 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EDGAR: Embedded Detection of Gunshots by AI in Real-time
Nov 25, 2022
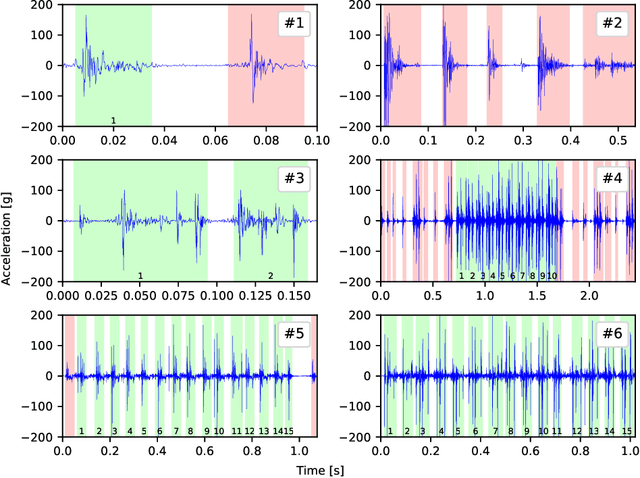
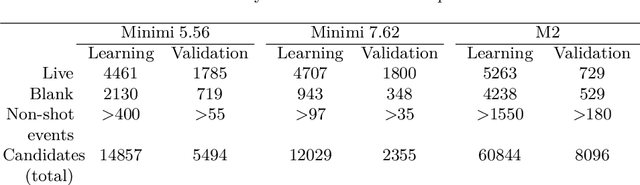
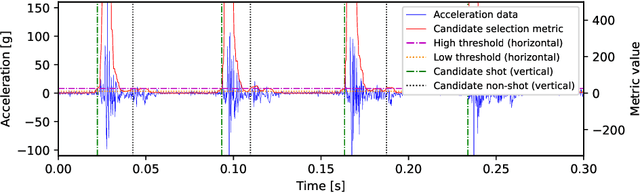
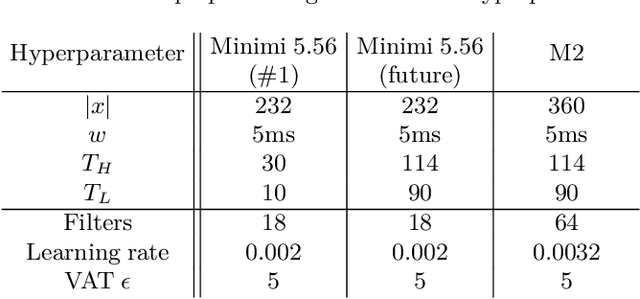
Electronic shot counters allow armourers to perform preventive and predictive maintenance based on quantitative measurements, improving reliability, reducing the frequency of accidents, and reducing maintenance costs. To answer a market pressure for both low lead time to market and increased customisation, we aim to solve the shot detection and shot counting problem in a generic way through machine learning. In this study, we describe a method allowing one to construct a dataset with minimal labelling effort by only requiring the total number of shots fired in a time series. To our knowledge, this is the first study to propose a technique, based on learning from label proportions, that is able to exploit these weak labels to derive an instance-level classifier able to solve the counting problem and the more general discrimination problem. We also show that this technique can be deployed in heavily constrained microcontrollers while still providing hard real-time (<100ms) inference. We evaluate our technique against a state-of-the-art unsupervised algorithm and show a sizeable improvement, suggesting that the information from the weak labels is successfully leveraged. Finally, we evaluate our technique against human-generated state-of-the-art algorithms and show that it provides comparable performance and significantly outperforms them in some offline and real-world benchmarks.
