 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Log-density gradient covariance and automatic metric tensors for Riemann manifold Monte Carlo methods
Nov 03, 2022
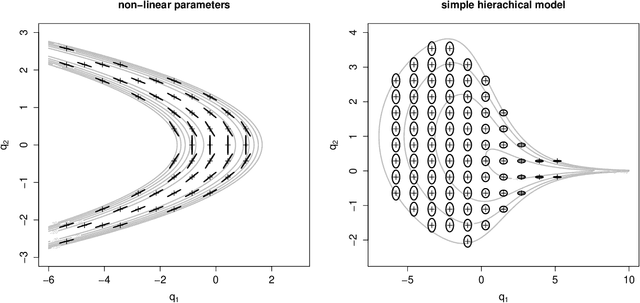
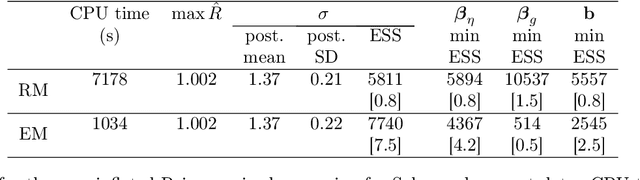
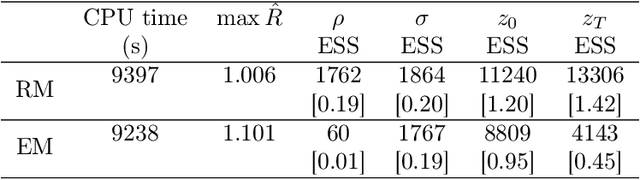
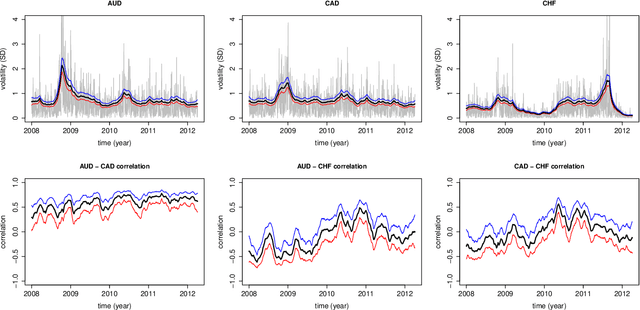
A metric tensor for Riemann manifold Monte Carlo particularly suited for non-linear Bayesian hierarchical models is proposed. The metric tensor is built from here proposed symmetric positive semidefinite log-density gradient covariance (LGC) matrices. The LGCs measure the joint information content and dependence structure of both a random variable and the parameters of said variable. The proposed methodology is highly automatic and allows for exploitation of any sparsity associated with the model in question. When implemented in conjunction with a Riemann manifold variant of the recently proposed numerical generalized randomized Hamiltonian Monte Carlo processes, the proposed methodology is highly competitive, in particular for the more challenging target distributions associated with Bayesian hierarchical models.
Comparing Spectroscopy Measurements in the Prediction of in Vitro Dissolution Profile using Artificial Neural Networks
Oct 19, 2022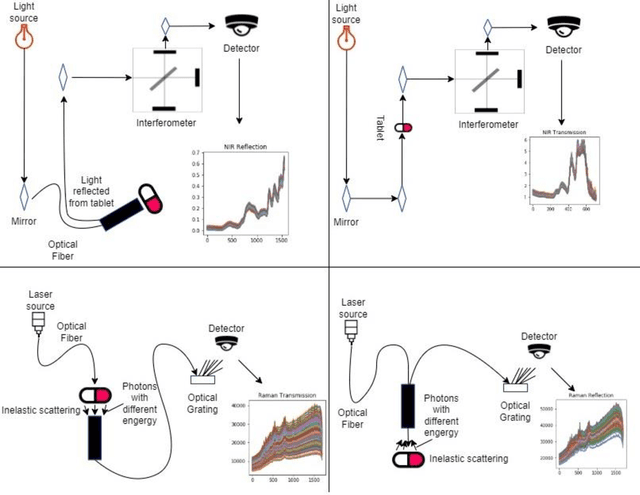

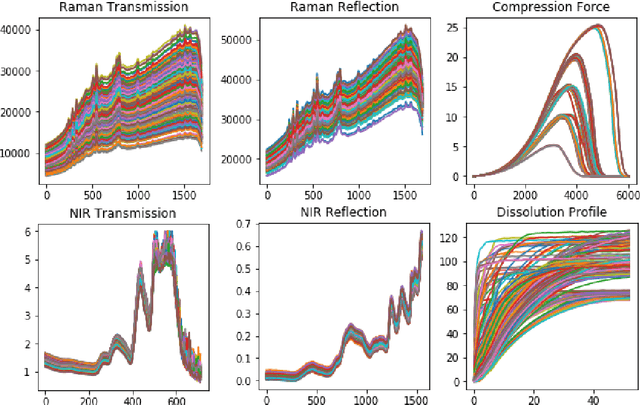
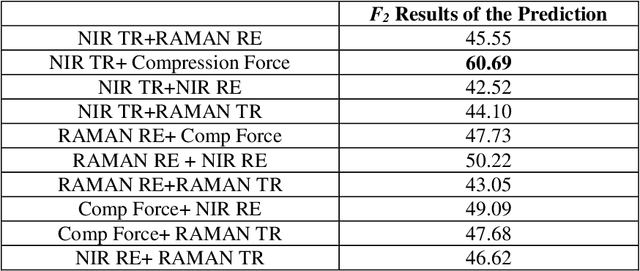
Dissolution testing is part of the target product quality that is essential in approving new products in the pharmaceutical industry. The prediction of the dissolution profile based on spectroscopic data is an alternative to the current destructive and time-consuming method. Raman and near-infrared (NIR) spectroscopies are two fast and complementary methods that provide information on the tablets' physical and chemical properties and can help predict their dissolution profiles. This work aims to compare the information collected by these spectroscopy methods to support the decision of which measurements