 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting Drug Repurposing Candidates and Their Mechanisms from A Biomedical Knowledge Graph
Nov 30, 2022

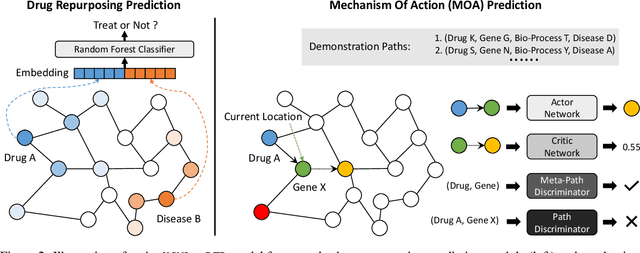
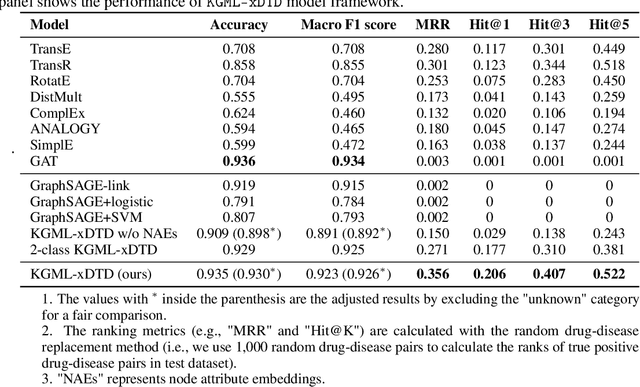
Computational drug repurposing is a cost- and time-efficient method to identify new indications of approved or experimental drugs/compounds. It is especially critical for emerging and/or orphan diseases due to its cheaper investment and shorter research cycle compared with traditional wet-lab drug discovery approaches. However, the underlying mechanisms of action between repurposed drugs and their target diseases remain largely unknown, which is still an unsolved issue in existing repurposing methods. As such, computational drug repurposing has not been widely adopted in clinical settings. In this work, based on a massive biomedical knowledge graph, we propose a computational drug repurposing framework that not only predicts the treatment probabilities between drugs and diseases but also predicts the path-based, testable mechanisms of action (MOAs) as their biomedical explanations. Specifically, we utilize the GraphSAGE model in an unsupervised manner to integrate each entity's neighborhood information and employ a Random Forest model to predict the treatment probabilities between pairs of drugs and diseases. Moreover, we train an adversarial actor-critic reinforcement learning model to predict the potential MOA for explaining drug purposing. To encourage the model to find biologically reasonable paths, we utilize the curated molecular interactions of drugs and a PubMed-publication-based concept distance to extract potential drug MOA paths from the knowledge graph as "demonstration paths" to guide the model during the process of path-finding. Comprehensive experiments and case studies show that the proposed framework outperforms state-of-the-art baselines in both predictive performance of drug repurposing and explanatory performance of recapitulating human-curated DrugMechDB-based paths.