Beyond Smoothing: Unsupervised Graph Representation Learning with Edge Heterophily Discriminating
Nov 25, 2022
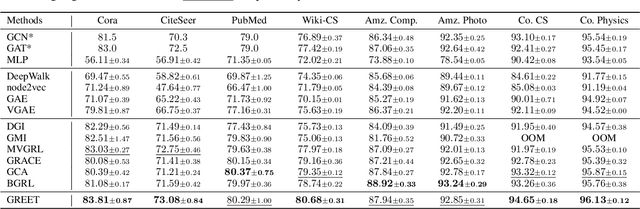
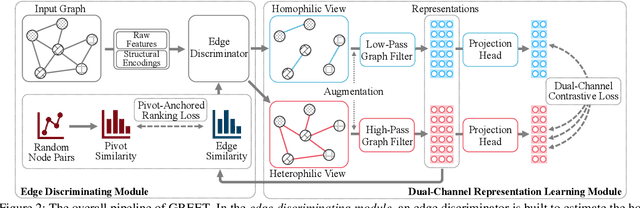
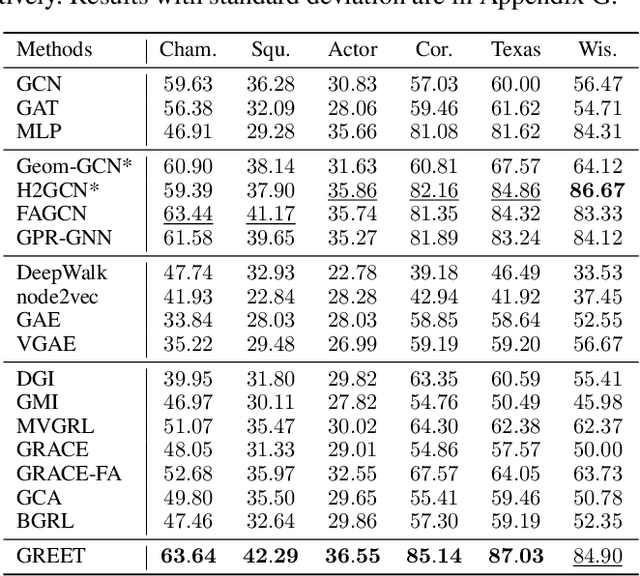
Unsupervised graph representation learning (UGRL) has drawn increasing research attention and achieved promising results in several graph analytic tasks. Relying on the homophily assumption, existing UGRL methods tend to smooth the learned node representations along all edges, ignoring the existence of heterophilic edges that connect nodes with distinct attributes. As a result, current methods are hard to generalize to heterophilic graphs where dissimilar nodes are widely connected, and also vulnerable to adversarial attacks. To address this issue, we propose a novel unsupervised Graph Representation learning method with Edge hEterophily discriminaTing (GREET) which learns representations by discriminating and leveraging homophilic edges and heterophilic edges. To distinguish two types of edges, we build an edge discriminator that infers edge homophily/heterophily from feature and structure information. We train the edge discriminator in an unsupervised way through minimizing the crafted pivot-anchored ranking loss, with randomly sampled node pairs acting as pivots. Node representations are learned through contrasting the dual-channel encodings obtained from the discriminated homophilic and heterophilic edges. With an effective interplaying scheme, edge discriminating and representation learning can mutually boost each other during the training phase. We conducted extensive experiments on 14 benchmark datasets and multiple learning scenarios to demonstrate the superiority of GREET.
Efficient Document Retrieval by End-to-End Refining and Quantizing BERT Embedding with Contrastive Product Quantization
Oct 31, 2022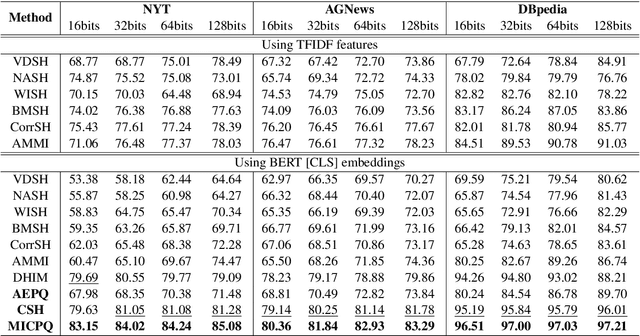
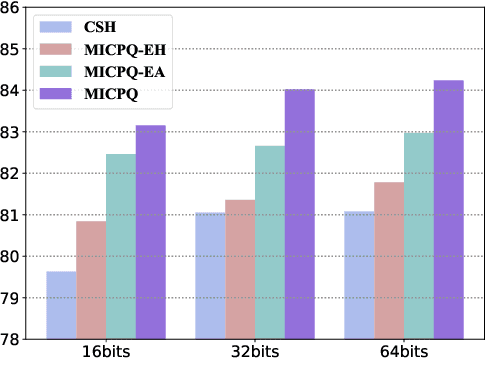
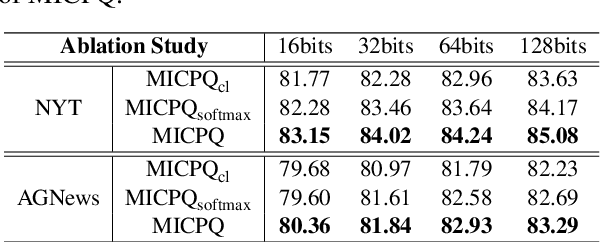