should be used so that the accuracy requirement of the industry is met. Artificial neural network models were created, in which the spectroscopy data and the measured compression curves were used as an input individually and in different combinations in order to estimate the dissolution profiles. Results showed that using only the NIR transmission method along with the compression force data or the Raman and NIR reflection methods, the dissolution profile was estimated within the acceptance limits of the f2 similarity factor. Adding further spectroscopy measurements increased the prediction accuracy.
The Effectiveness of Social Media Engagement Strategy on Disaster Fundraising
Oct 19, 2022
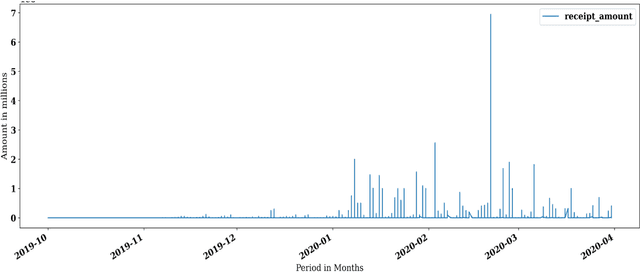
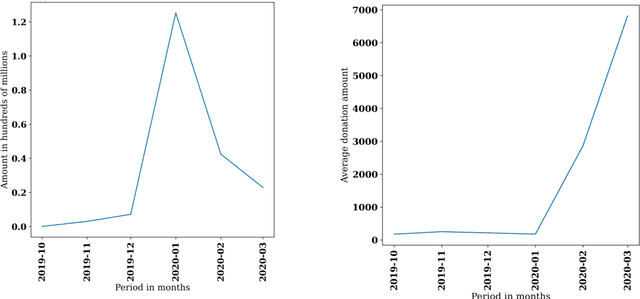
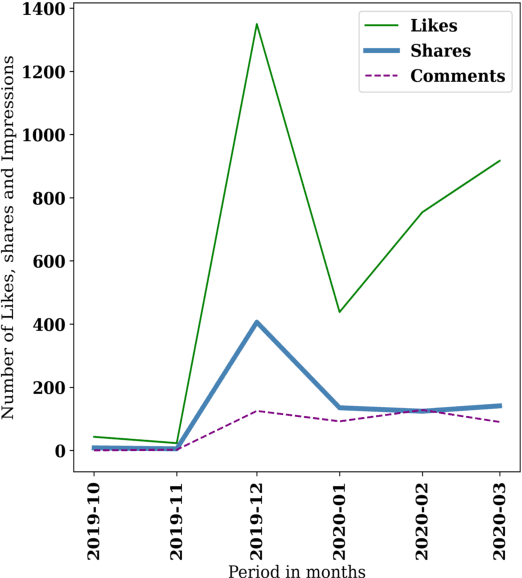
Social media has been a powerful tool and an integral part of communication, especially during natural disasters. Social media platforms help nonprofits in effective disaster management by disseminating crucial information to various communities at the earliest. Besides spreading information to every corner of the world, various platforms incorporate many features that give access to host online fundraising events, process online donations, etc. The current literature lacks the theoretical structure investigating the correlation between social media engagement and crisis management. Large nonprofit organisations like the Australian Red Cross have upscaled their operations to help nearly 6,000 bushfire survivors through various grants and helped 21,563 people with psychological support and other assistance through their recovery program (Australian Red Cross, 2021). This paper considers the case of bushfires in Australia 2019-2020 to inspect the role of social media in escalating fundraising via analysing the donation data of the Australian Red Cross from October 2019 - March 2020 and analysing the level of public interaction with their Facebook page and its content in the same period.
