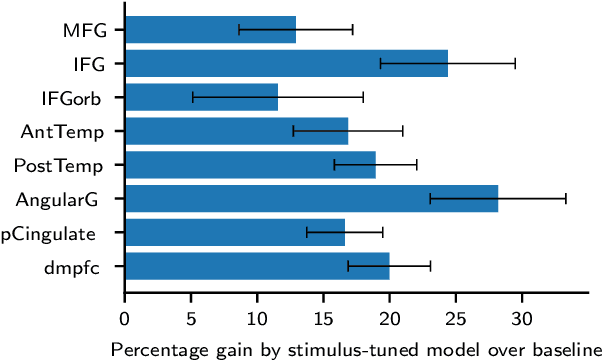
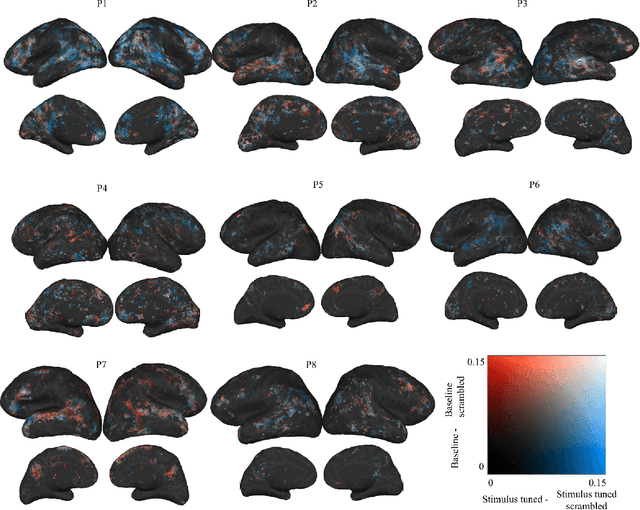
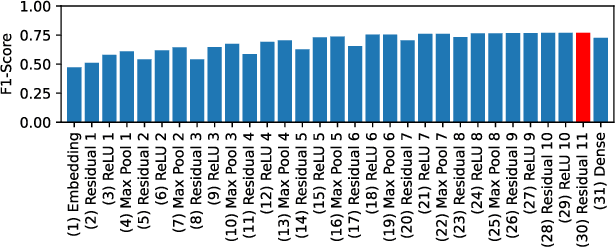
Pretrained language models that have been trained to predict the next word over billions of text documents have been shown to also significantly predict brain recordings of people comprehending language. Understanding the reasons behind the observed similarities between language in machines and language in the brain can lead to more insight into both systems. Recent works suggest that the prediction of the next word is a key mechanism that contributes to the alignment between the two. What is not yet understood is whether prediction of the next word is necessary for this observed alignment or simply sufficient, and whether there are other shared mechanisms or information that is similarly important. In this work, we take a first step towards a better understanding via two simple perturbations in a popular pretrained language model. The first perturbation is to improve the model's ability to predict the next word in the specific naturalistic stimulus text that the brain recordings correspond to. We show that this indeed improves the alignment with the brain recordings. However, this improved alignment may also be due to any improved word-level or multi-word level semantics for the specific world that is described by the stimulus narrative. We aim to disentangle the contribution of next word prediction and semantic knowledge via our second perturbation: scrambling the word order at inference time, which reduces the ability to predict the next word, but maintains any newly learned word-level semantics. By comparing the alignment with brain recordings of these differently perturbed models, we show that improvements in alignment with brain recordings are due to more than improvements in next word prediction and word-level semantics.