Fuzzy clustering for the within-season estimation of cotton phenology
Nov 30, 2022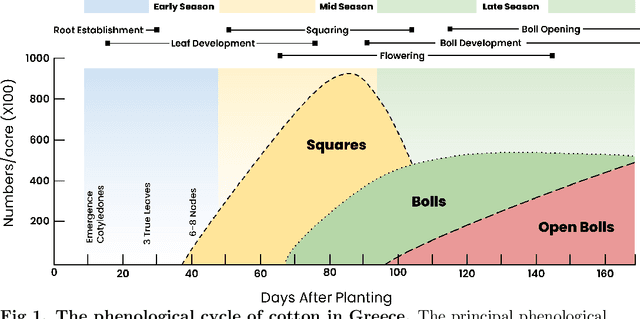

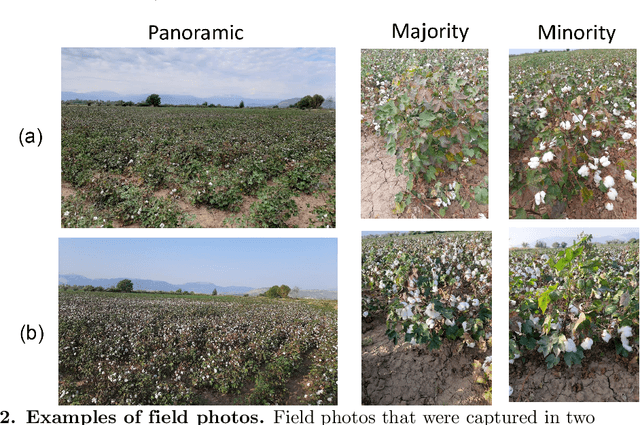
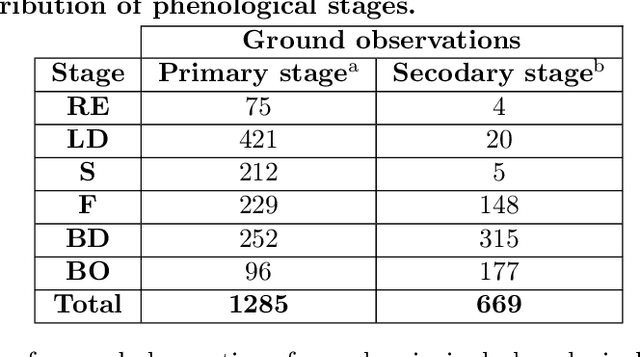
Crop phenology is crucial information for crop yield estimation and agricultural management. Traditionally, phenology has been observed from the ground; however Earth observation, weather and soil data have been used to capture the physiological growth of crops. In this work, we propose a new approach for the within-season phenology estimation for cotton at the field level. For this, we exploit a variety of Earth observation vegetation indices (derived from Sentinel-2) and numerical simulations of atmospheric and soil parameters. Our method is unsupervised to address the ever-present problem of sparse and scarce ground truth data that makes most supervised alternatives impractical in real-world scenarios. We applied fuzzy c-means clustering to identify the principal phenological stages of cotton and then used the cluster membership weights to further predict the transitional phases between adjacent stages. In order to evaluate our models, we collected 1,285 crop growth ground observations in Orchomenos, Greece. We introduced a new collection protocol, assigning up to two phenology labels that represent the primary and secondary growth stage in the field and thus indicate when stages are transitioning. Our model was tested against a baseline model that allowed to isolate the random agreement and evaluate its true competence. The results showed that our model considerably outperforms the baseline one, which is promising considering the unsupervised nature of the approach. The limitations and the relevant future work are thoroughly discussed. The ground observations are formatted in an ready-to-use dataset and will be available at https://github.com/Agri-Hub/cotton-phenology-dataset upon publication.
Robust Task-Specific Beamforming with Low-Resolution ADCs for Power-Efficient Hybrid MIMO Receivers
