 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Impact of Information Flow Topology on Safety of Tightly-coupled Connected and Automated Vehicle Platoons Utilizing Stochastic Control
Mar 29, 2022
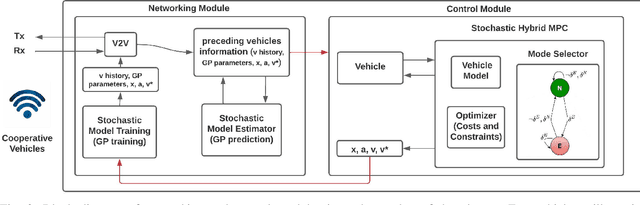
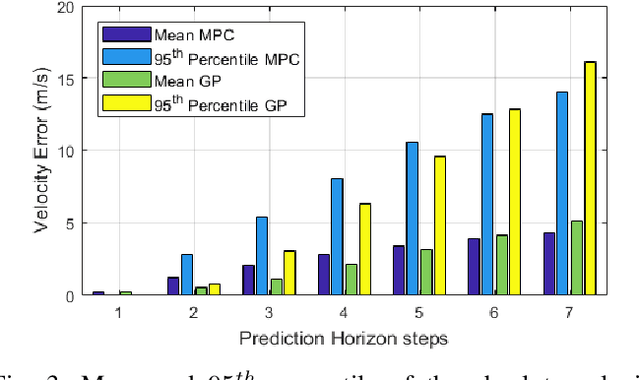
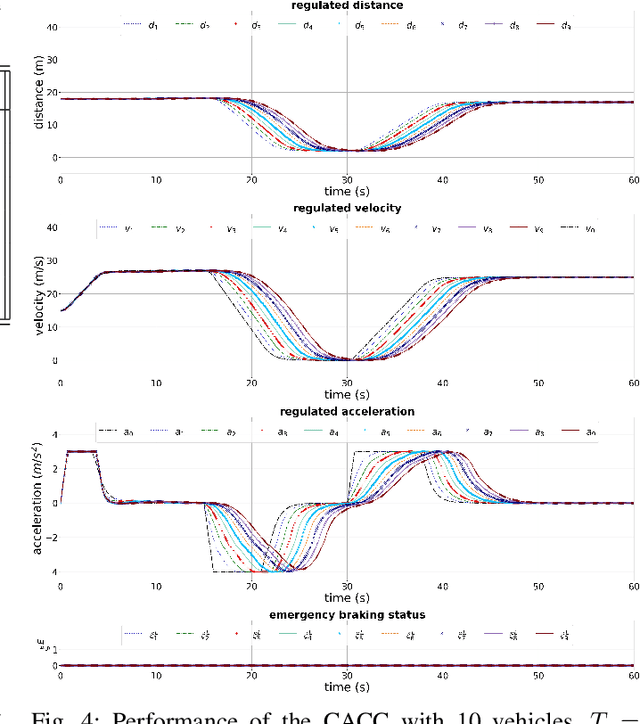
Cooperative driving, enabled by Vehicle-to-Everything (V2X) communication, is expected to significantly contribute to the transportation system's safety and efficiency. Cooperative Adaptive Cruise Control (CACC), a major cooperative driving application, has been the subject of many studies in recent years. The primary motivation behind using CACC is to reduce traffic congestion and improve traffic flow, traffic throughput, and highway capacity. Since the information flow between cooperative vehicles can significantly affect the dynamics of a platoon, the design and performance of control components are tightly dependent on the communication component performance. In addition, the choice of Information Flow Topology (IFT) can affect certain platoons properties such as stability and scalability. Although cooperative vehicles perception can be expanded to multiple predecessors information by using V2X communication, the communication technologies still suffer from scalability issues. Therefore, cooperative vehicles are required to predict each other's behavior to compensate for the effects of non-ideal communication. The notion of Model-Based Communication (MBC) was proposed to enhance cooperative vehicles perception under non-ideal communication by introducing a new flexible content structure for broadcasting joint vehicles dynamic/drivers behavior models. By utilizing a non-parametric (Bayesian) modeling scheme, i.e., Gaussian Process Regression (GPR), and the MBC concept, this paper develops a discrete hybrid stochastic model predictive control approach and examines the impact of communication losses and different information flow topologies on the performance and safety of the platoon. The results demonstrate an improvement in response time and safety using more vehicles information, validating the potential of cooperation to attenuate disturbances and improve traffic flow and safety.