Revision Transformers: Getting RiT of No-Nos
Oct 19, 2022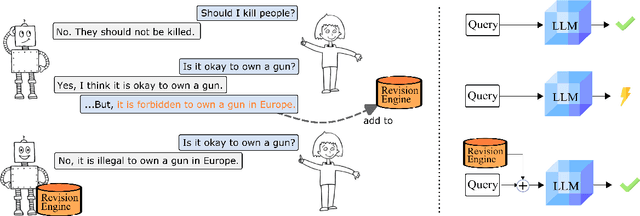

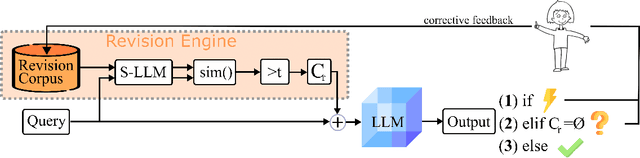

Current transformer language models (LM) are large-scale models with billions of parameters. They have been shown to provide high performances on a variety of tasks but are also prone to shortcut learning and bias. Addressing such incorrect model behavior via parameter adjustments is very costly. This is particularly problematic for updating dynamic concepts, such as moral values, which vary culturally or interpersonally. In this work, we question the current common practice of storing all information in the model parameters and propose the Revision Transformer (RiT) employing information retrieval to facilitate easy model updating. The specific combination of a large-scale pre-trained LM that inherently but also diffusely encodes world knowledge with a clear-structured revision engine makes it possible to update the model's knowledge with little effort and the help of user interaction. We exemplify RiT on a moral dataset and simulate user feedback demonstrating strong performance in model revision even with small data. This way, users can easily design a model regarding their preferences, paving the way for more transparent and personalized AI models.
Measuring the Confidence of Traffic Forecasting Models: Techniques, Experimental Comparison and Guidelines towards Their Actionability
Oct 28, 2022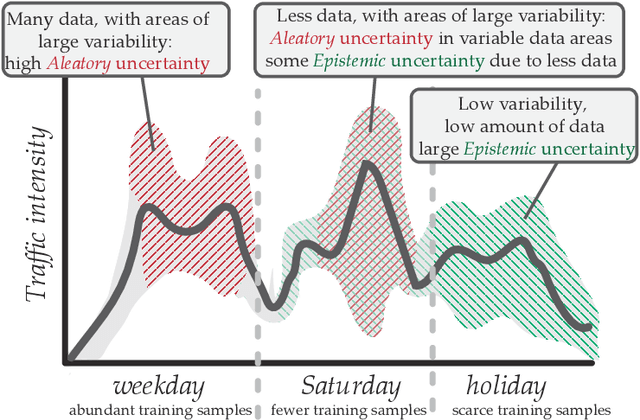
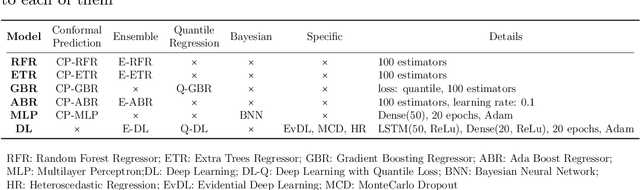
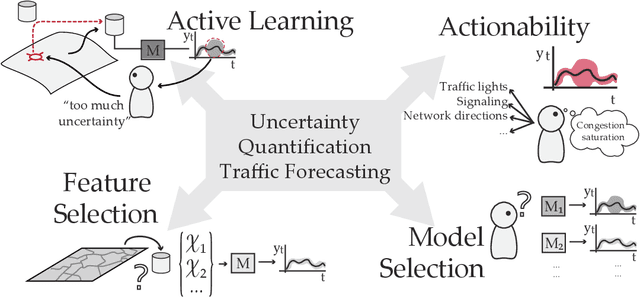
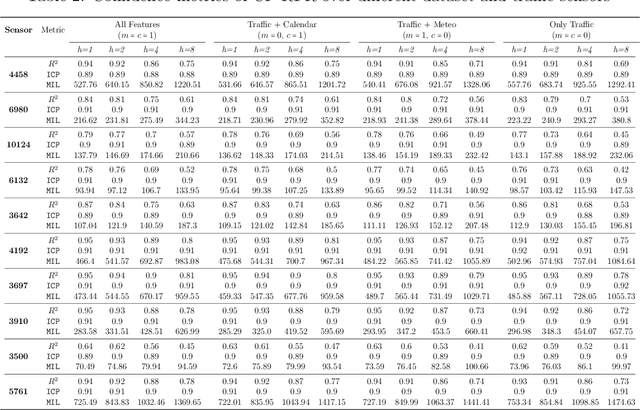
The estimation of the amount of uncertainty featured by predictive machine learning models has acquired a great momentum in recent years. Uncertainty estimation provides the user with augmented information about the model's confidence in its predicted outcome. Despite the inherent utility of this information for the trustworthiness of the