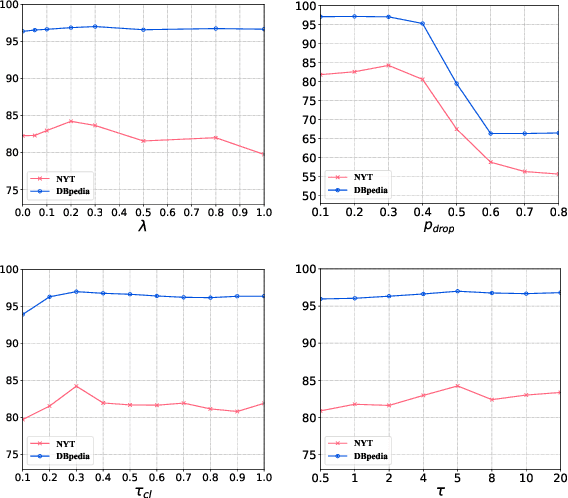
Efficient document retrieval heavily relies on the technique of semantic hashing, which learns a binary code for every document and employs Hamming distance to evaluate document distances. However, existing semantic hashing methods are mostly established on outdated TFIDF features, which obviously do not contain lots of important semantic information about documents. Furthermore, the Hamming distance can only be equal to one of several integer values, significantly limiting its representational ability for document distances. To address these issues, in this paper, we propose to leverage BERT embeddings to perform efficient retrieval based on the product quantization technique, which will assign for every document a real-valued codeword from the codebook, instead of a binary code as in semantic hashing. Specifically, we first transform the original BERT embeddings via a learnable mapping and feed the transformed embedding into a probabilistic product quantization module to output the assigned codeword. The refining and quantizing modules can be optimized in an end-to-end manner by minimizing the probabilistic contrastive loss. A mutual information maximization based method is further proposed to improve the representativeness of codewords, so that documents can be quantized more accurately. Extensive experiments conducted on three benchmarks demonstrate that our proposed method significantly outperforms current state-of-the-art baselines.
Downlink Massive MIMO Channel Estimation via Deep Unrolling : Sparsity Exploitations in Angular Domain
Oct 31, 2022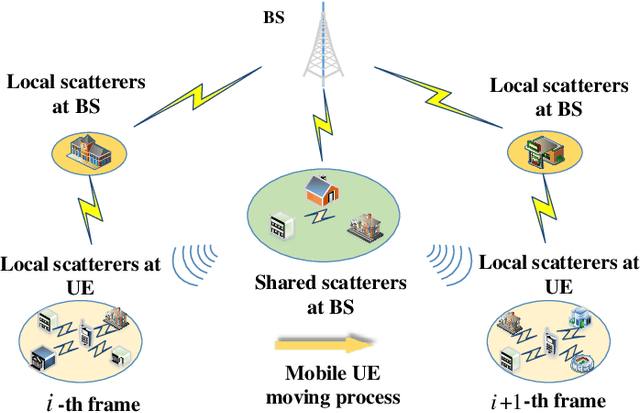
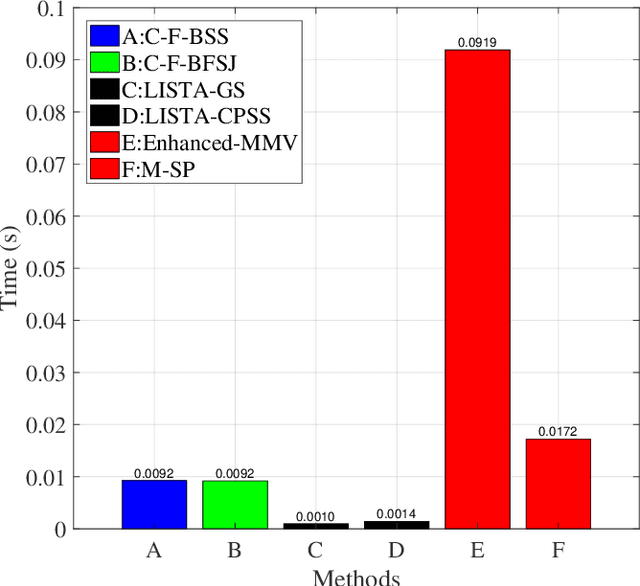
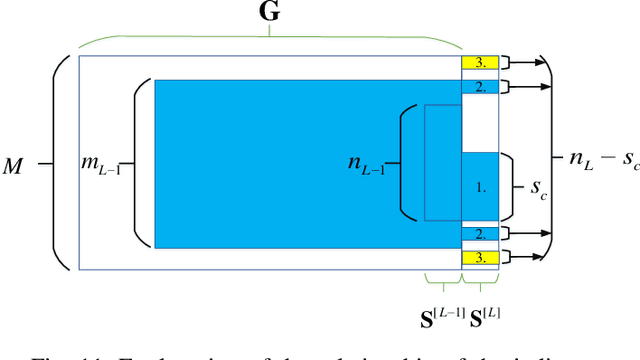
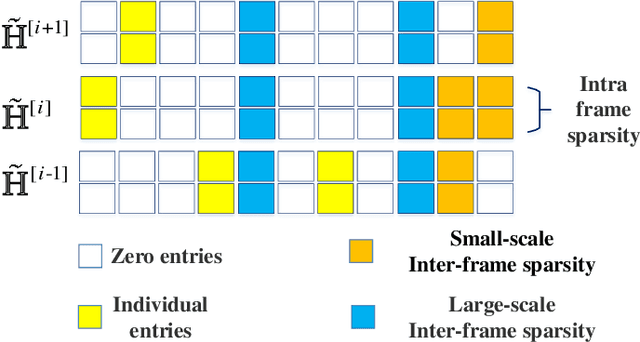