A Secure Federated Data-Driven Evolutionary Multi-objective Optimization Algorithm
Oct 15, 2022
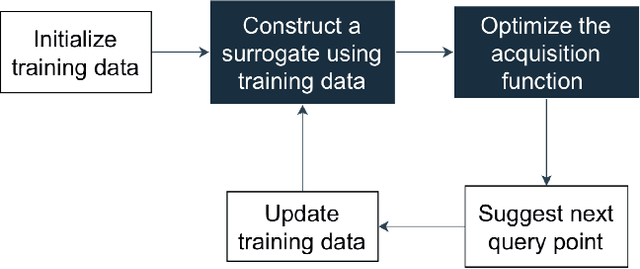
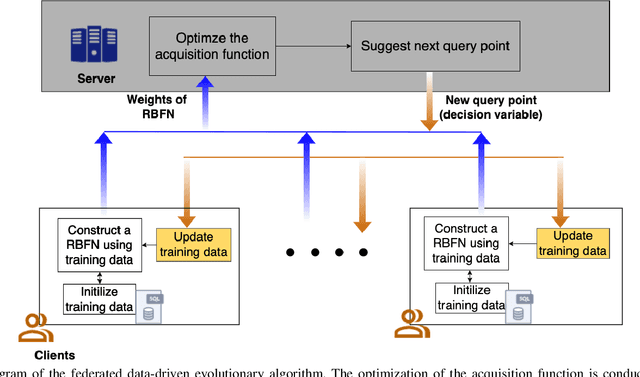
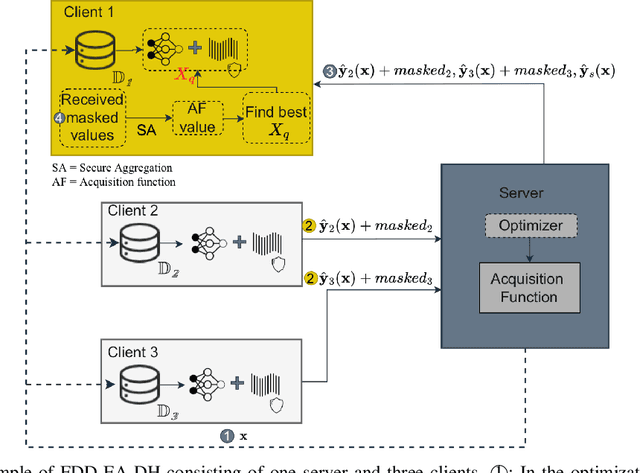
Data-driven evolutionary algorithms usually aim to exploit the information behind a limited amount of data to perform optimization, which have proved to be successful in solving many complex real-world optimization problems. However, most data-driven evolutionary algorithms are centralized, causing privacy and security concerns. Existing federated Bayesian algorithms and data-driven evolutionary algorithms mainly protect the raw data on each client. To address this issue, this paper proposes a secure federated data-driven evolutionary multi-objective optimization algorithm to protect both the raw data and the newly infilled solutions obtained by optimizing the acquisition function conducted on the server. We select the query points on a randomly selected client at each round of surrogate update by calculating the acquisition function values of the unobserved points on this client, thereby reducing the risk of leaking the information about the solution to be sampled. In addition, since the predicted objective values of each client may contain sensitive information, we mask the objective values with Diffie-Hellmann-based noise, and then send only the masked objective values of other clients to the selected client via the server. Since the calculation of the acquisition function also requires both the predicted objective value and the uncertainty of the prediction, the predicted mean objective and uncertainty are normalized to reduce the influence of noise. Experimental results on a set of widely used multi-objective optimization benchmarks show that the proposed algorithm can protect privacy and enhance security with only negligible sacrifice in the performance of federated data-driven evolutionary optimization.