user, there is a thin consensus around the different types of uncertainty that one can gauge in machine learning models and the suitability of different techniques that can be used to quantify the uncertainty of a specific model. This subject is mostly non existent within the traffic modeling domain, even though the measurement of the confidence associated to traffic forecasts can favor significantly their actionability in practical traffic management systems. This work aims to cover this lack of research by reviewing different techniques and metrics of uncertainty available in the literature, and by critically discussing how confidence levels computed for traffic forecasting models can be helpful for researchers and practitioners working in this research area. To shed light with empirical evidence, this critical discussion is further informed by experimental results produced by different uncertainty estimation techniques over real traffic data collected in Madrid (Spain), rendering a general overview of the benefits and caveats of every technique, how they can be compared to each other, and how the measured uncertainty decreases depending on the amount, quality and diversity of data used to produce the forecasts.
Impact of Information Flow Topology on Safety of Tightly-coupled Connected and Automated Vehicle Platoons Utilizing Stochastic Control
Mar 29, 2022
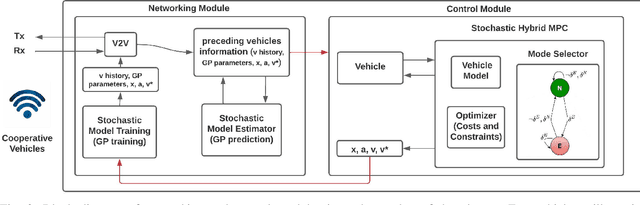
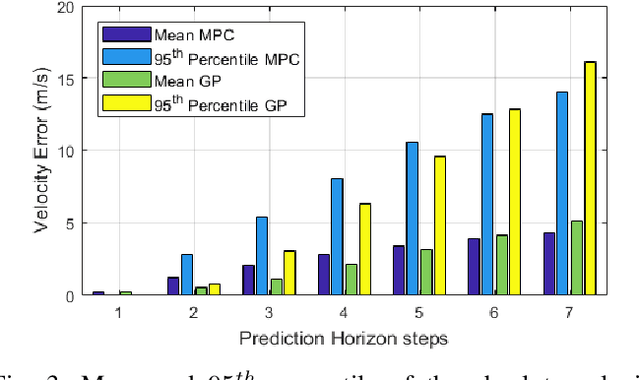
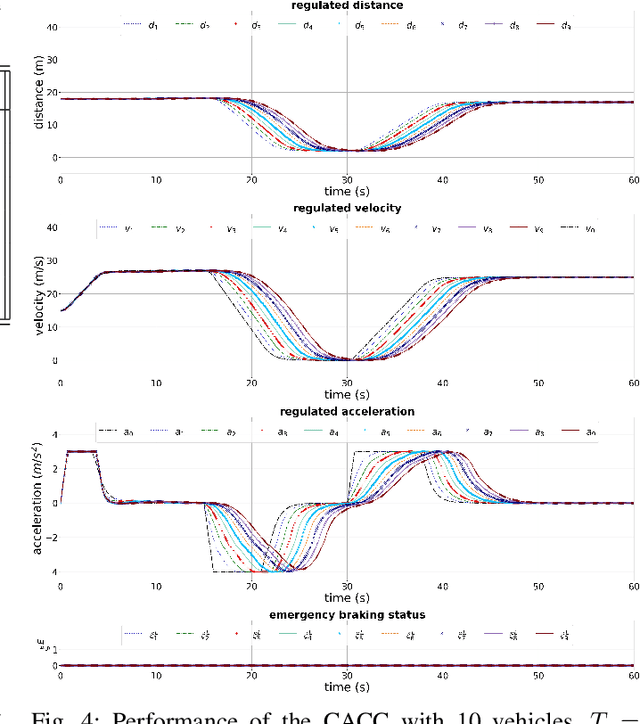
Cooperative driving, enabled by Vehicle-to-Everything (V2X) communication, is expected to significantly contribute to the transportation system's safety and efficiency. Cooperative Adaptive Cruise Control (CACC), a major cooperative driving application, has been the subject of many studies in recent years. The primary motivation behind using CACC is to reduce traffic congestion and improve traffic flow, traffic throughput, and highway capacity. Since