In frequency division duplex (FDD) massive MIMO systems, reliable downlink channel estimation is essential for the subsequent data transmission but is realized at the cost of massive pilot overhead due to hundreds of antennas at base station (BS). In order to reduce the pilot overhead without compromising the estimation, compressive sensing (CS) based methods have been widely applied for channel estimation by exploiting the inherent sparse structure of massive MIMO channel in angular domain. However, they still suffer from high complexity during optimization process and the requirement of prior knowledge on sparsity information. To overcome these challenges, this paper develops a novel hybrid channel estimation framework by integrating the model-driven CS and data-driven deep unrolling techniques. The proposed framework is composed of a coarse estimation part and a fine correction part, which is implemented in a two-stage manner to exploit both inter- and intra-frame sparsities of channels in angular domain. Then, two estimation schemes are designed depending on whether priori sparsity information is required, where the second scheme designs a new thresholding function to eliminate such requirement. Numerical results are provided to verify that our schemes can achieve high accuracy with low pilot overhead and low complexity.
Information Theoretic Structured Generative Modeling
Oct 12, 2021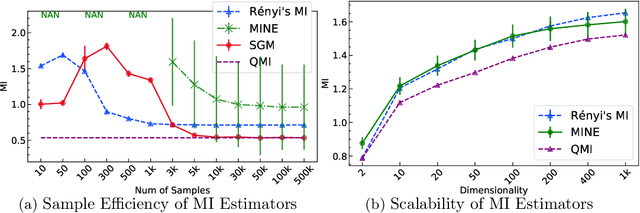
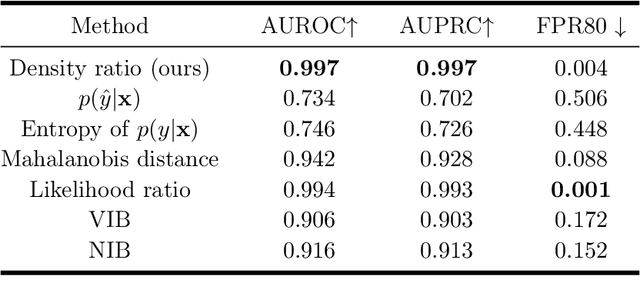
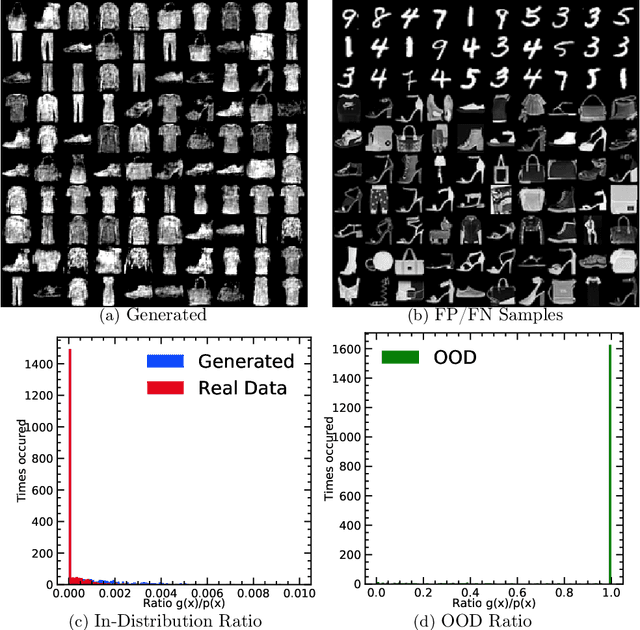
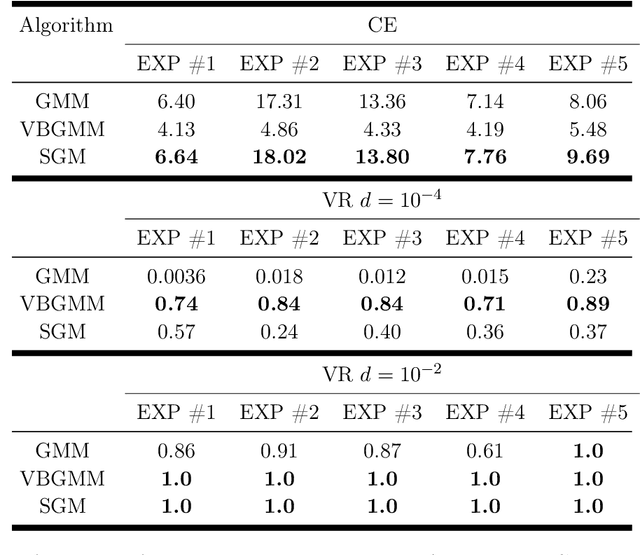
R\'enyi's information provides a theoretical foundation for tractable and data-efficient non-parametric density estimation, based on pair-wise evaluations in a reproducing kernel Hilbert space (RKHS). This paper extends this framework to parametric probabilistic modeling, motivated by the fact that R\'enyi's information can be estimated in closed-form for Gaussian mixtures. Based on this special connection, a novel generative model framework called the structured generative model (SGM) is proposed that makes straightforward optimization possible, because costs are scale-invariant, avoiding high gradient variance while imposing less