Weakly-supervised detection of AMD-related lesions in color fundus images using explainable deep learning
Dec 01, 2022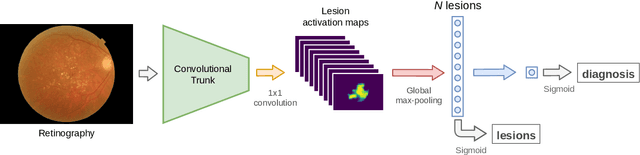
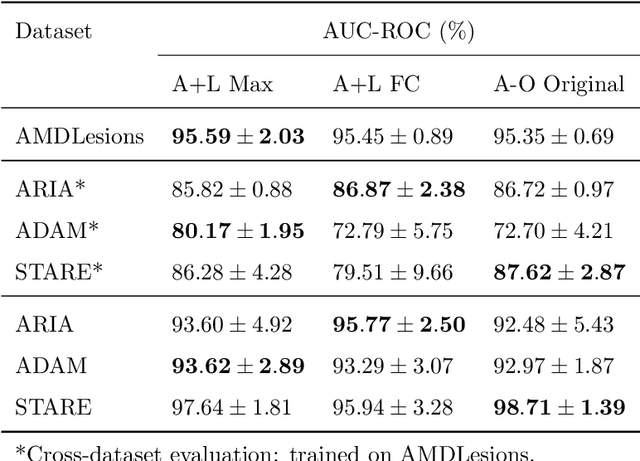
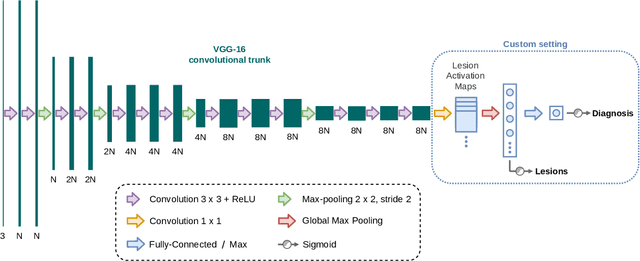
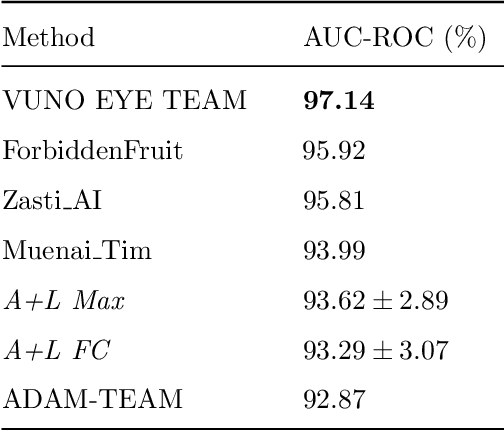
Age-related macular degeneration (AMD) is a degenerative disorder affecting the macula, a key area of the retina for visual acuity. Nowadays, it is the most frequent cause of blindness in developed countries. Although some promising treatments have been developed, their effectiveness is low in advanced stages. This emphasizes the importance of large-scale screening programs. Nevertheless, implementing such programs for AMD is usually unfeasible, since the population at risk is large and the diagnosis is challenging. All this motivates the development of automatic methods. In this sense, several works have achieved positive results for AMD diagnosis using convolutional neural networks (CNNs). However, none incorporates explainability mechanisms, which limits their use in clinical practice. In that regard, we propose an explainable deep learning approach for the diagnosis of AMD via the joint identification of its associated retinal lesions. In our proposal, a CNN is trained end-to-end for the joint task using image-level labels. The provided lesion information is of clinical interest, as it allows to assess the developmental stage of AMD. Additionally, the approach allows to explain the diagnosis from the identified lesions. This is possible thanks to the use of a CNN with a custom setting that links the lesions and the diagnosis. Furthermore, the proposed setting also allows to obtain coarse lesion segmentation maps in a weakly-supervised way, further improving the explainability. The training data for the approach can be obtained without much extra work by clinicians. The experiments conducted demonstrate that our approach can identify AMD and its associated lesions satisfactorily, while providing adequate coarse segmentation maps for most common lesions.
