 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Privacy Risks of Algorithmic Recourse
Nov 10, 2022

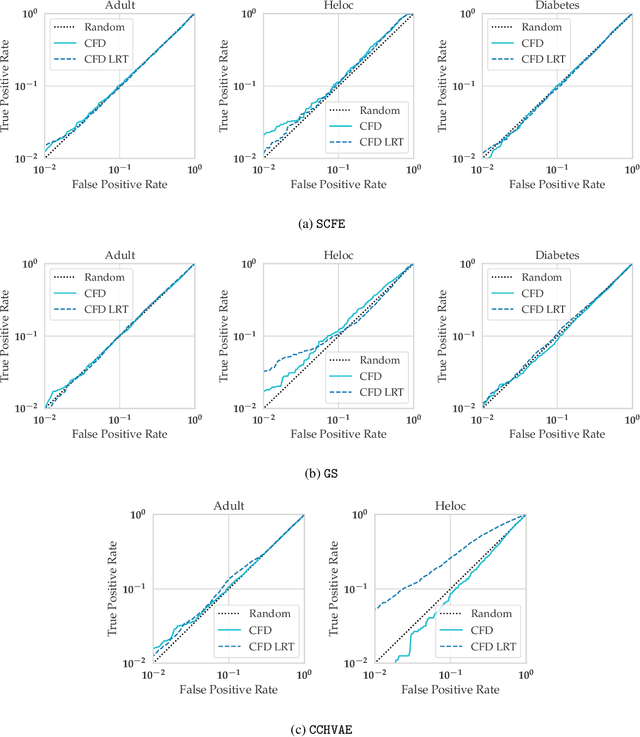
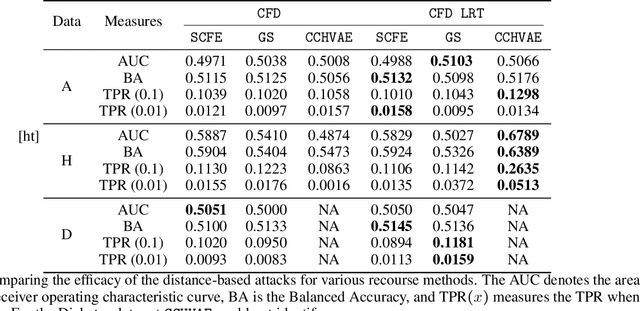
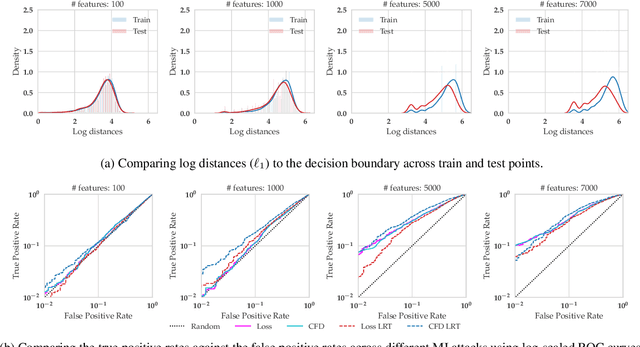
As predictive models are increasingly being employed to make consequential decisions, there is a growing emphasis on developing techniques that can provide algorithmic recourse to affected individuals. While such recourses can be immensely beneficial to affected individuals, potential adversaries could also exploit these recourses to compromise privacy. In this work, we make the first attempt at investigating if and how an adversary can leverage recourses to infer private information about the underlying model's training data. To this end, we propose a series of novel membership inference attacks which leverage algorithmic recourse. More specifically, we extend the prior literature on membership inference attacks to the recourse setting by leveraging the distances between data instances and their corresponding counterfactuals output by state-of-the-art recourse methods. Extensive experimentation with real world and synthetic datasets demonstrates significant privacy leakage through recourses. Our work establishes unintended privacy leakage as an important risk in the widespread adoption of recourse methods.