Nov 30, 2022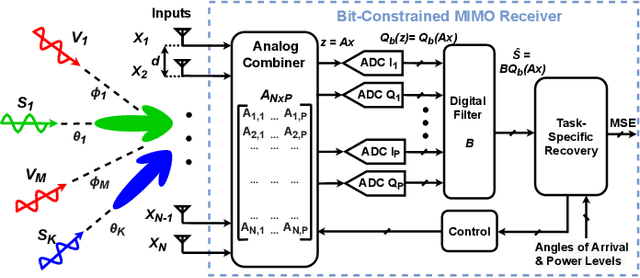
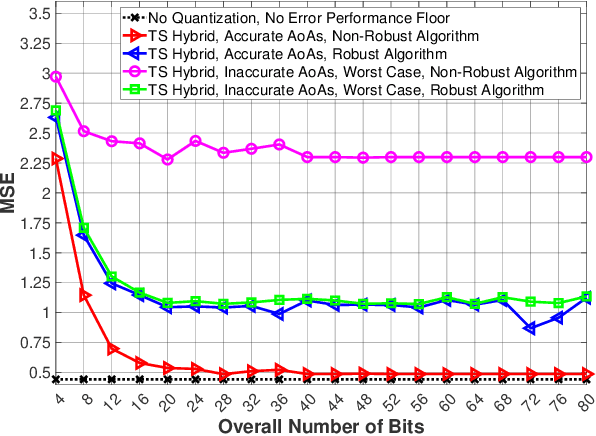
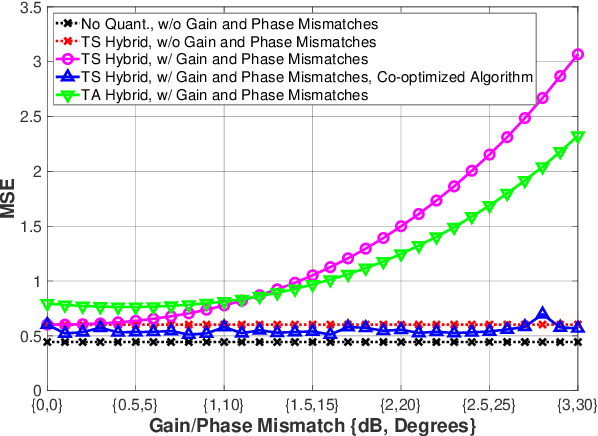
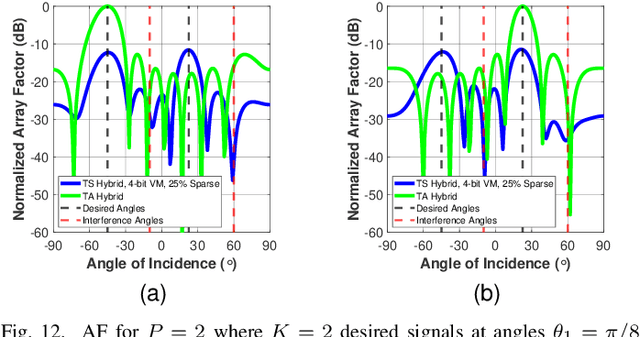
Multiple-input multiple-output (MIMO) systems exploit spatial diversity to facilitate multi-user communications with high spectral efficiency by beamforming. As MIMO systems utilize multiple antennas and radio frequency (RF) chains, they are typically costly to implement and consume high power. A common method to reduce the cost of MIMO receivers is utilizing less RF chains than antennas by employing hybrid analog/digital beamforming (HBF). However, the added analog circuitry involves active components whose consumed power may surpass that saved in RF chain reduction. An additional method to realize power-efficient MIMO systems is to use low-resolution analog-to-digital converters (ADCs), which typically compromises signal recovery accuracy. In this work, we propose a power-efficient hybrid MIMO receiver with low-quantization rate ADCs, by jointly optimizing the analog and digital processing in a hardware-oriented manner using task-specific quantization techniques. To mitigate power consumption on the analog front-end, we utilize efficient analog hardware architecture comprised of sparse low-resolution vector modulators, while accounting for their properties in design to maintain recovery accuracy and mitigate interferers in congested environments. To account for common mismatches induced by non-ideal hardware and inaccurate channel state information, we propose a robust mismatch aware design. Supported by numerical simulations and power analysis, our power-efficient MIMO receiver achieves comparable signal recovery performance to power-hungry fully-digital MIMO receivers using high-resolution ADCs. Furthermore, our receiver outperforms the task-agnostic HBF receivers with low-rate ADCs in recovery accuracy at lower power and successfully copes with hardware mismatches.