FIT: A Metric for Model Sensitivity
Oct 16, 2022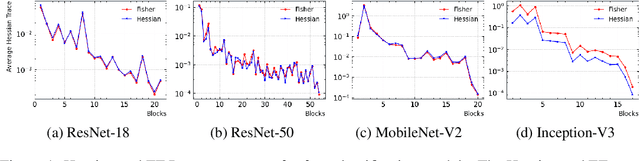

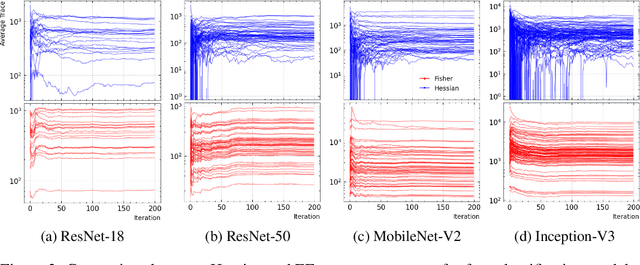
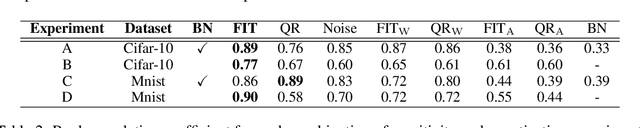
Model compression is vital to the deployment of deep learning on edge devices. Low precision representations, achieved via quantization of weights and activations, can reduce inference time and memory requirements. However, quantifying and predicting the response of a model to the changes associated with this procedure remains challenging. This response is non-linear and heterogeneous throughout the network. Understanding which groups of parameters and activations are more sensitive to quantization than others is a critical stage in maximizing efficiency. For this purpose, we propose FIT. Motivated by an information geometric perspective, FIT combines the Fisher information with a model of quantization. We find that FIT can estimate the final performance of a network without retraining. FIT effectively fuses contributions from both parameter and activation quantization into a single metric. Additionally, FIT is fast to compute when compared to existing methods, demonstrating favourable convergence properties. These properties are validated experimentally across hundreds of quantization configurations, with a focus on layer-wise mixed-precision quantization.
Improving Semantic Matching through Dependency-Enhanced Pre-trained Model with Adaptive Fusion
Oct 16, 2022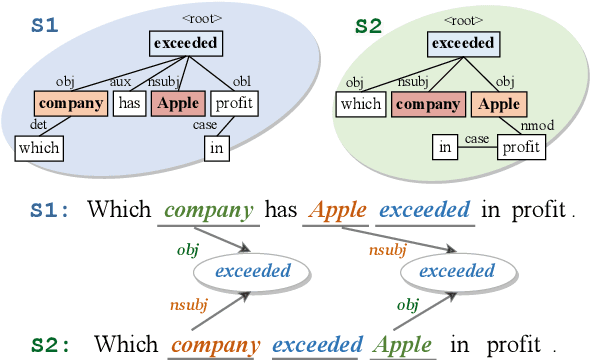
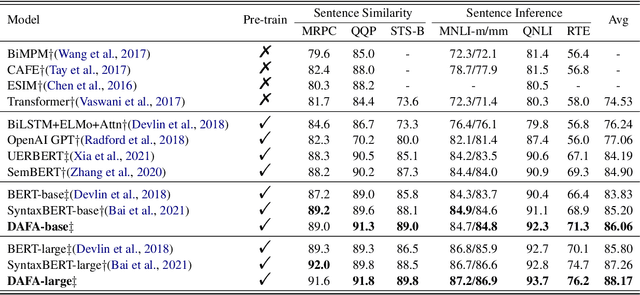
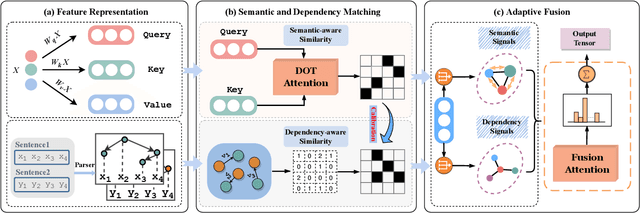
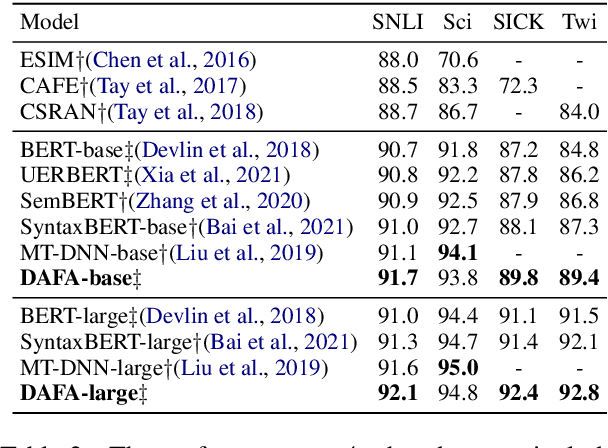
Transformer-based pre-trained models like BERT have achieved great progress on Semantic Sentence Matching. Meanwhile, dependency prior knowledge has also shown general benefits in multiple NLP tasks. However, how to efficiently integrate dependency prior structure into pre-trained models to better model complex semantic matching relations is still unsettled. In