restrictions on absolute continuity, which is a huge advantage in parametric information theoretic optimization. The implementation employs a single neural network driven by an orthonormal input appended to a single white noise source adapted to learn an infinite Gaussian mixture model (IMoG), which provides an empirically tractable model distribution in low dimensions. To train SGM, we provide three novel variational cost functions, based on R\'enyi's second-order entropy and divergence, to implement minimization of cross-entropy, minimization of variational representations of $f$-divergence, and maximization of the evidence lower bound (conditional probability). We test the framework for estimation of mutual information and compare the results with the mutual information neural estimation (MINE), for density estimation, for conditional probability estimation in Markov models as well as for training adversarial networks. Our preliminary results show that SGM significantly improves MINE estimation in terms of data efficiency and variance, conventional and variational Gaussian mixture models, as well as the performance of generative adversarial networks.
Joint Receiver Design for Integrated Sensing and Communications: Is SIC Optimal?
Nov 10, 2022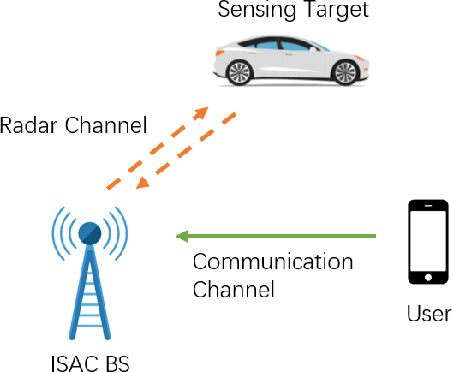
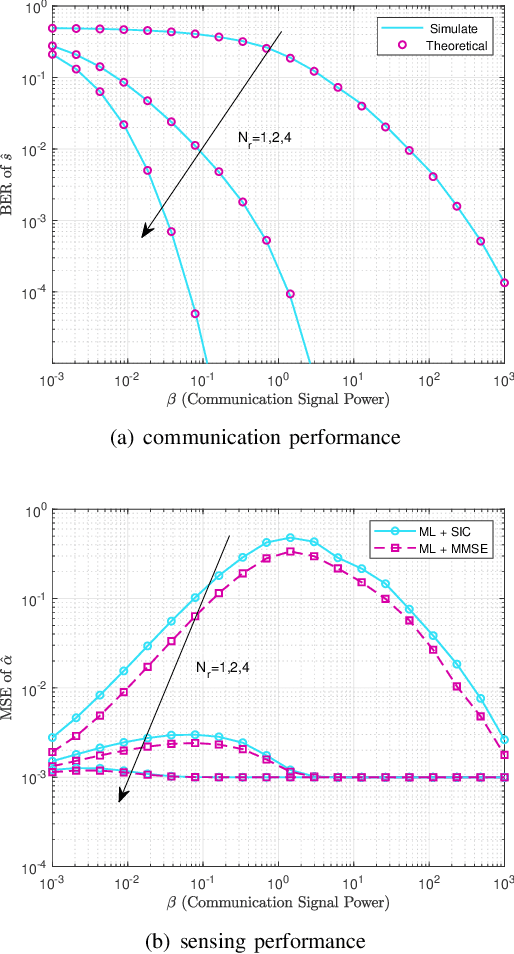
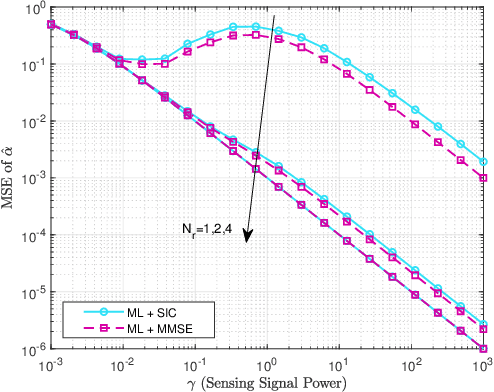
In this letter, we investigate the joint receiver design for integrated sensing and communication (ISAC) systems, where the communication signal and the target echo signal are simultaneously received and processed to achieve a balanced performance between both functionalities. In particular, we proposed two design schemes to solve the joint sensing and communication problem of receive signal processing. The first is based on maximum likelihood (ML) detection and successive interference cancellation (SIC), and the other formulates a minimum mean squared error (MMSE) estimator for target estimation. We show that with the structural information of the communication signal taken into account, the second approach outperforms the SIC method. Numerical results are provided to validate the effectiveness of the proposed optimal designs.