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
Nov 22, 2022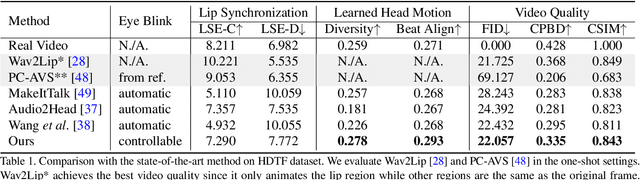
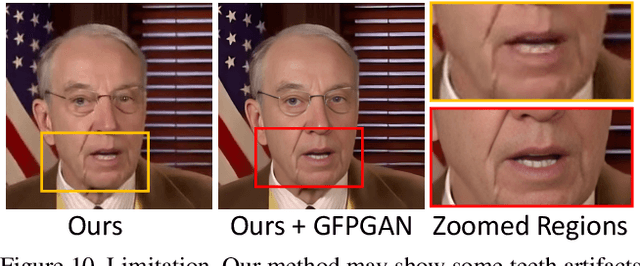
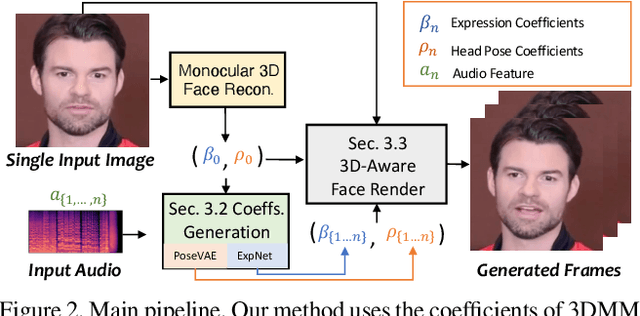
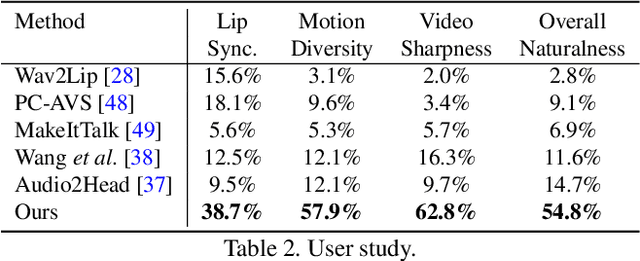
Generating talking head videos through a face image and a piece of speech audio still contains many challenges. ie, unnatural head movement, distorted expression, and identity modification. We argue that these issues are mainly because of learning from the coupled 2D motion fields. On the other hand, explicitly using 3D information also suffers problems of stiff expression and incoherent video. We present SadTalker, which generates 3D motion coefficients (head pose, expression) of the 3DMM from audio and implicitly modulates a novel 3D-aware face render for talking head generation. To learn the realistic motion coefficients, we explicitly model the connections between audio and different types of motion coefficients individually. Precisely, we present ExpNet to learn the accurate facial expression from audio by distilling both coefficients and 3D-rendered faces. As for the head pose, we design PoseVAE via a conditional VAE to synthesize head motion in different styles. Finally, the generated 3D motion coefficients are mapped to the unsupervised 3D keypoints space of the proposed face render, and synthesize the final video. We conduct extensive experiments to show the superior of our method in terms of motion and video quality.
Dealing with missing data using attention and latent space regularization
Nov 14, 2022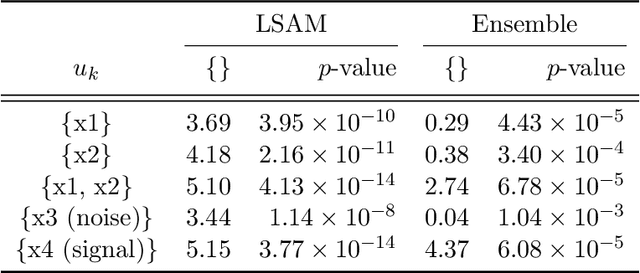
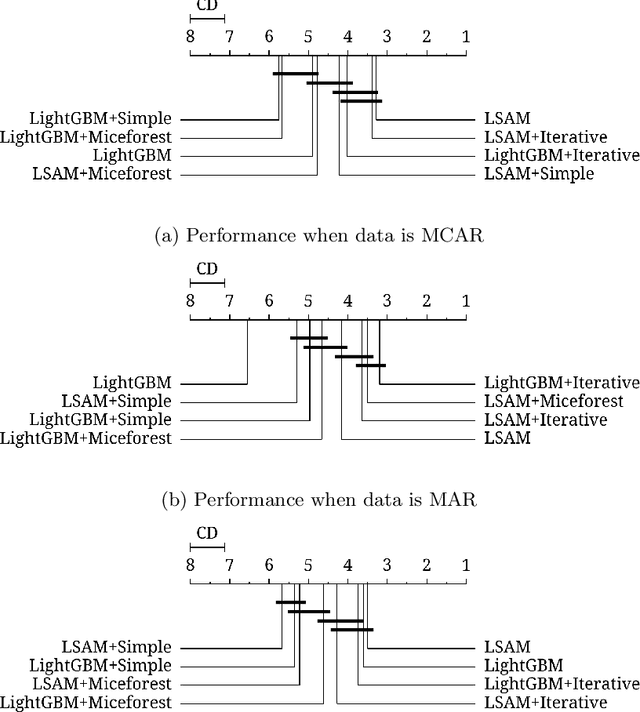
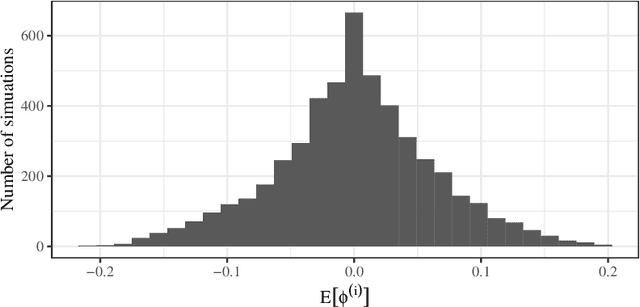