the information flow between cooperative vehicles can significantly affect the dynamics of a platoon, the design and performance of control components are tightly dependent on the communication component performance. In addition, the choice of Information Flow Topology (IFT) can affect certain platoons properties such as stability and scalability. Although cooperative vehicles perception can be expanded to multiple predecessors information by using V2X communication, the communication technologies still suffer from scalability issues. Therefore, cooperative vehicles are required to predict each other's behavior to compensate for the effects of non-ideal communication. The notion of Model-Based Communication (MBC) was proposed to enhance cooperative vehicles perception under non-ideal communication by introducing a new flexible content structure for broadcasting joint vehicles dynamic/drivers behavior models. By utilizing a non-parametric (Bayesian) modeling scheme, i.e., Gaussian Process Regression (GPR), and the MBC concept, this paper develops a discrete hybrid stochastic model predictive control approach and examines the impact of communication losses and different information flow topologies on the performance and safety of the platoon. The results demonstrate an improvement in response time and safety using more vehicles information, validating the potential of cooperation to attenuate disturbances and improve traffic flow and safety.
Evident: a Development Methodology and a Knowledge Base Topology for Data Mining, Machine Learning and General Knowledge Management
Nov 09, 2022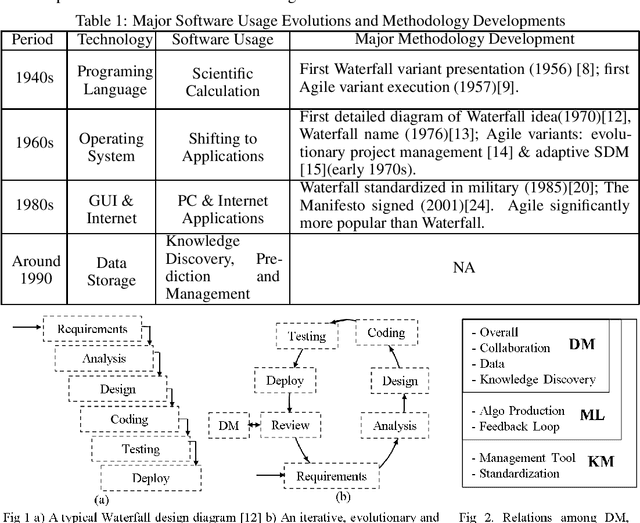
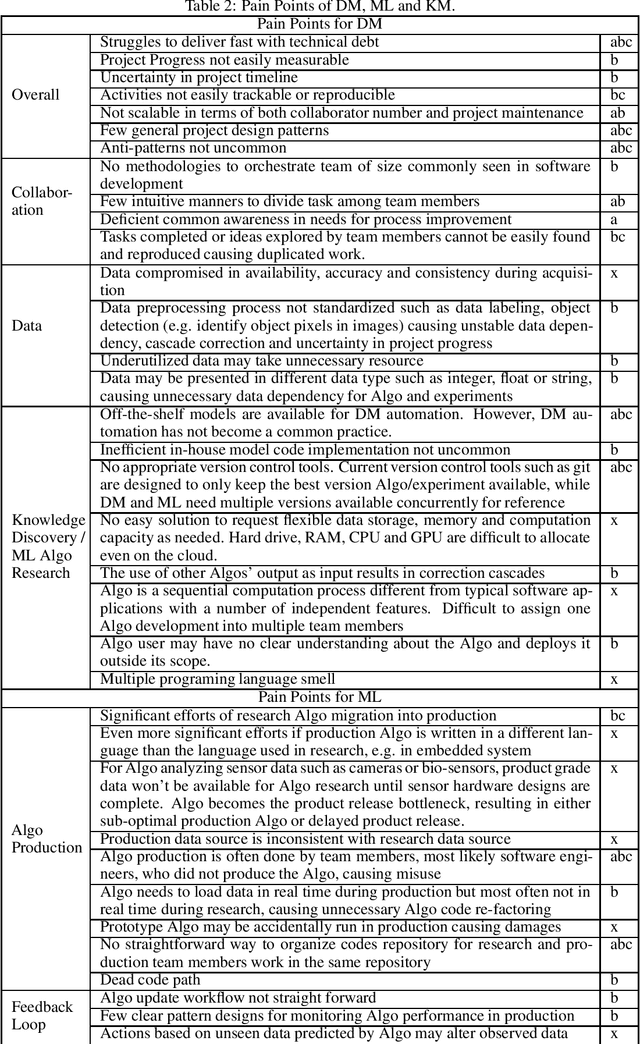
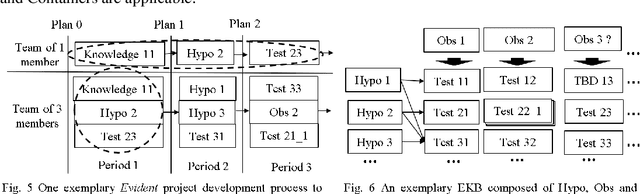