Contrastive Learning for Climate Model Bias Correction and Super-Resolution
Nov 10, 2022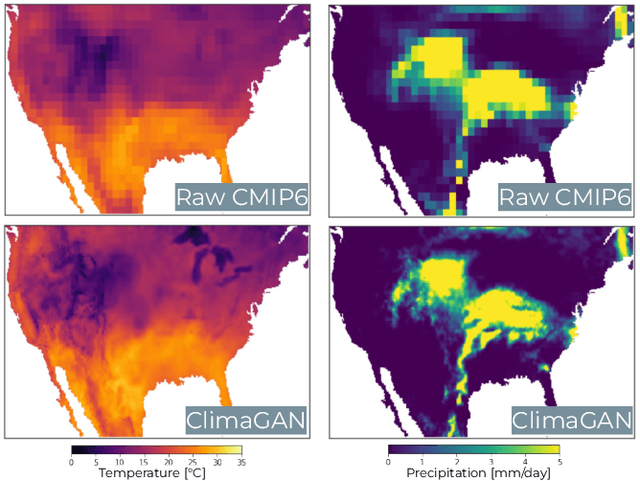
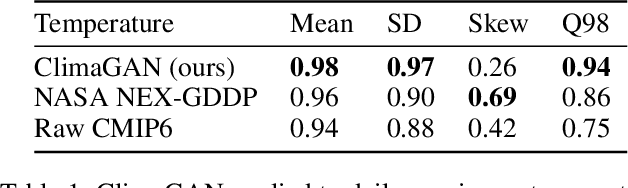
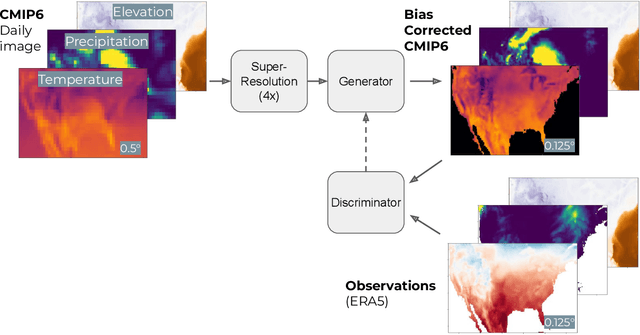
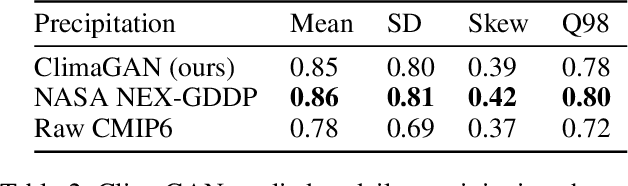
Climate models often require post-processing in order to make accurate estimates of local climate risk. The most common post-processing applied is bias-correction and spatial resolution enhancement. However, the statistical methods typically used for this not only are incapable of capturing multivariate spatial correlation information but are also reliant on rich observational data often not available outside of developed countries, limiting their potential. Here we propose an alternative approach to this challenge based on a combination of image super resolution (SR) and contrastive learning generative adversarial networks (GANs). We benchmark performance against NASA's flagship post-processed CMIP6 climate model product, NEX-GDDP. We find that our model successfully reaches a spatial resolution double that of NASA's product while also achieving comparable or improved levels of bias correction in both daily precipitation and temperature. The resulting higher fidelity simulations of present and forward-looking climate can enable more local, accurate models of hazards like flooding, drought, and heatwaves.