this paper, we propose the \textbf{D}ependency-Enhanced \textbf{A}daptive \textbf{F}usion \textbf{A}ttention (\textbf{DAFA}), which explicitly introduces dependency structure into pre-trained models and adaptively fuses it with semantic information. Specifically, \textbf{\emph{(i)}} DAFA first proposes a structure-sensitive paradigm to construct a dependency matrix for calibrating attention weights. It adopts an adaptive fusion module to integrate the obtained dependency information and the original semantic signals. Moreover, DAFA reconstructs the attention calculation flow and provides better interpretability. By applying it on BERT, our method achieves state-of-the-art or competitive performance on 10 public datasets, demonstrating the benefits of adaptively fusing dependency structure in semantic matching task.
Speaker Information Can Guide Models to Better Inductive Biases: A Case Study On Predicting Code-Switching
Mar 16, 2022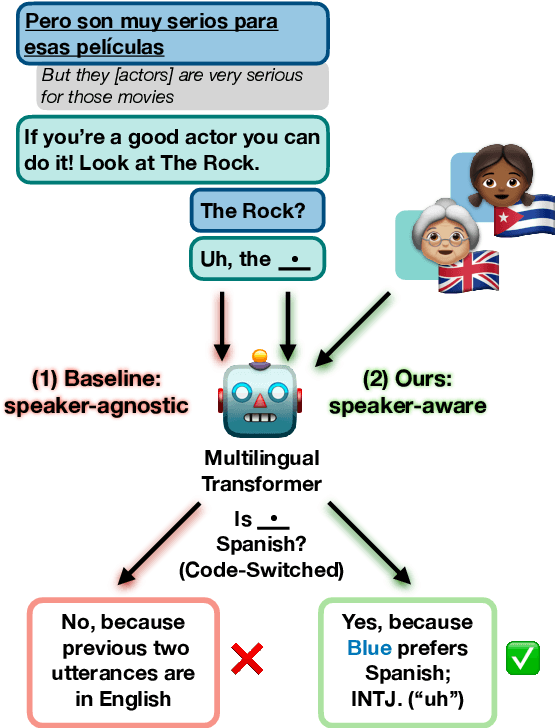

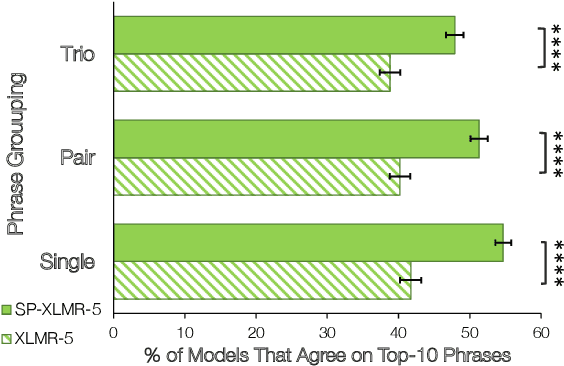
Natural language processing (NLP) models trained on people-generated data can be unreliable because, without any constraints, they can learn from spurious correlations that are not relevant to the task. We hypothesize that enriching models with speaker information in a controlled, educated way can guide them to pick up on relevant inductive biases. For the speaker-driven task of predicting code-switching points in English--Spanish bilingual dialogues, we show that adding sociolinguistically-grounded speaker features as prepended prompts significantly improves accuracy. We find that by adding influential phrases to the input, speaker-informed models learn useful and explainable linguistic information. To our knowledge, we are the first to incorporate speaker characteristics in a neural model for code-switching, and more generally, take a step towards developing transparent, personalized models that use speaker information in a controlled way.