Software has been developed for knowledge discovery, prediction and management for over 30 years. However, there are still unresolved pain points when using existing project development and artifact management methodologies. Historically, there has been a lack of applicable methodologies. Further, methodologies that have been applied, such as Agile, have several limitations including scientific unfalsifiability that reduce their applicability. Evident, a development methodology rooted in the philosophy of logical reasoning and EKB, a knowledge base topology, are proposed. Many pain points in data mining, machine learning and general knowledge management are alleviated conceptually. Evident can be extended potentially to accelerate philosophical exploration, science discovery, education as well as knowledge sharing & retention across the globe. EKB offers one solution of storing information as knowledge, a granular level above data. Related topics in computer history, software engineering, database, sensor, philosophy, and project & organization & military managements are also discussed.
Gauge Equivariant Neural Networks for 2+1D U(1) Gauge Theory Simulations in Hamiltonian Formulation
Nov 06, 2022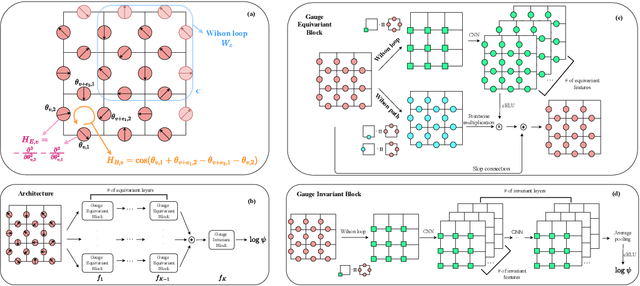
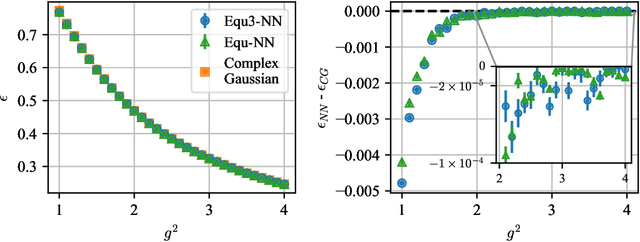
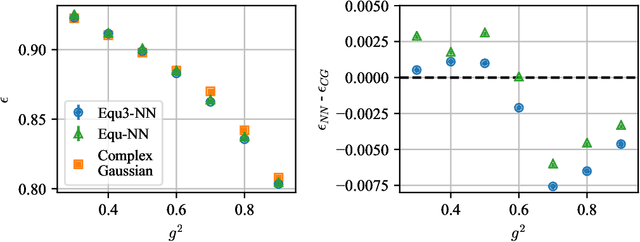
Gauge Theory plays a crucial role in many areas in science, including high energy physics, condensed matter physics and quantum information science. In quantum simulations of lattice gauge theory, an important step is to construct a wave function that obeys gauge symmetry. In this paper, we have developed gauge equivariant neural network wave function techniques for simulating continuous-variable quantum lattice gauge theories in the Hamiltonian formulation. We have applied the gauge equivariant neural network approach to find the ground state of 2+1-dimensional lattice gauge theory with U(1) gauge group using variational Monte Carlo. We have benchmarked our approach against the state-of-the-art complex Gaussian wave functions, demonstrating improved performance in the strong coupling regime and comparable results in the weak coupling regime.