Learning to Drop Out: An Adversarial Approach to Training Sequence VAEs
Sep 26, 2022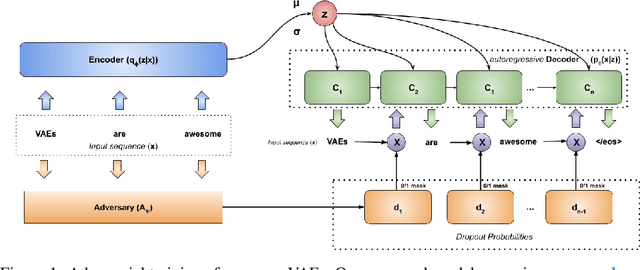
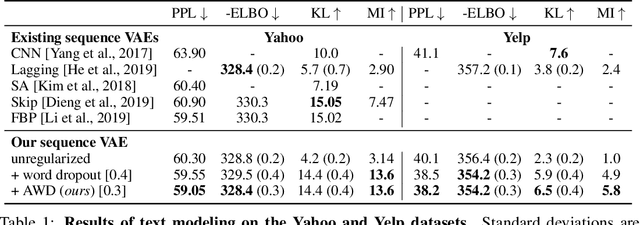
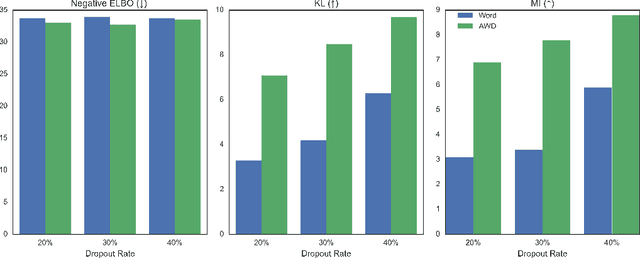

In principle, applying variational autoencoders (VAEs) to sequential data offers a method for controlled sequence generation, manipulation, and structured representation learning. However, training sequence VAEs is challenging: autoregressive decoders can often explain the data without utilizing the latent space, known as posterior collapse. To mitigate this, state-of-the-art models weaken the powerful decoder by applying uniformly random dropout to the decoder input. We show theoretically that this removes pointwise mutual information provided by the decoder input, which is compensated for by utilizing the latent space. We then propose an adversarial training strategy to achieve information-based stochastic dropout. Compared to uniform dropout on standard text benchmark datasets, our targeted approach increases both sequence modeling performance and the information captured in the latent space.
Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022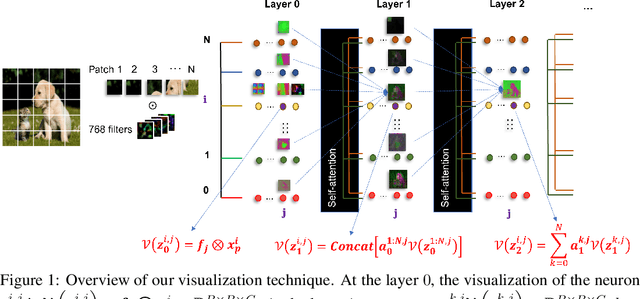
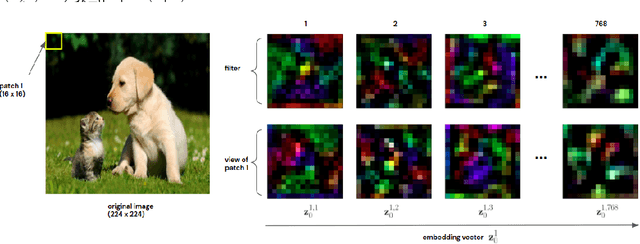


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization
Adaptive Contrastive Learning on Multimodal Transformer for Review Helpfulness Predictions
Nov 07, 2022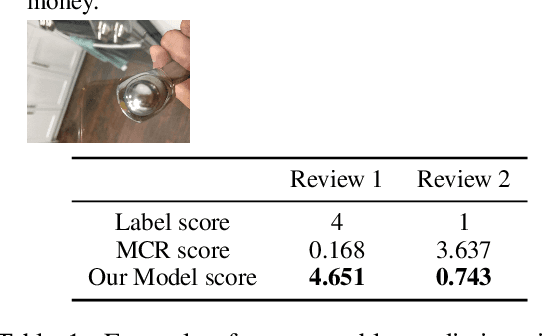
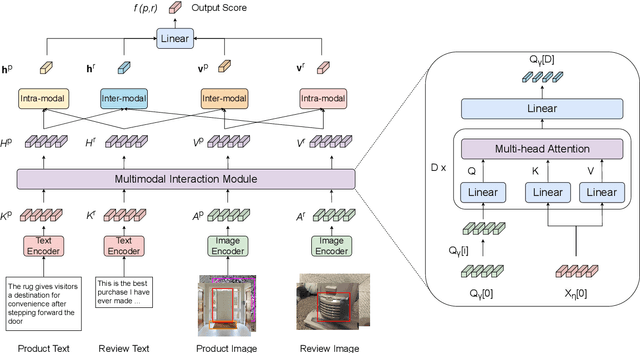
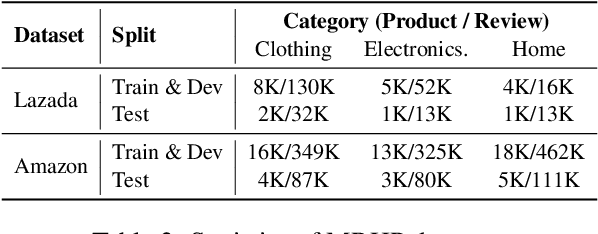
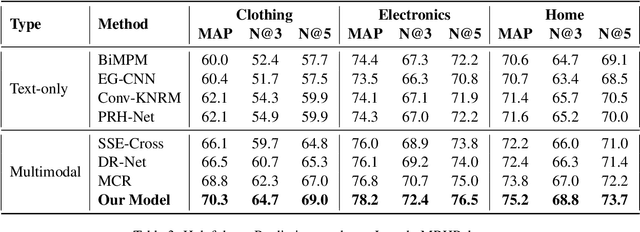
Modern Review Helpfulness Prediction systems are dependent upon multiple modalities, typically texts and images. Unfortunately, those contemporary approaches pay scarce attention to polish representations of cross-modal relations and tend to suffer from inferior optimization. This might cause harm to model's predictions in numerous cases. To overcome the aforementioned issues, we propose