U-HRNet: Delving into Improving Semantic Representation of High Resolution Network for Dense Prediction
Oct 13, 2022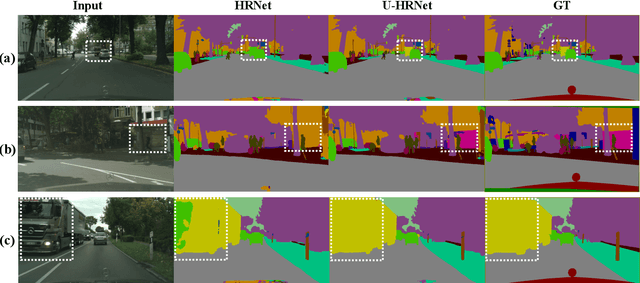

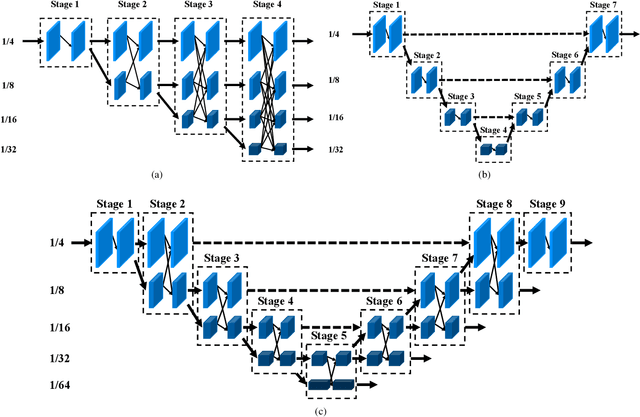
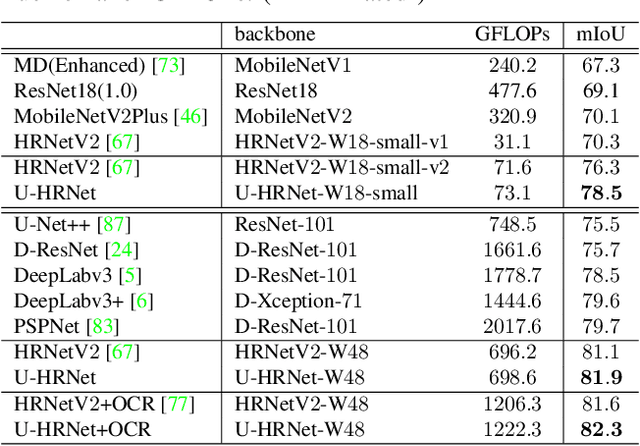
High resolution and advanced semantic representation are both vital for dense prediction. Empirically, low-resolution feature maps often achieve stronger semantic representation, and high-resolution feature maps generally can better identify local features such as edges, but contains weaker semantic information. Existing state-of-the-art frameworks such as HRNet has kept low-resolution and high-resolution feature maps in parallel, and repeatedly exchange the information across different resolutions. However, we believe that the lowest-resolution feature map often contains the strongest semantic information, and it is necessary to go through more layers to merge with high-resolution feature maps, while for high-resolution feature maps, the computational cost of each convolutional layer is very large, and there is no need to go through so many layers. Therefore, we designed a U-shaped High-Resolution Network (U-HRNet), which adds more stages after the feature map with strongest semantic representation and relaxes the constraint in HRNet that all resolutions need to be calculated parallel for a newly added stage. More calculations are allocated to low-resolution feature maps, which significantly improves the overall semantic representation. U-HRNet is a substitute for the HRNet backbone and can achieve significant improvement on multiple semantic segmentation and depth prediction datasets, under the exactly same training and inference setting, with almost no increasing in the amount of calculation. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
Contrastive Learning for Climate Model Bias Correction and Super-Resolution
Nov 10, 2022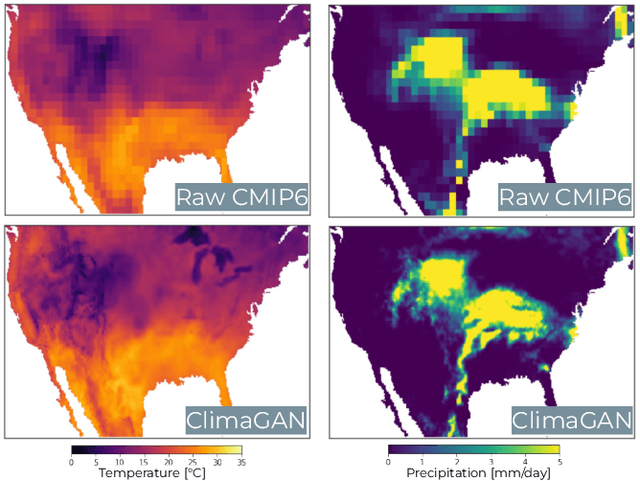
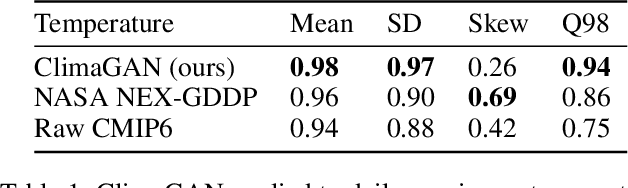
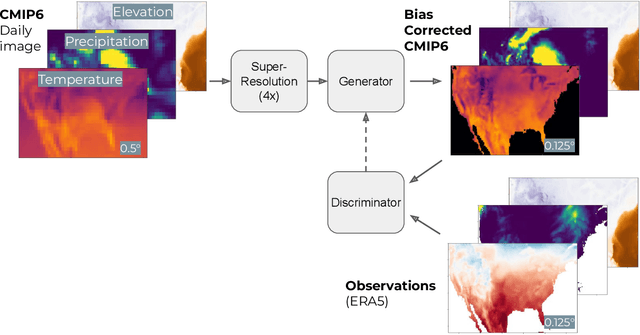
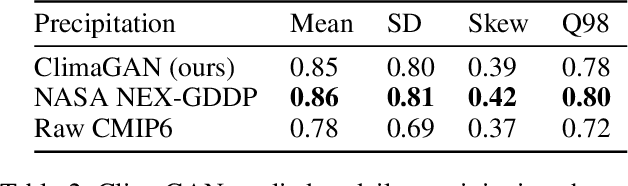