Human-instructed Deep Hierarchical Generative Learning for Automated Urban Planning
Dec 01, 2022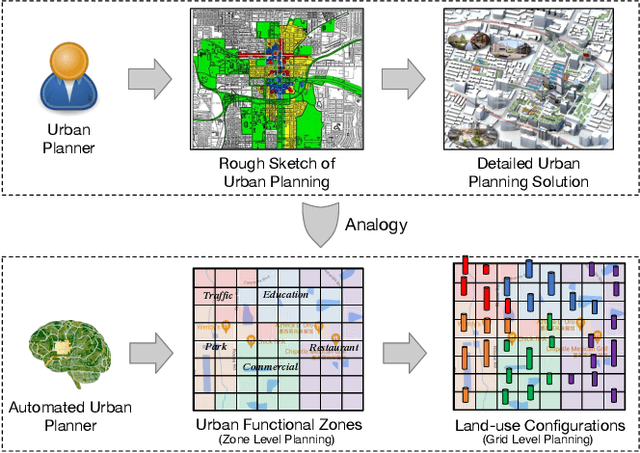
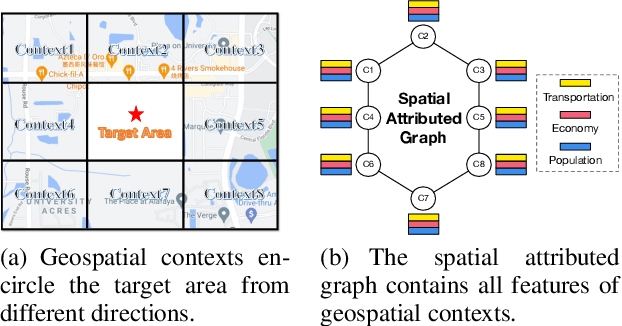
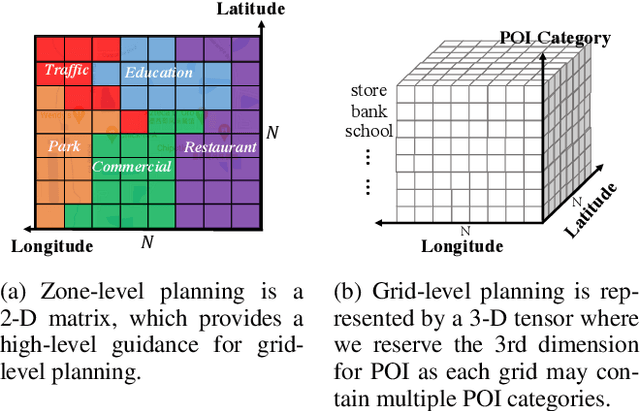
The essential task of urban planning is to generate the optimal land-use configuration of a target area. However, traditional urban planning is time-consuming and labor-intensive. Deep generative learning gives us hope that we can automate this planning process and come up with the ideal urban plans. While remarkable achievements have been obtained, they have exhibited limitations in lacking awareness of: 1) the hierarchical dependencies between functional zones and spatial grids; 2) the peer dependencies among functional zones; and 3) human regulations to ensure the usability of generated configurations. To address these limitations, we develop a novel human-instructed deep hierarchical generative model. We rethink the urban planning generative task from a unique functionality perspective, where we summarize planning requirements into different functionality projections for better urban plan generation. To this end, we develop a three-stage generation process from a target area to zones to grids. The first stage is to label the grids of a target area with latent functionalities to discover functional zones. The second stage is to perceive the planning requirements to form urban functionality projections. We propose a novel module: functionalizer to project the embedding of human instructions and geospatial contexts to the zone-level plan to obtain such projections. Each projection includes the information of land-use portfolios and the structural dependencies across spatial grids in terms of a specific urban function. The third stage is to leverage multi-attentions to model the zone-zone peer dependencies of the functionality projections to generate grid-level land-use configurations. Finally, we present extensive experiments to demonstrate the effectiveness of our framework.