Multimodal Contrastive Learning for Multimodal Review Helpfulness Prediction (MRHP) problem, concentrating on mutual information between input modalities to explicitly elaborate cross-modal relations. In addition, we introduce Adaptive Weighting scheme for our contrastive learning approach in order to increase flexibility in optimization. Lastly, we propose Multimodal Interaction module to address the unalignment nature of multimodal data, thereby assisting the model in producing more reasonable multimodal representations. Experimental results show that our method outperforms prior baselines and achieves state-of-the-art results on two publicly available benchmark datasets for MRHP problem.
Learning Semantic Textual Similarity via Topic-informed Discrete Latent Variables
Nov 07, 2022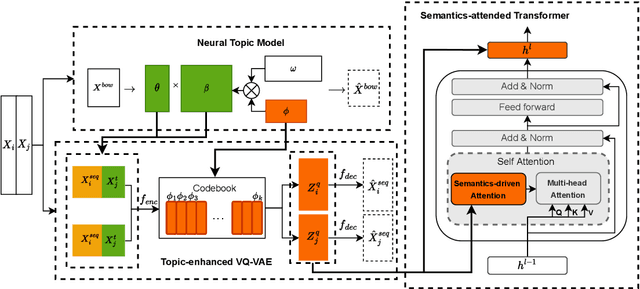
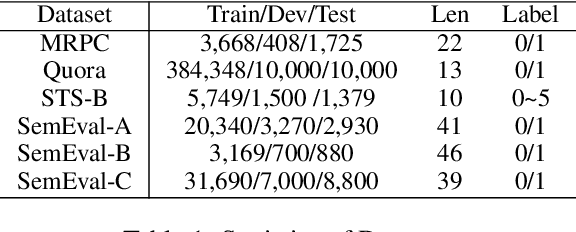
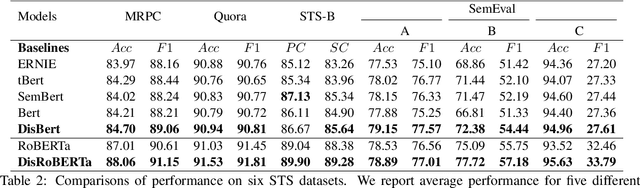
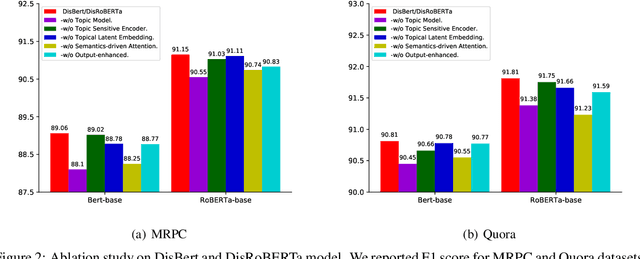
Recently, discrete latent variable models have received a surge of interest in both Natural Language Processing (NLP) and Computer Vision (CV), attributed to their comparable performance to the continuous counterparts in representation learning, while being more interpretable in their predictions. In this paper, we develop a topic-informed discrete latent variable model for semantic textual similarity, which learns a shared latent space for sentence-pair representation via vector quantization. Compared with previous models limited to local semantic contexts, our model can explore richer semantic information via topic modeling. We further boost the performance of semantic similarity by injecting the quantized representation into a transformer-based language model with a well-designed semantic-driven attention mechanism. We demonstrate, through extensive experiments across various English language datasets, that our model is able to surpass several strong neural baselines in semantic textual similarity tasks.