Climate models often require post-processing in order to make accurate estimates of local climate risk. The most common post-processing applied is bias-correction and spatial resolution enhancement. However, the statistical methods typically used for this not only are incapable of capturing multivariate spatial correlation information but are also reliant on rich observational data often not available outside of developed countries, limiting their potential. Here we propose an alternative approach to this challenge based on a combination of image super resolution (SR) and contrastive learning generative adversarial networks (GANs). We benchmark performance against NASA's flagship post-processed CMIP6 climate model product, NEX-GDDP. We find that our model successfully reaches a spatial resolution double that of NASA's product while also achieving comparable or improved levels of bias correction in both daily precipitation and temperature. The resulting higher fidelity simulations of present and forward-looking climate can enable more local, accurate models of hazards like flooding, drought, and heatwaves.
Robust Model Selection of Non Tree-Structured Gaussian Graphical Models
Nov 10, 2022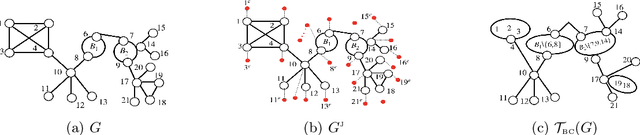

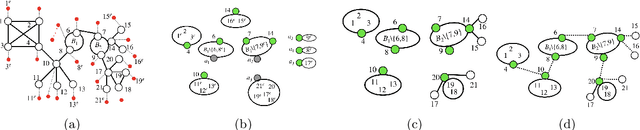
We consider the problem of learning the structure underlying a Gaussian graphical model when the variables (or subsets thereof) are corrupted by independent noise. A recent line of work establishes that even for tree-structured graphical models, only partial structure recovery is possible and goes on to devise algorithms to identify the structure up to an (unavoidable) equivalence class of trees. We extend these results beyond trees and consider the model selection problem under noise for non tree-structured graphs, as tree graphs cannot model several real-world scenarios. Although unidentifiable, we show that, like the tree-structured graphs, the ambiguity is limited to an equivalence class. This limited ambiguity can help provide meaningful clustering information (even with noise), which is helpful in computer and social networks, protein-protein interaction networks, and power networks. Furthermore, we devise an algorithm based on a novel ancestral testing method for recovering the equivalence class. We complement these results with finite sample guarantees for the algorithm in the high-dimensional regime.