A Novel Autonomous Mobile Platform for Monitoring Fish Habitat
Nov 02, 2022
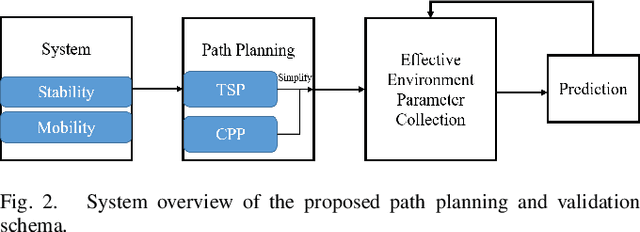
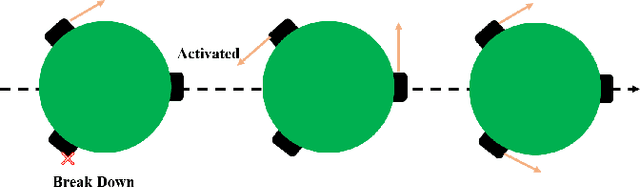
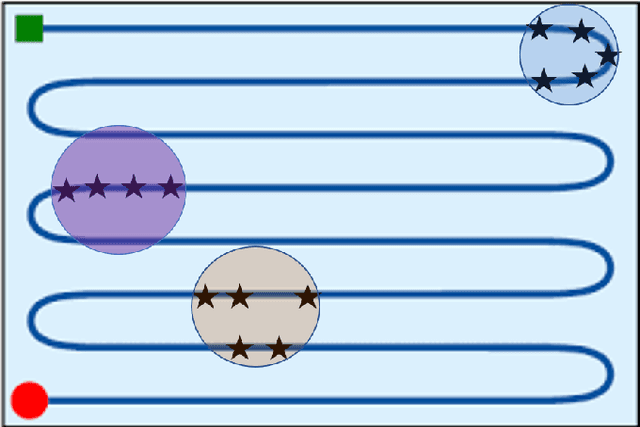
Implementing fully automatic unmanned surface vehicles (USVs) monitoring water quality is challenging since effectively collecting environmental data while keeping the platform stable and environmental-friendly is hard to approach. To address this problem, we construct a USV that can automatically navigate an efficient path to sample water quality parameters in order to monitor the aquatic environment. The detection device needs to be stable enough to resist a hostile environment or climates while enormous volumes will disturb the aquaculture environment. Meanwhile, planning an efficient path for information collecting needs to deal with the contradiction between the restriction of energy and the amount of information in the coverage region. To tackle with mentioned challenges, we provide a USV platform that can perfectly balance mobility, stability, and portability attributed to its special round-shape structure and redundancy motion design. For informative planning, we combined the TSP and CPP algorithms to construct an optimistic plan for collecting more data within a certain range and limiting energy restrictions.We designed a fish existence prediction scenario to verify the novel system in both simulation experiments and field experiments. The novel aquaculture environment monitoring system significantly reduces the burden of manual operation in the fishery inspection field. Additionally, the simplicity of the sensor setup and the minimal cost of the platform enables its other possible applications in aquatic exploration and commercial utilization.