Semantic-Aware Environment Perception for Mobile Human-Robot Interaction
Nov 07, 2022
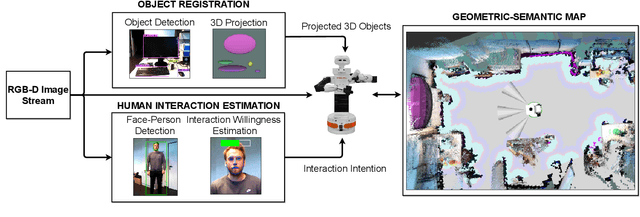
Current technological advances open up new opportunities for bringing human-machine interaction to a new level of human-centered cooperation. In this context, a key issue is the semantic understanding of the environment in order to enable mobile robots more complex interactions and a facilitated communication with humans. Prerequisites are the vision-based registration of semantic objects and humans, where the latter are further analyzed for potential interaction partners. Despite significant research achievements, the reliable and fast registration of semantic information still remains a challenging task for mobile robots in real-world scenarios. In this paper, we present a vision-based system for mobile assistive robots to enable a semantic-aware environment perception without additional a-priori knowledge. We deploy our system on a mobile humanoid robot that enables us to test our methods in real-world applications.
* ISPA 2012
Improving Document Image Understanding with Reinforcement Finetuning
Sep 26, 2022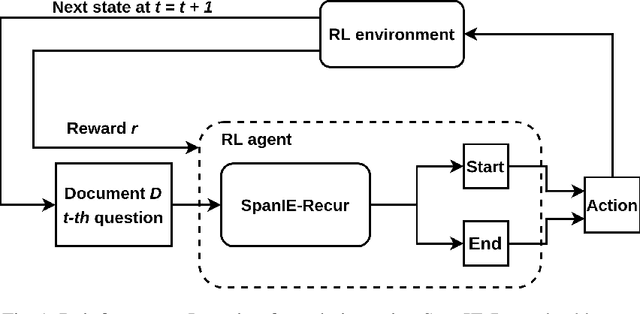
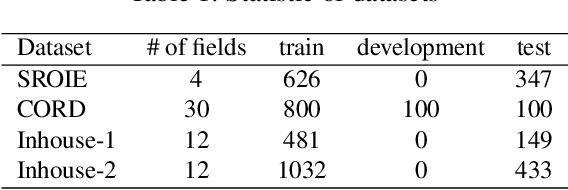
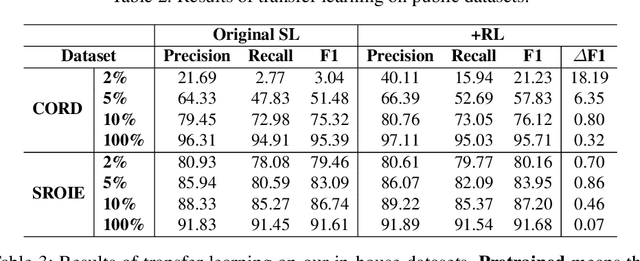
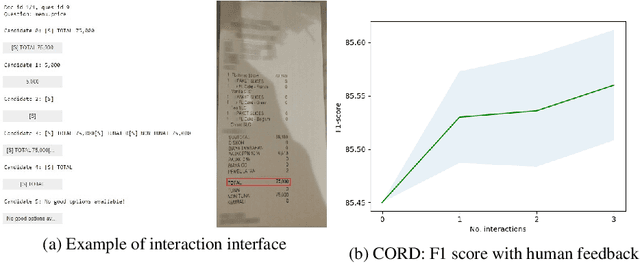
Successful Artificial Intelligence systems often require numerous labeled data to extract information from document images. In this paper, we investigate the problem of improving the performance of Artificial Intelligence systems in understanding document images, especially in cases where training data is limited. We address the problem by proposing a novel finetuning method using reinforcement learning. Our approach treats the Information Extraction model as a policy network and uses policy gradient training to update the model to maximize combined reward functions that complement the traditional cross-entropy losses. Our experiments on four datasets using labels and expert feedback demonstrate that our finetuning mechanism consistently improves the performance of a state-of-the-art information extractor, especially in the small training data regime.