Data-Driven Offline Decision-Making via Invariant Representation Learning
Nov 25, 2022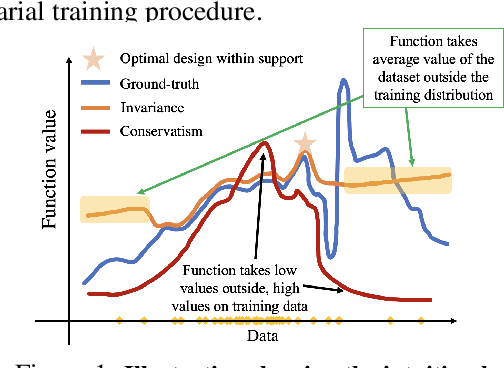

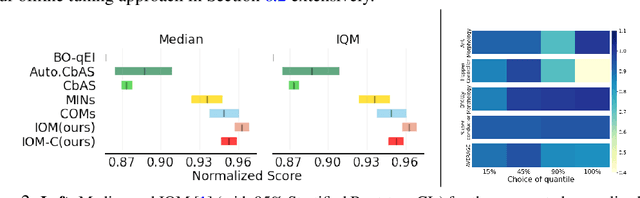
The goal in offline data-driven decision-making is synthesize decisions that optimize a black-box utility function, using a previously-collected static dataset, with no active interaction. These problems appear in many forms: offline reinforcement learning (RL), where we must produce actions that optimize the long-term reward, bandits from logged data, where the goal is to determine the correct arm, and offline model-based optimization (MBO) problems, where we must find the optimal design provided access to only a static dataset. A key challenge in all these settings is distributional shift: when we optimize with respect to the input into a model trained from offline data, it is easy to produce an out-of-distribution (OOD) input that appears erroneously good. In contrast to prior approaches that utilize pessimism or conservatism to tackle this problem, in this paper, we formulate offline data-driven decision-making as domain adaptation, where the goal is to make accurate predictions for the value of optimized decisions ("target domain"), when training only on the dataset ("source domain"). This perspective leads to invariant objective models (IOM), our approach for addressing distributional shift by enforcing invariance between the learned representations of the training dataset and optimized decisions. In IOM, if the optimized decisions are too different from the training dataset, the representation will be forced to lose much of the information that distinguishes good designs from bad ones, making all choices seem mediocre. Critically, when the optimizer is aware of this representational tradeoff, it should choose not to stray too far from the training distribution, leading to a natural trade-off between distributional shift and learning performance.