Leveraging Single-View Images for Unsupervised 3D Point Cloud Completion
Dec 01, 2022
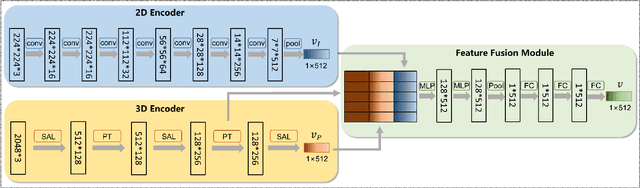
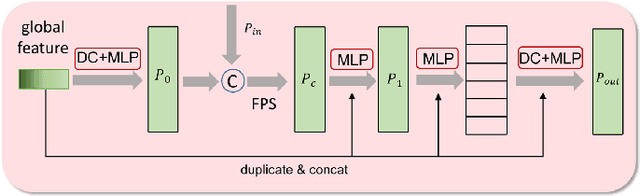
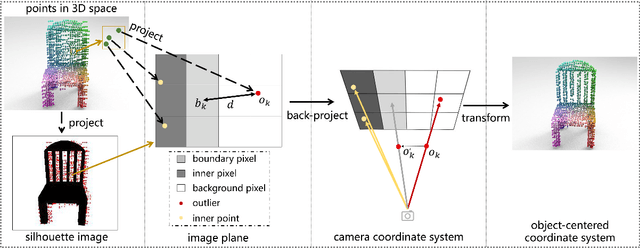
Point clouds captured by scanning devices are often incomplete due to occlusion. Point cloud completion aims to predict the complete shape based on its partial input. Existing methods can be classified into supervised and unsupervised methods. However, both of them require a large number of 3D complete point clouds, which are difficult to capture. In this paper, we propose Cross-PCC, an unsupervised point cloud completion method without requiring any 3D complete point clouds. We only utilize 2D images of the complete objects, which are easier to capture than 3D complete and clean point clouds. Specifically, to take advantage of the complementary information from 2D images, we use a single-view RGB image to extract 2D features and design a fusion module to fuse the 2D and 3D features extracted from the partial point cloud. To guide the shape of predicted point clouds, we project the predicted points of the object to the 2D plane and use the foreground pixels of its silhouette maps to constrain the position of the projected points. To reduce the outliers of the predicted point clouds, we propose a view calibrator to move the points projected to the background into the foreground by the single-view silhouette image. To the best of our knowledge, our approach is the first point cloud completion method that does not require any 3D supervision. The experimental results of our method are superior to those of the state-of-the-art unsupervised methods by a large margin. Moreover, compared to some supervised methods, our method achieves similar performance. We will make the source code publicly available at https://github.com/ltwu6/cross-pcc.
Learning Driving Policies for End-to-End Autonomous Driving
Oct 13, 2022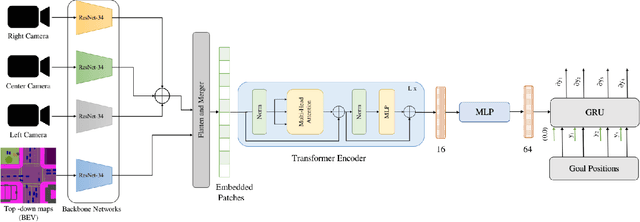

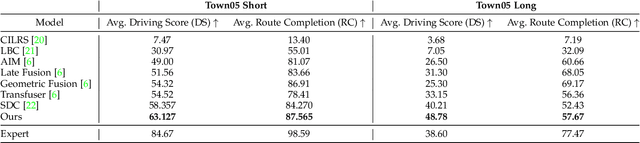
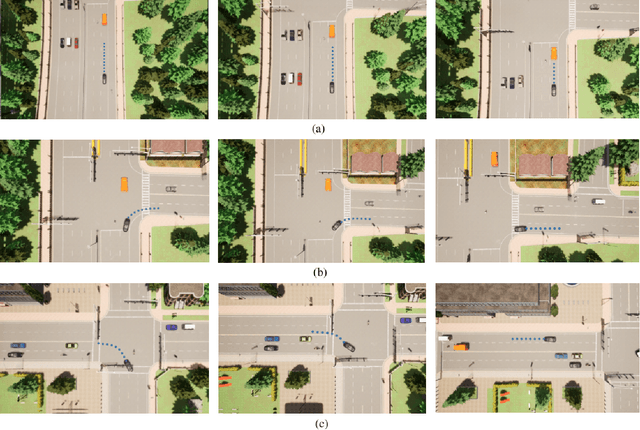
Humans tend to drive vehicles efficiently by relying on contextual and spatial information through the sensory organs. Inspired by this, most of the research is focused on how to learn robust and efficient driving policies. These works are mostly categorized as making modular or end-to-end systems for learning driving policies. However, the former approach has limitations due to the manual supervision of specific modules that hinder the scalability of these systems. In this work, we focus on the latter approach to formalize a framework for learning driving policies for end-to-end autonomous driving. In order to take inspiration from human driving, we have proposed a framework that incorporates three RGB cameras (left, right, and center) to mimic the human field of view and top-down semantic information for contextual representation in predicting the driving policies for autonomous driving. The sensor information is fused and encoded by the self-attention mechanism and followed by the auto-regressive waypoint prediction module. The proposed method's efficacy is experimentally evaluated using the CARLA simulator and outperforms the state-of-the-art methods by achieving the highest driving score at the evaluation time.