Robust Collaborative 3D Object Detection in Presence of Pose Errors
Nov 15, 2022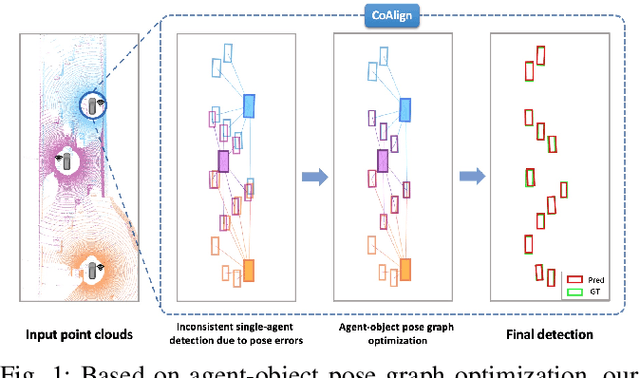
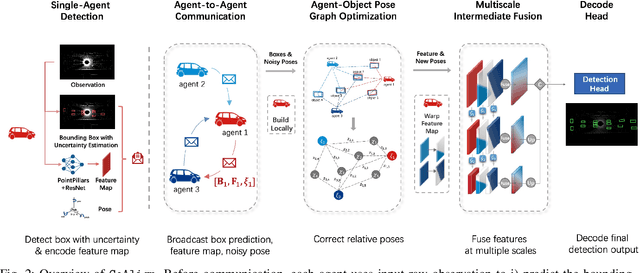
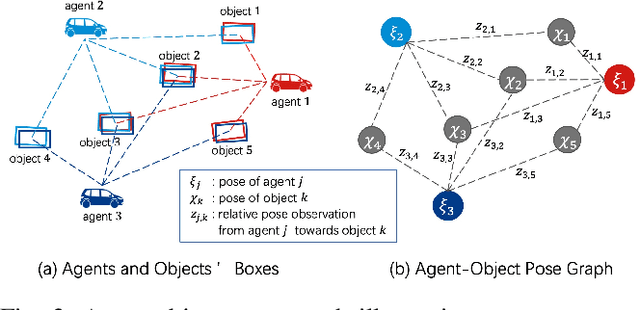
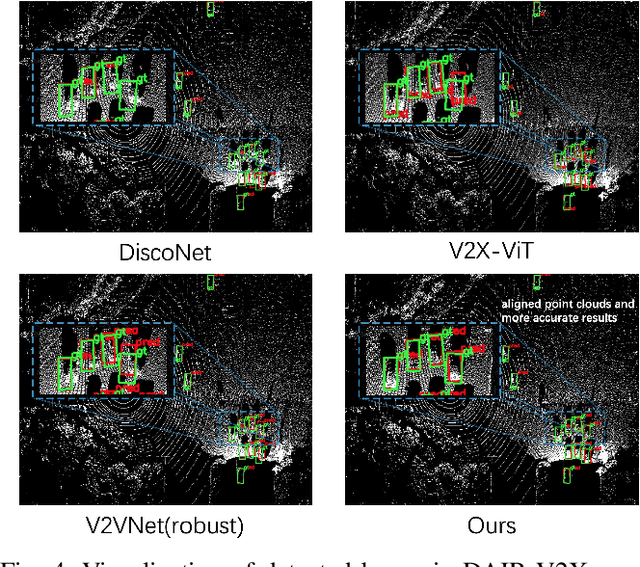
Collaborative 3D object detection exploits information exchange among multiple agents to enhance accuracy of object detection in presence of sensor impairments such as occlusion. However, in practice, pose estimation errors due to imperfect localization would cause spatial message misalignment and significantly reduce the performance of collaboration. To alleviate adverse impacts of pose errors, we propose CoAlign, a novel hybrid collaboration framework that is robust to unknown pose errors. The proposed solution relies on a novel agent-object pose graph modeling to enhance pose consistency among collaborating agents. Furthermore, we adopt a multi-scale data fusion strategy to aggregate intermediate features at multiple spatial resolutions. Comparing with previous works, which require ground-truth pose for training supervision, our proposed CoAlign is more practical since it doesn't require any ground-truth pose supervision in the training and makes no specific assumptions on pose errors. Extensive evaluation of the proposed method is carried out on multiple datasets, certifying that CoAlign significantly reduce relative localization error and achieving the state of art detection performance when pose errors exist. Code are made available for the use of the research community at https://github.com/yifanlu0227/CoAlign.
Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
Nov 15, 2022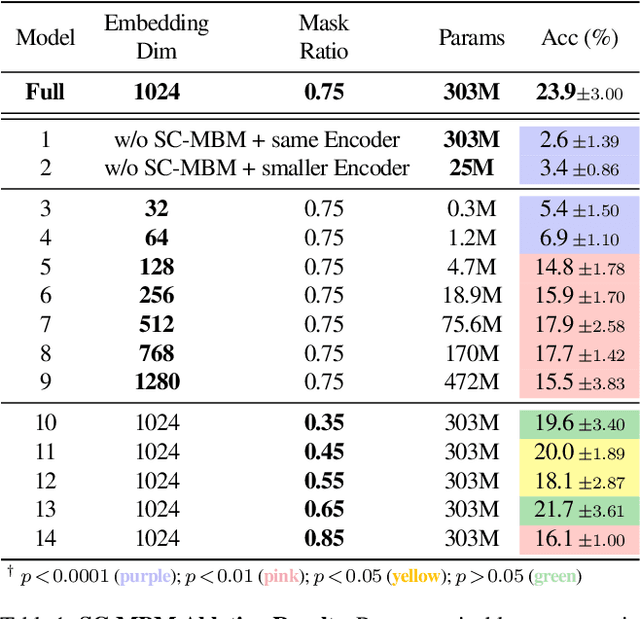
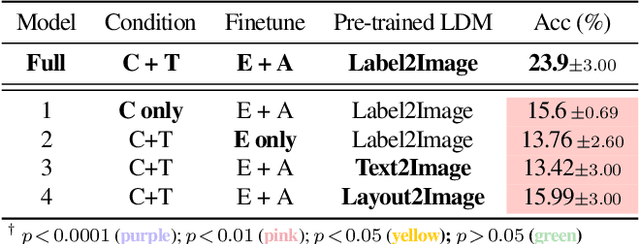
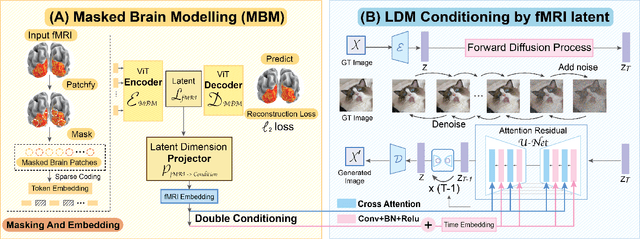
Decoding visual stimuli from brain recordings aims to deepen our understanding of the human visual system and build a solid foundation for bridging human and computer vision through the Brain-Computer Interface. However, reconstructing high-quality images with correct semantics from brain recordings is a challenging problem due to the complex underlying representations of brain signals and the scarcity of data annotations. In this work, we present MinD-Vis: Sparse Masked Brain Modeling with Double-Conditioned Latent Diffusion Model for Human Vision Decoding. Firstly, we learn an effective self-supervised representation of fMRI data using mask modeling in a large latent space inspired by the sparse coding of information in the primary visual cortex. Then by augmenting a latent diffusion model with double-conditioning, we show that MinD-Vis can reconstruct highly plausible images with semantically matching details from brain recordings using very few paired annotations. We benchmarked our model qualitatively and quantitatively; the experimental results indicate that our method outperformed state-of-the-art in both semantic mapping (100-way semantic classification) and generation quality (FID) by 66% and 41% respectively. An exhaustive ablation study was also conducted to analyze our framework.