Distributed Precoding Design for Multi-Group Multicasting in Cell-Free Massive MIMO
Nov 10, 2022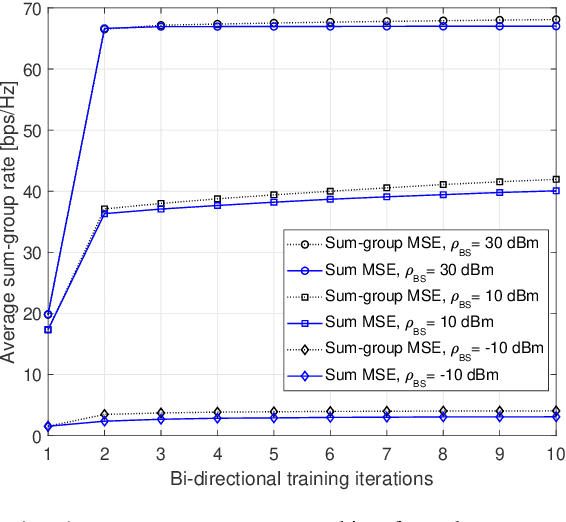
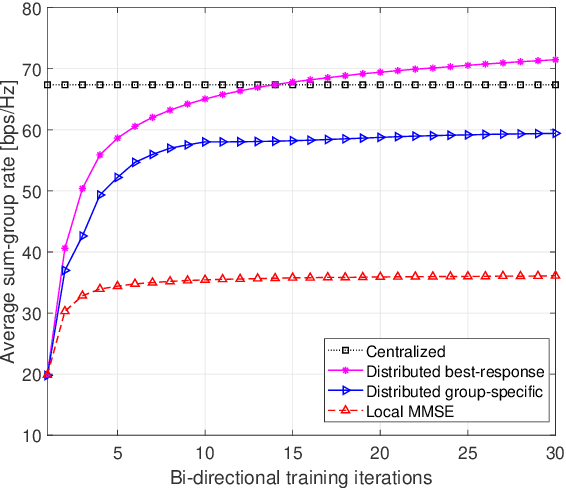
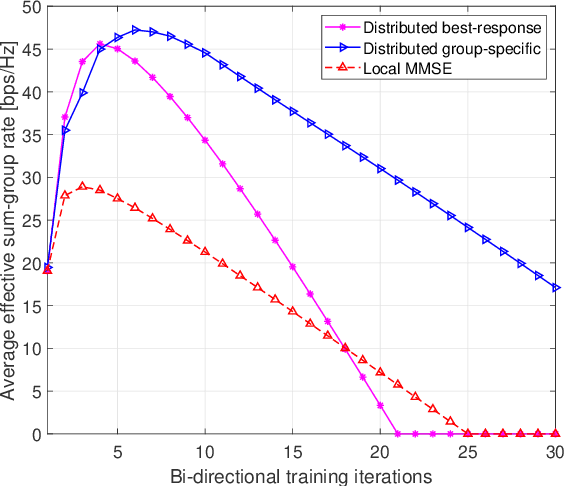
We consider multi-group multicast precoding designs for cell-free massive multiple-input multiple-output (MIMO) systems. To optimize the transmit and receive beamforming strategies, we focus on minimizing the sum of the maximum mean squared errors (MSEs) over the multicast groups, which is then approximated with the sum MSE to simplify the computation and signaling. We adopt an iterative bi-directional training scheme with uplink and downlink precoded pilots to cooperatively design the multi-group multicast precoders at each base station and the combiners at each user equipment in a distributed fashion. An additional group-specific uplink training resource is introduced, which entirely eliminates the need for backhaul signaling for channel state information (CSI) exchange. We also propose a simpler distributed precoding design based solely on group-specific pilots, which can be useful in the case of scarce training resources. Numerical results show that the proposed distributed methods greatly outperform conventional cell-free massive MIMO precoding designs that rely solely on local CSI.