Adversarial Contrastive Learning for Evidence-aware Fake News Detection with Graph Neural Networks
Oct 11, 2022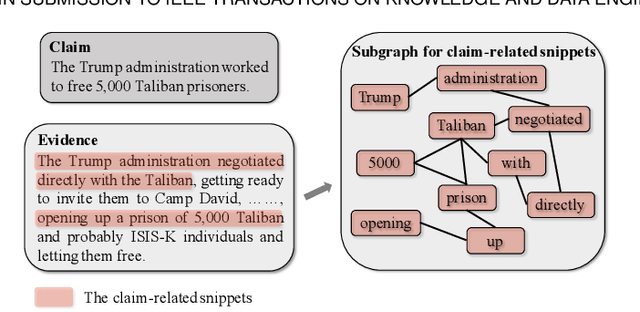

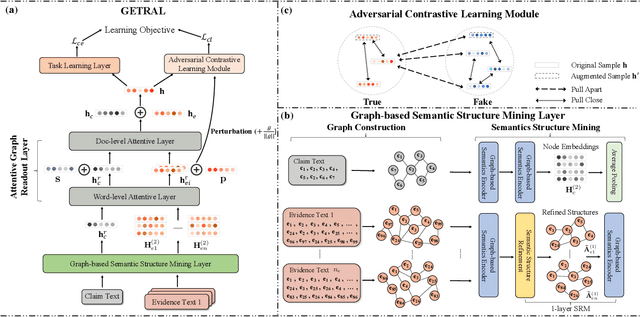

The prevalence and perniciousness of fake news have been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on attention mechanisms. Despite their effectiveness, they still suffer from three weaknesses. Firstly, sequential models fail to integrate the relevant information that is scattered far apart in evidences. Secondly, they underestimate much redundant information in evidences may be useless or harmful. Thirdly, insufficient data utilization limits the separability and reliability of representations captured by the model. To solve these problems, we propose a unified Graph-based sEmantic structure mining framework with ConTRAstive Learning, namely GETRAL in short. Specifically, we first model claims and evidences as graph-structured data to capture the long-distance semantic dependency. Consequently, we reduce information redundancy by performing graph structure learning. Then the fine-grained semantic representations are fed into the claim-evidence interaction module for predictions. Finally, an adversarial contrastive learning module is applied to make full use of data and strengthen representation learning. Comprehensive experiments have demonstrated the superiority of GETRAL over the state-of-the-arts and validated the efficacy of semantic mining with graph structure and contrastive learning.
Quantitative Evidence on Overlooked Aspects of Enrollment Speaker Embeddings for Target Speaker Separation
Oct 26, 2022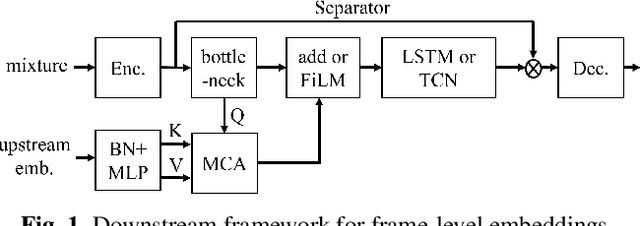
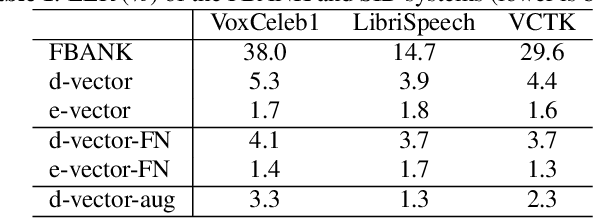
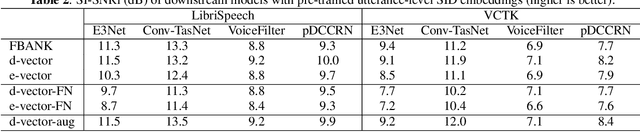

Single channel target speaker separation (TSS) aims at extracting a speaker's voice from a mixture of multiple talkers given an enrollment utterance of that speaker. A typical deep learning TSS framework consists of an upstream model that obtains enrollment speaker embeddings and a downstream model that performs the separation conditioned on the embeddings. In this paper, we look into several important but overlooked aspects of the enrollment embeddings, including the suitability of the widely used speaker identification embeddings, the introduction of the log-mel filterbank and self-supervised embeddings, and the embeddings' cross-dataset generalization capability. Our results show that the speaker identification embeddings could lose relevant information due to a sub-optimal metric, training objective, or common pre-processing. In contrast, both the filterbank and the self-supervised embeddings preserve the integrity of the speaker information, but the former consistently outperforms the latter in a cross-dataset evaluation. The competitive separation and generalization performance of the previously overlooked filterbank embedding is consistent across our study, which calls for future research on better upstream features.