Greedy Modality Selection via Approximate Submodular Maximization
Oct 22, 2022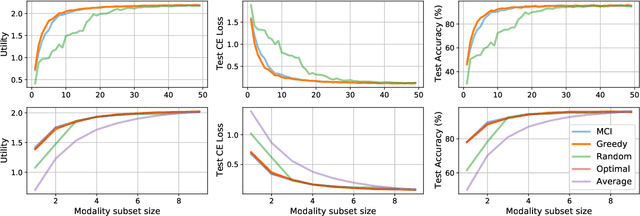
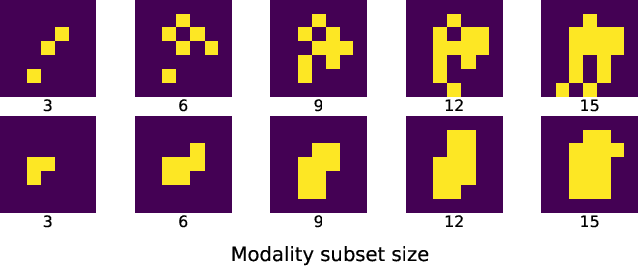

Multimodal learning considers learning from multi-modality data, aiming to fuse heterogeneous sources of information. However, it is not always feasible to leverage all available modalities due to memory constraints. Further, training on all the modalities may be inefficient when redundant information exists within data, such as different subsets of modalities providing similar performance. In light of these challenges, we study modality selection, intending to efficiently select the most informative and complementary modalities under certain computational constraints. We formulate a theoretical framework for optimizing modality selection in multimodal learning and introduce a utility measure to quantify the benefit of selecting a modality. For this optimization problem, we present efficient algorithms when the utility measure exhibits monotonicity and approximate submodularity. We also connect the utility measure with existing Shapley-value-based feature importance scores. Last, we demonstrate the efficacy of our algorithm on synthetic (Patch-MNIST) and two real-world (PEMS-SF, CMU-MOSI) datasets.
Full-scale Deeply Supervised Attention Network for Segmenting COVID-19 Lesions
Oct 27, 2022Automated delineation of COVID-19 lesions from lung CT scans aids the diagnosis and prognosis for patients. The asymmetric shapes and positioning of the infected regions make the task extremely difficult. Capturing information at multiple scales will assist in deciphering features, at global and local levels, to encompass lesions of variable size and texture. We introduce the Full-scale Deeply Supervised Attention Network (FuDSA-Net), for efficient segmentation of corona-infected lung areas in CT images. The model considers activation responses from all levels of the encoding path, encompassing multi-scalar features acquired at different levels of the network. This helps segment target regions (lesions) of varying shape, size and contrast. Incorporation of the entire gamut of multi-scalar characteristics into the novel attention mechanism helps prioritize the selection of activation responses and locations containing useful information. Determining robust and discriminatory features along the decoder path is facilitated with deep supervision. Connections in the decoder arm are remodeled to handle the issue of vanishing gradient. As observed from the experimental results, FuDSA-Net surpasses other state-of-the-art architectures; especially, when it comes to characterizing complicated geometries of the lesions.