On the Privacy Risks of Algorithmic Recourse
Nov 10, 2022
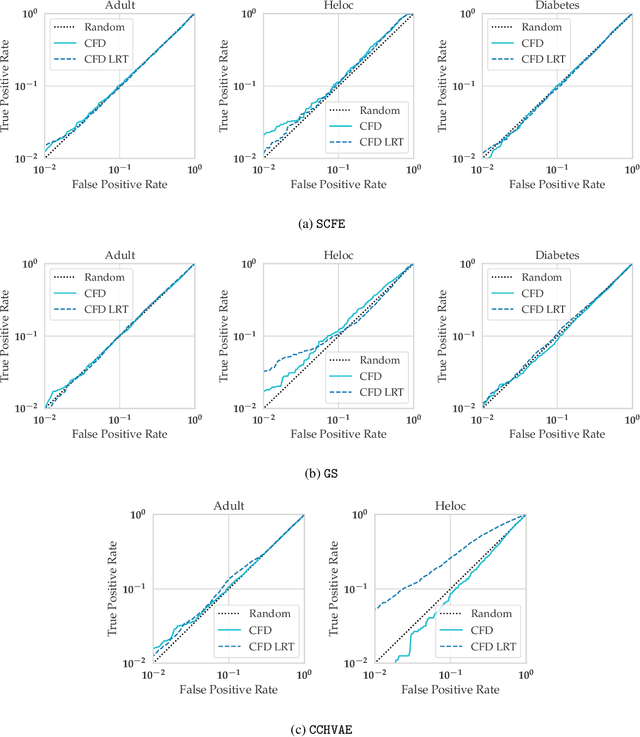
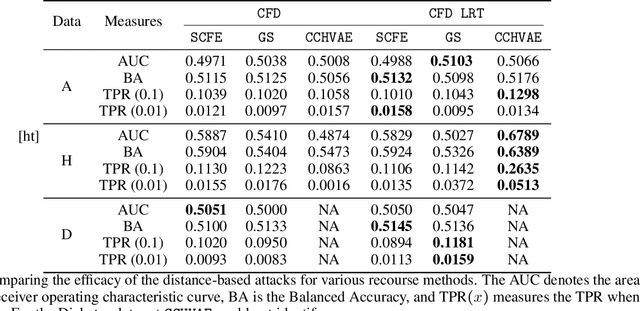
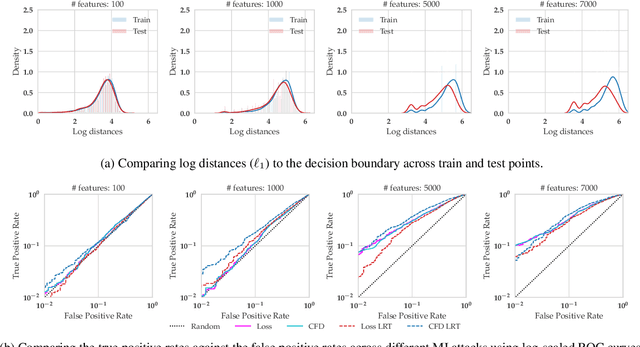
As predictive models are increasingly being employed to make consequential decisions, there is a growing emphasis on developing techniques that can provide algorithmic recourse to affected individuals. While such recourses can be immensely beneficial to affected individuals, potential adversaries could also exploit these recourses to compromise privacy. In this work, we make the first attempt at investigating if and how an adversary can leverage recourses to infer private information about the underlying model's training data. To this end, we propose a series of novel membership inference attacks which leverage algorithmic recourse. More specifically, we extend the prior literature on membership inference attacks to the recourse setting by leveraging the distances between data instances and their corresponding counterfactuals output by state-of-the-art recourse methods. Extensive experimentation with real world and synthetic datasets demonstrates significant privacy leakage through recourses. Our work establishes unintended privacy leakage as an important risk in the widespread adoption of recourse methods.