Most practical data science problems encounter missing data. A wide variety of solutions exist, each with strengths and weaknesses that depend upon the missingness-generating process. Here we develop a theoretical framework for training and inference using only observed variables enabling modeling of incomplete datasets without imputation. Using an information and measure-theoretic argument we construct models with latent space representations that regularize against the potential bias introduced by missing data. The theoretical properties of this approach are demonstrated empirically using a synthetic dataset. The performance of this approach is tested on 11 benchmarking datasets with missingness and 18 datasets corrupted across three missingness patterns with comparison against a state-of-the-art model and industry-standard imputation. We show that our proposed method overcomes the weaknesses of imputation methods and outperforms the current state-of-the-art.
Partial counterfactual identification and uplift modeling: theoretical results and real-world assessment
Nov 14, 2022
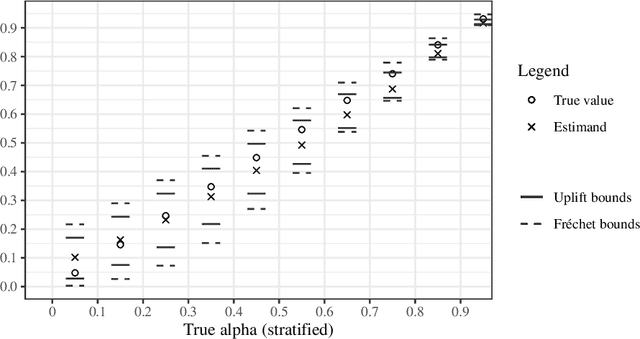

Counterfactuals are central in causal human reasoning and the scientific discovery process. The uplift, also called conditional average treatment effect, measures the causal effect of some action, or treatment, on the outcome of an individual. This paper discusses how it is possible to derive bounds on the probability of counterfactual statements based on uplift terms. First, we derive some original bounds on the probability of counterfactuals and we show that tightness of such bounds depends on the information of the feature set on the uplift term. Then, we propose a point estimator based on the assumption of conditional independence between the counterfactual outcomes. The quality of the bounds and the point estimators are assessed on synthetic data and a large real-world customer data set provided by a telecom company, showing significant improvement over the state of the art.