Predicting Protein-Ligand Binding Affinity with Equivariant Line Graph Network
Oct 27, 2022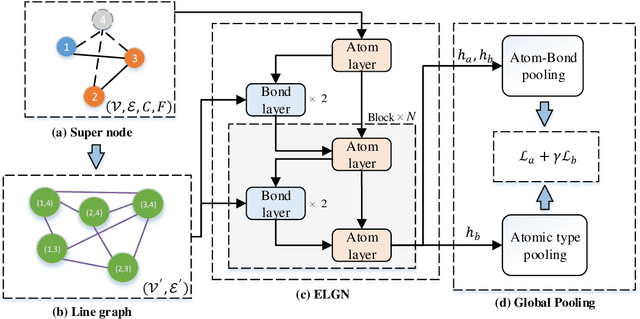
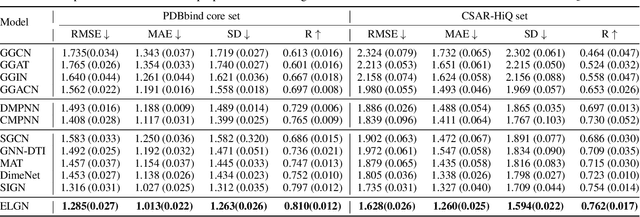
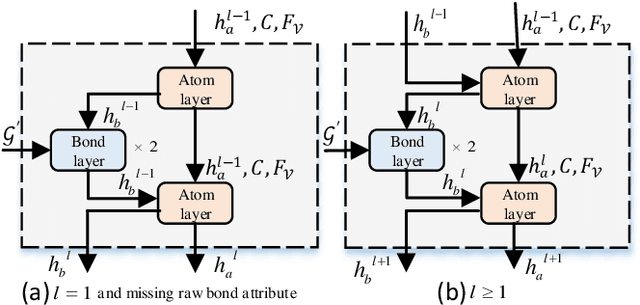
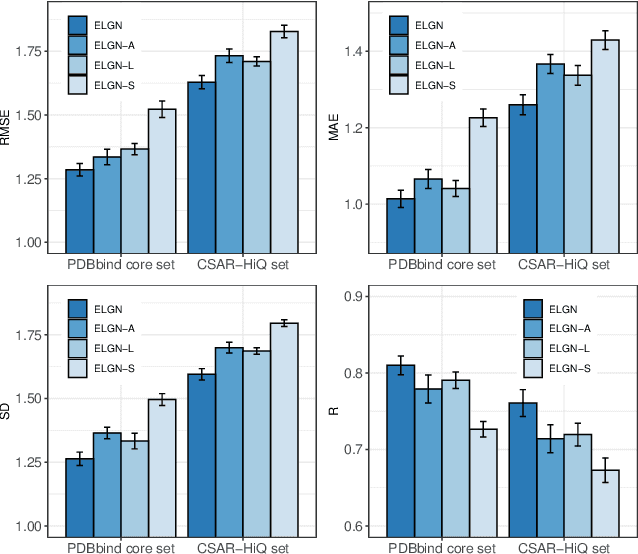
Binding affinity prediction of three-dimensional (3D) protein ligand complexes is critical for drug repositioning and virtual drug screening. Existing approaches transform a 3D protein-ligand complex to a two-dimensional (2D) graph, and then use graph neural networks (GNNs) to predict its binding affinity. However, the node and edge features of the 2D graph are extracted based on invariant local coordinate systems of the 3D complex. As a result, the method can not fully learn the global information of the complex, such as, the physical symmetry and the topological information of bonds. To address these issues, we propose a novel Equivariant Line Graph Network (ELGN) for affinity prediction of 3D protein ligand complexes. The proposed ELGN firstly adds a super node to the 3D complex, and then builds a line graph based on the 3D complex. After that, ELGN uses a new E(3)-equivariant network layer to pass the messages between nodes and edges based on the global coordinate system of the 3D complex. Experimental results on two real datasets demonstrate the effectiveness of ELGN over several state-of-the-art baselines.