Boosting Binary Neural Networks via Dynamic Thresholds Learning
Nov 04, 2022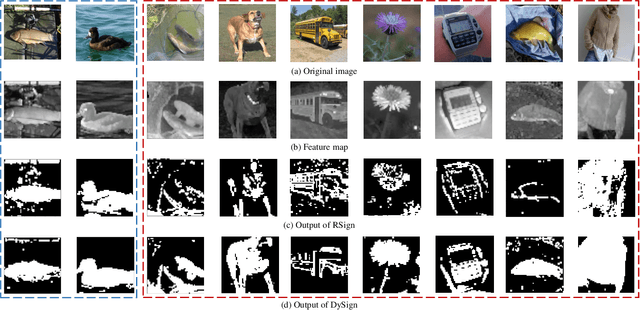
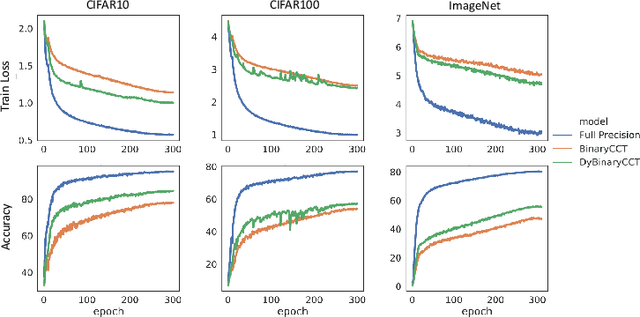
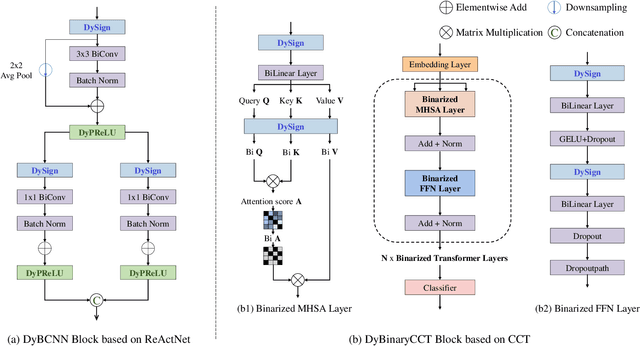
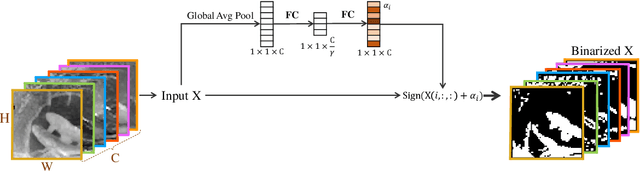
Developing lightweight Deep Convolutional Neural Networks (DCNNs) and Vision Transformers (ViTs) has become one of the focuses in vision research since the low computational cost is essential for deploying vision models on edge devices. Recently, researchers have explored highly computational efficient Binary Neural Networks (BNNs) by binarizing weights and activations of Full-precision Neural Networks. However, the binarization process leads to an enormous accuracy gap between BNN and its full-precision version. One of the primary reasons is that the Sign function with predefined or learned static thresholds limits the representation capacity of binarized architectures since single-threshold binarization fails to utilize activation distributions. To overcome this issue, we introduce the statistics of channel information into explicit thresholds learning for the Sign Function dubbed DySign to generate various thresholds based on input distribution. Our DySign is a straightforward method to reduce information loss and boost the representative capacity of BNNs, which can be flexibly applied to both DCNNs and ViTs (i.e., DyBCNN and DyBinaryCCT) to achieve promising performance improvement. As shown in our extensive experiments. For DCNNs, DyBCNNs based on two backbones (MobileNetV1 and ResNet18) achieve 71.2% and 67.4% top1-accuracy on ImageNet dataset, outperforming baselines by a large margin (i.e., 1.8% and 1.5% respectively). For ViTs, DyBinaryCCT presents the superiority of the convolutional embedding layer in fully binarized ViTs and achieves 56.1% on the ImageNet dataset, which is nearly 9% higher than the baseline.