Learnable Spatio-Temporal Map Embeddings for Deep Inertial Localization
Nov 14, 2022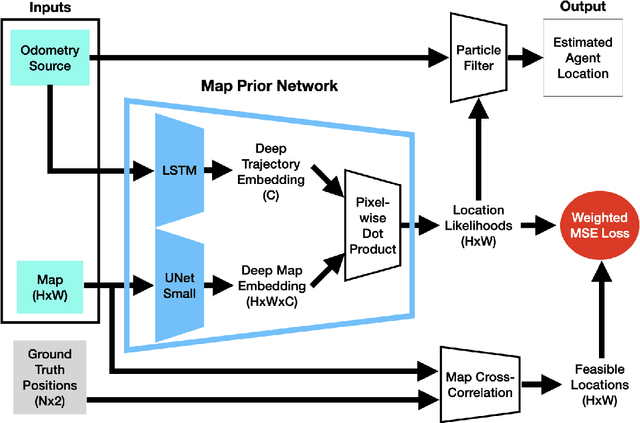
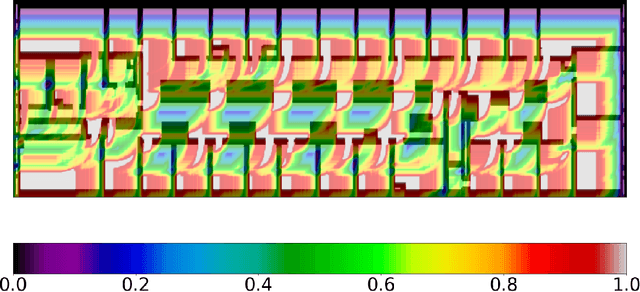
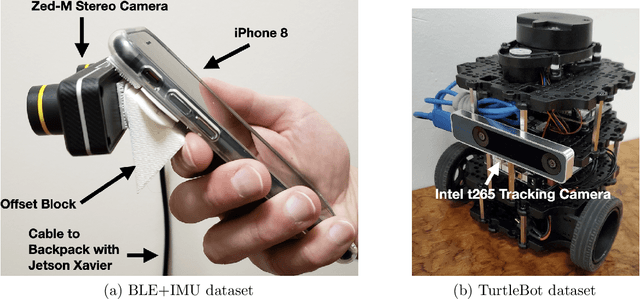
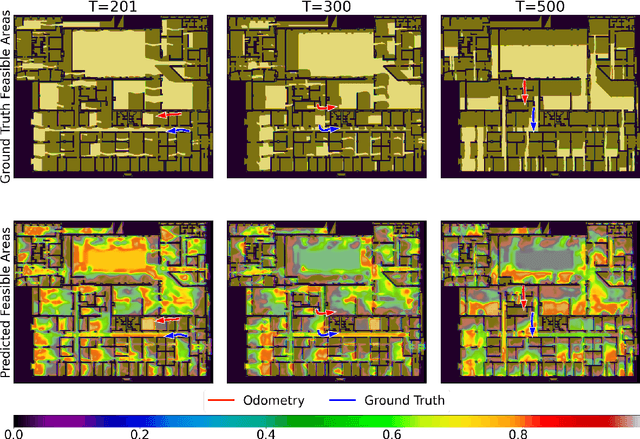
Indoor localization systems often fuse inertial odometry with map information via hand-defined methods to reduce odometry drift, but such methods are sensitive to noise and struggle to generalize across odometry sources. To address the robustness problem in map utilization, we propose a data-driven prior on possible user locations in a map by combining learned spatial map embeddings and temporal odometry embeddings. Our prior learns to encode which map regions are feasible locations for a user more accurately than previous hand-defined methods. This prior leads to a 49% improvement in inertial-only localization accuracy when used in a particle filter. This result is significant, as it shows that our relative positioning method can match the performance of absolute positioning using bluetooth beacons. To show the generalizability of our method, we also show similar improvements using wheel encoder odometry.