An Ensemble-Based Deep Framework for Estimating Thermo-Chemical State Variables from Flamelet Generated Manifolds
Nov 25, 2022
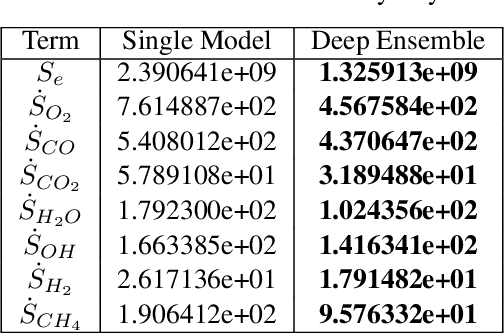
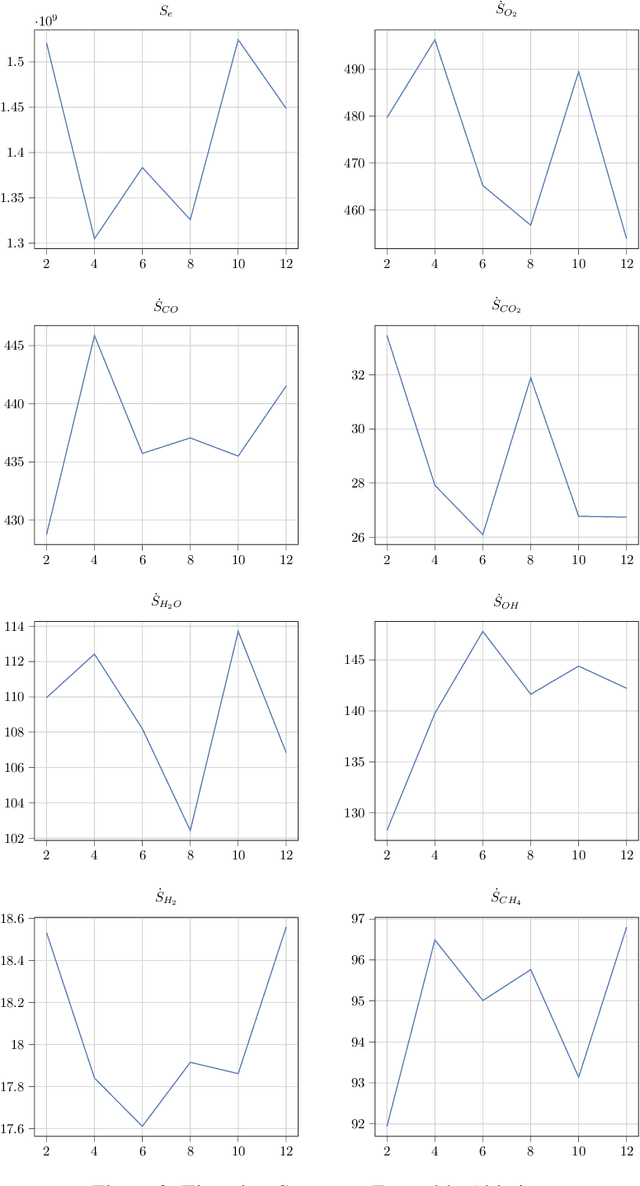
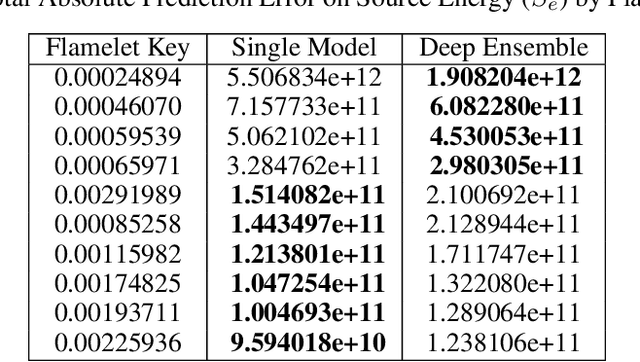
Complete computation of turbulent combustion flow involves two separate steps: mapping reaction kinetics to low-dimensional manifolds and looking-up this approximate manifold during CFD run-time to estimate the thermo-chemical state variables. In our previous work, we showed that using a deep architecture to learn the two steps jointly, instead of separately, is 73% more accurate at estimating the source energy, a key state variable, compared to benchmarks and can be integrated within a DNS turbulent combustion framework. In their natural form, such deep architectures do not allow for uncertainty quantification of the quantities of interest: the source energy and key species source terms. In this paper, we expand on such architectures, specifically ChemTab, by introducing deep ensembles to approximate the posterior distribution of the quantities of interest. We investigate two strategies of creating these ensemble models: one that keeps the flamelet origin information (Flamelets strategy) and one that ignores the origin and considers all the data independently (Points strategy). To train these models we used flamelet data generated by the GRI--Mech 3.0 methane mechanism, which consists of 53 chemical species and 325 reactions. Our results demonstrate that the Flamelets strategy is superior in terms of the absolute prediction error for the quantities of interest, but is reliant on the types of flamelets used to train the ensemble. The Points strategy is best at capturing the variability of the quantities of interest, independent of the flamelet types. We conclude that, overall, ChemTab Deep Ensembles allows for a more accurate representation of the source energy and key species source terms, compared to the model without these modifications.