Multi-view Contrastive Learning with Additive Margin for Adaptive Nasopharyngeal Carcinoma Radiotherapy Prediction
Oct 27, 2022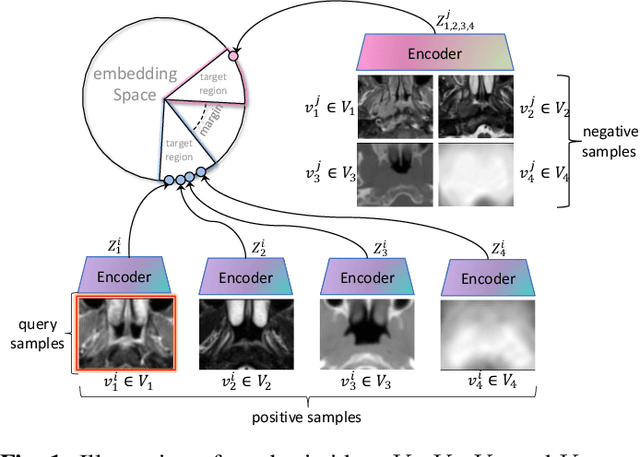

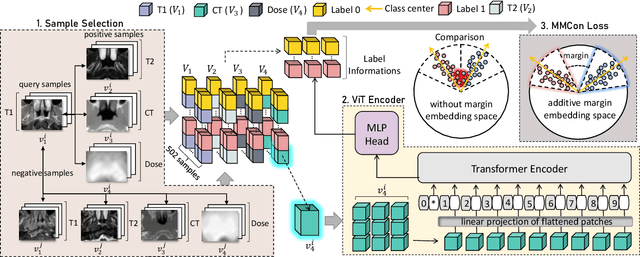
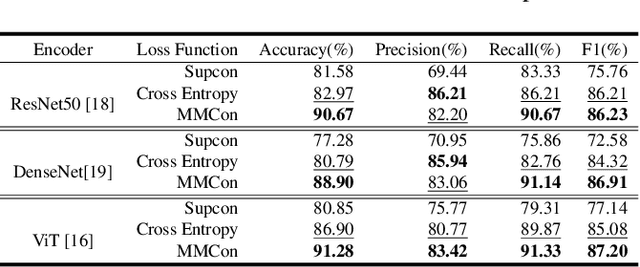
The prediction of adaptive radiation therapy (ART) prior to radiation therapy (RT) for nasopharyngeal carcinoma (NPC) patients is important to reduce toxicity and prolong the survival of patients. Currently, due to the complex tumor micro-environment, a single type of high-resolution image can provide only limited information. Meanwhile, the traditional softmax-based loss is insufficient for quantifying the discriminative power of a model. To overcome these challenges, we propose a supervised multi-view contrastive learning method with an additive margin (MMCon). For each patient, four medical images are considered to form multi-view positive pairs, which can provide additional information and enhance the representation of medical images. In addition, the embedding space is learned by means of contrastive learning. NPC samples from the same patient or with similar labels will remain close in the embedding space, while NPC samples with different labels will be far apart. To improve the discriminative ability of the loss function, we incorporate a margin into the contrastive learning. Experimental result show this new learning objective can be used to find an embedding space that exhibits superior discrimination ability for NPC images.