Choosing the number of factors in factor analysis with incomplete data via a hierarchical Bayesian information criterion
Apr 19, 2022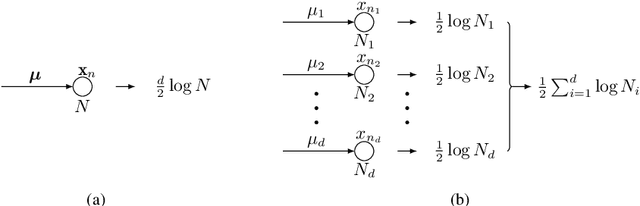
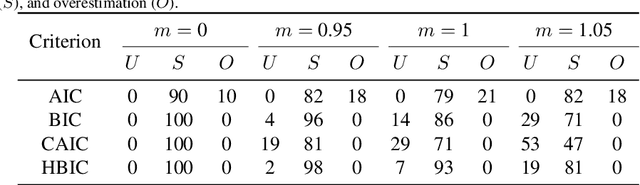
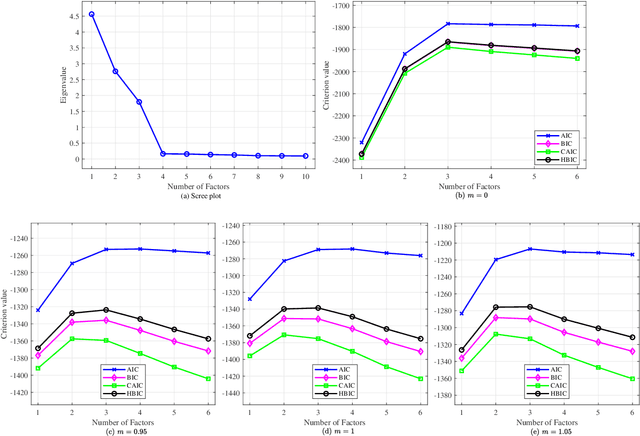
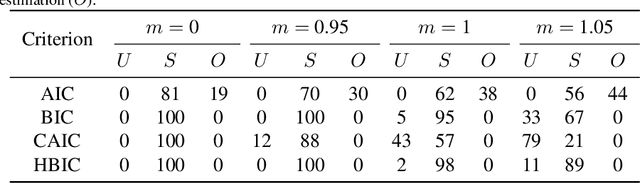
The Bayesian information criterion (BIC), defined as the observed data log likelihood minus a penalty term based on the sample size $N$, is a popular model selection criterion for factor analysis with complete data. This definition has also been suggested for incomplete data. However, the penalty term based on the `complete' sample size $N$ is the same no matter whether in a complete or incomplete data case. For incomplete data, there are often only $N_i<N$ observations for variable $i$, which means that using the `complete' sample size $N$ implausibly ignores the amounts of missing information inherent in incomplete data. Given this observation, a novel criterion called hierarchical BIC (HBIC) for factor analysis with incomplete data is proposed. The novelty is that it only uses the actual amounts of observed information, namely $N_i$'s, in the penalty term. Theoretically, it is shown that HBIC is a large sample approximation of variational Bayesian (VB) lower bound, and BIC is a further approximation of HBIC, which means that HBIC shares the theoretical consistency of BIC. Experiments on synthetic and real data sets are conducted to access the finite sample performance of HBIC, BIC, and related criteria with various missing rates. The results show that HBIC and BIC perform similarly when the missing rate is small, but HBIC is more accurate when the missing rate is not small.
A novel HD Computing Algebra: Non-associative superposition of states creating sparse bundles representing order information
Feb 17, 2022
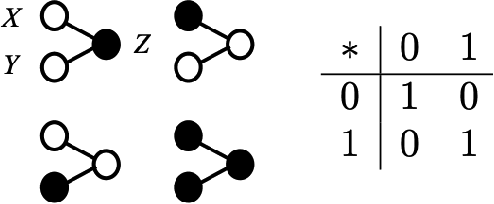
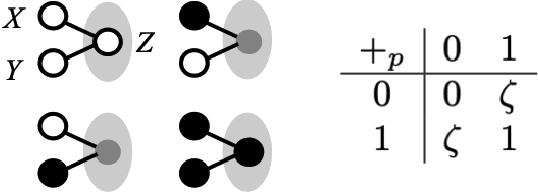
Information inflow into a computational system is by a sequence of information items. Cognitive computing, i.e. performing transformations along that sequence, requires to represent item information as well as sequential information. Among the most elementary operations is bundling, i.e. adding items, leading to 'memory states', i.e. bundles, from which information can be retrieved. If the bundling operation used is associative, e.g. ordinary vector-addition, sequential information can not be represented without imposing additional algebraic structure. A simple stochastic binary bundling rule inspired by the stochastic summation of neuronal activities allows the resulting memory state to represent both, item information as well as sequential information as long as it is non-associative. The memory state resulting from bundling together an arbitrary number of items is non-homogeneous and has a degree of sparseness, which is controlled by the activation threshold in summation. The bundling operation proposed allows to build a filter in the temporal as well as in the items' domain, which can be used to navigate the continuous inflow of information.
Assessing Bias in Face Image Quality Assessment
Nov 28, 2022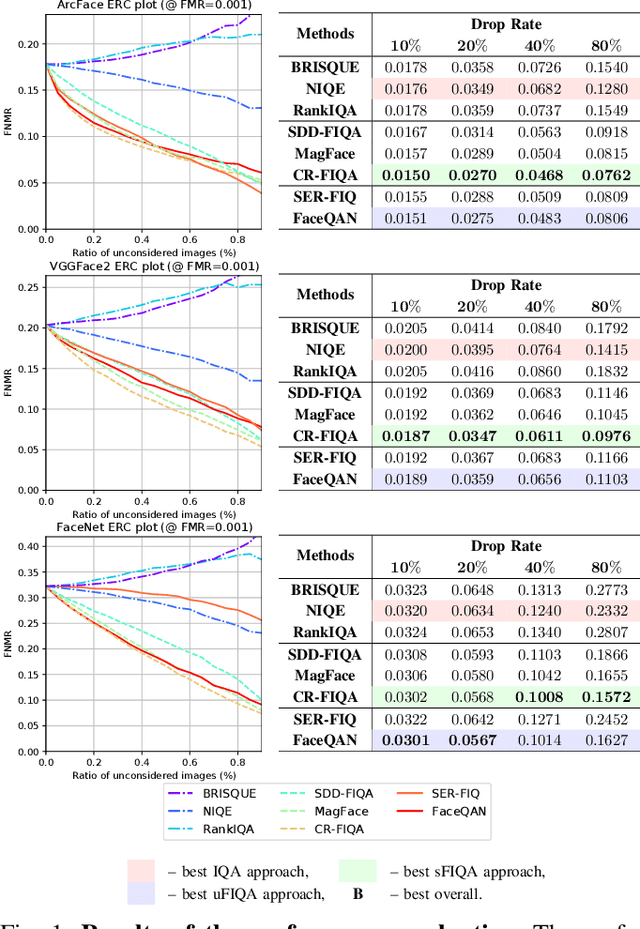

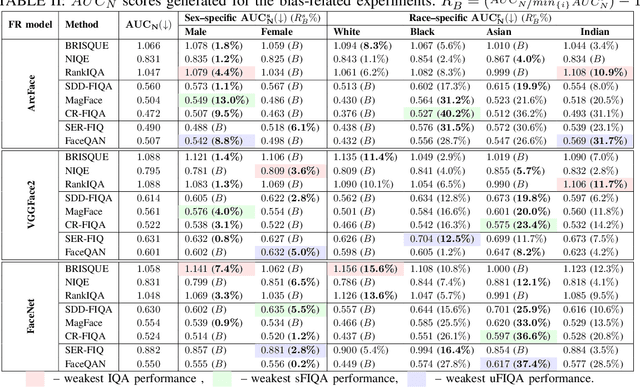
Face image quality assessment (FIQA) attempts to improve face recognition (FR) performance by providing additional information about sample quality. Because FIQA methods attempt to estimate the utility of a sample for face recognition, it is reasonable to assume that these methods are heavily influenced by the underlying face recognition system. Although modern face recognition systems are known to perform well, several studies have found that such systems often exhibit problems with demographic bias. It is therefore likely that such problems are also present with FIQA techniques. To investigate the demographic biases associated with FIQA approaches, this paper presents a comprehensive study involving a variety of quality assessment methods (general-purpose image quality assessment, supervised face quality assessment, and unsupervised face quality assessment methods) and three diverse state-of-theart FR models. Our analysis on the Balanced Faces in the Wild (BFW) dataset shows that all techniques considered are affected more by variations in race than sex. While the general-purpose image quality assessment methods appear to be less biased with respect to the two demographic factors considered, the supervised and unsupervised face image quality assessment methods both show strong bias with a tendency to favor white individuals (of either sex). In addition, we found that methods that are less racially biased perform worse overall. This suggests that the observed bias in FIQA methods is to a significant extent related to the underlying face recognition system.